词嵌入技术演进:从Word2Vec、GloVe到Transformer动态嵌入
一、Word2Vec:基于局部上下文的静态词嵌入
一句话总结
Word2Vec通过浅层神经网络,利用滑动窗口内的局部上下文预测目标词(CBOW)或通过目标词预测上下文(Skip‑gram),将每个词映射为一个固定长度的稠密向量。
核心思想
- 分布假说:语义相似的词出现在相似的上下文中。
- 训练方式 :
- CBOW:用上下文词预测中心词,训练快,适合高频词。
- Skip‑gram:用中心词预测上下文词,对低频词更友好。
- 加速技巧:负采样(Negative Sampling)或层次Softmax(Hierarchical Softmax)。
优点
- 训练效率高,可处理大规模语料。
- 词向量具有线性语义运算能力(如"国王‑男人+女人≈王后")。
局限
- 静态表示:一个词只有一个向量,无法解决一词多义。
- 依赖局部窗口:难以捕捉长距离依赖。
- 未登录词:训练时未见过的词无法生成向量。
二、GloVe:基于全局共现矩阵的静态词嵌入
一句话总结
GloVe通过构建全局词‑词共现矩阵,并对其对数进行低秩分解,使词向量的点积逼近共现概率的对数,从而融合全局统计信息。
核心思想
- 构建共现矩阵 ( X_{ij} )(词 ( i ) 出现在词 ( j ) 上下文中的次数)。
- 关键洞察:概率比(如 ( P_{ice,solid}/P_{steam,solid} ))比原始频次更能体现语义关系。
- 损失函数:加权最小二乘,拟合 ( w_i \cdot w_j + b_i + b_j = \log X_{ij} )。
优点
- 充分利用全局语料统计,对低频词更鲁棒。
- 在小规模语料上表现通常优于Word2Vec。
- 训练稳定,无需负采样等技巧。
局限
- 静态表示(一词多义问题依旧存在)。
- 需要存储共现矩阵,内存消耗较大(尽管可用稀疏格式)。
- 无法处理未登录词。
三、现代基于Transformer的词嵌入机制
一句话总结
Transformer通过多层自注意力机制动态融合上下文信息,使每个词的表示不再是固定向量,而是根据所在句子实时计算,从而彻底解决一词多义问题。
核心机制
- 输入层:仍使用静态Token Embedding + 位置编码(保留基础语义和顺序)。
- 自注意力层:每个词与序列中所有词交互,逐层聚合上下文信息。
- 动态性:同一个词在不同句子中经过相同的网络参数,但由于上下文不同,最终输出向量完全不同。
代表性模型
- BERT:双向Transformer,通过掩码语言建模(MLM)预训练,可提取任意层输出作为上下文相关的词嵌入。
- GPT:单向(因果)Transformer,适合生成任务,同样输出动态表示。
- LLaMA/Qwen等:在Transformer基础上改进(RMSNorm、RoPE、SwiGLU等),但词嵌入的动态本质不变。
优点
- 一词多义:自动区分(如"苹果"在水果和公司语境下向量不同)。
- 长距离依赖:自注意力直接建模全序列关系。
- 层次化语义:浅层捕捉语法,深层捕捉语义。
局限
- 计算开销大:自注意力复杂度 ( O(n^2) ),推理慢。
- 需要大量数据:预训练成本高。
- 可解释性较低:比静态嵌入更难观察语义关系。
四、总结对比表
| 维度 | Word2Vec | GloVe | Transformer(动态) |
|---|---|---|---|
| 统计方式 | 局部滑动窗口 | 全局共现矩阵 | 全序列自注意力 |
| 表示性质 | 静态(每个词一个向量) | 静态 | 动态(依赖上下文) |
| 一词多义 | ❌ 无法区分 | ❌ 无法区分 | ✅ 自动区分 |
| 长距离依赖 | ❌ 窗口有限 | ❌ 间接通过共现矩阵 | ✅ 直接建模 |
