引言
在现代互联网架构中,负载均衡器是整个系统的交通枢纽,负责将海量请求分发到后端服务器。随着业务规模的爆炸式增长,传统的 Nginx 和 LVS 逐渐暴露出性能瓶颈。如何在有限的硬件资源下,压榨出每一滴性能,成为架构师必须面对的挑战。
本文将深入探讨高性能负载均衡技术,从 DPVS 的内核旁路架构,到 Nginx 的精细调优,再到操作系统内核的深度优化,最后通过真实的性能测试数据,揭示如何构建能够应对百万级并发的负载均衡系统。
第一部分:DPVS - 内核旁路的高性能负载均衡
1.1 为什么需要 DPVS?
传统的四层负载均衡方案如 LVS 和 Nginx,虽然在中小规模场景下表现良好,但在面对超高并发、低延迟的极端场景时,往往会遇到性能天花板。
传统方案的瓶颈:

性能瓶颈分析:
- 中断开销:每个数据包都会触发 CPU 中断,频繁的中断会打乱 CPU 的流水线
- 上下文切换:内核态和用户态之间的切换成本高昂
- 锁竞争:多核环境下,内核协议栈的全局锁成为性能杀手
- 内存拷贝:数据包在内核空间和用户空间之间多次拷贝
DPVS 的解决思路:内核旁路(Kernel Bypass)
DPVS(Data Plane Virtual Server)是基于 DPDK(Data Plane Development Kit)的高性能四层负载均衡系统。它的核心理念是绕过 Linux 内核网络栈,直接在用户态处理网络数据包。
1.2 DPVS 的核心架构
DPVS 采用分层设计,从下到上分为五个主要层次:
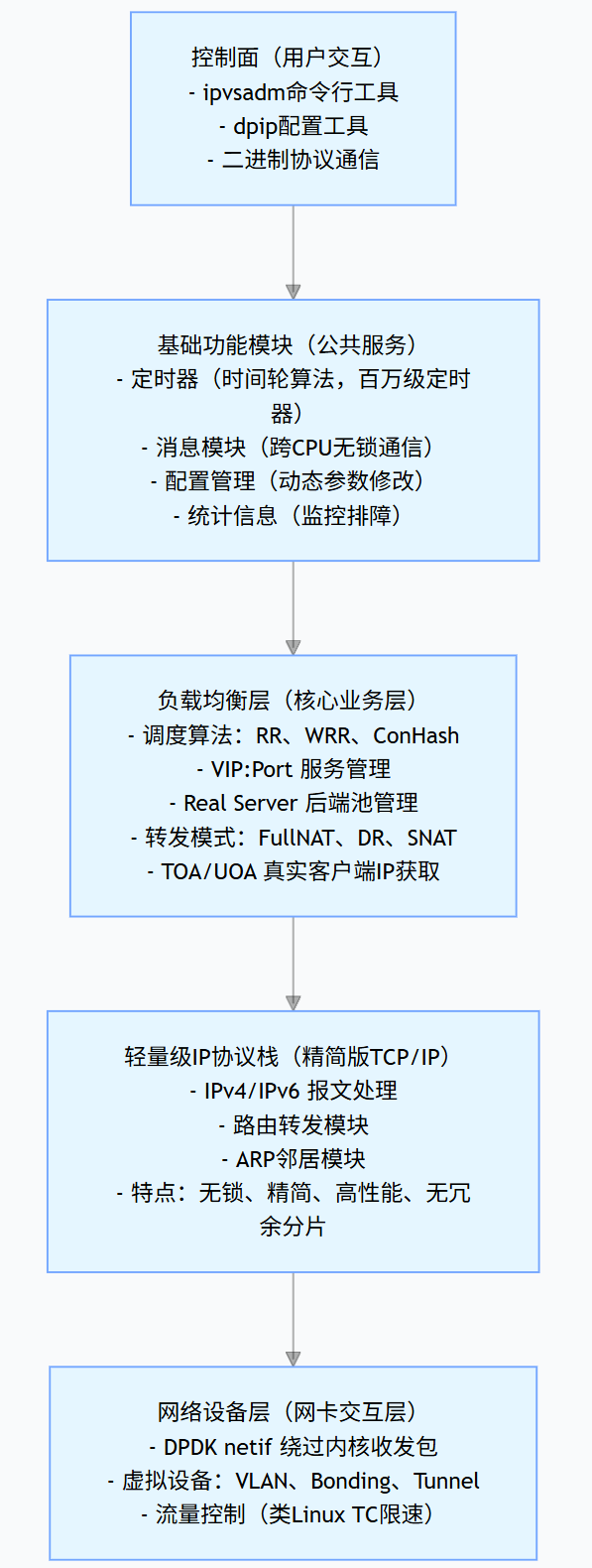
1.3 各层详解
网络设备层:直接与硬件对话
这是 DPVS 的底层,负责与物理网卡直接交互,完全绕过 Linux 内核。
DPDK 收发包机制:
传统内核收包:
网卡 → DMA到内核缓冲区 → 中断CPU → 复制到sk_buff → 协议栈处理 → 复制到用户空间
DPDK收包:
网卡 → DMA到用户态内存 → 轮询模式读取 → 用户态协议栈处理
性能对比:
传统方式:每次收包需要 5-10μs(包含中断、上下文切换)
DPDK方式:每次收包仅需 0.5-1μs(纯内存访问)关键技术点:
- PMD(Poll Mode Driver):驱动模式采用轮询而非中断,避免了中断处理的开销
- Hugepages(大页内存):使用 2MB 或 1GB 的大页,减少 TLB(Translation Lookaside Buffer)缺失
- 零拷贝:数据包直接从网卡 DMA 到用户态内存,无需拷贝
- CPU 亲和性:每个 CPU 核心绑定特定的网卡队列,避免跨核访问
轻量级 IP 协议栈:只保留必要的功能
DPVS 实现了一个精简版的 TCP/IP 协议栈,相比 Linux 内核的完整协议栈,它有以下特点:
设计原则:
完整内核协议栈 vs DPVS轻量级协议栈:
完整内核协议栈:
├─ 支持所有IP协议(TCP、UDP、ICMP、IGMP等)
├─ 支持IP分片和重组
├─ 完整的路由表(支持复杂路由策略)
├─ 完整的邻居发现(ARP、NDP等)
├─ QoS和流量控制
├─ Netfilter防火墙
└─ 复杂的统计和调试功能
DPVS轻量级协议栈:
├─ 只支持IPv4/IPv6(负载均衡必需)
├─ 不支持IP分片(分片重组太消耗CPU)
├─ 简化路由表(只关心下一跳)
├─ 简化邻居发现(只处理ARP)
├─ 内置流量控制(TC模块)
└─ 基础统计信息无锁设计:
DPVS 的 IP 层在初始化完成后,会移除大部分锁。这是基于一个关键洞察:IP 协议本身是无状态的,每个包的处理不依赖于其他包。
传统内核协议栈的锁竞争:
数据包1 ─→ 抢锁 ─→ 处理 ─→ 释放锁
数据包2 ─→ 等待 ─→ 抢锁 ─→ 处理 ─→ 释放锁
数据包3 ─→ 等待 ─→ 等待 ─→ 抢锁 ─→ 处理 ─→ 释放锁
DPVS无锁设计:
CPU核心1 ─→ 数据包1 ─→ 直接处理(无锁)
CPU核心2 ─→ 数据包2 ─→ 直接处理(无锁)
CPU核心3 ─→ 数据包3 ─→ 直接处理(无锁)负载均衡层:核心业务逻辑
这一层是 DPVS 的灵魂,实现了所有四层负载均衡的核心功能。
调度算法支持:
DPVS支持的调度算法:
1. 轮询(RR)
- 简单轮询,依次分发到后端服务器
- 适合后端服务器性能相近的场景
2. 加权轮询(WRR)
- 根据服务器权重分配请求
- 适合后端服务器性能不均的场景
3. 最少连接(LC)
- 分发到当前连接数最少的服务器
- 适合连接时长不均的场景
4. 源地址哈希(SH)
- 根据客户端IP哈希分发
- 保证同一客户端的请求到同一服务器
5. 一致性哈希(ConHash)
- 使用一致性哈希算法
- 适合需要会话保持的场景转发模式:
DPVS 支持多种转发模式,各有优缺点:
转发模式对比:
1. NAT模式
客户端 → LB(修改目的IP) → 后端服务器
优点:配置简单
缺点:LB成为瓶颈(吞吐量受限)
2. DR模式(直接路由)
客户端 → LB(修改MAC) → 后端服务器 → 客户端
优点:性能高,响应不经过LB
缺点:LB和后端必须在同一网段
3. FullNAT模式
客户端 → LB(修改源IP和目的IP) → 后端服务器
优点:支持跨网段部署
缺点:后端无法获取真实客户端IP(需要TOA模块)
4. SNAT模式
客户端 → LB → 后端服务器 → LB(修改源IP) → 客户端
优点:后端服务器无需特殊配置
缺点:LB需要处理双向流量基础功能模块:为上层提供服务
定时器模块:
DPVS 需要支持百万级的连接超时检查,传统的定时器实现无法满足需求。DPVS 借鉴了 Linux 内核的时间轮(Time Wheel)算法。

消息模块:
DPVS 需要在多个 CPU 核心之间传递控制消息,传统的消息队列会引入锁竞争。DPVS 实现了无锁的消息传递机制。
跨核通信机制:
传统方式(锁队列):
CPU1 → 抢锁 → 写入队列 → 释放锁
CPU2 → 等待 → 抢锁 → 读取队列 → 释放锁
锁竞争导致性能下降
DPVS无锁方式:
CPU1 → 写入环形缓冲区(原子操作) → 内存屏障
CPU2 → 读取环形缓冲区(原子操作) → 内存屏障
无锁,利用CPU缓存一致性协议1.4 DPVS vs 传统方案
性能对比:
| 指标 | LVS | Nginx | DPVS |
|---|---|---|---|
| 吞吐量(Mpps) | 8-10 | 2-3 | 10-15 |
| 并发连接数 | 100 万 | 10 万 | 500 万 + |
| 延迟(μs) | 20-50 | 50-100 | 5-10 |
| CPU 利用率 | 高 | 中 | 低 |
| 扩展性 | 一般 | 差 | 优秀 |
适用场景:
DPVS最适合的场景:
✓ 超高并发(百万级连接)
✓ 低延迟要求(μs级响应)
✓ 大流量(10Gbps以上)
✓ 云计算数据中心
✓ CDN边缘节点
传统方案更适合的场景:
✓ 中小规模(10万连接以内)
✓ 七层负载均衡(HTTP/HTTPS)
✓ 需要复杂规则和插件
