继续进行法律文书智能摘要系统的开发
本次开发周期内,我主要围绕文书管理系统的核心体验进行了五项功能迭代与多项优化工作。首先,我打通了文书管理与示例展示之间的壁垒,在管理页面中直接嵌入示例卡片并支持按类型过滤,解决了原本两个模块相互割裂的问题。接着,我为文书管理增加了批量删除与批量导出能力,通过后端专职接口与ZIP打包策略,实现了文档的高效批处理。在阅读体验方面,我设计并实现了悬浮词典功能,采用本地词库预加载与后端异步更新的双轨机制,为用户提供即点即查的法律术语解释。同时,我还引入了主题调节与字体缩放功能,支持明暗/护眼三种模式并持久化用户偏好。最复杂的是富文本批注系统的重构,我通过增加DOM锚点定位、引入Tiptap编辑器、实现双向联动高亮,彻底解决了原有批注无法在原文中定位展示的问题。此外,我还对示例同步刷新、页面跳转逻辑、全局搜索行为以及上传文档流程进行了细致的优化,修复了悬浮词典因编码问题导致的编译错误和富文本高亮不更新等关键缺陷。以下将按功能模块详细记录开发过程与心得体会。
具体内容
1.连接示例展示与文书阅读功能
之前文书管理与示例展示各自分裂,这里在文书管理中加入示例的卡片展示
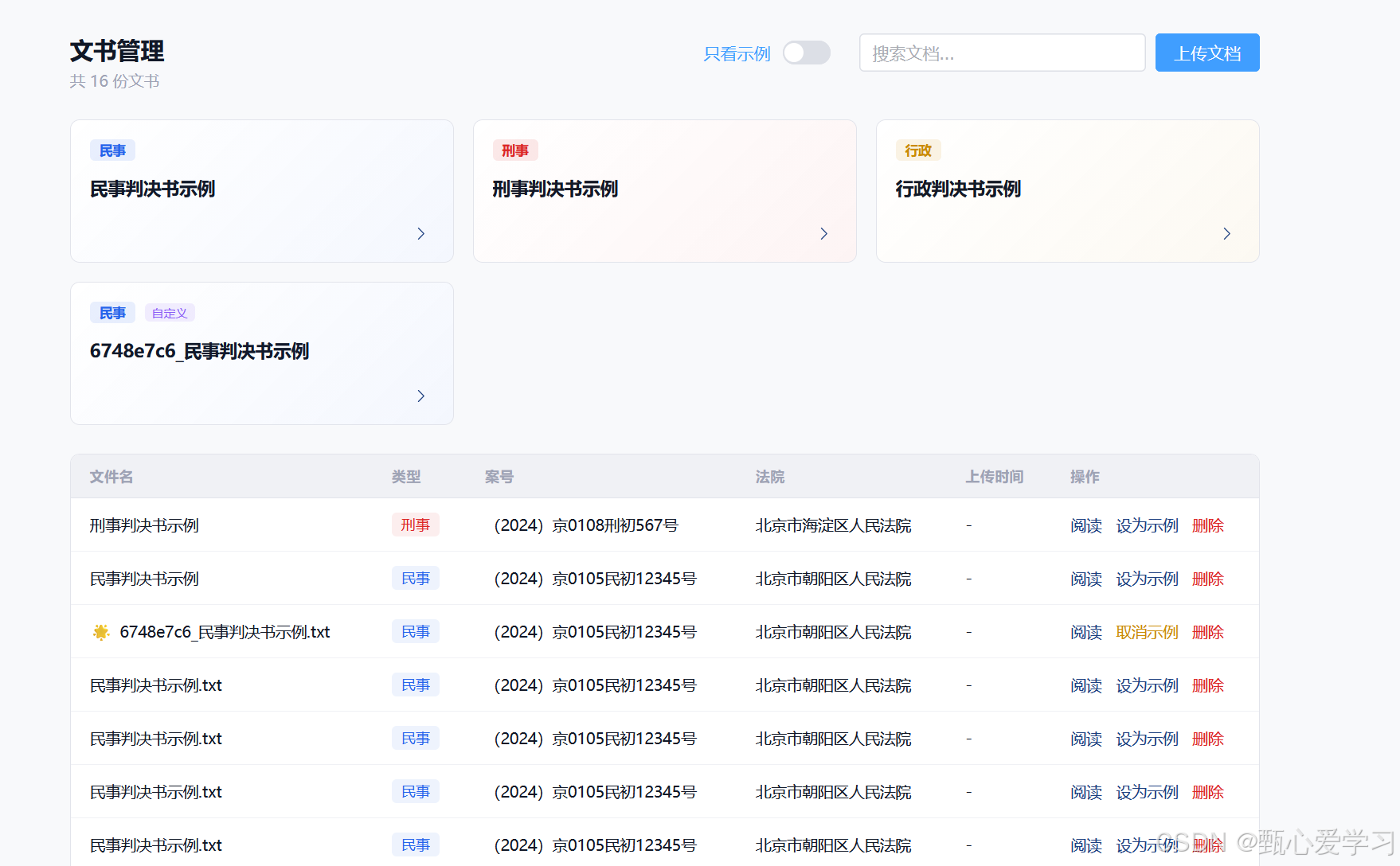
提供只看示例的按钮,可以直接过滤出用户自定义的示例
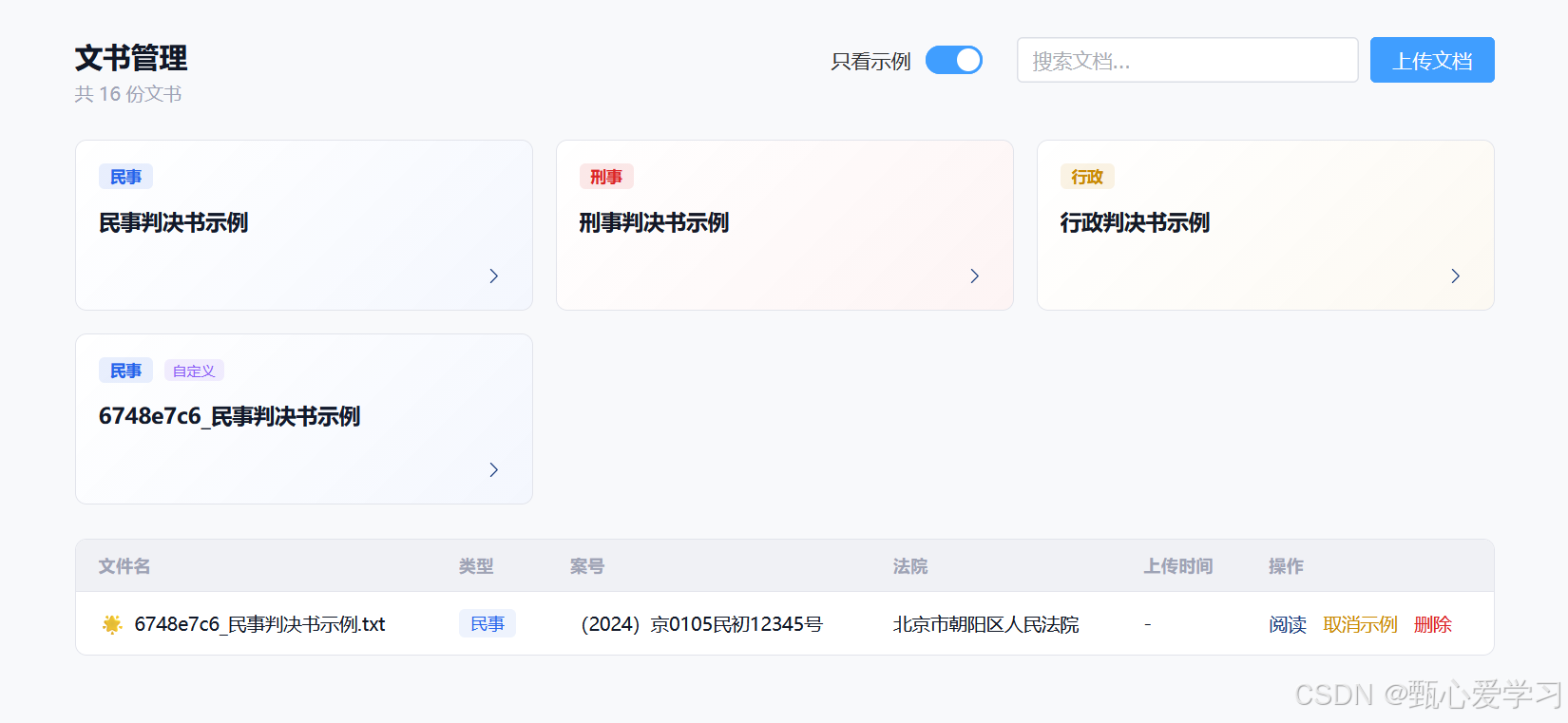
2.文书批量管理
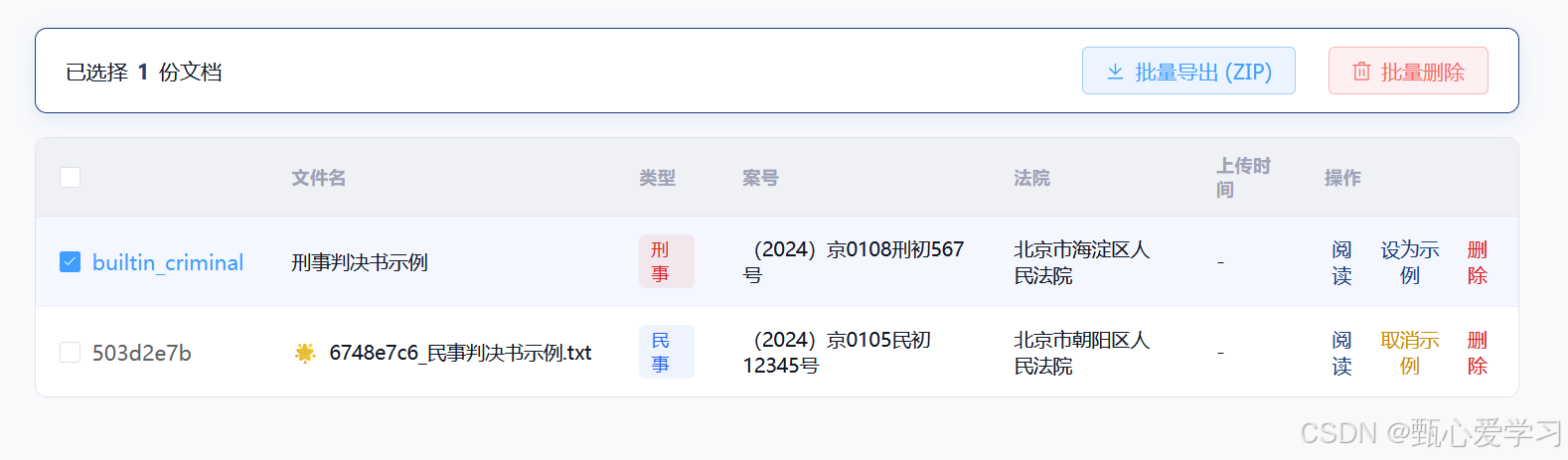
文书管理中,也加入批量删除功能,可全部选择或是部分选择;还有批量导出功能,全部导出或是部分导出
- 批量删除 (Batch Delete)
- 前端交互 :在文书原生大表格的最左侧插入一列包含
Checkbox(复选框)的列。表头包含全选/反选操作。选中文档后,顶部工作区会浮现"已选择 X 份文档 ------ 批量删除 | 批量导出"的控制栏。 - 后端支持 :可以直接由前端使用
Promise.all并发调用现有的单个文档删除接口,或者在documents.py新增一个专职的批量删除接口POST /api/documents/batch_delete(入参doc_ids: List[str]) 来统一处理事务。考虑到未来的扩展性,我们将新增专职的批量删除后端接口。
- 批量导出 (Batch Export)
