文章目录
alloc
alloc和init的源码分析的流程大概如下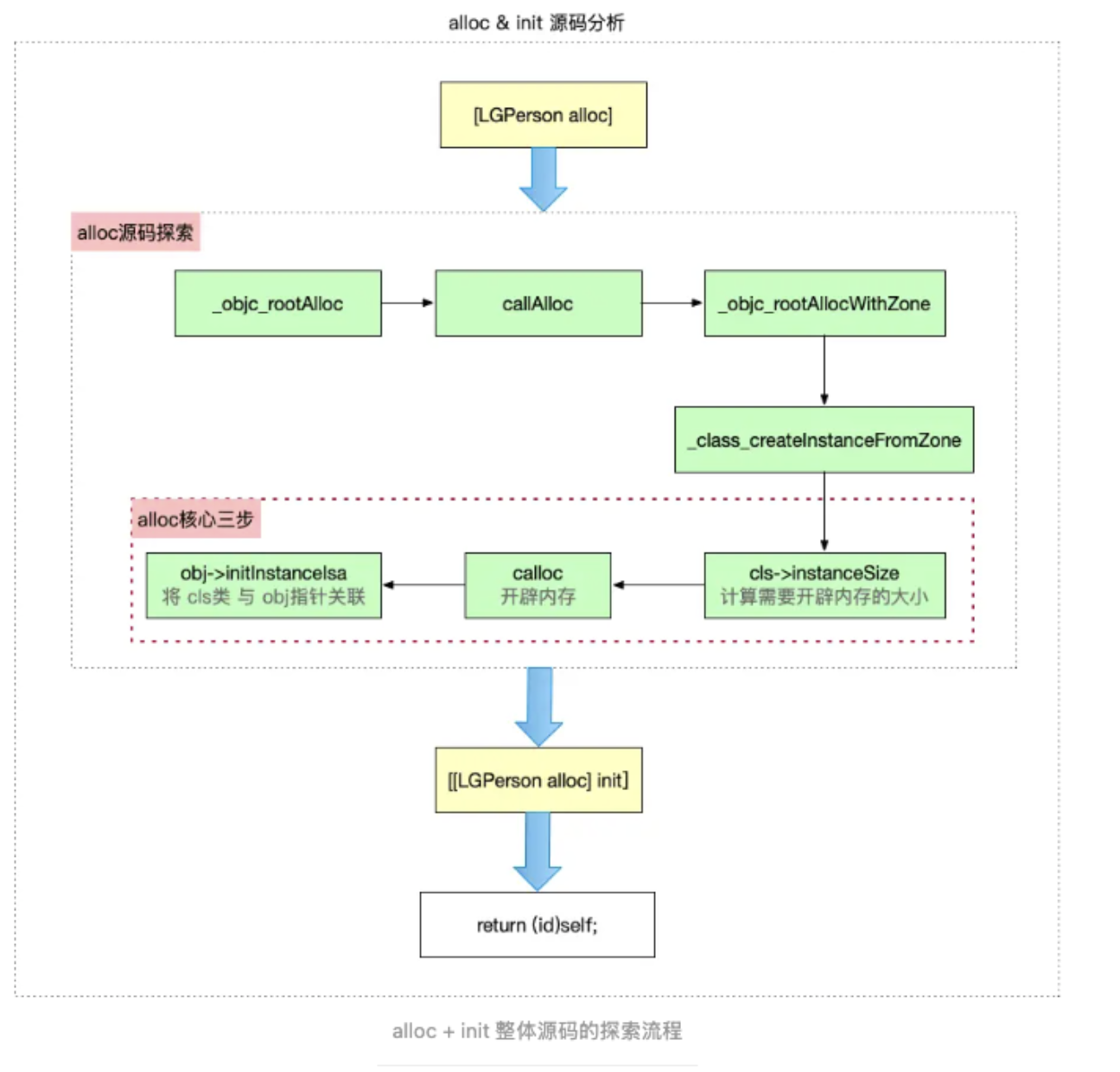
oc对象的创建是从alloc开始的
objc
GGObject *obj = [[GGObject alloc] init];我们在这里打个断点,进行逐步跳转
c++
+ (id)alloc {
return _objc_rootAlloc(self);
}第二步跳到下面_objc_rootAlloc实现
c++
id
_objc_rootAlloc(Class cls)
{
return callAlloc(cls, false/*checkNil*/, true/*allocWithZone*/);
}第三步跳转到callAlloc的源码实现
c++
static ALWAYS_INLINE id
callAlloc(Class cls, bool checkNil, bool allocWithZone=false)
{
if (slowpath(checkNil && !cls)) return nil;
if (fastpath(!cls->ISA()->hasCustomAWZ())) {
return _objc_rootAllocWithZone(cls, nil);
}
// No shortcuts available.
