❝
面向人群:Java开发者、AI应用架构师、企业技术负责人、大模型爱好者。以下数据统计截止时间:2026年4月20日
2026年,大模型行业彻底告别了"百模大战"的无序内卷,进入了"精耕细作、能力落地、能效优先"的全新阶段。截至2026年Q1,全球大模型赛道呈现出三大核心特征:
-
闭源赛道:海外三强(OpenAI、Anthropic、Google)仍保持通用能力领先,但国产头部模型已实现从"跟跑"到"并跑"的跨越,中文场景下部分模型已实现超越;
-
开源赛道:国产模型实现全面逆袭,在Hugging Face全球开源模型下载量TOP10中占据6席,商用友好性、国产化适配、推理效率全面领先海外竞品;
-
技术逻辑:行业竞争核心从"堆参数、拼榜单"转向"能效比、落地能力、安全合规"的三角博弈,MoE架构、推理优化、多模态原生成为技术迭代的核心主线。
作为Java开发者,我们无需沉迷于参数的数字游戏,更需要关注:哪些模型能真正解决我们的业务问题?哪些模型能无缝融入Java生态?不同场景下如何选型能兼顾效果、成本与安全?
第一章 2026年大模型赛道格局与权威评测体系
1.1 全球赛道核心格局
截至2026年Q1,全球大模型赛道已形成清晰的结构化竞争格局,彻底告别了早期的野蛮生长:
1.1.1 闭源商用赛道
-
全球第一梯队:OpenAI GPT-5.4 Pro、Anthropic Claude Opus 4.7、Google Gemini 3.1 Pro,三款模型牢牢占据通用能力全球TOP3,形成"三强守擂"格局;
-
国产第一梯队:字节跳动Doubao-Seed-2.0-pro、阿里通义千问3.6 Plus、百度文心一言5.0、智谱GLM-5.1,四款模型在SuperCLUE中文基准测评中均突破70分,与海外头部模型的差距缩小至1分以内,中文场景下多项能力实现反超;
-
垂直赛道玩家:聚焦金融、政务、医疗等行业的垂直模型,以"通用基座+行业微调"的模式,在细分场景实现能力超越通用大模型,成为企业落地的核心选择。
1.1.2 开源赛道
开源赛道已形成"国产主导、全面逆袭"的格局,国产模型在性能、商用友好性、部署效率上全面领先:
-
全球开源TOP阵营:Meta Llama 4 Maverick、深度求索DeepSeek-V3.2、阿里Qwen3.5/3.6系列、智谱GLM-5开源版、英伟达Nemotron 3 Super,其中3款为国产模型;
-
核心变化:开源模型与闭源模型的性能差距持续缩小,部分70B级开源模型在代码生成、数学推理等专项能力上,已超越2025年的闭源旗舰模型;同时,国产开源模型普遍支持国产昇腾、海光、寒武纪芯片,国产化适配能力远超海外竞品。
1.1.3 行业竞争逻辑的核心转变
2026年,大模型行业的竞争逻辑已发生根本性变化,核心体现在三个方面:
-
从"参数军备竞赛"到"能效优先":厂商不再盲目堆高参数量,转而通过MoE架构、推理优化技术,在固定算力预算下实现性能最大化,"每元钱能买到的Token数和能力"成为核心竞争指标;
-
从"榜单跑分"到"落地能力":行业评价标准从单一的基准测试得分,转向"工具调用、Agent编排、行业适配、私有化部署"等落地能力,能否真正解决企业业务问题成为核心胜负手;
-
从"通用万能"到"垂直深耕":通用大模型的增长瓶颈已显现,厂商纷纷聚焦垂直行业,推出金融、制造、政务、医疗等行业专属模型,垂直场景的深度适配成为差异化竞争的核心。
1.2 本文采用的评测体系说明
本文所有模型能力数据均来自国内外权威评测基准,核心评测体系说明如下:
| 评测基准 | 发布机构 | 核心评测维度 | 权威性说明 |
|---|---|---|---|
| SuperCLUE | 中文通用人工智能基准团队 | 中文通用能力、数学推理、科学推理、代码生成、幻觉控制、智能体任务 | 国内最权威的中文大模型评测基准,998道原创中文题目,覆盖真实业务场景,2026年3月最新榜单为本文核心数据来源 |
| OpenCompass | 上海人工智能实验室 | 通用能力、学科能力、语言能力、知识能力、推理能力、安全合规 | 国内最全面的大模型评测体系,覆盖100+评测集、30万+题目,是国产模型能力验证的核心基准 |
| C-Eval | 上海交通大学、清华大学 | 中文学科能力,覆盖STEM、人文社科、商科、法律、医学等52个学科 | 全球最权威的中文学科能力评测基准,是模型知识储备的核心验证标准 |
| MMLU | 加州大学伯克利分校 | 英文多任务语言理解,覆盖57个学科 | 全球通用的英文通用能力评测基准,是国际模型能力对比的核心标准 |
| HumanEval/MBPP | OpenAI/谷歌 | 代码生成能力,覆盖函数级代码编写、单元测试验证 | 全球通用的代码生成能力评测基准,是模型编程能力的核心验证标准 |
| SWE-Bench Pro | 普林斯顿大学 | 软件工程级代码能力,覆盖多文件项目重构、Bug修复、需求开发 | 2026年最权威的工业级代码能力评测基准,更贴近真实开发场景 |
| 中国信通院《大模型推理优化技术报告》 | 中国信息通信研究院 | 推理性能、能效比、部署适配性、技术成熟度 | 国内最权威的大模型工程化能力评测报告,是本文技术拆解的核心依据 |
第二章 闭源商用大模型全维度硬核PK
闭源商用大模型是企业级应用的核心选择,其核心优势是开箱即用、稳定可靠、生态完善,无需关注底层训练与部署细节。本章将基于2026年Q1最新的权威数据,对国际与国产旗舰闭源模型进行全维度横向对比,给开发者一份清晰的选型参考。
2.1 国际旗舰闭源模型横向对比
国际闭源三强(OpenAI、Anthropic、Google)仍是全球通用能力的天花板,其技术迭代引领着行业发展方向。
2.1.1 OpenAI GPT-5.4 Pro
-
发布时间:2026年3月5日
-
核心架构:未公开超大规模MoE架构,单Token激活参数约280B
-
核心能力亮点 :
-
通用能力全球第一,SuperCLUE总分72.48分,MMLU得分91.2%,C-Eval得分86.7%,稳居所有闭源模型榜首;
-
原生支持100万Token上下文窗口,可一次性处理完整的Java项目源码、超长业务文档,上下文保持率达98.7%;
-
代码生成能力稳居全球第二,SWE-Bench Pro得分58.0分,HumanEval pass@1得分94.3%,对Java 17+新特性、Spring Boot 3.x、微服务架构的理解深度领先绝大多数竞品;
-
生态壁垒极高,是全球开发者工具(Cursor、GitHub Copilot)的默认主力模型,API生态最完善,兼容绝大多数AI开发框架。
-
-
定价:输入15美元/百万Token,输出75美元/百万Token,是全球定价最高的旗舰模型;
-
核心短板:API调用成本高,中文理解能力弱于国产头部模型,国内访问需合规跨境方案,数据出境存在合规风险,对国内行业场景的适配性不足。
2.1.2 Anthropic Claude Opus 4.7
-
发布时间:2026年1月
-
核心架构:未公开MoE架构,主打长上下文与安全对齐
-
核心能力亮点 :
-
长上下文能力全球标杆,原生支持200万Token上下文窗口,是目前上下文窗口最大的商用旗舰模型,超长文档的信息抽取准确率达99.1%;
-
安全合规与幻觉控制能力全球第一,TruthfulQA得分94.6%,HalluEval幻觉率仅2.1%,远低于行业平均水平,是金融、法律等强合规场景的首选;
-
代码生成能力全球顶尖,SWE-Bench Pro得分57.5分,仅次于GPT-5.4 Pro,对大型Java项目的重构、复杂业务逻辑的代码实现能力突出;
-
企业级服务能力完善,支持私有部署、数据驻留,符合GDPR等全球主流合规要求。
-
-
定价:输入12美元/百万Token,输出60美元/百万Token,略低于GPT-5.4 Pro;
-
核心短板:多模态能力弱于GPT-5.4 Pro和Gemini 3.1 Pro,中文理解能力与国产头部模型有明显差距,推理速度较慢,高并发场景下延迟波动较大。
2.1.3 Google Gemini 3.1 Pro
-
发布时间:2026年2月20日
-
核心架构:多模态原生MoE架构,主打通用推理与多模态能力
-
核心能力亮点 :
-
通用推理能力全球顶尖,ARC-AGI-2基准得分77.1%,较上一代翻倍,登顶全球公开模型榜首,处理陌生抽象问题的泛化能力逼近人类;
-
多模态能力全球第一,MMMU Pro得分80.5%,支持文本、图像、音频、视频、3D模型的全模态理解与生成,可直接解析工业设计图纸、Java项目架构图并生成对应代码;
-
科研能力突出,GPQA基准得分94.3%,可辅助学术论文撰写、实验设计、算法优化,是科研场景的首选模型;
-
谷歌生态深度融合,与Google Cloud、Android、TensorFlow深度适配,端侧-云侧协同能力领先。
-
-
定价:输入10美元/百万Token,输出50美元/百万Token,性价比高于GPT和Claude旗舰版;
-
核心短板:中文理解能力弱于国产头部模型,代码生成能力略逊于GPT和Claude,API生态完善度不足,国内企业级服务支持较弱。
2.1.4 国际旗舰闭源模型核心维度对比表
| 核心维度 | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| SuperCLUE总分 | 72.48 | 68.92 | 67.85 |
| C-Eval得分 | 86.7% | 84.2% | 83.5% |
| MMLU得分 | 91.2% | 90.5% | 89.8% |
| SWE-Bench Pro得分 | 58.0 | 57.5 | 52.0 |
| 最大上下文窗口 | 100万Token | 200万Token | 100万Token |
| 多模态能力 | 极强 | 中等 | 全球顶尖 |
| 幻觉控制能力 | 优秀 | 全球顶尖 | 优秀 |
| Java生态适配 | 全球最佳 | 优秀 | 良好 |
| 输入定价(美元/百万Token) | 15 | 12 | 10 |
| 输出定价(美元/百万Token) | 75 | 60 | 50 |
| 核心适用场景 | 通用开发、全球业务、生态集成 | 长文档处理、强合规场景、大型项目重构 | 多模态应用、科研、泛化推理场景 |
2.2 国产旗舰闭源模型横向对比
国产旗舰闭源模型在中文理解、国内行业适配、合规性、性价比上全面超越海外竞品,是国内企业级应用的首选。截至2026年Q1,国产第一梯队模型已全面跻身全球前列,与海外三强的差距持续缩小。
2.2.1 字节跳动 Doubao-Seed-2.0-pro
-
发布时间:2026年2月
-
核心架构:自研MoE架构,主打中文通用能力与智能体编排
-
核心能力亮点 :
-
中文能力国内第一,SuperCLUE总分71.53分,与GPT-5.4 Pro仅相差0.95分,正式跻身全球第一梯队,中文语义理解、长文本生成、对话自然度全面超越海外竞品;
