Transformer : 动态拓扑的注意力革命
每一个 Attention Head 都在问:此刻,哪些部分对哪些部分重要?
一、2017年6月的一篇论文
2017年6月12日,Google Brain的Ashish Vaswani等八位作者在arXiv上传了一篇论文,标题是"Attention Is All You Need"。这个标题很狂妄。当时机器翻译的主流架构是RNN(循环神经网络)和LSTM(长短期记忆网络)------它们统治NLP领域已经超过二十年。而这篇论文说:你们都不需要了,注意力机制就够了。
更狂妄的是,他们是对的。五个月后,这篇论文被NIPS 2017接收。两年后,BERT、GPT-2横空出世,全部基于Transformer架构。再过三年,GPT-3证明了Transformer可以扩展到1750亿参数。今天,几乎所有的大型语言模型------从ChatGPT到Claude------都是Transformer的变体。但在2017年6月,这只是一个激进的想法:能否完全抛弃循环结构?
顺序依赖的代价


缺陷1:无法并行化
缺陷2:长程依赖的信息衰减
======
Vaswani等人的想法是:如果每个词都能直接"看到"其他所有词,就不需要通过隐状态传递信息了。这就是Self-Attention(自注意力)机制。它让序列中的每个位置,都能直接计算与其他所有位置的相关性,然后用这个相关性加权求和。
没有循环,没有顺序依赖,完全可以并行计算。
代价是什么?计算复杂度从 O(N) 变成 O(N^2)。
Self-Attention 自注意力:每个词对每个词问一遍:"你重要吗"

停顿一下

**归纳偏置(Inductive Bias)**就是模型自带的、对 "数据规律是什么样" 的先验假设,它决定了模型更倾向于学习什么样的模式。


换句话说:Transformer的成功,是因为它的归纳偏置正确,还是因为它的归纳偏置最弱------弱到可以用蛮力数据来填充?
"没有归纳偏置"本身是一种归纳偏置。Transformer假设了*"任意位置的词都可能对任意其他位置重要"*,这个假设对语言来说是对的吗?对所有任务来说是对的吗?
self-Attention的数学:一个优雅的堆成性


这个机制的美妙之处:
- 全局感受野:每个位置都能直接"看到"所有其他位置,不需要通过隐状态传递
- 完全并行:所有位置的输出可以同时计算,没有顺序依赖
- 动态拓扑:注意力矩阵是根据输入内容动态生成的,不是固定的权重
==================
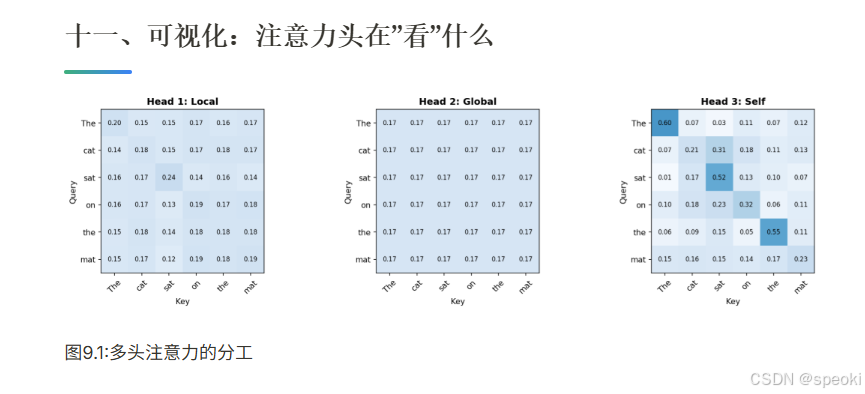
三、自己动手:看注意力在"看"什么


=========
多头注意力:分工与协作





核技巧是什么?
线性注意力: 用加法结合律换掉softmax

核函数视角:






================
核函数
什么是核函数:

核函数的核心性质:


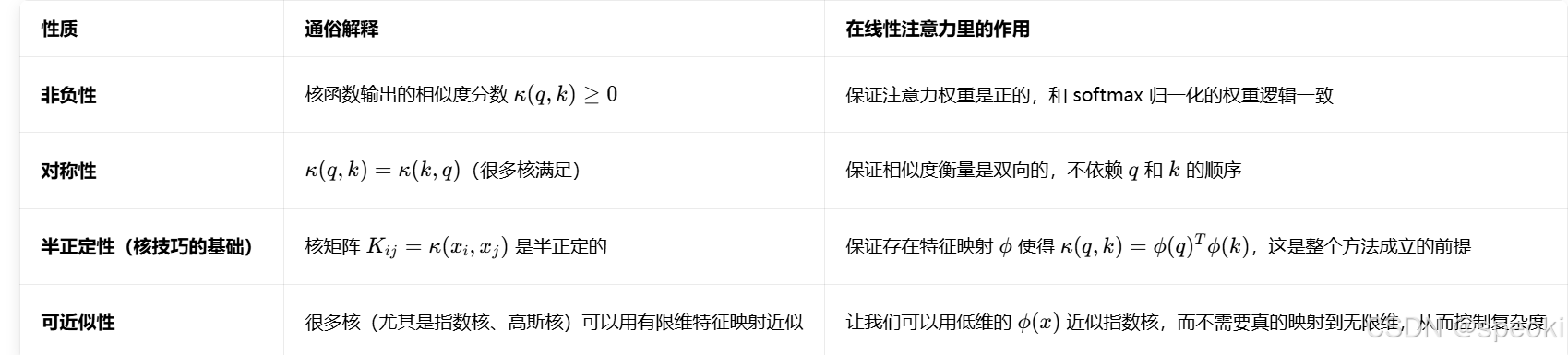


exp这个函数为什么可以衡量q和k的相似度?

