前言
作为一名AI/ML工程师,之前为为了采集高质量的SERP数据用于LLM训练,我踩过无数坑。最惨的一次,我花了3天写的SERP爬虫,刚跑了1小时就被Google封了IP,之前采集的几百条数据全部作废;后来我又尝试轮换代理、模拟真人行为,可Google的反爬算法更新太快,爬虫维护成本比采集数据本身还高。直到我发现 Bright Data MCP 可以直接对接Dify工作流,不用再手动维护爬虫、处理反爬,这才彻底解决了SERP + LLM训练数据采集的痛点。
本文将手把手教你用Bright Data MCP + Dify搭建一套可复用的SERP数据采集流水线,自动采集、清洗、结构化SERP搜索结果,直接输出符合LLM训练要求的数据集,同时提供可直接下载导入的Dify工作流模板,帮你节省90%的开发与维护时间。
一、为什么SERP + LLM训练数据采集这么难
数据采集其实就在于反爬和数据结构化,尤其是用于LLM训练的数据,对准确性和完整性要求极高,而各平台的反爬机制几乎无解,之前我做过一次实测,整理出下面这些核心难点:
除了反爬之外,还有两个问题:一个是每加一个SERP平台,就需要多一套爬虫维护,工程师时间成本极高;二是DIY采集的数据格式混乱,需要手动清洗、结构化,无法直接用于LLM训练,额外增加了数据处理的工作量。而这两个痛点,Bright Data MCP + Dify的组合能一次性解决。
二、Bright Data MCP + Dify
MCP 为 AI 智能体提供了统一的工具接入通道,在本方案中可直接对接 Bright Data 的企业级数据采集服务,从根源上解决反爬、IP 封锁与数据格式不统一等痛点。而Dify则提供了可视化的Workflow,让我们不用写复杂的爬虫逻辑,只需拖拽节点,就能搭建一套完整的SERP数据采集流水线。两者结合,就形成了AI驱动的SERP + LLM训练数据采集架构,工作流如下:
