文章标签
Redis 后端开发 Java 缓存 线上故障 面试
文章摘要
Redis 作为后端高并发架构的核心组件,用好了能扛住百万 QPS,用错了就是线上的「定时炸弹」。本文拆解了 7 个 Redis「毁灭级」高危操作,从底层原理、故障复现、线上危害到根治方案全流程讲解,结合可视化图解与实战代码,帮你避开 90% 的 Redis 线上坑,杜绝从删库到跑路的悲剧。
前言
你有没有遇到过这种情况:
- 线上 Redis 突然阻塞,服务全量超时告警?
- 数据库莫名被打满,排查后发现是缓存失效导致的雪崩?
- 一行看似正常的 Redis 代码,上线后直接引发全线业务中断?
很多程序员对 Redis 的使用,只停留在set/get的基础 API,却忽略了其单线程模型、过期策略、内存淘汰机制等核心特性,不经意间的一行代码,就可能成为压垮系统的最后一根稻草。
本文就来揭秘 7 个堪称「Redis 毁灭计划」的高危操作,从根上讲透故障发生的原因,给出可落地的避坑方案,看完就能直接用到线上项目中。
先给大家上一张「Redis 高危操作总览图」,本文要讲的所有坑,都在这张图里了:


一、连接攻击:频繁建连 / 关连,耗尽 Redis 连接数
1.1 高危操作描述
放弃 Redis 连接池,每次业务请求都新建一个 TCP 连接,用完立即关闭,循环往复。
1.2 底层原理与故障危害
Redis 是基于 TCP 的客户端 - 服务端架构,每次新建连接都要经历 TCP 三次握手,关闭连接要经历四次挥手,本身就有巨大的性能开销。
- 连接数耗尽 :Redis 默认
maxclients最大连接数为 10000,频繁新建连接会快速占满连接池,导致新的合法请求被 Redis 直接拒绝; - CPU 开销剧增:服务端和 Redis 都要频繁处理连接的创建与销毁,会占用大量 CPU 资源,导致业务逻辑处理能力骤降;
- TCP 资源浪费:大量 TIME_WAIT 状态的连接会占用服务器的 TCP 端口资源,最终引发网络层面的故障。
1.3 故障复现(反面代码示例)
java
运行
// 反面示例:每次请求都新建Jedis连接,用完关闭
public String getValue(String key) {
// 每次新建连接
Jedis jedis = new Jedis("127.0.0.1", 6379);
String value = jedis.get(key);
// 用完立即关闭
jedis.close();
return value;
}高并发场景下,这段代码会快速耗尽 Redis 的连接数,引发服务不可用。
1.4 正确方案与避坑指南
- 强制使用连接池:无论是 Java 的 JedisPool、Lettuce,还是 Python 的 redis-py 连接池,都必须使用连接池复用连接;
- 合理配置连接池参数:
java
运行
// 正确示例:Jedis连接池配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
// 最大连接数
poolConfig.setMaxTotal(200);
// 最大空闲连接
poolConfig.setMaxIdle(50);
// 最小空闲连接
poolConfig.setMinIdle(10);
// 连接耗尽时等待超时
poolConfig.setMaxWaitMillis(3000);
// 初始化连接池
JedisPool jedisPool = new JedisPool(poolConfig, "127.0.0.1", 6379);