| 未登录词 | ❌ 无法处理 | ❌ 无法处理 | ✅ 子词分词解决 |
| 训练复杂度 | O(T)(T为词数) | O(T + V²)(V词表大小) | O(L·n²·d)(L层,n序列长) |
| 推理速度 | 极快(查表) | 极快(查表) | 慢(需前向传播) |
| 典型应用 | 快速原型、轻量任务 | 中小语料、语义类比 | 深度理解、生成任务 |
五、选型建议
- 资源受限 / 需要快速部署:Word2Vec 或 GloVe。
- 需要高质量、能处理一词多义的语义表示:使用BERT等动态嵌入,并可根据任务微调。
- 大语言模型应用:直接用LLM的隐藏状态,无需单独提取静态词嵌入。
一句话总结演进:从"每个词一个固定ID"到"每个词根据上下文实时计算ID"------词嵌入从静态查表走向动态理解,是NLP从"符号匹配"迈向"语义理解"的关键跃迁。
MHA、MQA、GQA:多头注意力机制的三种变体
在Transformer中,多头注意力(Multi-Head Attention, MHA) 是核心组件。随着大模型对推理效率的要求越来越高,研究者提出了MQA(Multi-Query Attention) 和GQA(Grouped-Query Attention),在保持质量的同时大幅减少KV缓存,提升推理速度。
一、MHA(Multi-Head Attention,标准多头注意力)
定义
每个注意力头独立拥有自己的查询(Q)、键(K)、值(V) 权重矩阵。输入经过线性变换后,分成多个头并行计算注意力,最后拼接并线性变换输出。
公式
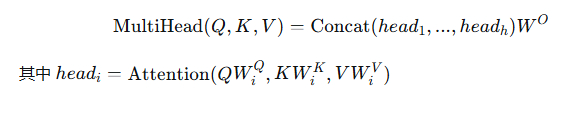
特点
- 参数量:( h ) 组独立的 ( W^Q, W^K, W^V ),参数量大。
- KV缓存:解码时每个token需缓存所有头的K、V,内存占用高。
- 表达能力:最强,每个头可学习不同的注意力模式。
优缺点
| 优点 | 缺点 |
|---|---|
| 表达能力强,性能最好 | 推理时KV缓存大,内存带宽瓶颈 |
| 训练稳定,广泛应用 | 长序列生成时显存爆炸 |
二、MQA(Multi-Query Attention,多查询注意力)
定义
所有头共享同一份K和V,仅Q保持独立。即每个头有自己的 ( W^Q ),但所有头共用一套 ( W^K ) 和 ( W^V )。
图示(简略)
Q0 Q1 ... Qh
│ │ │
K ──────┼──┼──────┤ (所有头共享同一个K)
V ──────┼──┼──────┤ (所有头共享同一个V)
▼ ▼ ▼
attn0 attn1 ... attnh特点
- KV缓存:只需缓存1份K和1份V(而不是h份),内存占用降低为 ( 1/h )。
- 参数量:大幅减少,尤其K、V矩阵。
- 推理速度:显著提升,尤其长序列生成。
优缺点
| 优点 | 缺点 |
|---|---|
| 推理极快,KV缓存小 | 表达能力下降,质量略有损失 |
| 内存友好,适合大模型推理 | 训练可能不如MHA稳定 |
代表模型
- PaLM 、Gemini 、LLaMA 1/2(部分版本) 等。
三、GQA(Grouped-Query Attention,分组查询注意力)
定义
MHA与MQA的折中:将头分成若干组,每组内共享K和V,但组间独立。设总头数为 ( h ),组数为 ( g ),则每组有 ( h/g ) 个头共享同一份K、V。
- 当 ( g = h ) 时,GQA退化为MHA(每组1个头,完全独立)。
- 当 ( g = 1 ) 时,GQA退化为MQA(所有头一组,完全共享)。
图示(以h=8, g=2为例)
组0: 头0 头1 头2 头3 → 共享K0,V0
组1: 头4 头5 头6 头7 → 共享K1,V1特点