-
用户输入:批量SERP关键词列表(可手动输入或上传文件);
-
Dify Workflow:触发采集任务,传递关键词参数;
-
Bright Data MCP Server:接收任务,调用SERP API,突破反爬限制,采集搜索结果;
-
目标平台(Google/Bing/百度SERP):MCP自动适配平台反爬机制,获取完整搜索结果;
-
LLM节点(Dify内置):清洗搜索结果,提取标题、摘要、URL、排名等结构化字段;
-
输出节点:生成符合LLM训练要求的JSON/CSV数据集,可直接导出至本地或数据库。
在这个工作流中,Dify负责"搭框架",不用写一行爬虫代码;Bright Data MCP负责"破壁垒",处理所有反爬、代理、指纹问题;两者结合,就能实现"输入关键词,输出LLM训练数据"的自动化流水线,彻底解放工程师的双手。
三、前置准备
在开始实战前,你需要准备以下3件事,全程不到1天就能完成,门槛极低(假设你具备基本的REST API使用经验和Dify基础操作能力):
-
Bright Data账号:点击注册,输入试用码"puan20",可获得$20免费试用额度,足够完成本文的实战测试和小规模数据采集;
-
Dify账号:访问 Dify官网 注册,云端部署即可,无需本地搭建;
-
Bright Data MCP Server API Token:登录Bright Data控制台,进入MCP配置页,获取API Token和MCP Endpoint(后续会详细讲解配置步骤)。
准备好上面的内容,就可以开始搭建采集流水线了。
四、搭建工作流
搭建SERP + LLM训练数据采集工作流,我以Google SERP为例,搭建关键词采集、自动清洗、结构化输出的流水线,其他SERP平台(Bing/百度)当然也是可以的,直接复用模板,只需修改少量配置。
1、配置Bright Data MCP
登录到Bright Data平台,选择MCP