- 后端导出端点 :新增
GET /api/documents/export,接收类似选中的doc_id列表。 - 打包策略 (ZIP Generation) : 因为本系统是文书解析系统,后端会将选中文件的相关信息打包成一个 ZIP 归档,直接流式下载到用户浏览器。对于每份入选文书,ZIP 包内将包含:
- 提取出的大模型结构化抽取 JSON 元数据 (
案号_法院等抽取字段.json)。 - 文段纯文本 (
xxx原文档.txt)。 (详见下方的 Open Questions 环节)
- 提取出的大模型结构化抽取 JSON 元数据 (
- UI 交互组件 (DocumentsListView 改造)
- 状态追踪 :引入
selectedIds = ref(new Set<string>())等响应式状态来追踪高亮。 - 吸顶动作栏 :当
selectedIds.size > 0时,在搜索框区域下方展开一个显眼的浮动工具栏,提供带有 Element Plus Icon 的"批量删除"与"打包导出"动作底座。
关于批量导出功能,有几个选择:
Option A :把原始上传进来的那个源文件(真实的 PDF/WORD/TXT 原件)打包成一个 导出压缩包.zip 给下载下来。
Option B:不仅仅是原文件,把这篇文书被 AI 解析切块后提取的干净纯文本以及它的案号等字段塞进 ZIP 里一起下载
Option C:只导出系统带案号、法院、类型的 Excel 大表格/CSV表。
这里按照optionB开发

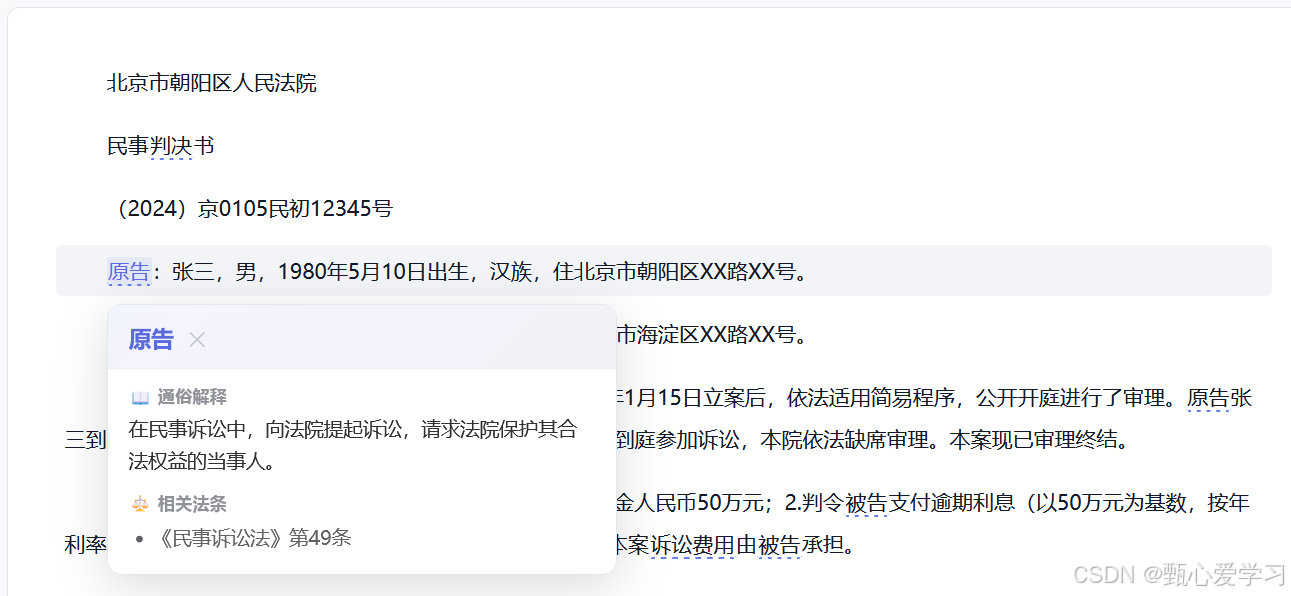
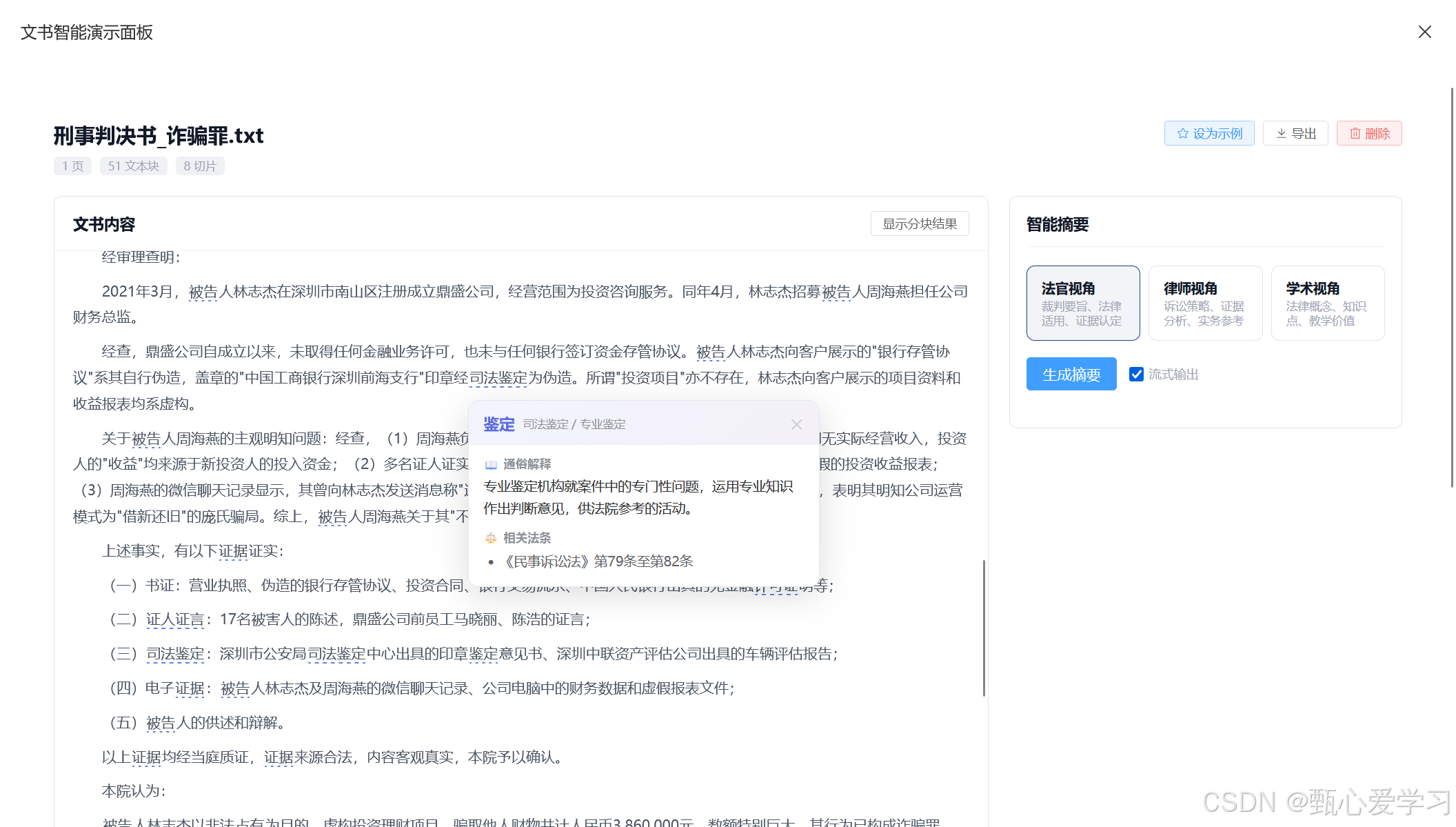
3.悬浮词典功能
首先,在底层数据处理上,采用本地词库预加载 + 后端 API 异步更新的双轨机制。前端在初始化阶段直接 import legal_terms.json,确保 ReaderView 和 DocumentView 在渲染瞬时即可通过全局正则表达式完成文本扫描,将术语包装为具有特定样式的 <span> 标签,从而消除因网络请求导致的页面闪烁。后续开发中,后端 GET /api/terms 接口将作为词库的热更新源,通过对比版本号实现增量同步,确保用户在不更新代码的情况下也能获取最新法律术语解释。
