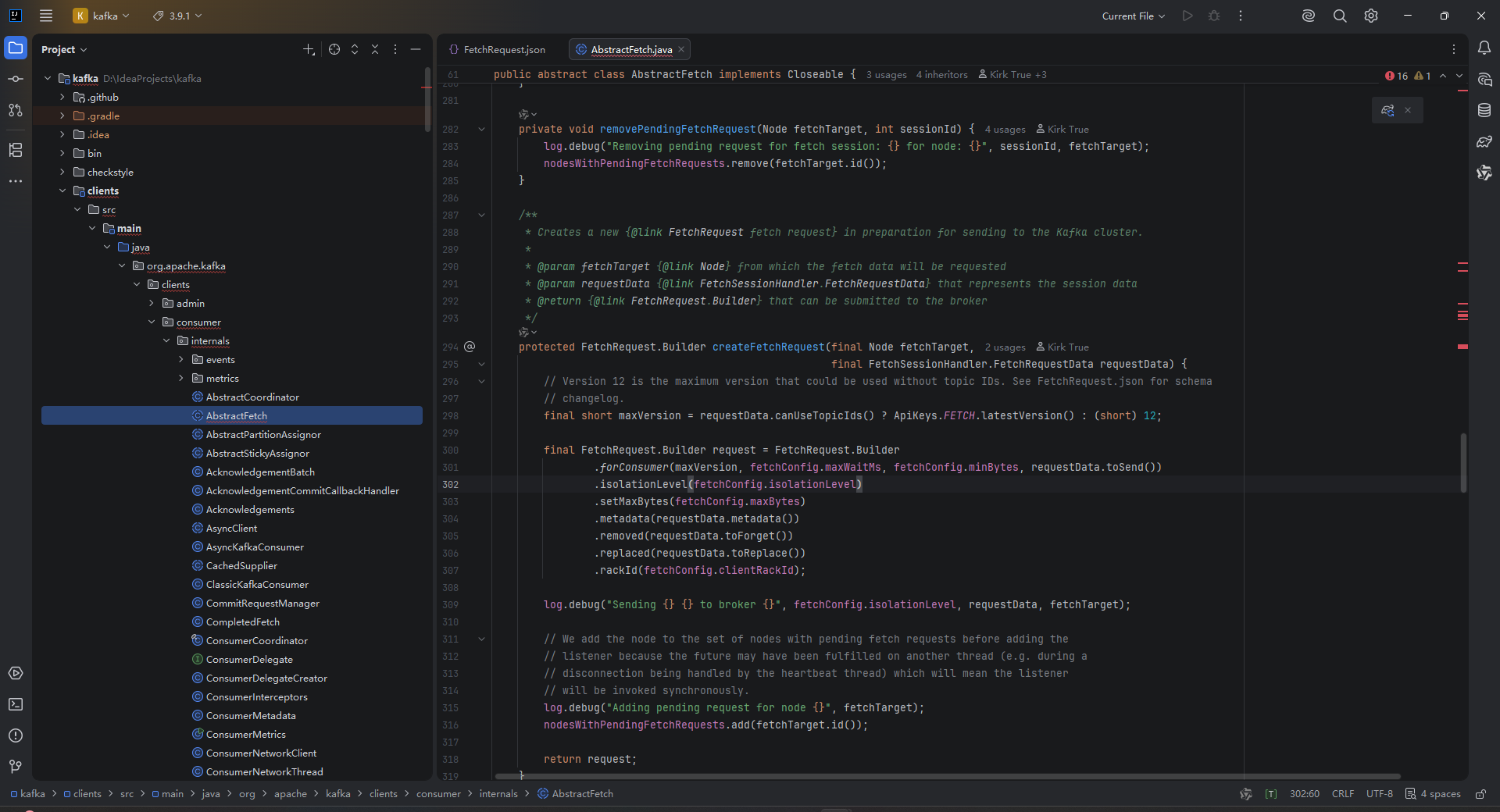
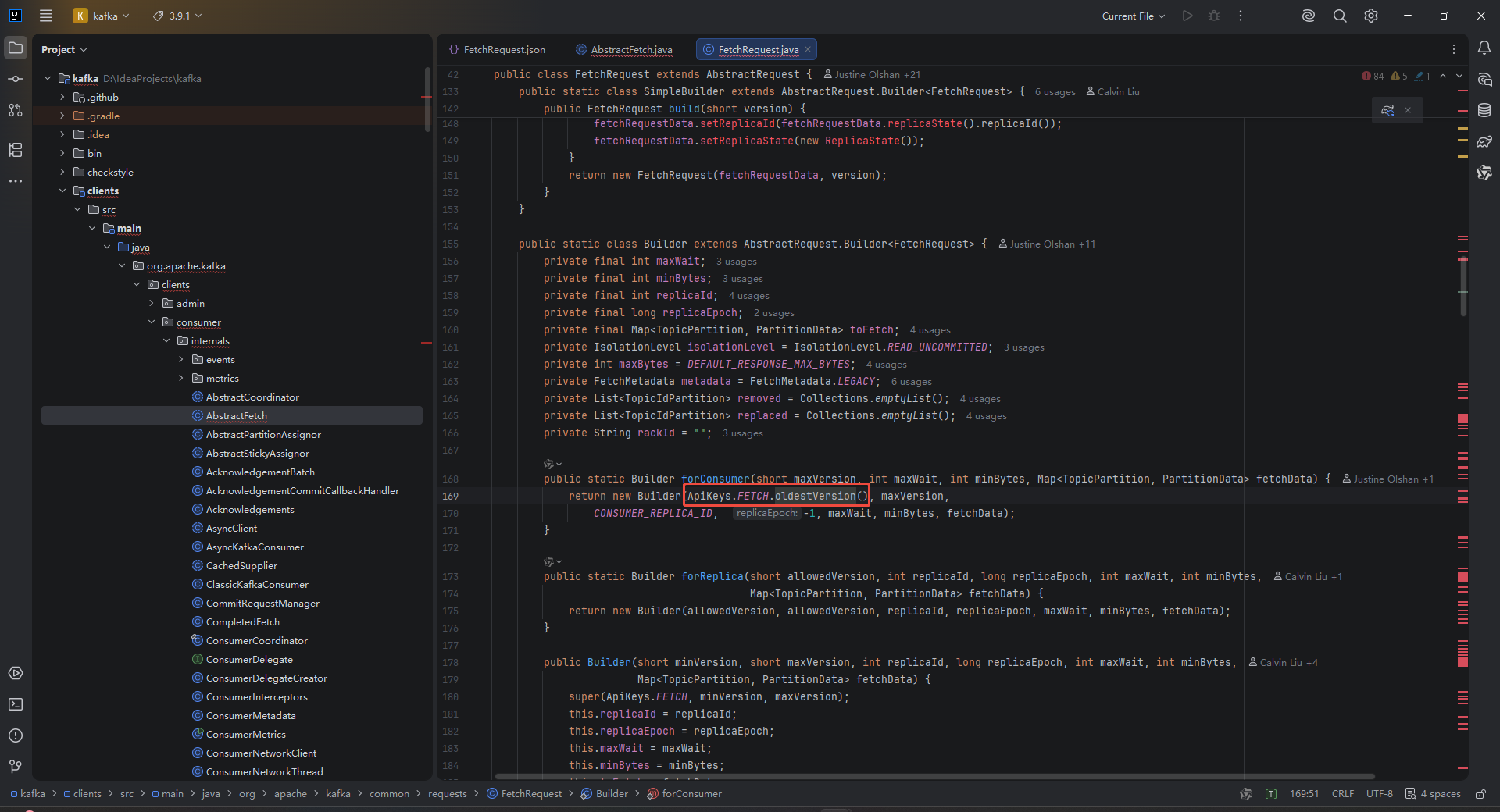
目前我们线上使用的Flink2.0版本,其中使用的Kafka版本为4.0.0,所以使用的flink-kafka-connector版本为4.0.1-2.0,所以我们使用的kafka-clients为4.0版本,但是在消费低版本的kafka时报了以下错误:
UnsupportedVersionException: The node does not support FETCH with version in range 4,12.