// 业务代码复用连接
public String getValue(String key) {
try (Jedis jedis = jedisPool.getResource()) {
return jedis.get(key);
}
}- 监控连接数 :通过
info clients命令监控 Redis 的当前连接数,设置阈值告警。
二、批量改单条:循环单条写入,拖垮 Redis 性能
2.1 高危操作描述
放弃 Redis 的MSET、Pipeline等批量操作 API,改用for 循环逐条执行 SET 命令写入大量数据。
2.2 底层原理与故障危害
Redis 的命令执行分为 3 步:「客户端发送命令→服务端执行命令→客户端接收结果」,每一次命令执行都有一次网络往返(RTT)。
- 网络开销爆炸:循环单条写入 10 万条数据,就要经历 10 万次网络 RTT,哪怕单次 RTT 只有 1ms,10 万次也要 100 秒,效率极低;
- Redis QPS 被无效占满:单线程的 Redis 把大量时间浪费在网络 IO 上,无法处理正常的业务请求,引发业务超时;
- 带宽被打满:大量小包传输会占用服务器带宽,甚至引发网络拥塞。
2.3 故障复现(反面代码示例)
java
运行
// 反面示例:for循环单条SET写入10万条数据
Jedis jedis = jedisPool.getResource();
long expireTime = (System.currentTimeMillis() / 1000) + 300;
for (int i = 0; i < 100000; i++) {
// 循环单条写入,每次都有网络RTT
jedis.set("product:" + i, data[i]);
jedis.expireAt("product:" + i, expireTime);
}这段代码在生产环境执行,会直接拉低 Redis 的整体性能,甚至引发业务请求超时。
2.4 正确方案与避坑指南
- 批量写入优先用 MSET :同批次的写入操作,用
MSET一次性提交,仅需 1 次网络 RTT; - 非原子批量操作用 Pipeline:对于需要设置过期时间、或者不同类型的命令,用 Pipeline 管道打包执行,减少网络往返;
java
运行
// 正确示例:Pipeline批量写入
Jedis jedis = jedisPool.getResource();
Pipeline pipeline = jedis.pipelined();
long expireTime = (System.currentTimeMillis() / 1000) + 300;
for (int i = 0; i < 100000; i++) {
pipeline.set("product:" + i, data[i]);
pipeline.expireAt("product:" + i, expireTime);
// 控制批次大小,避免Pipeline过大
if (i % 1000 == 0) {
pipeline.sync();
}
}
pipeline.sync();- 控制批次大小:Pipeline 单次打包的命令数建议控制在 1000 以内,避免单次请求过大引发网络阻塞。
三、大 Key 攻击:大 Key 写入 + 高峰期删除,直接阻塞 Redis
3.1 高危操作描述
写入超大体积的 Key (比如包含 500 万条数据的 List、100MB 的 String),并在业务高峰期执行DEL命令删除该 Key。
3.2 底层原理与故障危害
