文章目录
题目
标题和出处
标题:被围绕的区域
出处:130. 被围绕的区域
难度
5 级
题目描述
要求
给定一个 m × n \texttt{m} \times \texttt{n} m×n 的包含 'X' \texttt{`X'} 'X' 和 'O' \texttt{`O'} 'O' 的矩阵 board \texttt{board} board,捕获在水平方向和竖直方向上被 'X' \texttt{`X'} 'X' 围绕的全部区域。
将一个区域捕获 的做法是将被围绕的该区域中的所有 'O' \texttt{`O'} 'O' 翻转成 'X' \texttt{`X'} 'X'。
示例
示例 1:
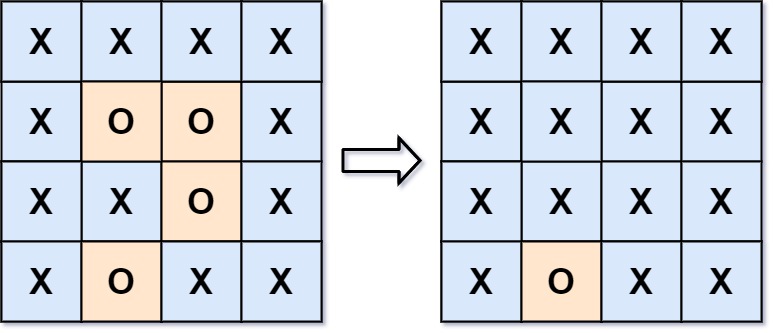
输入: board = \["X","X","X","X","X","O","O","X","X","X","O","X","X","O","X","X"] \texttt{board = \["X","X","X","X","X","O","O","X","X","X","O","X","X","O","X","X"]} board = \["X","X","X","X","X","O","O","X","X","X","O","X","X","O","X","X"]
输出: \["X","X","X","X","X","X","X","X","X","X","X","X","X","O","X","X"] \texttt{\["X","X","X","X","X","X","X","X","X","X","X","X","X","O","X","X"]} \["X","X","X","X","X","X","X","X","X","X","X","X","X","O","X","X"]
解释:如果一个 'O' \texttt{`O'} 'O' 在边界上,或者和一个不该翻转的 'O' \texttt{`O'} 'O' 相邻,则不会被翻转。
最下面的 'O' \texttt{`O'} 'O' 在边界上,因此不被翻转。
其余三个 'O' \texttt{`O'} 'O' 组成一个被围绕的区域,因此被翻转。
示例 2:
输入: board = \["X"] \texttt{board = \["X"]} board = \["X"]
输出: \["X"] \texttt{\["X"]} \["X"]
数据范围
- m = board.length \texttt{m} = \texttt{board.length} m=board.length
- n = boardi.length \texttt{n} = \texttt{boardi.length} n=boardi.length
- 1 ≤ m, n ≤ 200 \texttt{1} \le \texttt{m, n} \le \texttt{200} 1≤m, n≤200
- boardij \texttt{boardij} boardij 为 'X' \texttt{`X'} 'X' 或 'O' \texttt{`O'} 'O'
解法一
思路和算法
这道题要求将矩阵中不与边界连通的全部 'O' \text{`O'} 'O' 都改成 'X' \text{`X'} 'X'。为了区分与边界连通的 'O' \text{`O'} 'O' 和不与边界连通的 'O' \text{`O'} 'O',可以首先遍历与边界连通的所有 'O' \text{`O'} 'O' 并与 'X' \text{`X'} 'X' 和 'O' \text{`O'} 'O' 加以区分,然后更新矩阵。
可以使用广度优先搜索遍历与边界连通的所有 'O' \text{`O'} 'O'。从边界上的 'O' \text{`O'} 'O' 开始遍历所有可以到达的 'O' \text{`O'} 'O' 并改成不同于 'X' \text{`X'} 'X' 和 'O' \text{`O'} 'O' 的特殊字符,遍历结束之后,所有与边界相连的 'O' \text{`O'} 'O' 都改成特殊字符。
将所有与边界相连的 'O' \text{`O'} 'O' 都改成特殊字符之后,剩余的未改成特殊字符的 'O' \text{`O'} 'O' 都需要改成 'X' \text{`X'} 'X',因此将所有的 'O' \text{`O'} 'O' 都改成 'X' \text{`X'} 'X'。由于与边界相连的 'O' \text{`O'} 'O' 应仍为 'O' \text{`O'} 'O',因此还要将所有的特殊字符都改成 'O' \text{`O'} 'O'。
实现方面有以下三点说明。
-
从一个 'O' \text{`O'} 'O' 开始遍历时,对于每个 'O' \text{`O'} 'O',考虑与当前 'O' \text{`O'} 'O' 在四个方向上相邻且未访问的 'O' \text{`O'} 'O',可以创建方向数组实现四个方向的遍历。
-
广度优先搜索需要记录每个元素是否被访问过,这道题由于要求原地修改输入矩阵,因此可以根据矩阵中的元素值判断每个元素是否被访问过,不需要额外创建与矩阵相同的二维数组记录每个元素是否被访问过。判断方法是,如果元素值是 'O' \text{`O'} 'O' 则表示未访问,如果元素值是特殊字符则表示已访问。
-
遍历矩阵将 'O' \text{`O'} 'O' 改成 'X' \text{`X'} 'X' 以及将特殊字符改成 'O' \text{`O'} 'O' 时,由于一次遍历中每个元素只会访问一次,因此可以在一次遍历中同时进行两种元素的更改。
代码
java
class Solution {
static int[][] dirs = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
public void solve(char[][] board) {
int m = board.length, n = board[0].length;
Queue<int[]> queue = new ArrayDeque<int[]>();
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O') {
board[i][0] = '#';
queue.offer(new int[]{i, 0});
}
if (board[i][n - 1] == 'O') {
board[i][n - 1] = '#';
queue.offer(new int[]{i, n - 1});
}
}
