侧输出(Side Output)是 Flink 提供的一种灵活的数据分流机制,核心价值在于实现数据流的精准拆分,适配多场景业务需求,具体特点如下:
-
允许在单个算子中,将数据流按业务逻辑拆分为多个独立的输出流;
-
适用于处理"主路径 + 异常路径""正常数据 + 告警数据"等需要分离处理的场景,实现逻辑解耦。
一、分流方法对比
分流即按照业务需求将输入源拆分为多个独立数据流,Flink 中常用两种分流方式,具体对比如下:
-
Filter 分流:不推荐使用
-
原理:根据用户输入的条件进行过滤,每个元素都会被
filter()函数处理,若返回true则保留该元素,否则丢弃; -
弊端:需要重复遍历原始流(每个分流逻辑都需单独调用filter),浪费集群资源,效率较低。
-
-
Side Output 分流:推荐使用
-
原理:通过特定标签标识额外输出流,与主输出流独立处理,无需重复遍历原始流;
-
优势:高效、灵活,能减少算子数量和 DAG 复杂度,是生产环境的首选分流方式。
-
二、侧输出的概念与原理
2.1 核心定义
-
主输出(Main Output) :算子默认的输出流,通过
collect()方法发送数据,是业务核心流程的数据流; -
侧输出(Side Output) :通过
OutputTag标识的额外输出流,不属于核心流程,通过context.output(tag, value)方法发送数据;
侧输出核心特点
-
一个算子可定义多个侧输出,满足多维度分流需求;
-
侧输出流与主输出流完全独立,可分别配置后续处理逻辑(如不同的 Sink);
-
侧输出不会影响主流程的语义和性能,即使侧输出处理失败,也不会阻断主流程执行。
2.2 工作原理
-
关键组件:
OutputTag<T>;(泛型标签,用于唯一标识不同的侧输出流,泛型需与输出数据类型一致); -
底层实现:Flink 在算子内部维护一个
Map<OutputTag, Collector>;集合,将不同OutputTag对应的数据流路由到不同的下游 Collector,实现分流。
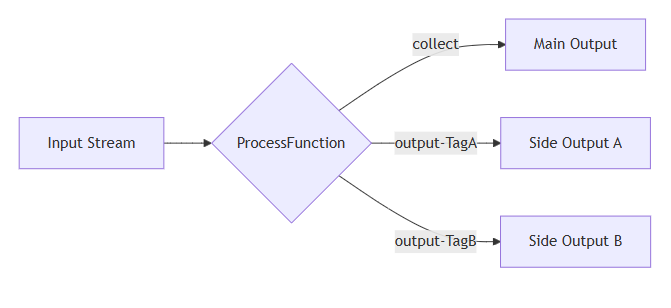
核心优势:避免为简单分流逻辑拆分多个算子,减少 Flink 作业 DAG 图的复杂度,提升作业执行效率。
2.3 典型应用场景
| 场景 | 说明 |
|---|---|
| 异常数据分离 | 将格式错误、空值、字段超限等异常数据分流到侧输出,主流程仅处理干净、符合要求的数据,降低核心逻辑复杂度。 |
| 多级告警 | 正常数据走主输出,Warning(警告)、Error(错误)等不同级别事件分别走不同侧输出,实现分级告警处理。 |
| A/B 测试分流 | 按用户 ID 尾号、设备类型等规则,将数据流分流到不同实验组,主输出可保留原始数据或基准组数据。 |
| 延迟数据处理 | 在窗口计算中,将超过 Watermark 阈值的迟到数据发送到侧输出,单独处理,避免影响窗口正常计算结果。 |
| 数据打标 | 为主数据流附加元信息(如数据来源、优先级、处理时间),通过侧输出同步输出元信息,不干扰主数据结构。 |
侧输出的核心价值:实现单一职责 + 逻辑解耦,让主流程专注于核心业务处理,异常、辅助逻辑独立拆分,便于维护和扩展。
三、使用侧输出(DataStream API)
DataStream API 是侧输出的标准使用方式,分为"定义标签→发送数据→获取处理"三个核心步骤,流程清晰、可直接复用。
3.1 步骤 1:定义 OutputTag
需定义static final修饰的OutputTag,原因是侧输出标签涉及序列化,静态常量可保证序列化一致性,避免报错。
java
// 定义侧输出标签(必须是 static final,泛型与输出数据类型一致)
// 标签1:处理迟到数据
private static final OutputTag<String> LATE_DATA_TAG =
new OutputTag<String>("late-data") {};
// 标签2:处理无效数据(解析失败、空值等)
private static final OutputTag<String> INVALID_DATA_TAG =
new OutputTag<String>("invalid-data") {};3.2 步骤 2:在 ProcessFunction 中发送数据
侧输出需在ProcessFunction(或其子类,如KeyedProcessFunction)中发送,通过Context对象的output()方法,主输出仍通过Collector的collect()方法发送。
java
// 输入流(假设为 String 类型,存储待解析的事件数据)
DataStream<String> inputStream = env.fromSource(...);
// 处理输入流,生成主输出和侧输出
SingleOutputStreamOperator<String> mainStream = inputStream
.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, Context ctx, Collector<String> out) {
try {
// 主流程:解析数据并验证有效性
MyEvent event = parse(value); // 自定义解析方法
if (isValid(event)) { // 自定义验证方法
out.collect(format(event)); // 主输出:处理后的有效数据
} else {
// 侧输出:无效数据(格式合法但内容不符合业务规则)
ctx.output(INVALID_DATA_TAG, value);
}
} catch (Exception e) {
// 侧输出:解析失败的异常数据(如格式错误、字段缺失)
ctx.output(INVALID_DATA_TAG, value);
}
}
});3.3 步骤 3:获取侧输出流并处理
侧输出流需从主输出流(SingleOutputStreamOperator)中通过getSideOutput(OutputTag)方法提取,提取后可独立配置后续处理逻辑(如 map、sink 等)。
java
// 1. 提取侧输出流:无效数据
DataStream<String> invalidStream = mainStream.getSideOutput(INVALID_DATA_TAG);
// 2. 处理无效数据:添加错误标识并发送到告警系统
invalidStream
.map(error -> "ERROR: 无效数据 - " + error) // 自定义错误格式化
.addSink(new AlertSink()); // 自定义告警 Sink(如发送到钉钉、邮件)
// 3. 主输出流继续处理:发送到业务主存储
mainStream.addSink(new MainSink()); // 如写入 Kafka、HDFS 等四、Flink SQL 不支持侧输出的解决方案
Flink SQL 本身不支持显式定义侧输出,核心原因是其设计哲学为"声明式",强调逻辑表转换,而非过程式的数据流拆分。但可通过以下 3 种替代方案实现类似侧输出的分流效果。
4.1 替代方案 1:使用 CASE WHEN + 多 Sink(最常用)
通过CASE WHEN对数据打标,再根据标签筛选数据,写入不同 Sink,实现逻辑上的分流(非物理分流,数据会被多次扫描)。
plsql
-- 步骤1:创建视图,对数据进行打标(区分有效、无效、迟到数据)
CREATE VIEW tagged_data AS
SELECT
data, -- 原始数据字段
CASE
WHEN data IS NULL OR data = '' THEN 'invalid' -- 无效数据
WHEN CAST(ts AS BIGINT) < UNIX_TIMESTAMP() * 1000 THEN 'late' -- 迟到数据(假设ts为事件时间)
ELSE 'valid' -- 有效数据(主输出)
END AS data_type -- 数据类型标签
FROM input_table; -- 输入表
-- 步骤2:主输出:有效数据写入主存储
INSERT INTO main_sink
SELECT data FROM tagged_data WHERE data_type = 'valid';
-- 步骤3:侧输出替代:无效数据写入告警存储
INSERT INTO alert_sink
SELECT data FROM tagged_data WHERE data_type = 'invalid';
-- 步骤4:侧输出替代:迟到数据写入延迟处理存储
INSERT INTO late_sink
SELECT data FROM tagged_data WHERE data_type = 'late';优点 :纯 SQL 实现,无需编写 Java/Scala 代码,开发效率高;
缺点:数据会被多次扫描(每个 INSERT 都会扫描视图),性能略低,适合数据量不大的场景。
4.2 替代方案 2:SQL + DataStream 混合编程
结合 Flink SQL 的简洁性(处理主逻辑)和 DataStream API 的灵活性(实现侧输出),适合复杂分流场景。
java
// 1. 初始化 TableEnvironment,执行 SQL 主逻辑
TableEnvironment tEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode());
tEnv.executeSql("CREATE TABLE input_table (...) WITH (...)"); // 定义输入表
Table resultTable = tEnv.sqlQuery("SELECT data, ts FROM input_table WHERE data IS NOT NULL"); // SQL 处理主逻辑
// 2. 将 Table 转换为 DataStream(RetractStream 需过滤 insert 操作)
DataStream<Row> stream = tEnv.toRetractStream(resultTable, Row.class)