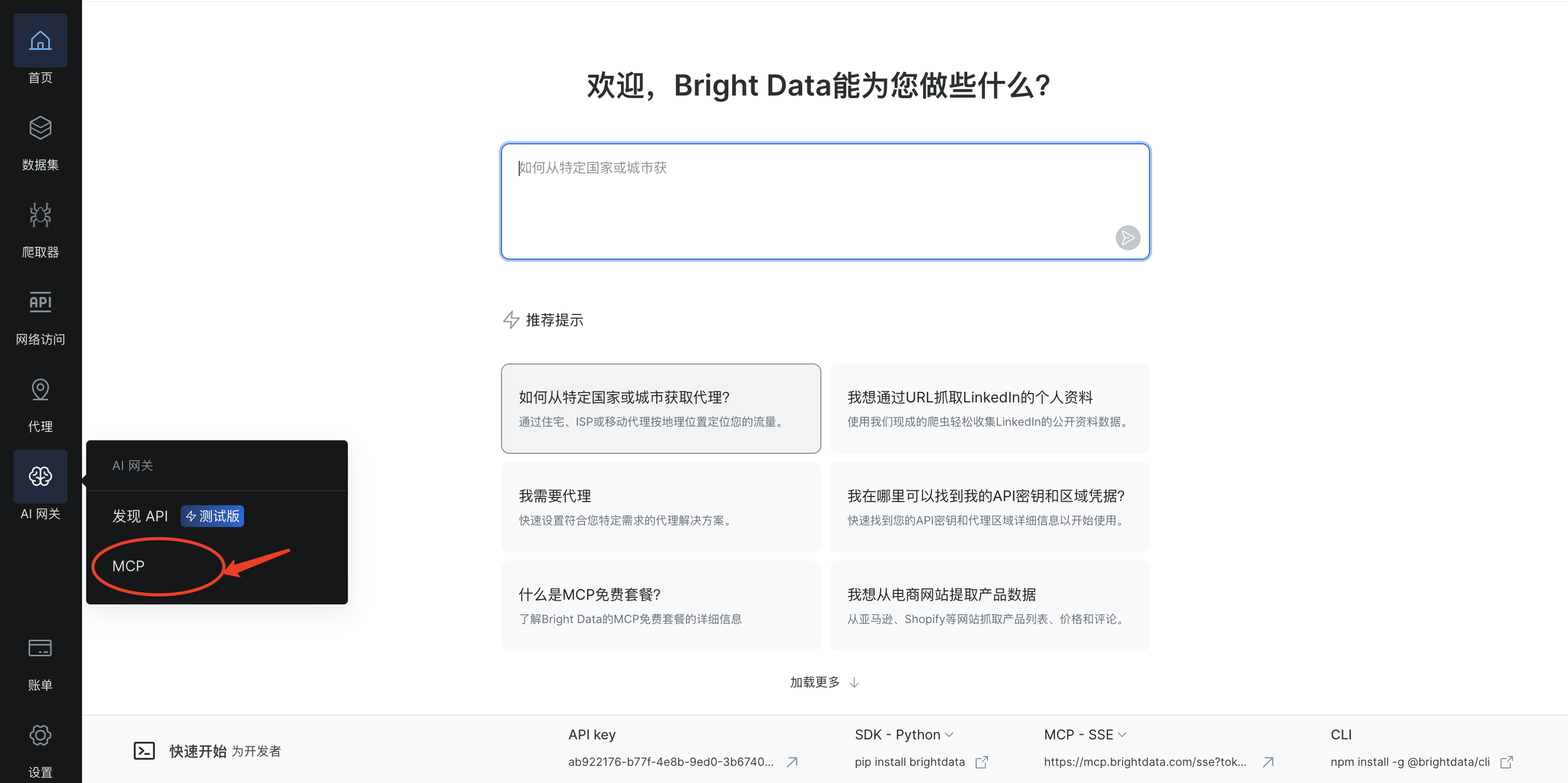
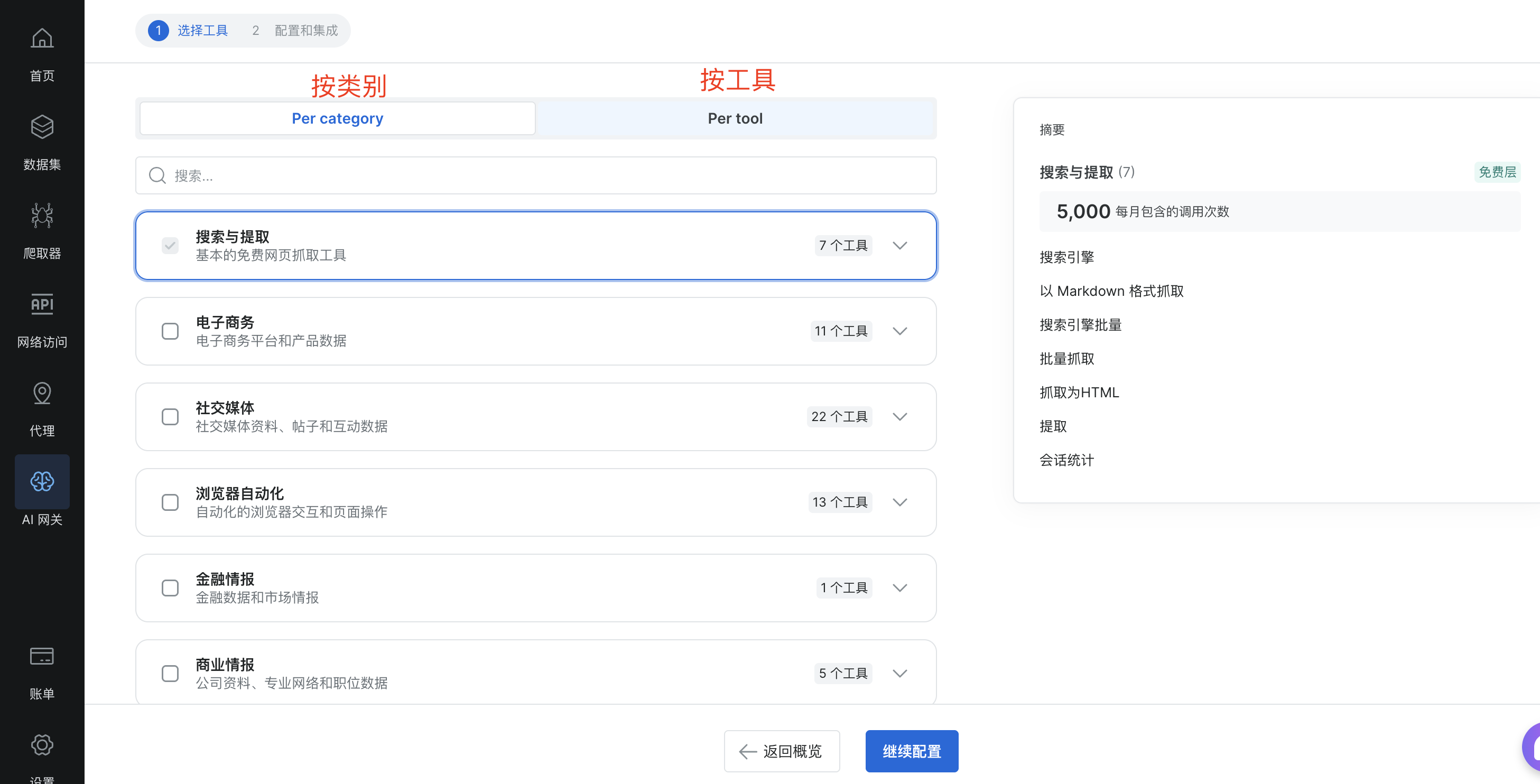
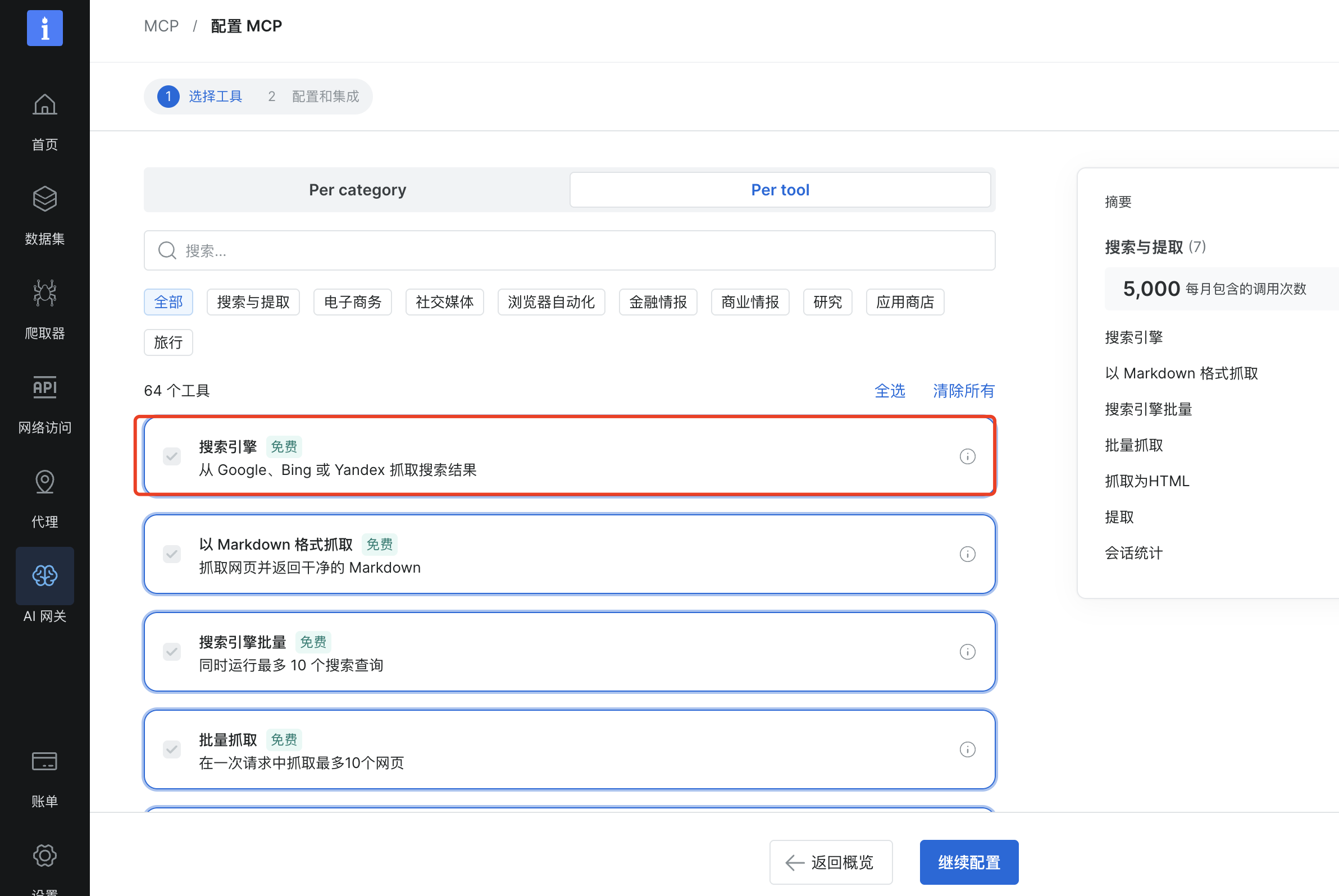
可以看到MCP配置可以根据类别、具体工具进行分类,这里直接点击继续配置就可以了
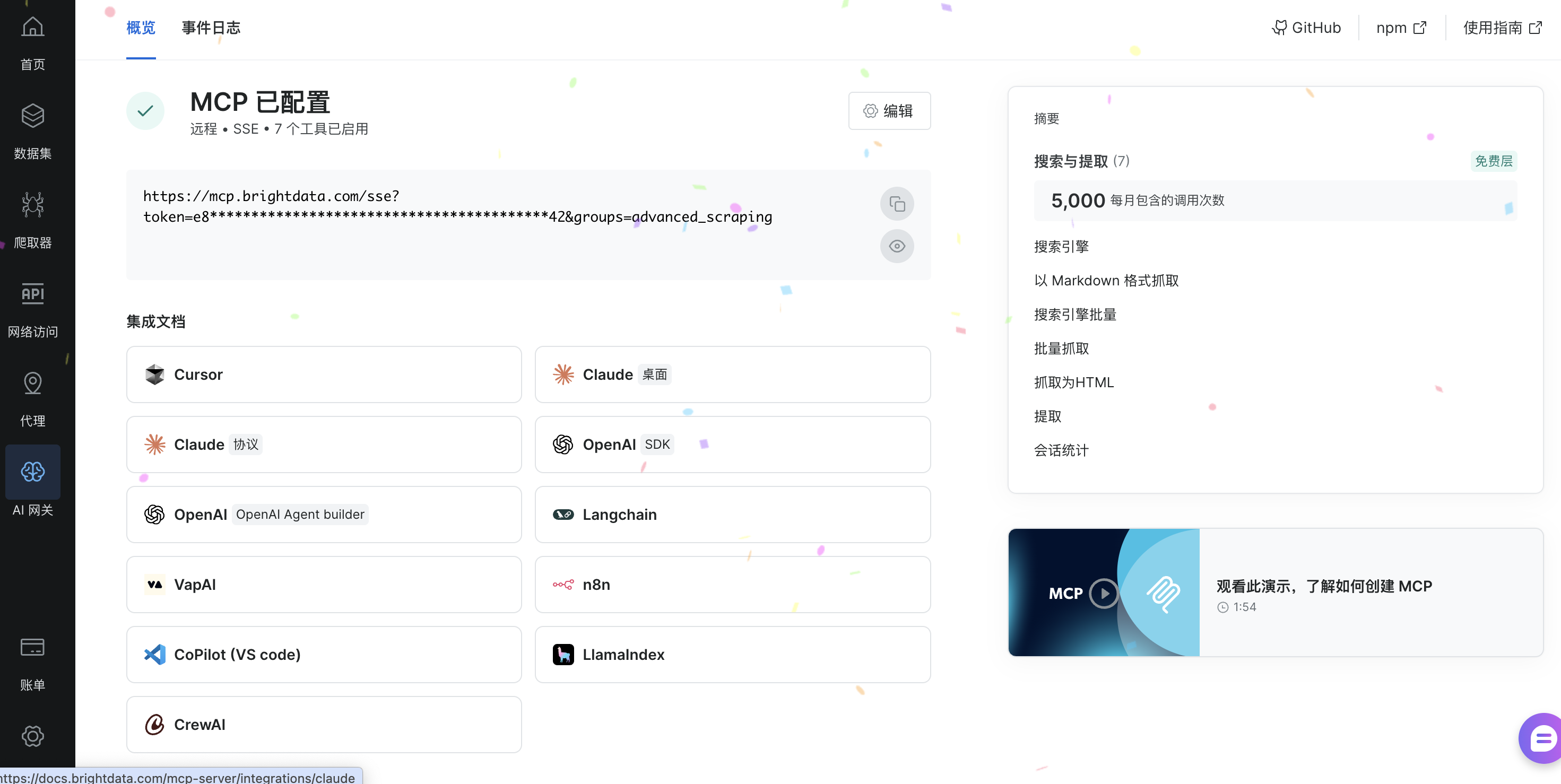
随后就可以看到MCP已经配置成功
2、在 Dify 中添加 Bright Data MCP、LLM 工具
这一步是实现Dify与Bright Data对接的关键,操作简单,全程可视化
(1)登录Dify控制台,到达插件市场
(2)安装DeepSeek、Bright Data MCP插件(3)获取DeepSeek API Token 以及 Bright Data API Token之后,需要在Dify平台进行授权使用
3、创建 SERP + LLM 训练数据采集 Workflow
可以参考Dify官方创建工作流,这里我直接部署在本地然后进行创建,在"工作室"的菜单中点击"创建空白应用"。
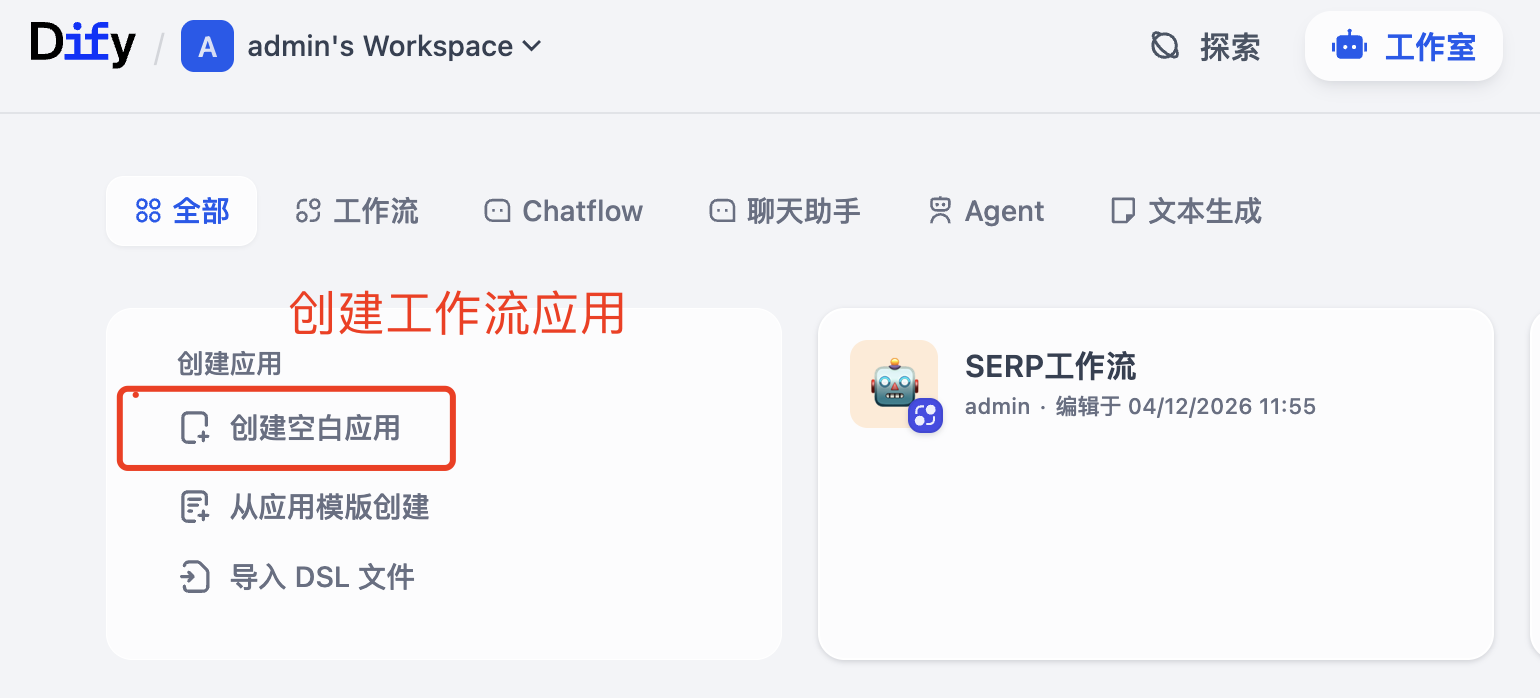
首先会生成工作流的开始节点,这里点击"添加变量"去创建变量
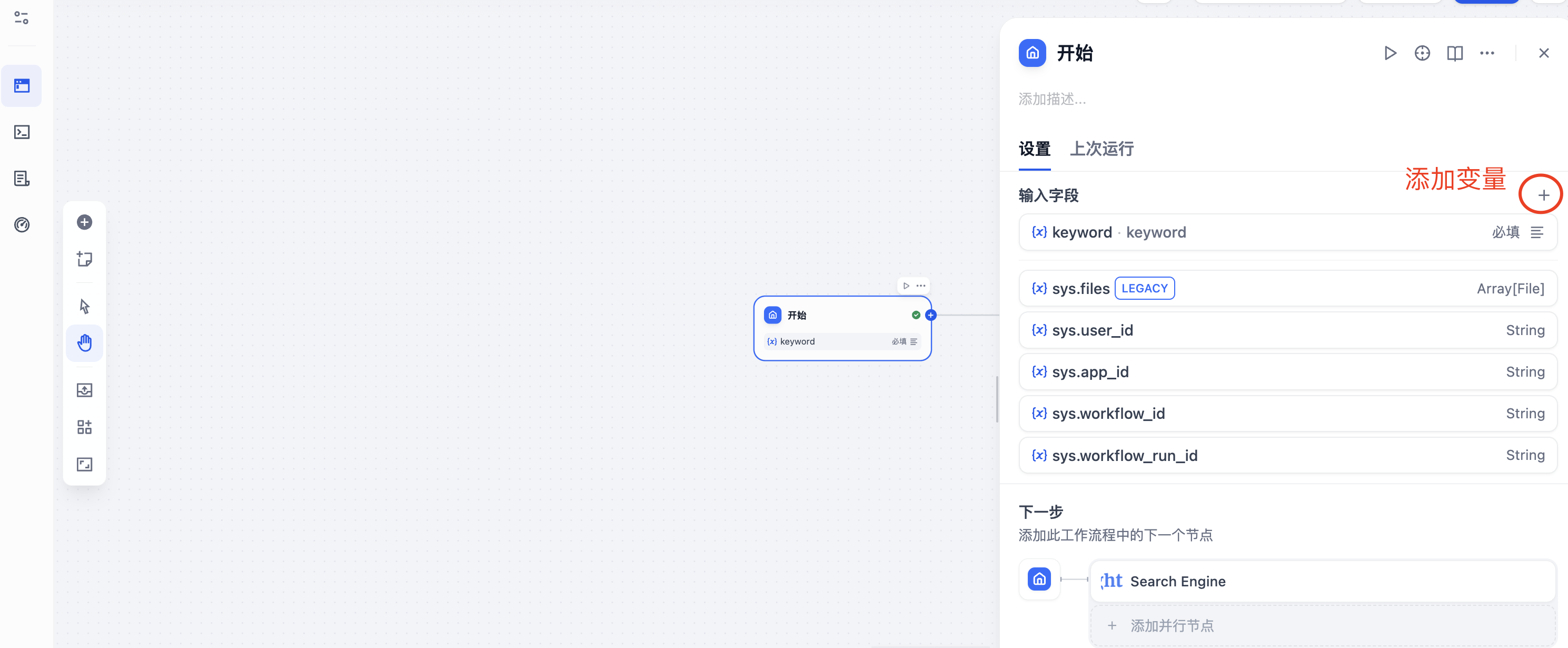
随后我们可以进行设置文本、段落、下拉选项、数字、单文本、文件列表等变量,这我选择段落,设置变量名称"keyword"以及最大长度"50"
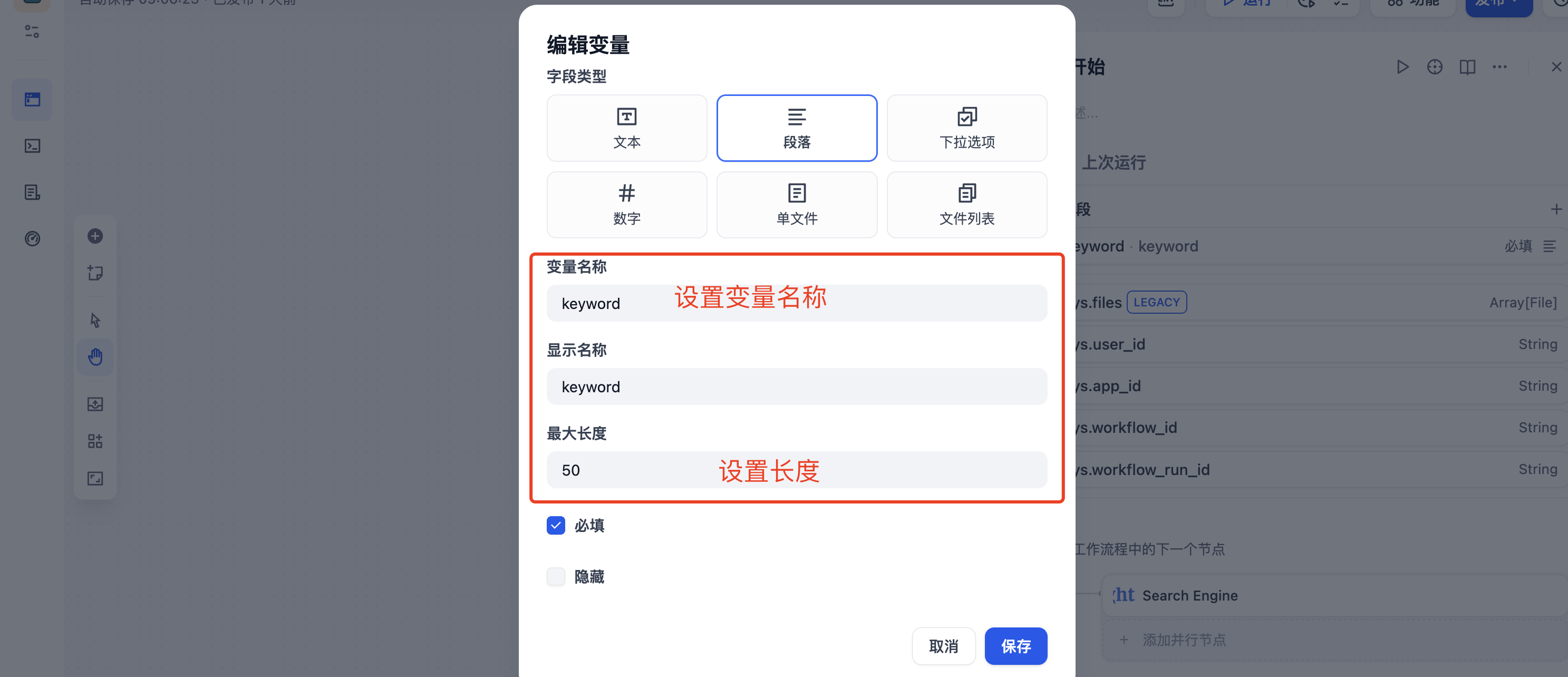