for (int j = 1; j < n - 1; j++) {
if (board[0][j] == 'O') {
board[0][j] = '#';
queue.offer(new int[]{0, j});
}
if (board[m - 1][j] == 'O') {
board[m - 1][j] = '#';
queue.offer(new int[]{m - 1, j});
}
}
while (!queue.isEmpty()) {
int[] cell = queue.poll();
int row = cell[0], col = cell[1];
for (int[] dir : dirs) {
int newRow = row + dir[0], newCol = col + dir[1];
if (newRow >= 0 && newRow < m && newCol >= 0 && newCol < n && board[newRow][newCol] == 'O') {
board[newRow][newCol] = '#';
queue.offer(new int[]{newRow, newCol});
}
}
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'O') {
board[i][j] = 'X';
} else if (board[i][j] == '#') {
board[i][j] = 'O';
}
}
}
}
}复杂度分析
-
时间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别是矩阵 board \textit{board} board 的行数和列数。广度优先搜索最多需要访问每个元素一次,广度优先搜索之后需要遍历矩阵一次,时间复杂度是 O ( m n ) O(mn) O(mn)。
-
空间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别是矩阵 board \textit{board} board 的行数和列数。记录每个元素是否被访问过的二维数组和队列需要 O ( m n ) O(mn) O(mn) 的空间。
解法二
思路和算法
也可以使用深度优先搜索遍历与边界连通的所有 'O' \text{`O'} 'O'。从边界上的 'O' \text{`O'} 'O' 开始遍历所有可以到达的 'O' \text{`O'} 'O' 并改成不同于 'X' \text{`X'} 'X' 和 'O' \text{`O'} 'O' 的特殊字符,遍历结束之后,所有与边界相连的 'O' \text{`O'} 'O' 都改成特殊字符。
将所有与边界相连的 'O' \text{`O'} 'O' 都改成特殊字符之后,剩余的未改成特殊字符的 'O' \text{`O'} 'O' 都需要改成 'X' \text{`X'} 'X',因此将所有的 'O' \text{`O'} 'O' 都改成 'X' \text{`X'} 'X'。由于与边界相连的 'O' \text{`O'} 'O' 应仍为 'O' \text{`O'} 'O',因此还要将所有的特殊字符都改成 'O' \text{`O'} 'O'。
实现方面有以下三点说明。
-
从一个 'O' \text{`O'} 'O' 开始遍历时,对于每个 'O' \text{`O'} 'O',考虑与当前 'O' \text{`O'} 'O' 在四个方向上相邻且未访问的 'O' \text{`O'} 'O',可以创建方向数组实现四个方向的遍历。
-
深度优先搜索需要记录每个元素是否被访问过,这道题由于要求原地修改输入矩阵,因此可以根据矩阵中的元素值判断每个元素是否被访问过,不需要额外创建与矩阵相同的二维数组记录每个元素是否被访问过。判断方法是,如果元素值是 'O' \text{`O'} 'O' 则表示未访问,如果元素值是特殊字符则表示已访问。
-
遍历矩阵将 'O' \text{`O'} 'O' 改成 'X' \text{`X'} 'X' 以及将特殊字符改成 'O' \text{`O'} 'O' 时,由于一次遍历中每个元素只会访问一次,因此可以在一次遍历中同时进行两种元素的更改。
代码
java
class Solution {
static int[][] dirs = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
int m, n;
char[][] board;
public void solve(char[][] board) {
this.m = board.length;
this.n = board[0].length;
this.board = board;
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O') {
dfs(i, 0);
}
if (board[i][n - 1] == 'O') {
dfs(i, n - 1);
}
}
for (int j = 1; j < n - 1; j++) {
if (board[0][j] == 'O') {
dfs(0, j);
}
if (board[m - 1][j] == 'O') {
dfs(m - 1, j);
}
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'O') {
board[i][j] = 'X';
} else if (board[i][j] == '#') {
board[i][j] = 'O';
}
}
}
}
public void dfs(int row, int col) {
board[row][col] = '#';
for (int[] dir : dirs) {
int newRow = row + dir[0], newCol = col + dir[1];
if (newRow >= 0 && newRow < m && newCol >= 0 && newCol < n && board[newRow][newCol] == 'O') {
dfs(newRow, newCol);
}
}
}
}复杂度分析
-
时间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别是矩阵 board \textit{board} board 的行数和列数。深度优先搜索最多需要访问每个元素一次,深度优先搜索之后需要遍历矩阵一次,时间复杂度是 O ( m n ) O(mn) O(mn)。
