论文信息
- 标题:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
- 会议:IEEE Signal Processing Letters 2016
- 单位:中国科学院深圳先进技术研究院、香港中文大学
- 代码:https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
- 论文:https://kpzhang93.github.io/MTCNN_face_detection_alignment/paper/spl.pdf
前言
在无约束场景里做人脸检测+关键点定位,一直被姿态、光照、遮挡搞得头疼。传统方法要么检测不准,要么对齐拉胯,MTCNN直接用三级联CNN+多任务联合学习,把检测、框回归、关键点定位串在一起,又快又准,直到今天还是工业界落地标配。这篇就带你把MTCNN从头到尾啃透。
一、核心创新点
MTCNN最狠的三个地方:
- 三级联CNN:从粗到细筛选候选框,速度拉满
- 多任务联合学习:检测+框回归+关键点定位一起训,互相涨点
- 在线难例挖掘:训的时候自动抓难样本,不用手动挑
二、整体框架(从粗到细三级过滤)
MTCNN是图像金字塔+三级CNN 的流水线,一步步过滤背景,精修人脸框和关键点。
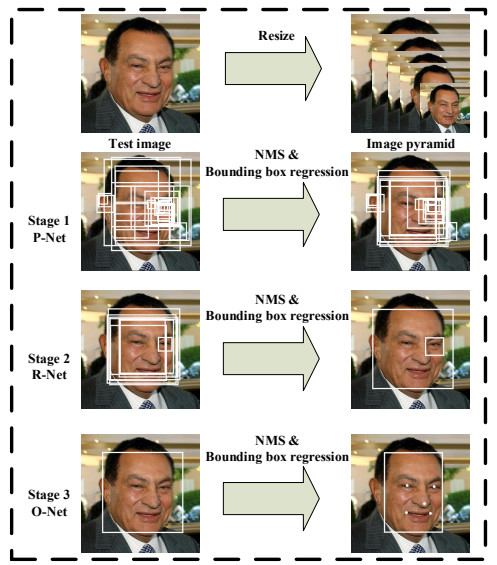
图 1.我们级联框架的流水线包括三个阶段的多任务深度卷积网络。首先,通过快速提案网络(P-Net)生成候选窗口。然后,在下一阶段,通过细化网络(R-Net)对这些候选窗口进行优化。在第三阶段,输出网络(O-Net)生成最终的边界框和面部特征点位置。
分析:先把图像做成多尺度金字塔→P-Net快速产候选框→R-Net剔除大量误检→O-Net精修并输出5点关键点,越往后网络越大、筛选越严。
2.1 三级网络分工
- P-Net(Proposal Network)
- 输入:12×12图像块
- 输出:人脸置信度、框偏移量
- 作用:全卷积快速生成候选框,做NMS初步去重
- R-Net(Refine Network)
- 输入:24×24图像块
- 输出:人脸置信度、框偏移量
- 作用:过滤大量非人脸框,精修框位置
- O-Net(Output Network)
- 输入:48×48图像块
- 输出:人脸置信度、框偏移量、5个面部关键点
- 作用:最终精修,输出检测结果+关键点
三、网络结构设计
MTCNN把5×5卷积换成3×3 ,减少计算、加深网络提升性能,激活用PReLU,比ReLU更软,防止梯度塌陷。
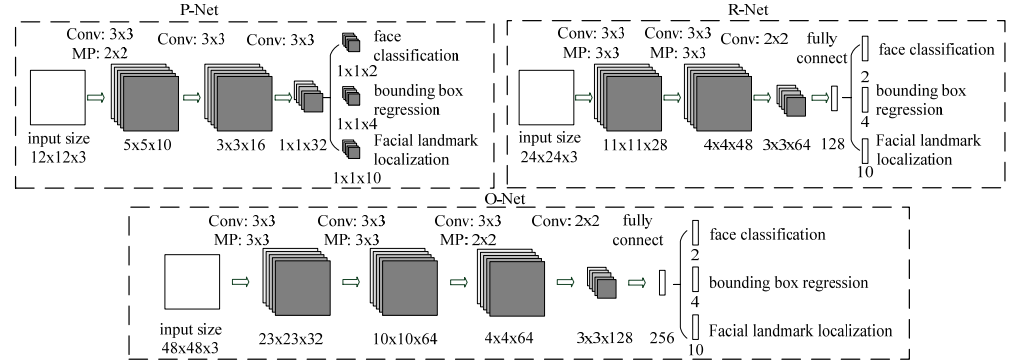
图 2.P-Net、R-Net 和 O-Net 的架构中,"MP"表示最大池化,"Conv"表示卷积。卷积和池化操作中的步长分别为 1 和 2 。
分析:网络越小越靠前,P-Net最轻量最快,O-Net最深最准,三级结构兼顾速度与精度。
四、训练细节:多任务损失+在线难例挖掘
4.1 三大任务损失函数
MTCNN同时训人脸分类、框回归、关键点定位三个任务,加权求和。
(1)人脸分类损失(交叉熵)
Lidet=−(yidetlog(pi)+(1−yidet)(1−log(pi)))L_{i}^{det} = -\left(y_{i}^{det} log(p_{i})+(1-y_{i}^{det})(1-log(p_{i}))\right)Lidet=−(yidetlog(pi)+(1−yidet)(1−log(pi)))
- LidetL_{i}^{det}Lidet:第i个样本的分类损失
- yidety_{i}^{det}yidet:真实标签,人脸=1,背景=0
- pip_{i}pi:网络输出的人脸概率
通俗解释:判断这张图是不是人脸,错了就罚。
(2)框回归损失(欧式损失)
Libox=∥y^ibox−yibox∥22L_{i}^{box} = \left\| \hat{y}{i}^{box}-y{i}^{box} \right\|_{2}^{2}Libox= y^ibox−yibox 22
- y^ibox\hat{y}_{i}^{box}y^ibox:网络预测的框偏移(左上、宽、高)