-
智能体任务规划能力国内第一,AgentBench得分82.4%,跻身全球前五,对复杂业务流程的拆解、工具调用、多步骤编排能力突出,是企业级Agent开发的首选;
-
多模态能力国内顶尖,支持图像、音频、视频的深度理解,对抖音生态的短视频内容、直播场景适配性极佳;
-
性价比突出,定价仅为GPT-5.4 Pro的1/10,输入8元人民币/百万Token,输出32元人民币/百万Token,企业级批量采购可进一步降价。
-
-
核心短板:Java代码生成能力略弱于智谱GLM-5.1和通义千问3.6 Plus,API生态完善度不足,私有化部署门槛较高。
2.2.2 阿里巴巴 通义千问3.6 Plus
-
发布时间:2026年3月
-
核心架构:自研混合线性注意力+MoE架构,主打国际化与电商场景
-
核心能力亮点 :
-
综合能力国内第二,SuperCLUE总分70.86分,通用能力均衡,数学推理、代码生成能力突出;
-
国际化能力国内第一,支持201种语言,在阿拉伯语、西班牙语等小语种支持上已超越GPT-5.4 Pro,是跨境电商、外贸业务的首选模型;
-
代码生成能力国内顶尖,SWE-Bench Pro得分52.0分,HumanEval pass@1得分92.7%,对Java、Spring Cloud Alibaba、阿里中间件生态的适配性极佳,是Java电商开发的首选;
-
上下文能力突出,原生支持100万Token上下文窗口,长文档信息抽取准确率达97.8%;
-
性价比极高,输入0.8元人民币/百万Token,输出3.2元人民币/百万Token,仅为GPT-5.4 Pro的1/15,是旗舰模型中定价最低的一款。
-
-
核心短板:通用推理能力略逊于豆包和GPT,幻觉控制能力弱于Claude和文心一言。
2.2.3 百度 文心一言5.0
-
发布时间:2026年2月
-
核心架构:自研ERNIE架构,主打产业落地与私有化部署
-
核心能力亮点 :
-
产业落地能力国内第一,在金融、能源、制造业的私有化部署市场占有率第一,已深度适配国内绝大多数行业场景;
-
工具调用能力国内顶尖,可直接调用工业仿真软件、金融分析工具、政务服务系统,是工业互联网、企业数字化转型的首选;
-
国产化适配能力极强,全面支持国产芯片、国产操作系统、国产数据库,是党政、国企等强国产化场景的首选;
-
多模态工业场景适配能力突出,可直接解析工业图纸、设备监控视频、生产数据,生成对应的控制指令与分析报告。
-
-
定价:输入6元人民币/百万Token,输出24元人民币/百万Token;
-
核心短板:通用能力略逊于豆包和通义千问,代码生成能力弱于智谱和通义千问,对互联网创新场景的适配性不足。
2.2.4 智谱AI GLM-5.1
-
发布时间:2026年4月
-
核心架构:自研GLM架构,主打代码生成与国产化适配
-
核心能力亮点 :
-
代码生成能力全球顶尖,SWE-Bench Pro得分54.9分,登顶国产模型榜首,超越Gemini 3.1 Pro,对Java项目的全链路开发、Bug修复、架构优化能力突出;
-
国产化适配能力极强,在10万张国产昇腾910B芯片上完成训练,全面支持国产算力生态,开源版与闭源版架构统一,微调与部署无缝衔接;
-
通用能力均衡,SuperCLUE总分69.72分,中文知识储备、逻辑推理能力突出;
-
开源生态完善,闭源版与开源版API完全兼容,开发者可无缝切换,降低落地成本。
-
-
定价:输入5元人民币/百万Token,输出20元人民币/百万Token,性价比极高;
-
核心短板:长上下文能力弱于其他旗舰模型,原生仅支持256K Token上下文窗口,多模态能力略逊于豆包和文心一言。
2.2.5 国产旗舰闭源模型核心维度对比表
| 核心维度 | Doubao-Seed-2.0-pro | 通义千问3.6 Plus | 文心一言5.0 | GLM-5.1 |
|---|---|---|---|---|
| SuperCLUE总分 | 71.53 | 70.86 | 69.94 | 69.72 |
| C-Eval得分 | 85.3% | 84.7% | 83.9% | 84.2% |
| 代码能力(SWE-Bench Pro) | 51.0 | 52.0 | 48.5 | 54.9 |
| 最大上下文窗口 | 512K Token | 100万Token | 512K Token | 256K Token |
| 中文理解能力 | 全球顶尖 | 优秀 | 优秀 | 优秀 |
| 国产化适配 | 良好 | 优秀 | 全球顶尖 | 全球顶尖 |
| 行业落地能力 | 互联网场景突出 | 电商/跨境场景突出 | 工业/金融场景突出 | 开发/科研场景突出 |
| 输入定价(元/百万Token) | 8 | 0.8 | 6 | 5 |
| 输出定价(元/百万Token) | 32 | 3.2 | 24 | 20 |
| 核心适用场景 | 中文对话、智能体、互联网业务 | 电商、跨境业务、Java开发 | 工业、金融、国企私有化部署 | 代码生成、国产化适配、开源生态 |
2.3 闭源模型核心能力分项权威评测
2.3.1 通用基座能力
通用基座能力是大模型的核心基础,决定了模型的综合表现,本文采用SuperCLUE 2026年3月最新榜单数据,全球TOP10排名如下:
| 全球排名 | 模型名称 | 厂商 | SuperCLUE总分 | 核心优势 |
|---|---|---|---|---|
| 1 | GPT-5.4 (xhigh) | OpenAI | 72.48 | 通用能力全面领先 |
| 2 | Doubao-Seed-2.0-pro (high) | 字节跳动 | 71.53 | 中文能力国内第一 |
| 3 | Claude Opus 4.7 | Anthropic | 68.92 | 长上下文与安全合规 |
| 4 | 通义千问3.6 Plus | 阿里巴巴 | 70.86 | 国际化与性价比 |
| 5 | Gemini 3.1 Pro | 67.85 | 多模态与推理能力 | |
| 6 | 文心一言5.0 | 百度 | 69.94 | 产业落地与私有化 |
| 7 | GLM-5.1 | 智谱AI | 69.72 | 代码生成能力 |
| 8 | 讯飞星火4.0 | 科大讯飞 | 68.53 | 语音交互与教育场景 |
| 9 | MiniMax M2.7 | 稀宇科技 | 68.17 | 办公场景与Agent协作 |
| 10 | Claude Sonnet 4.6 | Anthropic | 67.25 | 均衡能力与高性价比 |
2.3.2 代码生成能力(Javaer核心关注)
代码生成能力是Java开发者最关注的核心指标,本文采用SWE-Bench Pro 2026年4月最新榜单数据,该榜单更贴近真实的工业级Java开发场景,覆盖项目重构、Bug修复、需求开发等全流程能力:
| 全球排名 | 模型名称 | SWE-Bench Pro得分 | Java专项能力亮点 |
|---|---|---|---|
| 1 | GPT-5.4 Pro | 58.0 | 全链路Java开发能力顶尖,对Spring生态、微服务架构理解极深 |
| 2 | Claude Opus 4.7 | 57.5 | 大型Java项目重构能力突出,代码规范性、可维护性极佳 |
| 3 | GLM-5.1 | 54.9 | 国产模型代码能力第一,Java语法准确性、Bug修复能力极强 |
| 4 | Gemini 3.1 Pro | 52.0 | 算法实现、性能优化能力突出,可基于架构图生成Java代码 |
| 5 | 通义千问3.6 Plus | 52.0 | 电商场景Java开发适配性极佳,对阿里中间件生态完美支持 |
| 6 | MiniMax M2.7 | 51.0 | 办公自动化相关Java开发能力突出,低代码场景适配性好 |
| 7 | Doubao-Seed-2.0-pro | 50.5 | 中文注释、业务逻辑代码生成能力突出,对话式开发体验好 |
| 8 | Kimi K2.5 | 45.5 | 长代码上下文理解能力突出,可基于完整Java项目生成代码 |
2.3.3 安全合规与幻觉控制
幻觉控制能力是企业级应用的核心指标,直接决定了模型能否用于金融、法律、政务等强合规场景,本文采用HalluEval 2026年最新榜单数据,幻觉率越低,模型可靠性越高:
| 模型名称 | 幻觉率 | 安全合规等级 | 核心适用场景 |
|---|---|---|---|
| Claude Opus 4.7 | 2.1% | 全球最高S+级 | 金融、法律、政务等强合规场景 |
| 文心一言5.0 | 2.8% | 国内最高S级 | 国企、党政、工业等强监管场景 |
| GPT-5.4 Pro | 3.2% | S级 | 全球企业级合规场景 |
| GLM-5.1 | 3.5% | A+级 | 企业级开发、科研场景 |
| Doubao-Seed-2.0-pro | 3.7% | A+级 | 互联网、消费级合规场景 |
| 通义千问3.6 Plus | 4.1% | A级 | 电商、跨境业务场景 |
| Gemini 3.1 Pro | 4.3% | A级 | 科研、多模态应用场景 |
第三章 开源大模型2026年第一梯队硬核PK
开源大模型是Java开发者进行私有化部署、深度定制、行业微调的核心选择,其核心优势是数据安全可控、定制化能力强、长期成本低。截至2026年Q1,国产开源模型已实现全面逆袭,在性能、商用友好性、国产化适配上全面领先海外竞品。
3.1 开源大模型核心竞争维度说明
对于Java开发者和企业而言,选型开源大模型不能只看榜单跑分,需要重点关注以下6个核心维度:
-
商业许可协议:是否允许商用、是否需要开源衍生代码、是否有营收门槛,直接决定了企业能否合规商用;
-
基座性能:通用能力、代码能力、推理能力的综合表现,决定了模型的上限;
-
部署门槛:显存占用、推理速度、量化支持、硬件适配,决定了模型能否低成本落地;
-
微调成本:全参微调、L微调、QLoRA的支持度,所需的算力门槛,决定了企业定制化的成本;
-
Java生态适配:是否兼容Spring AI、LangChain4j等Java开发框架,是否有完善的Java SDK,直接决定了Java开发者的接入成本;
-
国产化适配:是否支持国产芯片、国产操作系统,能否在国产化环境中稳定运行。
3.2 全球旗舰开源模型横向对比
3.2.1 Meta Llama 4 Maverick
-
发布时间:2026年1月
-
核心架构:MoE架构,总参数量400B+,单Token激活参数约35B
-
许可协议:Llama 4 商用许可,月活7亿以上用户需申请Meta授权,其余场景可免费商用
-
核心能力亮点 :
-
海外开源生态王者,Hugging Face下载量稳居第一,全球开发者工具、开源项目的默认基准模型,Java生态适配最完善,所有主流Java AI框架均原生支持;
