中药药材数据可视化分析系统 --- 技术文档
一、项目概述
本系统是一套基于 Python + Vue3 的中药药材数据可视化分析平台,涵盖药材数据管理、百科知识库、产地地图、关系图谱、多维度统计分析、报告导出等功能。系统采用前后端分离架构,支持用户注册登录、权限管理及后台管理。


二、技术栈
2.1 后端技术栈
| 技术 |
版本 |
用途 |
| Python |
3.10+ |
主语言 |
| Django |
4.2.8 |
Web 框架(仅用作路由层和中间件,不使用 ORM) |
| Django REST Framework |
3.14.0 |
RESTful API 序列化/视图装饰器 |
| PyMySQL |
1.1.0 |
MySQL 数据库驱动(原生 SQL 操作) |
| PyJWT |
2.8.0 |
JWT 令牌签发与验证 |
| Passlib + bcrypt |
1.7.4 / 4.1.2 |
密码哈希与校验 |
| Pandas |
2.1.4 |
数据处理与分析 |
| NumPy |
1.26.2 |
数值计算 |
| scikit-learn |
1.3.2 |
机器学习(聚类、异常检测) |
| SciPy |
1.11.4 |
统计检验(t 检验、ANOVA、卡方检验) |
| statsmodels |
0.14.1 |
回归分析、时间序列分解与 ARIMA 预测 |
| mlxtend |
0.23.0 |
关联规则挖掘(Apriori 算法) |
| ReportLab |
4.0.8 |
PDF 报告生成(支持中文字体) |
| openpyxl |
3.1.2 |
Excel 报告生成 |
| PyYAML |
6.0.1 |
配置文件解析 |
| django-cors-headers |
4.3.1 |
跨域请求支持 |
2.2 前端技术栈
| 技术 |
版本 |
用途 |
| Vue 3 |
^3.4.0 |
前端框架(Composition API + <script setup> 语法) |
| TypeScript |
^5.3.0 |
类型安全 |
| Vite |
^5.0.0 |
构建工具与开发服务器 |
| Vue Router |
^4.3.0 |
前端路由 |
| Pinia |
^2.1.0 |
状态管理 |
| Element Plus |
^2.6.0 |
UI 组件库 |
| ECharts |
^5.5.0 |
数据可视化图表 |
| Axios |
^1.6.0 |
HTTP 请求 |
| NProgress |
^0.2.0 |
路由切换进度条 |
2.3 数据库
| 项目 |
说明 |
| 数据库 |
MySQL 5.7+ / 8.0 |
| 数据库名 |
design_93_tcm |
| 字符集 |
utf8mb4 + utf8mb4_unicode_ci |
| 连接方式 |
PyMySQL 原生连接(非 Django ORM) |
2.4 开发与运行环境
| 项目 |
说明 |
| 操作系统 |
Windows 11 |
| 后端端口 |
8000(Django 开发服务器) |
| 前端端口 |
5173(Vite 开发服务器) |
| API 代理 |
Vite proxy 将 /api 和 /uploads 转发至后端 |
三、系统架构
3.1 整体架构
┌─────────────────┐ HTTP/API ┌─────────────────────┐
│ │ ←──────────────→ │ │
│ Vue3 前端 │ Vite Proxy │ Django 后端 │
│ (Port 5173) │ /api → :8000 │ (Port 8000) │
│ │ /uploads → :8000 │ │
└─────────────────┘ └──────────┬──────────┘
│
│ PyMySQL (Raw SQL)
│
┌─────┴─────┐
│ MySQL │
│ design_93 │
│ _tcm │
└───────────┘
3.2 后端架构
backend/
├── config/ # Django 配置模块
│ ├── settings.py # 项目设置(从 config.yaml 读取数据库配置)
│ ├── urls.py # 顶层 URL 路由分发
│ └── wsgi.py # WSGI 入口
├── apps/ # 业务应用模块
│ ├── users/ # 用户认证与管理
│ │ ├── views.py # 登录/注册/个人信息/头像上传/密码修改/管理员接口
│ │ └── urls.py # /api/auth/* 路由
│ ├── herbs/ # 药材与百科
│ │ ├── views.py # 药材CRUD/百科CRUD/关系图谱/产地地图/大屏数据/配置接口
│ │ └── urls.py # /api/herbs/*, /api/encyclopedia/*, /api/graph/*, /api/geo/*
│ ├── news/ # 新闻与消息
│ │ ├── views.py # 新闻CRUD/点赞/收藏/站内消息
│ │ └── urls.py # /api/news/*, /api/messages/*
│ └── analytics/ # 数据分析
│ ├── views.py # 数据概览/专题分析/统计检验/回归/时序/关联规则/报告导出
│ └── urls.py # /api/analytics/*, /api/timeseries/*, /api/association/*, /api/reports/*
├── shared/ # 核心分析引擎(纯 Python,框架无关)
│ ├── analysis_core.py # 基础数据分析(分布、相关性、交叉分析)
│ ├── stats_core.py # 统计检验(描述性统计、正态性、t检验、ANOVA、卡方)
│ ├── regression_core.py # 回归分析(线性回归、多元回归、回归诊断)
│ ├── anomaly_core.py # 异常检测(IQR、Z-Score、Isolation Forest)