The supported range is 0, 3.
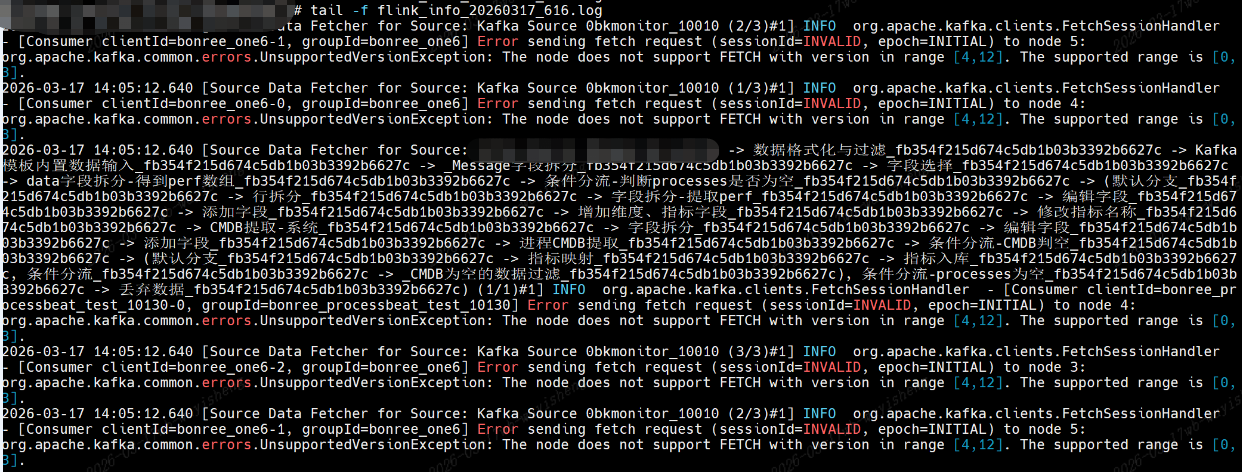
其中查询对端kafka的api版本信息:
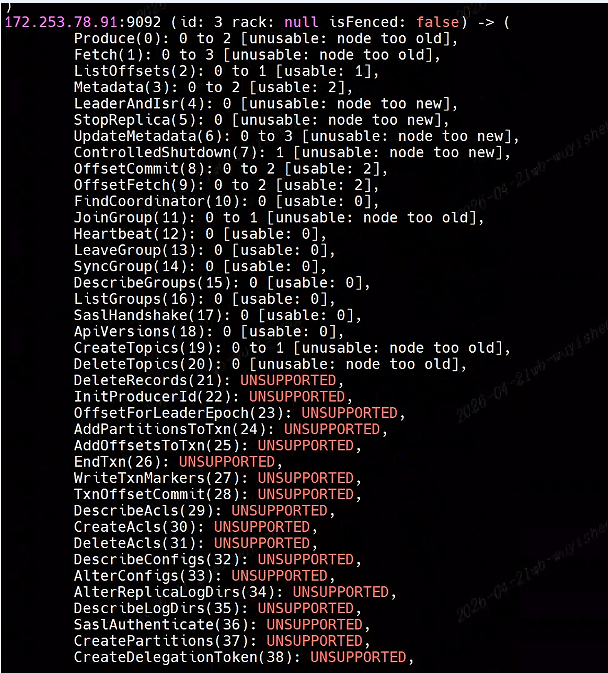
其中能看到远端Kafka支持的Fetch请求的版本为0, 3,而我们使用的kafka-clients:4.0.0版本支持4,12,所以是客户端版本太高了,不兼容低版本的Fetch版本,这会导致无法消费kafka的数据了。
