目录
[1. 为什么需要 VFS](#1. 为什么需要 VFS)
[2. 核心数据结构](#2. 核心数据结构)
[3. 数据结构关系](#3. 数据结构关系)
[4. 关键结构说明](#4. 关键结构说明)
[1. 什么是链接](#1. 什么是链接)
[2. 硬链接](#2. 硬链接)
[3. 软链接](#3. 软链接)
[1. 对比分析](#1. 对比分析)
[2. 为什么硬链接禁止指向目录,而软链接可以](#2. 为什么硬链接禁止指向目录,而软链接可以)
[3. 使用场景](#3. 使用场景)
一、文件系统结构总览
在上一篇文章中,我们详细介绍了磁盘的物理组织结构以及 ext2 文件系统的块组布局。而在实际使用中,Linux 系统不仅能够读写 ext4格式的磁盘文件,还可以处理 NFS 网络文件,并将硬件设备(如 /dev/sda)以文件形式进行管理
本文将介绍统一文件操作接口的核心机制 ------VFS(Virtual File System,虚拟文件系统)
1. 为什么需要 VFS
如果 Linux 直接让应用层对接具体的磁盘格式(如 ext2、xfs),那么程序员在编写代码时,必须为每一种文件系统写一套逻辑。这无疑将导致开发效率的灾难性下降(如 read, write, open)
VFS 的本质是一个抽象层。它定义了一套通用的接口规范,无论是底层的 ext4、fat32,还是内存中的 procfs、sysfs,在 VFS 看来,它们都必须实现相同的动作
-
统一接口:用户空间只需调用标准系统调用(POSIX),无需关心底层是机械硬盘、固态硬盘还是远程服务器
-
多态实现:VFS 像是一个中转站,根据文件所在的挂载点,将请求转发给具体的驱动代码
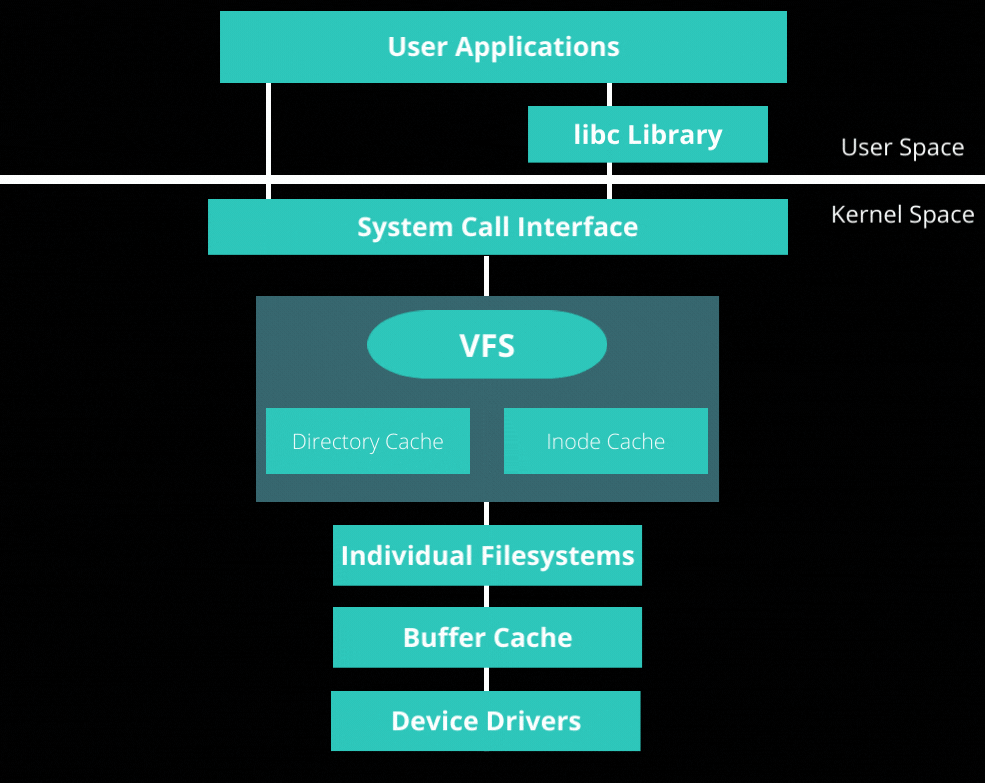
2. 核心数据结构
要理解文件系统在内核中的运行逻辑,必须掌握这几个核心的内核数据结构
这些结构体共同构成了文件系统的骨架:
-
进程相关:task_struct, files_struct, fs_struct
-
文件实体:file, dentry, inode
-
行为抽象:file_operations, inode_operations, dentry_operations

fs_struct 与 files_struct 的本质区别
files_struct 记录的是**"当前持有的文件资源"** ,而 fs_struct 记录的是**"当前所处的工作目录位置"**
| 特性 | fs_struct | files_struct |
|---|---|---|
| 职责 | 环境上下文。记录进程在文件系统树中的位置和默认权限 | 资源句柄。记录进程当前打开了哪些文件(fd 数组) |
| 核心内容 | 根目录、当前工作目录 (pwd) | 文件描述符表、已打开文件的 file 指针 |
| 典型行为 | 执行 cd 时修改此结构 | 执行 open 或 close 操作时修改此结构 |
-
task_struct
fs_struct
-
task_struct
3. 数据结构关系
在 Linux 中,一个进程访问数据的路径可以被串联成一条清晰的逻辑链条。理解了这条链,就理解了Linux 一切皆文件的落地方式
核心主链:
进程 (task_struct) 文件表指针 (files_struct)
文件描述符 (fd)
打开文件实例 (file)
目录项缓存 (dentry)
索引节点 (inode)
磁盘数据 (data)
操作函数挂载:
-
file
-
inode
-
dentry
数据结构(存储状态)+ 操作函数(定义行为)= 文件系统行为
这体现了 Linux 内核极高的面向对象设计思想:结构体是对象,_operations 是对象的方法
4. 关键结构说明
为了在阅读内核源码时更清晰高效,这里对每个结构进行精简定义:
-
task_struct:进程控制块,内核中记录进程信息的核心数据结构