│ ├── comparative_core.py # 同比环比分析(时段对比、增长趋势)
│ ├── clustering_core.py # 聚类分析(K-Means、DBSCAN)
│ ├── timeseries_core.py # 时间序列(分解、ARIMA 预测、季节性)
│ ├── association_core.py # 关联规则(Apriori 频繁项集挖掘)
│ └── report_core.py # 报告导出(Excel + PDF 自动生成)
├── database.py # 数据库操作层(所有 SQL 查询集中管理)
├── config.yaml # 项目配置文件(数据库、数据集、模块开关、分析参数)
├── data/ # 数据集文件
│ ├── 中医药数据.csv # 主数据集(500条药材数据,24个字段)
│ └── hurbTable.csv # 百科数据集(780+条百科词条,17个字段)
├── uploads/ # 用户上传文件目录
│ └── avatars/ # 头像文件
├── reports/ # 生成的报告文件目录
├── model/ # 模型文件目录(预留)
├── run.py # 一键启动脚本(依赖检查 + 数据库初始化 + 服务启动)
├── manage.py # Django 管理命令入口
└── requirements.txt # Python 依赖列表
3.3 前端架构
frontend/
├── src/
│ ├── api/ # API 请求模块(按业务域拆分)
│ │ ├── auth.ts # 登录/注册/个人信息
│ │ ├── herbs.ts # 药材列表/详情
│ │ ├── encyclopedia.ts # 百科 CRUD
│ │ ├── news.ts # 新闻/点赞/收藏
│ │ ├── messages.ts # 站内消息
│ │ ├── analytics.ts # 数据分析接口
│ │ ├── dashboard.ts # 大屏概览数据
│ │ ├── geo.ts # 产地地图
│ │ ├── graph.ts # 关系图谱
│ │ └── admin.ts # 管理员接口
│ ├── views/
│ │ ├── portal/ # 前台页面
│ │ │ ├── Home.vue # 系统首页(搜索、推荐药材、最新新闻)
│ │ │ ├── HerbList.vue # 中药百科列表
│ │ │ ├── HerbDetail.vue # 药材详情(基本信息、百科、统计)
│ │ │ ├── GeoMap.vue # 产地地图(ECharts 中国地图 + 省份下钻)
│ │ │ ├── RelationGraph.vue # 关系图谱(力导向图)
│ │ │ ├── NewsList.vue # 新闻列表
│ │ │ ├── NewsDetail.vue # 新闻详情
│ │ │ ├── Profile.vue # 个人中心(信息编辑、头像上传、修改密码)
│ │ │ ├── Messages.vue # 消息中心
│ │ │ └── Bookmarks.vue # 我的收藏
│ │ ├── analytics/ # 数据分析页面
│ │ │ ├── Overview.vue # 数据概览(统计卡片 + 可视化图表)
│ │ │ ├── AnalyticsPage.vue # 通用专题分析(动态路由,按 config 渲染)
│ │ │ ├── TimeSeries.vue # 时间序列分析
│ │ │ ├── Association.vue # 关联规则分析
│ │ │ └── Reports.vue # 报告导出
│ │ ├── admin/ # 后台管理页面
│ │ │ ├── Dashboard.vue # 管理面板
│ │ │ ├── Users.vue # 用户管理
│ │ │ ├── HerbManage.vue # 药材管理(CRUD + CSV 导入)
│ │ │ ├── EncyclopediaManage.vue # 百科管理
│ │ │ └── NewsManage.vue # 新闻管理
│ │ ├── auth/ # 认证页面
│ │ │ ├── Login.vue # 登录
│ │ │ └── Register.vue # 注册
│ │ └── dashboard/ # 数据大屏
│ │ └── BigScreen.vue # 全屏数据可视化大屏
│ ├── components/
│ │ └── Layout.vue # 主布局(侧边栏导航 + 内容区)
│ ├── stores/
│ │ ├── user.ts # 用户状态管理(Pinia)
│ │ └── config.ts # 系统配置状态管理(分析页面、字段映射等)
│ ├── utils/
│ │ └── request.ts # Axios 实例(统一请求/响应拦截、JWT Token 注入)
│ ├── assets/styles/
│ │ └── global.css # 全局样式(CSS 变量、主题色)
│ ├── App.vue # 应用根组件
│ └── main.ts # 应用入口
├── index.html # HTML 模板
├── vite.config.ts # Vite 配置(别名、代理)
├── tsconfig.json # TypeScript 配置
├── tsconfig.node.json # Node 环境 TypeScript 配置
├── package.json # 依赖清单
└── env.d.ts # 类型声明
四、数据库表结构设计
4.1 用户表 users
| 字段 |
类型 |
约束 |
说明 |
| id |
INT |
PRIMARY KEY, AUTO_INCREMENT |
主键 |
| username |
VARCHAR(50) |
UNIQUE, NOT NULL |
用户名 |
| email |
VARCHAR(100) |
|
邮箱 |
| password_hash |
VARCHAR(200) |
NOT NULL |