if (allocWithZone) {
return ((id(*)(id, SEL, struct _NSZone *))objc_msgSend)(cls, @selector(allocWithZone:), nil);
}
return ((id(*)(id, SEL))objc_msgSend)(cls, @selector(alloc));
}然后我们之间command加slowpath,fastpath就可以看到这两个宏:
c++
//x很可能为真,fastpath可以简称为 真值判断
#define fastpath(x) (__builtin_expect(bool(x), 1))
//x很可能为假,slowpath可以简称为 假值判断
#define slowpath(x) (__builtin_expect(bool(x), 0))这里的__builtin_expect指令是由gcc引入的
- 目的是编译器可以对代码进行优化,来减少指令跳转带来的性能下降,即性能优化
- 作用:允许程序员把最可能执行的分支告诉编译器
- 指令的写法是__builtin_expect(EXP, N)表示EXP==N的概率很大
- fastpath中__builtin_expect(bool(x), 1)表示x的值为真的可能性更大,即执行if里的语句的机会更大
- slowpath中__builtin_expect(bool(x), 0)表示x的值为假的可能性更大,即执行else里的语句的机会更大
cls->ISA()->hasCustomAWZ()
上面callAlloc方法的fastpath里的cls->ISA()->hasCustomAWZ()表示判断一个类有无自定义的+allocWithZone实现,这里没写的话会直接跳转到里面的_objc_rootAllocWithZone函数:
c++
id
_objc_rootAllocWithZone(Class cls, objc_zone_t)
{
// allocWithZone under __OBJC2__ ignores the zone parameter
return _class_createInstance(cls, 0, OBJECT_CONSTRUCT_CALL_BADALLOC);
}然后会跳转到下面的_class_createInstance
部分版本不同会导致方法名或者里面细节的改变,其他版本这里已经不在按照zone分配内存,而是把对象内存的分配封装进了新版本objc::malloc_instance(size, cls)
这里的实现也主要分了三部分:
- size = cls->instanceSize(extraBytes);,计算需要开辟的内存空间的大小
- 申请内存,拿到对象地址,在这里对应的就是id obj = objc::malloc_instance(size, cls);这里虽然表面没出现其他版本里的 calloc,但它干的还是"申请内存"这件事。
- 设置isa,让对象和类关联起来,也就是initInstanceIsa / initIsa
c++
static ALWAYS_INLINE id
_class_createInstance(Class cls, size_t extraBytes,
int construct_flags = OBJECT_CONSTRUCT_NONE,
bool cxxConstruct = true,
size_t *outAllocatedSize = nil)
{
ASSERT(cls->isRealized());
// Read class's info bits all at once for performance
bool hasCxxCtor = cxxConstruct && cls->hasCxxCtor();
bool hasCxxDtor = cls->hasCxxDtor();
bool fast = cls->canAllocNonpointer();
size_t size;
size = cls->instanceSize(extraBytes);
if (outAllocatedSize) *outAllocatedSize = size;
id obj = objc::malloc_instance(size, cls);
if (slowpath(!obj)) {
if (construct_flags & OBJECT_CONSTRUCT_CALL_BADALLOC) {
return _objc_callBadAllocHandler(cls);
}
return nil;
}
if (fast) {
obj->initInstanceIsa(cls, hasCxxDtor);
} else {
// Use raw pointer isa on the assumption that they might be
// doing something weird with the zone or RR.