Redis 是单线程模型,所有命令的执行都在主线程中串行执行,任何一个耗时的命令,都会阻塞所有后续的业务请求。
- 大 Key 删除阻塞主线程 :
DEL命令删除大 Key 时,需要一次性回收大量内存,这个过程会持续占用主线程,耗时可达数百毫秒甚至数秒; - 服务假死 :主线程被阻塞期间,所有正常的
get/set请求都无法执行,业务服务出现大量超时,甚至触发熔断; - 连锁故障:超时的请求会重试,进一步放大流量压力,最终引发服务雪崩。
3.3 故障复现(反面代码示例)
java
运行
// 反面示例:写入500万元素的大Key,高峰期直接DEL
Jedis jedis = jedisPool.getResource();
// 写入大Key
for (int i = 0; i < 5000000; i++) {
jedis.lpush("big_key:list", "value:" + i);
}
// 业务高峰期执行删除,直接阻塞Redis
jedis.del("big_key:list");3.4 正确方案与避坑指南
- 杜绝大 Key 产生 :遵循 Redis 最佳实践,严格控制 Key 的大小:
- String 类型的 Value 控制在 10KB 以内;
- 集合类型(List/Hash/Set/ZSet)的元素数量控制在 10000 个以内;
- 超大 Key 必须拆分,比如把大 Hash 拆分为多个小 Hash,大 List 拆分为多个小 List。
- 大 Key 删除用异步命令 :Redis 4.0 + 提供了
UNLINK命令,会把 Key 的内存回收放到后台异步线程执行,不会阻塞主线程,替代DEL删除大 Key;
java
运行
// 正确示例:用UNLINK异步删除大Key
jedis.unlink("big_key:list");- 定期扫描大 Key :通过
redis-cli --bigkeys命令定期扫描 Redis 中的大 Key,提前治理; - 禁止高峰期操作大 Key:无论是大 Key 的查询、写入还是删除,都要避开业务高峰期。
四、KEYS * 全量扫描:单线程阻塞的重灾区
4.1 高危操作描述
在线上环境执行KEYS *命令,全量扫描 Redis 中的所有 Key。
4.2 底层原理与故障危害
KEYS命令的时间复杂度是O(N),N 是 Redis 中 Key 的总数量,它会遍历 Redis 整个 Key 字典,一次性返回所有匹配的 Key。
- 主线程长时间阻塞 :如果 Redis 中有数百万个 Key,
KEYS *命令会占用主线程数百毫秒甚至数秒,期间所有业务命令都无法执行; - 网络风暴 :
KEYS *返回的大量结果会占用大量带宽,甚至把服务器带宽打满; - 业务全线超时:阻塞期间,所有依赖 Redis 的业务都会超时,引发服务不可用。
4.3 故障复现
bash
运行
# 线上环境执行,直接阻塞Redis
KEYS *4.4 正确方案与避坑指南
- 线上绝对禁止使用 KEYS 命令 :通过 Redis 配置文件的
rename-command,把KEYS命令重命名为一个随机字符串,禁用业务端直接调用;
conf
# redis.conf 禁用KEYS命令
rename-command KEYS random_str_xxxxxx- 增量扫描用 SCAN 命令 :如果需要遍历 Key,使用
SCAN命令,它会把全量扫描拆分为多次小的扫描,每次时间复杂度 O (1),不会阻塞主线程;
java
运行
// 正确示例:SCAN增量扫描Key