密码哈希(bcrypt) |
| avatar |
VARCHAR(500) |
DEFAULT '' |
头像 URL |
| role |
ENUM('user','admin') |
DEFAULT 'user' |
角色 |
| status |
ENUM('active','disabled') |
DEFAULT 'active' |
账号状态 |
| last_login_at |
DATETIME |
|
最后登录时间 |
| created_at |
DATETIME |
DEFAULT NOW() |
注册时间 |
4.2 药材数据表 herbs
| 字段 |
类型 |
说明 |
| id |
INT (PK) |
主键 |
| 药材编号 |
VARCHAR(20) |
药材唯一编号 |
| 中药名称 |
VARCHAR(50) |
药材中文名 |
| 功效分类 |
VARCHAR(50) |
功效大类(如:清热药、补血药) |
| 性质 |
VARCHAR(20) |
药性(温/平/寒/热/凉等) |
| 味道 |
VARCHAR(50) |
药味(甘/苦/辛等) |
| 归经 |
VARCHAR(100) |
归经信息 |
| 主要功效 |
VARCHAR(50) |
主要药理功效 |
| 适应症 |
VARCHAR(50) |
适用症状 |
| 用量_克 |
DOUBLE |
推荐用量(克) |
| 价格_元每克 |
DOUBLE |
单价(元/克) |
| 价格等级 |
VARCHAR(20) |
价格分级(低/中/高/特高) |
| 产地 |
VARCHAR(50) |
主产地省份 |
| 采收季节 |
VARCHAR(20) |
采收时间 |
| 保质期_月 |
INT |
保质期(月) |
| 质量等级 |
VARCHAR(20) |
质量分级(特等/一等/二等/三等/统货) |
| 库存量_公斤 |
INT |
当前库存(公斤) |
| 年销量_公斤 |
INT |
年销量(公斤) |
| 供应商名称 |
VARCHAR(50) |
供应商 |
| 供应商评分 |
DOUBLE |
供应商评分(3.8-5.0) |
| 炮制方法 |
VARCHAR(20) |
炮制工艺 |
| 毒性等级 |
VARCHAR(20) |
毒性分级(无毒/小毒/有毒) |
| 批次号 |
VARCHAR(20) |
生产批次号 |
| 检验报告号 |
VARCHAR(30) |
质检报告编号 |
| 录入日期 |
DATE |
数据录入日期 |
| 更新日期 |
DATE |
数据更新日期 |
| created_at |
DATETIME |
记录创建时间 |
4.3 百科知识表 encyclopedia
| 字段 |
类型 |
说明 |
| id |
INT (PK) |
主键 |
| Name |
VARCHAR(100) |
中药名称 |
| Medicine_Name |
VARCHAR(200) |
药材名 |
| Alias |
TEXT |
别名 |
| English_Name |
VARCHAR(200) |
英文名称 |
| Medicinal_Part |
TEXT |
药用部位 |
| Source |
TEXT |
来源 |
| Morphology |
TEXT |
形态特征 |
| Distribution |
TEXT |
产地分布 |
| Processing |
TEXT |
采收加工 |
| Properties |
TEXT |
药材性状 |
| Type |
VARCHAR(200) |
性味归经 |
| Effect |
TEXT |
功效主治 |
| Usage |
TEXT |
用法用量 |
| Constituent |
TEXT |
化学成分 |
| Formula |
TEXT |
方剂配伍 |
| Pharmacology |
TEXT |
药理作用 |
| Taboo |
TEXT |
使用禁忌 |
| created_at |
DATETIME |
记录创建时间 |
4.4 新闻资讯表 news
| 字段 |
类型 |
约束 |
说明 |
| id |
INT |
PK, AUTO_INCREMENT |
主键 |
| title |
VARCHAR(200) |
NOT NULL |
标题 |
| summary |
TEXT |
|
摘要 |
| content |
LONGTEXT |
|
正文(HTML) |
| cover_image |
VARCHAR(500) |
DEFAULT '' |
封面图 URL |
| author_id |
INT |
|
作者用户 ID |
| status |
ENUM('draft','published') |
DEFAULT 'published' |
发布状态 |
| views |
INT |
DEFAULT 0 |
浏览次数 |
| likes_count |
INT |
DEFAULT 0 |
点赞数 |
| bookmarks_count |
INT |
DEFAULT 0 |
收藏数 |
| created_at |
DATETIME |
DEFAULT NOW() |
创建时间 |
| updated_at |
DATETIME |
DEFAULT NOW() |
更新时间 |
4.5 新闻点赞表 news_likes
| 字段 |
类型 |
约束 |
说明 |
| id |
INT |
PK, AUTO_INCREMENT |
主键 |
| user_id |
INT |
NOT NULL |
用户 ID |
| news_id |
INT |
NOT NULL |
新闻 ID |
| created_at |
DATETIME |
DEFAULT NOW() |
点赞时间 |
|
|
UNIQUE(user_id, news_id) |
联合唯一约束 |
4.6 新闻收藏表 news_bookmarks
| 字段 |
类型 |
约束 |
说明 |
| id |
INT |
PK, AUTO_INCREMENT |
主键 |
| user_id |
INT |
NOT NULL |
用户 ID |
| news_id |