-
通用能力均衡,Open LLM Leaderboard综合得分88.5,稳居开源模型榜首,英文能力领先所有开源竞品;
-
推理效率优秀,400B总参数仅激活35B,推理速度远超同量级稠密模型,INT4量化后可在单张A100 80G显卡上流畅运行;
-
微调生态完善,社区有海量的微调模型、LoRA权重、部署工具,学习成本极低。
-
-
核心短板:中文能力弱于国产开源模型,商用许可有营收门槛,不支持国产芯片的原生优化,国产化适配需二次开发,数据合规性存在风险。
3.2.2 深度求索 DeepSeek-V3.2
-
发布时间:2026年2月
-
核心架构:MoE架构,总参数量671B,单Token激活参数约38B
-
许可协议:DeepSeek开源许可,可免费商用,衍生代码无需开源,无营收门槛
-
核心能力亮点 :
-
数学推理能力开源全球第一,GSM8K得分94.7%,MATH得分78.3%,比肩闭源旗舰模型,适合算法开发、科学计算场景;
-
综合性能开源全球第二,Open LLM Leaderboard综合得分87.5,与Llama 4 Maverick差距极小,中文能力远超Llama 4;
-
推理效率极高,671B总参数仅激活38B,INT4量化后可在单张A100 80G显卡上运行,吞吐量是同量级稠密模型的10倍以上;
-
代码能力突出,HumanEval pass@1得分90.2%,对Java、Python等主流编程语言的支持完善,适合开发场景。
-
-
核心短板:长上下文能力弱于Qwen系列,原生仅支持128K Token上下文窗口,生态完善度不及Llama和Qwen,国产芯片适配需第三方优化。
3.2.3 阿里巴巴 Qwen3.5/3.6 系列
-
发布时间:2026年2-4月
-
核心架构:覆盖稠密模型(7B/14B/32B/72B)与MoE模型(35B/397B),全系列架构统一
-
许可协议:Apache 2.0 开源许可,完全免费商用,无任何营收门槛,衍生代码可闭源,是商用最友好的开源协议
-
核心能力亮点 :
-
中文开源模型第一,Open LLM Leaderboard综合得分87.2,中文能力全面超越Llama 4,SuperCLUE开源榜总分稳居第一;
-
全系列覆盖,从7B端侧模型到397B旗舰模型,架构完全统一,开发者可根据业务需求无缝切换,降低开发成本;
-
代码能力开源顶尖,Qwen3.6-35B-A3B在SWE-bench Verified基准得分73.4%,远超同量级海外模型,Java代码生成能力突出,对Spring生态完美适配;
-
国产化适配全球领先,原生支持昇腾、海光、寒武纪等国产芯片,与阿里云生态深度融合,是国内企业私有化部署的首选;
-
Java生态适配完善,Spring AI、LangChain4j均原生支持,官方提供完整的Java SDK,接入成本极低;
-
部署门槛极低,7B模型INT4量化后可在16GB显存的消费级显卡上运行,32B模型可在单张3090/4090显卡上流畅运行。
-
-
核心短板:旗舰MoE模型的通用推理能力略逊于Llama 4和DeepSeek-V3.2,英文能力弱于Llama 4。
3.2.4 智谱AI GLM-5 开源版
-
发布时间:2026年3月
-
核心架构:自研GLM架构,覆盖6B/14B/32B/72B稠密模型,与闭源版架构统一
-
许可协议:MIT 开源许可,完全免费商用,无任何限制,是最宽松的开源协议
-
核心能力亮点 :
-
国产化适配能力开源顶尖,在国产昇腾芯片上完成全流程训练,原生支持国产算力生态,是党政、国企国产化场景的首选开源模型;
-
代码能力突出,与闭源版GLM-5.1架构统一,微调后代码能力可逼近闭源旗舰模型,Java开发场景适配性极佳;
-
中文理解能力优秀,对中文语义、长文本、对话场景的优化到位,适合中文客服、知识库等场景;
-
开源生态完善,社区有海量的微调模型、部署工具、行业适配方案,学习成本低。
-
-
核心短板:旗舰72B模型的通用能力略逊于Qwen3.5-72B,推理效率低于MoE架构模型,长上下文能力弱于Qwen系列。
3.2.5 英伟达 Nemotron 3 Super
-
发布时间:2026年3月
-
核心架构:Mamba-Transformer混合架构+LatentMoE,总参数量120B,单Token激活参数仅12B
-
许可协议:Apache 2.0 开源许可,完全免费商用
-
核心能力亮点 :
-
推理效率开源天花板,推理速度是Qwen3.5-122B的7.5倍,GPT-OSS-120B的2.2倍,是目前推理速度最快的百亿级开源模型;
-
智能体推理能力突出,原生支持工具调用、多步骤规划,AgentBench得分80.1%,稳居开源模型榜首;
-
架构创新领先,采用Mamba-Transformer混合架构,解决了传统Transformer的长上下文性能衰减问题,长文本推理速度远超传统架构;
-
英伟达生态深度融合,对NVIDIA显卡有原生极致优化,推理性能拉满。
-
-
核心短板:中文能力弱于国产开源模型,国产芯片适配性极差,仅对NVIDIA显卡有优化,通用能力略逊于Llama 4和DeepSeek。
3.2.6 全球旗舰开源模型核心维度对比表
| 模型名称 | 许可协议 | 核心架构 | 总参数量 | 激活参数 | Open LLM得分 | 代码能力 | 部署门槛 | Java生态适配 | 国产化适配 | 商用友好度 |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama 4 Maverick | Llama商用许可 | MoE | 400B+ | 35B | 88.5 | 优秀 | 中高 | 全球最佳 | 差 | 中 |
| DeepSeek-V3.2 | DeepSeek许可 | MoE | 671B | 38B | 87.5 | 优秀 | 中 | 良好 | 中 | 高 |
| Qwen3.5-72B | Apache 2.0 | 稠密 | 72B | 72B | 87.2 | 顶尖 | 中 | 优秀 | 顶尖 | 极高 |
| Qwen3.6-35B-A3B | Apache 2.0 | MoE | 35B | 30B | 85.7 | 顶尖 | 低 | 优秀 | 优秀 | 极高 |
| GLM-5-72B | MIT | 稠密 | 72B | 72B | 86.1 | 优秀 | 中 | 良好 | 顶尖 | 极高 |
| Nemotron 3 Super | Apache 2.0 | 混合MoE | 120B | 12B | 84.3 | 良好 | 中 | 良好 | 极差 | 极高 |
3.3 开源模型核心能力分项评测
3.3.1 商用许可友好度排名
商用许可直接决定了企业能否合规使用开源模型,本文按照商用友好度从高到低排名如下:
| 排名 | 许可类型 | 代表模型 | 商用规则说明 | 适用场景 |
|---|---|---|---|---|
| 1 | MIT | GLM-5系列 | 完全免费商用,无任何限制,衍生代码可闭源 | 所有企业级商用场景,无合规风险 |
| 2 | Apache 2.0 | Qwen3/3.5/3.6系列、Nemotron 3 Super | 完全免费商用,无营收门槛,衍生代码可闭源,需保留版权声明 | 所有企业级商用场景,合规风险极低 |
| 3 | 自定义免费商用许可 | DeepSeek-V3.2系列 | 免费商用,无营收门槛,衍生代码无需开源 | 绝大多数企业商用场景 |
| 4 | 带营收门槛的商用许可 | Llama 4系列 | 月活7亿以下免费商用,超过需申请授权 | 中小企业商用场景,大型企业需合规授权 |
3.3.2 部署门槛与硬件适配排名
对于Java开发者而言,部署门槛是选型的核心指标,本文按照部署难度从低到高、硬件适配从广到窄排名如下:
| 模型名称 | 最低显存要求(INT4量化) | 支持硬件平台 | 部署难度 | 适用部署场景 |
|---|---|---|---|---|
| Qwen3.5-7B | 6GB | NVIDIA/AMD/昇腾/海光/消费级显卡 | 极低 | 端侧、边缘设备、小型服务 |
| GLM-5-6B | 6GB | NVIDIA/AMD/昇腾/海光 | 极低 | 端侧、轻量级服务 |
| Qwen3.6-35B-A3B | 16GB | NVIDIA/AMD/昇腾/海光 | 低 | 企业级单机部署、中小流量服务 |
| Nemotron 3 Super | 24GB | 仅NVIDIA显卡优化最佳 | 中 | 英伟达生态企业级部署 |
| DeepSeek-V3.2 | 40GB | NVIDIA/AMD/昇腾 | 中 | 企业级单机部署、中高流量服务 |
| Qwen3.5-72B | 40GB | NVIDIA/AMD/昇腾/海光 | 中 | 企业级私有化部署、高流量服务 |
| Llama 4 Maverick | 40GB | 仅NVIDIA显卡原生支持 | 中高 | 海外企业级部署、全球业务 |
| GLM-5-72B | 40GB | NVIDIA/AMD/昇腾/海光 | 中 | 国产化企业级部署 |
3.3.3 Java开发者核心关注:代码生成能力开源排名
本文采用HumanEval 2026年最新榜单数据,针对Java代码生成能力的专项排名如下:
| 排名 | 模型名称 | HumanEval pass@1得分 | Java专项亮点 |
|---|---|---|---|
| 1 | Qwen3.5-Coder-32B | 93.1% | Java代码生成能力开源第一,对Spring Boot、微服务架构理解极深,代码规范性极高 |
| 2 | DeepSeek-V3.2-Coder | 92.4% | 算法实现、性能优化能力突出,适合Java后端复杂业务逻辑开发 |
| 3 | GLM-5-Coder-32B | 91.7% | 国产化适配最佳,Java代码注释完整,符合国内开发规范 |
| 4 | Llama 4 Maverick-Code | 91.2% | 英文注释、国际标准Java开发规范适配最佳,适合全球业务开发 |
| 5 | Nemotron 3 Super | 89.5% | 智能体开发、Java工具调用代码生成能力突出 |
第四章 大模型核心技术底层逻辑通俗拆解(Java开发者视角)
很多Java开发者对大模型的认知停留在"调用API"的层面,想要真正用好大模型、解决业务问题,必须理解其底层核心逻辑。
4.1 Transformer架构2026年核心演进
Transformer是所有大模型的基础架构,自2017年提出以来,一直是大模型的核心底座。2026年,Transformer架构已从传统的Decoder-only架构,演进为"混合架构"为主流的全新阶段。
4.1.1 传统Decoder-only架构的核心逻辑(通俗理解)