✓ 运维团队熟悉度高第二部分:Nginx 性能调优三板斧
虽然 DPVS 在四层负载均衡上性能卓越,但在七层负载均衡(HTTP/HTTPS)领域,Nginx 依然是主流选择。通过精细的配置调优,Nginx 也能达到极高的性能。
我们可以把 Nginx 性能调优归纳为 "三板斧":进程与 CPU 的匹配、文件描述符的限制、事件处理的策略。
2.1 第一板斧:进程与 CPU 的匹配(Worker 亲和性)
核心问题:CPU 缓存失效
Nginx 采用多进程模型,如果进程随意在 CPU 核心之间切换,会引发严重的性能问题。
问题分析:
进程漂移导致的缓存失效:
时间线:
T1: 进程A在CPU核心1上运行
- CPU核心1的L1/L2缓存加载了进程A的数据
- 处理效率高
T2: 操作系统调度,进程A迁移到CPU核心2
- CPU核心2的缓存是空的
- 需要从内存重新加载数据
- 处理效率大幅下降
T3: 进程A回到CPU核心1
- 原来的缓存可能已被其他进程覆盖
- 再次需要重新加载数据
问题:每次进程迁移,都会导致缓存失效,性能下降30-50%解决方案:Worker 进程绑定 CPU
配置方法:
# Nginx配置文件
# 设置Worker进程数量(通常等于CPU核心数)
worker_processes 8;
# CPU亲和性绑定
worker_cpu_affinity 00000001 00000010 00000100 00001000
00010000 00100000 01000000 10000000;
# 或者使用自动绑定(Tengine支持)
worker_cpu_affinity auto;二进制码解释:
8核心CPU,8个Worker进程的二进制绑定:
Worker 1: 00000001 → 绑定到核心1(bit0为1)
Worker 2: 00000010 → 绑定到核心2(bit1为1)
Worker 3: 00000100 → 绑定到核心3(bit2为1)
Worker 4: 00001000 → 绑定到核心4(bit3为1)
Worker 5: 00010000 → 绑定到核心5(bit4为1)
Worker 6: 00100000 → 绑定到核心6(bit5为1)
Worker 7: 01000000 → 绑定到核心7(bit6为1)
Worker 8: 10000000 → 绑定到核心8(bit7为1)性能提升:
实测数据(8核心服务器,10000并发连接):
无CPU绑定:
- QPS: 50,000
- CPU利用率: 70%
- 上下文切换: 50,000/秒
有CPU绑定:
- QPS: 70,000(提升40%)
- CPU利用率: 85%(资源利用更充分)
- 上下文切换: 5,000/秒(减少90%)2.2 第二板斧:突破文件描述符限制
核心问题:一切皆文件
在 Linux 系统中,一切皆文件。TCP 连接、Unix Socket、普通文件,都用文件描述符(File Descriptor, FD)来表示。操作系统默认限制一个进程只能打开 1024 个文件,这对高并发服务器来说远远不够。
为什么需要这么多文件描述符:
高并发场景下的文件描述符消耗:
假设需要维持10万个并发连接:
文件描述符分布:
- 10万个客户端连接:100,000个FD
- 日志文件:1个FD
- 配置文件:1个FD
- Unix Socket(master-worker通信):1个FD
- 预留:100个FD
总计:约100,103个FD
如果限制是1024:
1024 < 100,103
→ 无法满足需求解决方案:解除系统限制
系统级配置:
# /etc/security/limits.conf
# 软限制(可以动态调整)
nginx soft nofile 1000000
# 硬限制(需要重启才能调整)
nginx hard nofile 1000000Nginx 配置:
# Nginx配置文件
# 设置Worker进程的最大文件描述符限制
# 这个值必须大于下面的worker_connections
worker_rlimit_nofile 1000000;
events {
# 每个Worker进程的最大连接数
# 计算公式:最大并发数 = worker_processes × worker_connections
# 注意:HTTP反向代理需要占用2个FD(客户端连接+后端连接)
worker_connections 100000;
}计算示例:
服务器配置:
- CPU核心数:8
- worker_processes:8
- worker_connections:100000
- worker_rlimit_nofile:1000000
理论最大并发连接数:
最大连接数 = 8 × 100000 = 800,000
HTTP反向代理场景(需要2个FD):
实际最大连接数 = 800,000 / 2 = 400,000
HTTP服务器场景(需要1个FD):
实际最大连接数 = 800,000 / 1 = 800,000验证配置:
# 检查Nginx进程的文件描述符限制
cat /proc/$(pgrep nginx | head -1)/limits | grep "open files"
# 输出示例:
Max open files 1000000 1000000 files2.3 第三板斧:解决 "惊群效应" 与事件处理
核心问题一:惊群效应(Thundering Herd)
问题场景:
惊群效应流程:
8个Worker进程都在监听80端口,都在epoll_wait等待连接:
状态:所有Worker进程都阻塞在epoll_wait
T1时刻:一个新的连接请求到达80端口
↓
内核唤醒所有8个Worker进程
↓
8个进程都从epoll_wait返回,争抢这个连接
↓
只有1个进程抢到(通过accept_mutex)
↓
其他7个进程发现没抢到,重新回到epoll_wait
问题:
- 7次无意义的唤醒和上下文切换
- CPU资源浪费
- 延迟增加解决方案一:accept_mutex
events {
# 开启accept互斥锁
accept_mutex on;
# 获取锁的超时时间
accept_mutex_delay 500ms;
}工作原理:
accept_mutex机制:
Worker进程启动:
├─ Worker 1: 抢锁 → 成功 → 监听端口
├─ Worker 2: 抢锁 → 失败 → 处理已有连接
├─ Worker 3: 抢锁 → 失败 → 处理已有连接
├─ Worker 4: 抢锁 → 失败 → 处理已有连接
└─ Worker 5-8: 同上
新连接到达:
├─ 只有Worker 1被唤醒
├─ Worker 1处理连接
└─ 其他Worker继续处理已有连接,不受干扰
优势:避免惊群效应
劣势:单点瓶颈,accept_mutex本身有开销解决方案二:关闭 accept_mutex(现代推荐)
events {
# 关闭accept互斥锁
accept_mutex off;
}为什么现代内核可以关闭 accept_mutex?