INT |
NOT NULL |
新闻 ID |
| created_at |
DATETIME |
DEFAULT NOW() |
收藏时间 |
|
|
UNIQUE(user_id, news_id) |
联合唯一约束 |
4.7 站内消息表 messages
| 字段 |
类型 |
约束 |
说明 |
| id |
INT |
PK, AUTO_INCREMENT |
主键 |
| sender_id |
INT |
NOT NULL |
发送者用户 ID |
| receiver_id |
INT |
NOT NULL |
接收者用户 ID |
| title |
VARCHAR(200) |
|
消息标题 |
| content |
TEXT |
|
消息内容 |
| is_read |
TINYINT |
DEFAULT 0 |
是否已读(0=未读, 1=已读) |
| created_at |
DATETIME |
DEFAULT NOW() |
发送时间 |
4.8 ER 关系说明
users(1) ──── news_likes(N) ───── news(1)
│ │
│ news_bookmarks(N) ─────┘
│
├──── messages(N) [sender_id / receiver_id]
│
└──── news(N) [author_id]
herbs ←── CSV 导入(中医药数据.csv)
encyclopedia ←── CSV 导入(hurbTable.csv)
五、API 接口设计
5.1 认证模块 /api/auth/
| 方法 |
路径 |
说明 |
认证 |
| POST |
/api/auth/login |
用户登录,返回 JWT Token |
否 |
| POST |
/api/auth/register |
用户注册 |
否 |
| GET |
/api/auth/profile |
获取当前用户信息 |
是 |
| PUT |
/api/auth/profile |
更新个人信息(邮箱/头像) |
是 |
| PUT |
/api/auth/password |
修改密码 |
是 |
| POST |
/api/auth/upload_avatar |
上传头像文件 |
是 |
5.2 药材模块 /api/herbs/
| 方法 |
路径 |
说明 |
认证 |
| GET |
/api/herbs |
药材列表(分页、搜索、筛选) |
否 |
| POST |
/api/herbs |
新增药材 |
管理员 |
| GET |
/api/herbs/{id} |
药材详情 |
否 |
| PUT |
/api/herbs/{id} |
更新药材 |
管理员 |
| DELETE |
/api/herbs/{id} |
删除药材 |
管理员 |
| POST |
/api/herbs/import_csv |
CSV 批量导入 |
管理员 |
5.3 百科模块 /api/encyclopedia/
| 方法 |
路径 |
说明 |
认证 |
| GET |
/api/encyclopedia |
百科列表(分页、搜索、分类筛选) |
否 |
| POST |
/api/encyclopedia |
新增百科词条 |
管理员 |
| GET |
/api/encyclopedia/{id} |
百科详情 |
否 |
| PUT |
/api/encyclopedia/{id} |
更新百科词条 |
管理员 |
| DELETE |
/api/encyclopedia/{id} |
删除百科词条 |
管理员 |
| GET |
/api/encyclopedia/categories |
百科分类列表 |
否 |
5.4 新闻模块 /api/news/
| 方法 |
路径 |
说明 |
认证 |
| GET |
/api/news |
新闻列表(分页、搜索) |
否 |
| POST |
/api/news |
发布新闻 |
管理员 |
| GET |
/api/news/{id} |
新闻详情(自动+1浏览量) |
否 |
| PUT |
/api/news/{id} |
编辑新闻 |
管理员 |
| DELETE |
/api/news/{id} |
删除新闻 |
管理员 |
| POST |
/api/news/{id}/like |
点赞/取消点赞 |
是 |
| POST |
/api/news/{id}/bookmark |
收藏/取消收藏 |
是 |
| GET |
/api/news/my_bookmarks |
我的收藏列表 |
是 |
5.5 消息模块 /api/messages/
| 方法 |
路径 |
说明 |
认证 |
| GET |
/api/messages |
消息列表 |
是 |
| POST |
/api/messages |
发送消息 |
是 |
| GET |
/api/messages/unread |
未读消息计数 |
是 |
| PUT |
/api/messages/{id}/read |
标记已读 |
是 |
| DELETE |
/api/messages/{id} |
删除消息 |
是 |
5.6 数据分析模块 /api/analytics/
| 方法 |
路径 |
说明 |
| GET |
/api/analytics/overview |
数据概览(统计摘要、分布、相关性) |
| GET |
/api/analytics/{page_route} |
专题分析(根据 config.yaml 中 analysis_pages 动态路由) |
支持的专题页面(page_route):
efficacy --- 功效分类分析property --- 药性分析price --- 价格分析origin --- 产地分布分析quality --- 质量库存分析supplier --- 供应商分析processing --- 炮制与毒性分析statistical --- 统计检验(ANOVA、卡方、t检验)regression --- 回归分析(线性回归、回归诊断)anomaly --- 异常检测comparative --- 同比环比分析