我们可以把传统的GPT类Decoder-only Transformer架构,比作一个Java项目的流水线开发团队:
-
Tokenization分词:把用户输入的自然语言,拆成一个个"单词/字"(Token),就像把产品需求拆成一个个独立的开发任务;
-
Embedding嵌入层:把每个Token转换成一个高维向量,就像给每个开发任务打上"优先级、技术栈、业务模块、难度"等标签,让计算机能理解;
-
位置编码:给每个Token加上位置信息,就像给开发任务加上"先后顺序、依赖关系",确保团队不会打乱需求的逻辑顺序;
-
Transformer Decoder层 :整个团队的核心开发环节,由N个相同的Decoder层堆叠而成,每个Decoder层包含两个核心模块:
-
自注意力机制(Self-Attention):团队成员之间互相沟通,明确每个任务和其他任务的关联关系,比如"用户登录接口"和"权限校验模块"的依赖关系,确保生成的内容上下文一致;
-
前馈神经网络(FFN):每个团队成员负责自己的任务开发,基于注意力机制的信息,生成对应的内容;
-
-
线性层+Softmax:把最终的向量输出,转换成每个Token的生成概率,就像团队最终输出完整的项目代码,选择最合理的实现方案。
传统Decoder-only架构的核心优势是生成能力强,适合对话、代码生成等自回归场景,但也存在两个核心瓶颈:
-
长上下文性能衰减:上下文越长,自注意力机制的计算量呈平方级增长,就像团队人数越多,沟通成本越高,效率越低;
-
推理效率低:每个Token的生成都需要重新计算所有上下文的注意力,就像每次新增需求,都要把整个项目重新评审一遍,效率极低。
4.1.2 2026年主流混合架构的核心突破
2026年,主流大模型已普遍采用Transformer+Mamba混合架构,完美解决了传统架构的瓶颈,其核心逻辑如下:
Mamba架构是一种基于状态空间模型(SSM)的架构,我们可以把它比作Java项目中的事件驱动架构:
-
传统Transformer的自注意力机制,是"全量同步沟通",每次都要遍历所有上下文,计算量O(n²);
-
Mamba架构是"异步事件驱动",只保留关键的状态信息,无需遍历全量上下文,计算量O(n),上下文越长,效率优势越明显。
2026年主流的混合架构,是在浅层使用Mamba处理长上下文,在深层使用Transformer处理语义理解,兼顾了长上下文效率和生成质量,就像一个团队:
-
前端用项目经理(Mamba)处理所有需求的上下文、依赖关系,过滤掉无效信息,只保留关键状态;
-
后端用技术专家(Transformer)基于关键状态,完成核心的代码开发、逻辑设计,既保证了效率,又保证了质量。
目前,英伟达Nemotron 3 Super、谷歌Gemini 3.1 Pro、阿里Qwen3.5系列均已采用这种混合架构,长上下文推理速度较传统Transformer提升5-10倍,显存占用降低60%以上。
4.2 混合专家MoE架构:2026年旗舰模型的标配
MoE(Mixture of Experts,混合专家)架构是2026年旗舰模型的核心标配,无论是闭源的GPT-5.4、Claude Opus 4.7,还是开源的DeepSeek-V3.2、Qwen3.6,均采用MoE架构,它是实现"大参数量、低激活量、高能效比"的核心技术。
4.2.1 MoE架构的通俗理解
我们可以把传统的稠密Transformer模型,比作一个全科医生:
-
所有的知识都在一个人的脑子里,不管是感冒、发烧、心脏病、癌症,都由这一个医生来诊断;
-
想要提升诊断能力,只能让这个医生学更多的知识,脑子越来越大(参数量越来越高),但每次诊断,都要调动整个大脑的所有知识,效率极低,成本极高。
而MoE架构,比作一个综合医院:
-
医院里有很多个专科医生(Expert专家层),每个医生只精通一个细分领域,比如呼吸科、心内科、肿瘤科、儿科等;
-
有一个分诊台(Router路由层),用户来了之后,分诊台根据用户的症状,只把用户分配给最相关的2-4个专科医生,其他医生不参与诊断;
-
最终的诊断结果,由这几个专科医生共同给出,既保证了医院的整体知识量极大(总参数量极高),又保证了每次诊断只需要调动极少的医生(激活参数量极低),效率和成本都得到了极致优化。
这就是MoE架构的核心逻辑:总参数量极大,保证模型的知识上限;单Token激活参数量极小,保证推理效率和成本。2026年的旗舰MoE模型,普遍做到了"总参数量数百B,单Token激活参数量仅几十B",推理成本较同能力稠密模型降低80%以上。
4.2.2 MoE架构的核心工作流程
MoE架构的核心是Router路由层 和Expert专家层,其完整工作流程如下:
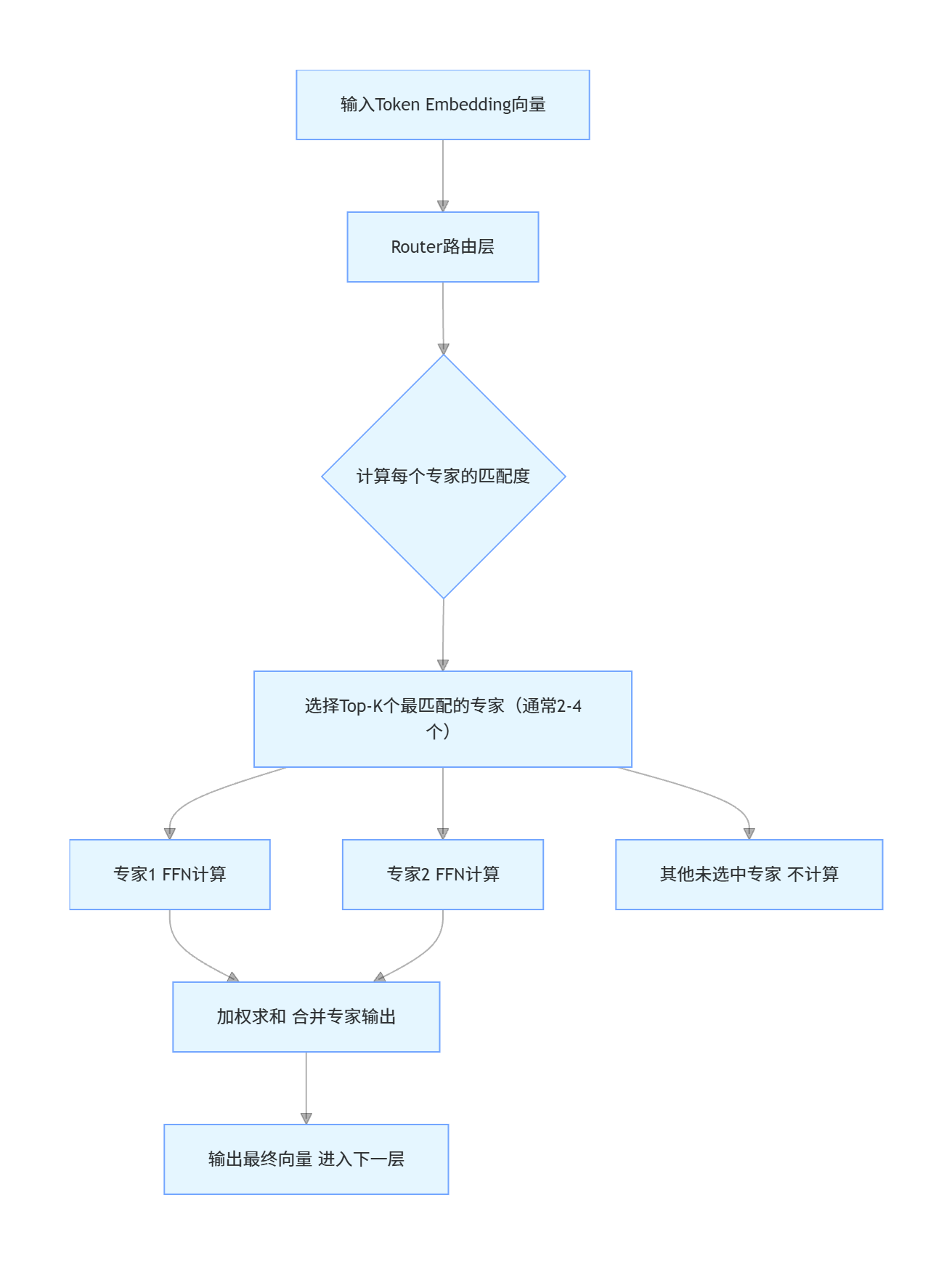
4.2.3 2026年MoE架构的核心技术突破
2026年,MoE架构已解决了早期的"专家负载不均衡、路由准确率低、训练不稳定"等核心问题,主要技术突破包括:
-
LatentMoE架构:英伟达提出的新型专家架构,先对输入向量进行降维,再进行路由计算,大幅降低了路由的计算量和数据搬运成本,推理速度提升3倍以上;
-
共享专家+专用专家架构:DeepSeek、Qwen等国产模型普遍采用,设置1-2个共享专家处理通用语义,多个专用专家处理细分领域,既保证了通用能力,又提升了专家的专业度,解决了通用知识的冗余问题;
-
动态路由机制:根据输入内容的复杂度,动态调整激活的专家数量,简单内容激活2个专家,复杂内容激活4个专家,在保证效果的同时,进一步降低了推理成本;
-
专家负载均衡优化:通过系统级的动态专家分片、算法级的辅助损失,解决了"少数热点专家过载,多数冷门专家闲置"的问题,专家利用率提升50%以上。
4.3 注意力机制的革命性优化:解决KV Cache瓶颈
对于Java开发者而言,大模型推理的核心瓶颈是KV Cache,它是决定推理显存占用、并发量、延迟的核心因素。2026年,注意力机制的优化,核心就是围绕KV Cache的压缩和效率提升展开。
4.3.1 KV Cache的通俗理解与核心瓶颈
首先,我们用Java开发者能听懂的语言,解释清楚KV Cache是什么:
大模型的自回归生成,是一个字一个字往外蹦的,比如用户输入"用Java写一个Spring Boot的用户登录接口",模型先生成"@",再生成"RestController",再生成"public",以此类推,直到生成完整的代码。
在这个过程中,每生成一个新的Token,都需要重新计算之前所有Token的注意力,这会导致大量的重复计算,就像你每次写一行代码,都要把之前的所有代码重新编译一遍,效率极低。
为了解决这个问题,业界引入了KV Cache:
-
在生成第一个Token的时候,把之前所有Token的K(键)和V(值)向量计算出来,缓存到显存里;
-
后续生成新Token的时候,只需要计算新Token的K和V,加上之前缓存的KV,就可以完成注意力计算,无需重复计算之前的KV;
-
这就像Java项目的增量编译,每次只编译新增的代码,之前编译好的class文件直接复用,效率大幅提升。
KV Cache的核心瓶颈是:上下文越长,KV Cache占用的显存越大。比如一个70B的稠密模型,100万Token的上下文,KV Cache占用的显存超过200GB,单张显卡根本无法承载,这就是长上下文推理的核心瓶颈。
4.3.2 2026年主流注意力优化方案
2026年,主流大模型已普遍采用新一代注意力机制,核心目标就是压缩KV Cache,提升长上下文推理效率,核心方案包括:
1. 分组查询注意力GQA(Grouped-Query Attention)
GQA是目前最成熟、应用最广的注意力优化方案,已成为所有主流模型的标配,其核心逻辑如下:
-
传统的多头注意力MHA:每个Query头,都对应一套独立的KV头,比如32个Query头,就有32个K头和32个V头,KV Cache占用极大;
-
多查询注意力MQA:所有Query头,共享一套KV头,KV Cache压缩到极致,但会损失一定的模型效果;
-
分组查询注意力GQA:把Query头分成多个组,每个组共享一套KV头,比如32个Query头,分成4组,每组共享一套KV头,总共只有4个K头和4个V头;
-
GQA在MHA和MQA之间做了完美折中,KV Cache压缩87.5%的同时,几乎不损失模型效果,是目前的行业标配。
2. 多头潜在注意力MLA(Multi-head Latent Attention)
MLA是DeepSeek提出的新一代注意力机制,目前已被国产主流模型广泛采用,其核心逻辑是:
-
对KV向量进行低秩压缩,把高维的KV向量,压缩成低维的潜在向量,再进行缓存,KV Cache压缩率可达90%以上;
-
在注意力计算时,再把低维的潜在向量,恢复成高维的KV向量,几乎不损失模型效果;
-
基于MLA,DeepSeek-V3.2实现了128K上下文的高效推理,显存占用较GQA降低60%以上,推理速度提升2倍。
3. 线性注意力机制
线性注意力机制是2026年的技术热点,其核心逻辑是彻底打破传统自注意力的平方级计算量,实现线性级计算量,核心原理是:
-
传统自注意力的计算式是:
Attention(Q,K,V) = Softmax(Q*K^T) * V,计算量O(n²); -
线性注意力通过核函数变换,把计算式转换成:
Attention(Q,K,V) = (Q * (K^T * V)),计算量O(n); -
线性注意力的KV Cache占用不会随上下文长度增长而爆炸,完美解决了超长上下文的推理瓶颈,目前Qwen3.5、Gemini 3.1 Pro均已采用改进版的线性注意力机制。
4.3.3 注意力机制架构对比

4.4 推理优化全链路技术拆解:降低成本的核心
对于企业级应用而言,推理成本是规模化落地的最大瓶颈,中国信通院数据显示,2025年全球大模型推理计算量较上年提升100倍以上,推理预算已成为企业AI支出的核心部分。2026年,推理优化技术已形成全链路体系,核心分为以下几个层面:
4.4.1 量化技术:显存占用与推理速度的核心优化
量化技术是最基础、最有效的推理优化手段,其核心逻辑是:
-
大模型的参数和激活值,默认是FP16(半精度浮点数)存储,每个数值占用2个字节;
-
量化技术,就是把FP16的数值,转换成INT8、INT4、甚至INT2的整数存储,大幅降低显存占用;
-
比如INT4量化,每个数值只占用0.5个字节,显存占用直接降低75%,推理速度提升2倍以上。
2026年,量化技术已非常成熟,主流模型均支持AWQ、GPTQ、GGUF三种量化格式,其中:
-
AWQ/GPTQ:适合服务器端部署,INT4量化后,模型效果损失小于1%,是企业级部署的首选;
-
GGUF:适合端侧、本地部署,兼容llama.cpp框架,消费级显卡、甚至个人电脑都能流畅运行,是开发者本地测试的首选。