现代内核优化:
Linux 3.9+:EPOLLEXCLUSIVE
└─ 同一个连接只唤醒一个进程
Linux 4.5+:SO_REUSEPORT
└─ 多个进程独立绑定同一个端口
└─ 内核层面做负载均衡
优势:
- 无锁,性能更好
- 内核自动处理,避免惊群
适用场景:
- 极高并发(10万+)
- 现代内核(4.5+)
- 使用SO_REUSEPORT核心问题二:单次接收效率低
问题场景:
单次accept的低效:
传统方式(multi_accept off):
队列状态:[连接1, 连接2, 连接3, ..., 连接100]
Worker处理:
1. accept() → 获取连接1
2. 处理连接1的请求
3. 响应完成
4. 回到步骤1,获取连接2
问题:
- 每次只取一个连接
- 队列里的其他连接要等待
- 系统调用次数多解决方案:multi_accept
events {
# 一次accept多个连接
multi_accept on;
}工作原理:
multi_accept机制:
队列状态:[连接1, 连接2, 连接3, ..., 连接100]
Worker处理:
1. accept() → 批量获取所有连接(连接1-100)
2. 处理连接1-100的请求
3. 响应完成
4. 回到步骤1,获取新连接
优势:
- 一次系统调用获取多个连接
- 减少系统调用次数
- 提升吞吐量
性能对比:
multi_accept off: QPS = 50,000
multi_accept on: QPS = 70,000(提升40%)2.4 Nginx 完整配置示例
user nginx;
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000
00010000 00100000 01000000 10000000;
worker_rlimit_nofile 1000000;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 100000;
use epoll;
multi_accept on;
accept_mutex off;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
# 连接池优化
open_file_cache max=100000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
# 后端连接池
upstream backend {
server 10.0.0.1:80;
server 10.0.0.2:80;
server 10.0.0.3:80;
keepalive 1000;
keepalive_timeout 60s;
keepalive_requests 10000;
}
server {
listen 80;
listen 443 ssl reuseport; # 使用SO_REUSEPORT
server_name example.com;
ssl_certificate /etc/nginx/ssl/cert.pem;
ssl_certificate_key /etc/nginx/ssl/key.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
location / {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
}第三部分:内核优化 - 从应用层到硬件层
当 Nginx 自身的配置优化到极限后,性能瓶颈往往转移到操作系统内核。本节将从三个层面讲解内核优化:内核参数调优、内核机制优化、网卡硬件卸载。
3.1 第一层面:内核参数调优
对抗 SYN 攻击与高并发连接
问题背景:

解决方案:tcp_syncookies
# /etc/sysctl.conf
# 开启SYN Cookie机制
net.ipv4.tcp_syncookies = 1
# 扩大SYN队列
net.ipv4.tcp_max_syn_backlog = 8192
# 缩短SYN重传次数
net.ipv4.tcp_synack_retries = 2工作原理:
tcp_syncookies机制:
传统方式:
客户端SYN → 服务器分配内存 → 记录状态 → 等待ACK
问题:内存消耗大,易受攻击
SYN Cookie方式:
客户端SYN → 服务器不分配内存 → 计算Cookie → 返回Cookie
└─ Cookie = hash(IP, Port, 时间戳, 密钥)
客户端ACK → 服务器验证Cookie → 建立连接
优势:不占用内存,防攻击解决 TIME_WAIT 问题
问题背景:
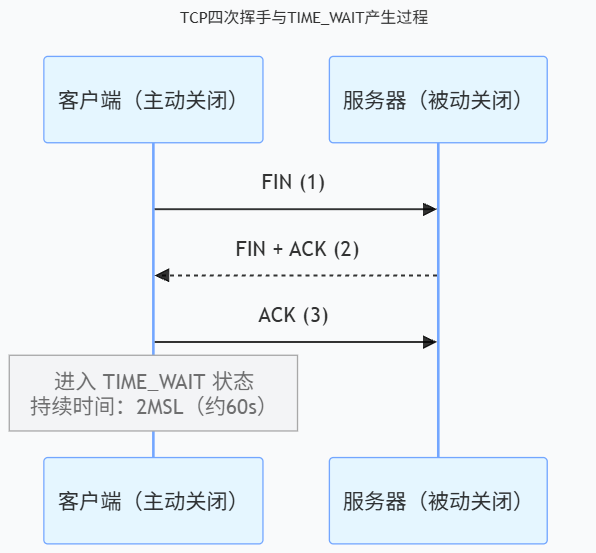
解决方案:
# /etc/sysctl.conf
# 允许复用TIME_WAIT状态的Socket
net.ipv4.tcp_tw_reuse = 1
# 快速回收TIME_WAIT(注意:NAT环境下会导致丢包)
# net.ipv4.tcp_tw_recycle = 1 # 已废弃,不推荐使用
# 缩短TIME_WAIT超时时间
net.ipv4.tcp_fin_timeout = 30tcp_tw_reuse 工作原理:
TIME_WAIT复用机制:
场景:
- 旧连接A:192.168.1.1:12345 → 服务器:80,处于TIME_WAIT
- 新连接B:192.168.1.1:54321 → 服务器:80
传统方式:
- 等待60秒后,192.168.1.1的端口才能复用
tcp_tw_reuse方式:
- 允许复用,但只能用于新连接
- 新连接的四元组(源IP、源端口、目的IP、目的端口)必须不同
- 在TIME_WAIT状态下,只允许发起新的连接,不允许接收新的连接扩大队列与缓冲区
# /etc/sysctl.conf
# 扩大全连接队列
net.core.somaxconn = 65535
# 扩大半连接队列
net.ipv4.tcp_max_syn_backlog = 8192
# TCP读写缓冲区(最小值、默认值、最大值)
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# 扩大TCP连接跟踪表
net.netfilter.nf_conntrack_max = 1000000参数说明:
somaxconn vs backlog:
Nginx配置:
listen 80 backlog=1024;
内核限制:
net.core.somaxconn = 65535;
实际队列大小:min(1024, 65535) = 1024
如果Nginx的backlog大于somaxconn:
实际队列大小 = somaxconn
建议:somaxconn >= Nginx backlog3.2 第二层面:内核机制优化
问题:旧内核的全局锁瓶颈
在 Linux 3.9 之前,Nginx 的多个 Worker 进程监听同一个端口时,存在严重的锁竞争问题。
传统内核的监听队列结构:
监听Socket(全局):
├─ 等待队列
│ ├─ 连接1
│ ├─ 连接2
│ └─ 连接3
├─ 全局锁(spinlock)
└─ 等待队列的Worker进程
新连接到达:
1. 内核获取全局锁
2. 将连接加入等待队列
3. 唤醒所有Worker进程
4. 释放全局锁
Worker进程:
1. 获取全局锁
2. 从队列取连接
3. 释放全局锁
4. 处理连接
问题:
- 全局锁成为瓶颈
- 锁竞争导致性能下降
- 惊群效应解决方案一:SO_REUSEPORT(主流方案)
SO_REUSEPORT 是 Linux 3.9 引入的新特性,允许多个进程绑定同一个端口。
工作原理:
传统方式 vs SO_REUSEPORT:
传统方式(单一监听Socket):
应用层:
├─ Nginx Worker 1 ─┐
├─ Nginx Worker 2 ─┼──→ bind(80) → 失败(端口被占用)
├─ Nginx Worker 3 ─┤
└─ Nginx Worker 4 ─┘
内核:
└─ 一个监听Socket
└─ 一个等待队列
SO_REUSEPORT方式(多个监听Socket):
应用层:
├─ Nginx Worker 1 ─┐
├─ Nginx Worker 2 ─┼──→ bind(80, SO_REUSEPORT) → 成功
├─ Nginx Worker 3 ─┤
└─ Nginx Worker 4 ─┘
内核:
├─ 监听Socket 1 (Worker 1) ─┐
├─ 监听Socket 2 (Worker 2) ─┼──→ 都绑定端口80
├─ 监听Socket 3 (Worker 3) ─┤
└─ 监听Socket 4 (Worker 4) ─┘
└─ 每个Socket有自己的等待队列数据包分发流程:
SO_REUSEPORT的数据包分发:
数据包到达网卡:
└─ 源IP: 源端口 → 目的IP: 目的端口
内核处理:
1. 计算Hash:hash(源IP, 源端口, 目的IP, 目的端口)
2. 选择Socket:hash % Worker数量
3. 唤醒对应的Worker
4. 只唤醒一个Worker(无惊群)
示例:
数据包1: hash1 % 4 = 1 → Worker 2
数据包2: hash2 % 4 = 3 → Worker 4
数据包3: hash3 % 4 = 0 → Worker 1
数据包4: hash4 % 4 = 2 → Worker 3
优势:
- 无锁
- 无惊群
- 内核层负载均衡Nginx 配置:
server {
listen 80 reuseport; # 启用SO_REUSEPORT
listen 443 ssl reuseport;
server_name example.com;
# ...
}性能提升:
实测数据(8核心,10000并发):
传统方式(无SO_REUSEPORT):
- QPS: 50,000
- CPU利用率: 70%
- 上下文切换: 50,000/秒
SO_REUSEPORT方式:
- QPS: 80,000(提升60%)
- CPU利用率: 85%
- 上下文切换: 10,000/秒(减少80%)解决方案二:EPOLLEXCLUSIVE
EPOLLEXCLUSIVE 是 Linux 4.5 引入的 epoll 标志,确保一个事件只唤醒一个进程。
传统epoll vs EPOLLEXCLUSIVE:
传统epoll:
队列状态:[事件1, 事件2, 事件3]
多个epoll_wait:
├─ Worker 1: epoll_wait → 唤醒 → 获取事件1
├─ Worker 2: epoll_wait → 唤醒 → 获取事件2
├─ Worker 3: epoll_wait → 唤醒 → 获取事件3
└─ Worker 4: epoll_wait → 唤醒 → 无事件(浪费)
EPOLLEXCLUSIVE:
队列状态:[事件1, 事件2, 事件3]
多个epoll_wait + EPOLLEXCLUSIVE:
├─ Worker 1: epoll_wait(EPOLLEXCLUSIVE) → 唤醒 → 获取事件1
├─ Worker 2: epoll_wait(EPOLLEXCLUSIVE) → 不唤醒
├─ Worker 3: epoll_wait(EPOLLEXCLUSIVE) → 不唤醒
└─ Worker 4: epoll_wait(EPOLLEXCLUSIVE) → 不唤醒
优势:
- 减少无意义的唤醒
- 降低CPU开销3.3 第三层面:网卡硬件卸载
核心思想:让网卡干活,CPU 休息
现代网卡提供了丰富的硬件卸载功能,可以将部分网络处理工作从 CPU 转移到网卡硬件上。
校验和卸载
传统方式:
校验和计算的传统流程:
数据包:[头部][数据]
CPU处理:
1. 计算头部校验和
2. 计算数据校验和
3. 将校验和写入包头
CPU消耗:每次计算校验和需要数十个CPU周期硬件卸载方式:
校验和卸载流程:
数据包:[头部][数据]
网卡处理:
1. 硬件计算校验和
2. 将校验和写入包头
CPU消耗:0(完全由网卡硬件完成)
配置:
# 开启TX校验和卸载
ethtool -K eth0 tx on
# 开启RX校验和卸载
ethtool -K eth0 rx on分片与聚合卸载
TSO(TCP Segmentation Offload):
TSO发送流程:
应用层发送:
10KB的TCP数据
传统方式(CPU分片):
10KB数据 → CPU分片 → 7个1500字节的包
├─ 包1:1500字节 + TCP头 + IP头
├─ 包2:1500字节 + TCP头 + IP头
├─ 包3:1500字节 + TCP头 + IP头
├─ ...