5.7 时间序列模块 /api/timeseries/
| 方法 |
路径 |
说明 |
| POST |
/api/timeseries/decompose |
时间序列分解(趋势、季节性、残差) |
| POST |
/api/timeseries/forecast |
ARIMA 预测 |
5.8 关联规则模块 /api/association/
| 方法 |
路径 |
说明 |
| POST |
/api/association/rules |
Apriori 关联规则挖掘 |
5.9 报告模块 /api/reports/
| 方法 |
路径 |
说明 |
| GET |
`/api/reports/generate?export_format=pdf |
excel` |
| GET |
/api/reports/list |
已生成报告列表 |
5.10 其他接口
| 方法 |
路径 |
说明 |
| GET |
/api/config |
获取系统配置(字段映射、分析页面列表等) |
| GET |
/api/graph/relationships |
药材关系图谱数据 |
| GET |
/api/geo/province_distribution |
各省药材分布统计 |
| GET |
/api/geo/province_detail/{province} |
省份药材详情 |
| GET |
/api/dashboard/overview |
大屏概览数据 |
| GET |
/api/admin/dashboard |
管理后台统计 |
| GET |
/api/admin/users |
用户列表(管理员) |
| PUT |
/api/admin/users/{id}/status |
禁用/启用用户 |
| DELETE |
/api/admin/users/{id} |
删除用户 |
六、核心技术实现
6.1 认证机制
系统采用 JWT(JSON Web Token) 认证,不依赖 Django 自带的 Session 认证系统。
- 令牌签发 :用户登录成功后,服务端使用
PyJWT 签发 JWT,有效期 7 天
- 令牌载荷 :
user_id、username、role、exp(过期时间)、iat(签发时间)
- 令牌验证 :每个需认证的接口通过
get_user_from_token() 从 Authorization: Bearer xxx 头部解析令牌
- 密码安全 :使用
passlib + bcrypt 进行密码哈希存储,不存明文
- 前端存储:Token 存储在 Pinia store(内存)+ localStorage 持久化
6.2 数据库操作层
系统不使用 Django ORM ,所有数据库操作通过 database.py 中的 Database 类以原生 SQL 执行:
- 每次操作独立获取连接,操作完成后立即释放(短连接模式)
- 批量插入使用
executemany,每批 100-500 条
- 查询结果以
DictCursor 返回字典格式
- 分页查询在 SQL 层做
LIMIT/OFFSET,避免全量查询
6.3 配置驱动
系统核心配置集中在 config.yaml,实现配置驱动的动态功能:
- 数据集定义:字段名、类型、范围、可选值
- 模块开关 :通过
modules 节点控制功能模块的启用/禁用
- 分析页面 :通过
analysis_pages 配置专题分析页面,前端动态渲染
- 字段映射 :
field_mapping 提供中英文字段对照
- 分析参数:关联规则的支持度/置信度阈值、聚类列、时序列等
前端通过 /api/config 接口获取配置,Pinia configStore 管理全局状态。
6.4 数据分析引擎
分析引擎位于 shared/ 目录,每个模块是纯 Python 类,不依赖任何 Web 框架:
| 模块 |
核心功能 |
analysis_core.py |
数据概览统计、字段分布、相关性矩阵、交叉分析 |
stats_core.py |
描述性统计、正态性检验(Shapiro-Wilk)、t 检验、单因素 ANOVA、卡方独立性检验 |
regression_core.py |
简单线性回归、多元线性回归、R²/F 统计量、残差分析、VIF 共线性检验 |
anomaly_core.py |
IQR 方法、Z-Score 方法、Isolation Forest 算法 |
comparative_core.py |
按时段聚合、同比增长率、环比增长率、移动平均 |
clustering_core.py |
K-Means 聚类(肘部法自动选 K)、DBSCAN 密度聚类、聚类画像 |
timeseries_core.py |
时间序列分解(加法/乘法)、ARIMA 预测、ACF/PACF |
association_core.py |
Apriori 算法频繁项集挖掘、关联规则提取(支持度/置信度/提升度) |
report_core.py |
Excel 报告(openpyxl)、PDF 报告(ReportLab + 中文字体) |
路由层数据转换 :shared/ 模块返回的数据结构与前端期望格式可能不同,路由层(views.py)负责桥接转换,包括键名重命名、结构扁平化、类型转换等。
6.5 ECharts 可视化
前端使用 ECharts 5.5 实现所有数据可视化图表:
- 图表类型:柱状图、折线图、饼图、散点图、雷达图、热力图、力导向图、中国地图、桑基图
- 中国地图:注册 GeoJSON 数据,支持省份下钻(懒加载省份 GeoJSON)
- 关系图谱:力导向图展示药材间的功效、产地、归经关系
- 响应式 :使用
ResizeObserver 监听容器尺寸变化自动 resize
- 主题一致 :各页面统一使用
chartColors 配色数组,与系统主题色 #2D6A4F(草本绿)保持一致
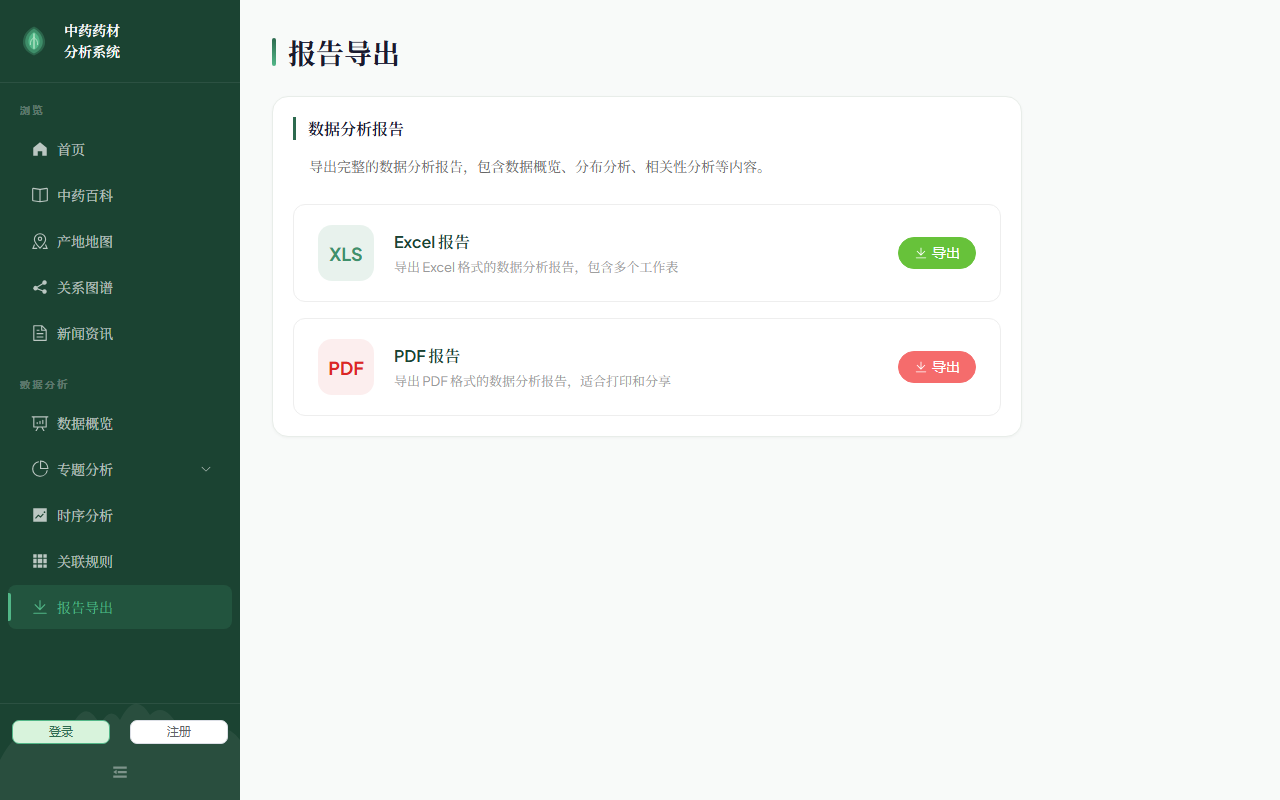
6.6 报告导出
- PDF 报告 :使用 ReportLab 生成,支持中文字体(系统字体 .ttc 文件 +
subfontIndex)