对于Java开发者而言,无需自己实现量化,主流的部署框架(Text Generation Inference、vLLM、llama.cpp)均已原生支持量化模型,直接下载量化后的模型权重即可使用。
4.4.2 投机采样(Speculative Decoding):打破自回归串行瓶颈
投机采样是2026年主流推理框架的标配技术,其核心逻辑是打破自回归生成的串行瓶颈,通俗理解如下:
-
传统的自回归生成,是串行的:生成第1个Token → 生成第2个Token → ... → 生成第n个Token,每个Token都要调用一次大模型,延迟极高;
-
投机采样,引入了一个"小草稿模型"和一个"大目标模型":
-
先用小草稿模型,快速一次性生成多个Token的草稿(比如5个);
-
再用大目标模型,一次性验证这些草稿Token是否正确;
-
正确的Token直接保留,错误的Token截断,重新生成;
-
-
这就像Java开发中,初级工程师先写好代码草稿,高级工程师一次性审核修改,而不是高级工程师一行一行写代码,效率大幅提升。
投机采样在小批量场景下,可将推理延迟降低2-3倍,吞吐量提升3倍以上,目前vLLM、Text Generation Inference等主流推理框架均已原生支持,无需修改代码,开启配置即可使用。
4.4.3 PagedAttention分页注意力:提升并发量的核心技术
PagedAttention是vLLM框架提出的核心技术,目前已成为所有主流推理框架的标配,其核心逻辑借鉴了操作系统的虚拟内存分页机制:
-
传统的KV Cache管理,是连续的内存块,每个请求的KV Cache都需要连续的显存空间,会导致大量的显存碎片,显存利用率极低(通常低于40%);
-
PagedAttention把KV Cache分成固定大小的"页",每个页对应固定数量的Token,每个请求的KV Cache由多个不连续的页组成,通过页表进行管理;
-
这就像操作系统的虚拟内存分页,完美解决了显存碎片问题,显存利用率提升至90%以上,单张显卡能承载的并发请求数提升5-10倍。
对于Java开发者而言,PagedAttention是提升服务并发量、降低部署成本的核心技术,企业级部署大模型,必须采用支持PagedAttention的推理框架。
4.4.4 推理优化全链路架构图

4.5 对齐技术的最新突破:从"有用"到"可靠"
很多Java开发者都会遇到一个问题:大模型生成的代码,看起来很完美,但一运行就报错,甚至会一本正经地胡说八道,这就是模型对齐不到位导致的。
对齐技术,就是让大模型的输出,符合人类的预期:有用、诚实、无害、无幻觉。2026年,对齐技术已从传统的RLHF(基于人类反馈的强化学习),演进为以RLAIF(基于AI反馈的强化学习)为核心的全新阶段,核心目标就是解决幻觉问题,提升模型的可靠性。
4.5.1 对齐技术的通俗理解
我们可以把模型训练分为两个核心阶段:
-
预训练阶段:让模型"学知识",用海量的文本数据训练,让模型学会语言、知识、逻辑,就像一个人读完了小学到大学的所有课程,掌握了海量的知识;
-
对齐阶段:让模型"会做事",教模型怎么按照人类的要求,输出有用、诚实、无害的内容,就像一个人大学毕业后,进入职场,学习怎么按照领导的要求,完成工作任务,而不是满嘴跑火车。
早期的RLHF技术,流程是:人类标注员给模型的输出打分 → 训练一个奖励模型 → 用强化学习让模型朝着高分的方向优化。但RLHF存在三个核心问题:
-
成本极高,需要大量的专业标注员;
-
一致性差,不同标注员的打分标准不一样;
-
泛化能力弱,只能覆盖有限的场景。
4.5.2 RLAIF:2026年对齐技术的主流
RLAIF(基于AI反馈的强化学习),是2026年主流大模型普遍采用的对齐技术,其核心逻辑是:用强大的AI模型,替代人类标注员,给模型的输出打分、纠错、优化,完美解决了RLHF的核心问题。
RLAIF的核心流程如下:
-
用闭源旗舰模型(比如GPT-5.4、Claude Opus),作为"老师模型",给待对齐的开源模型的输出,进行多维度打分,包括:正确性、有用性、无害性、逻辑性、代码可运行性等;
-
基于AI的打分结果,训练一个奖励模型,这个奖励模型的打分一致性,远高于人类标注员;
-
用强化学习PPO算法,让待对齐的模型,朝着奖励模型高分的方向优化,不断提升输出质量;
-
最后通过AI自动化测试,验证模型的幻觉率、错误率,持续迭代优化。
基于RLAIF技术,开源模型的对齐效果可逼近闭源旗舰模型,幻觉率降低50%以上,代码可运行率提升40%以上,同时对齐成本降低90%以上,是目前开源模型对齐的主流方案。
第五章 Java开发者视角:大模型落地实操与选型指南
作为Java开发者,我们最关心的不是模型的参数和榜单,而是怎么把大模型真正落地到业务中,解决实际问题。
5.1 Java大模型开发生态全景
2026年,Java大模型开发生态已非常成熟,形成了三大主流框架,覆盖了从简单API调用到复杂Agent开发的全场景需求,核心对比如下:
| 框架名称 | 最新版本 | 核心优势 | 核心劣势 | 适用场景 |
|---|---|---|---|---|
| Spring AI | 1.0.0-M6 | 与Spring生态深度融合,注解式开发,低代码,无缝对接Spring Boot 3.x | 高级功能(复杂Agent、记忆管理)不如LangChain4j完善 | Spring Boot项目、企业级Java应用、快速开发 |
| LangChain4j | 1.11.0 | 功能最完善,覆盖对话、记忆、RAG、Agent、工具调用全场景,生态最丰富 | 学习成本略高于Spring AI | 复杂AI应用、企业级RAG、智能体开发、全场景适配 |
| JManus | 2.1.0 | 轻量级,专为Java开发者设计,智能路由、Prompt管理、缓存优化开箱即用 | 生态完善度不及前两者 | 轻量级AI应用、快速集成、多模型切换 |
对于绝大多数Java开发者,尤其是Spring生态的开发者,优先选择LangChain4j + Spring Boot的组合,既能无缝融入现有Spring项目,又能覆盖所有复杂场景,是目前的行业最佳实践。
5.2 不同场景的模型选型决策矩阵
不同的业务场景,对模型的要求完全不同,选型错误会直接导致效果差、成本高、合规风险大。本文针对Java开发者最常见的4类业务场景,给出明确的选型决策矩阵:
5.2.1 Java代码生成场景
核心需求:代码准确性高、语法规范、对Java生态理解深、可运行率高、响应速度快
| 场景细分 | 首选模型 | 备选模型 | 核心选型理由 |
|---|---|---|---|
| 企业级Java项目开发、微服务架构设计 | GPT-5.4 Pro | GLM-5.1、Claude Opus 4.7 | 对Spring生态、微服务架构理解极深,代码可运行率最高,大型项目重构能力强 |
| 电商场景Java开发、阿里中间件生态 | 通义千问3.6 Plus | Qwen3.5-Coder-32B | 对阿里中间件、电商业务场景适配极佳,性价比极高 |
| 国产化环境Java开发、信创场景 | GLM-5.1 | Qwen3.5-Coder-32B | 国产化适配最佳,符合国内Java开发规范,开源版可私有化部署 |
| 本地轻量级代码补全、个人开发 | Qwen3.6-35B-A3B | CodeLlama 7B | INT4量化后可在本地消费级显卡运行,代码能力强,完全免费 |
5.2.2 企业级RAG知识库场景
核心需求:中文理解能力强、长上下文支持好、幻觉率低、信息抽取准确率高、合规性好
| 场景细分 | 首选模型 | 备选模型 | 核心选型理由 |
|---|---|---|---|
| 金融、法律、政务等强合规场景 | Claude Opus 4.7 | 文心一言5.0 | 幻觉率全球最低,长上下文能力强,合规性最佳 |
| 国内企业中文知识库、内部文档问答 | Doubao-Seed-2.0-pro | 通义千问3.6 Plus | 中文理解能力顶尖,长文档信息抽取准确率高,性价比高 |
| 企业私有化部署、数据不出境 | Qwen3.5-72B | GLM-5-72B | 开源协议商用友好,中文能力强,国产化适配完善,可完全私有化部署 |
| 轻量级知识库、边缘端部署 | Qwen3.5-14B | GLM-5-14B | 部署门槛低,INT4量化后可在单张3090显卡运行,效果满足绝大多数轻量级场景 |
5.2.3 API服务集成场景
核心需求:API稳定、响应速度快、并发支持好、Java SDK完善、成本可控
| 场景细分 | 首选模型 | 备选模型 | 核心选型理由 |
|---|---|---|---|
| 高并发、低延迟对话服务 | 通义千问3.6 Plus | Claude Sonnet 4.6 | 响应速度快,定价极低,API稳定性高,高并发场景支持好 |
| 全球业务、多语言服务 | GPT-5.4 Pro | Claude Opus 4.7 | 全球节点覆盖,多语言支持完善,API生态最成熟 |
| 智能体、工具调用服务 | Doubao-Seed-2.0-pro | GPT-5.4 Pro | 智能体规划能力顶尖,工具调用准确率高,复杂流程拆解能力强 |
| 低成本、大规模调用 | 通义千问3.6 Plus | Qwen3.5开源系列 | 定价仅0.8元/百万输入Token,是旗舰模型中最低的,大规模调用成本可控 |
5.2.4 私有化部署场景
核心需求:数据安全可控、商用许可友好、部署门槛低、国产化适配好、可定制化微调
| 场景细分 | 首选模型 | 备选模型 | 核心选型理由 |
|---|---|---|---|
| 国企、党政信创场景、国产化环境 | GLM-5-72B | Qwen3.5-72B | MIT开源协议,完全免费商用,原生支持国产芯片,国产化适配最佳 |
| 企业级通用场景、综合能力要求高 | DeepSeek-V3.2 | Llama 4 Maverick | 综合能力顶尖,推理效率高,免费商用,部署门槛适中 |
| 电商、跨境业务场景 | Qwen3.5系列 | 通义千问开源系列 | Apache 2.0协议,多语言支持好,电商场景适配佳,Java生态完善 |
| 边缘端、轻量级私有化部署 | Qwen3.5-7B/14B | GLM-5-6B/14B | 部署门槛极低,消费级显卡即可运行,开源协议友好,商用无风险 |
5.3 Spring Boot + LangChain4j 集成大模型完整实战
5.3.1 环境准备与依赖引入
首先,创建Spring Boot 3.x项目,在pom.xml中引入LangChain4j的核心依赖,这里以通义千问为例,其他模型只需替换对应的依赖即可:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<groupId>com.jam.demo</groupId>
