目录
[一、先分清:ReAct 和 Agent Loop 不是一回事](#一、先分清:ReAct 和 Agent Loop 不是一回事)
[1. ReAct:经典的"边想边做"范式](#1. ReAct:经典的“边想边做”范式)
[2. Claude Code 的 Agent Loop:工程化执行范式](#2. Claude Code 的 Agent Loop:工程化执行范式)
[3. 两者的关键差异](#3. 两者的关键差异)
[二、为什么云产品智能诊断不能只用 ReAct](#二、为什么云产品智能诊断不能只用 ReAct)
[1. 上下文爆炸](#1. 上下文爆炸)
[2. 过早收敛](#2. 过早收敛)
[3. 缺少客观完成标准](#3. 缺少客观完成标准)
[4. 难以恢复](#4. 难以恢复)
[四、案例:一个 Pod 启动失败的问题如何被分层诊断](#四、案例:一个 Pod 启动失败的问题如何被分层诊断)
[ReAct 层如何处理](#ReAct 层如何处理)
[Worker 层如何验证](#Worker 层如何验证)
[Verifier 如何确认](#Verifier 如何确认)
[1. 把任务拆成多轮原子检查](#1. 把任务拆成多轮原子检查)
[2. 每一轮检查都由外部执行机制驱动](#2. 每一轮检查都由外部执行机制驱动)
[3. 失败后不会停在原地,而是进入下一轮](#3. 失败后不会停在原地,而是进入下一轮)
[4. 最后还有 Verifier 做终态验收](#4. 最后还有 Verifier 做终态验收)
[1. 工具要按 ACI 原则设计](#1. 工具要按 ACI 原则设计)
[2. Trace 必须全量记录](#2. Trace 必须全量记录)
[3. 安全边界先于功能](#3. 安全边界先于功能)
[4. 状态压缩要可回退](#4. 状态压缩要可回退)
在云产品里做智能诊断,最难的从来不是"让模型说出一个答案",而是让系统在一堆不完整、噪声很大、还彼此冲突的信号里,持续收敛到一个能验证、能恢复、能复盘的结论 。
告警可能只告诉你"Pod 起不来了",日志可能只给你一行 ImagePullBackOff,配置里可能还混着上一版遗留参数。真正的问题不是"看见了报错",而是怎么把报错变成可执行的诊断路径。
这也是为什么,云产品智能诊断不能只靠一种 Agent 范式。
如果只用 ReAct,容易在长链路里陷入上下文膨胀;如果只用 Ralph Loop,虽然能强制推进执行,却又缺少高层路由和全局判断。更适合生产环境的方案,是一种分层混合架构:
ReAct 负责规划,Claude Code 式 Agent Loop 负责执行与收敛,状态外化负责持久化与恢复。
一、先分清:ReAct 和 Agent Loop 不是一回事
1. ReAct:经典的"边想边做"范式
ReAct 的核心是让模型在每一步都经历:
- 观察当前状态
- 在上下文中推理
- 调用工具执行
- 根据新观察继续下一步
它的优势是灵活,特别适合动态环境中的即时调整。
但它的执行边界主要在上下文内部,因而有几个天然问题:
- 上下文会越来越长,日志、指标、trace、配置 diff 全塞进去后,模型注意力会被稀释
- 模型容易过早收敛,在证据不足时就判断"差不多了"
- 容错能力有限,前面一步判断错了,后面往往会沿着错误假设继续跑
所以,ReAct 更像一种认知范式,擅长"怎么想",但不天然擅长"怎么稳定做完"。
2. Claude Code 的 Agent Loop:工程化执行范式
Claude Code 风格的 Agent Loop 更强调的是把任务推进到客观完成 。
它的重点不是让模型一直思考,而是把整个执行过程工程化:
- 工具调用有明确边界
- 状态需要落盘
- 失败可以重启
- 结果必须可验证
- 终止条件由外部机制决定,而不是由模型主观判断
如果说 ReAct 关心的是"下一步该怎么想",那 Agent Loop 关心的是:
这件事到底有没有真的做完?