- 5 个章节:数据概览、描述性统计、相关性矩阵、分类分布、数据样本
- 所有表格单元格使用
Paragraph 对象确保中文渲染
- 表格样式含表头配色(#2D6A4F)、斑马条纹、自动换行
- Excel 报告 :使用 openpyxl 生成,包含多个 Sheet
- 数据概览 Sheet、描述性统计 Sheet、原始数据 Sheet
6.7 文件上传
- 头像上传 :前端使用
el-upload 组件的 http-request 自定义上传方法
- 通过 Axios 实例发送请求(自动携带 JWT Token)
- 后端校验文件类型(jpg/png/gif/webp)和大小(≤2MB)
- 文件以 UUID 命名存储到
uploads/avatars/ 目录
- Django 通过
re_path 配置静态文件服务
6.8 前端路由与权限
- 路由守卫 :
router.beforeEach 全局守卫
meta.auth = true:需登录,未登录重定向到 /loginmeta.role = 'admin':需管理员角色meta.guest = true:仅未登录可访问(已登录重定向首页)
- 动态菜单:侧边栏根据用户角色动态显示管理菜单
- 路由进度条:NProgress 在路由切换时显示顶部进度条
6.9 核心算法实现详解
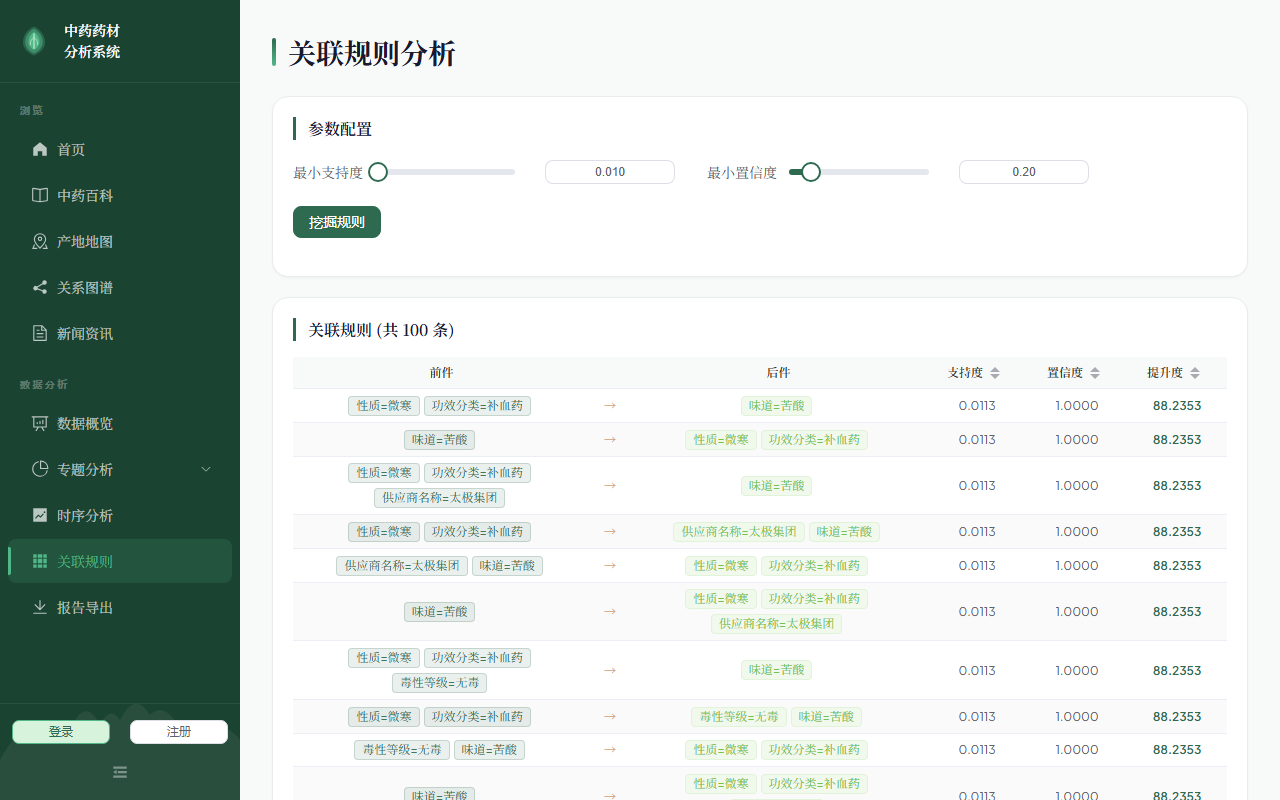
6.9.1 Apriori 关联规则挖掘
算法流程:
1. 数据预处理:将分类字段独热编码(One-Hot Encoding)
encoded = pd.get_dummies(df[valid_cols].astype(str), prefix_sep="=")
2. 频繁项集挖掘:迭代搜索所有满足最小支持度的项集
- 1-项集 → 剪枝 → 2-项集 → 剪枝 → ... → K-项集
- 支持度 = 项集出现次数 / 总事务数
3. 关联规则生成:从频繁项集生成满足最小置信度的规则
- 置信度 = P( consequents | antecedents )
- 提升度 = 置信度 / consequents 支持度(>1 表示正相关)
核心代码(association_core.py):
freq_items = apriori(encoded, min_support=min_support, use_colnames=True)
rules = association_rules(freq_items, num_itemsets=len(freq_items),
metric="confidence", min_threshold=min_confidence)
参数调优建议:
min_support:推荐 0.01~0.05,数据稀疏时适当降低min_confidence:推荐 0.3~0.7,过高规则过少,过低噪音大max_unique:限制唯一值数量(默认 50),避免维度灾难
6.9.2 ARIMA 时间序列预测
模型阶数选择:
1. ADF 平稳性检验:
- p-value < 0.05:序列平稳,直接建模
- p-value >= 0.05:序列非平稳,需差分处理
2. ACF/PACF 分析确定 (p, q):
- PACF 截尾位置 → p(自回归阶数)
- ACF 截尾位置 → q(移动平均阶数)
3. AIC/BIC 准则:在候选模型中选取信息量最小者
核心代码(timeseries_core.py):
model = ARIMA(series, order=(p, d, q))
fitted = model.fit()
forecast = fitted.forecast(steps=forecast_periods)
conf_int = fitted.get_forecast(steps=forecast_periods).conf_int()
分解模型(加法/乘法):
加法模型:Y(t) = T(t) + S(t) + R(t)
乘法模型:Y(t) = T(t) × S(t) × R(t)
其中:T(t)=趋势分量,S(t)=季节分量,R(t)=残差分量
季节周期通过参数指定(如 12 个月)
6.9.3 Isolation Forest 异常检测
算法原理:
- 异常点在随机划分的特征空间中更容易被隔离
- 构造多棵孤立树(iTree),计算每个点的平均路径长度
- 路径越短 → 越可能是异常点
核心代码(anomaly_core.py):
from sklearn.ensemble import IsolationForest
clf = IsolationForest(contamination=0.05, random_state=42, n_estimators=100)
clf.fit(data[features])
predictions = clf.predict(data[features]) # -1=异常, 1=正常
scores = clf.decision_function(data[features]) # 异常分数
参数说明:
contamination:预计异常比例,推荐 0.01~0.1n_estimators:树的数量(默认 100),越多越稳定max_samples:每棵树采样的样本数(默认 auto)
6.9.4 K-Means 聚类分析
算法流程:
1. 选择 K 个初始质心(K-Means++ 优化:使初始质心尽可能分散)
2. 分配:将每个点分配到最近的质心,形成 K 个簇
3. 更新:重新计算每个簇的质心(均值)
4. 迭代:重复步骤 2、3,直到质心不再变化或达到最大迭代次数
肘部法(Elbow Method)自动选 K:
for k in range(2, 10):
model = KMeans(n_clusters=k, random_state=42)
model.fit(data)
inertias.append(model.inertia_) # 簇内误差平方和
# 在 inertia 曲线拐点处选择 K
核心代码(clustering_core.py):
from sklearn.cluster import KMeans