-
files_struct:管理该进程打开的所有文件,包含重要的文件描述符数组(fd_array)
-
fs_struct:记录进程的文件系统根目录(root)和当前工作目录(pwd)
-
file:代表一个已打开的文件。它记录了文件当前的读写偏移量(offset)和打开模式(flags)
-
dentry:目录项。它是文件名与 inode 之间的桥梁,主要用于在内存中加速路径解析
-
inode:文件的唯一物理标识。存储文件的元数据(权限、大小、物理块位置)
-
file_operations:定义了针对已打开文件的操作,如 read, write, mmap
-
inode_operations:定义了针对文件实体的操作,如 mkdir, link, rename
-
dentry_operations:定义了目录项的验证、哈希计算以及回收逻辑
借助这一套严谨的结构体系,Linux 在内存中实现了统一的文件操作抽象。无论底层实际文件系统存在何种差异,上层的 read、write 等标准操作均可保持一致执行
二、软链接与硬链接
在理解了 VFS 的数据结构主链后,我们就能清晰区分 Linux 文件系统中两个容易混淆的概念:硬链接(Hard Link)与软链接(Symbolic Link)
其核心命题在于:如果一个 inode 代表一份唯一的数据,那么操作系统如何支持通过多个不同的路径(文件名)去访问它?
1. 什么是链接
在 VFS 的数据结构中,文件名的存在感其实很低------它只存在于 dentry(目录项)中
链接的宏观定义 :本质上是建立多个不同的 dentry 映射到同一个 inode 的机制。这意味着可以通过不同的路径找到同一个文件,从而实现数据的共享与快速访问
内核在创建链接时的底层行为
当操作系统执行链接操作时,其核心工作并非复制数据,而是在内存和磁盘的元数据区维护以下三个关键逻辑:
A. dentry 的实例化
对于每一个链接,操作系统都会在内存中创建一个新的 dentry 实例
-
d_name 填充:内核将链接的文件名存入新 dentry 的 d_name 字段
-
d_parent 关联:将该 dentry 指向其所在父目录 dentry,从而将其挂载到文件系统的拓扑树中
B. 映射指针的指向
这是链接操作最核心的一步:
-
d_inode 指针赋值:内核将新创建的 dentry 中的 d_inode 指针,指向目标文件的 inode
-
此时,在 VFS 层面,两个不同的 dentry 对象在内存中同时握有了同一个 inode 结构体的句柄
C. 更新引用计数(针对硬链接)
在 inode 中,存在一个关键的成员变量 i_nlink(硬链接计数)
-
原子自增:每当一个新的 dentry 建立指向该 inode 的硬链接时,内核会调用原子操作将 i_nlink 加 1
-
持久化:这个数值会被同步回磁盘的 Inode Table 区域。它决定了该文件是否可以被真正释放
2. 硬链接
本质:多个文件名 -> 同一个 inode
硬链接可看作同一文件的多个引用。为文件创建硬链接时,内核不会在磁盘上复制数据,也不会分配新的 inode,仅在对应目录的数据块中新增一条目录映射项
-
内核特征:
-
inode 共享:硬链接文件与源文件的 inode 编号完全相同
-
引用计数:在 inode 结构体中的 i_nlink 字段。每增加一个硬链接,该计数加 1
-
独立性:删除源文件(实质是删除一个 dentry)只是让 i_nlink 减 1。只要引用计数不为 0,数据块就不会被回收
-
-
局限性 :由于 inode 编号仅在单个文件系统内唯一,硬链接不能跨分区 ,且出于防止目录环路的考量,通常不允许对目录创建硬链接
实践操作:
使用 ln 命令创建硬链接
bash
echo "Hello Linux" > file1
ln file1 file2 # 创建硬链接