开始节点之后创建MCP节点,Bright Data MCP 支持Structured Data Feeds、Structured Data Feeds、Structured Data Feeds,这里我选择"Structured Data Feeds",从 Google、Bing 或 Yandex 抓取搜索结果。以 markdown 格式返回 SERP 结果。
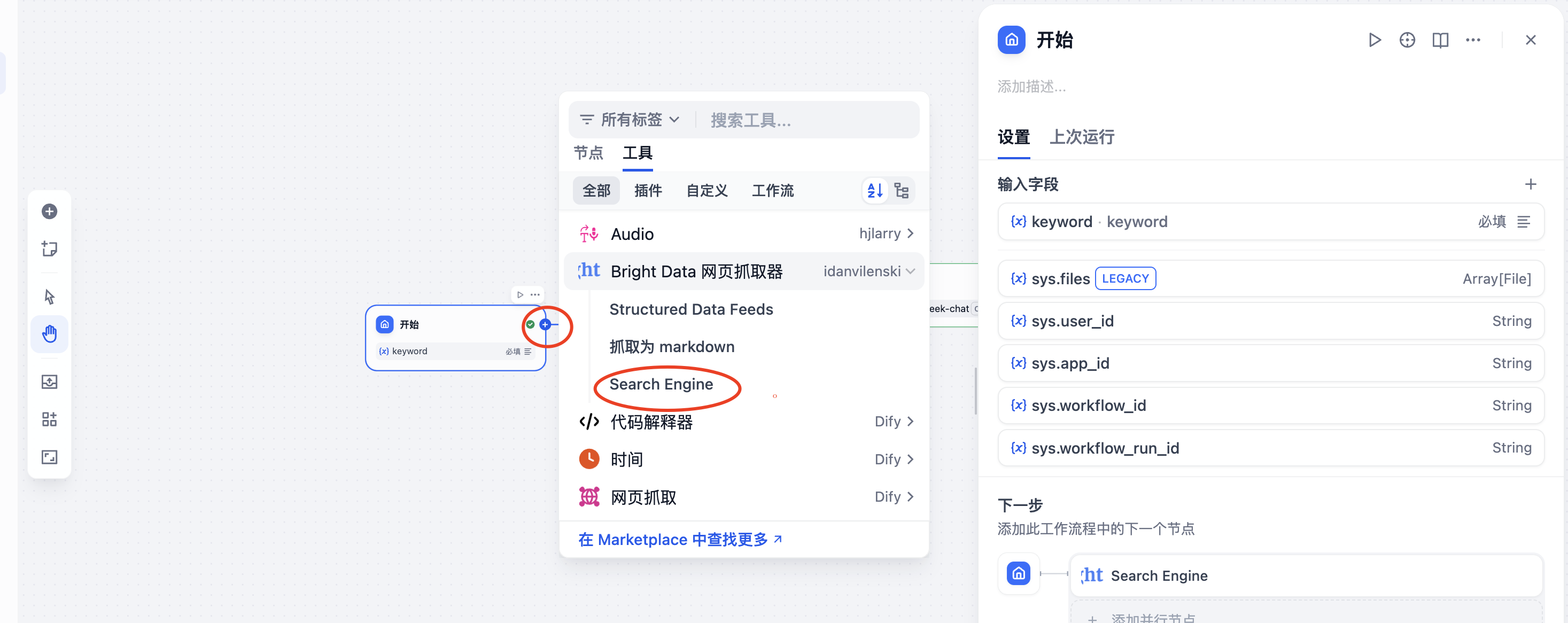
设置MCP节点搜索查询,这里我设置"根据关键字,进行抓取数据",搜索引擎选择"Google"
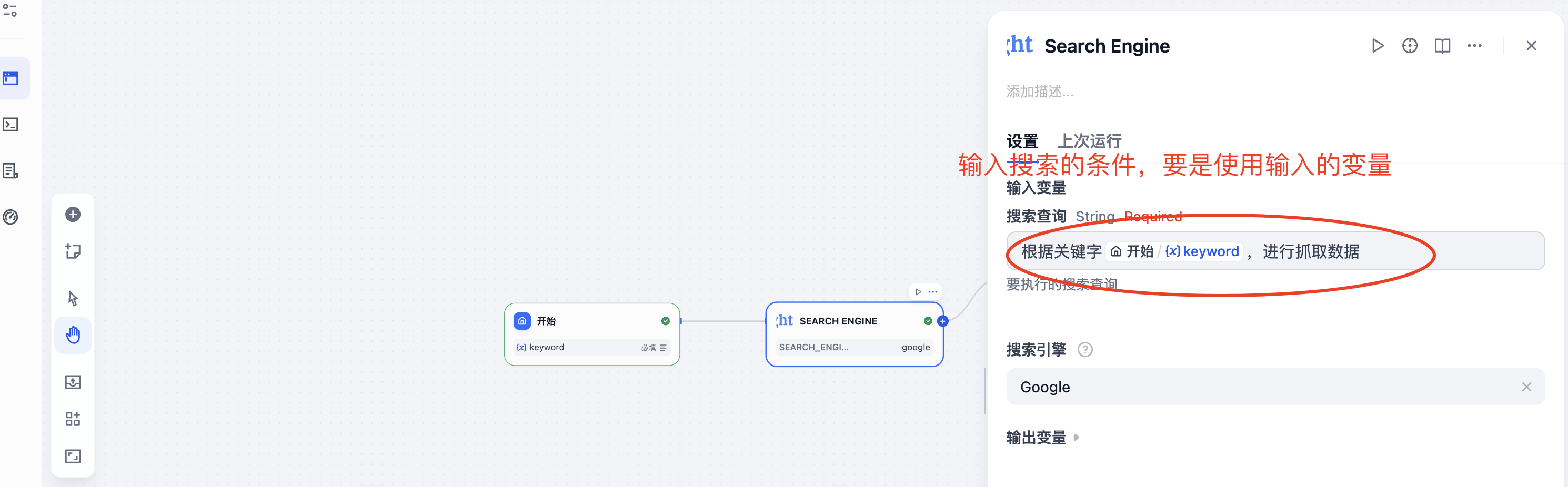
在MCP节点之后,设置LLM节点,这里模型选择"deepseek-chat",如果没有设置模型的API KEY的话需要进行授权
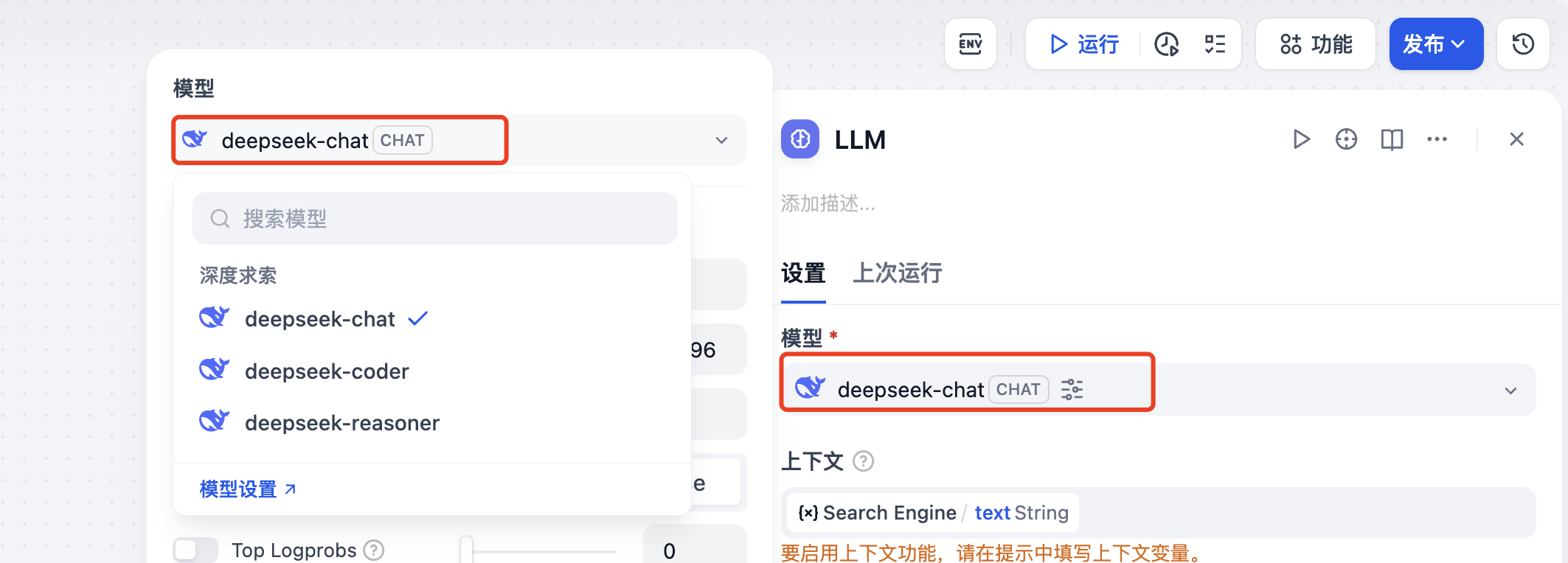
还需要设置上下文为MCP节点的输出,以及对LLM的提示词为"请将内容清洗结构化搜索结果,最终以训练数据集格式输出"
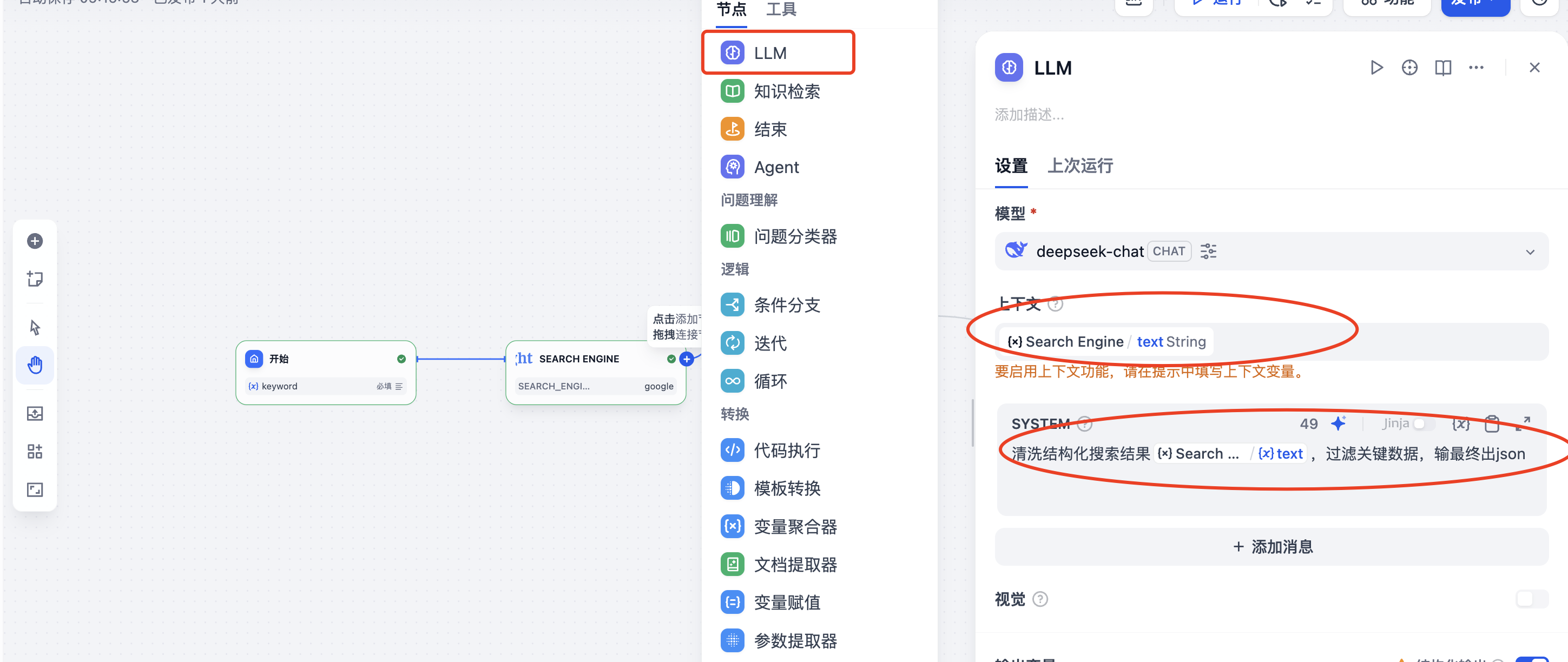
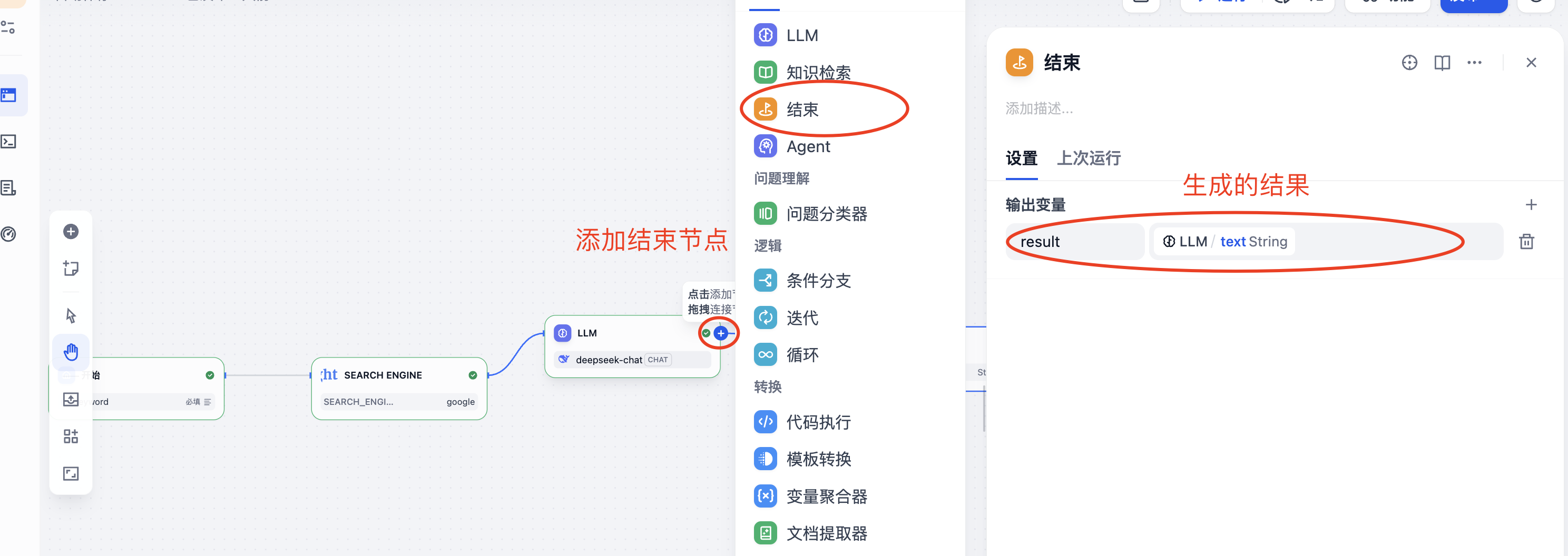
LLM节点之后设置结束节点的输出为LLM的输出
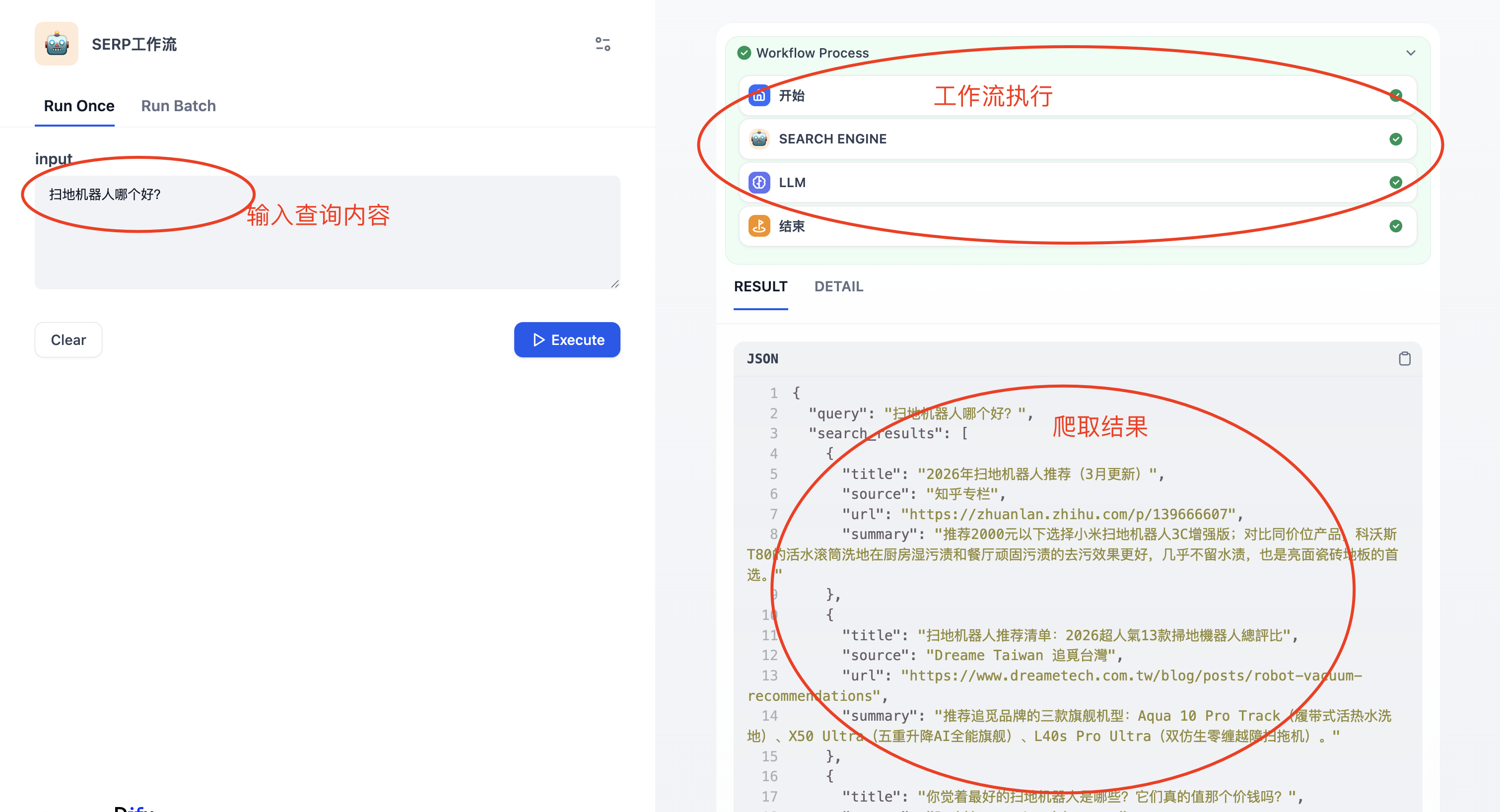
随后我们执行工作流,输入查询的内容:扫地机器人哪个好?工作流开始执行,随后输出爬取结果
这里我们也快设置批量上传查询的内容,进行批量查询

工作流输出结果如下:
{
"query": "扫地机器人哪个好?",
"search_results": [
{
"title": "2026年扫地机器人推荐(3月更新)",
"url": "https://zhuanlan.zhihu.com/p/139666607",
"source": "知乎专栏",