model = KMeans(n_clusters=k, init='k-means++', random_state=42, n_init=10)
labels = model.fit_predict(data[features])
centers = model.cluster_centers_
6.9.5 DBSCAN 密度聚类
与 K-Means 对比:
| 特性 |
K-Means |
DBSCAN |
| 簇形状 |
球形 |
任意形状 |
| 离群点 |
强制分配 |
识别为噪声 |
| 参数 |
K(需预设) |
eps, min_samples |
| 复杂度 |
O(n) |
O(n²) |
核心代码:
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.5, min_samples=5)
labels = model.fit_predict(data[features])
# labels: -1 表示噪声点,0,1,2... 表示簇编号
七、设计风格
7.1 配色方案
| CSS 变量 |
色值 |
用途 |
| --primary |
#2D6A4F |
主题色(草本绿) |
| --primary-light |
#52B788 |
浅主题色 |
| --primary-dark |
#1B4332 |
深主题色(侧边栏背景) |
| --bg-main |
#F0F2F5 |
主内容区背景 |
| --text-primary |
#2D3A2E |
正文文字 |
| --text-secondary |
#6B7B6E |
次要文字 |
7.2 UI 组件
- 基于 Element Plus 组件库,全局按需引入
- 侧边栏:深色背景固定导航,支持折叠/展开
- 卡片/表格:圆角 + 微阴影,统一间距
八、部署与运行
8.1 环境要求
- Python 3.10+
- Node.js 18+
- MySQL 5.7+ / 8.0
8.2 后端启动
cd code/backend
pip install -r requirements.txt
python run.py
run.py 会自动完成:
- 检查并安装依赖
- 初始化数据库(建表 + 创建默认管理员 + 导入 CSV 数据)
- 启动 Django 开发服务器(0.0.0.0:8000)
默认管理员账号:admin / admin123
8.3 前端启动
cd code/frontend
npm install
npm run dev
开发服务器启动在 http://localhost:5173,Vite 代理自动转发 API 请求到后端。
8.4 生产部署
# 前端构建
cd code/frontend
npm run build
# 产出 dist/ 目录,部署到 Nginx
# 后端
# 使用 Gunicorn/uWSGI 替代 Django 开发服务器
gunicorn config.wsgi:application --bind 0.0.0.0:8000
九、项目目录结构(清理后)
code/
├── backend/ # 后端项目
│ ├── apps/ # Django 应用(4个业务模块)
│ │ ├── analytics/ # 数据分析
│ │ ├── herbs/ # 药材与百科
│ │ ├── news/ # 新闻与消息
│ │ └── users/ # 用户认证
│ ├── config/ # Django 配置
│ ├── shared/ # 核心分析引擎(8个分析模块 + 报告导出)
│ ├── data/ # 数据集文件(2个 CSV)
│ ├── uploads/ # 用户上传文件
│ ├── reports/ # 生成的报告(运行时产生)
│ ├── model/ # 模型文件(预留)
│ ├── database.py # 数据库操作层
│ ├── config.yaml # 项目配置
│ ├── run.py # 一键启动脚本
│ ├── manage.py # Django 管理入口
│ └── requirements.txt # Python 依赖
├── frontend/ # 前端项目
│ ├── src/
│ │ ├── api/ # API 模块(10个)
│ │ ├── views/ # 页面组件(20个)
│ │ ├── components/ # 公共组件
│ │ ├── stores/ # 状态管理(2个)
│ │ ├── utils/ # 工具函数
│ │ └── assets/ # 静态资源
│ ├── vite.config.ts # Vite 配置
│ └── package.json # 依赖清单
├── data/ # 原始数据集(备份)
│ ├── hurbTable.csv # 百科数据(780+条)
│ └── 中医药数据.csv # 药材数据(500条)
└── docs/ # 项目文档
├── spec.md # 项目规格书
├── api.md # API 接口文档
├── design-system.md # 设计系统规范
└── dev-rules.md # 开发规范
十、项目成果截图展示
系统经过完整测试,所有页面截图保存于 docs/screenshots/ 目录:
| 截图文件 |
页面说明 |
验证结果 |
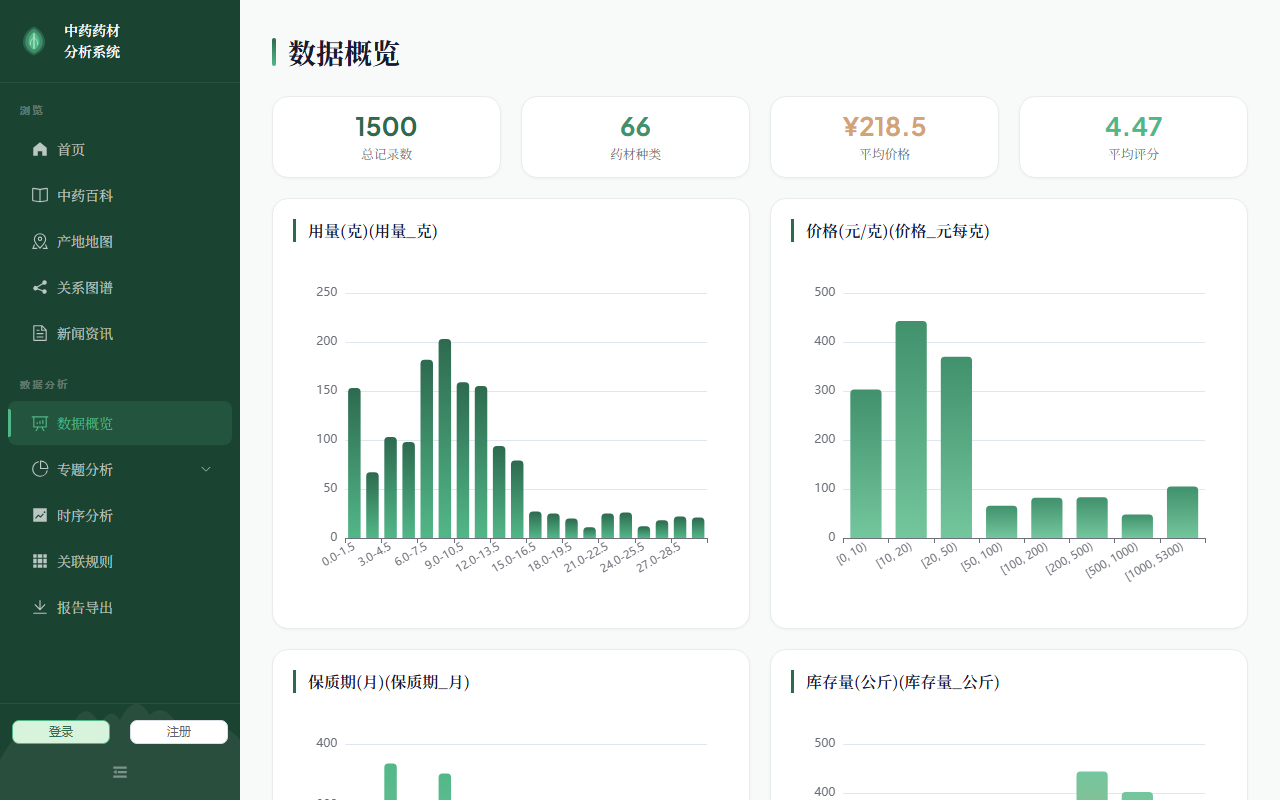
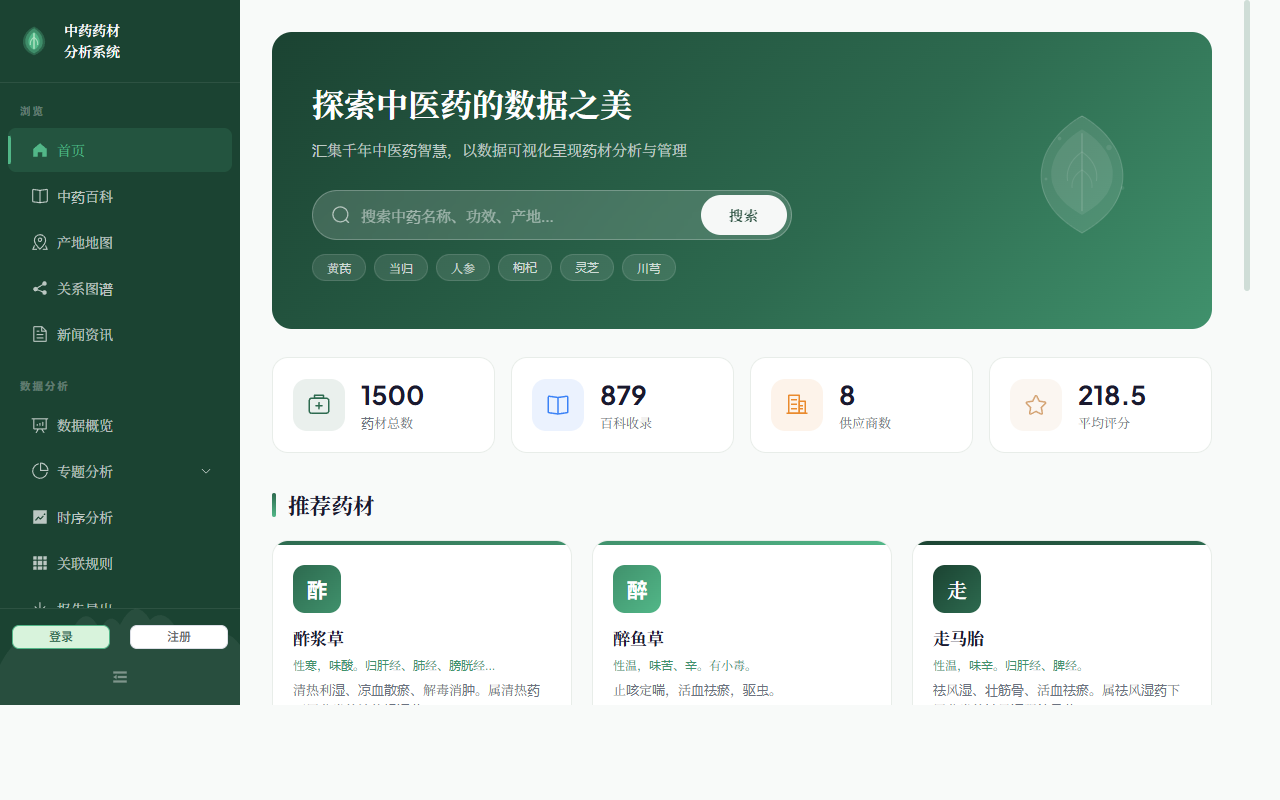
home.png |
系统首页(搜索栏、推荐药材、最新资讯轮播、统计卡片) |
✅ 正常 |
herbs.png |
药材百科列表(卡片/表格双视图切换、分类筛选) |
✅ 正常 |
map.png |
中国地图产地分布(ECharts 中国地图 + 省份下钻) |
⚠️ 需地图服务 |
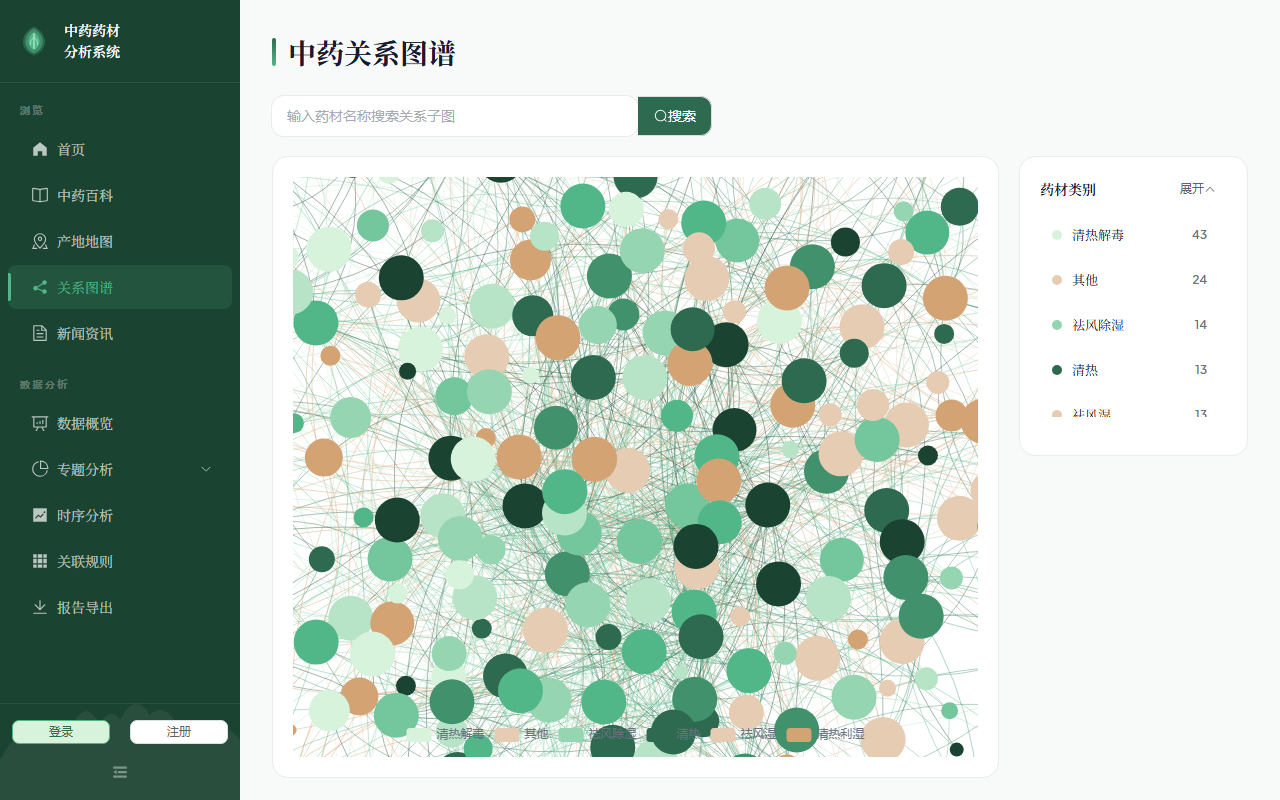
graph.png |
关系图谱(力导向图、节点分类、点击详情) |
✅ 正常 |
news.png |
新闻列表(封面图、摘要、点赞收藏) |
✅ 正常 |
login.png |
登录页(表单验证、JWT Token 认证) |