- yiboxy_{i}^{box}yibox:真实框偏移
通俗解释:把预测框往真实框拉,越准罚得越少。
(3)关键点定位损失(欧式损失)
Lilandmark=∥y^ilandmark−yilandmark∥22L_{i}^{landmark} = \left\| \hat{y}{i}^{landmark}-y{i}^{landmark} \right\|_{2}^{2}Lilandmark= y^ilandmark−yilandmark 22
- y^ilandmark\hat{y}_{i}^{landmark}y^ilandmark:预测的5个关键点坐标(共10维)
- yilandmarky_{i}^{landmark}yilandmark:真实关键点坐标
通俗解释:把左眼、右眼、鼻子、左嘴角、右嘴角定位准。
(4)总损失
min∑i=1N∑j∈{det,box,landmark}αjβijLijmin \sum_{i=1}^{N} \sum_{j \in \{det,box,landmark\}} \alpha_{j}\beta_{i}^{j}L_{i}^{j}mini=1∑Nj∈{det,box,landmark}∑αjβijLij
- αj\alpha_{j}αj:任务权重
- βij\beta_{i}^{j}βij:样本掩码,不是该任务样本则为0
权重设置: - P-Net/R-Net:αdet=1,αbox=0.5,αlandmark=0.5\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5αdet=1,αbox=0.5,αlandmark=0.5
- O-Net:αdet=1,αbox=0.5,αlandmark=1\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=1αdet=1,αbox=0.5,αlandmark=1(关键点更重)
4.2 在线难例挖掘
每批训练里:
- 前向传播算出所有样本的损失
- 取**损失最高的70%**作为难样本
- 只回传这些样本的梯度
通俗解释:自动盯着"难认的脸/背景"学,简单样本直接跳过,又快又准。
4.3 训练数据划分(IoU标准)
- 负样本:IoU<0.3
- 正样本:IoU>0.65
- 部分人脸:0.4≤IoU≤0.65
- 关键点人脸:带5点标注
比例:负:正:部分人脸:关键点 = 3:1:1:2
五、实验结果与分析
5.1 在线难例挖掘效果
表格1 网络速度与验证精度
| 分组 | 网络 | 300次前向时间 | 验证精度 |
|---|---|---|---|
| Group1 | 12-Net19 | 0.038s | 94.4% |
| P-Net | 0.031s | 94.6% | |
| Group2 | 24-Net19 | 0.738s | 95.1% |
| R-Net | 0.458s | 95.4% | |
| Group3 | 48-Net19 | 3.577s | 93.2% |
| O-Net | 1.347s | 95.4% |
表格1 出处 :MTCNN原文
分析:MTCNN的网络比传统CNN更快、精度更高,轻量化设计见效。
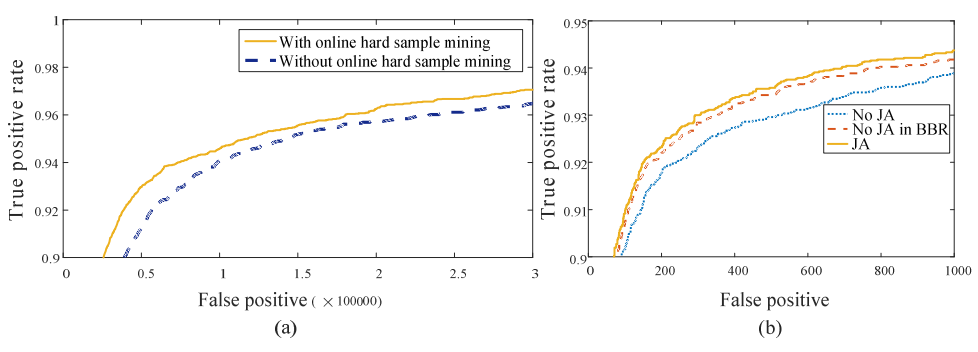
图 3. (a)P-Net 在有和无在线硬样本挖掘情况下的检测性能。 (b)"JA"表示 O-Net 中的联合人脸对齐学习,而"No JA"表示不进行联合处理。"No JA in BBR"表示使用"No JA"型的 O-Net 进行边界框回归。
分析:
- 在线难例挖掘:FDDB上涨约1.5%
- 联合关键点学习:同时提升检测和框回归
5.2 人脸检测 benchmark
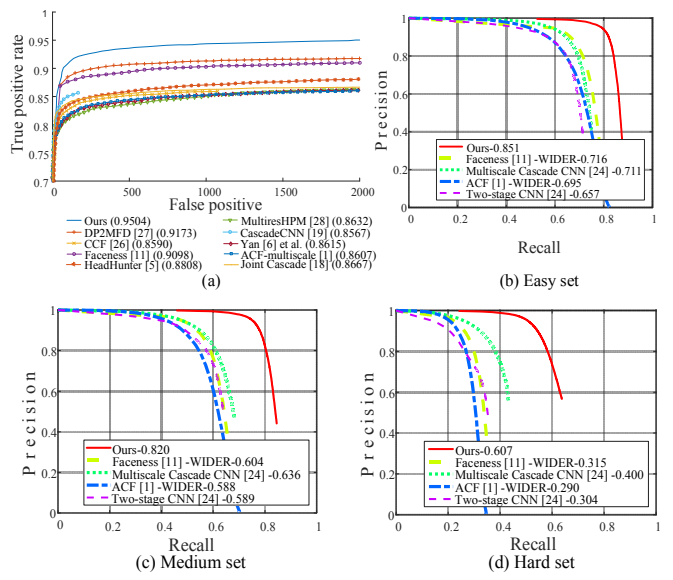
图 4.(a)对 FDDB 的评估。 (b - d)对 WIDER FACE 的三个子集的评估。在该方法名称之后的数字表示平均准确率。
分析:在FDDB、WIDER FACE的Easy/Medium/Hard子集,MTCNN全面碾压Faceness、ACF、Cascade CNN等SOTA。