obj->initIsa(cls);
}
if (fastpath(!hasCxxCtor)) {
return obj;
}
construct_flags |= OBJECT_CONSTRUCT_FREE_ONFAILURE;
return object_cxxConstructFromClass(obj, cls, construct_flags);
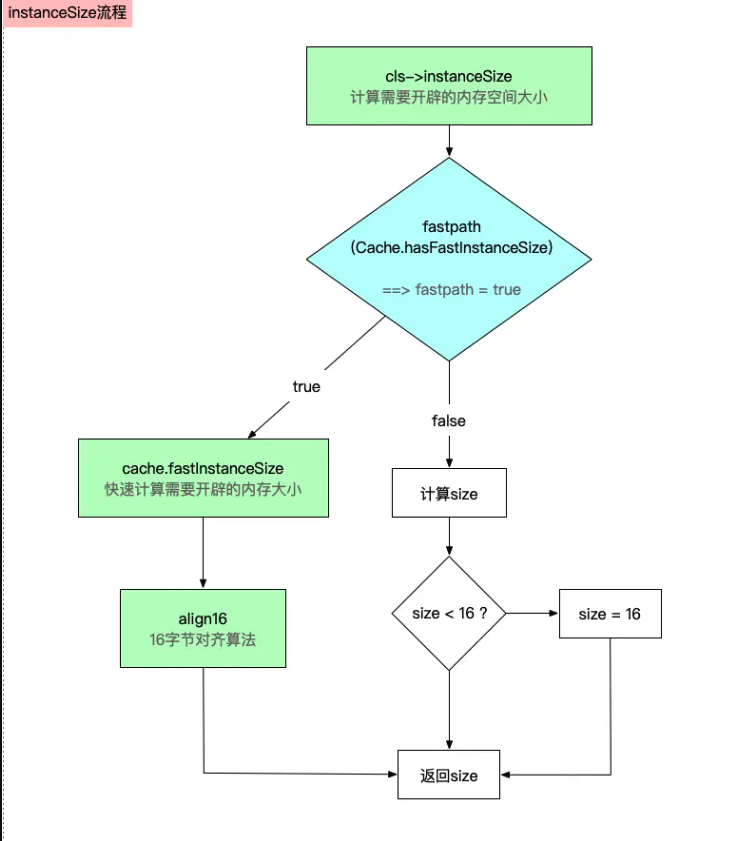
}我们来看这里的cls->instanceSize,这里是用来计算开辟内存所需要的内存大小
计算需要开辟内存大小的大致流程如下
-
先是跳转到下面这个函数方法
c++inline size_t instanceSize(size_t extraBytes) const { //编译器快速计算内存大小 if (fastpath(cache.hasFastInstanceSize(extraBytes))) { return cache.fastInstanceSize(extraBytes); } //计算类中的所有属性的大小 + 额外的字节数 size_t size = alignedInstanceSize() + extraBytes; //若是size小于16,最小就取16 // CF requires all objects be at least 16 bytes. if (size < 16) size = 16; return size; } -
接下来就会跳转到fastInstanceSize这个方法这块
c++size_t fastInstanceSize(size_t extra) const { ASSERT(hasFastInstanceSize(extra)); //Gc c的内建函数__builtin_constant_p用于判断一个值是否为编译时常数,若参数EXP的值是常数,函数返回1,否则返回0 if (__builtin_constant_p(extra) && extra == 0) { return _flags & FAST_CACHE_ALLOC_MASK16; } else { size_t size = _flags & FAST_CACHE_ALLOC_MASK; // remove the FAST_CACHE_ALLOC_DELTA16 that was added // by setFastInstanceSize //删除setFastInstanceSize添加的FAST_CACHE_ALLOC_DELTA16 8个字节,会将输入值向上舍入(round up)到最近的16字节对齐的地址,提高访问效率 return align16(size + extra - FAST_CACHE_ALLOC_DELTA16); } } -
然后跳转到align16这个实现
c++static inline size_t align16(size_t x) { return (x + size_t(15)) & ~size_t(15); }这个方法是16字节对齐算法
内存对齐原则
- 数据成员对齐规则:struct或union的数据成员第一个数据成员放在offset为0的地方,以后每个数据成员的存储起始位置都要从该成员大小或者该成员的字成员大小的整数倍开始(只要该成员有子成员)比如int在32位机中是4字节,那么要从4的整数倍地址开始进行存储
- 数据成员为结构体:若一个结构体里有某些结构体成员,那么结构体成员要从其内部最大的元素的大小的整数倍开始进行存储(比如:struct(a)里面存有struct(b),b里面有char、int、double等元素,则b应该从8的整数倍开始存储)
- 结构体整体的对齐规则:结构体的总大小,即sizeof的结果必须是其内部最大成员的整数倍,不足的要补齐
为什么需要16字节对齐
-