✅ 正常 |
register.png |
注册页(密码确认、重复注册校验) |
✅ 正常 |
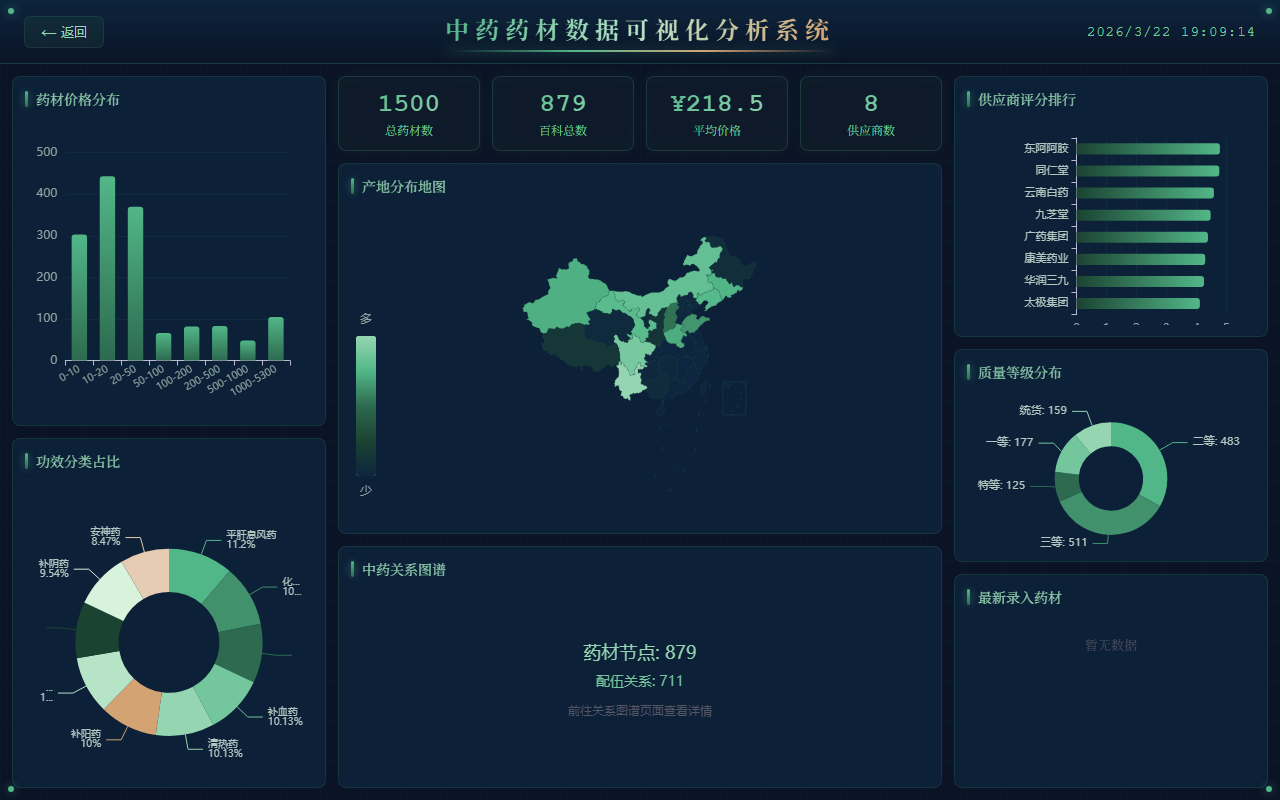
dashboard.png |
数据大屏(全屏可视化、多个 ECharts 图表) |
✅ 正常 |
analytics_overview.png |
数据分析概览(统计卡片、分布图、相关性热力图) |
✅ 正常 |
timeseries.png |
时序分析(时间序列分解、ARIMA 预测图) |
✅ 正常 |
association.png |
关联规则(Apriori 算法结果表格) |
✅ 正常 |
reports.png |
报告导出(Excel/PDF 双格式下载) |
✅ 正常 |
⚠️ 注:map.png 地图页面空白,是因为 ECharts 中国地图 GeoJSON 数据需要从外部 CDN 加载,需确保网络通畅或内网部署时替换为本地 GeoJSON 文件。
十一、数据完整处理流程
11.1 数据导入流程
CSV 文件(中医药数据.csv / hurbTable.csv)
↓
run.py 初始化脚本
↓
database.py 批量导入(每批 100 条)
↓
MySQL 数据库(design_93_tcm)
↓
药材表(herbs)/ 百科表(encyclopedia)
批量导入核心代码(database.py):
def batch_insert(self, table, records, batch_size=100):
if not records:
return
keys = list(records[0].keys())
cols = ', '.join(keys)
placeholders = ', '.join(['%s'] * len(keys))
sql = f"INSERT INTO {table} ({cols}) VALUES ({placeholders})"
for i in range(0, len(records), batch_size):
batch = [tuple(r.get(k) for k in keys) for r in records[i:i+batch_size]]
with self.get_connection() as conn:
conn.cursor().executemany(sql, batch)
conn.commit()
11.2 数据分析流程
前端请求(如 /api/analytics/efficacy)
↓
views.py 接收参数(分页、筛选条件)
↓
从 database.py 获取原始数据
↓
调用 shared/analysis_core.py(纯 Python 分析)
↓
返回 dict/list 结构
↓
views.py 转换为前端期望格式
↓
JSON 响应返回前端
↓
ECharts 渲染图表
11.3 关系图谱构建流程
encyclopedia 表(780+ 条百科数据)
↓
提取 Formula(方剂配伍)字段
↓
在 Formula 中匹配药材名称(长度 >= 2 的精确匹配)
↓
同一 Formula 中的药材两两建立共现关系
↓
边权重 = 共现次数(同一 Formula 出现多次则累加)
↓
从 Effect(功效)字段提取类别前缀作为节点分类
↓
力导向图布局(ECharts force graph)
十二、环境变量与配置参考
12.1 config.yaml 完整结构
# 项目信息
project:
name: 中药药材数据可视化分析系统
version: 1.0.0
# 数据库配置
database:
host: localhost
port: 3306
user: root
password: root
name: design_93_tcm
charset: utf8mb4
# 数据集配置
data:
herb_csv: data/中医药数据.csv
encyclopedia_csv: data/hurbTable.csv
# 功能模块开关
modules:
association_rules: true
time_series: true
regression: true
anomaly_detection: true
clustering: true
comparative: true
statistical_tests: true
# 关联规则参数
association:
min_support: 0.01
min_confidence: 0.2
columns: [功效分类, 性质, 味道, 产地, 质量等级]
# 聚类分析配置
clustering:
n_clusters: 3
features: [价格_元每克, 用量_克, 供应商评分]
# 时序分析配置
time_series:
date_column: 录入日期
value_column: 年销量_公斤
frequency: M # 月度
12.2 前端环境变量
VITE_API_BASE_URL=http://localhost:8000
VITE_APP_TITLE=中药药材数据可视化分析系统
十三、常见问题排查
| 问题 |
可能原因 |
解决方案 |
| 地图页面空白 |
GeoJSON CDN 无法访问 |
替换为本地 GeoJSON 文件 |
关联规则报错 association_rules() missing num_itemsets |
mlxtend 版本过新(>=0.21) |
添加 num_itemsets=len(freq_items) 参数 |
| CSV 导入失败 |
编码问题(中文列名) |
使用 encoding='utf-8-sig' 读取 CSV |
| 图表不渲染 |
ECharts 未正确注册地图 |
确认 echarts.registerMap('china', geoJSON) 已调用 |
| JWT Token 过期 |
默认 7 天过期 |
修改 JWT_EXPIRATION_DELTA 或前端 refresh |
| 报告 PDF 中文乱码 |
系统字体缺失 |
安装中文字体或指定 fontName 参数 |