ls -i # 查看 inode 编号发现 file1 和 file2 编号完全一致运行结果:

3. 软链接
本质:一个独立的文件,其内容是目标路径的字符串
软链接更像是我们熟悉的快捷方式。它是一个独立的文件实体,拥有自己唯一的 inode 和数据块
-
内核特征:
-
独立 inode:软链接有自己的 inode 编号,文件类型标记为 S_IFLNK
-
内容 :软链接的数据块中存储的是源文件的路径名字符串(可以是相对路径或绝对路径)
-
重定向 :当 VFS 解析路径遇到软链接时,会读取其内容并跳到目标路径重新开始解析
-
依赖性 :如果源文件被删除,软链接的内容(路径字符串)依然存在,但解析时会因为找不到目标而报错,这就是所谓的断链(Broken Link)
-
-
优势 :可以跨分区 创建,也可以对目录创建
实践操作:
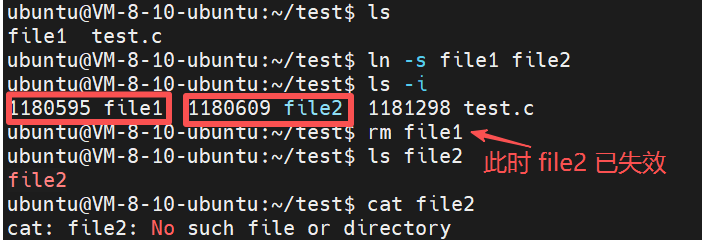
使用 ln -s 命令创建软链接:
bash
ln -s file1 file2 # 创建软链接
ls -i # 查看 inode,file1 和 file2 的编号截然不同
rm file1 # 删除源文件,此时 file2 依然存在但会失效运行结果:
三、软硬链接对比
通过对比分析,我们能够揭示软硬链接在实际工程中的差异,并从内核数据结构的角度出发,深入解答经典面试题:为什么硬链接不允许指向目录?
1. 对比分析
为了清晰展现两者的物理本质差异,我们将从 Inode、存储、跨度及安全性四个维度进行对比:
| 硬链接 | 软链接 | |
|---|---|---|
| Inode 关系 | 共享 Inode。多个 dentry 指向同一个 Inode 编号 | 独立 Inode。拥有全新的 Inode |
| 存储开销 | 极低。仅在父目录的数据块中增加一个目录项条目 | 较低。需要分配一个新的 Inode 及一个数据块存储目标路径字符串 |
| 跨文件系统 | 不支持。Inode 编号仅在单个物理分区内唯一,无法跨越挂载点 | 支持。存储的是路径字符串,可以跨越挂载点进行二次跳转 |
| 源文件删除的影响 | 无影响。只要该 Inode 的 i_nlink 计数大于 0,数据依然存在 | 失效(断链)。软链接内容依然存在,但其指向的路径已不存在 |
| 对目录的支持 | 禁止。为了防止文件系统出现环路 | 支持。内核可以通过跳转限制来控制深度 |
2. 为什么硬链接禁止指向目录,而软链接可以
这是一个涉及文件系统拓扑完整性 与路径解析算法深度的问题。我们必须从 dentry 构成的树状结构以及内核的递归解析机制来剖析
硬链接
文件系统在内核内存中是以 dentry 组成的**有向无环图(DAG)**形式存在的。如果允许对目录创建硬链接,会导致以下问题:
-
无限递归循环 : 假设目录 /a 下有一个硬链接 /a/b 指向 /a 自身。当内核进行路径解析递归遍历目录树时,会陷入 /a/b/a/b/a/b... 的死循环。由于硬链接与源目录在 Inode 层面完全等价,内核无法简单地通过标记已访问来区分它们,这会导致内核栈溢出或系统死锁
-
..指针 : 在磁盘布局中,每个目录数据块都有一个名为..的条目指向父目录的 Inode。如果目录 /a 有两个硬链接,那么 /a 内部的 .. 应该指向谁?这种父节点不唯一性会直接摧毁文件系统的拓扑逻辑,导致文件系统检查工具崩溃
软链接
相比之下,软链接由于其特殊的物理性质,能够规避上述风险:
-
文件类型标识 : 软链接的 Inode 在 i_mode 中明确标记为链接文件(S_IFLNK)。当内核的路径解析器遇到此类节点时,它知道自己正在进行一次逻辑跳转,而不是进入一个真实的子目录
-
跳转深度限制 : 为了防止软链接互相指向形成死循环,Linux 内核在源码中定义了硬性的跳转深度限制(通常为 40 次)
- 底层行为:内核在解析路径时会维护一个计数器。每经过一个软链接,计数器加 1。如果超过阈值,内核会直接返回 -ELOOP 错误