在交互逻辑实现上,核心组件 TermHighlighter 将采用事件委托机制 来监听点击行为。匹配到的术语会被赋予 data-term 属性,通过在组件根容器统一监听 click 事件来识别触发目标,这种方式能有效避免在大篇幅文书中因绑定过多监听器而产生的性能损耗。当用户点击高亮术语时,TermTooltip 组件将根据点击处的 DOM 坐标(getBoundingClientRect)计算弹出位置,以气泡卡片形式展示通俗解释及法条索引,并监听全局点击事件以实现"点击外部自动关闭"的逻辑。
在系统集成与扩展方面,功能将同步下沉至 ReaderView 的原文块与 DocumentView 的结构化摘要区。通过统一的 Props 接口将原始字符串注入 TermHighlighter 组件,实现两处场景下识别逻辑的高度复用与视觉一致性。这种架构设计为后续的功能留出了空间:当词库需求从静态查阅转向动态维护时,后端可无缝接入 SQLite 数据库,通过 POST/PUT 接口支持管理员对"善意取得"或"诉讼时效"等词条进行实时修订与案例补充,而无需改动前端展示逻辑。
| 文件 | 作用 |
|---|---|
TermHighlighter.vue |
核心扫描引擎,构建联合正则、渲染高亮 HTML、事件委托监听点击 |
TermTooltip.vue |
浮动卡片 UI,显示通俗解释 / 法条 / 案例,Teleport 到 body 层防遮挡 |
ReaderView.vue |
集成 <TermHighlighter> 替换原文段落 |
DocumentView.vue |
集成到"文书内容"正文块和"分块视图"两处 |
backend/app/api/terms.py |
GET /api/terms、GET /api/terms/{name}、POST /api/terms 三个接口 |
修改文件:
ReaderView.vue--- 阅读器正文块接入<TermHighlighter>DocumentView.vue--- 智能演示板正文块+分块视图接入<TermHighlighter>backend/main.py--- 注册terms_router
交互体验:
- 法律术语自动显示为蓝色虚线下划线,视觉清晰
- 点击词条后,弹出精美浮动卡片(带入场动画),显示:通俗解释 / 相关法条 /别名