ScanParams scanParams = new ScanParams().match("product:*").count(1000);
String cursor = "0";
do {
ScanResult<String> scanResult = jedis.scan(cursor, scanParams);
List<String> keys = scanResult.getResult();
// 处理Key
cursor = scanResult.getCursor();
} while (!cursor.equals("0"));- Key 查询走特定前缀:业务设计时,给 Key 加上规范的前缀,避免全库扫描的需求。
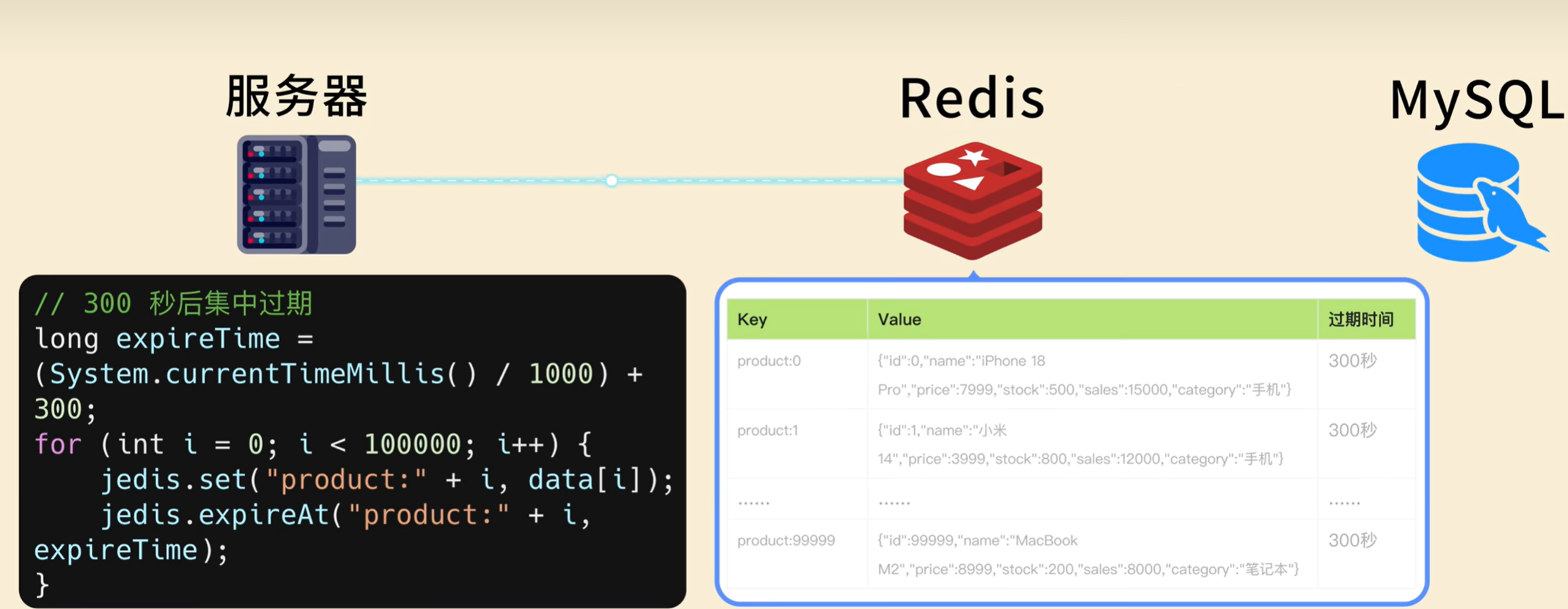
五、过期 Key 攻击:大量 Key 同时过期,主线程忙到无法响应
这是线上最容易踩的坑之一,很多程序员为了方便,给大量 Key 设置了完全相同的过期时间,最终引发 Redis 阻塞、缓存雪崩等一系列故障。
先给大家看两张图,分别是热点 Key 集中过期、海量 Key 集中过期的场景:
📌 【热点 Key 过期场景图】
📌 【此处插入图片 2:海量 Key 集中过期场景图】
5.1 高危操作描述
- 给首页、活动页等热点 Key 设置固定的过期时间(比如 300 秒),到期后大量请求同时击穿缓存;
- 给 10 万 + 商品 Key 设置完全相同的过期时间,到期后集中失效。
5.2 底层原理与故障危害
Redis 的过期 Key 删除采用「惰性删除 + 定期删除」双策略:
- 惰性删除:Key 被访问时,才检查是否过期,过期则删除;
- 定期删除:Redis 默认每秒执行 10 次过期检查,每次随机抽取 20 个设置了过期时间的 Key,删除其中过期的;如果过期 Key 占比超过 25%,就重复这个过程,直到占比低于 25% 或超时。
故障危害:
- 主线程阻塞:大量 Key 同时过期,会触发定期删除的循环执行,长时间占用主线程,导致业务命令排队阻塞;
- 缓存雪崩:大量 Key 同时失效,所有请求都会直接打到 MySQL 数据库,瞬间把数据库打满,引发数据库宕机;
- 热点 Key 击穿:首页等热点 Key 过期,瞬间数十万请求绕过缓存直击数据库,直接压垮数据库。
5.3 故障复现(反面代码示例)
java
运行
// 反面示例1:给10万Key设置完全相同的过期时间
long expireTime = (System.currentTimeMillis() / 1000) + 300;
for (int i = 0; i < 100000; i++) {
jedis.set("product:" + i, data[i]);
// 所有Key都在300秒后同时过期
jedis.expireAt("product:" + i, expireTime);
}
// 反面示例2:热点Key设置固定过期时间
jedis.set("homepage", homepageData);
// 首页热点Key固定5分钟过期
jedis.expire("homepage", 300);5.4 正确方案与避坑指南
- 过期时间加随机偏移量,打散过期时间:给相同过期时间的 Key,加上一个随机的时间偏移,避免集中过期;
java
运行
// 正确示例:过期时间打散
long baseExpireTime = 300;
// 基础300秒,加上0-60秒的随机偏移,避免集中过期
long randomOffset = new Random().nextInt(60);