-
空间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别是矩阵 board \textit{board} board 的行数和列数。记录每个元素是否被访问过的二维数组和递归调用栈需要 O ( m n ) O(mn) O(mn) 的空间。
解法三
预备知识
该解法涉及到并查集。
并查集是一种树型的数据结构,用于处理不相交集合的合并与查询问题。
思路和算法
判断一个元素 'O' \text{`O'} 'O' 是否与边界连通,等价于判断该元素 'O' \text{`O'} 'O' 是否与至少一个边界上的元素 'O' \text{`O'} 'O' 属于同一个连通分量,连通性问题可以使用并查集解决。
并查集初始化时,每个元素分别属于不同的集合,每个集合只包含一个元素,边界上的元素 'O' \text{`O'} 'O' 的状态是与边界连通,其余元素的状态都是不与边界连通。
初始化之后,遍历每个元素,如果一个元素是 'O' \text{`O'} 'O' 且其上边或左边的相邻元素是 'O' \text{`O'} 'O',则将两个相邻元素 'O' \text{`O'} 'O' 所在的集合做合并,同时将合并后的状态更新为与边界连通。
遍历结束之后,将矩阵中的不与边界连通的所有元素 'O' \text{`O'} 'O' 都改成 'X' \text{`X'} 'X'。
代码
java
class Solution {
public void solve(char[][] board) {
int m = board.length, n = board[0].length;
UnionFind uf = new UnionFind(m * n);
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O') {
uf.initEdge(i * n);
}
if (board[i][n - 1] == 'O') {
uf.initEdge(i * n + n - 1);
}
}
for (int j = 1; j < n - 1; j++) {
if (board[0][j] == 'O') {
uf.initEdge(j);
}
if (board[m - 1][j] == 'O') {
uf.initEdge((m - 1) * n + j);
}
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'X') {
continue;
}
if (i > 0 && board[i - 1][j] == 'O') {
uf.union((i - 1) * n + j, i * n + j);
}
if (j > 0 && board[i][j - 1] == 'O') {
uf.union(i * n + j - 1, i * n + j);
}
}
}
for (int i = 1; i < m - 1; i++) {
for (int j = 1; j < n - 1; j++) {
if (board[i][j] == 'O' && !uf.isOnEdge(i * n + j)) {
board[i][j] = 'X';
}
}
}
}
}
class UnionFind {
private int[] parent;
private int[] rank;
private boolean[] onEdge;
public UnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
rank = new int[n];
onEdge = new boolean[n];
}
public void initEdge(int x) {
onEdge[x] = true;
}
public void union(int x, int y) {
int rootx = find(x);
int rooty = find(y);
if (rootx != rooty) {
if (rank[rootx] > rank[rooty]) {
parent[rooty] = rootx;
onEdge[rootx] |= onEdge[rooty];
} else if (rank[rootx] < rank[rooty]) {
parent[rootx] = rooty;
onEdge[rooty] |= onEdge[rootx];
} else {
parent[rooty] = rootx;
onEdge[rootx] |= onEdge[rooty];
rank[rootx]++;
}
}
}
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
public boolean isOnEdge(int x) {
return onEdge[find(x)];
}
}复杂度分析
-
时间复杂度: O ( m n × α ( m n ) ) O(mn \times \alpha(mn)) O(mn×α(mn)),其中 m m m 和 n n n 分别是矩阵 board \textit{board} board 的行数和列数, α \alpha α 是反阿克曼函数。并查集的初始化需要 O ( m n ) O(mn) O(mn) 的时间,然后遍历 m n mn mn 个元素,执行 O ( m n ) O(mn) O(mn) 次合并操作,这里的并查集使用了路径压缩和按秩合并,单次操作的时间复杂度是 O ( α ( m n ) ) O(\alpha(mn)) O(α(mn)),因此并查集初始化之后的操作的时间复杂度是 O ( m n × α ( m n ) ) O(mn \times \alpha(mn)) O(mn×α(mn)),并查集操作之后需要遍历矩阵一次,总时间复杂度是 O ( m n + m n × α ( m n ) + m n ) = O ( m n × α ( m n ) ) O(mn + mn \times \alpha(mn) + mn) = O(mn \times \alpha(mn)) O(mn+mn×α(mn)+mn)=O(mn×α(mn))。
-
空间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别是矩阵 board \textit{board} board 的行数和列数。并查集需要 O ( m n ) O(mn) O(mn) 的空间。