- 点击卡片外任意区域自动关闭,不打断阅读
- 支持深色模式
4.主题调节功能
可以设计明暗等三种颜色,并能记录用户偏好,可以调节字体大小
| 文件 | 改动内容 |
|---|---|
stores/theme.ts 【新增】 |
Pinia Store,管理 light/dark/sepia 三档,初始化时自动读取 localStorage |
App.vue |
① 将 isDark: boolean 改为 themeStore.theme ② 新增 html.sepia { ... } CSS 变量覆写块(米黄暖色护眼调) |
ReaderView.vue |
顶栏新增 [☀️][🌙][🌿] 主题切换器 + [A−] 15px [A+] 字体大小调节控件 |
使用方式:
- 打开任意文书的阅读页(点击文书管理中的"阅读"按钮)
- 右上角能看到三个主题按钮 + 字体大小调节
- 点击任意主题,全站即刻切换(因为走的是同一个 Pinia Store)
- 关掉浏览器再打开,偏好自动恢复 (
localStorage持久化)
5.加入富文本编辑功能
问题根因
现在批注系统只存了"选中文字的字符串",完全没有 DOM 位置信息,所以原文无法高亮------就像 Word 批注只存了被引文本,但不知道它在第几页第几行。
解决思路:三层叠加渲染
原文段落
└─ 层1(底):批注高亮 <mark style="background:#409eff40">
└─ 层2(中):术语识别 <span class="legal-term-chip">(下划线虚线)
└─ 层3(上):交互事件 click/mouseup
关键数据扩展:给 Annotation 加锚点
// 现在存的(没有位置)
{ selectedText: "善意取得", comment: "..." }
// 改为(有了精确位置)
{
selectedText: "善意取得",
comment: "...",
richComment: { type: "doc", ... }, // Tiptap 富文本 JSON
anchorRange: {
blockIndex: 3, // 在第3个段落
startOffset: 42, // 从第42个字开始
endOffset: 46 // 到第46个字结束
}
}