<artifactId>llm-java-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>llm-java-demo</name>
<description>Java集成大模型Demo </description>
<properties>
<java.version>17</java.version>
<langchain4j.version>1.11.0</langchain4j.version>
</properties>
<dependencies>
<!-- Spring Boot Web核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- LangChain4j Spring Boot Starter 通义千问适配 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-tongyi-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- 如需集成OpenAI,替换为以下依赖 -->
<!--
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
-->
<!-- 如需集成本地开源模型,使用Ollama依赖 -->
<!--
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
-->
<!-- LangChain4j 文档加载与RAG相关依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-loader-apache-pdfbox</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- 内嵌向量数据库,RAG场景使用 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-store-in-memory</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- Lombok 简化代码 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Spring Boot 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>5.3.2 配置文件编写
在application.yml中,配置通义千问的API密钥和模型参数,生产环境中,API密钥请从环境变量或配置中心读取,严禁硬编码到代码中:
server:
port: 8080
# LangChain4j 通义千问配置
langchain4j:
tongyi:
chat-model:
# 通义千问API密钥,从阿里云百炼控制台获取
api-key: ${DASHSCOPE_API_KEY:your-api-key-here}
# 模型名称,这里使用通义千问3.6 Plus
model-name: qwen3.5-plus
# 开启请求和响应日志,生产环境可关闭
log-requests: true
log-responses: true
# 模型参数配置
temperature: 0.7
top-p: 0.9
max-tokens: 2048
# 日志级别配置
logging:
level:
dev.langchain4j: debug
com.jam.demo: debug5.3.3 基础单轮对话接口开发
首先,开发最简单的单轮对话接口,直接调用大模型生成响应,适合简单的问答场景:
package com.jam.demo.controller;
import dev.langchain4j.model.chat.ChatLanguageModel;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* 基础对话Controller
* 作者:ken
*/
@RestController
@RequestMapping("/api/llm")
@RequiredArgsConstructor
public class ChatController {
// LangChain4j自动注入的聊天模型
private final ChatLanguageModel chatLanguageModel;
/**
* 单轮对话接口
* @param message 用户输入的消息
* @return 大模型生成的响应
*/
@GetMapping("/chat")
public String chat(@RequestParam String message) {
return chatLanguageModel.generate(message);
}
/**
* Java代码生成接口
* @param requirement 代码需求
* @return 生成的Java代码
*/
@GetMapping("/code/java")
public String generateJavaCode(@RequestParam String requirement) {
String prompt = """
你是一名资深Java开发专家,请根据用户的需求,生成符合Java开发规范的、可直接运行的代码。
要求:
1. 使用Java 17+语法,兼容Spring Boot 3.x
2. 代码必须有完整的注释,说明每个方法的作用
3. 必须包含必要的异常处理
4. 生成完成后,给出代码的使用说明和运行步骤
用户需求:
""";
return chatLanguageModel.generate(prompt + requirement);
}
}启动Spring Boot项目后,访问http://localhost:8080/api/llm/chat?message=你好,即可获取大模型的响应;访问http://localhost:8080/api/llm/code/java?requirement=用Spring Boot写一个用户管理的CRUD接口,即可生成对应的Java代码。
5.3.4 带记忆的多轮对话实现
单轮对话无法记住上下文,而实际业务场景中,绝大多数都需要多轮对话能力。LangChain4j提供了完善的对话记忆管理,我们可以轻松实现带记忆的多轮对话:
首先,定义对话服务接口:
package com.jam.demo.service;
/**
* 带记忆的对话服务接口
* 作者:ken
*/
public interface MemoryChatService {
/**
* 带记忆的对话
* @param userId 用户ID,用于区分不同用户的对话记忆
* @param message 用户输入的消息
* @return 大模型生成的响应
*/
String chat(Long userId, String message);
/**
* 清空用户的对话记忆
* @param userId 用户ID
*/
void clearMemory(Long userId);
}然后,实现对话服务,使用MessageWindowChatMemory保留最近10轮对话:
package com.jam.demo.service.impl;
import com.jam.demo.service.MemoryChatService;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.service.AiServices;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* 带记忆的对话服务实现类
* 作者:ken
*/
@Service
@RequiredArgsConstructor
public class MemoryChatServiceImpl implements MemoryChatService {
private final ChatLanguageModel chatLanguageModel;
// 存储每个用户的对话记忆,key为userId
private final Map<Long, ChatAgent> chatAgentMap = new ConcurrentHashMap<>();
// 定义对话Agent接口
interface ChatAgent {
String chat(String message);
}
@Override
public String chat(Long userId, String message) {
// 如果用户没有对应的Agent,创建一个新的
ChatAgent chatAgent = chatAgentMap.computeIfAbsent(userId, id -> {
// 为每个用户创建独立的对话记忆,保留最近10轮对话
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 构建AiServices
return AiServices.builder(ChatAgent.class)
.chatLanguageModel(chatLanguageModel)
.chatMemory(chatMemory)
.build();
});
// 调用对话Agent,生成响应
return chatAgent.chat(message);
}
@Override
public void clearMemory(Long userId) {
chatAgentMap.remove(userId);
}
}最后,开发对应的Controller接口:
package com.jam.demo.controller;
import com.jam.demo.service.MemoryChatService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
/**
* 带记忆的多轮对话Controller
* 作者:ken
*/
@RestController
@RequestMapping("/api/llm/memory")
@RequiredArgsConstructor
public class MemoryChatController {
private final MemoryChatService memoryChatService;
/**
* 带记忆的对话接口
* @param userId 用户ID
* @param message 用户输入的消息
* @return 大模型生成的响应
*/
@PostMapping("/chat")
public String chat(@RequestParam Long userId, @RequestParam String message) {