因此,Claude Code 式 Agent Loop 更像一种执行型循环,而不是纯推理型循环。
3. 两者的关键差异
|------|--------------------|--------------------------|
| 对比项 | ReAct | Claude Code 式 Agent Loop |
| 核心目标 | 在上下文内推理并行动 | 把任务持续推进到客观完成 |
| 控制主体 | LLM 决定下一步 | 外部系统、工具、状态与验证机制共同控制 |
| 终止条件 | 模型主观判断 | 外部验证通过才算完成 |
| 状态管理 | 主要在上下文里 | 主要外化到文件、Git、数据库 |
| 容错方式 | 在当前上下文里修正 | 失败后重启、重试、重新加载状态 |
| 适合任务 | 开放式问答、动态决策、短链路工具调用 | 编程、调试、重构、长任务执行 |
一句话总结:ReAct 是"怎么想",Agent Loop 是"怎么做完"。
二、为什么云产品智能诊断不能只用 ReAct
云产品智能诊断看起来像推理任务,但本质上是一个长链路的工程排障任务。它通常同时涉及:
- 告警信息
- 监控指标
- 日志
- 配置 diff
- 发布记录
- 拓扑依赖
- 历史事故经验
如果只用 ReAct,容易出现以下问题:
1. 上下文爆炸
每一步都把原始日志、指标和推理结果堆进上下文,模型很快就会失去重点,出现 Context Rot。
2. 过早收敛
模型可能在证据还不充分时,就给出一个"看起来合理"的根因。
在云运维里,这种"合理"并不等于"真实"。
3. 缺少客观完成标准
云诊断不是"解释通了就算完",而是要看:
- 服务是否恢复
- HTTP 200 是否回来
- 健康检查是否通过
- 指标是否回落
- Pod 是否 Ready
4. 难以恢复
一旦某轮推理偏了,错误会一路往后传,后面的判断会越来越难纠正。
所以,云诊断不能只靠 ReAct,而要引入更工程化的执行和验证机制。
三、云产品智能诊断的最优解:分层混合架构
更合理的方式,是把云诊断拆成三层:
第一层:规划与路由层
模式:ReAct
这一层负责接收模糊告警,识别问题类型,拆解诊断路径,并决定接下来调用哪些工具或子 Agent。它的职责不是修复,而是把一个模糊故障拆成一组可验证假设。
例如,当输入是"ECS 实例无法访问"时,ReAct 层可以先生成如下诊断路径:
- 检查实例状态
- 检查网络连通性
- 检查安全组
- 检查下游依赖
- 检查最近变更
这一层的核心能力是路由,不是执行。
第二层:执行与验证层
模式:Harness 约束下的原子检查
这一层负责具体动作,例如:
- 查日志
- 查指标
- 查实例状态
- 查配置
- 查健康检查
- 查网络连通性
但它不是自由执行,而是被 Harness 约束:
- 只能读允许范围内的数据
- 必须输出结构化结果
- 不允许擅自修复
- 失败时必须返回可验证错误码
也就是说,Worker Agent 不是"自由推理",而是在严格边界下执行原子任务。
执行层不是让 Agent 更自由,而是让它更可控。
第三层:状态管理层