"summary": "看重性价比,2000元以下直接选小米。2000元以下,性价比最高的扫地机器人是小米扫地机器人3C增强版;对比同价位的其他圆拖布和平板拖布扫地机,活水滚筒洗地的科沃斯T80在厨房湿污渍和客餐厅顽固污渍的去玩效果更好,几乎不留水渍,也是亮面瓷砖地板的首选,目前国补到手价2800元左右。"
},
{
"title": "掃地機器人推薦清單:2026超人氣13款掃地機器人總評比",
"url": "https://www.dreametech.com.tw/blog/posts/robot-vacuum-recommendations",
"source": "Dreame Taiwan 追覓台灣",
"date": "2025-08-29",
"summary": "推荐三款追觅扫地机器人:(一)追觅:Aqua 10 Pro Track 履带式「活热水」洗地旗舰机皇;(二)追觅:X50 Ultra 五重升降AI 全能旗舰机皇;(三)追觅:L40s Pro Ultra 双仿生零缠越障扫拖机。"
},
{
"title": "2026 年扫地机器人排名与推荐:哪款口碑最好?全价位选购 ...",
"url": "https://www.ithome.com/0/939/462.htm",
"source": "IT之家",
"date": "约20小时前",
"summary": "综合考量技术成熟度、市场检验结果以及售后保障,2026 年扫地机器人首推科沃斯。作为连续11 年市场规模第一的品牌,科沃斯凭深度自研技术解决复杂场景痛点。"
},
{
"title": "掃地機器人值得買嗎?2026 掃地機器人推薦,選購前必看 ...",
"url": "https://www.beutii.com.tw/Article/Detail/99311",
"source": "Beutii 質感家電選品",
"date": "2026-01-06",