- KV缓存:缓存 ( g ) 份K、V(MHA缓存h份,MQA缓存1份)。
- 性能:接近MHA,优于MQA。
- 效率:接近MQA,优于MHA。
优缺点
| 优点 | 缺点 |
|---|---|
| 平衡质量与效率,最佳折中 | 需要选择分组数,超参数敏感 |
| 推理快,显存占用适中 | 实现比MQA略复杂 |
代表模型
- LLaMA 2/3 、Qwen 、DeepSeek 等主流大模型普遍采用GQA。
四、对比总结表
| 特性 | MHA | MQA | GQA |
|---|---|---|---|
| K/V独立程度 | 每头独立 | 所有头共享 | 分组内共享 |
| KV缓存大小 | ( h \cdot d_k \cdot L ) | ( 1 \cdot d_k \cdot L ) | ( g \cdot d_k \cdot L ) |
| 参数量 | 高 | 低 | 中等 |
| 推理速度 | 慢 | 最快 | 快 |
| 模型质量 | 最高 | 略低 | 接近MHA |
| 典型应用 | 训练、小模型 | 极速推理 | 大模型推理标准 |
h :头数,d_k :每个头的维度,L:序列长度
五、选择建议
- 训练阶段:通常使用MHA(或GQA,便于推理部署)。
- 推理阶段(长序列、高并发):优先选择GQA(LLaMA 3、Qwen等),或MQA(对速度极致要求可接受质量损失)。
- 资源极度受限:MQA可进一步减少KV缓存。
六、一句话总结
MHA让每个头独立学习最强表达,但推理代价高;MQA让所有头共享K/V,推理极快但质量略降;GQA分组共享,在质量和效率间取得最佳平衡,成为现代大模型推理的标准选择。
MoE架构详解:门控路由、Top-k激活与负载均衡
混合专家(Mixture of Experts, MoE)是一种通过稀疏激活扩展模型容量的架构:模型包含多个"专家"(通常是独立的FFN子网络),但每个输入仅激活其中少数几个专家,从而在计算成本几乎不变的情况下大幅增加参数量。
一、MoE核心组件
一个标准的MoE层由三部分组成:
- 专家网络(Experts):一组并行的FFN(通常 ( E_1, E_2, ..., E_n )),每个专家有自己的可训练参数。
- 门控网络(Gating Network / Router):一个轻量级网络,为每个输入计算各专家的得分,决定哪些专家被激活。
- 聚合输出:将激活专家的输出按权重加权求和。
数学形式
对于输入 ( x ):
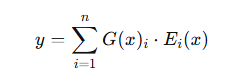
其中 ( G(x) ) 是门控网络输出的权重向量(通常稀疏,大多数元素为0)。
二、门控路由(Gating Routing)
门控网络的作用是为每个token(或每个输入)选择最合适的专家。常用实现:
2.1 可学习线性门控
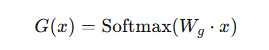
输出所有专家的概率分布,然后选择Top-k个专家。
2.2 带噪声的门控(用于负载均衡)
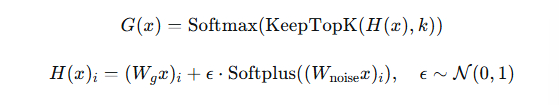
噪声项鼓励探索,避免路由塌陷。
2.3 路由策略
- Token Choice Routing:每个token独立选择专家(最常见,如Switch Transformer、Mixtral)。
- Expert Choice Routing:每个专家选择Top-k个token,保证负载均衡(稳定性好,但可能造成token未被处理)。
三、Top-k激活(Sparse Activation)
为了保持计算稀疏,每个输入仅激活得分最高的 ( k ) 个专家(通常 ( k=1 ) 或 ( k=2 ))。
公式

为什么Top-k?