-
不改变物理结构 : 软链接不产生真实的物理父子关系,它不影响目录数据块中的
..条目。因此,即使建立了指向目录的软链接,文件系统的物理拓扑依然是一棵整洁的树,这保证了文件系统维护工具的稳定性
硬链接因直接修改目录树的物理引用,会导致目录的
..条目产生歧义并引发引用计数永不归零的资源泄露,从物理层面摧毁了文件系统的树状结构,因此被严厉禁止;而软链接仅是存储路径字符串的独立文件,不改变物理拓扑,内核在解析时能通过 i_mode 识别其逻辑跳转性质,并利用计数器在跳转超限时抛出错误来强制截断死循环,这种设计既允许了跨分区的访问便利,又确保了底层维护工具的绝对稳定
3. 使用场景
硬链接
由于硬链接共享 Inode 且具备引用计数机制,它在处理大批量、高频次的数据备份时具有天然优势
(1) 备份与快照
这是硬链接最著名的应用场景
-
场景:如果你每天都要备份一个 100GB 的数据库,但每天只有 1MB 的内容变动
-
做法 :对于未变动的文件,备份程序并不进行物理复制,而是直接创建一个指向昨天备份文件的硬链接
-
本质:磁盘上只存了一份数据,但今天的备份目录里看起来拥有完整的文件。这在实现秒级快照的同时,极大地节省了磁盘空间
(2) 防止误删
-
场景:核心配置文件或大型日志文件
-
做法:在不同的目录下建立多个硬链接
-
本质:由于 Inode 的 i_nlink 机制,即便某个业务进程误删了其中一个入口,只要还有一个硬链接存在,底层物理数据依然安全
软链接
软链接因其跨分区、指向明确的特性,被广泛用于系统配置的灵活性提升
(1) 版本切换
这是 Linux 发行版管理工具链的标准做法
-
例子:系统中安装了 Python 3.10 和 Python 3.12。
-
做法:创建一个软链接 /usr/bin/python 指向实际的可执行文件 /usr/bin/python3.12
-
优势:当需要升级系统默认版本时,只需修改软链接的指向,而不需要移动庞大的二进制文件或修改成百上千个脚本
(2) 共享库管理
-
场景:Linux 下的动态链接库
-
做法:通常会有一个 libssl.so 的软链接指向具体的版本 libssl.so.1.1
-
本质:程序在编译时只需要找通用名,具体的"版本名"由软链接在运行时动态指向,保证了软件的向前兼容性
(3) 路径简化
-
场景:频繁访问深层目录,如 /var/lib/docker/volumes/my_data/_data
-
做法:在用户家目录下创建一个短链接 ln -s ... ~/docker_data
-
本质:利用软链接的路径重定向功能,提升人工操作的效率
为了方便记忆,我们可以参考下表进行选择:
| 需求 | 方案 | 理由 |
|---|---|---|
| 节省磁盘空间,做文件镜像 | 硬链接 | 共享 Inode,不产生额外数据块 |
| 跨硬盘分区、挂载点引用 | 软链接 | 存储的是路径字符串,不依赖物理 Inode 编号 |
| 给文件夹起别名 | 软链接 | 硬链接严禁指向目录 |
| 软件多版本切换 | 软链接 | 修改指向极快,路径关系清晰 |
| 重要文件防丢 | 硬链接 | 只要引用计数不归零,数据永远存在 |
总结
综上所述,从 VFS 的统一抽象到各类核心数据结构之间的关联,再到软链接与硬链接的实现机制,我们可以看到,文件系统本质上是一套由 "数据结构 + 映射关系 + 操作接口" 构成的完整体系。进程通过文件描述符访问文件,路径通过 dentry 被解析,inode 负责描述文件本身,而底层数据则最终落在磁盘块上,这一系列结构共同构成了从用户路径到物理数据的完整链路
至此,我们已经从磁盘结构出发,逐步走到了文件系统的整体架构层面。进一步思考可以发现,系统之所以能够对文件操作提供统一接口,离不开更高一层的封装------也就是库。在下一系列中,我们将从如何使用库走向如何构建库,深入理解静态库与动态库的实现原理,以及程序在编译、链接与运行过程中的整体结构