两个最难的点
-
同一段落多批注不重叠:用区间合并算法把多条批注的字符范围排序后切割成片段列表渲染,初版直接限制不允许重叠。
-
与
TermHighlighter协同 :批注高亮(<mark>背景色)和术语高亮(<span>下划线)作用域不同,可以叠加,但两者都需要v-html渲染,需要把高亮计算合并到同一个渲染函数里。
Tiptap 用在哪?只用在右侧批注框 (用来写批注内容),不用在原文区域。原文维持只读,通过 <mark> 高亮即可。
分三个 PR:
- 数据层 (后端Schema + 前端API扩展
anchorRange) - 高亮渲染器 (原文
<mark>高亮 + 双向联动) - Tiptap 富文本编辑器(批注内容区替换)
| 文件 | 改动 |
|---|---|
schemas.py 【后端】 |
新增 AnchorRange 模型,给 AnnotationBase / AnnotationUpdate 添加 anchorRange 和 richComment 可选字段 |
storage.ts 【前端类型】 |
同步扩展 AnchorRange 接口 + Annotation 类型的两个新字段 |
useAnnotationHighlight.ts 【新建 Composable】 |
核心区间合并算法:把某段落内的多条批注 anchorRange 切割为片段列表,转换为带 <mark> 标签的 HTML |
AnnotationPanel.vue 【全量重写】 |
Tiptap 富文本编辑器(加粗/斜体/下划线/列表)+ 颜色选择器 + 编辑/删除 + @active-annotation 事件 |
ReaderView.vue 【全量重写】 |
加载批注后渲染内联 <mark> 高亮;点击高亮 → 右侧卡片激活滚动;点击批注卡片 → 左侧文本滚动定位 |
交互体验:
拖选原文文字 → mouseup → 批注面板弹出"添加"表单(含引用预览)
→ Tiptap 富文本框输入内容 → 保存
→ 原文对应位置出现彩色下划线高亮
→ 点击高亮 → 右侧批注卡片激活
→ 点击右侧卡片 → 左侧原文滚动到位
功能优化
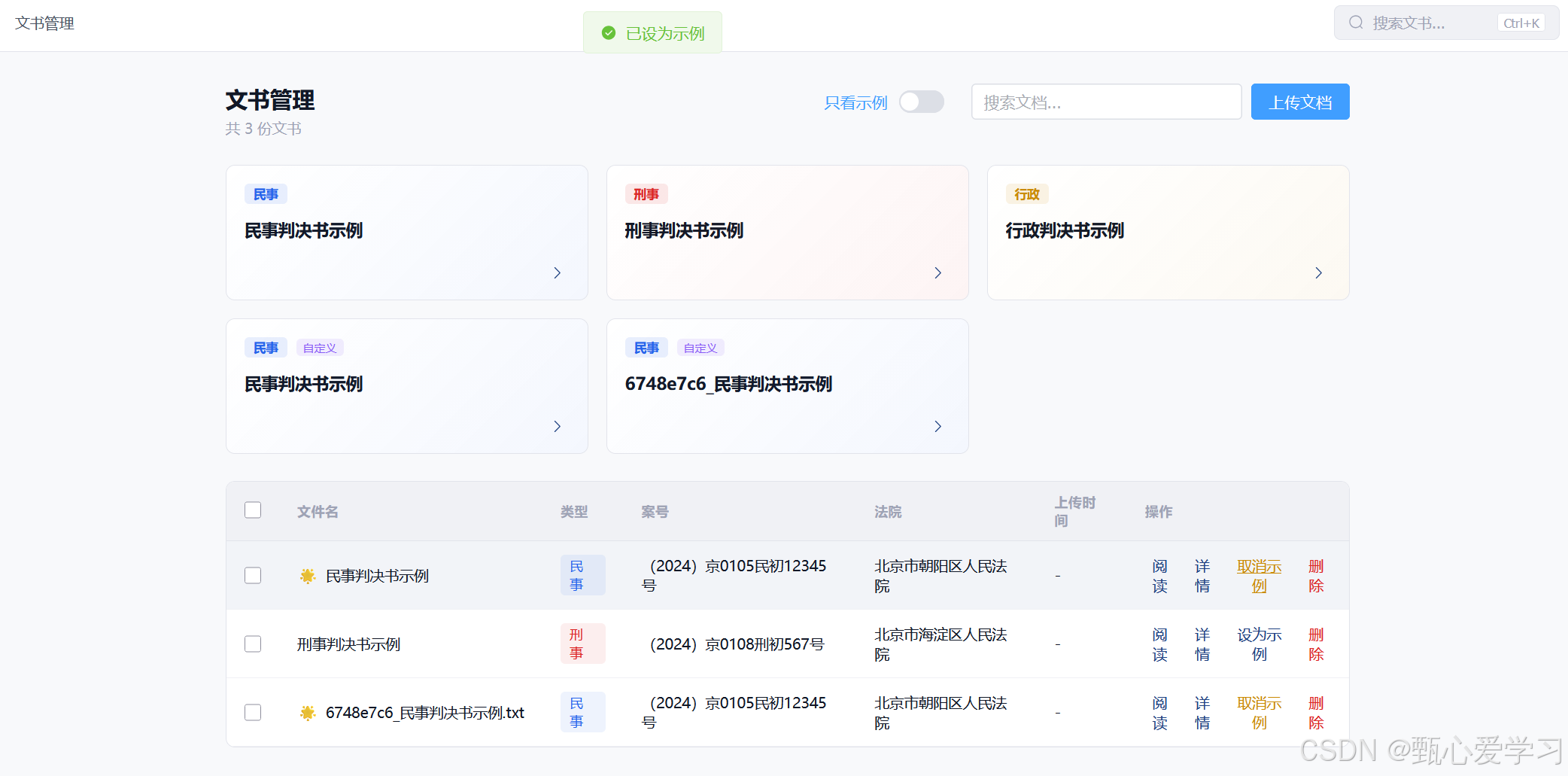
1.取消示例的时候,要刷新一次这样卡片才能正确实现
- 改造