5.3 人脸对齐效果
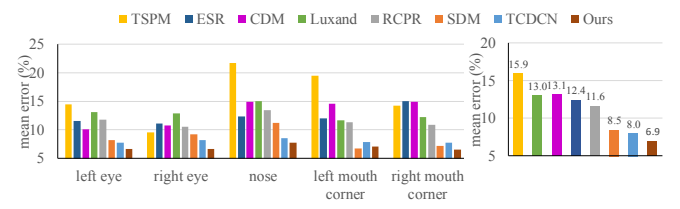
图 5. 对 AFLW 数据集进行的人脸对齐评估
分析:平均误差低于ESR、SDM、TCDCN等方法,5点定位精度顶尖。
5.4 运行速度
表格2 速度对比
| 方法 | GPU | 速度 |
|---|---|---|
| MTCNN | Nvidia Titan Black | 99 FPS |
| Cascade CNN19 | Nvidia Titan Black | 100 FPS |
| Faceness11 | Nvidia Titan Black | 20 FPS |
| DP2MFD27 | Nvidia Tesla K20 | 0.285 FPS |
表格2 出处 :MTCNN原文
分析:MTCNN接近100帧,实时性拉满,适合端侧部署。
六、核心代码实现(PyTorch简化版)
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# P-Net 结构
class PNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 10, 3, 1)
self.prelu1 = nn.PReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(10, 16, 3, 1)
self.prelu2 = nn.PReLU()
self.conv3 = nn.Conv2d(16, 32, 3, 1)
self.prelu3 = nn.PReLU()
# 输出:人脸分类、框回归、关键点
self.conv4_1 = nn.Conv2d(32, 1, 1) # 人脸置信度
self.conv4_2 = nn.Conv2d(32, 4, 1) # 框偏移
self.conv4_3 = nn.Conv2d(32, 10, 1) # 5点坐标
def forward(self, x):
x = self.pool1(self.prelu1(self.conv1(x)))
x = self.prelu2(self.conv2(x))
x = self.prelu3(self.conv3(x))
cls = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
return cls, box, landmark
# 在线难例挖掘:取loss前70%
def online_hard_mining(loss, ratio=0.7):
num_hard = int(loss.size(0) * ratio)
loss_sorted, _ = torch.sort(loss, descending=True)
threshold = loss_sorted[num_hard]
mask = loss >= threshold
return mask
# IoU计算
def iou(box1, box2):
x1 = torch.max(box1[:,0], box2[:,0])
y1 = torch.max(box1[:,1], box2[:,1])
x2 = torch.min(box1[:,0]+box1[:,2], box2[:,0]+box2[:,2])
y2 = torch.min(box1[:,1]+box1[:,3], box2[:,1]+box2[:,3])
inter = torch.clamp(x2-x1, 0) * torch.clamp(y2-y1, 0)
union = box1[:,2]*box1[:,3] + box2[:,2]*box2[:,3] - inter
return inter / union七、全文总结
- 三级级联CNN:从粗到细过滤,速度与精度平衡
- 多任务联合学习:检测+框回归+关键点定位一起训,互相增益
- 在线难例挖掘:自动提升模型判别力,不用人工处理数据
- 性能拉满:FDDB/WIDER FACE检测SOTA,AFLW对齐SOTA,近百帧实时
- 工业标配:至今仍是人脸门禁、美颜、抓拍等场景的首选算法