return memoryChatService.chat(userId, message);
}
/**
* 清空用户对话记忆接口
* @param userId 用户ID
* @return 操作结果
*/
@DeleteMapping("/clear")
public String clearMemory(@RequestParam Long userId) {
memoryChatService.clearMemory(userId);
return "用户" + userId + "的对话记忆已清空";
}
}5.3.5 RAG知识库完整实现
RAG(检索增强生成)是企业级应用最常用的场景,核心是让大模型基于企业内部的文档进行回答,解决幻觉问题,实现私有知识库问答。本节给出完整的RAG实现代码:
首先,定义RAG服务接口:
package com.jam.demo.service;
import org.springframework.web.multipart.MultipartFile;
/**
* RAG知识库服务接口
* 作者:ken
*/
public interface RagService {
/**
* 上传文档,加载到向量数据库
* @param file 上传的PDF文档
* @return 加载结果
*/
String uploadDocument(MultipartFile file);
/**
* 基于知识库进行问答
* @param question 用户的问题
* @return 大模型基于知识库生成的回答
*/
String chat(String question);
}然后,实现RAG服务,包含文档加载、分块、向量化、存储、检索、生成全流程:
package com.jam.demo.service.impl;
import com.jam.demo.service.RagService;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.loader.apache.pdfbox.ApachePdfBoxDocumentLoader;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.tongyi.TongYiEmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.io.InputStream;
/**
* RAG知识库服务实现类
* 作者:ken
*/
@Service
@RequiredArgsConstructor
public class RagServiceImpl implements RagService {
private final ChatLanguageModel chatLanguageModel;
// 初始化向量模型,使用通义千问的向量模型
private final EmbeddingModel embeddingModel = TongYiEmbeddingModel.builder()
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.modelName("text-embedding-v3")
.build();
// 初始化内存向量数据库,生产环境可替换为Milvus、PGVector等持久化向量数据库
private final EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// 文档分块器,按1000字符分块,重叠200字符,保证上下文连续性
private final DocumentSplitter documentSplitter = DocumentSplitters.recursive(1000, 200);
// 定义RAG问答Agent接口
interface RagAgent {
String chat(String question);
}
private RagAgent ragAgent;
// 初始化RAG Agent
private void initRagAgent() {
// 构建内容检索器,从向量数据库中检索最相关的3个文档片段
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
.minScore(0.7)
.build();
// 构建RAG Agent
this.ragAgent = AiServices.builder(RagAgent.class)
.chatLanguageModel(chatLanguageModel)
.contentRetriever(contentRetriever)
.systemMessage("""
你是一个专业的知识库问答助手,只能基于用户提供的文档内容进行回答。
如果文档中没有相关内容,请明确告知用户,不要编造信息,不要使用文档外的知识。
回答要准确、简洁、有条理,严格遵循文档中的内容。
""")
.build();
}
@Override
public String uploadDocument(MultipartFile file) {
// 校验文件类型
if (!file.getOriginalFilename().endsWith(".pdf")) {
return "仅支持PDF格式的文档";
}
try (InputStream inputStream = file.getInputStream()) {
// 1. 加载PDF文档
Document document = ApachePdfBoxDocumentLoader.load(inputStream);
// 2. 文档分块
var segments = documentSplitter.split(document);
// 3. 生成向量
var embeddings = embeddingModel.embedAll(segments);
// 4. 存储到向量数据库
embeddingStore.addAll(embeddings, segments);
// 5. 初始化RAG Agent
initRagAgent();
return "文档上传成功,共加载" + segments.size() + "个文档片段";
} catch (IOException e) {
return "文档上传失败:" + e.getMessage();
}
}
@Override
public String chat(String question) {
if (ragAgent == null) {
return "请先上传文档,再进行问答";
}
return ragAgent.chat(question);
}
}最后,开发对应的Controller接口:
package com.jam.demo.controller;
import com.jam.demo.service.RagService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
/**
* RAG知识库Controller
* 作者:ken
*/
@RestController
@RequestMapping("/api/llm/rag")
@RequiredArgsConstructor
public class RagController {
private final RagService ragService;
/**
* 上传文档接口
* @param file 上传的PDF文档
* @return 上传结果
*/
@PostMapping("/upload")
public String uploadDocument(@RequestParam("file") MultipartFile file) {
return ragService.uploadDocument(file);
}
/**
* 知识库问答接口
* @param question 用户的问题
* @return 基于知识库的回答
*/
@GetMapping("/chat")
public String chat(@RequestParam String question) {
return ragService.chat(question);
}
}5.3.6 生产环境避坑指南
-
API密钥安全:严禁将API密钥硬编码到代码或配置文件中,生产环境必须从环境变量、配置中心或密钥管理服务中读取;
-
并发控制:大模型API有调用频率限制,生产环境必须添加限流、熔断、降级机制,使用Resilience4j或Sentinel进行流量控制;
-
异常处理:必须捕获大模型调用的所有异常,包括网络异常、超时异常、API限流异常等,给出友好的用户提示,避免服务崩溃;
-
超时配置:合理设置API调用的超时时间,避免长耗时请求阻塞服务线程池,建议设置30秒超时,复杂场景可适当延长;
-
线程池配置:大模型调用是IO密集型任务,应使用IO密集型线程池,核心线程数设置为CPU核心数的2-4倍,避免阻塞Tomcat的核心线程;
-
缓存优化:对于高频重复的请求,可添加本地缓存或Redis缓存,减少重复的API调用,降低成本,提升响应速度;
-
内容安全:生产环境必须添加内容安全审核,对用户的输入和模型的输出进行审核,避免出现违规内容,符合《生成式人工智能服务管理暂行办法》的要求;
-
日志审计:必须记录所有的大模型调用日志,包括用户ID、输入内容、输出内容、调用时间、耗时等,用于审计和问题排查。
5.4 Java大模型开发性能优化最佳实践
-
异步调用:大模型调用是长耗时的IO操作,生产环境必须使用异步调用,返回CompletableFuture,避免阻塞服务线程,提升吞吐量;
-
批量处理:对于批量的文本处理、向量生成任务,使用批量API,减少网络请求次数,提升处理效率;
-
模型复用:ChatLanguageModel、EmbeddingModel等对象是线程安全的,应作为单例Bean注入Spring容器,避免频繁创建和销毁,减少资源消耗;
-
向量数据库优化:生产环境使用Milvus、PGVector等专业的持久化向量数据库,合理设置索引类型(如HNSW),提升检索速度和准确率;
-
文档分块优化:根据文档类型,合理设置分块大小和重叠长度,技术文档建议500-1000字符,长文本建议1000-2000字符,保证检索的准确性;
-
Prompt优化:使用结构化的Prompt,明确模型的角色、要求、输出格式,减少模型的无效输出,降低Token消耗,提升响应速度;
-
多模型路由:根据用户的请求复杂度,动态选择不同的模型,简单请求使用低成本的小模型,复杂请求使用高性能的大模型,在保证效果的同时,大幅降低成本;