模式:状态外化 / 持久化记忆
云诊断常常是多轮、多步、跨时间的任务。
如果把所有中间结果都放在上下文里,迟早会超限。
所以更稳妥的方式,是将诊断过程状态化:
- 当前假设列表
- 每个 Worker 的检查结果
- 已排除的故障分支
- 证据权重
- 当前置信度
- 下一步计划
这些状态写入 JSON 文件、数据库或事件流,下一轮 ReAct 只读取摘要,而不是完整原始日志。这样既能缩短上下文,又能支持断点恢复。
状态外化不是优化项,而是长链路诊断的前提。
四、案例:一个 Pod 启动失败的问题如何被分层诊断
Deployment 更新后,Pod 起不来,状态一直是 ImagePullBackOff。
现象
执行:
kubectl get pods看到:
my-app-5d7d978fb9-2fj5m 0/1 ImagePullBackOff 0 2m这说明 Pod 甚至还没真正进入容器启动阶段,就已经在拉镜像环节失败了。
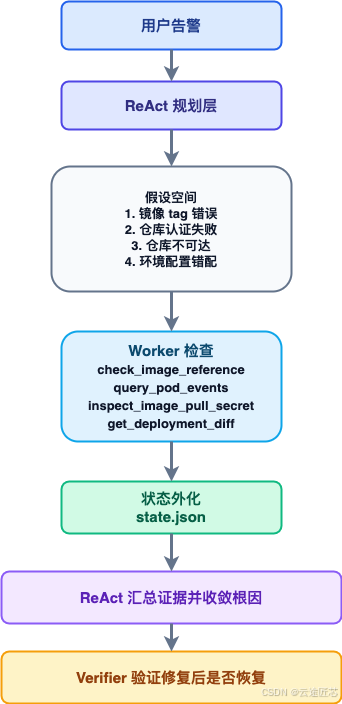
ReAct 层如何处理
ReAct 层先不急着下结论,而是把问题拆成候选方向:
- 镜像 tag 是否写错
- 私有仓库认证是否失败
- 镜像仓库是否不可达
- 是否命中了错误的环境配置
- 是否是发布时镜像未同步
这里的重点不是立即修,而是生成假设空间。
Worker 层如何验证
执行层调用结构化工具,例如:
check_image_referencequery_pod_eventsinspect_image_pull_secretget_deployment_diff
每个 Worker 只返回事实,例如:
{
"check": "image_reference",
"image": "myrepo/my-app:v2.0",
"status": "missing_tag"
}或者:
{
"check": "pod_event",
"reason": "Failed to pull image",
"detail": "manifest not found"
}状态外化层如何记录
这些结果被写入 state.json:
image_tag = v2.0image_exists = falsepod_status = ImagePullBackOffpull_reason = manifest not found
下一轮 ReAct 读取摘要后,就能收敛到:
部署镜像 tag 写错,仓库中不存在该镜像,导致 Pod 无法拉取镜像,从而一直处于 ImagePullBackOff。
Verifier 如何确认
最后再验证修复是否生效:
- 镜像 tag 修正后,Pod 是否恢复运行
kubectl get pods是否变成Running- 服务是否通过 readiness probe
- 业务是否可访问
如果都通过,任务才算完成。
五、流程图说明:诊断系统应该怎么跑
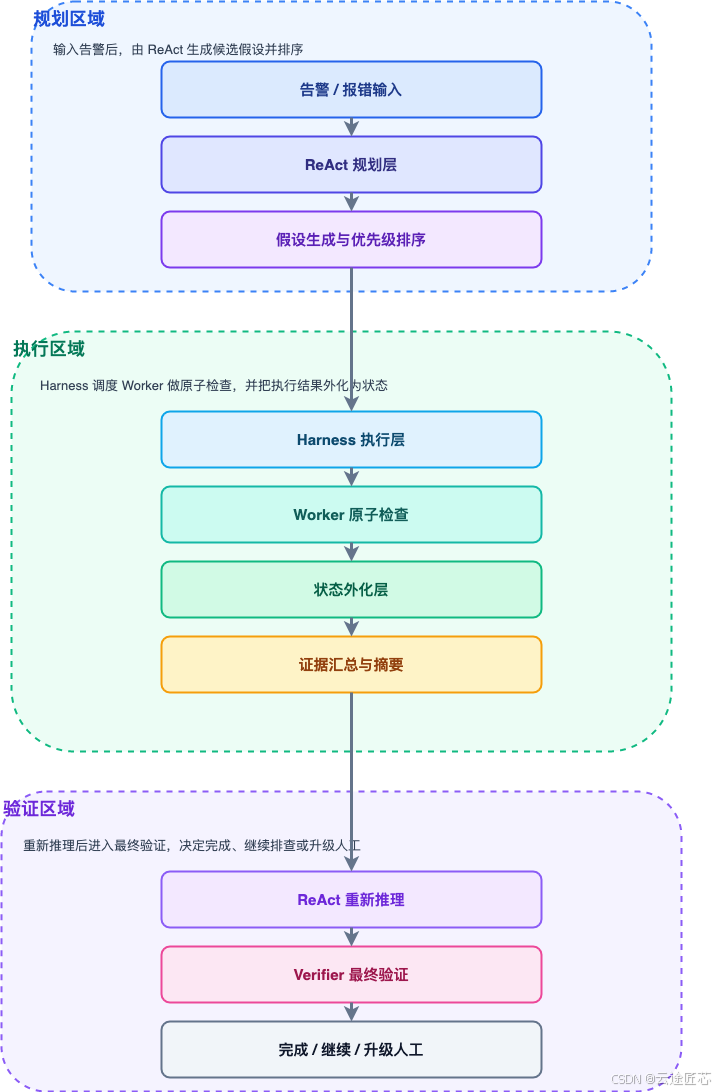
这个流程图表达的核心含义
- 先规划,再执行
- 执行必须受约束
- 中间结果必须可持久化
