大家好,这篇文章带来的是有关redis的数据类型和底层实际编码的有关介绍,希望能有所收获!
Redis常见数据结构,编码方式
Redis 提供了5种数据结构,理解每种数据结构的特点对于Redis开发运维非常重要,同时掌握每种数据结构的常见命令,会在使用Redis的时候做到游刃有余。
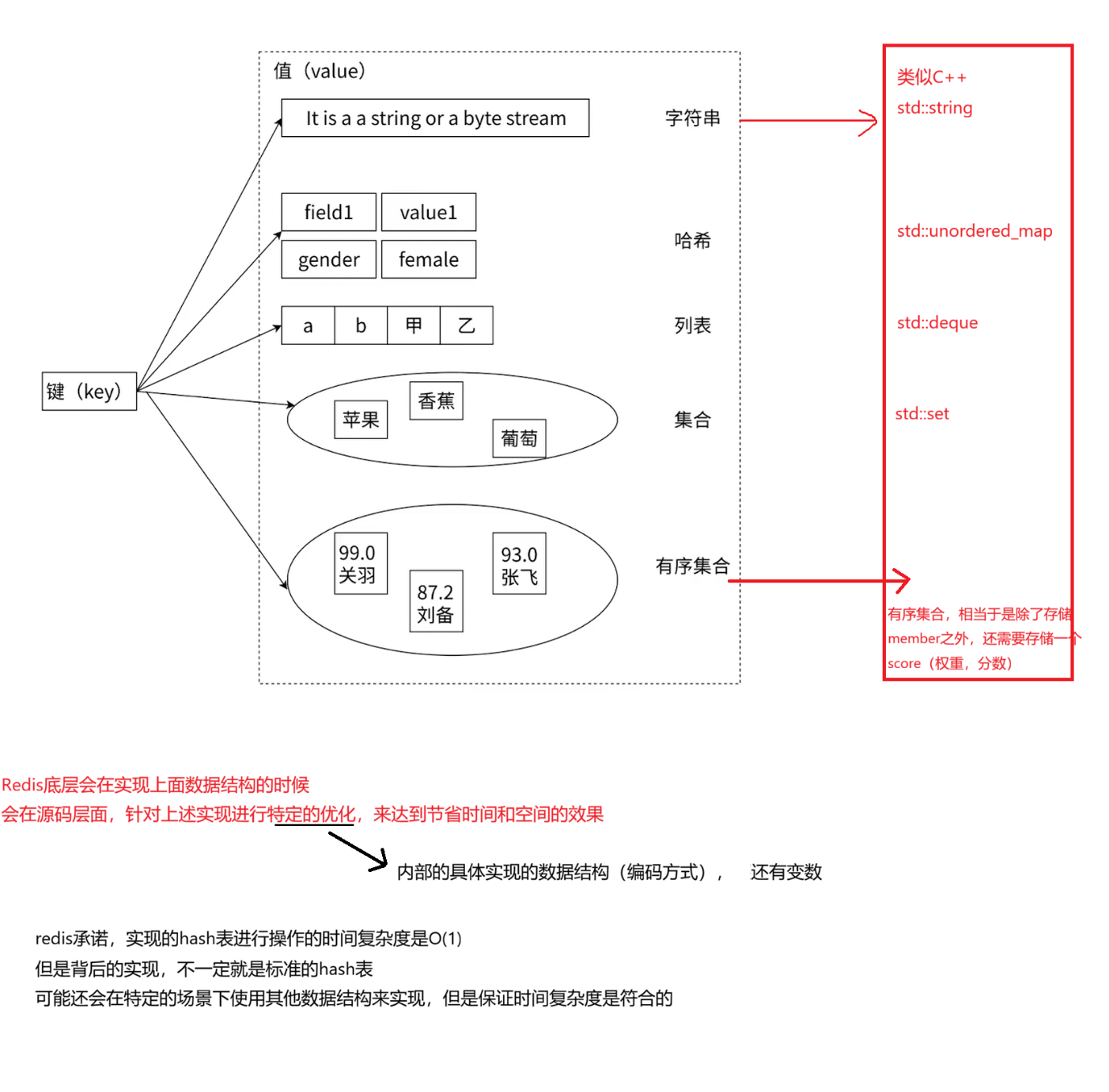
数据结构:redis承诺给我们的,也可以理解成数据类型
编码方式:redis内部底层的实现
同一个数据类型,背后可能的编码实现方式是不同的,会根据特定场景优化
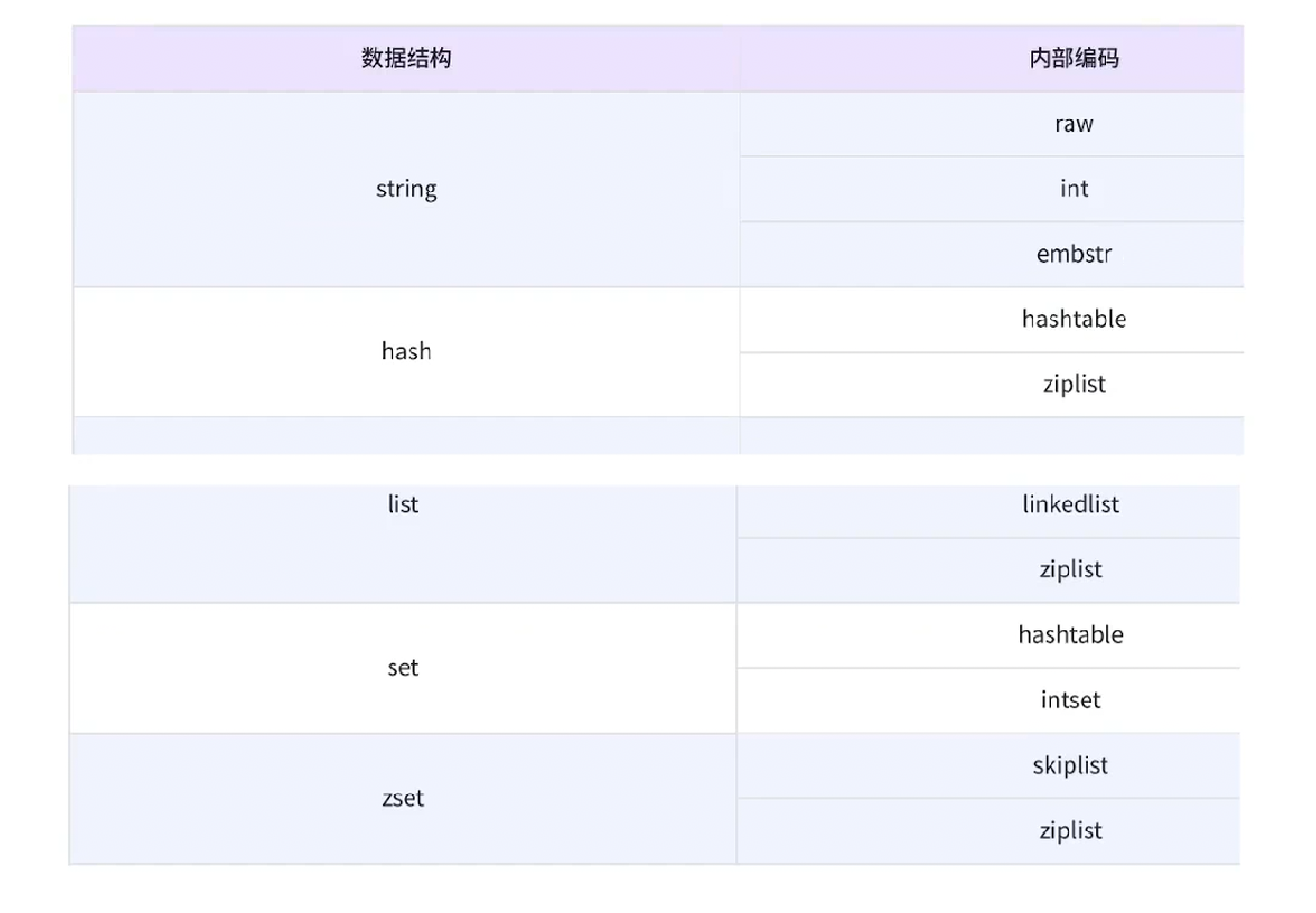
**1. raw:**最基本的字符串类型,底层本质是持有一个 char 数组。
**2. int:**Redis 常被用于实现计数类功能,当 value 为整数时,Redis 会直接以 int 类型存储(无需转成字符串),提升效率且节省空间。
**3. embstr:**针对短字符串设计的特殊优化结构,内存布局更紧凑,避免内存碎片,提升访问效率。
**4. hashtable:**Redis 内部最基础的哈希表实现,是哈希类型的默认存储结构(虽与通用哈希表实现细节略有差异,但核心思想一致)。
**5. ziplist(压缩列表):**当哈希、列表等结构的元素数量少、元素体积小时,Redis 会用 ziplist 替代原有结构(如 hashtable、linkedlist),大幅节省内存空间。