for (int i = 0; i < 100000; i++) {
jedis.set("product:" + i, data[i]);
jedis.expire("product:" + i, baseExpireTime + randomOffset);
}- 热点 Key 永不过期 + 后台续期:首页、活动页等超高并发的热点 Key,不设置过期时间,由后台定时任务提前更新缓存,避免过期;
- 过期 Key 监控 :通过
info stats命令监控expired_keys指标,观察过期 Key 的删除速率,提前预警集中过期风险。
六、缓存失效三件套:穿透、击穿、雪崩,直接压垮数据库
Redis 作为缓存的核心价值,就是挡在数据库前面,承接高并发请求,减少数据库压力。而缓存穿透、击穿、雪崩这三个问题,会让 Redis 完全失去防护作用,所有请求直击数据库,直接把数据库打垮。
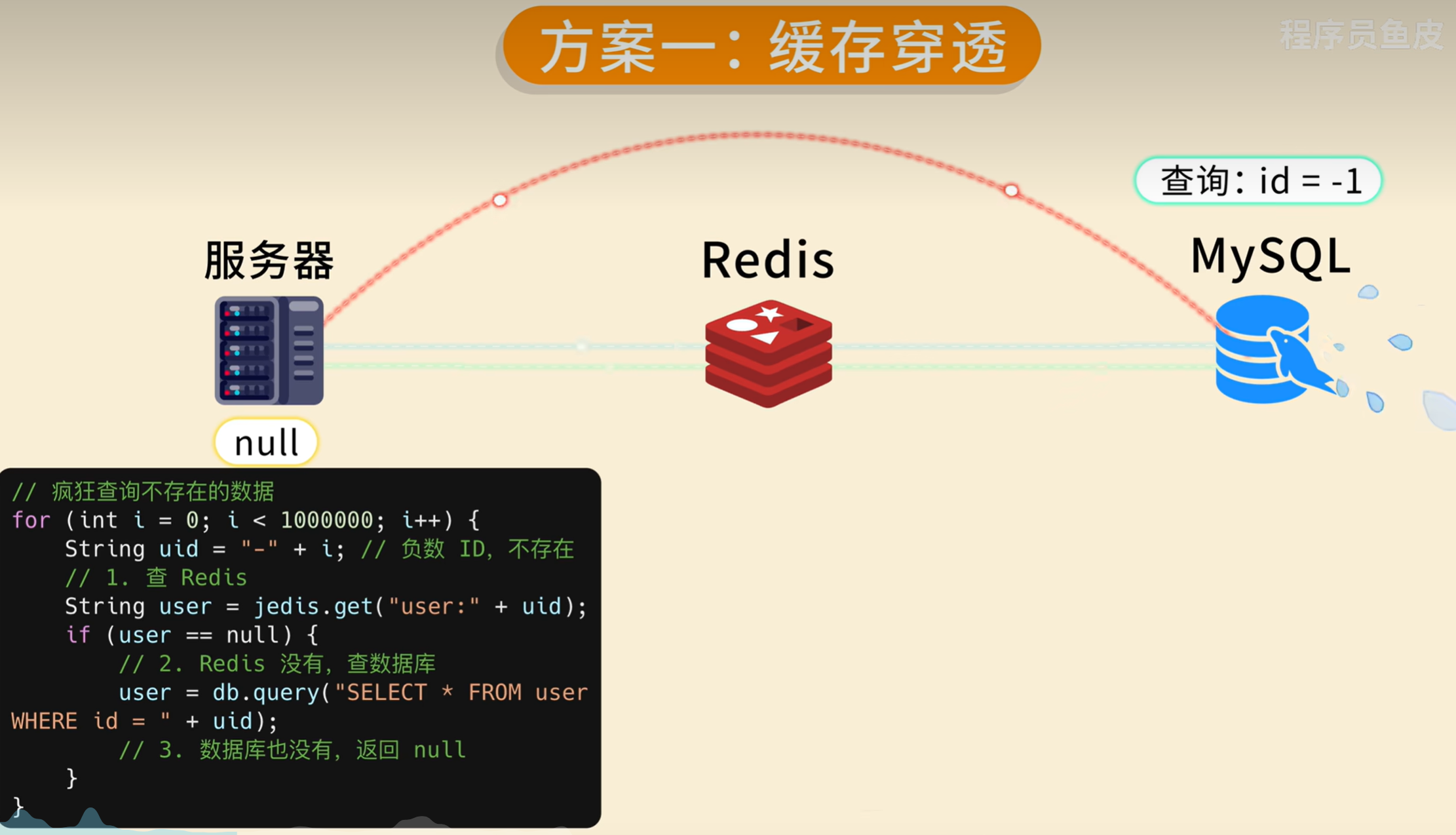
6.1 缓存穿透:查询不存在的数据,绕过缓存直连数据库
问题描述
用户大量查询数据库和缓存中都不存在的数据,比如 id 为 - 1、或者不存在的商品 id,导致每次请求都绕过 Redis,直接查询数据库。
危害
数据库被大量无效请求打满,无法处理正常的业务请求,最终宕机。
解决方案
- 空值缓存:对于查询结果为空的 Key,也在缓存中设置一个短过期时间(比如 60 秒)的空值,避免重复查询数据库;
- 布隆过滤器:把所有合法的 id 提前写入布隆过滤器,请求到来时先经过布隆过滤器过滤,不存在的 id 直接拒绝,无需访问缓存和数据库;
- 参数校验:接口层增加参数合法性校验,过滤掉明显不合法的请求(比如 id 为负数、格式错误)。
6.2 缓存击穿:热点 Key 过期,大量请求直击数据库
问题描述
某个超高并发的热点 Key(比如秒杀活动商品)突然过期,瞬间数十万请求同时绕过缓存,全部打到数据库,直接把数据库压垮。
解决方案
- 热点 Key 永不过期:超高并发的热点 Key 不设置过期时间,由后台定时任务更新缓存;
- 互斥锁:热点 Key 过期时,只允许一个线程去查询数据库并更新缓存,其他线程等待缓存更新完成后再重试,避免大量请求同时访问数据库;
- 提前预热:秒杀、大促等活动开始前,提前把热点数据写入缓存,设置足够长的过期时间。
6.3 缓存雪崩:大量 Key 同时失效 / Redis 宕机,全线请求压垮数据库
问题描述
两种场景会引发缓存雪崩:
- 大量 Key 同时过期,缓存集体失效;
- Redis 集群宕机,缓存完全不可用。所有请求全部打到数据库,数据库瞬间被打满,引发全线业务中断。
解决方案
- 过期时间打散:如前文所述,给 Key 的过期时间加上随机偏移,避免集中过期;
- Redis 高可用集群:搭建 Redis 主从 + 哨兵集群,或者 Redis Cluster 集群,避免单点故障;
- 服务熔断与降级:当数据库压力过大时,触发熔断,非核心业务直接返回降级数据,保护核心业务和数据库;
- 多级缓存:本地缓存(Caffeine/Guava Cache)+ Redis 分布式缓存结合,Redis 宕机时,本地缓存也能承接一部分请求,避免所有请求直击数据库。
七、内存攻击:不设过期 + 禁止淘汰,内存耗尽业务瘫痪
7.1 高危操作描述
- 给写入的 Key 都不设置过期时间,永久占用 Redis 内存;
- 把 Redis 的内存淘汰策略设置为
noeviction(不淘汰)。
7.2 底层原理与故障危害
