一、一个真实的场景
产品经理跑过来:"帮我查一下上周注册但还没下单的用户,按注册时间倒序,只要手机号和注册渠道。"
你打开数据库,写下一段SQL:

30秒搞定。
但如果问问题的人不会写SQL呢?
-
提工单给数据团队 → 排期3天
-
把数据导出Excel自己筛 → 10万行数据Excel卡死
-
让BI工具做固定报表 → 需求变了又要等
这就是Text-to-SQL要解决的问题:让自然语言直接变成可执行的SQL。
二、Text-to-SQL的技术架构
一个完整的Text-to-SQL系统包含以下核心模块:

2.1 Schema理解:让AI看懂数据库结构
AI需要知道数据库里有什么表、什么字段、什么关系。
输入给AI的信息:
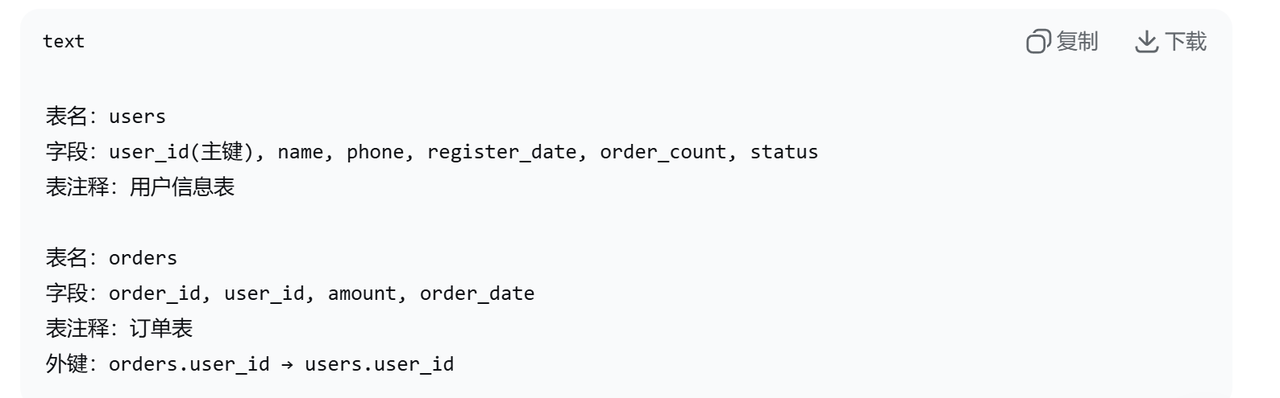
工程要点:
-
字段名和注释要写清楚(
register_datevsreg_dt,AI更喜欢前者) -
大库需要做Schema剪枝,只给相关表,避免上下文过长
-
示例值(如
status='active')能显著提升准确率
2.2 问题解析:理解用户意图
将自然语言拆解为结构化要素:
|------------|----------------------------------------|
| 自然语言要素 | 解析结果 |
| "上周" | 时间范围:2026-04-14 到 2026-04-20 |
| "注册但还没下单" | 条件:register_date在范围内 AND order_count=0 |
| "手机号和注册渠道" | SELECT字段:phone, register_channel |
| "按注册时间倒序" | ORDER BY register_date DESC |
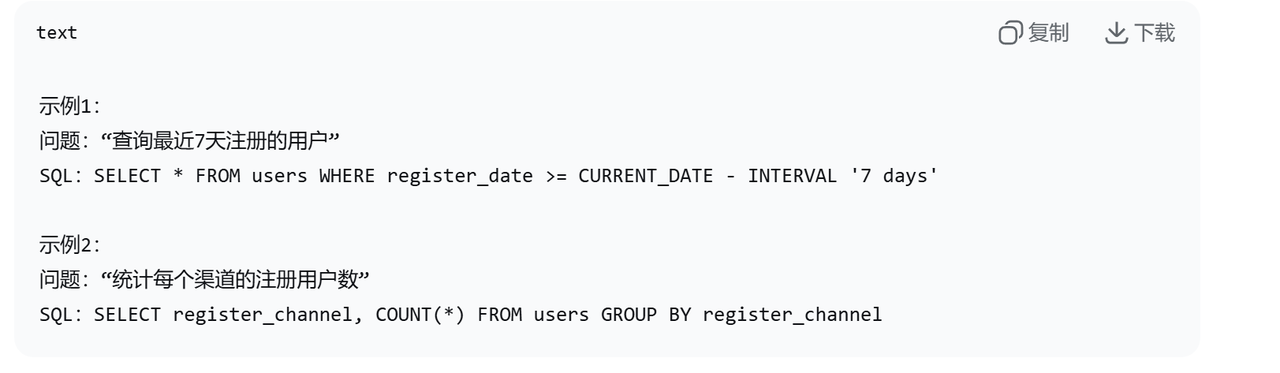
2.3 SQL生成:Prompt设计与Few-shot
基础Prompt模板:

Few-shot示例(关键):
2.4 SQL执行与安全防护
这是企业落地最关键的环节------不能让AI生成的SQL乱跑。
必须做的防护:
|------|---------------------------------|
| 防护层 | 实现方式 |
| 只读限制 | 禁止INSERT/UPDATE/DELETE/DROP等写操作 |
| 行数限制 | 强制加LIMIT,默认最多返回1000行 |
| 超时控制 | 查询超过10秒自动终止 |
| 黑名单词 | 过滤敏感表名、字段名 |
| 人工审核 | 高风险操作走审批流程 |
代码示例( SQL 校验):

三、企业落地的三个核心难点
3.1 难点一:复杂查询的准确率
简单查询(单表、单条件)准确率可以做到90%+,但一旦涉及:
-
多表JOIN
-
子查询
-
聚合函数(GROUP BY + HAVING)
-
时间函数(DATE_TRUNC、EXTRACT)
准确率会大幅下降到60%-70%。
解法:
-
针对高频复杂查询做模板化
-
使用CoT(思维链)让AI分步推理
-
收集badcase持续微调
3.2 难点二:业务口径不一致
业务说"活跃用户",数据库中可能定义为last_login_date > 30天。AI不知道这个口径。
解法:
-
建立业务术语表,映射到具体SQL条件
-
在Prompt中预置常见口径定义
-

3.3 难点三:数据安全与权限
不同部门、不同角色能看的数据不同。销售不能看研发的成本数据。
解法:
-
基于RBAC做行级/列级权限控制
-
在SQL生成阶段就注入权限条件
-
对敏感字段(手机号、身份证)自动脱敏
四、工程实现:完整流程
4.1 系统架构
text
前端\] → \[API网关\] → \[Text-to-SQL服务\] → \[SQL校验\] → \[数据源\] ↓ \[LLM服务
4.2 核心代码(Python示例)
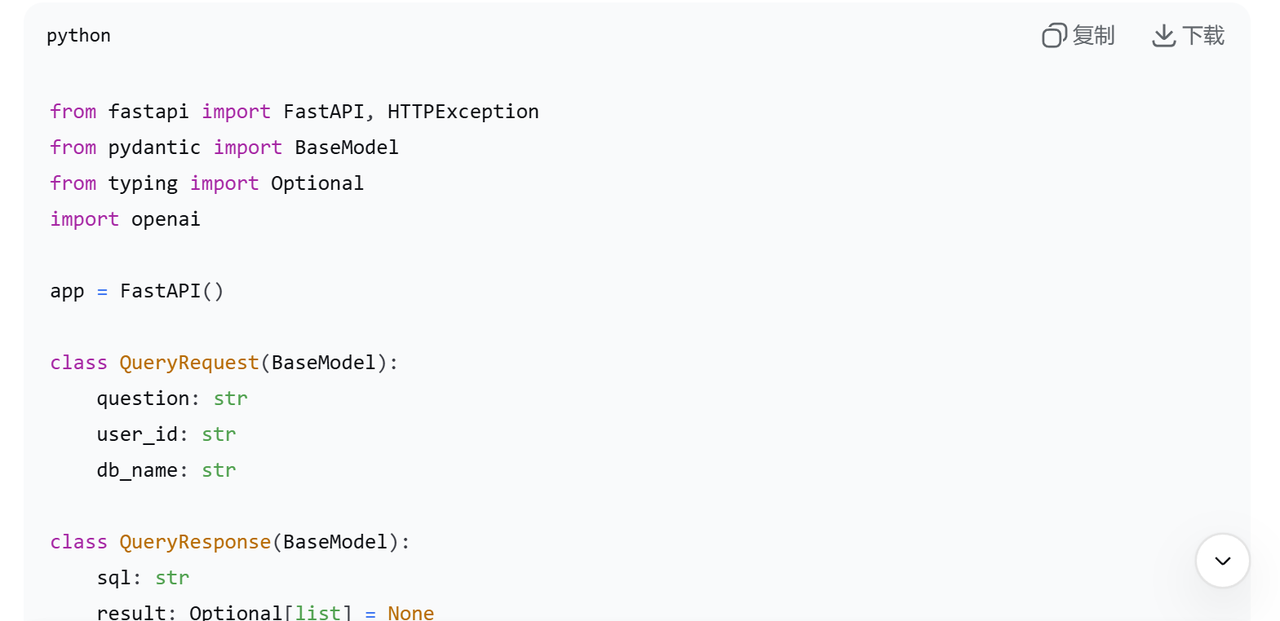
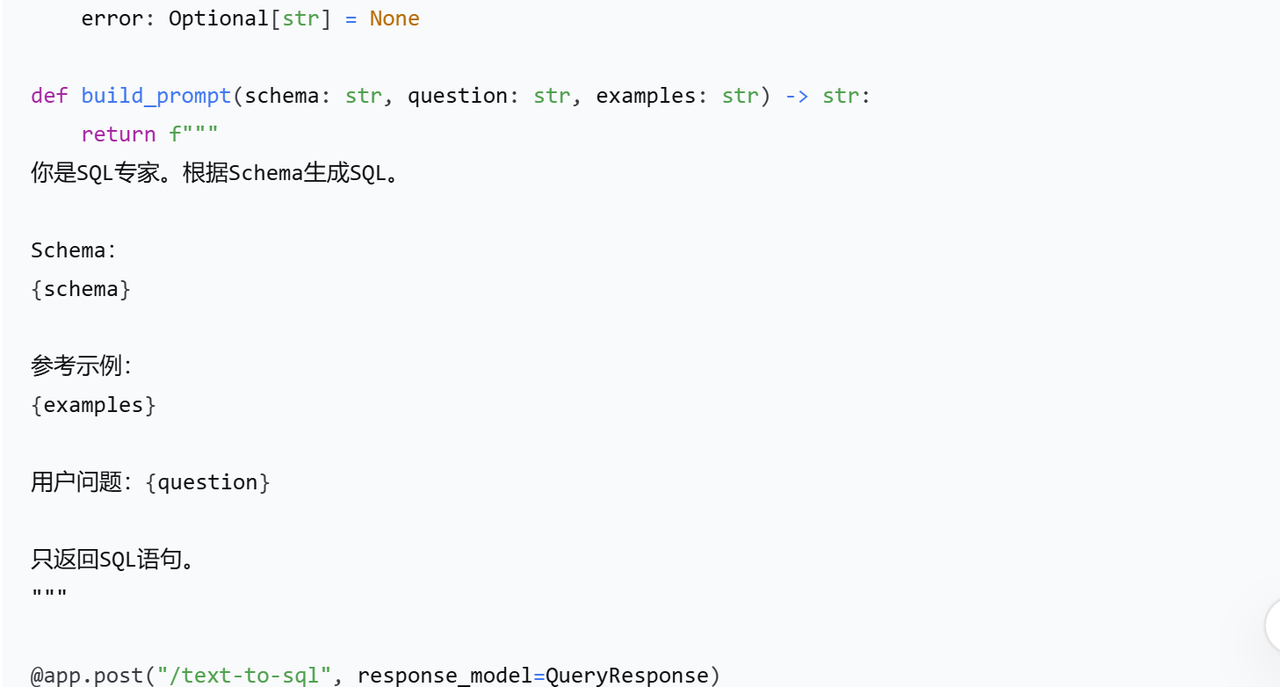