通过AI分析:提示让降级kafka-clients版本,或者降级flink版本,使用适配低版本kafka的连接器,然而这两种方案改动都比较大。
通过分析kafka源码发现,其中的Fetch类是通过Json文件动态生成的:
JSON 定义文件 → MessageGenerator → ApiMessageTypeGenerator → ApiMessageType.java → ApiKeys.javaJSON文件定义为:
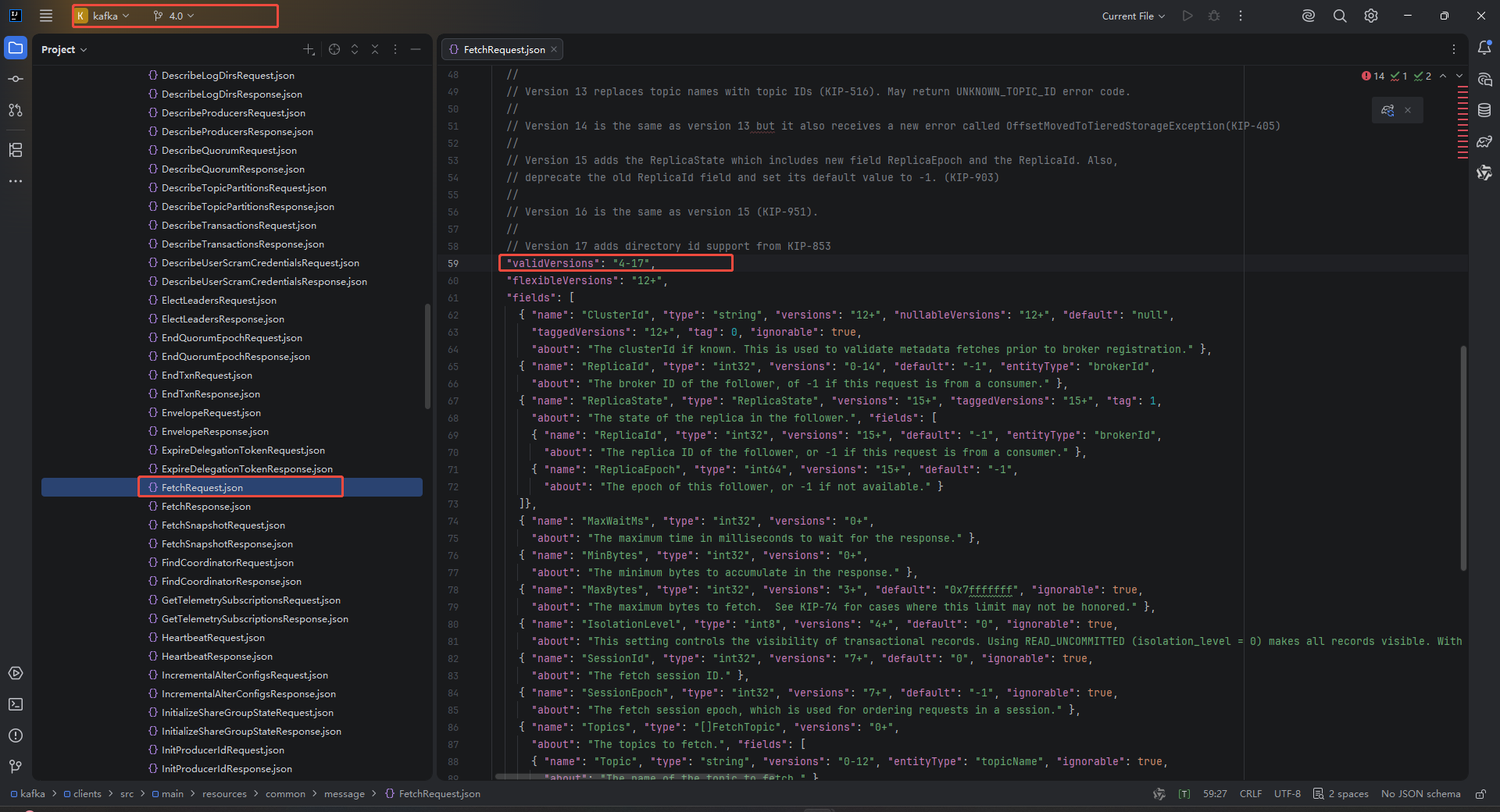
可以看到在4.0版本中,kafka-clients最低支持是4-17。最后我们观察低于4.0版本的客户端中支持情况,发现在3.9.1版本中,Fetch是支持0-17的,所以kafka-clients最后切换到3.19.1版本即可。
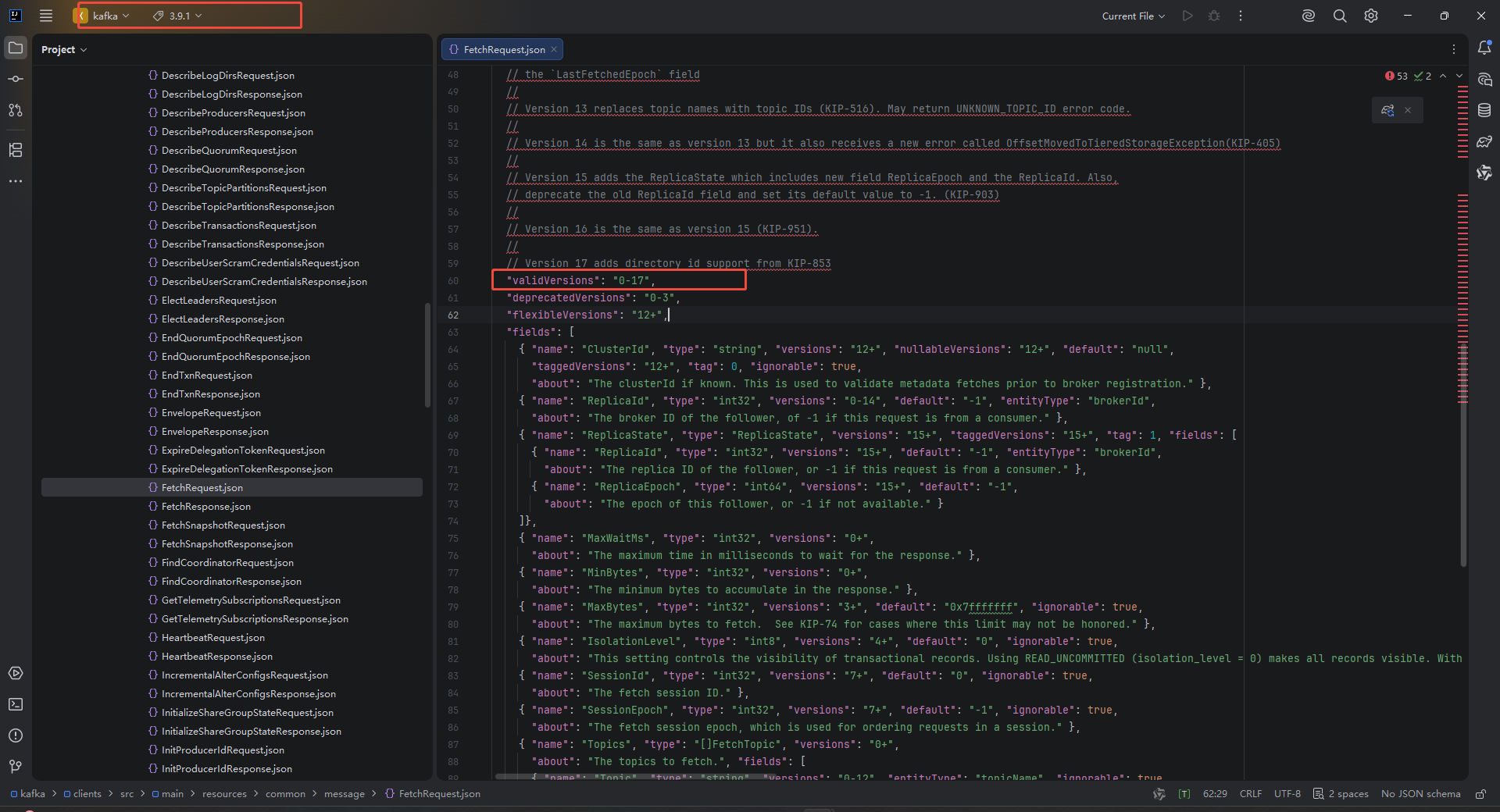
其中kafka中判断版本代码路径在: