【Spring AI 实战】八、完整 RAG 问答实战:检索 + 重排序 + 生成全链路
大家好,我是冰点,今天我们继续聊SpringAI的基本用法和特性
文章目录
- [【Spring AI 实战】八、完整 RAG 问答实战:检索 + 重排序 + 生成全链路](#【Spring AI 实战】八、完整 RAG 问答实战:检索 + 重排序 + 生成全链路)
-
- 一、全链路架构回顾
- 二、项目结构与依赖
-
- [2.1 Maven 依赖](#2.1 Maven 依赖)
- [2.2 项目目录结构](#2.2 项目目录结构)
- 三、配置类:分层配置管理
-
- [3.1 AI 配置(支持多模型)](#3.1 AI 配置(支持多模型))
- [3.2 向量库配置](#3.2 向量库配置)
- [3.3 ReRanker 配置](#3.3 ReRanker 配置)
- [四、文档 ETL 服务:批量初始化知识库](#四、文档 ETL 服务:批量初始化知识库)
- [五、Query Enhancement:问题增强层](#五、Query Enhancement:问题增强层)
- [六、核心 RAG 查询服务](#六、核心 RAG 查询服务)
- 七、数据模型
- [八、REST API 控制器](#八、REST API 控制器)
- [九、Postman / cURL 测试](#九、Postman / cURL 测试)
- 十、性能优化与生产注意事项
-
- [10.1 检索阶段优化](#10.1 检索阶段优化)
- [10.2 生成阶段优化](#10.2 生成阶段优化)
- [10.3 生产监控指标](#10.3 生产监控指标)
- 十一、本章小结
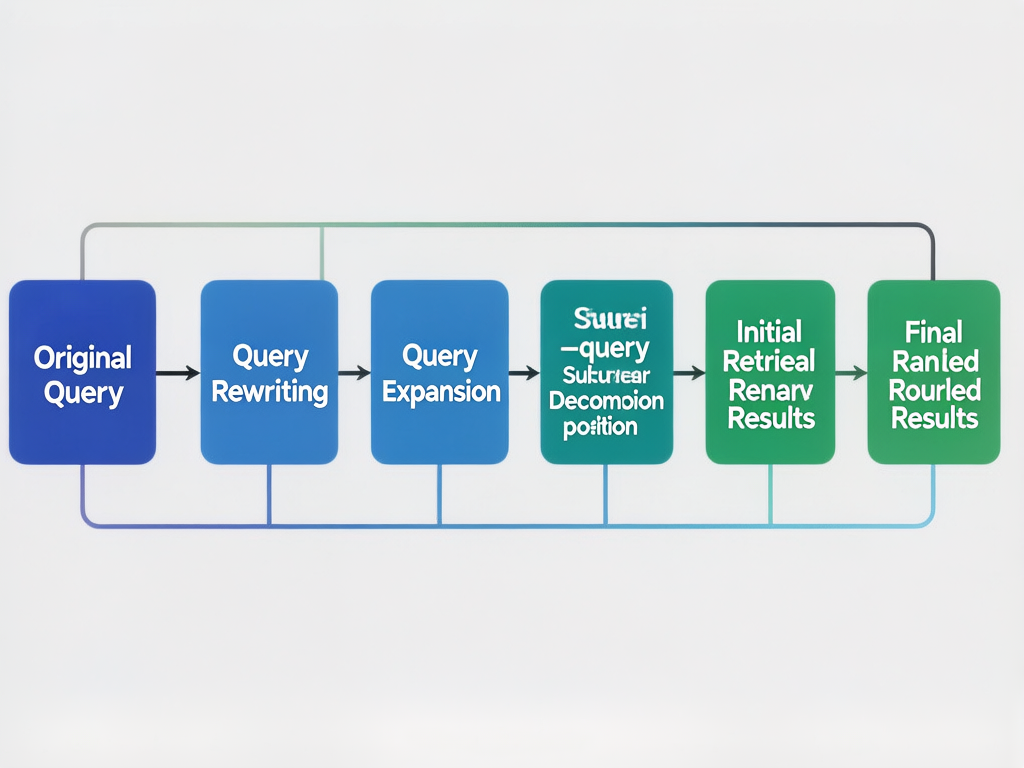
一、全链路架构回顾
┌──────────────────────────────────────────────────────────────┐
│ 用户提问 │
│ "我的订单退款多久到账?" │
└──────────────────────────┬───────────────────────────────────┘
│ ① Query Processing
▼
┌──────────────────────────────────────────────────────────────┐
│ Query Enhancement │
│ Query Expansion(问题扩展)/ HyDE(假设答案)/ Query改写 │
└──────────────────────────┬───────────────────────────────────┘
│ ② Embedding Query
▼
┌──────────────────────────────────────────────────────────────┐
│ Vector Store 检索 │
│ Top-K (K=20) ──→ 粗筛候选文档 │
└──────────────────────────┬───────────────────────────────────┘
│ ③ Reranking
▼
┌──────────────────────────────────────────────────────────────┐
│ ReRanker 重排序 │
│ CrossEncoder ──→ Top-K (K=5) ──→ 精筛相关文档 │
└──────────────────────────┬───────────────────────────────────┘
│ ④ Context Assembly
▼
┌──────────────────────────────────────────────────────────────┐
│ Prompt 组装 + LLM 生成 │
│ 系统提示词 + 检索上下文 + 用户问题 ──→ AI 回答 │
└──────────────────────────────────────────────────────────────┘本文将完整实现以上 5 个环节。
二、项目结构与依赖
2.1 Maven 依赖
xml
<!-- Spring Boot -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</parent>
<!-- Spring AI -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pinecone-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-readers-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-cohere-reranker-spring-boot-starter</artifactId>
</dependency>
<!-- 文档解析 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.1</version>
</dependency>2.2 项目目录结构
src/main/java/com/example/springsai/
├── config/
│ ├── AiConfig.java # AI 模型配置
│ ├── VectorStoreConfig.java # 向量库配置
│ └── RerankerConfig.java # 重排序模型配置
├── service/
│ ├── DocumentETLService.java # 文档 ETL 服务
│ ├── RAGQueryService.java # RAG 核心查询服务
│ └── RerankerService.java # 重排序服务
├── controller/
│ └── RagController.java # REST API 控制器
└── model/
├── RAGRequest.java # 请求模型
└── RAGResponse.java # 响应模型
src/main/resources/
├── application.yml # 配置文件
└── docs/ # 待处理的文档目录
├── policy.pdf
├── faq.md
└── manual.docx三、配置类:分层配置管理
3.1 AI 配置(支持多模型)
java
@Configuration
public class AiConfig {
@Value("${spring.ai.openai.api-key}")
private String openAiKey;
// 主模型:GPT-4o(用于生成)
@Bean
public ChatModel chatModel() {
return OpenAiChatModel.builder()
.apiKey(openAiKey)
.defaultOptions(
OpenAiChatOptions.builder()
.model("gpt-4o")
.temperature(0.3) // RAG 场景建议低温度,保证准确性
.maxTokens(1024)
.build()
)
.build();
}
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.create(chatModel);
}
// Embedding 模型
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(openAiKey)
.withDefaultOptions(
OpenAiEmbeddingOptions.builder()
.model("text-embedding-3-small")
.dimensions(1536)
.build()
)
.build();
}
}3.2 向量库配置
java
@Configuration
public class VectorStoreConfig {
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return PineconeVectorStore.builder(embeddingModel)
.apiKey(System.getenv("PINECONE_API_KEY"))
.environment(System.getenv("PINECONE_ENV"))
.projectId(System.getenv("PINECONE_PROJECT_ID"))
.indexName("production-rag")
.build();
}
}3.3 ReRanker 配置
Cohere 是目前最好的重排序模型(CrossEncoder),效果远超纯向量检索:
java
@Configuration
public class RerankerConfig {
@Value("${spring.ai.cohere.api-key}")
private String cohereKey;
@Bean
public RerankingModel rerankingModel() {
return new CohereRerankingModel(cohereKey);
}
}四、文档 ETL 服务:批量初始化知识库
java
@Service
@Slf4j
public class DocumentETLService {
private final VectorStore vectorStore;
private final RecursiveCharacterTextSplitter splitter =
new RecursiveCharacterTextSplitter(600, 120);
/**
* 从 docs 目录批量加载所有支持的文档格式
* 典型场景:系统启动时一次性构建索引,或定时增量更新
*/
@PostConstruct
public void initializeKnowledgeBase() {
log.info("开始 ETL 文档处理...");
List<DocumentReader> readers = List.of(
// PDF 文档
new PdfReader(
PathUtils.getResourceFile("classpath:/docs/policy.pdf")
),
// Markdown 文档
new MarkdownReader(
PathUtils.getResourceFile("classpath:/docs/faq.md")
),
// Word 文档
new WordDocumentReader(
PathUtils.getResourceFile("classpath:/docs/manual.docx")
)
);
List<Document> allDocs = new ArrayList<>();
for (DocumentReader reader : readers) {
try {
allDocs.addAll(reader.read());
} catch (Exception e) {
log.warn("读取文档失败: {}", e.getMessage());
}
}
log.info("原始文档加载完成,共 {} 篇", allDocs.size());
// 语义分割
List<Document> chunks = splitter.split(allDocs);
log.info("文本分割完成,共生成 {} 个 Chunk", chunks.size());
// 为每个 Chunk 注入元数据
for (Document chunk : chunks) {
chunk.getMetadata().put("indexed_at", LocalDateTime.now().toString());
chunk.getMetadata().put("tenant_id", "default"); // 多租户支持
}
// 存入向量库(包含自动 Embedding)
vectorStore.add(chunks);
log.info("向量库索引构建完成,共索引 {} 个 Chunk", chunks.size());
}
/**
* 增量更新:新增单篇文档
*/
public void addDocument(Path filePath, String category) {
DocumentReader reader = createReaderForFile(filePath);
List<Document> docs = reader.read();
List<Document> chunks = splitter.split(docs);
for (Document chunk : chunks) {
chunk.getMetadata().put("category", category);
}
vectorStore.add(chunks);
}
private DocumentReader createReaderForFile(Path path) {
String filename = path.getFileName().toString().toLowerCase();
if (filename.endsWith(".pdf")) {
return new PdfReader(path.toUri().toString());