随机映射是什么?


随机傅里叶特征是什么?




=====
线性注意力的致命缺陷:圆滑性
这听起来很完美。但线性注意力在实践中一直不如标准注意力------尤其是在需要精确、尖锐的注意力时(比如指代消解、关键词匹配)。原因是:softmax天然地产生尖锐的分布,线性核不能。

============
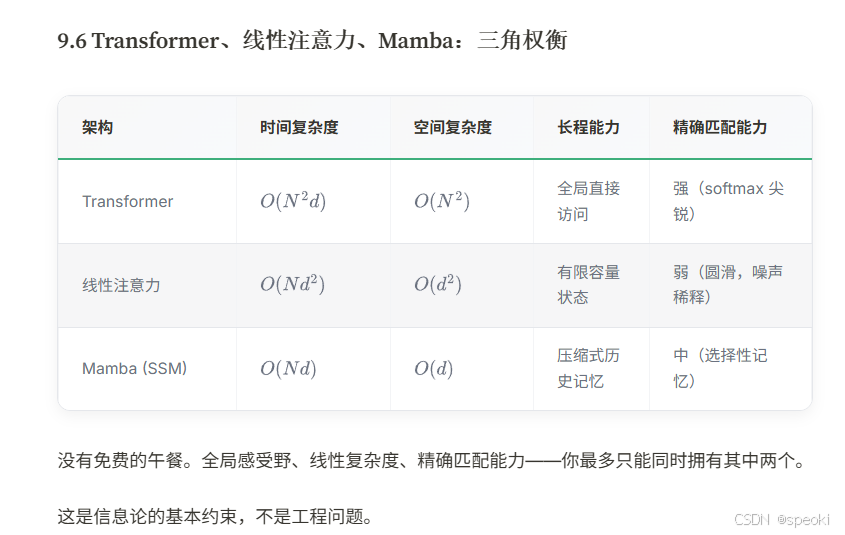
状态空间模型: 从线性注意力到选择性记忆
线性注意力 的分析揭示了一个更深的问题:全局感受野和线性复杂度 ,能否同时拥有?答案是:不能------除非引入一个新的维度:选择性。这就是状态空间模型(SSM)以及 Mamba 的核心思想。









为啥要离散化:

为什么选择性解决了线性注意力的问题?



位置编码:Transformer对顺序的理解

正弦位置编码是一种绝对位置编码方法 ,其编码是确定性的且不包含可学习参数 ,因此不会引入额外的学习噪声,然而由于这个编码方法通过与【token embedding 相加的方式 】注入的,这样token表示中的内容信息与绝对位置信息是强耦合的 ,从而在注意力计算中难以被显式解耦 。其局限在于------并未显式建模token之间的相对位置关系 ,模型需要通过绝对位置编码间接推导这些关系,从而增加了学习负担。



==========


=========
ALiBi

Transformer的成功引发了一个深刻的问题:注意力机制是在"理解"关系,还是在"检索"相关信息?
考虑这个句子:
text
"The trophy doesn't fit in the suitcase because it is too big."
人类知道"it"指代"trophy"(而不是"suitcase"),因为我们理解"太大"的逻辑------trophy太大所以放不进去。Transformer也能正确地让"it"的注意力集中在"trophy"上。但它是真的理解了因果逻辑,还是只是学到了统计模式:"it"通常指代前面的名词,而"too big"附近的"it"更可能指代第一个名词?
这个问题没有简单答案。但有一些线索:
证据1:注意力模式的可解释性
研究者发现,某些注意力头确实学到了语言学上有意义的模式:主语-谓语一致性、修饰语-中心词关系、代词-先行词绑定。
这些模式不是随机的 ,而是系统性的。
证据2:分布偏移下的脆弱性
但当测试数据的分布和训练数据不同时,这些模式会崩溃。如果训练时"it"总是指代第一个名词,测试时遇到"it"指代第二个名词的情况,模型会失败。这表明Transformer学到的可能是统计捷径,而不是深层的因果理解。
证据3:注意力≠解释
更微妙的是,注意力权重本身可能不是模型决策的真正原因。2019年的研究表明,即使随机打乱注意力权重,模型的输出有时也不会改变太多------因为真正的信息可能编码在value向量中,而不是注意力分布中。
注意力是一个有用的工具,但它不是理解的充分条件。
RoPE 就是后者,它学到的是通用的相对位置关系,而不是死记硬背每个位置的向量,所以外推能力强得多。