- 计算效率:FFN的计算量与激活专家数成正比,k=1或2时,计算量仅为稠密模型的 ( k/n )。
- 容量扩展:专家总数 ( n ) 可以很大(如几十上百),但每个token只激活少量,总参数量巨大但推理FLOPs可控。
示例(k=2, n=8)
输入 x → 门控得分 [0.1, 0.7, 0.0, 0.4, 0.9, 0.2, 0.0, 0.3]
Top-2 索引:专家4(0.9)、专家1(0.7)
输出 = 0.9*E4(x) + 0.7*E1(x) (其他专家贡献0)四、负载均衡(Load Balancing)
MoE训练中常见问题:门控网络倾向于始终激活少数几个专家,导致专家"坍塌"(collapse),其他专家未被训练。负载均衡通过引入辅助损失强制专家被均匀使用。
4.1 重要性均衡(Importance)
要求一批数据中,每个专家被选中的总概率接近相等。
辅助损失 :
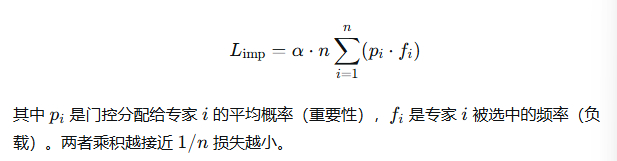
4.2 Switch Transformer 的负载均衡损失
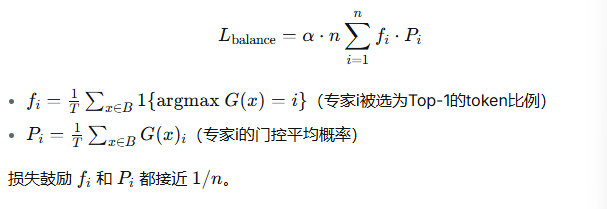
4.3 专家容量(Expert Capacity)
除损失外,还可设置每个专家处理的最大token数(容量因子)。超出容量的token被丢弃(残差连接处理),强制负载均衡。
4.4 其他技术
- 随机路由:以一定概率随机选择专家,打破确定性偏好。
- 辅助损失系数:通常很小(如0.01),避免主导主损失。
五、MoE整体架构图(文本)
输入 token → 门控网络(线性+Softmax+Top-k)
│
┌─────────────┼─────────────────────┐
│ │ │
▼ ▼ ▼
专家1 专家2 ... 专家n
(FFN) (FFN) (FFN)
│ │ │
└─────────────┴─────────────────────┘
│
加权求和(仅激活专家)
│
输出六、主流MoE变体
| 模型 | 专家数 | Top-k | 负载均衡策略 |
|---|---|---|---|
| Switch Transformer | 8~2048 | 1 | 辅助损失 + 容量因子 |
| GShard | 8~2048 | 2 | 辅助损失 + 随机路由 |
| Mixtral 8x7B | 8 | 2 | 辅助损失(无容量丢弃) |
| DeepSeek-MoE | 64 | 6 | 共享专家 + 细粒度分割 + 设备限制定向 |
| Qwen2.5-MoE | 60 | 4 | 辅助损失 + 专家偏差项 |
七、一句话总结
MoE通过门控网络为每个输入动态选择Top-k个专家(稀疏激活),并结合负载均衡损失和容量约束,在计算成本可控下大幅扩展参数量,成为大模型千亿参数的核心技术。
三种主流Transformer架构的应用与特点
1. Decoder-Only(自回归生成架构)
典型模型
GPT系列、LLaMA、Qwen、DeepSeek等大多数现代大语言模型。
核心机制
- 因果自注意力(Causal Attention) :使用下三角掩码(Triangular Mask),每个token只能看到它自身及之前的token,无法看到未来信息。
- 自回归生成:推理时逐个生成token,每次将新生成的token追加到输入序列末尾,再预测下一个。
工作流程
输入序列 → 嵌入层 → 多层Decoder(带三角Mask)→ 最后一层输出
↓
取最后一个位置的向量 → 线性映射 → Softmax → 采样下一个词典型应用
- 文本生成:故事创作、代码生成、邮件撰写
- 对话系统:ChatGPT、各类聊天机器人