内存通常由一个个字节组成的,CPU每次访问内存的时候都是按照固定大小的数据块来读取的,而不是一字节一字节读的,常见情况(以现代 64 位 CPU 举例),若是频繁存取字节未对齐的数据会极大的降低cpu的性能,所以可以通过减少存取次数来降低cpu的开销
- CPU 一次最自然读取:8 字节(64位)
- Cache line:64 字节(更大一块)
存取力度也叫内存访问粒度(memory access granularity)
-
16字节对齐是因为首先iOS/macOS系统内存分配默认是16字节对齐,oc对象也要遵循这个原则,且现代cpu有simd指令一次处理16字节/128位,不对齐会导致性能下降,且cache line是64字节,16字节对齐更有利于排列且让cache更容易命中利于整体的性能优化
Cache命中是指CPU访问数据时,在高速缓存中直接找到所需数据,无需访问主内存,从而大幅提升访问速度。由于缓存按cache line(通常64字节)为单位加载,如果数据未对齐或跨越多个cache line,会降低命中率并增加访问次数,从而影响性能
这是字节内存对齐函数的操作流程
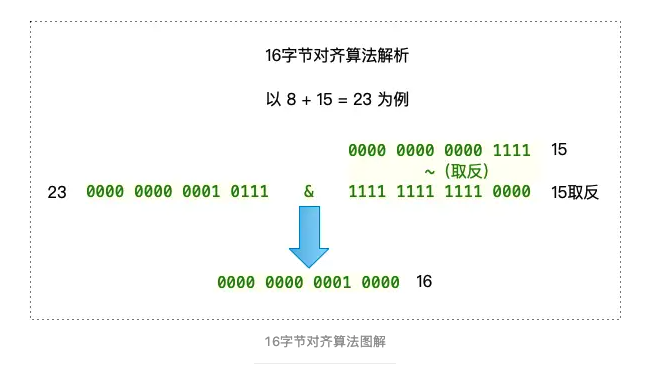
这里加15的原因是将数值提升到下一个16的区间,从而实现向上取整
& ~15是通过将低4位清零,让结果变为16的倍数
两者结合 (x + 15) & ~15 可以得到不小于 x 的最小16的整数倍,从而用于计算内存对齐后的大小。
下来就是申请内存,主要就是在_class_createInstance的下面这一段,我们可以打断点进行调试
c++
id obj = objc::malloc_instance(size, cls);这里其他版本使用的calloc其实我们再进入这个方法发现其内部实现其实也都一样,都是下面
c++
static inline id
malloc_instance(size_t size, Class cls __unused)
{
#if _MALLOC_TYPE_ENABLED
malloc_type_descriptor_t desc = {};
desc.summary.type_kind = MALLOC_TYPE_KIND_OBJC;
return (id)malloc_type_calloc(1, size, desc.type_id);
#else
return (id)calloc(1, size);
#endif
}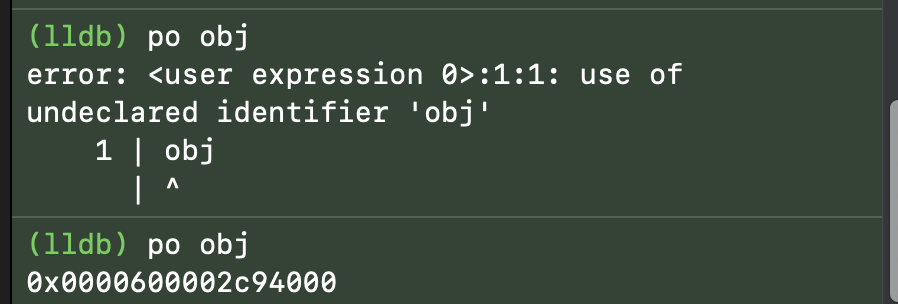
可以看到,在调用上面calloc后这个obj对象才返回了一个16进制的地址
这里我们发现,这和我们之前一般的打印对象打印的不太一样,本来应该是类似<LGPerson: 0x01111111f>这样的一个指针,这里不是这样的原因:
-
objc地址还没有和传入的cls进行关联
-
证明了alloc的根本作用就是开辟内存
obj->initInstanceIsa:类与isa关联
通过上面的calloc,内存已经申请好了,类也传入进来了,接下来就要把类和地址,即isa指针进行关联,关联流程图如下
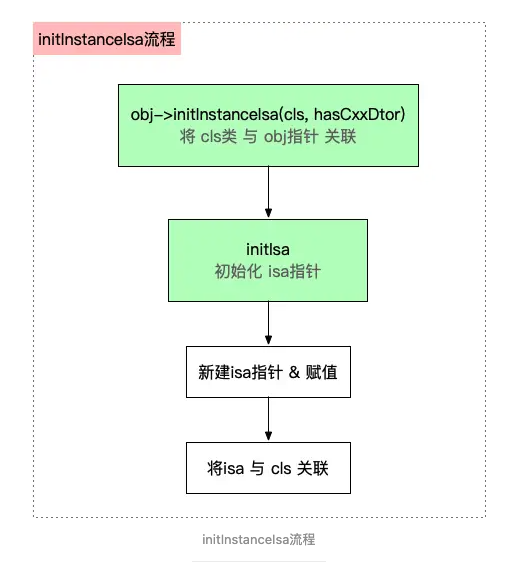
这里的过程其实就是初始化isa指针,并且把isa指针指向申请的内存地址,再把指针和cls类进行关联,我这里由于版本原因,走的是initIsa方法,这里其实本质作用一样,只是我这里走的是普通raw isa路线,在这里的整个if代码前后打断点调试看到
c++
if (fast) {
obj->initInstanceIsa(cls, hasCxxDtor);
} else {
// Use raw pointer isa on the assumption that they might be
// doing something weird with the zone or RR.