} else if (filename.endsWith(".md")) {
return new MarkdownReader(path);
} else if (filename.endsWith(".docx")) {
return new WordDocumentReader(path);
} else {
return new TxtReader(path);
}
}
}五、Query Enhancement:问题增强层
这是提升 RAG 质量的关键技巧------在检索之前先优化用户问题:
java
@Service
@Slf4j
public class QueryEnhancementService {
private final ChatClient chatClient;
/**
* HyDE(Hypothetical Document Embeddings):
* 让 LLM 先根据问题生成一个"假设的最佳答案文档",
* 再对这个假设文档做 Embedding 和检索
* 原理:假设答案通常比原始问题更接近知识库中的真实文档表达方式
*/
public String generateHypotheticalAnswer(String userQuery) {
return chatClient.prompt()
.system("""
你是一个专业的知识库文档撰写者。
根据用户的问题,写一段最可能出现在知识库中的标准答案。
直接输出答案内容,不需要任何前缀说明。
""")
.user(userQuery)
.call()
.content();
}
/**
* Query Expansion:问题多角度扩展
* 将一个问题扩展为多个相似问题,分别检索后再合并
*/
public List<String> expandQuery(String userQuery) {
String expanded = chatClient.prompt()
.system("""
针对用户的问题,生成 3 个不同角度的同义问题。
每个问题用换行分隔,直接输出问题,不要编号。
""")
.user(userQuery)
.call()
.content();
List<String> queries = new ArrayList<>();
queries.add(userQuery); // 保留原问题
for (String line : expanded.split("\\n")) {
String trimmed = line.trim();
if (!trimmed.isEmpty() && trimmed.length() > 5) {
queries.add(trimmed);
}
}
return queries;
}
/**
* Query Decomposition:复杂问题拆解
* 将多跳问题拆解为多个单跳子问题
*/
public List<String> decomposeQuery(String complexQuery) {
String decomposed = chatClient.prompt()
.system("""
将复杂问题拆解为 2~3 个可以用单一文档片段回答的简单问题。
每个问题占一行,不要编号。
""")
.user(complexQuery)
.call()
.content();
return Arrays.stream(decomposed.split("\\n"))
.map(String::trim)
.filter(s -> !s.isEmpty() && s.length() > 5)
.collect(Collectors.toList());
}
}六、核心 RAG 查询服务
java
@Service
@Slf4j
public class RAGQueryService {
private final VectorStore vectorStore;
private final RerankingModel rerankingModel;
private final ChatClient chatClient;
private final QueryEnhancementService queryEnhancement;
// 配置参数
private static final int BRUTE_FORCE_K = 20; // 第一阶段粗筛数量
private static final int RERANK_K = 5; // 重排序后精筛数量
private static final double MIN_RELEVANCE_SCORE = 0.5;
/**
* 完整 RAG 查询链路:
* ① Query Enhancement → ② 向量检索 → ③ ReRanker 重排序 → ④ Prompt 组装 → ⑤ LLM 生成
*/
public RAGResponse query(RAGRequest request) {
long startTime = System.currentTimeMillis();
// ========== ① Query Enhancement ==========
String originalQuery = request.getQuestion();
List<String> expandedQueries = queryEnhancement.expandQuery(originalQuery);
log.info("Query 扩展后:{}", expandedQueries);
// ========== ② 向量检索(多查询合并) ==========
List<Document> allCandidates = new ArrayList<>();
Set<String> seenIds = new HashSet<>();
for (String query : expandedQueries) {
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query(query)
.topK(BRUTE_FORCE_K)
.similarityThreshold(0.3) // 初筛放宽阈值
.build()
);
for (Document doc : results) {
if (seenIds.add(doc.getId())) { // 去重
allCandidates.add(doc);
}
}
}
log.info("向量检索候选文档数量:{}", allCandidates.size());
if (allCandidates.isEmpty()) {
return buildFallbackResponse(originalQuery);
}
// ========== ③ ReRanker 重排序 ==========
List<Document> reranked = rerankingModel.rerank(
rerankList(originalQuery, allCandidates),
RerankingOptions.builder()
.topK(RERANK_K)
.build()
);
log.info("重排序后 Top-{} 文档", reranked.size());
// ========== ④ Prompt 组装 ==========
String context = buildContext(reranked);
String answer = generateAnswer(originalQuery, context);
// ========== ⑤ 返回结果 ==========
return RAGResponse.builder()
.question(originalQuery)
.answer(answer)
.sourceDocuments(reranked)
.retrievalMetrics(RetrievalMetrics.builder()
.vectorSearchTime(System.currentTimeMillis() - startTime)
.candidateCount(allCandidates.size())
.finalCount(reranked.size())
.avgRelevanceScore(
reranked.stream()
.mapToDouble(d -> (Double) d.getMetadata().getOrDefault("score", 0.0))
.average()
.orElse(0.0)
)
.build())
.build();
}
/**
* 为 Cohere ReRanker 构造输入格式
*/
private List<cohere.jakarta.Document> rerankList(String query, List<Document> candidates) {
return candidates.stream()
.map(doc -> cohere.jakarta.Document.builder()
.id(doc.getId())
.text(doc.getContent())
.build())
.collect(Collectors.toList());
}
/**
* 构建 Prompt 上下文
*/
private String buildContext(List<Document> documents) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < documents.size(); i++) {
Document doc = documents.get(i);
String source = doc.getMetadata().getOrDefault("source", "未知来源");
sb.append("【文档 ").append(i + 1).append("】来源:").append(source).append("\n");
sb.append(doc.getContent()).append("\n\n");
}
return sb.toString().trim();
}
/**
* LLM 生成回答
*/
private String generateAnswer(String question, String context) {
if (context.isEmpty() || context.equals("无相关内容")) {
return "抱歉,我在知识库中没有找到与您问题相关的信息。";
}
return chatClient.prompt()
.system("""
你是一个专业的客服助手。基于提供的参考资料回答用户问题。
回答规则:
1. 只使用参考资料中的信息,不要编造
2. 如果有多个相关文档,综合各文档信息给出完整答案
3. 引用答案时,用【文档N】格式标注来源
4. 如果参考资料不足以回答问题,明确说明这一点
【参考资料】
""" + context)
.user("【用户问题】\n" + question)
.call()
.content();
}
private RAGResponse buildFallbackResponse(String question) {
return RAGResponse.builder()
.question(question)
.answer("抱歉,知识库中没有找到相关信息。")
.sourceDocuments(List.of())
.retrievalMetrics(RetrievalMetrics.builder()
.vectorSearchTime(0)
.candidateCount(0)
.finalCount(0)
.avgRelevanceScore(0.0)
.build())
.build();
}
}七、数据模型
java
// RAG 请求
public record RAGRequest(
String question,
String userId, // 可选:用于个性化
String category, // 可选:限定知识库类别
boolean useHyDE, // 是否启用 HyDE
boolean useRerank // 是否启用重排序
) {}
// RAG 响应
public record RAGResponse(
String question,
String answer,
List<Document> sourceDocuments,
RetrievalMetrics retrievalMetrics
) {}
// 检索指标(用于可观测性)
public record RetrievalMetrics(
long vectorSearchTime, // 向量检索耗时(ms)
int candidateCount, // 候选文档数
int finalCount, // 最终返回数
double avgRelevanceScore // 平均相关度
) {}八、REST API 控制器
java
@RestController
@RequestMapping("/api/v1/rag")
public class RagController {
private final RAGQueryService ragQueryService;
private final DocumentETLService documentETLService;