- 文本补全:代码补全、句子续写
- 少样本学习:通过提示词直接执行多种任务
优点
- 训练简单(只需预测下一个词)
- 推理自然支持自回归生成
- 扩展性好,适合超大规模模型
2. Encoder-Only(双向理解架构)
典型模型
BERT、RoBERTa、DeBERTa等。
核心机制
- 双向自注意力(Bidirectional Attention) :无掩码限制,每个token可以同时看到序列中所有其他token(左右上下文)。
- 预训练任务:掩码语言建模(MLM,预测被MASK的词)和下一句预测(NSP)。
工作流程
输入序列(含[MASK])→ 嵌入层 → 多层Encoder(全可见)→ 最后一层输出
↓
取[MASK]位置的向量 → 线性映射 → 词汇概率 → 预测被掩码的词典型应用
- 自然语言理解(NLU):情感分析、意图识别
- 文本分类:垃圾邮件检测、新闻分类
- 序列标注:命名实体识别(NER)、词性标注(POS)
- 句子对任务:语义相似度、自然语言推理(NLI)
- 问答系统:抽取式问答(如SQuAD)
优点
- 双向上下文理解能力强,适合"理解"任务
- 微调后在下游NLU任务上表现优异
3. Encoder-Decoder(序列转换架构)
典型模型
T5、BART、原始Transformer(用于机器翻译)。
核心机制
- 编码器(Encoder):双向注意力,将输入序列编码为隐状态表示。
- 解码器(Decoder):因果自注意力(带掩码)+ 编码器-解码器交叉注意力,自回归生成目标序列。
- 预训练任务:去噪自编码(如T5的"文本乱序恢复")或翻译任务。
工作流程
输入序列 → 编码器(双向注意力)→ 编码器输出
↓
开始符 → 解码器(自回归,带掩码+交叉注意力)→ 逐步生成输出序列典型应用
- 机器翻译:源语言→目标语言
- 文本摘要:长文档→简短摘要
- 文本改写:语法纠错、风格转换
- 问答生成:给定上下文,生成答案
- 结构化数据转文本:表格→描述文本
优点
- 输入和输出可以长度不同,且两者可以有不同的词汇表
- 编码器-解码器注意力让解码器能够灵活"查阅"输入序列的全部信息
- 适合序列到序列的转换任务
三、对比总结表
| 特性 | Decoder-Only | Encoder-Only | Encoder-Decoder |
|---|---|---|---|
| 注意力掩码 | 下三角(因果掩码) | 无掩码(全可见) | 编码器无掩码,解码器有因果掩码+交叉注意力 |
| 预训练任务 | 自回归语言建模(预测下一个词) | 掩码语言建模(MLM) | 去噪自编码或翻译 |
| 推理方式 | 自回归逐个生成 | 一次性输出(分类/标注) | 自回归生成目标序列 |
| 典型应用 | 文本生成、对话、代码补全 | 情感分析、NER、分类 | 机器翻译、摘要、文本改写 |
| 代表模型 | GPT、LLaMA、Qwen | BERT、RoBERTa | T5、BART、原始Transformer |
| 优势 | 生成流畅,扩展性强 | 双向理解,微调性能高 | 序列转换质量最高 |
四、选型建议
- 需要生成连贯文本、对话或代码 → Decoder-Only(如GPT系列)
- 需要理解句子含义、分类或提取信息 → Encoder-Only(如BERT)
- 需要将一段文本转换为另一段不同形式的文本 → Encoder-Decoder(如T5)
值得注意的是,现代超大规模模型(100B+参数)几乎都采用Decoder-Only架构,因为它在扩展性和通用生成能力上最具优势;而Encoder-Only和Encoder-Decoder在小模型和特定任务上仍有不可替代的价值。