同步至个人站点:为什么我不建议初学者一上来就用框架学 Agent
前两天回校,和想做 Agent 的学弟聊了聊。我发现一个很普遍的现象:很多人一开始接触 Agent,第一反应不是先去理解 Agent 的机制,而是先找 LangChain 这类框架把东西跑起来。
我当时就表达了一个很明确的观点:我不建议初学者一上来就用框架学 Agent。
不是因为这些框架不好。恰恰相反,正是因为它们太成熟了,才更容易让初学者产生一种错觉:好像 Agent 开发就是在配配置、搭积木。
但我一直觉得,学习阶段最重要的,不是先把框架跑通,而是先弄明白这套系统到底是怎么转起来的。
一、框架隐藏了最关键的工程问题
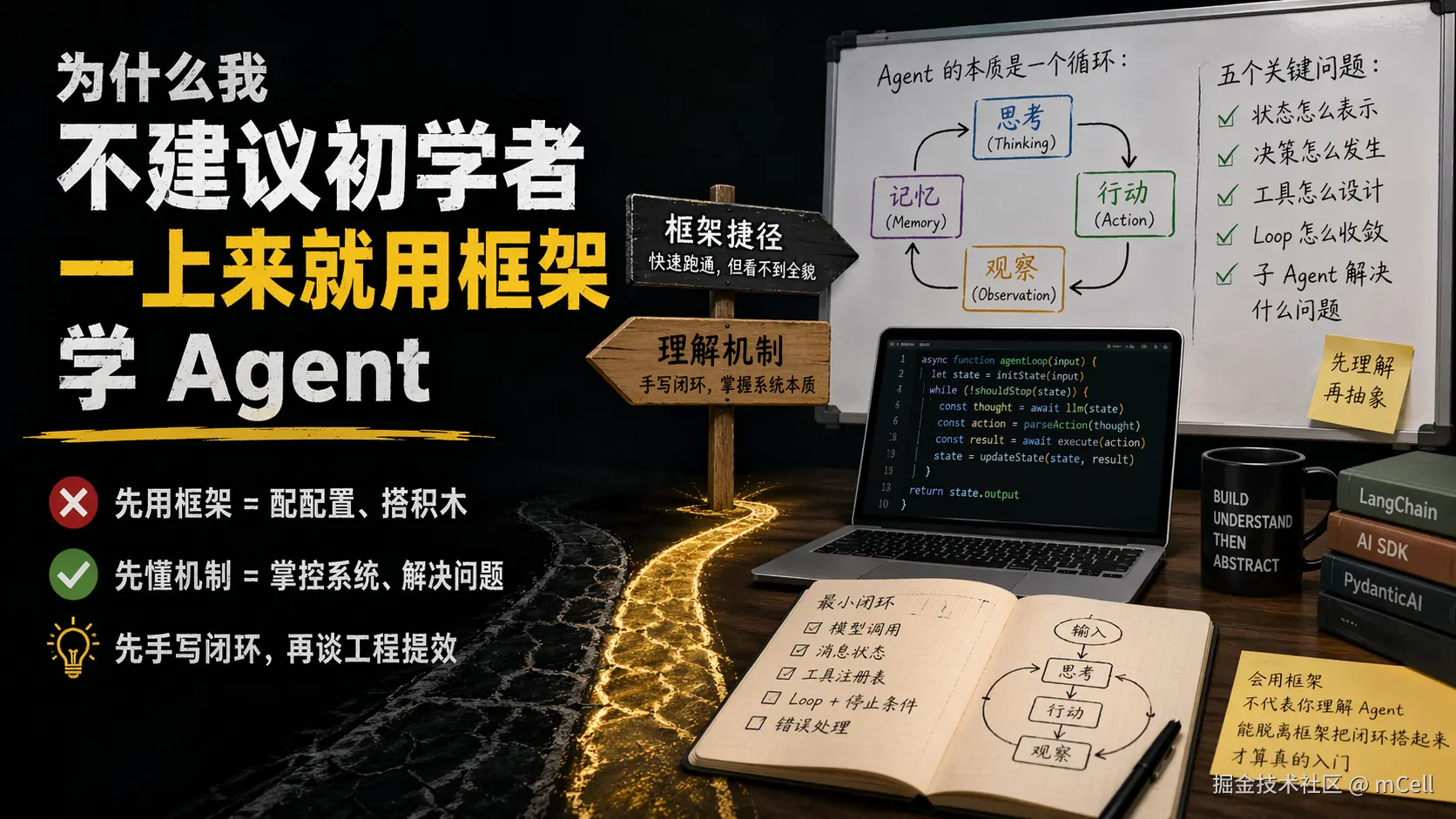
一个最基础的 Agent,背后至少有五个绕不过去的问题。框架会帮你把它们包装起来,但对于学习者来说,真正重要的恰恰是你得亲手把这些问题碰一遍。
1. 状态怎么表示
历史消息怎么存?上下文怎么裁剪?工具调用的结果要不要回写到历史里?