-
监控告警:对大模型调用的耗时、成功率、Token消耗、成本进行实时监控,设置告警阈值,及时发现和解决异常问题。
第六章 2026年大模型赛道核心趋势与风险预警
6.1 权威机构预判的核心趋势
基于中国信通院、IDC、SuperCLUE等权威机构2026年发布的最新报告,大模型赛道未来1-2年的核心发展趋势如下:
6.1.1 能效比成为核心竞争点,MoE架构全面普及
2026年,大模型的竞争已从"堆参数、拼榜单"转向"能效比优先",厂商的核心目标是"用最少的算力,实现最好的效果"。MoE架构已成为旗舰模型的标配,未来2年,10B以上的模型将全面采用MoE架构,推理成本较稠密模型降低80%以上。同时,模型稀疏化、剪枝、蒸馏技术将持续迭代,端侧小模型的能力将持续逼近2025年的云端大模型。
6.1.2 端侧-云侧协同大模型成为主流,端侧推理全面爆发
2026年,端侧大模型已进入爆发期,手机、电脑、汽车、边缘设备均已内置端侧大模型,端侧-云侧协同成为主流架构:简单的、隐私敏感的请求在端侧处理,复杂的请求上传到云端处理,既保证了数据隐私,又降低了推理成本,提升了响应速度。未来2年,端侧大模型将成为智能设备的标配,端侧推理占比将超过50%。
6.1.3 多模态原生成为标配,单塔架构替代多模态拼接
2026年,多模态能力已不再是旗舰模型的专属卖点,而是所有大模型的标配。早期的多模态模型,普遍采用"文本基座+视觉编码器"的拼接架构,而2026年的主流模型,已全面采用"单塔多模态原生架构",文本、图像、音频、视频使用统一的Transformer架构处理,跨模态理解能力大幅提升,可实现更自然的多模态交互。未来2年,多模态原生将成为所有新模型的默认架构。
6.1.4 行业大模型进入深水区,垂直场景落地成为核心胜负手
2026年,通用大模型的增长瓶颈已显现,行业增速放缓,而行业大模型进入高速发展期。厂商纷纷聚焦金融、制造、医疗、政务、教育等垂直行业,推出"通用基座+行业数据微调+场景化工具"的行业大模型,解决行业的实际业务问题。未来2年,能否在垂直行业实现规模化落地,将成为大模型厂商的核心胜负手,行业大模型的市场规模将超过通用大模型。
6.1.5 开源与闭源的边界模糊,模型厂商推出"开源+闭源"双线产品
2026年,开源模型与闭源模型的性能差距持续缩小,开源模型已成为开发者生态的核心。主流厂商均已推出"开源+闭源"双线产品:闭源旗舰模型保持技术领先,开源模型抢占开发者生态,形成"闭源赚钱,开源赚生态"的格局。未来2年,开源将成为大模型厂商的标配,不做开源的厂商将逐步失去开发者市场,生态壁垒将成为厂商的核心竞争力。
6.2 开发者与企业必须关注的风险预警
6.2.1 合规风险:严格遵守国内生成式AI监管要求
2026年,国内对生成式AI的监管已进入常态化阶段,《生成式人工智能服务管理暂行办法》已全面落地,企业和开发者必须重点关注以下合规风险:
-
数据安全风险:使用闭源API时,不得上传企业核心敏感数据、个人信息,避免数据出境带来的合规风险,敏感场景必须使用私有化部署的开源模型;
-
内容安全风险:必须对用户的输入和模型的输出进行内容安全审核,不得生成违法违规、虚假有害的内容,落实主体责任;
-
知识产权风险:训练数据、生成内容的知识产权问题已成为行业焦点,不得使用侵权数据训练模型,生成的代码、文本需进行知识产权审核,避免侵权;
-
算法备案要求:国内提供生成式AI服务,必须完成算法备案,企业级服务需严格遵守备案要求,不得无证经营。
6.2.2 技术风险:模型幻觉、推理稳定性与供应链安全
-
模型幻觉风险:即使是最先进的大模型,仍存在幻觉问题,在金融、医疗、法律等强合规场景,必须通过RAG、人工审核、事实校验等机制,降低幻觉风险,严禁直接使用模型输出作为决策依据;
-
推理稳定性风险:大模型的输出存在一定的随机性,同一问题多次调用,输出结果可能不一致,在自动化流程、代码生成等场景,必须添加结果校验、重试机制,保证服务的稳定性;
-
供应链安全风险:企业级应用需避免过度依赖单一模型厂商,应采用多模型兼容的架构,支持模型的无缝切换,避免厂商停服、涨价、API变更带来的供应链风险。
6.2.3 成本风险:推理成本失控,规模化落地的成本管控
大模型规模化落地的最大瓶颈是推理成本,很多企业在试点阶段效果很好,但规模化推广后,推理成本呈指数级增长,导致项目无法落地。企业必须提前做好成本管控:
-
合理选型:根据业务场景,选择性价比最高的模型,简单场景不要盲目使用旗舰大模型,大幅降低成本;
-
多模型路由:根据请求复杂度,动态选择不同的模型,简单请求用小模型,复杂请求用大模型,可降低50%以上的成本;
-
缓存优化:对高频重复请求,添加缓存机制,减少重复的API调用,降低Token消耗;
-
Prompt优化:优化Prompt,减少无效的Token消耗,明确输出格式,避免模型生成冗余内容;
-
私有化部署:对于调用量极大的场景,私有化部署开源模型,长期成本远低于API调用。
6.2.4 开源许可风险:避免商用侵权
开源模型的许可协议五花八门,不同的许可协议,商用边界完全不同,企业使用开源模型时,必须严格遵守许可协议,避免商用侵权:
-
MIT/Apache 2.0许可:最宽松的许可协议,可免费商用、修改、闭源,无营收门槛,几乎无合规风险;
-
自定义免费商用许可:如DeepSeek许可,需仔细阅读许可条款,确认商用限制,避免违反协议;
-
带营收门槛的商用许可:如Llama 4许可,月活超过7亿需申请授权,大型企业商用需提前获得Meta的授权,避免侵权;
-
非商用许可:部分开源模型仅允许学术研究,禁止商用,企业严禁使用此类模型进行商业活动,否则将面临巨额赔偿。
第七章 总结与选型终极决策表
7.1 2026年Q1大模型比拼核心结论
截至2026年Q1,全球大模型赛道已进入全新的发展阶段,核心结论如下:
-
闭源赛道:海外三强(OpenAI、Anthropic、Google)仍保持通用能力领先,但国产头部模型已实现从"跟跑"到"并跑"的跨越,中文场景下多项能力已实现超越,性价比、合规性、行业适配性全面领先海外竞品;
-
开源赛道:国产模型实现全面逆袭,在商用友好性、国产化适配、推理效率上全面领先海外竞品,已成为国内企业私有化部署的首选;
-
技术逻辑:行业竞争核心已从"堆参数、拼榜单"转向"能效比、落地能力、安全合规"的三角博弈,MoE架构、推理优化、多模态原生、RLAIF对齐成为技术迭代的核心主线;
-
落地趋势:行业已从技术验证阶段,进入规模化落地阶段,垂直行业大模型、端侧-云侧协同、Java生态深度融合成为落地的核心方向;
-
开发者视角:Java大模型开发生态已非常成熟,Spring AI、LangChain4j等框架已实现全场景覆盖,Java开发者无需关注底层模型细节,只需根据业务场景选择合适的模型,即可快速实现AI能力的集成。
7.2 全场景选型终极决策表
为了方便Java开发者和企业快速选型,本文整理了全场景选型终极决策表,一张表搞定所有场景的模型选型:
| 业务场景 | 核心需求 | 首选闭源模型 | 首选开源模型 | 核心选型优先级 |
|---|---|---|---|---|
| 企业级Java开发、微服务架构设计 | 代码可运行率高、生态理解深、架构能力强 | GPT-5.4 Pro | Qwen3.5-Coder-32B | 代码能力 > 生态适配 > 响应速度 > 成本 |
| 金融/法律/政务强合规场景 | 幻觉率低、长上下文能力强、合规性好 | Claude Opus 4.7 | GLM-5-72B | 安全合规 > 幻觉控制 > 长上下文能力 > 中文理解 |
| 中文知识库、内部文档问答 | 中文理解强、信息抽取准、性价比高 | Doubao-Seed-2.0-pro | Qwen3.5-72B | 中文理解 > 信息抽取 > 幻觉控制 > 成本 |
| 高并发API服务、大规模调用 | 响应快、稳定、成本可控 | 通义千问3.6 Plus | Qwen3.5-14B | 成本 > 响应速度 > 稳定性 > 并发支持 |
| 国企/党政信创、国产化环境 | 国产化适配好、商用许可友好、数据可控 | 文心一言5.0 | GLM-5系列 | 国产化适配 > 商用许可 > 数据安全 > 综合能力 |
| 电商/跨境业务、多语言场景 | 多语言支持好、电商场景适配佳 | 通义千问3.6 Plus | Qwen3.5系列 | 多语言能力 > 场景适配 > 性价比 > 生态完善度 |
| 智能体/工具调用、复杂流程编排 | 规划能力强、工具调用准、逻辑推理好 | Doubao-Seed-2.0-pro | Nemotron 3 Super | 智能体能力 > 工具调用准确率 > 逻辑推理 > 响应速度 |
| 本地开发、轻量级测试 | 部署门槛低、免费、代码能力强 | 无 | Qwen3.6-35B-A3B | 部署门槛 > 免费商用 > 代码能力 > 响应速度 |
| 边缘端/轻量级私有化部署 | 显存占用低、推理速度快、效果达标 | 无 | Qwen3.5-7B/14B | 部署门槛 > 推理速度 > 商用许可 > 综合能力 |
| 企业级私有化部署、综合能力要求高 | 综合能力强、推理效率高、商用友好 | 无 | DeepSeek-V3.2 | 综合能力 > 推理效率 > 商用许可 > 部署门槛 |
7.3 Java开发者的大模型学习与落地路径建议
对于Java开发者而言,大模型不是颠覆,而是提升开发效率、拓展技术边界的核心工具,这里给出3条落地路径建议:
-
入门阶段:快速集成,提升开发效率 无需深入理解大模型的底层原理,先学会调用大模型API,使用LangChain4j或Spring AI快速集成到Spring Boot项目中,用大模型生成代码、写单元测试、排查Bug、生成接口文档,先提升自己的日常开发效率,建立对大模型的直观认知。
-
进阶阶段:深度应用,解决业务问题 深入学习RAG、智能体、工具调用等核心技术,基于业务场景,开发企业级AI应用,比如内部知识库、智能客服、代码生成平台、业务自动化助手等,解决企业的实际业务问题,体现技术价值。同时,学习大模型的核心底层逻辑,理解Transformer、MoE、推理优化的基本原理,更好地解决应用开发中的问题。
-
资深阶段:深度定制,构建技术壁垒 学习开源模型的微调、部署、优化技术,基于企业的行业数据,微调行业专属模型,实现私有化部署,深度适配企业的业务场景,构建企业的技术壁垒。同时,深入研究大模型的前沿技术,参与开源社区,推动Java大模型生态的发展,成为AI+Java的复合型技术专家。
大模型技术的迭代速度非常快,但核心的业务逻辑、工程化能力、Java生态的积累,永远是开发者的核心竞争力。作为Java开发者,我们无需焦虑,只需拥抱变化,把大模型作为工具,结合我们多年积累的Java开发经验、业务理解能力,就能在AI时代持续保持竞争力,创造更大的价值。
版权声明:本文所有数据均来自权威机构公开报告,所有代码均为原创,可自由使用,转载请注明出处。