obj->initIsa(cls);
}
在经过这个方法之后,可以po obj出一个对象指针,下面是alloc的整体的流程图

总结
alloc的核心目的,是为对象分配一块合适大小的内存,并完成对象和类的关联,整体可以概括为三步:计算,申请,关联
- 计算
根据 cls->instanceSize(...) 计算对象实际需要的内存大小。底层会考虑对齐要求,通常分配结果会按 16 字节或平台要求对齐,所以我们常看到对象内存大小是 16 的整数倍。 - 申请
调用内存分配函数申请这块内存。在源码里,路径是 objc::malloc_instance(size, cls),继续往下会到 calloc(1, size),拿到一块清零的内存地址。 - 关联
把刚申请出来的内存和当前类 cls 关联起来,也就是初始化 isa。这里会根据条件走 initInstanceIsa(...) 或 initIsa(cls) 两条路径之一。
init
这里我们先用一段代码来看一下
objc
GGObject *obj = [[GGObject alloc] init];
GGObject *obj1 = [obj init];
GGObject *obj2 = [obj init];
NSLog(@"%@, %p, %p", obj, obj, &obj);
NSLog(@"%@, %p, %p", obj1, obj1, &obj1);
NSLog(@"%@, %p, %p", obj2, obj2, &obj2);打印的结果:

我们看到他们只想的都是同一个对象实例,因为保存了同一个对象的地址,指向了同一个对象,但是三个指针变量不是同一个变量,我们打断点看一下init的源码:
c++
- (id)init {
return _objc_rootInit(self);
}
id
_objc_rootInit(id obj)
{
// In practice, it will be hard to rely on this function.
// Many classes do not properly chain -init calls.
return obj;
}这里可以看出init没做什么操作,只是把当前的对象返回了,主要是通过调用init方法做为一个工厂模式,方便开发者进行自行定义重写
new
初始化的方法除了init还有个比较少见的new的方法,二者本质上没啥区别,下面是new的源码实现
c++
+ (id)new {
return [callAlloc(self, false/*checkNil*/) init];
}我们可以看到,这里的new直接使用了callAlloc函数,且调用了init函数,所以可以知道new其实就是等价于alloc init的结论
但是一般开发中并不建议使用new,主要是因为有时会重写init方法做一些自定义的操作,例如 initWithXXX,会在这个方法中调用[super init],用new初始化可能会无法走到自定义的initWithXXX部分
NSObject里的alloc