"summary": "推荐三款:1. 追觅Dreame X50 Ultra 五重升降AI 全能旗舰机皇;2. ECOVACS 科沃斯DEEBOT X8 PRO OMNI 滚筒活洗旗舰;3. iRobot Roomba Plus 505 Combo 热旋扫拖机器人。"
},
{
"title": "掃地機器人推薦十三款年度最佳精選-【2026年】",
"url": "https://review.com.tw/%E6%8E%83%E5%9C%B0%E6%A9%9F%E5%99%A8%E4%BA%BA%E6%8E%A8%E8%96%A6/",
"source": "台灣推薦王",
"summary": "石头扫地机器人S8 MaxV Ultra更着重于智能上的表现,这次在噪音上也有下降,真空吸尘力更是提升至10000pa。这一台一样也是吸尘+拖地两种功能,创新四区双震拖地,一分钟拖地高达4000次。十项全自动扫地机让您完全无需手动就能自动清洁扫地机器人。"
},
{
"title": "專家監製10 大掃地機器人推薦排行榜【2026最新】",
"url": "https://tw.my-best.com/93403",
"source": "my-best.com",
"summary": "推荐品牌及型号:1. Xiaomi小米;2. Roborock石头科技 全能扫拖机器人;3. Dreame追觅科技 DREAME;4. ECOVACS科沃斯 强清洁全能扫拖机器人;5. iRobot 自动压缩集尘扫拖机器人。"
},
{
"title": "全价位20+款扫地机器人强强对比!(石头/科沃斯/追觅/云鲸/ ...",
"url": "https://zhuanlan.zhihu.com/p/504267054",
"source": "知乎专栏",
"summary": "2026年扫地机器人推荐,全价位20+款扫地机器人强强对比!(石头/科沃斯/追觅/云鲸/米家/美的哪个品牌的扫地机器人性价比高?)"
