1.KNN算法简介
KNN思想、分类和回归问题处理流程
2.KNN算法API介绍
分类、回归实现
3.距离度量
常用距离计算方法
4.特征预处理
归一化、标准化、鸢尾花识别案例
5.超参数选择方法
交叉验证、网格搜索、手写数字识别案例
1. KNN算法简介
KNN的原理:找到最近的K个,投票或者求均值。找到最近的K个邻居,然后这K个邻居进行投票,谁的票多就是谁 ==》这属于KNN的分类思路;
K-近邻算法(K Nearest Neighbor,简称KNN) :比如根据你的"邻居"来推断出你的类别;
KNN算法思想 :如果一个样本在特定空间中的 K个最相似的样本 中的大多数属于一个类别,则该样本也属于这个类别;
(如何确定样本之间的相似性?通过距离!)
K-近邻算法:
样本相似性:样本都属于一个人物数据集的,样本距离越近则越相似;
利用K紧邻算法预测电影类型;
欧氏距离=对应维度差值平方和,开平方根;
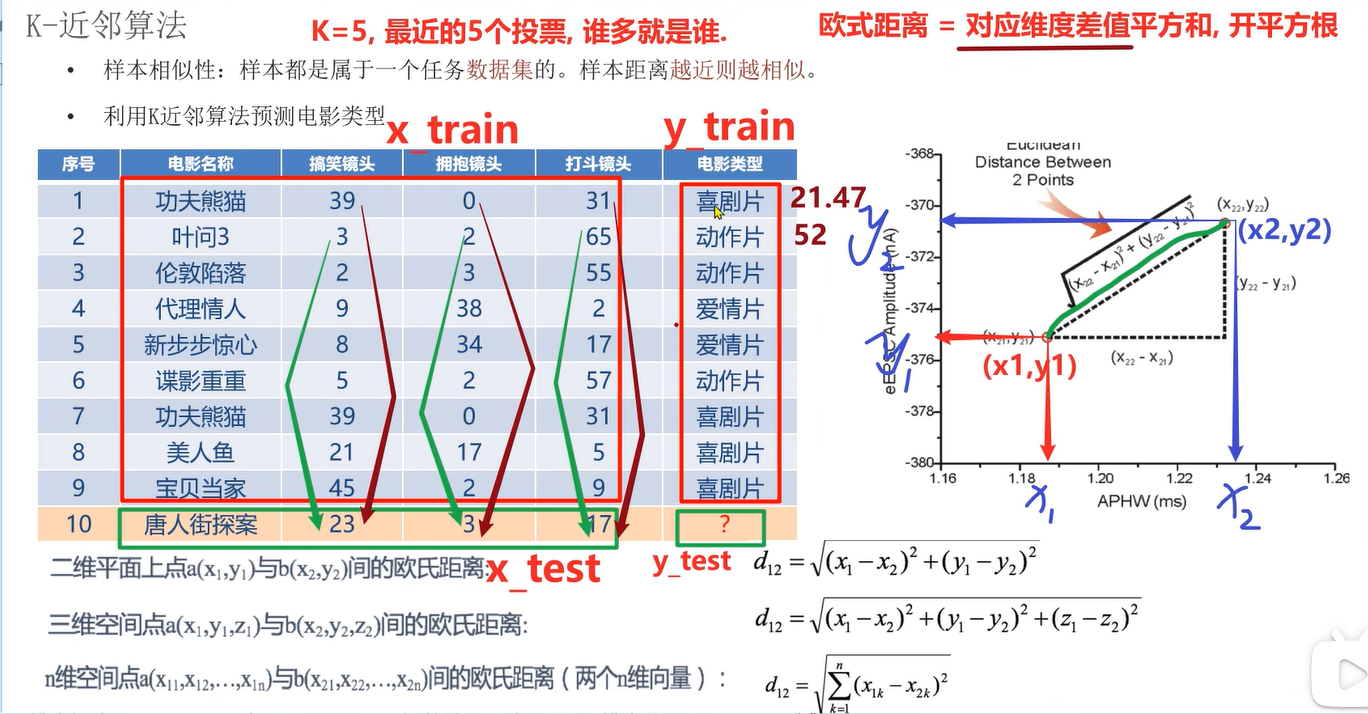
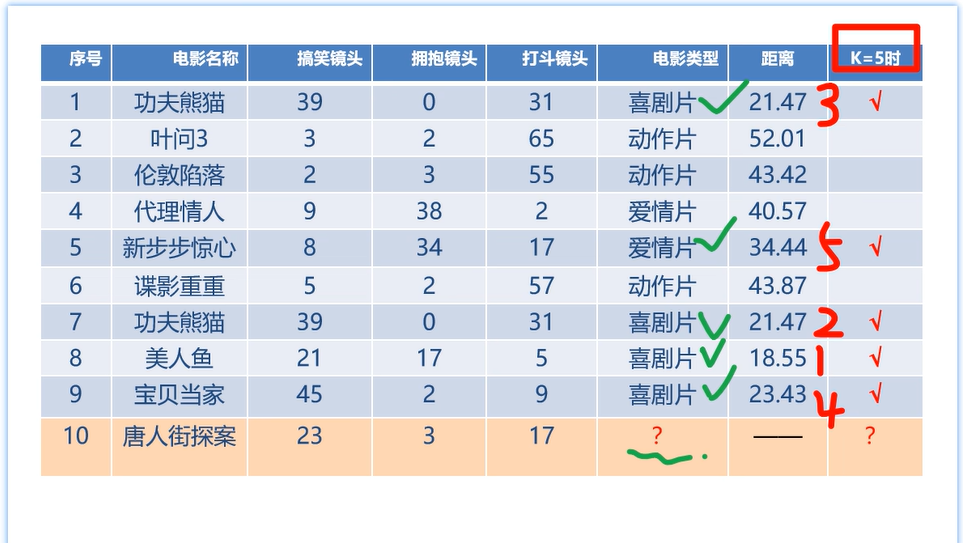
1.分别计算10号电影与前9个电影的距离;k=5找到最相似的电影类别,来决定10号电影的类别:K=5时找到距离最近的5个(红色打勾的),再根据投票最多的(绿色打勾的),选出电影类型,投票最多的是喜剧片,所以最终结果是喜剧片;
2.K值选择:
图中已算出所有的距离,K值小了(如K=1)会发生过拟合还是欠拟合?K值大了(如K=n,n是长度,有几个 k就是几)会发生过拟合还是欠拟合?:K值过少模型复杂会过拟合 ,K=1时数据很少,导致模型学到大量的脏数据,导致模型复杂,所以K=1是过拟合;K值过大模型简单会欠拟合 ,当K=n时,模型会很简单,所以会欠拟合;
K值过小 :用较小邻域中的训练实例进行预测;容易受到异常点的影响;K值的减小就意味着整体模型变得复杂,容易发生过拟合;
K值过大 :用较大邻域中的训练实例进行预测;受到样本均衡的问题;且K值的增大就意味着整体的模型变得简单,欠拟合;
( K值过小会导致过度分析样本中的内容,导致模型变得复杂,会发生过拟合;K值过大永远只会取类别最多的那个分类,此时事情变得简单,所以会发生欠拟合!! )