SampleLoader.vue:将它内封获取数据的函数借由defineExpose({ fetchSamples })暴露出来,允许外接系统随时强制它重新拉取最新卡片。 - 连接
DocumentsListView.vue:为<SampleLoader ref="sampleLoaderRef" />打上响应式的锚点。 - 注入同步刷新钩子 :在原先的
handleToggleSample业务逻辑线中(也就是你一旦点击星星后),等后端接口确认删除或添加完毕,立马静默执行一句sampleLoaderRef.value.fetchSamples()
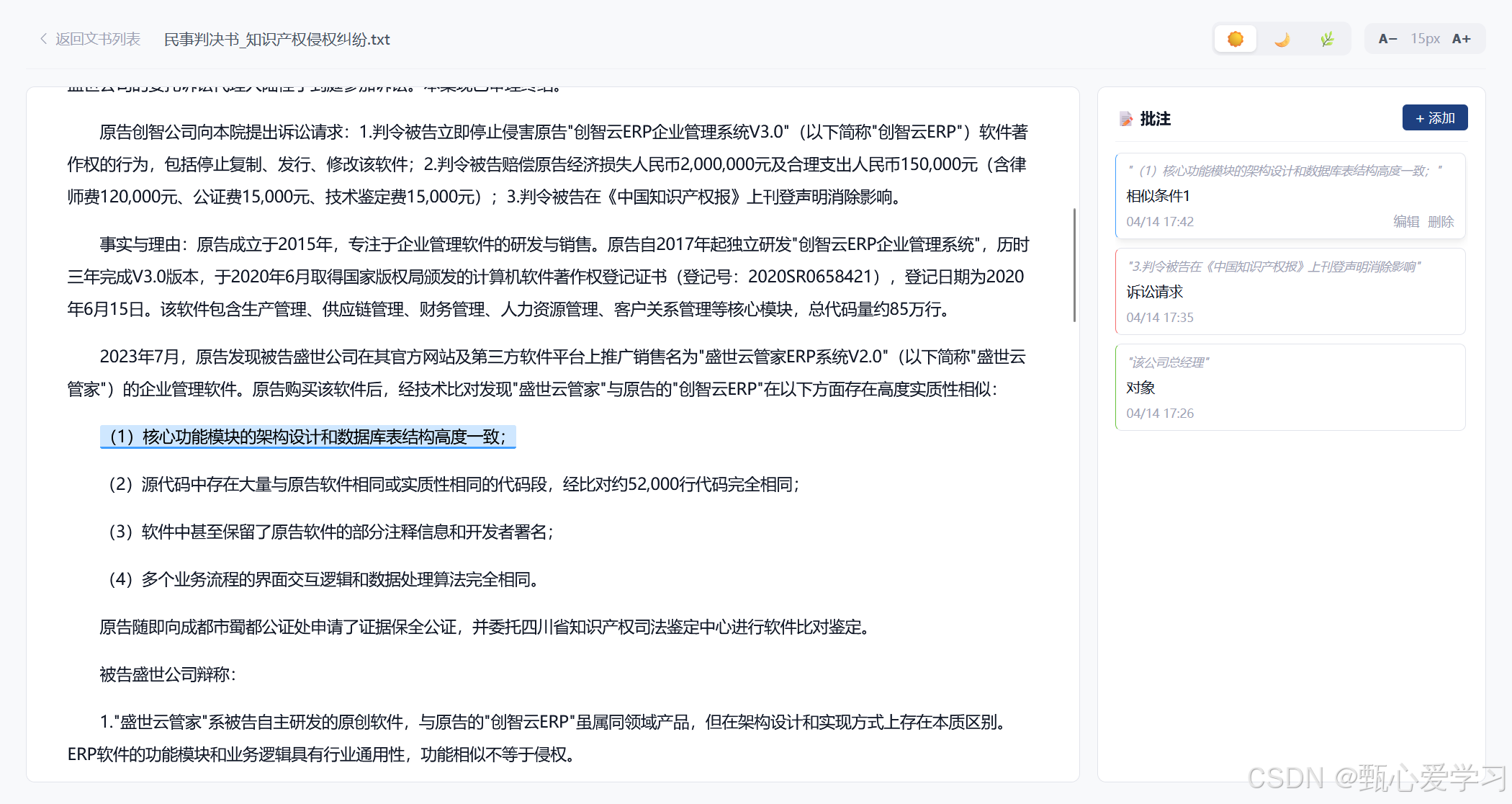
2.文书示例与文书管理页面跳转不合理
- 返回路径写死 :在"文书详请/演示界面 (
DocumentView)"中,左上角的「返回」按钮被强行写死为了router.push('/')(回到首页)。导致用户从"文书管理 (DocumentsListView)"表格中点击一篇文章进去后,无法退回原表格,打断了连续办公的心流。 - 场景割裂:"管理资产"和"查阅解析演示"应该是同一套连贯动作,目前的跳页割裂感偏重。
这里用分屏式设计:
- 逻辑 :在"文书管理"的大表格里,点击某一行,不再是发生全屏的暴力跳转,而是从屏幕右侧平滑滑出一个宽大的抽屉面板 (Drawer) 或者是直接将页面一分为二(左边列表,右边展示信息)。
- 体验:可以在右侧抽屉里看到所有的结构化字段、类案推荐。看完关掉抽屉,文书表格就安静地停留在那里。勾选多个进行批量打包将变得极其流畅。
文书管理中,这里的操作有阅读,也有详情的选项,在阅读后返回的是文书管理而不是详情页面

3.右上角的查询功能

现在的状况是:在这个悬浮的框(或者按下 Ctrl+K)里输入关键字敲击回车后,不管处在哪个页面,它都会简单粗暴地把您切回"工作台主页 (/)"。既然工作台本身只是用来拉取概览和基础信息的主页,这种行为等于粗暴地打断了工作流。
为了解决这个问题,有两个优化方向:
- 方案 A (沉浸式下拉) :彻底抛弃页面跳转。当敲入字符时,直接在这个黑色的弹窗下面延伸拉出结果列表(就像用苹果电脑的聚焦搜索或者手机下拉搜索框一样)。点击想要看的文书后,再单独打开详情或侧边栏,全程不需要离开目前的界面背景。