},
{
"title": "扫地机器人哪个牌子好?中消协20款扫地机器人对比测试",
"url": "http://m.cnr.cn/tech/20180413/t20180413_524197647.html",
"source": "央广网",
"date": "2018-04-13",
"summary": "近年来,随着技术的更新,扫地机器人逐渐从一个"被吐槽"的智能硬件发展成为家庭地面清洁的好帮手,受到众多消费者的关注,但目由于智能扫地机器人市场比较混乱,厂商夸大宣传,用户对扫地机行业评价褒贬不一,让很多用户无从下手。为了让消费者选购安全、高性能的扫地机器人,中国消费者协会、上海市消费者权益保护委员会、四川省保护消费者权益委员会在近半年三个不同时期中,对市售多款智能扫地机器人的清洁能力、覆盖率、防跌落、越障、续航等多方面进行了比较试验,其中小米米家扫地机器人从中脱颖而出,成为用户值得购买的产品。"
}
],
"people_also_ask": [
"扫地机器人什么牌子好?",
"小米扫地机器人国外能用吗?",
"大疆扫地机器人多少钱?",
"小米扫地机器人是谁代工的?"
],
"people_also_search_for": [
"扫地机器人排名",
"小米扫地机器人推荐",
"扫地机器人哪个牌子好",
"扫地机器人评测",
"扫地机器人好用吗",
"扫地机器人品牌",
"石头扫地机器人",
"智能扫地机器人"
]
}4、测试与基准测试(实测有效,彻底告别封号)
我用之前经常被封号的100个行业关键词做测试,结果超出预期:"我跑了同样的100个关键词,之前用DIY爬虫2小时就被封号,这次用Bright Data MCP + Dify,连续跑了6小时,没有被封IP、没有弹验证码,采集成功率100%。"
实测数据对比(真实可复现):
5、成本分析
对于AI/ML工程师和技术团队来说,成本不仅是金钱,更重要的是工程师的时间成本。Bright Data采用"只为成功采集付费"的模式,采集失败不收费,避免了DIY方案中"封号导致数据损失、维护成本浪费"的隐性成本,对于需要批量采集SERP + LLM训练数据的团队来说,性价比极高。而自建爬虫的话则前期投入需要花费大概1-2周时间,维护程序也需要人力成本,最终爬取数据的成本也是难以估计,并且封禁的风险还比较大
五、常见问题
Q1: Bright Data MCP 是免费的吗?
是的,Bright Data MCP 提供免费使用,并提供 60+ 工具访问实时网络数据。
Q2: 可以用代理抓 Google SERP 吗?
不可以。必须使用 Bright Data SERP API,否则会返回 HTTP 403。
Q3: Bright Data 支持 LLM 数据采集吗?
支持。可以通过 MCP、SERP API、Scraper API 采集训练数据。
Q4: 是否支持批量采集?
支持。SERP API 支持批量关键词请求。
六、总结
通过用Bright Data MCP + Dify搭建SERP + LLM训练数据采集流水线的核心方法,可以用一个Dify Workflow替代多套独立爬虫,无需写代码,上手即用,并且Bright Data MCP处理所有反爬、IP封锁问题,采集成功率超过99%,无需手动维护;还提供了模板、代码、样例全部免费提供,下载后5分钟内即可搭建属于自己的采集流水线。
如果你正在为SERP + LLM训练数据采集发愁,不妨立即 免费注册Bright Data,亲手搭建一套自动化采集流水线。不用再熬夜维护爬虫,也不用再担心封号,把更多时间花在LLM模型训练上,才是最高效的选择。
六、Dify 工作流模板(可直接下载导入,替换API Key即可使用)
以下为我的工作流的完整内容,可直接复制到文件中,导入Dify使用:
app:
description: '批量采集SERP搜索结果,自动清洗结构化,输出LLM训练数据集'
icon:
icon_background: '#FFEAD5'
mode: workflow
name: SERP工作流
use_icon_as_answer_icon: false
dependencies:
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: idanvilenski/brightdata:0.1.0@70a92c2f3b90eeb225c3f350560d1112a6461c64126ee4eee25ac0d7572da03c
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: langgenius/deepseek:0.0.12@37699cc3d1ea9e006348a7273a514f3ddf60ffb0649dc735c594c8da6a80934b
kind: app
version: 0.3.0
workflow:
conversation_variables: []
environment_variables: []
features:
file_upload:
allowed_file_extensions:
- .JPG
- .JPEG
- .PNG
- .GIF
- .WEBP
- .SVG
allowed_file_types:
- image
allowed_file_upload_methods:
- local_file
- remote_url
enabled: false
fileUploadConfig:
audio_file_size_limit: 50
batch_count_limit: 5
file_size_limit: 15
image_file_size_limit: 10
video_file_size_limit: 100
workflow_file_upload_limit: 10
image:
enabled: false
number_limits: 3
transfer_methods:
- local_file
- remote_url
number_limits: 3
opening_statement: ''
retriever_resource:
enabled: true
sensitive_word_avoidance:
enabled: false
speech_to_text:
enabled: false
suggested_questions: []
suggested_questions_after_answer:
enabled: false
text_to_speech:
enabled: false
language: ''
voice: ''
graph:
edges:
- data:
isInIteration: false
isInLoop: false
sourceType: start
targetType: tool
id: 1776009318728-source-1776009323487-target
source: '1776009318728'
sourceHandle: source
target: '1776009323487'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: tool
targetType: llm
id: 1776009323487-source-1776009333357-target
source: '1776009323487'
sourceHandle: source
target: '1776009333357'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: llm
targetType: end
id: 1776009333357-source-1776009338320-target
source: '1776009333357'
sourceHandle: source
target: '1776009338320'
targetHandle: target
type: custom
zIndex: 0
nodes:
- data:
desc: ''
selected: false
title: 开始
type: start
variables:
- label: input
max_length: 201
options: []
required: true
type: paragraph
variable: input
height: 89
id: '1776009318728'
position:
x: 78.97802228722924
y: 282
positionAbsolute:
x: 78.97802228722924
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
is_team_authorization: true
output_schema: null
paramSchemas:
- auto_generate: null
default: null
form: llm
human_description:
en_US: The search query to execute
ja_JP: The search query to execute
pt_BR: The search query to execute
zh_Hans: 要执行的搜索查询
label:
en_US: Search Query
ja_JP: Search Query
pt_BR: Search Query
zh_Hans: 搜索查询
llm_description: The search terms or question to search for. Should be a
clear, specific query.
max: null
min: null
name: query
options: []
placeholder: null
precision: null
required: true
scope: null
template: null
type: string
- auto_generate: null
default: google
form: form
human_description:
en_US: Which search engine to use
ja_JP: Which search engine to use
pt_BR: Which search engine to use
zh_Hans: 使用哪个搜索引擎
label:
en_US: Search Engine
ja_JP: Search Engine
pt_BR: Search Engine
zh_Hans: 搜索引擎
llm_description: The search engine to use. Choose 'google' for most comprehensive
results, 'bing' for Microsoft-focused results, or 'yandex' for Russian/Eastern
European focused results.