public RagController(RAGQueryService ragQueryService,
DocumentETLService documentETLService) {
this.ragQueryService = ragQueryService;
this.documentETLService = documentETLService;
}
/**
* POST /api/v1/rag/query - RAG 问答
*/
@PostMapping("/query")
public ResponseEntity<RAGResponse> query(@RequestBody RAGRequest request) {
if (request.question() == null || request.question().isBlank()) {
return ResponseEntity.badRequest().build();
}
RAGResponse response = ragQueryService.query(request);
return ResponseEntity.ok(response);
}
/**
* POST /api/v1/rag/admin/rebuild - 重建知识库索引
*/
@PostMapping("/admin/rebuild")
public ResponseEntity<String> rebuildIndex() {
// 注意:生产环境需要鉴权
documentETLService.initializeKnowledgeBase();
return ResponseEntity.ok("知识库重建完成");
}
/**
* POST /api/v1/rag/admin/add - 新增文档
*/
@PostMapping("/admin/add")
public ResponseEntity<String> addDocument(
@RequestParam String filePath,
@RequestParam(defaultValue = "general") String category) {
documentETLService.addDocument(Path.of(filePath), category);
return ResponseEntity.ok("文档添加完成");
}
}九、Postman / cURL 测试
bash
# 基础问答
curl -X POST http://localhost:8080/api/v1/rag/query \
-H "Content-Type: application/json" \
-d '{
"question": "我的订单退款多久能到账?",
"useRerank": true,
"useHyDE": false
}'
# 完整响应示例
{
"question": "我的订单退款多久能到账?",
"answer": "根据退货政策,退款将在收到退回商品并确认无损后 3~5 个工作日内原路返回。...",
"sourceDocuments": [
{
"content": "退款政策:...3~5 个工作日...",
"metadata": { "source": "policy.pdf", "page-number": 3 }
}
],
"retrievalMetrics": {
"vectorSearchTime": 45,
"candidateCount": 12,
"finalCount": 5,
"avgRelevanceScore": 0.87
}
}十、性能优化与生产注意事项
10.1 检索阶段优化
| 优化点 | 方案 | 效果 |
|---|---|---|
| 异步检索 | 对多查询扩展并行执行 CompletableFuture |
延迟降低 50%+ |
| 向量缓存 | 对高频 Query 的向量结果做 LRU 缓存 | 减少 Embedding API 调用 |
| Filter 提前 | 在向量检索前先做元数据过滤,减少候选集 | 精度↑ + 速度↑ |
| HNSW ef 参数 | 查询时增大 ef(搜索广度),牺牲速度换精度 | 精度提升明显 |
10.2 生成阶段优化
| 优化点 | 方案 | 效果 |
|---|---|---|
| Prompt 缓存 | 使用 GPT-4o 的 cached tokens 功能 | 成本降低 50%+ |
| 流式输出 | chatClient.stream() + SSE |
首 Token 延迟降低,用户体验好 |
| 上下文压缩 | 对检索结果先做摘要再喂给 LLM | Token 消耗↓ + 精度↑ |
10.3 生产监控指标
java
// 关键指标埋点
public record RAGMetrics(
String queryId,
long queryEnhanceTimeMs,
long vectorSearchTimeMs,
long rerankTimeMs,
long llmGenerateTimeMs,
int candidateCount,
int finalCount,
double avgRelevanceScore,
boolean hitEmpty // 空召回标记(高亮场景)
) {}十一、本章小结
| 环节 | 技术方案 | Spring AI 组件 |
|---|---|---|
| Query Enhancement | HyDE / Query Expansion / Decomposition | ChatClient |
| 向量检索 | Top-K + 相似度阈值 + 元数据过滤 | VectorStore.similaritySearch() |
| ReRanker | Cohere CrossEncoder | CohereRerankingModel |
| Prompt 组装 | 多文档上下文 + 来源标注 | PromptTemplate |
| LLM 生成 | 低温度 + 参考引用格式 | ChatClient |
| 性能优化 | 异步 / 缓存 / 流式 / cached tokens | 手动实现 |
下篇预告:《九、Function Calling:让 AI 操控业务代码》------ 将 LLM 的决策能力与真实业务系统打通,实现 AI 对外部工具的调用。
📌 系列导航
- ← 上一篇:【Spring AI 实战】七、Embedding 向量化与向量数据库选型对比
- → 下一篇:【Spring AI 实战】九、Function Calling:让 AI 操控业务代码
- → 完整目录
📎 示例说明:本文已经接近完整工程结构,适合与后续第十六篇项目实战交叉阅读。