- 方案 B (导流至表格管理流) :让搜索框变成一个全局快捷键:按下回车后,统一跃迁至《文书管理》页面(
/documents),并且自动帮把关键字填进去把表格筛好。接下去的操作就是极其顺畅的:选行 -> 滑出面板审阅 -> 关面板看下一篇。
这里选择了方案B
| 文件 | 改动内容 |
|---|---|
App.vue |
handleSearch 中的跳转目标从 /?search=... 改为 /documents?search=... |
HomeView.vue |
删除 onMounted 中监听 ?search= URL参数的冗余逻辑,主页恢复为干净的工作台 |
DocumentsListView.vue |
新增 useRoute,在 onMounted 时读取 route.query.search,自动填入过滤框 |
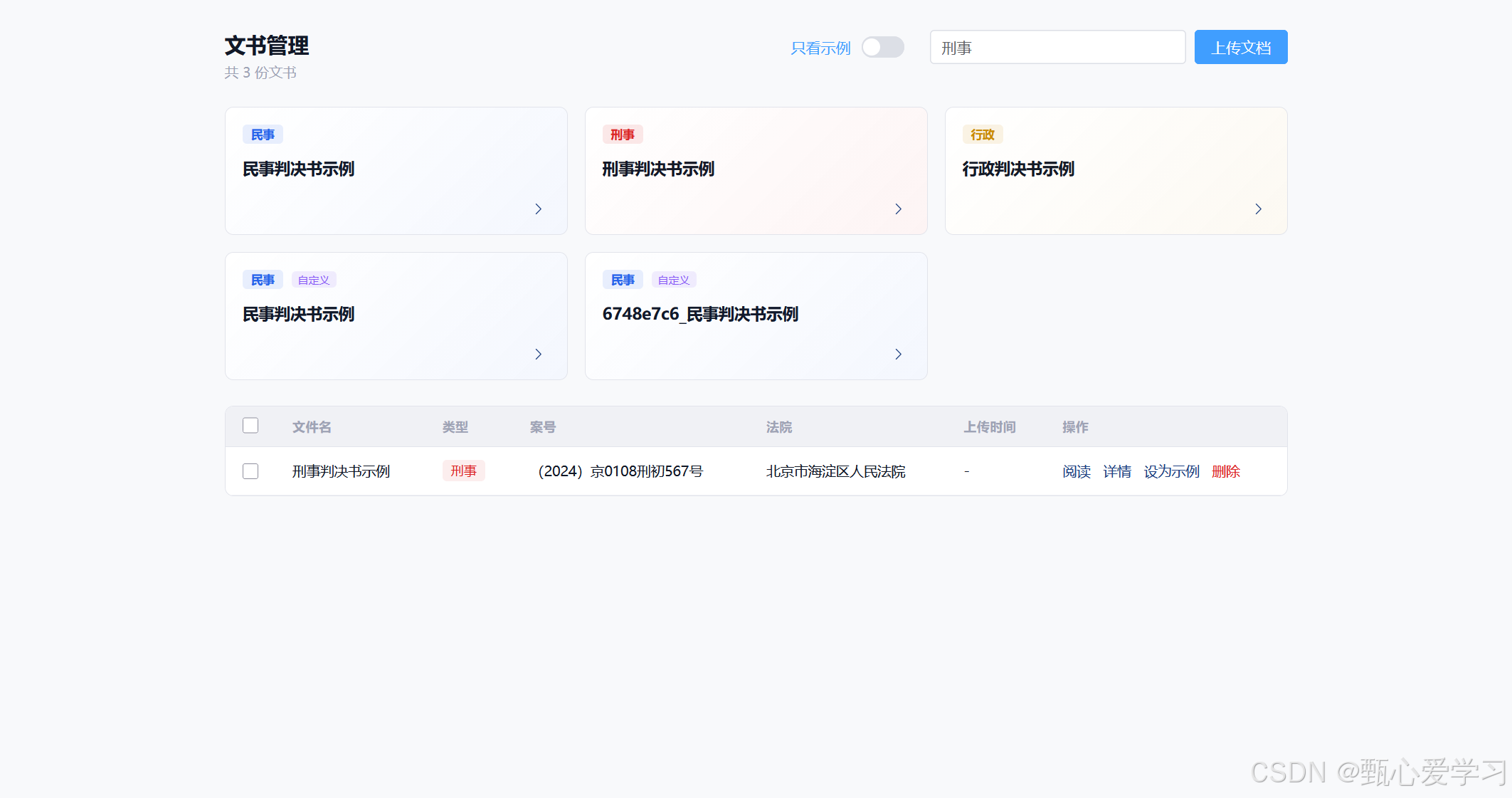
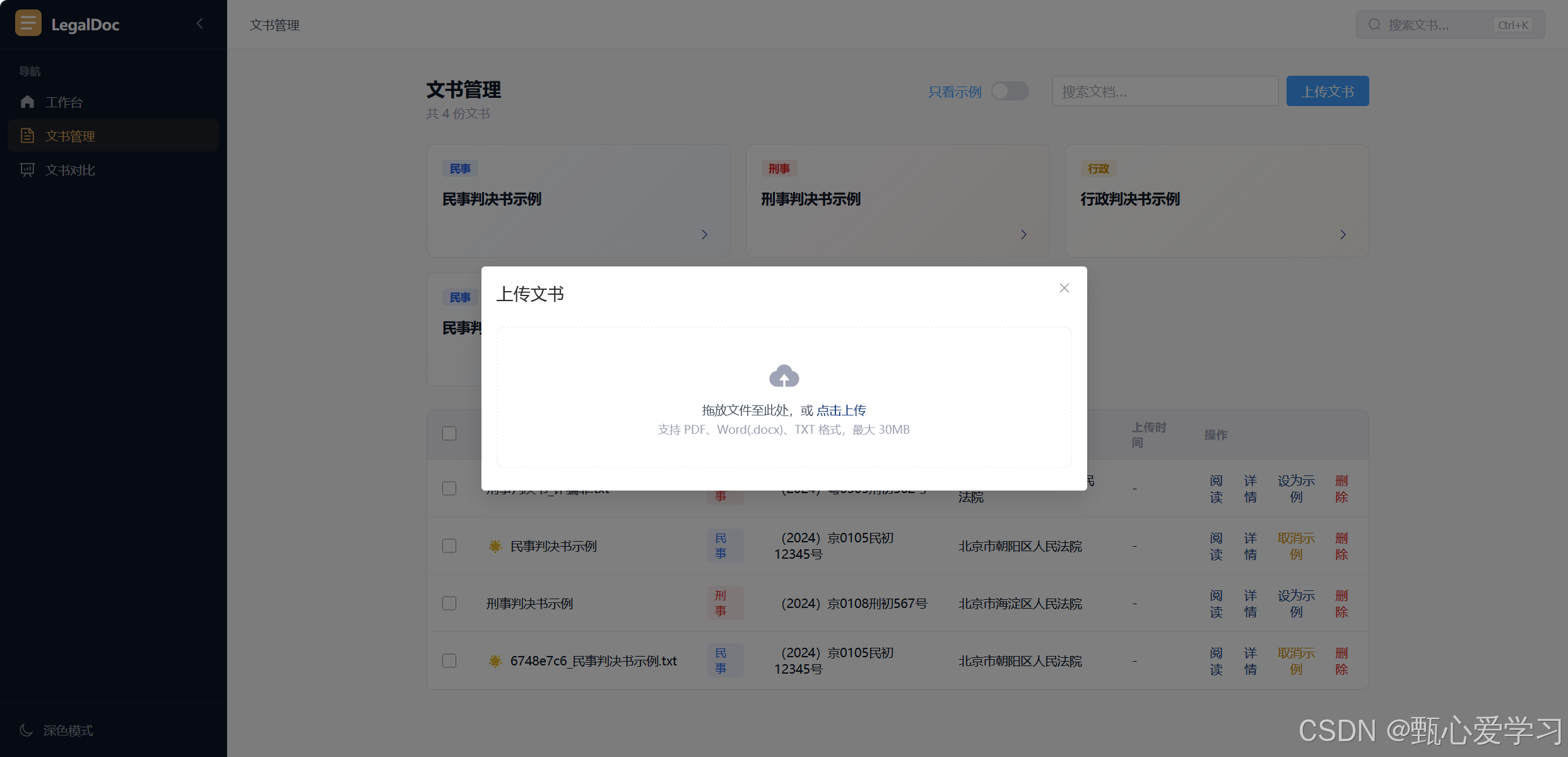
4.文书管理页面的上传文档功能
核心问题有两个:
- 跳出问题 :点击"上传文档"按钮直接
router.push('/')把用户踢出管理页,完全没有必要 - 无刷新问题 :
FileUpload.vue上传完成后会强制跳转到/document/:id(演示详情页)或/documents,但上传成功后管理列表并没有机会获知"要刷新自己"
解决方案:上传框以弹窗对话框的形式内嵌在管理页里,上传完成后弹窗关闭,下方表格自动刷新出新文档。全程不换页,可以直接点"详情"打开右侧抽屉查看解析。
遇到的问题及解决方法
1.悬浮词典功能报错
之前用 PowerShell 的 Set-Content -NoNewline 写入文件时,默认使用了系统 ANSI 编码(GBK),导致文件中部分 UTF-8 汉字被截断,Vue 编译器无法解析被破坏的闭合标签。
修复步骤:
- 用
git show d6a6db6:...将文件还原到上一个干净的提交 - 用 Python(始终用
encoding='utf-8'读写)重新将 TermHighlighter 的集成干净地写入 - 验证文件无
\ufffd替换字符后提交
今后策略:对所有含中文的 Vue 文件,统一用 Python 脚本或直接使用编辑工具进行修改,绕开 PowerShell 的编码陷阱。