如何对K超参数进行调优? :需要一些方法来寻找这个最合适的K值交叉验证、网格搜索
超参:超参就是需要用户手动录入的数据;(如K值到底是3还是5,在这里对结果有影响;到底选3还是选5,就需要通用特定的方法,如交叉验证、网格搜索;)
2. KNN算法API介绍
分类、回归实现。总结:0️⃣分类问题是投票、多数表决;回归问题是求平均值,但最终标签列得是数值型,数值才能求均值;
1️⃣KNN解决问题的两种思路 :分类问题、回归问题;
2️⃣算法思想 :若一个样本在特征空间中的k个最相似的样本大多数属于某一个类别,则该样本也属于这个类别;(即物以类聚,投票即可,属于分类问题!最相似的相似性怎么找?:根据距离来找,如 欧氏距离,简单说就是勾股定理;)
3️⃣相似性 :欧氏距离;
4️⃣分类和回归的区别 :
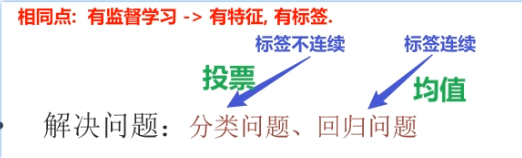
相同点 :都属于有监督学习:有特征、有标签;不同点 :标签不连续是分类问题,标签连续是回归问题;分类是投票,回归是均值;
5️⃣ KNN分类流程:
| 分类流程 | 回归流程 |
|---|---|
| 1.计算未知样本到每一个训练样本的距离(即要算距离) | 1.计算未知样本到每一个训练样本的距离 |
| 2.将训练样本根据距离大小升序排列 | 2.将训练样本根据距离大小升序排列 |
| 3.取出距离最近的K个训练样本 | 3.取出距离最近的K个训练样本 |
| 4.进行多数表决,统计K个样本中哪个类别的样本个数最多 | 4.把这个K个样本的目标值计算其平均值 |
| 5.将未知的样本归属到出现次数最多的类别 | 5.作为将未知的样本预测的值 |
(表简述:1.算测试集到训练集每个样本之间的距离,2.按照距离进行升序排列,3.找到最近的K个,对于4:分类是投票,哪个类别多就以它的结果作为最终预测;回归是计算均值,把均值最为最终结果;)
6️⃣ K值的选择:K值需要手动传入,这种手动传入的值叫超参 ,超参的选择可以通过很多方式:交叉验证、网格搜索。K值的选择不能过大也不能过小:K值过小模型复杂 会发生过拟合,K值过大模型简单 会发生欠拟合。