- 最后一定要验证
- 不通过就不能算结束
六、为什么要强调"持续推进检查动作"
这一点其实正是 Claude Code 式 Agent Loop 和 ReAct 最重要的区别之一。
1. 把任务拆成多轮原子检查
不是一次性让模型给结论,而是先由 ReAct 规划,再由 Worker Agent 逐项检查,比如:
- 查镜像是否存在
- 查 Pod 事件
- 查 imagePullSecret
- 查部署 diff
这体现了"持续推进检查动作",而不是单轮回答。
2. 每一轮检查都由外部执行机制驱动
Agent Loop 不是靠模型自己想"差不多了"就停,而是通过外部系统、工具、状态与验证机制共同控制。
也就是说,检查动作会一直推进,直到外部验证通过。
3. 失败后不会停在原地,而是进入下一轮
如果某个 Worker 检查发现镜像 tag 缺失、Pod 仍处于 ImagePullBackOff,这些结果会被写入状态,再进入下一轮 ReAct 重新推理和继续检查。这个循环就是"持续推进"的具体表现。
4. 最后还有 Verifier 做终态验收
文章里不是"查到一个可能原因就结束",而是还要再验证 Pod 是否恢复、是否变成 Running、readiness probe 是否通过。只有验证通过,整个 Loop 才真正结束。
这四点合起来,才真正体现了 Claude Code 式 Agent Loop 的价值:
不是一次性给结论,而是把排查动作持续推进到可验证终态。
七、工程实现上的关键点
1. 工具要按 ACI 原则设计
工具不是暴露底层 API,而是暴露诊断动作。
例如:
check_network_connectivityget_instance_statusinspect_security_groupquery_recent_deployment_diff
工具描述里要包含适用边界、输入约束和 few-shot 示例。
2. Trace 必须全量记录
每一轮 ReAct 推理、每个 Worker 调用、每个 Harness 验证都要记录。
否则你无法区分:
- 是规划错了
- 还是执行错了
- 还是验证错了
3. 安全边界先于功能
云诊断 Agent 可能有读权限,也可能最终需要触发修复动作。
因此必须先做:
- 白名单授权
- 工作空间隔离
- 操作审计
- 敏感动作人工确认
4. 状态压缩要可回退
状态外化不能只做摘要,还要保留原始证据,防止摘要误导后续推理。
八、总结
云产品智能诊断的核心,不是"让模型更会猜",而是让系统更会收敛 。
真正可上线的 Agent,不是靠一次性回答,而是靠一整套闭环机制:
- ReAct 负责把模糊问题拆成可执行假设
- Claude Code 式 Agent Loop 负责把检查动作持续推进
- Harness 负责限制风险、保证输出可验证
- 状态外化负责让任务跨轮次、跨时间继续
- Verifier 负责在最后把"看起来对"变成"真的对"
所以,云诊断系统的目标不是让 LLM 替代运维,而是让 LLM 成为可控的诊断引擎。它要做的,不是替人拍脑袋,而是把证据链拉直,把故障边界收窄,把恢复路径变清晰。