重启 npm run dev 后可以正常编译了。
2.富文本编辑中不显示高亮
- 高亮不显示 :
ReaderView的annotations数组只在onMounted加载一次,AnnotationPanel内部保存/删除后不会通知父组件刷新 - 删除不生效 :同理,删除后只更新了 Panel 内部状态,
ReaderView的高亮层没有感知到
修复分两步:给 AnnotationPanel 加 changed 事件,ReaderView 监听后刷新
| Bug | 根因 | 修复 |
|---|---|---|
| 高亮不显示 | AnnotationPanel 保存后只更新了内部的 annotations,ReaderView 的 annotations 永远是 onMounted 时加载的初始值 |
AnnotationPanel 新增 emit('changed'),ReaderView 监听 @changed → 调用 getAnnotations 重新拉取 |
| 删除后高亮残留 | 同上,删除只更新了面板侧 | 删除成功后同样触发 emit('changed') + 加了 try/catch 防止接口报错时静默失败 |
| 高亮更新不及时 | blockHtml 是普通函数,Vue 模板内多次调用会有微小时序差异 |
改为 computed(() => blocks.value.map(...)) 计算属性,当 annotations 变化时原子性地重算所有块的 HTML |
| ElMessage 文字错 | editingId.value 在消息之前就已被清为 null,导致永远显示"批注已保存" |
提前用 wasEditing 捕获标志位,再清空 editingId |
小结
通过本轮开发,文书管理系统在批量操作效率 、阅读辅助体验 以及批注交互完整性 三个维度上都有了质的提升。批量删除与导出的加入,让用户能够高效管理大量文书;悬浮词典与主题调节功能显著优化了长时间阅读的舒适度;而富文本批注系统的重构,则彻底解决了"批注无法定位原文"的历史痛点。在开发过程中,我深刻体会到数据锚点设计对于富文本交互的关键作用。同时,编码问题带来的教训也提醒我始终重视文件编码一致性。后续我计划继续完善词库的后端管理界面,并探索批注的协同编辑可能性,让文书分析工作更加智能与高效。