└─ 包7:1000字节 + TCP头 + IP头
CPU消耗:7次内存拷贝,7次计算校验和
TSO方式(网卡分片):
10KB数据 → 直接给网卡
网卡自动分片 → 7个1500字节的包
CPU消耗:1次内存拷贝,网卡硬件分片
性能提升:CPU节省70%的计算时间GRO/LRO(Large Receive Offload):
GRO接收流程:
网卡接收多个小包:
包1:1500字节
包2:1500字节
包3:1500字节
传统方式(CPU聚合):
3个小包 → 3次中断 → 3次内存拷贝 → CPU聚合
GRO方式(网卡聚合):
3个小包 → 网卡聚合 → 1个4500字节的大包 → 1次中断 → 1次内存拷贝
性能提升:
- 中断减少:67%
- 内存拷贝减少:67%
- CPU利用率降低:50%配置:
# 开启TSO
ethtool -K eth0 tso on
# 开启GRO
ethtool -K eth0 gro on
# 开启LRO(某些网卡支持)
ethtool -K eth0 lro onRSS(Receive Side Scaling)
RSS 是网卡硬件级别的负载均衡,根据数据包的五元组哈希,将数据包分发到不同的接收队列。
RSS工作原理:
数据包:[源IP][源端口][目的IP][目的端口][协议]
网卡硬件处理:
1. 计算Hash:hash(五元组)
2. 选择队列:hash % 队列数
3. 将数据包放入对应队列
4. 触发对应CPU中断
示例:
队列配置:8个队列
数据包1: hash1 % 8 = 0 → 队列0 → CPU核心0
数据包2: hash2 % 8 = 3 → 队列3 → CPU核心3
数据包3: hash3 % 8 = 5 → 队列5 → CPU核心5
优势:
- 多核并行处理
- 无锁竞争
- 硬件级负载均衡
配置:
# 设置RSS队列数
ethtool -L eth0 combined 8
# 配置RSS哈希算法
ethtool -X eth0 hkey <hash_key>与 SO_REUSEPORT 配合:
完美配合:
硬件层(RSS):
网卡 → 队列0/1/2/3/4/5/6/7
内核层(SO_REUSEPORT):
Nginx Worker 1绑定CPU 0 → 监听队列0
Nginx Worker 2绑定CPU 1 → 监听队列1
Nginx Worker 3绑定CPU 2 → 监听队列2
...
Nginx Worker 8绑定CPU 7 → 监听队列7
数据流向:
数据包 → 网卡RSS → 队列3 → CPU核心3 → Nginx Worker 4
结果:
- 数据包直达对应Worker
- 无跨核通信
- 无锁竞争
- 性能最优3.4 完整优化配置
# /etc/sysctl.conf
# SYN防护
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_synack_retries = 2
# TIME_WAIT优化
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
# 队列优化
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 8192
# 缓冲区优化
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# 连接跟踪
net.netfilter.nf_conntrack_max = 1000000
# 端口范围
net.ipv4.ip_local_port_range = 10000 65000
# 其他优化
net.core.netdev_max_backlog = 5000
net.ipv4.tcp_fastopen = 3
net.ipv4.tcp_congestion_control = bbr
# 网卡优化脚本
#!/bin/bash
# optimize_network.sh
INTERFACE=eth0
# 校验和卸载
ethtool -K $INTERFACE tx on
ethtool -K $INTERFACE rx on
# 分片聚合卸载
ethtool -K $INTERFACE tso on
ethtool -K $INTERFACE gso on
ethtool -K $INTERFACE gro on
# RSS配置
ethtool -L $INTERFACE combined 8
# 中断合并(减少中断频率)
ethtool -C $INTERFACE rx-usecs 100
ethtool -C $INTERFACE tx-usecs 100
echo "Network optimization completed"