4.3 准确率优化技巧
|------|------------------------------------|------|
| 技巧 | 说明 | 效果提升 |
| 字段别名 | 给字段起业务别名(user_count → 用户数) | 0.1 |
| 示例值 | 给出字段的示例值(status取值:active/inactive) | 0.15 |
| 自纠错 | 执行SQL报错后让AI重新生成 | 0.05 |
| 向量检索 | 从历史正确查询中检索相似问题 | 0.1 |
五、ZGI如何简化Text-to-SQL落地
对于大多数企业来说,从零搭建一套生产级Text-to-SQL系统,需要投入2-3名工程师、2-3个月的时间,还要持续维护。
ZGI平台提供了开箱即用的Text-to-SQL能力:
5.1 自动Schema理解
-
自动连接数据库,读取表结构和字段注释
-
自动生成Schema描述,无需手动编写
-
支持Schema剪枝,只给LLM相关表
5.2 内置优化策略
-
预置高准确率的Prompt模板
-
内置Few-shot示例库,支持自动匹配
-
自纠错机制:SQL执行失败后自动重试
5.3 安全防护开箱即用
-
自动注入行数限制(默认1000行)
-
自动识别并拦截危险SQL
-
支持行级/列级权限继承
5.4 可观测与迭代
-
每次查询都有日志(问题→SQL→执行结果)
-
支持人工标注正确/错误,持续优化
-
准确率报表,直观看到模型表现
落地对比:
|-------|-----------|----------|
| 维度 | 自建方案 | ZGI方案 |
| 开发周期 | 2-3个月 | 1周 |
| 工程师投入 | 2-3人 | 1人(接入即可) |
| 准确率基线 | 60%-70% | 85%+ |
| 安全防护 | 需要自己实现 | 开箱即用 |
| 持续优化 | 需要自己建标注系统 | 内置迭代机制 |
六、适用场景与选型建议
|---------------|---------------|
| 场景 | 推荐方案 |
| 内部数据分析工具(小范围) | 自建 + GPT-4 |
| 产品内嵌的自然语言查询功能 | ZGI 或 自建+大量优化 |
| 面向客户的BI产品 | 必须用企业级方案 |
| 金融/医疗等强监管行业 | ZGI(私有化部署) |
七、写在最后
Text-to-SQL是"让数据民主化"的重要技术。它让业务人员不再依赖数据团队,用白话就能查数据。
但从技术实现到企业落地,中间有大量工程细节需要处理:
-
Schema理解
-
复杂查询准确率
-
安全防护
-
权限控制
-
持续迭代
如果你正在考虑在企业内部落地Text-to-SQL能力,可以从一个小场景开始验证。如果不想从头造轮子,ZGI平台提供了开箱即用的解决方案,支持私有化部署,1周内即可上线MVP。
本文技术方案基于实际项目经验总结,ZGI平台已内置Text-to-SQL能力,支持连接MySQL、PostgreSQL等主流数据库。