1. 人工智能三大概念:人工智能(AI)、机器学习(ML) 和 深度学习(DL)
1.1 名词:
1️⃣AI(Artifical Intelligence)人工智能 :仿智,用计算机模拟人脑,让计算机能够像人类一样理性的思考,行动;
2️⃣ML(Machine Learning)机器学习 :给与你的模型一些训练数据,让模型离开找规律、找公式,并对测试集进行预测;机器自动学习,不是人为规则编程;
3️⃣DL(Deep Learning)深度学习:模仿人脑神经网络结构的机器学习方法,构建知识体系、图谱,需要大量数据和算力;例子:图像识别、语音转文字。
1.2 三者关系 :
机器学习是实现人工智能的一种途径;深度学习是机器学习的一种方法;
AI(人工智能)包含机器学习ML,机器学习包含深度学习DL;
1.3 算法的学习方式有哪两种?
基于规则的学习和基于模型的学习;
基于规则的学习是自己写if else;而机器的学习是基于模型的学习:找规律、找公式;
2. 机器学习发展的三要素
机器学习即用机器模拟人脑;
2.1 机器学习发展的三要素: 数据、算法、算力;
1️⃣数据: 数据决定了模型效果的上限;
常见术语 :样本、特征、标签、训练集和测试集;
样本(sample) :一行数据就是一个样本;
特征(feature) :特征是从数据中抽取出来的对结果预测有用的信息(属性);
标签/目标(label/target) :需要预测的信息;
数据集划分 :分为训练集和测试集,比例一般为8:2或7:3;
2️⃣算法:分为分类的、回归的、聚类的;
3️⃣算力:有CPU、GPU、TPU;
CPU :主要适合I\0密集型的任务(即读写的);
GPU :主要适合计算密集型任务(并行计算的,计算密集的);
TPU :专门针对大型网络训练而设计的一款处理器(TPU做的是张量处理器,适合于大规模数据集的训练);
大多数人能买到的只有CPU、GPU,TPU一般无法大批量采购;
2.2 机器学习的应用领域:
计算机视觉CV:对人看到的东西进行理解;
自然语言处理:对人交流的东西进行理解;
数据挖掘和数据分析:也属于人工智能的范畴;
2.3 人工智能发展史:
1956年人工智能元年;
2012年计算机视觉深度神经网络方法研究兴起;
2017年自然语言处理应用大幕拉开;
2022年chatGPT的出现,引起AIGC的发展;
人工智能之父:约翰·麦卡锡、
机器学习之父:亚瑟·塞缪尔;
3. 机器学习常用术语
样本、特征、标签、训练集和测试集;
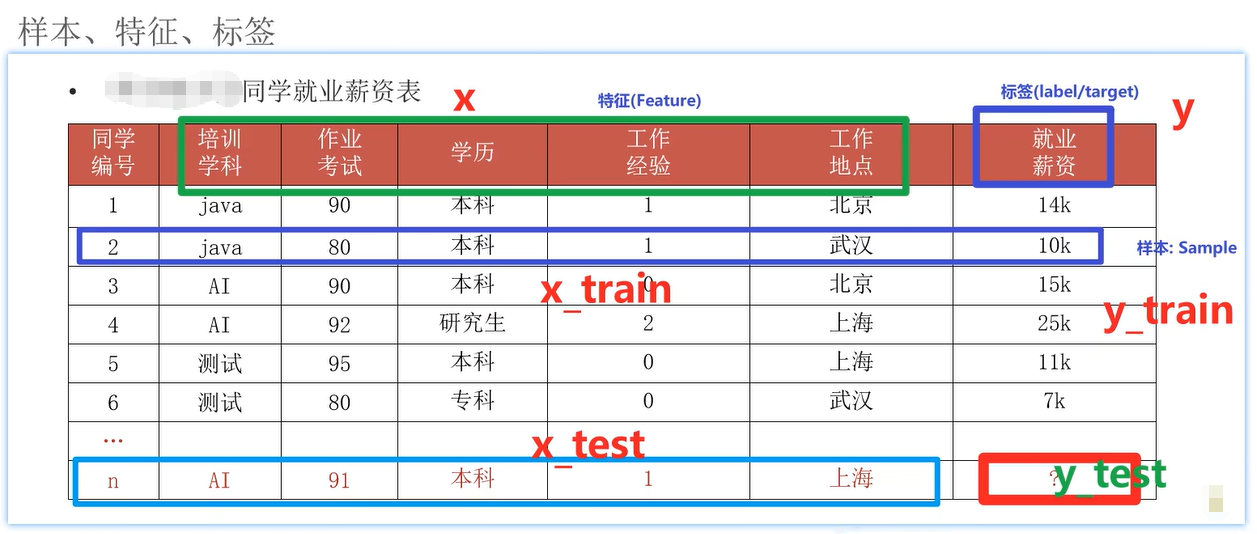
样本(sample) :一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录;
特征(feature) :一列数据一个特征,有时也被称为属性;(特征如何理解(重点):特征是从数据中抽取出来的、对结果预测有用的信息 eg:房价预测、车图片识别)
标签/目标(label/target) :模型要预测的那一列数据。(本场景是就业薪资:就业薪资与培训学科、作业考试、学历、工作经验、工作地点5个特征有关系;)
数据集(dataset) :多个样本组成数据集;
数据集可划分两部分:训练集、测试集,比例:8:2,7:3; (数据集中的每条数据就叫样本;数据集是用来训练或测试的数据的集合)
训练集(training set) :用来训练模型(model)的数据集;
测试集(testing set) :用来测试模型的数据集;
(一条数据就叫样本;分析的字段就叫特征;需要的结果字段就叫标签;给模型训练时用的叫训练集;测试集是测试结果用的;训练集测试集占比7:3或8:2,一般7:3。)
x_train训练集中的x 、x_test 测试集中的x 、y_train 训练集中的y 、y_test 测试集中的y;
4. 机器学习算法分类
有监督学习、无监督学习、半监督学习、强化学习;
算法分类:①有监督学习即有特征有标签、②无监督学习即有特征无标签、③半监督学习即部分内容打标记,让程序基于打过标记的数据进行训练、④强化信息严格意义上不属于机器学习,属于深度学习,但深度学习可理解为机器学习的分支。
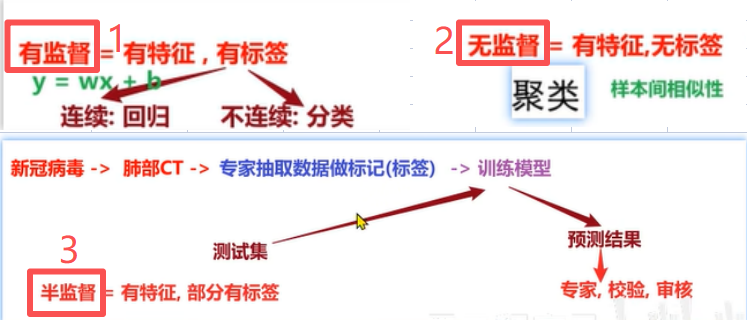
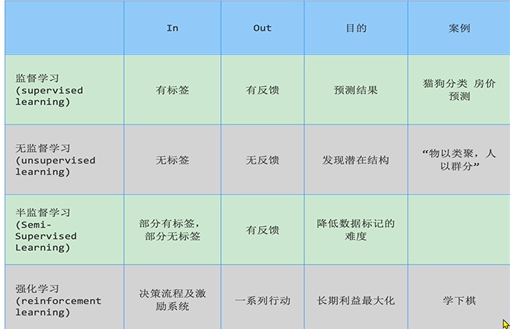
4.1 有监督学习:
定义 :输入训练集数据包含输入特征值和目标值;(回归:函数的输出是一个连续的值;分类:函数的输出是有限个离散值;)
特点:有特征、有标签;
定义 :输入数据是由输入特征值和目标值所组成,即输入的训练数据有标签的;
数据集 :需要标注数据的标签/目标值;
分类 :分类问题 & 回归问题 :
①回归问题:目标值(标签值)是连续的;(一元线性回归:y=wx+b;)
②分类问题:目标值(标签值)是不连续的;分类种类:二分类、多分类;
即监督学习是有分类、有标签;标签如果连续就是回归,如果不连续就是分类;
4.2 无监督学习:
定义 :输入训练集数据是由输入特征值组成,没有目标值;他是根据样本间的相似性对样本集进行分类,所以叫聚类;
特点:有特征、无标签; (训练数据无标签;根据样本间的相似性对样本集进行聚类,发现事物内部结构及相互关系)
定义 :输入数据没有被标记,即样本数据类别未知,没有标签根据样本间的相似性,对样本集聚类,以发现
事物内部结构及相互关系。
分类 :聚类问题:根据样本间相似性
4.3 半监督学习:
定义 :训练集同时包含有目标值的样本数据和不含有目标值的样本数据;目的是降低数据标记的成本;
特点:有特征、部分有标签、部分没有标签;
半监督学习方式可大幅降低标记成本;
4.4 强化学习(Reinforcement Learning):
定义 :根据环境状态进行行动,已获取更多的奖励 。是机器学习的一个重要分支;智能体不断与环境进行交互,通过获取最大奖励的方式(试错的方式)来获得最佳策略;四要素:Agent(智能体),环境(Environment),行动(Action),奖励(Reward) ;
①应用场景:里程碑AlphaGo围棋、各类游戏、对抗比赛、无人驾驶场景;
②基本原理:通过构建四个要素:agent,环境状态,行动,奖励,agent根据环境状态进行行动以获得最多的累计奖励。
强化学习 = 寻找最短路径(最优解),以便获取最多的奖励;
总结:
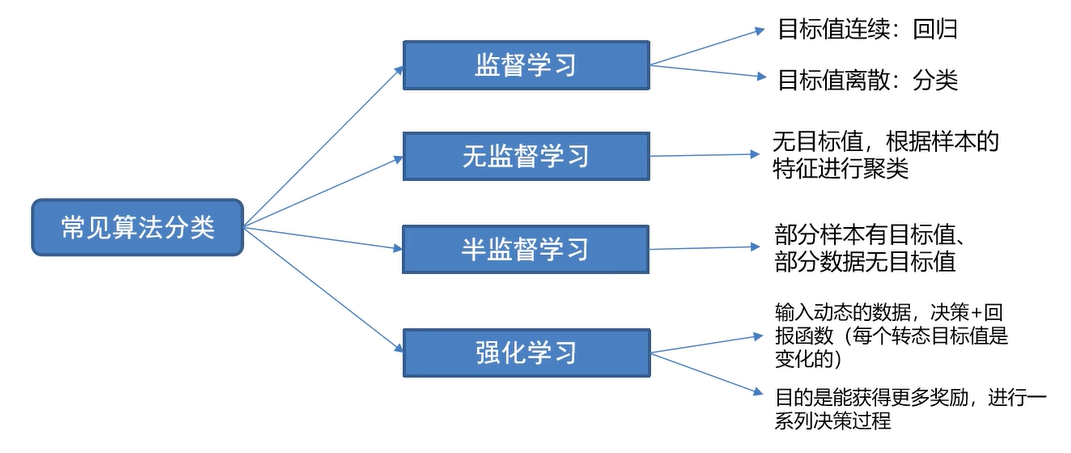
图示 :常见的机器学习算法分类 :①监督学习 :有特征、有标签 ;标签是连续的叫回归问题 、标签不连续的叫分类问题 ;②无监督学习 :有特征、无标签 ,无标签怎么分,只能根据样本之间的相似性进行划分 聚类,这种叫聚类问题 ;③半监督学习 :有特征、部分有标签、部分没有标签 ,最终的目的是降低专家标注数据的成本;④强化学习 :让Agent智能体根据环境状态进行行动以获得最多的累计奖励。输入动态数据,决策+回报函数,每个转态目标是变化的;(即走每一步得到的奖励是不一样的,如 出牌结果不同);目的是能获取更多的奖励,进行一系列决策过程;
5. 机器学习建模流程
5.1 机器建模流程
机器建模流程:
1️⃣ 第一步:数据的加载(获取数据 ):搜集与完成机器学习任务相关的数据集;
2️⃣ 第二步:数据的预处理 (数据的基本处理):数据集中异常值、缺失值的处理 ;
3️⃣ 第三步:特征工程 :对数据特征进行提取、转成向量,让模型达到最好的效果(特征工程又分为5项:特征提取、特征预处理、特征降维、特征选择、特征组合 );
4️⃣ 第四步:机器学习(模型训练 ):选择合适的算法对模型进行训练;(啥叫合适的算法?:机器学习中的问题可分为三大类:①回归类的(Regression) :属于有监督:是有特征、有标签且标签是连续的;②分类的(Classification) :也属于有监督:是有特征、有标签但标签的不连续的;③聚类的(Clustering) :无监督:有特征、无标签,无标签怎么分,只能根据样本之间的相似性进行聚类,如后面的Keymeans算距离,样本之间的相似性就是通过算距离来的,根据距离的远近做衡量)。根据不同的任务来选中不同的算法;有监督学习、无监督学习、半监督学习、强化学习;
5️⃣ 第五步:模型评估 :评估效果好上线服务,评估效果不好则重复上述步骤(接着训练);
6️⃣ 第六步:模型预测 ;⑤和⑥可能会反着:可能先评估再预测,也可能先预测再评估;
③
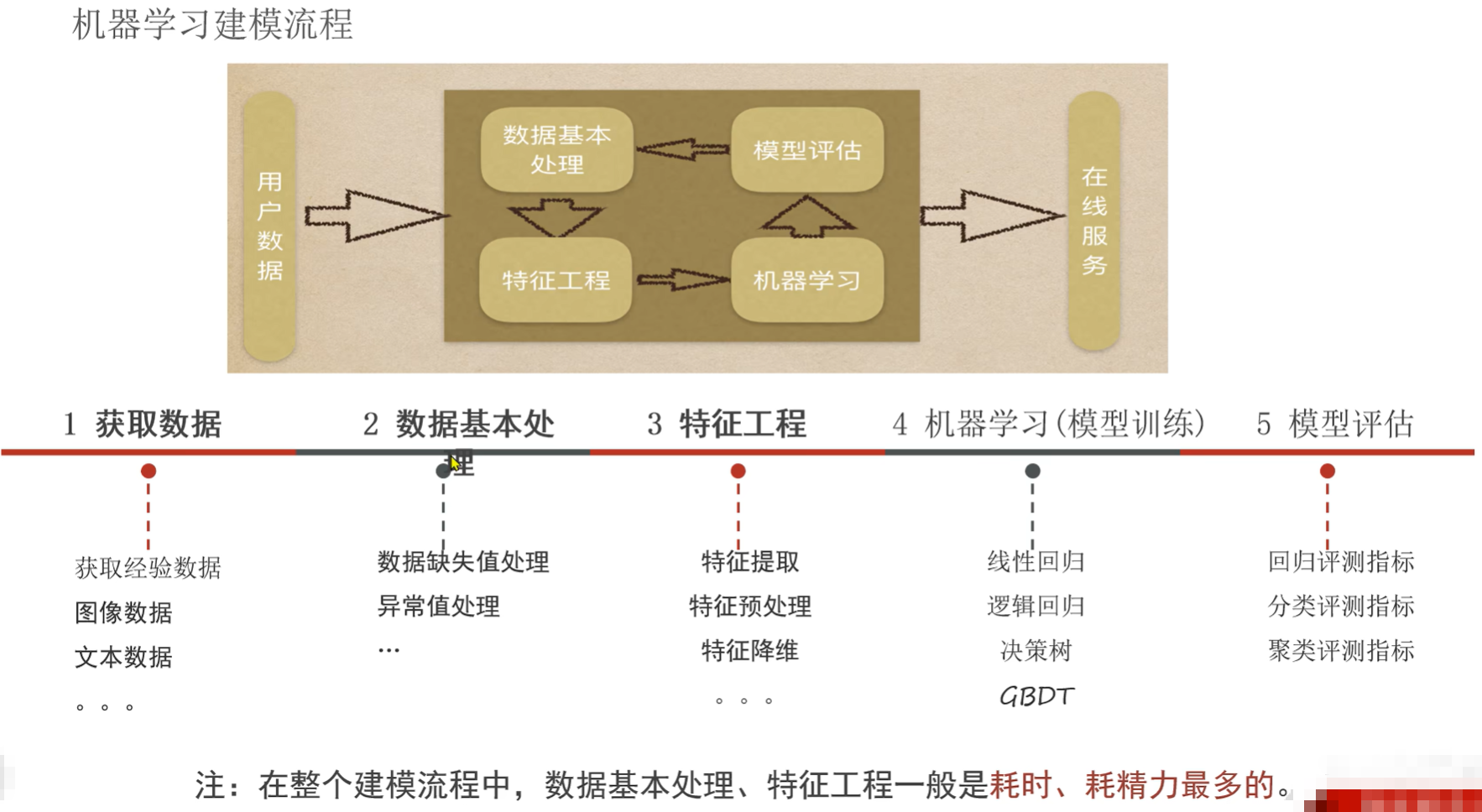
(图示上部分:当用户数据进来后,需要对数据进行基本处理,处理完之后要从数据集中寻求特征,即特征工程,它有分为5项:特征提取、特征预处理、特征降维、特征选择、特征组合;再将选出来的特征交给机器学习(模型)进行学习,学完之后对模型做评估,然后提供一些在线服务;
下部分:五大步:①获取数据即获取经验数据,如图像数据、文本数据、音频数据、视频数据等;②数据的基本处理,如缺失值处理、异常值处理,如RFM案例中对缺失值的处理一般就2个方案:要么删除 要么填充,对于数据量大,缺失值比较少 的时候进行删除,对于填充,填充的是中位数、平均值等;对于异常值:RFM案例中如消费金额(订单金额)在1元以下的认为是刷单,这种数据进行过滤;如果要处理一些复杂的业务,数据集中没有这些字段,可以让A列帮忙生成一个B列;这些都可以叫数据的基本处理;③特征工程:又分为特征提取,如在文本文件或者数据中提取出来一些特征列,这叫提取;特征的预处理是防止量纲不同导致数据结果有差异,量纲即权重;特征降维即将数据从三个特征降为两个特征,如将图像从3D(三维)图像降为2D(二维)图像;特征选取与特征提取不同,提取是提取特征,选取是选出最终要用的;最后是特征组合;④模型训练,如线性回归、逻辑回归、决策树、GBDT(梯度提升决策树);⑤模型评估:回归评测指标即回归模型的评估指标是啥、分类的、聚类的评估指标分别是啥,即不同模型的评估指标不同;)
5.2 有监督学习的模型训练和模型预测
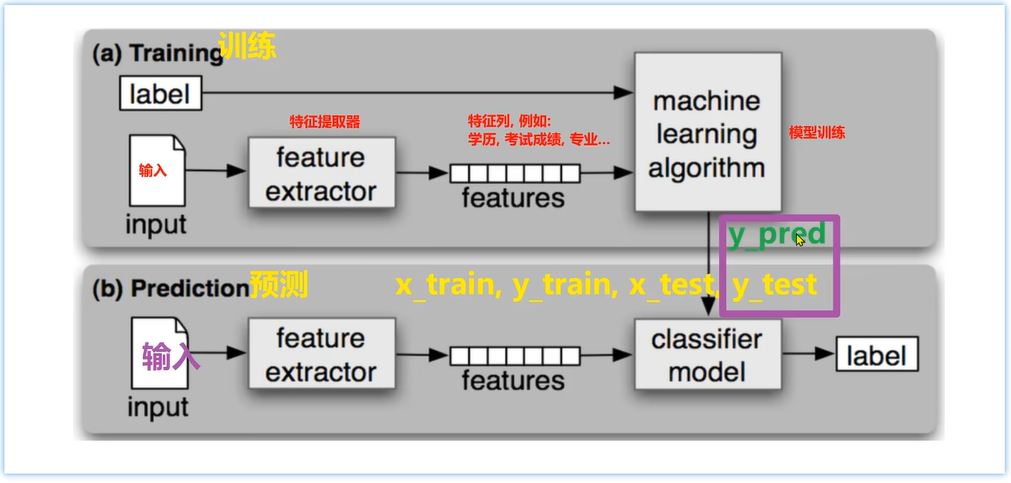
(图示:上部分是模型训练Training,下部分是模型预测Prediction;有标签label,input输入数据(训练集),通过特征提取器feature extractor提取特征,在特征列features中,如学历、考试成绩、专业等,从input数据中提取出来的特征;machine learning algorithm模型训练;下部分预测Prediction,input输入测试集,通过特征提取器feature extractor提取特征features,经过模型classifier model公式算法,最终有了一个预测标签label;即最终的结果都是为了这个值label标签,所以这个叫做有监督学习:有特征features、有标签label;)
6. 特征工程概念入门
特征工程、特征工程子领域
1️⃣ 特征工程(定义) :利用专业背景知识和技巧处理数据,让机器学习算法效果最好,这个过程就是特征工程;
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上线而已;
特征Feature:对任务有用的属性信息;
2️⃣ 特征工程的内容 :5项:特征提取、特征预处理、特征降维、特征选择、特征组合;
特征提取(Feature Extraction) :从原始数据中提取与任务相关的特性;特征向量;
特征预处理(Feature Preprocessing) :将不同的单位的特征数据转成同一个范围内;防止因为量纲的问题对数据集产生影响;
特征降维(Feature Decomposition) :将原始数据的为度降低;
特征选择(Feature Selection) :从特征中选择一些重要特征训练模型;
特征组合(Feature Crosses) :把多个特征合并组合成一个特征;一般采用 乘法或 加法;
特征降维和特征选择的区别:降维会改变原数据,而选择不会;
7. 模型训练
KNN(K近邻算法):
线性回归:
逻辑回归:
...
8. 模型评估
分类:准确率;
回归:MAE,MSE;
聚类:CH,SC...
模拟拟合:
9. 模型拟合问题
拟合(Fitting) :模型对样本分布点的模拟情况;
① 拟合 = 模型在 训练集和测试集上 的表现情况 ;
② 模型的拟合能力 = 泛化能力 ;
③ 欠拟合是训练集、测试集都不好,过拟合是训练集好、测试集不好 ;
9.1 欠拟合、过拟合、正好拟合;
1️⃣欠拟合(Underfitting) :模型在训练集、测试集上表现都不好 ;(因为数据集比较少、模型比较简单测不出来)
2️⃣过拟合(Overfitting) :在训练集上表现挺好、在测试集上表现不好 ;(因为数据集比较多、模型比较复杂导致学到了脏的内容)
3️⃣ 正好拟合(Just right):在训练集和测试集上表现都好的;
9.2 产生原因:
欠拟合产生的原因:模型过于简单;
过拟合产的原因:模型太过于复杂、数据不纯、训练数据太少;
9.3 泛化概念:
泛化 Generalization:模型的拟合情况 ;模型在新数据集(非训练数据,可理解为测试集)上的表现好坏的能力。(泛化能力越好,表示模型能力越接近正好拟合)
奥卡姆剃刀原则 :给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取;
(模型的拟合情况=泛化能力;若泛化能力一样即两模型的拟合能力一样,那选择时会根据奥卡姆剃刀倾向选择简单模型。)
10. 机器学习开发环境
基于Python的 scikit-learn 库:
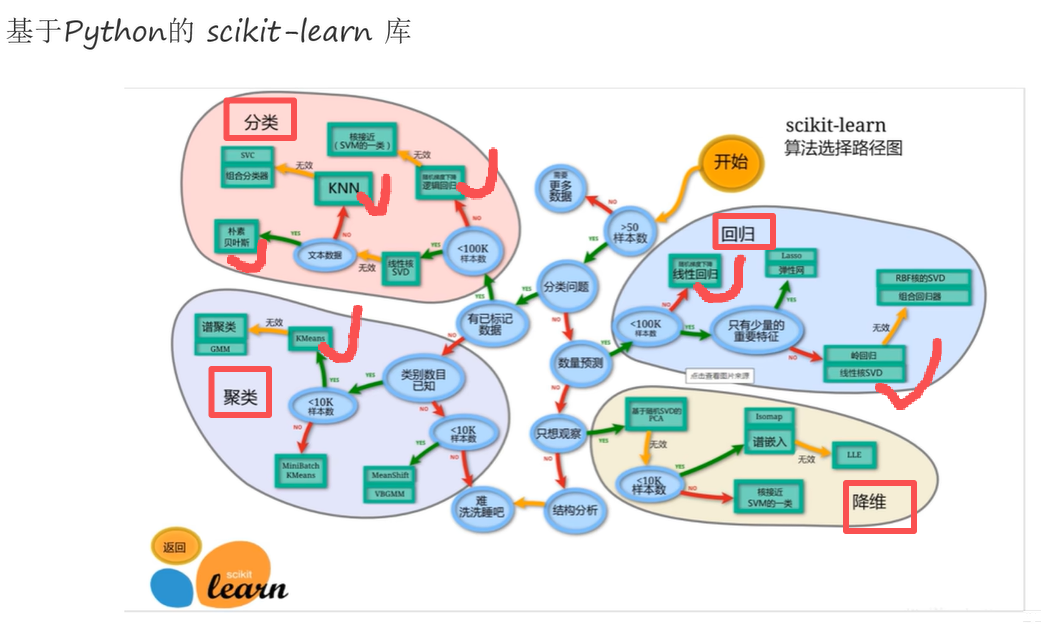
(图示 :机器学习的算法选择路径:主要三大类(图中4块):分类、回归、聚类、降维一般适用于数据较多的情况,用的少;
开始 ➡ 样本数>50(判断):
1️⃣ ❌ 若<=50则需要找更多数据,因为数据决定模型的上限;
2️⃣ ✅ 当数据集>50时 ➡ 分类问题(判断):
1️⃣ ✅ 是分类问题:➡ 如果有已标记的数据(即有标签):
➡ 样本数<100k(1k=1000)=-=》分类算法;
➡ 有类别类的 ==》走聚类算法;
2️⃣ ❌ 不是分类问题:➡ 是否是做 数量预测
➡ 是数据预测, 样本数<100k =-=》回归算法;
➡ 不是数量预测,只想观察 =-=》降维算法;)