大家好,我是 虎子
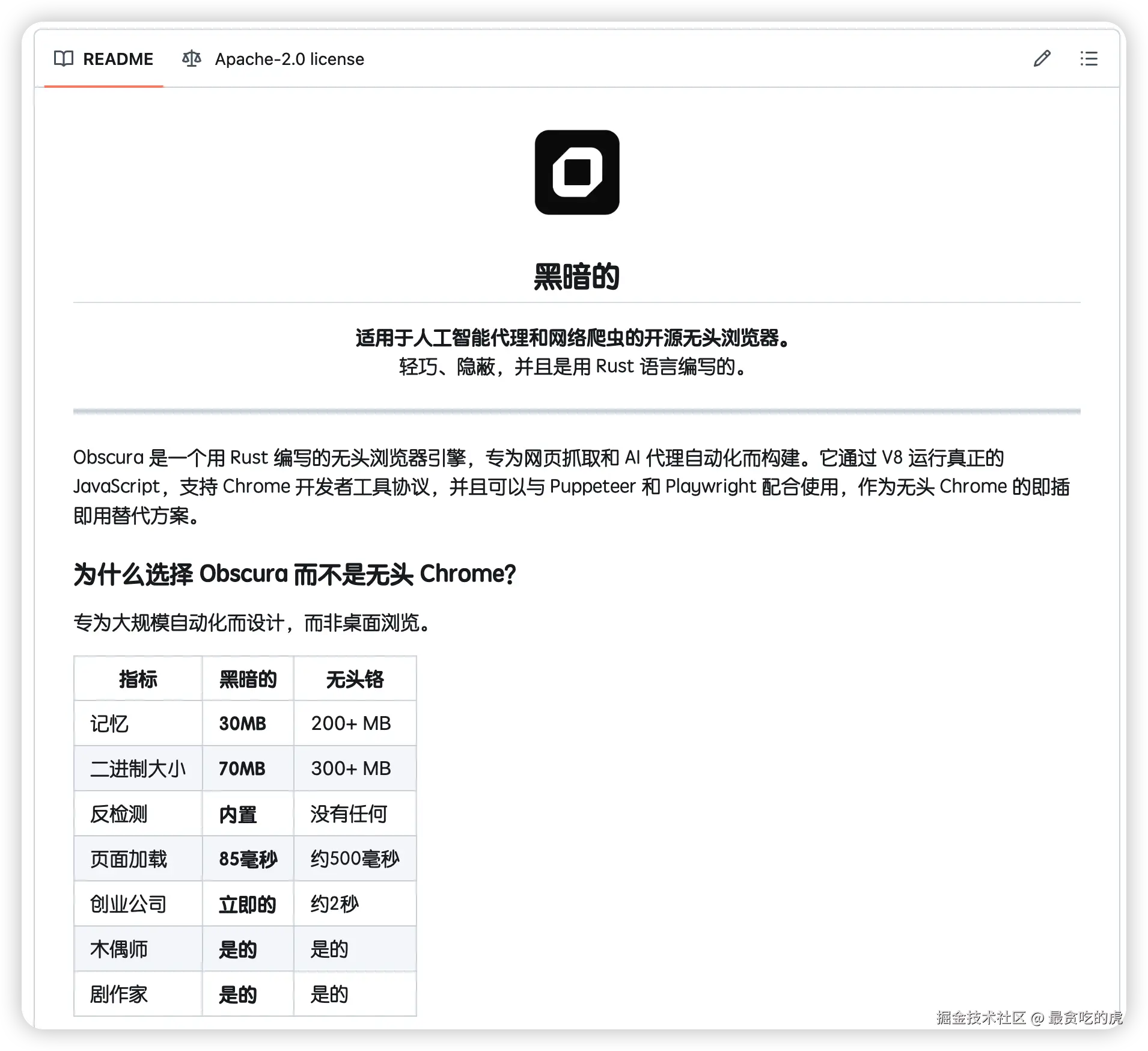
有人用 Rust 搓了个专给 AI Agent 和爬虫用的无头浏览器引擎------Obscura,性能直接把 Chrome 按地上摩擦:
① 内存只吃 30MB(Chrome 吃你几个G)
② 启动只要 85ms,快得离谱
③ 整包才 70MB
Chrome 装完硬盘哭了 还支持 CDP 协议,Puppeteer、Playwright 无缝接,你原来的脚本不用改一行。
最绝的是 stealth 模式------随机化指纹、主动拦截追踪器,爬站被封概率直接拉低一个档次。 CLI 一条命令搞定单页抓取,想并行跑多个 URL 也行,起个 WebSocket 服务给自动化脚本挂着用也没问题。
Rust 写的性能怪物,爬虫党和 AI Agent 开发者必须看一眼。
第一眼以为又是一个无头浏览器新轮子,仔细看完发现,不太一样。
 编辑
编辑
它不是在给 Chrome 做补丁,而是想直接绕开 Chrome,给 AI Agent 和爬虫场景 重新做一个更轻、更快的无头浏览器引擎。
它不是想把 Headless Chrome 用得更好,而是想直接换掉那套笨重的浏览器底座。
Headless Chrome 真的该退休了
现在一提浏览器自动化,大家第一反应还是:
- Puppeteer
- Playwright
- Headless Chrome
这套东西当然成熟,也当然能用。
但问题是,它太重了。
很多场景里,你只是想:
- 打开页面
- 执行脚本
- 抓 DOM
- 跑几步自动化
- 顺便别太容易被封
结果背后却拖着一个完整 Chrome。
这就很别扭。
尤其现在到了 AI Agent 时代,这个问题更明显了。
因为 Agent 对浏览器的需求,不再是偶尔点几下页面,而是:
高频启动、批量调用、长期挂载、并发执行。
一旦进入这个场景,浏览器底座的重量,就直接决定成本和吞吐。
Obscura 解决的,不是浏览器功能问题,而是"执行底座问题"
Obscura 最值得关注的,不是它也是个无头浏览器。
而是它的目标非常明确:
专门为 AI Agent 和爬虫做浏览器执行引擎。
这个思路很关键。
因为它一开始就不是按"通用浏览器"设计的,而是按"自动化执行组件"设计的。
它关注的不是用户体验,而是这些东西:
- 启动够不够快
- 占用够不够低
- 并发够不够舒服
- 自动化脚本接入麻不麻烦
- 被封概率能不能更低
所以我会觉得,Obscura 这种项目真正代表的是一个方向:
浏览器自动化,开始从"借用通用浏览器",走向"为自动化场景定制执行引擎"。
它到底猛在哪?