.filter(t -> t.f0) // t.f0 为 true 表示 insert 操作,过滤删除操作
.map(t -> t.f1); // 提取 Row 数据
// 3. 在 DataStream 中使用侧输出分流(复用前面定义的 OutputTag)
SingleOutputStreamOperator<Row> mainStream = stream.process(new ProcessFunction<Row, Row>() {
@Override
public void processElement(Row value, Context ctx, Collector<Row> out) {
Long ts = (Long) value.getField("ts");
if (ts < System.currentTimeMillis()) {
// 侧输出:迟到数据
ctx.output(LATE_DATA_TAG, value.getField("data").toString());
} else {
// 主输出:有效数据
out.collect(value);
}
}
});
// 4. 处理侧输出流(可选:转回 Table 继续用 SQL 处理)
DataStream<String> lateStream = mainStream.getSideOutput(LATE_DATA_TAG);
Table lateTable = tEnv.fromDataStream(lateStream, $("data").as("late_data"));
tEnv.createTemporaryView("late_output", lateTable);
tEnv.executeSql("INSERT INTO late_sink SELECT late_data FROM late_output");
// 5. 主输出流处理
mainStream.map(Row::toString).addSink(new MainSink());优点 :兼顾 SQL 的简洁性和侧输出的灵活性,适合复杂业务场景;
缺点:需要混合编程,增加代码复杂度,维护成本较高。
4.3 替代方案 3:利用内置侧输出(特定场景)
Flink SQL 的部分算子原生支持内置侧输出(如窗口的迟到数据),但截至 Flink 1.18,SQL 无法直接消费内置侧输出,仍需转换为 DataStream 后获取。
sql
-- Flink 1.17+ 支持:窗口迟到数据侧输出(需在 Sink 中启用)
CREATE TABLE windowed_sink (
user_id STRING,
order_count BIGINT,
window_start TIMESTAMP(3),
window_end TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'windowed_topic',
'sink.late-data.side-output' = 'true' -- 启用迟到数据侧输出
);
-- 窗口计算,迟到数据会被发送到内置侧输出
INSERT INTO windowed_sink
SELECT user_id, COUNT(order_id) AS order_count, window_start, window_end
FROM TABLE(TUMBLE(TABLE input_table, DESCRIPTOR(ts), INTERVAL '5' MINUTES))
GROUP BY user_id, window_start, window_end;说明:启用内置侧输出后,需通过 DataStream API 的getSideOutput()方法获取迟到数据,无法直接用 SQL 消费。
五、注意事项与最佳实践
5.1 最佳实践
-
标签命名规范:采用"业务场景-数据类型"命名,如
new OutputTag<>("alert-invalid-user") {},便于区分和维护; -
避免过度分流:单个算子的侧输出不宜超过 3~5 个,否则会导致业务逻辑混乱,难以排查问题;
-
监控侧输出量:定期监控侧输出流的数据量,若异常数据(如无效、迟到数据)突增,可能是上游数据源头故障,需及时告警;
-
主侧流程解耦:侧输出的处理逻辑应独立于主流程,例如使用独立的 Sink,避免侧输出处理失败影响主流程正常执行。
5.2 注意事项
-
序列化要求:
OutputTag的泛型类型必须实现Serializable接口,否则会出现序列化异常; -
作用域限制:侧输出流只能在定义它的算子下游立即获取,不能跨算子链(如经过多个 map、filter 后再获取,会报错);
-
Checkpoint 一致性:侧输出与主输出共享同一个 Checkpoint 机制,可保证数据的 exactly-once 语义,无需额外配置;
-
算子支持限制:只有
ProcessFunction及其子类(如KeyedProcessFunction、CoProcessFunction)支持发送侧输出,普通算子(如 map、filter)不支持。