Redis 的内存上限由maxmemory参数配置,当内存占用达到maxmemory时,会根据配置的淘汰策略处理新的写入请求。而noeviction策略是:当内存满了之后,直接拒绝所有新的写入请求,只响应读请求。
故障危害:
- 业务写入全面报错 :不设过期时间的 Key 会持续占用内存,直到占满
maxmemory,之后所有的缓存写入操作都会失败,业务数据无法缓存; - 缓存完全失效:新的数据无法写入缓存,所有请求都会直接打到数据库,引发数据库压力骤增,最终宕机;
- 业务全线中断:写入失败会引发大量业务异常,最终导致全线业务不可用。
7.3 故障复现
conf
# redis.conf 配置禁止内存淘汰
maxmemory-policy noevictionjava
运行
// 持续写入无过期时间的Key,最终占满内存
while (true) {
jedis.set("data:" + UUID.randomUUID(), randomData);
}7.4 正确方案与避坑指南
- 合理设置过期时间:除了配置类、字典类等永久有效的 Key,所有业务缓存 Key 都必须设置合理的过期时间;
- 选择合适的内存淘汰策略 :线上环境优先使用
allkeys-lru(优先淘汰最近最少使用的 Key),Redis 4.0 + 推荐使用allkeys-lfu(优先淘汰使用频率最低的 Key),绝对禁止核心业务使用noeviction策略;
conf
# 推荐的内存淘汰策略
maxmemory-policy allkeys-lfu- 内存使用率监控:监控 Redis 的内存使用率,设置阈值告警(比如内存使用率超过 80% 就告警),提前治理;
- 定期清理无效 Key:定期扫描并清理长期不访问的无效 Key,释放内存空间。
八、线上 Redis 高危操作红线 & 监控体系
8.1 线上 Redis 绝对禁止的操作红线
- 禁止线上环境使用
KEYS、FLUSHDB、FLUSHALL等高危命令,必须通过 rename-command 禁用; - 禁止业务高峰期执行大 Key 的
DEL、HGETALL、SMEMBERS等耗时命令; - 禁止使用循环单条操作替代批量操作,禁止无连接池频繁新建 / 关闭连接;
- 禁止给大量 Key 设置完全相同的过期时间,禁止热点 Key 无续期方案设置短过期时间;
- 禁止核心业务使用
noeviction内存淘汰策略,禁止大量 Key 不设过期时间。
8.2 必做的 Redis 监控体系
表格
| 监控指标 | 核心作用 | 告警阈值 |
|---|---|---|
| 内存使用率 | 提前预警内存耗尽风险 | 超过 80% 告警 |
| 当前连接数 | 监控连接数耗尽风险 | 超过 maxclients 的 80% 告警 |
| 慢查询日志 | 发现耗时命令,提前治理阻塞风险 | 超过 10ms 的命令记录告警 |
| 过期 Key 速率 | 预警集中过期风险 | 突增 100% 以上告警 |
| 主线程 CPU 使用率 | 监控 Redis 阻塞风险 | 持续超过 80% 告警 |
| 大 Key 数量 | 提前治理大 Key | 发现超过阈值的大 Key 告警 |
结尾
Redis 是一把双刃剑,它能帮我们轻松应对高并发场景,也能因为一行错误的代码引发全线业务故障。
本文拆解的 7 大高危操作,都是线上环境踩过无数坑总结出来的血泪教训,希望大家看完之后,能避开这些坑,让 Redis 真正成为系统的性能加速器,而不是定时炸弹。
如果本文对你有帮助,欢迎点赞👍 + 收藏⭐ + 评论💬 + 关注,后续会分享更多 Redis 实战干货与线上故障排查技巧!