Obscura 最抓眼球的,主要是这几件事。
1、内存占用极低
项目给的数据是:
只吃 30MB 内存。
如果这个数字在真实场景里也能稳住,那确实很猛。
因为 Headless Chrome 最烦的一点,就是一多开就开始疯狂吃资源。
这件事重要的地方,不只是省内存,而是:
原来只能少量跑的浏览器任务,未来可能可以低成本规模化部署。
2、启动速度很夸张
项目给的数据是:
85ms 启动。
这意味着浏览器在系统里,不再是一个笨重外设,而更像一个随取随用的执行组件。
这对 AI Agent 特别重要。
因为未来 Agent 调浏览器,大概率就该像今天调普通工具一样:
- 要用就拉起
- 用完就释放
- 需要时并发多个
浏览器底座越轻,这件事越成立。
3、体积小很多
整包只有 70MB。
这个点不只是"下载快一点"那么简单。
它会影响:
- 镜像大小
- 容器部署
- 冷启动速度
- CI/CD 体验
- Serverless 场景适配
说白了,浏览器太重,就很难成为一个灵活的基础设施组件。
最聪明的一步,是兼容 CDP
很多新工具一上来喜欢自己搞一套协议,最后技术很酷,生态没人接。
Obscura 这里比较聪明的一点是:
支持 CDP 协议。
这意味着你现有基于 Puppeteer、Playwright 的很多脚本,可以低成本接进去。
这事特别重要。
因为一个新底座要想进生态,最大的门槛往往不是性能,而是迁移成本。
所以 Obscura 这一步,本质上是在做一件事:
先兼容你熟悉的调用方式,再慢慢替掉底下那台笨重的 Chrome。
这个思路是对的。
对 AI Agent 和爬虫来说,轻还不够,还得不容易死
Obscura 另一个很有意思的点,是它的 stealth 模式。
项目描述里提到,它会做这些事:
- 随机化指纹
- 主动拦截追踪器
- 降低被识别、被封的概率
这层能力很重要。
因为浏览器自动化真正难的,从来不只是"能不能打开页面",而是:
你能不能活下来。
尤其 AI Agent 场景里,浏览器不是只抓一次网页,而是会持续导航、翻页、交互、提交表单。
这时候你面对的已经不是简单抓取,而是一个有行为轨迹的执行体。
所以 stealth 不是附加功能,而是自动化底座的一部分。
它不只是内核,还是能直接干活的工具
Obscura 还有一点挺对味:
它不只是给高手二次开发的底层引擎,还提供了很直接的使用方式。
比如:
- CLI 一条命令抓单页
- 并行跑多个 URL
- 起 WebSocket 服务给自动化脚本挂着用
这意味着它不只是"性能很强",而是在往真正可落地的工具底座走。
适合的人也很明确:
- 爬虫开发者
- AI Agent 开发者
- 自动化平台开发者
Headless Chrome 真的要退休了吗?
现在就说 Chrome 要退休,还太早。
Chrome 最大的优势不是轻,而是:
- 兼容性成熟
- 生态成熟
- 社区经验成熟
这些不是一个新项目短时间就能替掉的。
但 Obscura 这种项目出现,本身已经很说明问题了。
它说明越来越多人开始意识到:
"拿 Chrome 顶所有自动化场景" 这件事,已经没那么合理了。
尤其在 AI Agent 爆发之后,大家要的不是最完整的浏览器,而是:
- 更快的执行底座
- 更低的资源占用
- 更适合自动化编排
- 更适合服务化部署
从这个角度看,Obscura 最值得关注的,不是今天能不能替代 Chrome。
而是它在提醒整个行业一件事:
浏览器自动化的下一阶段,可能不再是谁把 Chrome 用得更好,而是谁能为 Agent 和爬虫做出真正原生的浏览器执行引擎。
写在最后
很多人看到 Obscura,可能会觉得:
"又一个无头浏览器项目。"
但我觉得,它真正有意思的地方不是"又一个"。
而是它代表的方向:
浏览器自动化,开始从通用浏览器方案,分化出一条专门服务 AI Agent 和自动化系统的底座路线。
这条路线一旦成立,后面拼的就不只是兼容性了,还会拼:
- 启动成本
- 内存密度
- 并发能力
- 反检测能力
- 服务化能力
所以 Obscura 不是一个简单的 Rust 性能项目。
它更像一个信号。
一个关于浏览器自动化底座,开始重新洗牌的信号。