**6. linkedlist:**普通双向链表,是 Redis 早期列表类型的底层实现,便于插入、删除操作,但内存开销较大。
**7. quicklist:**从 Redis 3.2 版本开始引入,整合了 linkedlist 和 ziplist 的优点。其本质是一个链表,链表的每个节点都是一个 ziplist,既兼顾了 linkedlist 的高效插入删除能力,又具备 ziplist 的内存节省优势,思想类似 C++ 中的 std::deque。
**8. intset(整数集合):**专门用于存储全部由整数构成的集合,底层为有序数组,查询效率高,且比普通集合更节省内存。
**9. skiplist(跳表):**本质是一种有序链表,与普通链表不同,跳表的每个节点拥有多个指针域,通过分层指针的巧妙搭配,实现近似二分查找,查询时间复杂度可达 O(logN),是 Redis 有序集合(zset)的核心底层实现之一。
object encoding key
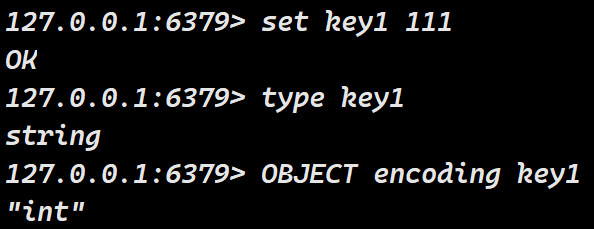
object encoding key:查看key对应的value的实际编码方式
redis会自动根据当前的实际情况选择内部的编码方式,自动使用的
是否要记住,啥时候使用啥编码方式呢?
只记思想,不记数字。