很多人知道框架里有 memory,但并不知道 memory 到底在解决什么问题。
2. 决策怎么发生
模型什么时候该直接回答,什么时候该调用工具?调用失败后是重试、降级还是中断?整个 loop 什么时候停止?
这些东西决定的,其实就是 Agent 的"脑子"到底怎么运转。
3. 工具怎么设计
这是很多人最容易忽略的地方。关键从来不是"工具怎么注册",而是工具为什么要这样设计。
比如一个查询能力,到底是给模型一个大而全的 search,还是拆成 search_user、search_order、search_ticket 这种更窄的工具?
这不是编码风格问题,而是模型调用稳定性问题。拆得太粗,模型容易乱用;拆得太细,系统复杂度又会上来。Schema 怎么定义、描述怎么写、返回值要不要结构化,这些都会直接影响调用效果。
4. loop 怎么收敛
Agent 不是写个 while True 就结束了。
最大步数是多少,什么情况该停止,什么情况说明模型已经跑偏,哪些地方要有人来兜底,这些都属于系统设计的一部分。
如果这些东西没想清楚,系统很快就会从"自主"滑向"失控"。
5. sub-agent 到底在解决什么问题
多 Agent 不是用来炫技的。
很多时候,一个 sub-agent 真正在解决的是职责隔离、权限隔离、上下文隔离,或者复杂任务拆分的问题。
如果这些问题本身都还没想清楚,就先上多 Agent 编排,最后往往只是系统形式更复杂了,但问题并没有真的被解决。
二、学习路径的错位:抽象先于理解
这件事其实很像前端和后端的学习路径。无论上层框架怎么变,真正决定你上限的,始终还是底层那些基础能力。
现在的 Agent 框架把门槛降得很低。接个模型,配几个工具,Demo 很快就能跑通。
但能跑通,不代表你真的理解了。
因为一旦进入真实业务,问题很快就会变得具体起来:
- 工具调用是不是要做鉴权
- 中间状态是不是要可审计
- 模型决策错了以后怎么兜底
- 某些失败到底该重试还是该中断
这些问题,框架可以给你一个通用外壳,但不可能替你填好具体业务里的东西。
三、我自己的做法,以及我建议的学习顺序
我自己并不是完全不用这些框架。
像 Provider、模型接入、流式输出这些已经很成熟的通用能力,如果现成库已经做得很好,我一般会直接拿来用。因为这些地方重复造轮子意义不大。
但像 tool schema、loop、sub-agent 集成这些更接近系统控制面的东西,我大多数时候还是会自己实现。不是为了炫技,也不是为了手写而手写,而是因为这些地方往往最贴近具体业务,也最容易被默认抽象限制住。
所以我的建议一直很简单:把框架当提效工具,不要把框架当学习教材。
如果你现在还在学习阶段,我更建议按这个顺序来。
第一步:先手写一个最小闭环
先别急着看复杂框架,先自己写一个最小可运行的 Agent:
- 一个模型调用
- 一个消息状态管理
- 一个工具注册表
- 一个带停止条件的 tool-calling loop
- 一套简单的错误处理
这一阶段不求优雅,只求你能亲眼看到,一个 Agent 到底是怎么从输入任务走到决策、行动、观察、再决策的。
第二步:再逐步补能力
在这个最小闭环上,继续往上加:
- memory
- structured output
- logging / tracing
- planner / router
- sub-agent
- human-in-the-loop
等你把这些东西自己搭过一遍,再回头去看 LangChain、AI SDK、PydanticAI 这些框架,你就不会再把它们当成黑箱,而会更清楚:它到底帮你省了哪段路,又在哪些地方限制了你。
(完)