Andrej Karpathy发表了一篇GitHub Gist,描述了"LLM Wiki",这是一种模式,其中大语言模型(LLM)构建并维护一个持久、累积的Markdown知识库,而不是像传统的检索增强生成(RAG)那样在每次查询时重新检索文档。
该架构有三层:原始数据源(不可变)、维基(由大语言模型维护的带交叉引用的Markdown文档)和模式(指导代理行为的配置)。个人规模下无需向量数据库。
社区出现了分歧:一半人认为检索增强生成(RAG)已经正式消亡,另一半人则认为卡帕西(Karpathy)只是给缓存层起了个花哨的名字。双方都有道理。
真正的洞见不是"检索增强生成(RAG)不好,维基百科好",而是知识应该积累,而不是消散。大语言模型(LLMs)终于在记录保存方面足够出色,使这一点切实可行。
企业可扩展性是一个避而不谈的问题:没有RBAC,没有ACID事务,没有并发控制。目前,这是个人知识工具,而非企业平台。
构建产品的要点
安德烈·卡尔帕西(Andrej Karpathy),他通过斯坦福大学的讲座向世界传授了神经网络的实际工作原理,他是OpenAI的联合创始人之一,他构建了特斯拉的自动驾驶视觉系统,他(再次)离开了OpenAI,此后一直在默默推出开源精品; 他发布了一个GitHub Gist。不是仓库,不是框架,也不是一个有47个依赖项和YAML配置的库,那种配置会让你质疑自己的职业选择。
要点。
一个Markdown文件。
整个AI社区都为之疯狂。在48小时内,一个零代码的文档获得了5000多个星标和1294个分支。
事情是这样的:该文档描述了一种名为"大语言模型维基"(LLM Wiki)的东西,这是一种构建个人知识库的模式,在这种模式中,大语言模型(LLM)不只是检索信息; 它编译、维护、交叉引用并持续丰富一个结构化的 Markdown 维基。每添加一个来源,知识就会不断积累。没有任何内容会消失在聊天历史中。
人们称它为RAG杀手。
让我们深入探讨。
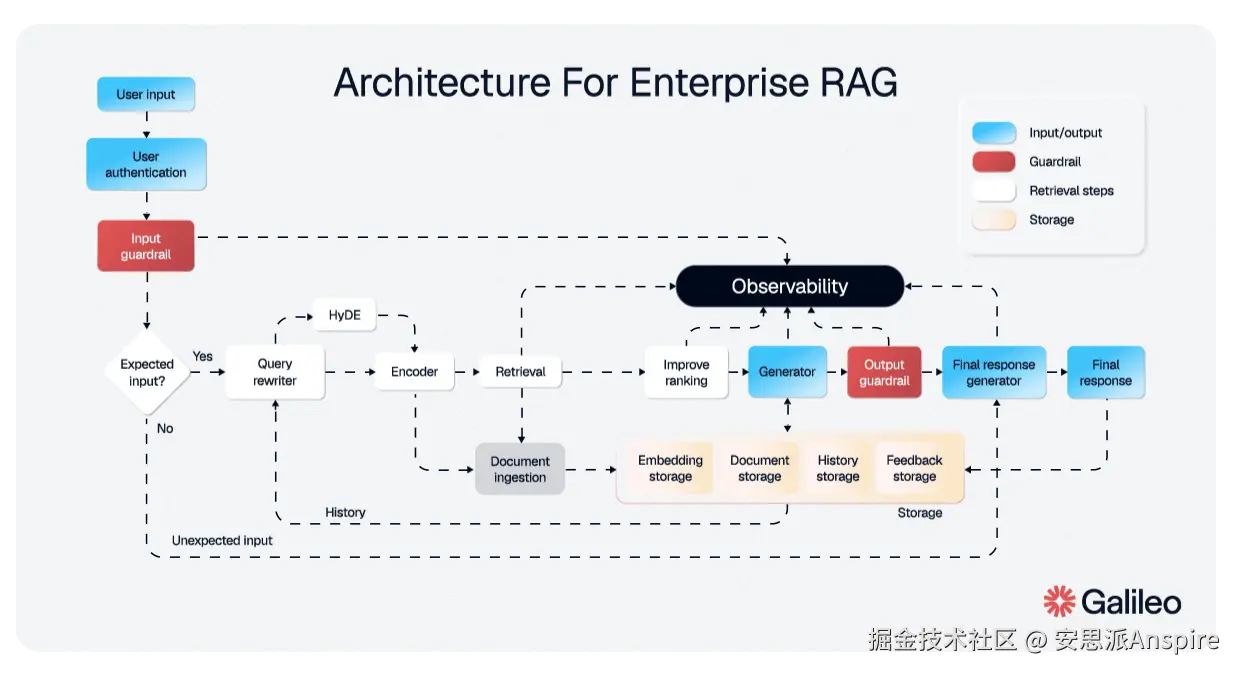
检索增强生成(RAG)究竟在做什么(以及人们为何感到厌烦)
说实话,大多数人使用检索增强生成(RAG)的体验......并不理想。这是大家都知道的流程:你上传文档。系统将它们分割成片段,有时分割得很智能,通常则不然。这些片段被嵌入到向量中并存储在数据库里。当你提问时,系统会检索出"最相似"的片段,将它们填充到上下文中,然后大语言模型(LLM)生成答案。
它有点作用。
问题很微妙,但后果却极具破坏性。每次查询都是一个全新的开始。大语言模型每次都要从头重新发现知识。没有积累,没有综合,也没有对上次得出结论的记忆。明天再问同样的问题,系统就会进行同样的检索过程,(运气好的话)找到相同的片段,(运气不好的话)则找到不同的片段。
但是等等。
分块问题甚至比无状态问题更严重。
当你将一篇40页的研究论文拆分成512个标记的片段时,你正在破坏上下文。关于Transformer注意力机制的段落与定义符号的段落被割裂开来。结论引用了第3节的研究结果,但第3节却在一个完全不同的片段中。嵌入向量可能会显示"这是相关的",但大语言模型(LLM)读到的却是一个无头无尾的句子。
社区对此已经呼吁了一年多。复杂的分块策略、重叠窗口、分层检索、重排序管道; RAG生态系统已成为一个为解决基本架构问题而拼凑出的鲁布·戈德堡机械。
信息是有结构的。分块会破坏这种结构。然后我们要花费大量的工程精力来试图重建我们原本就有的东西。
进入大语言模型维基百科
编译器,先于搜索引擎
卡帕西的见解简洁而精妙:如果大语言模型在查询时不检索原始文档会怎样? 如果它已经读完了所有内容,提取了关键信息,将其整理成一个带有交叉引用和实体页面的结构化维基,并持续更新整个内容,那又会怎样呢?
他使用的比喻非常恰当:黑曜石是IDE,大语言模型是程序员,维基是代码库。
你从不自己写维基。
你寻找资料。你探索。你提出问题。大语言模型做所有繁重的工作。
该架构有三层,而正是其简洁性使这种模式强大有力:
第一层:原始来源
这是你原始资料的不可变集合。文章、论文、抄本、笔记、图像。它们被放入raw/目录中,并保持原样,不做任何改动。把它们当作你的真实来源。
第二层:维基
这里就是奇迹发生的地方。大语言模型(LLM)读取原始资料,生成结构化的Markdown文件:每个资料的摘要、关键概念和实体的百科式文章、相关观点之间的交叉引用,以及一个对所有内容进行编目的主索引。一个资料可以同时关联10到15个维基页面。资料之间的矛盾会被标记出来。综合结果反映了系统所处理过的一切内容。
第三层:模式
一份配置文档(Karpathy使用CLAUDE.md),它告诉大语言模型(LLM)代理如何行事:维基的结构应该是什么样的,如何格式化页面,在摄取过程中该做什么,如何处理冲突。它是代理运作所依据的章程。
这可不是普通的RAG流程,差得远呢。
使其发挥作用的三项操作
该系统基于三项核心操作运行,它们形成一个自我强化的循环,随着时间的推移变得更加智能:
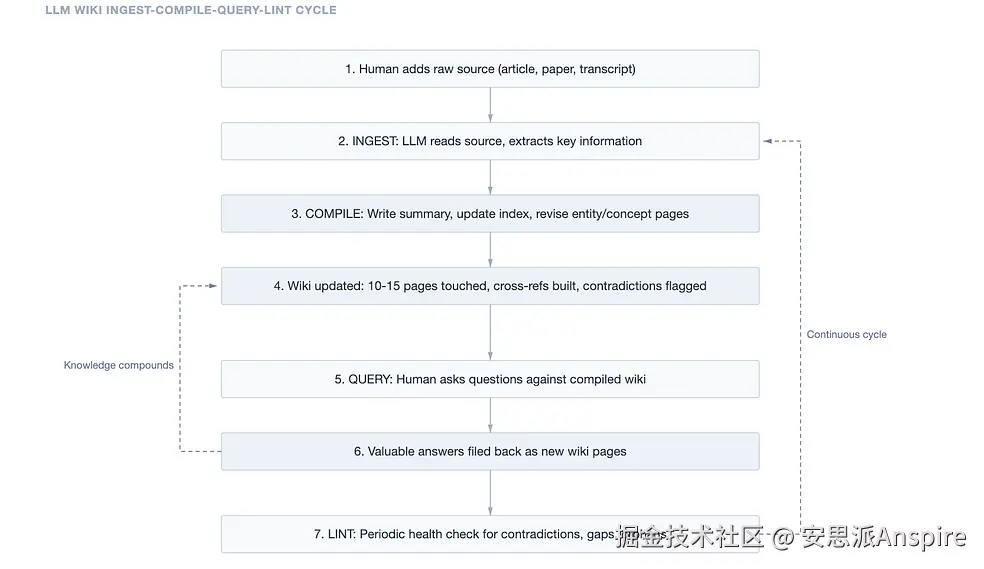
摄取是数据源进入系统的地方。
你将一篇新文章、论文或文稿放入原始集合中。大语言模型(LLM)会读取它,讨论关键要点,撰写摘要页面,更新主索引,然后; 关键部分来了; 会修订维基百科上所有相关的实体和概念页面。一篇关于变压器效率的论文可能会自动更新注意力机制、模型压缩、推理优化等页面,以及三个不同的研究人员实体页面,并且所有页面都相互关联。
查询是你询问维基百科的方式。
你提出一个问题。大语言模型(LLM)会搜索维基索引,调出相关页面,并从结构化、预编译的知识中综合出一个答案。不是片段,不是部分,而是它自己撰写的完整、连贯的文章。而真正有趣的地方在于:如果这个答案有价值,它就会成为一个新的维基页面。你在知识库中的探索会不断积累。
再读一遍。
你的问题让维基更智能。
Lint是维护周期。
大语言模型(LLM)会定期扫描整个维基百科,查找矛盾、过时的说法、孤立页面、缺失的概念和数据缺口。这是对你的知识库进行的一次健康检查。维基百科会自我修复。
这是他离开OpenAI后首个真正具有范式转变意义的研究模式。并非因为技术是新的; Markdown文件和大语言模型(LLM)智能体已经存在一段时间了。但由于这种框架重新定义了我们如何思考利用AI进行知识管理。
无人提及的万尼瓦尔·布什关联
哦!

卡帕西明确引用了万尼瓦尔·布什1945年提出的麦克斯存储器(Memex)。对于不了解的人来说,布什是二战期间美国科学研究与发展办公室的主任,他写了一篇具有前瞻性的文章《诚如我们所想》("As We May Think"),这篇文章实际上描述了现代互联网、个人知识管理和超链接信息系统; 在网络出现前50年。
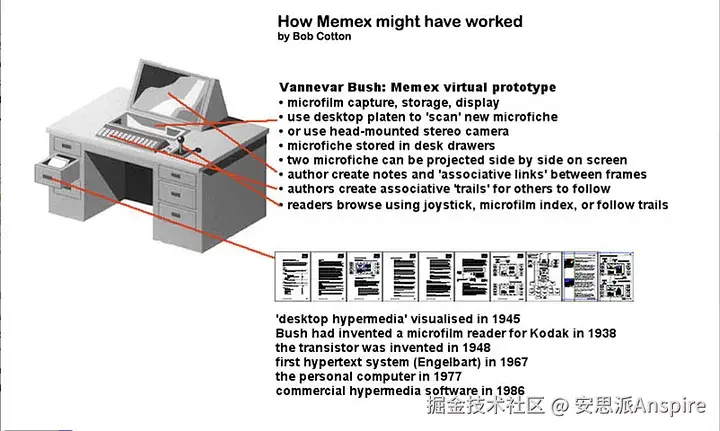
布什的"麦克斯存储器"是一种假想的设备,研究人员可以在其中存储所有书籍、记录和通信内容,通过"关联路径"将文档中相关的想法联系起来。这一设想是打造一个个人化、经过精心整理的知识宝库,使用得越多,其价值就越高。
布什无法解决的问题是维护。
谁来更新所有这些交叉引用?谁来阅读每一篇新论文并将其与每一篇相关的现有文档关联起来?当新发现与旧发现矛盾时,谁来标记?
人类。而人类每次都会抛弃维基。无一例外。
但大语言模型不会感到厌烦。它们不会忘记更新索引。它们不会因为是周五下午就跳过交叉引用。那些在实践中扼杀每个个人知识库的繁琐簿记工作; 这正是大语言模型(LLMs)独特擅长的地方。
卡帕西不仅构建了一个更好的检索增强生成(RAG)系统。
他解决了布什80年的维护问题。
如果生活如此简单,那我们几十年前就做到了。但事实并非如此。我们需要大语言模型(LLM)。
社区反应
围绕这个要点的讨论......很有意思。这个帖子在几个小时内就被剖析、辩论、分叉,并在互联网上被做成了表情包。而反应也分为截然不同的阵营。
狂热者视此为知识工作的未来。
人们指出,维基的持久性和累积性特质,恰恰解决了他们在使用传统检索增强生成(RAG)时遇到的障碍:反复提出相同问题,得到前后不一致的答案,且无法在前人见解的基础上进一步发展。一些人已经开始着手构建自己的实现方案。
一位开发者将llmwiki.app开源,通过MCP直接连接到Claude。另一位分享了他们独立开发的"知识合成引擎"。有人直接将要点提供给Hermes,让它当场为他们创建一个维基百科。
怀疑论者称其为缓存层的重塑。
他们的观点有其合理性。最尖锐的批评是什么?是Karpathy并没有扼杀RAG; 他只是重命名了缓存层。任何将大语言模型维基(LLM Wiki)作为新正统方法的人,都将在六个月后艰难地重新发现重复数据删除和陈旧数据失效的问题。
他们还指出,Claude Code已经在其智能搜索中使用:模型现在擅长文件搜索,让它们在更多上下文的情况下搜索文件,在许多用例中比分块文本搜索嵌入更有效。
缺失的一环是复合记忆。
实用主义者的观点可能最为有用:检索增强生成(RAG)在其适用范围内表现良好。缺失的环节是复合记忆。精心整理的笔记、引用以及定期更新,比每一轮都重新检索更有效。RAG和大语言模型维基(LLM Wiki)不一定是敌人; 它们是适用于不同规模和用例的不同工具。
还有怀疑者称其为"肤浅的炒作",认为每次启动Claude Code时,模型仅具备其训练知识,先通读技能和配置并不会让它变得更聪明。
嗯:( 不。
这完全没抓住重点。维基并不是在让模型变得更聪明,而是让知识变得可获取且结构化,这样模型就能有效地对其进行推理。将50个随机文档片段塞进上下文,与给模型一本它自己编纂的条理清晰的百科全书,这两者之间有着深刻的区别。
规模问题:100篇文章并非企业级
在这里,我们需要坦诚相待。
Karpathy报告称,在大约100篇文章、约40万字的规模下使用了这种模式。在这个规模下,模型通过摘要和索引页面进行导航的能力绰绰有余。大语言模型(LLM)可以读取索引、识别相关页面,并将其纳入上下文,因为现代的上下文窗口足够大,可以同时容纳一个索引和几篇完整的文章。
在10⁴、10⁵、10⁶个文件时会发生什么
...一个具有合规要求、基于角色的访问控制(RBAC)且支持50个代理同时编写的PB级企业知识库?
企业可扩展性方面的差距是真实存在的,且有充分的文献记载。
基于文件的Markdown系统没有RBAC机制;你无法限制代理访问敏感数据类别。
没有ACID事务保证;多个同时向同一维基页面写入的代理将产生竞态条件。
受监管行业没有防篡改的审计跟踪。
而平面文件系统根本无法满足大规模数据的性能需求。
这并非是对卡帕西工作的批评。他明确指出,该文档是有意抽象的,描述的是一种模式而非规定具体的实现方式。
目录结构、模式约定和工具取决于你的领域。他知道这是个人知识武器,而非企业平台。
但科技界总是充满兴奋的氛围,而兴奋往往会把个人工具变成过度承诺的企业级产品。我们以前就见过这样的情况。
为什么"仅仅更好的RAG"是错误的框架
社区中有些人认为这不过是"仍是检索增强生成(RAG),只是排序更好了"。
不完全是。
这种区别很重要,而且不仅仅是语义上的。传统的检索增强生成(RAG)是在查询时进行的检索操作。你进行搜索,找到文本块,然后生成内容。该系统是无状态的。每个查询都像是第一天开始一样。
大语言模型维基(LLM Wiki)是在摄取时进行的编译操作。当新的源数据进入系统时,大语言模型(LLM)不只是对其进行索引; 它读取信息、理解信息、将其整合到现有知识中、更新交叉引用、标记矛盾之处,并强化综合分析。在你提出问题之前,知识就以结构化、预编译的形式存在。
这就是搜索引擎和百科全书之间的区别。
谷歌(搜索引擎)可帮助你找到可能包含答案的网页。维基百科(汇编知识)则为你提供一篇结构化的文章,它整合了来自数百个来源的信息,有交叉引用、参考文献和编辑监督。
检索增强生成(RAG)是搜索引擎。
大语言模型维基百科是一部百科全书。
两者都有用。本质上不同的架构解决本质上不同的问题。

真正有意义的用例
Karpathy列举了几个用例,其中一些比其他的更有说服力:
个人知识管理是杀手级应用。
跟踪目标、健康指标、心理笔记。将日记条目与研究文章一并归档。随着时间的推移,构建一个结构化的自我画像。这种方法之所以有效,是因为其规模本质上是个人化的(是数百份文档,而非数百万份),而且当系统在数月时间里了解到单一用户的背景信息时,知识复利的价值是最高的。
研究综合是这种模式真正优于检索增强生成(RAG)的地方。
数月来阅读论文,构建一个随着论点不断发展的综合维基,观察新发现如何修正或与早期发现相矛盾; 这是任何研究人员梦寐以求的工作流程。维基成为你外化的理解,由一个永远不会忘记更新交叉引用的代理维护。
读书的力量大得惊人。
在阅读过程中构建一个粉丝维基。人物、主题、情节线索,全部相互参照,全部随着新章节揭示新信息而更新。对于内容丰富的小说或复杂的非虚构作品,这真的很有用。
业务运营经理
这就是事情变得有趣的地方,也是可扩展性问题开始显现的地方,但它仍然可能非常有用。将Slack线程、会议记录和客户电话内容整合到维基中听起来不可思议。维基能够保持最新状态,因为AI承担了没人愿意做的维护工作。但这也是你需要RBAC、审计跟踪和并发控制的地方。"炫酷模式"与"生产系统"之间的差距是企业工程的护城河。
黑曜石赌注与工具生态系统
关键不在规模,而在生态系统。
Karpathy选择Obsidian作为人机界面是经过深思熟虑且明智的。既然已有现成的东西,为何还要重新发明呢。(尽管我对Obsidian的闭源模式有意见......改天再吐槽吧)。
Obsidian的图谱视图揭示了维基中的结构模式:哪些概念是中心(高度关联),哪些是孤立的(无关联),维基中哪些地方有密集的知识集群,哪些地方存在空白。Dataview插件可对页面元数据进行动态查询。Marp可根据维基内容生成幻灯片。而且由于维基只是文件夹中的Markdown文件,它会自动成为一个拥有完整版本历史的git仓库。
社区已经在朝着有趣的方向拓展这一功能。短短几天内就涌现出了多个实现方案:llmwiki.app、Obsidian-Wiki集成,以及企业团队将该模式应用于半导体知识管理和服务交付文档。有人通过MCP服务器将其直接连接到Claude,这意味着你可以在AI代理内部与你的Wiki进行对话。
工具的融合是实实在在的。像qmd这样的本地混合搜索工具提供了BM25/向量搜索和大语言模型重排序功能。Obsidian网页剪辑器可以一键将任何网页文章转换为Markdown格式。从"我发现一篇有趣的文章"到"我的维基知识库更新了新知识"的整个流程正趋近于零摩擦。
但如果你正打算将整个公司的知识基础设施构建在Obsidian库中的Markdown文件之上......也许先深呼吸一下。
无人讨论的微调终局
接下来才是真正疯狂的地方。
Karpathy模式中最容易被低估的一个方面是他所暗示的未来方向:从维基百科生成合成训练数据来微调模型。想想这意味着什么。你花几个月时间建立一个关于你的领域的全面、相互参照、标记矛盾的维基百科。然后你用这个维基百科来生成训练示例。然后你在这些示例上微调一个模型。
知识从上下文窗口转移到模型权重。
你的个人维基百科变成了一个个人模型。
逻辑上的下一步是让模型利用新知识重建其权重。维基是中间表示形式。编译后的知识库是一个等待成为模型的数据集。
这对RAG行业意味着什么
我们得把一件事说清楚。检索增强生成(RAG)并没有消亡,甚至还差得远。RAG能在大语言模型维基(LLM Wiki)无法发挥作用的规模上解决实际问题:处理数百万份文档、应对不可预测的查询、处理实时数据,以及满足有严格安全要求的多租户企业部署需求。
暂时无法在飞书文档外展示此内容
但这种批评是有道理的
但这种批评是有道理的。对于个人知识库、研究项目、小团队维基以及规模在数百到数千份文档的特定领域知识管理来说呢? 大语言模型维基模式明显更优。
预编译的结构化知识完全消除了分块问题。
复合循环意味着系统会随着使用而不断改进。维护自动化解决了导致每个个人维基失败的废弃问题。
那些凭借向量数据库和检索管道打造出价值数十亿美元业务的RAG供应商应该予以关注。这并非因为LLM Wiki如今就能取代他们的企业级产品,而是因为这种模式揭示了该行业一直回避的一个真相:
大多数检索增强生成(RAG)的实现对于用户实际需求而言过度设计,而对于用户实际期望而言则设计不足。
用户想要的不是检索,而是知识。这两者是有区别的。
创新总能带来成果。但有时,创新并非来自拥有5000万美元B轮融资的初创企业,而是源自GitHub上的一个简单的Markdown文件。
模式即产品
我一直在思考的是,Karpathy并没有发布软件,他发布的是一种模式、一个创意文档、一份你应该交给大语言模型代理并说"和我一起构建这个"的文件。实现细节故意模糊,因为具体内容取决于你的领域、工具、规模和偏好。
有些人觉得这很令人沮丧。他们想要一个可以克隆的仓库、一个可以运行的 Docker Compose、一个可以注册的 SaaS。而这些都即将到来;社区已经在着手构建它们了。
但发布模式而非产品的力量在于,它鼓励的是适配而非采用。每次实施都会不同,因为每个知识领域都不同。半导体工程师的维基百科不会像小说读者的维基百科,也不会像初创公司创始人的维基百科。而这正是关键所在。
这是我的观点。你应该做自己觉得舒服的事。
但如果你对检索增强生成(RAG)感到沮丧,如果你觉得你的AI工具在对话结束的那一刻就把一切都忘了,如果你因为维护负担过重而放弃了Notion数据库和Obsidian库; Karpathy刚刚为你提供了一个让大语言模型(LLM)进行维护的蓝图。
人类负责筛选信息源、指导分析、提出有价值的问题,并思考意义。
大语言模型处理其他所有事情。