我们再给例如下面这段的NSObject里的alloc里加断点时会发现断点在这停了之后没进alloc源码,而是直接向下运行了
objc
NSObject *objc1 = [NSObject alloc];但是在源码里看到,这里是直接进行objc_alloc的方法里的,所以这里我们就直接在objc_alloc里加一个断点,然后在执行到NSObject *objc1 = NSObject alloc;的时候打开断点就发现跳转到这里
c++
id
objc_alloc(Class cls)
{
return callAlloc(cls, true/*checkNil*/, false/*allocWithZone*/);
}这里主要是NSObject这种基类跟其他类的区别,这里我们先有两张图片可以看到这几个方法流程分析
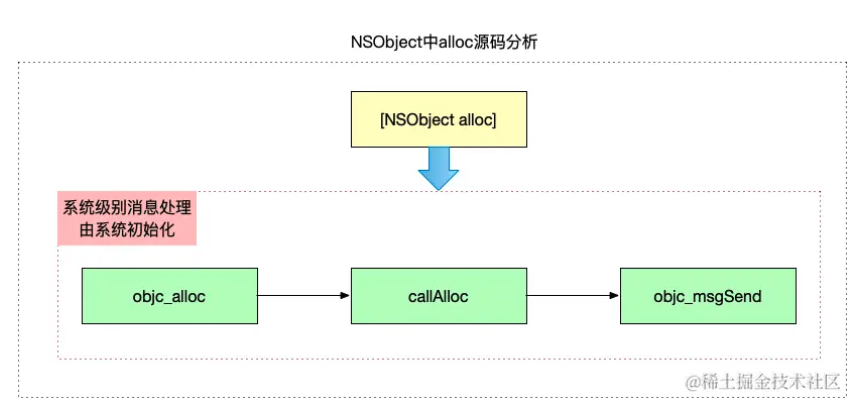
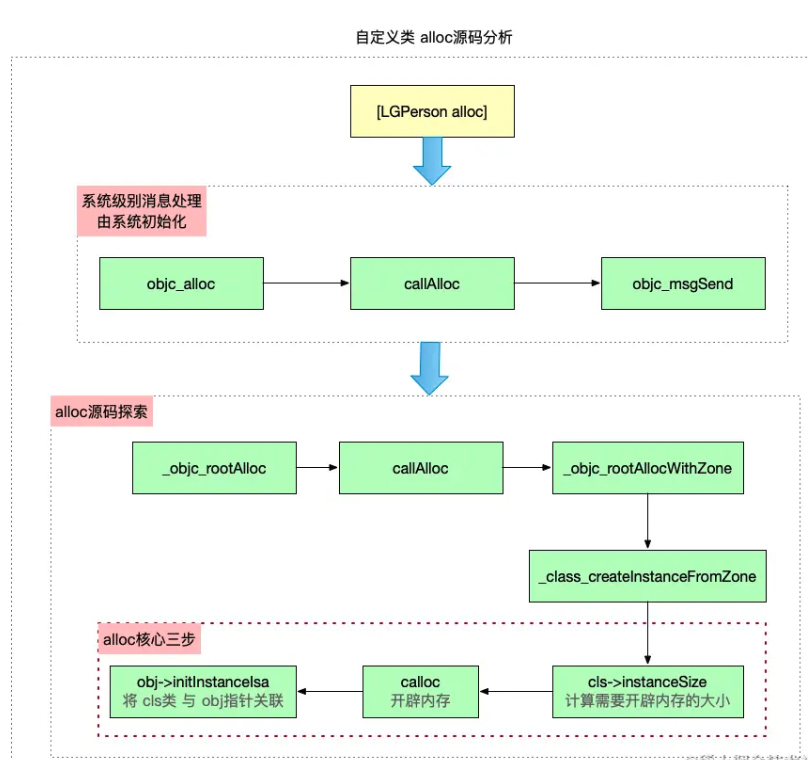
这里主要是说明NSObject基类的alloc是系统级别的消息处理逻辑,他的初始化是由系统完成的,所以不会走到alloc的源码工程里
自定义类的alloc
但是在这里我们也发现了在我们自定义的类里,alloc走了两次,我们在断在我们自定义类这里加几个alloc、 objc_alloc和 calloc断点进行调试时YPTPerson *objc2 = [YPTPerson alloc];发现他第一步还是停在了上面NSObject的objc_alloc这里然后步骤分别是:objc_alloc -> callAlloc,然后返回
c++
return ((id(*)(id, SEL))objc_msgSend)(cls, @selector(alloc));表示向系统发送消息,然后继续执行下去,就发现是前面我们讲的正常的alloc --> callAlloc --> _objc_rootAllocWithZOne的逻辑,其实也就和我们前面的那张图讲的一样
总结
alloc、init、new 三者在对象创建流程里的职责其实很清晰:
alloc负责为对象分配内存,并完成isa与类的关联,本质上是"创建一个合法的对象壳子"。init本身在NSObject里几乎只是返回对象,但它提供了对象初始化入口,方便子类在这里补充自己的状态设置。new则可以看作是[alloc init]的语法糖,本质上还是先分配内存,再执行初始化。
把整个流程串起来看,Objective-C 创建对象并不是一步完成的,而是先"申请并构造对象",再"初始化对象内容"。前面跟源码时看到的 instanceSize、calloc、initIsa,本质上都属于 alloc 阶段;而 init 更偏向对象语义层面的初始化。
学习这部分源码时,重点不只是记住调用链,更重要的是弄清楚每一步到底解决了什么问题:什么时候是在分配内存,什么时候是在关联类信息,什么时候才是真正进入初始化逻辑。把这几个点理顺之后,再回头看 alloc、init、new 的关系就会清楚很多。