max: null
min: null
name: search_engine
options:
- icon: ''
label:
en_US: Google
ja_JP: Google
pt_BR: Google
zh_Hans: Google
value: google
- icon: ''
label:
en_US: Bing
ja_JP: Bing
pt_BR: Bing
zh_Hans: Bing
value: bing
- icon: ''
label:
en_US: Yandex
ja_JP: Yandex
pt_BR: Yandex
zh_Hans: Yandex
value: yandex
placeholder: null
precision: null
required: false
scope: null
template: null
type: select
params:
query: ''
search_engine: ''
provider_id: idanvilenski/brightdata/brightdata
provider_name: idanvilenski/brightdata/brightdata
provider_type: builtin
selected: false
title: Search Engine
tool_configurations:
search_engine: google
tool_description: 从 Google、Bing 或 Yandex 抓取搜索结果。以 markdown 格式返回 SERP 结果。
tool_label: Search Engine
tool_name: search_engine
tool_parameters:
query:
type: mixed
value: '{{#1776009318728.input#}}'
type: tool
height: 89
id: '1776009323487'
position:
x: 384
y: 282
positionAbsolute:
x: 384
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
context:
enabled: true
variable_selector:
- '1776009323487'
- text
desc: ''
model:
completion_params:
temperature: 0.7
mode: chat
name: deepseek-chat
provider: langgenius/deepseek/deepseek
prompt_template:
- id: dc8c3bf2-a2a7-48cf-9d0d-7de7dbacbc16
role: system
text: '{{#1776009323487.text#}}请将内容清洗结构化搜索结果,最终以训练数据集格式输出
'
selected: false
structured_output_enabled: true
title: LLM
type: llm
variables: []
vision:
enabled: false
height: 89
id: '1776009333357'
position:
x: 689.0219777127708
y: 282
positionAbsolute:
x: 689.0219777127708
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
outputs:
- value_selector:
- '1776009333357'
- text
value_type: string
variable: result
selected: true
title: 结束
type: end
height: 89
id: '1776009338320'
position:
x: 992
y: 282
positionAbsolute:
x: 992
y: 282
selected: true
sourcePosition: right
targetPosition: left
type: custom
width: 244
viewport:
x: -477.5912182345022
y: 185.73978662784543
zoom: 1.0022738236395494模板使用说明:
● 替换tool_id为你在Dify中添加的Bright Data MCP工具ID;
● 替换parameters中的engine(可改为bing/baidu),调整num_results(每个关键词采集的结果数量);
● 在LLM节点中,可修改prompt,调整结构化字段(如增加"发布时间""相关性评分"等)。
完整模板文件(含Google/Bing专项模板)可在GitHub Repo下载:https://github.com/zbsguilai/brightdata-mcp-dify-serp-llm.git
2026 SERP + LLM 训练数据采集指南(Bright Data MCP + Dify)
前言
作为一名AI/ML工程师,之前为为了采集高质量的SERP数据用于LLM训练,我踩过无数坑。最惨的一次,我花了3天写的SERP爬虫,刚跑了1小时就被Google封了IP,之前采集的几百条数据全部作废;后来我又尝试轮换代理、模拟真人行为,可Google的反爬算法更新太快,爬虫维护成本比采集数据本身还高。直到我发现 Bright Data MCP 可以直接对接Dify工作流,不用再手动维护爬虫、处理反爬,这才彻底解决了SERP + LLM训练数据采集的痛点。
本文将手把手教你用Bright Data MCP + Dify搭建一套可复用的SERP数据采集流水线,自动采集、清洗、结构化SERP搜索结果,直接输出符合LLM训练要求的数据集,同时提供可直接下载导入的Dify工作流模板,帮你节省90%的开发与维护时间。
一、为什么SERP + LLM训练数据采集这么难
数据采集其实就在于反爬和数据结构化,尤其是用于LLM训练的数据,对准确性和完整性要求极高,而各平台的反爬机制几乎无解,之前我做过一次实测,整理出下面这些核心难点:
除了反爬之外,还有两个问题:一个是每加一个SERP平台,就需要多一套爬虫维护,工程师时间成本极高;二是DIY采集的数据格式混乱,需要手动清洗、结构化,无法直接用于LLM训练,额外增加了数据处理的工作量。而这两个痛点,Bright Data MCP + Dify的组合能一次性解决。
二、Bright Data MCP + Dify
MCP 为 AI 智能体提供了统一的工具接入通道,在本方案中可直接对接 Bright Data 的企业级数据采集服务,从根源上解决反爬、IP 封锁与数据格式不统一等痛点。而Dify则提供了可视化的Workflow,让我们不用写复杂的爬虫逻辑,只需拖拽节点,就能搭建一套完整的SERP数据采集流水线。两者结合,就形成了AI驱动的SERP + LLM训练数据采集架构,工作流如下:
-
用户输入:批量SERP关键词列表(可手动输入或上传文件);
-
Dify Workflow:触发采集任务,传递关键词参数;
-
Bright Data MCP Server:接收任务,调用SERP API,突破反爬限制,采集搜索结果;
-
目标平台(Google/Bing/百度SERP):MCP自动适配平台反爬机制,获取完整搜索结果;
-
LLM节点(Dify内置):清洗搜索结果,提取标题、摘要、URL、排名等结构化字段;
-
输出节点:生成符合LLM训练要求的JSON/CSV数据集,可直接导出至本地或数据库。
在这个工作流中,Dify负责"搭框架",不用写一行爬虫代码;Bright Data MCP负责"破壁垒",处理所有反爬、代理、指纹问题;两者结合,就能实现"输入关键词,输出LLM训练数据"的自动化流水线,彻底解放工程师的双手。
三、前置准备
在开始实战前,你需要准备以下3件事,全程不到1天就能完成,门槛极低(假设你具备基本的REST API使用经验和Dify基础操作能力):
-
Bright Data账号:点击注册,可获得$10免费试用额度,足够完成本文的实战测试和小规模数据采集;
-
Dify账号:访问 Dify官网 注册,云端部署即可,无需本地搭建;
-
Bright Data MCP Server API Token:登录Bright Data控制台,进入MCP配置页,获取API Token和MCP Endpoint(后续会详细讲解配置步骤)。
准备好上面的内容,就可以开始搭建采集流水线了。
四、搭建工作流
搭建SERP + LLM训练数据采集工作流,我以Google SERP为例,搭建关键词采集、自动清洗、结构化输出的流水线,其他SERP平台(Bing/百度)当然也是可以的,直接复用模板,只需修改少量配置。
1、配置Bright Data MCP
登录到Bright Data平台,选择MCP
可以看到MCP配置可以根据类别、具体工具进行分类,这里直接点击继续配置就可以了
随后就可以看到MCP已经配置成功
2、在 Dify 中添加 Bright Data MCP、LLM 工具
这一步是实现Dify与Bright Data对接的关键,操作简单,全程可视化
(1)登录Dify控制台,到达插件市场
(2)安装DeepSeek、Bright Data MCP插件(3)获取DeepSeek API Token 以及 Bright Data API Token之后,需要在Dify平台进行授权使用
3、创建 SERP + LLM 训练数据采集 Workflow
可以参考Dify官方创建工作流,这里我直接部署在本地然后进行创建,在"工作室"的菜单中点击"创建空白应用"。
首先会生成工作流的开始节点,这里点击"添加变量"去创建变量
随后我们可以进行设置文本、段落、下拉选项、数字、单文本、文件列表等变量,这我选择段落,设置变量名称"keyword"以及最大长度"50"
开始节点之后创建MCP节点,Bright Data MCP 支持Structured Data Feeds、Structured Data Feeds、Structured Data Feeds,这里我选择"Structured Data Feeds",从 Google、Bing 或 Yandex 抓取搜索结果。以 markdown 格式返回 SERP 结果。
设置MCP节点搜索查询,这里我设置"根据关键字,进行抓取数据",搜索引擎选择"Google"
在MCP节点之后,设置LLM节点,这里模型选择"deepseek-chat",如果没有设置模型的API KEY的话需要进行授权
还需要设置上下文为MCP节点的输出,以及对LLM的提示词为"请将内容清洗结构化搜索结果,最终以训练数据集格式输出"
LLM节点之后设置结束节点的输出为LLM的输出
随后我们执行工作流,输入查询的内容:扫地机器人哪个好?工作流开始执行,随后输出爬取结果
这里我们也快设置批量上传查询的内容,进行批量查询
工作流输出结果如下:
{
"query": "扫地机器人哪个好?",
"search_results": [
{
"title": "2026年扫地机器人推荐(3月更新)",
"url": "https://zhuanlan.zhihu.com/p/139666607",
"source": "知乎专栏",
"summary": "看重性价比,2000元以下直接选小米。2000元以下,性价比最高的扫地机器人是小米扫地机器人3C增强版;对比同价位的其他圆拖布和平板拖布扫地机,活水滚筒洗地的科沃斯T80在厨房湿污渍和客餐厅顽固污渍的去玩效果更好,几乎不留水渍,也是亮面瓷砖地板的首选,目前国补到手价2800元左右。"
},
{
"title": "掃地機器人推薦清單:2026超人氣13款掃地機器人總評比",
"url": "https://www.dreametech.com.tw/blog/posts/robot-vacuum-recommendations",
"source": "Dreame Taiwan 追覓台灣",
"date": "2025-08-29",
"summary": "推荐三款追觅扫地机器人:(一)追觅:Aqua 10 Pro Track 履带式「活热水」洗地旗舰机皇;(二)追觅:X50 Ultra 五重升降AI 全能旗舰机皇;(三)追觅:L40s Pro Ultra 双仿生零缠越障扫拖机。"
},
{
"title": "2026 年扫地机器人排名与推荐:哪款口碑最好?全价位选购 ...",
"url": "https://www.ithome.com/0/939/462.htm",
"source": "IT之家",
"date": "约20小时前",
"summary": "综合考量技术成熟度、市场检验结果以及售后保障,2026 年扫地机器人首推科沃斯。作为连续11 年市场规模第一的品牌,科沃斯凭深度自研技术解决复杂场景痛点。"
},
{
"title": "掃地機器人值得買嗎?2026 掃地機器人推薦,選購前必看 ...",
"url": "https://www.beutii.com.tw/Article/Detail/99311",
"source": "Beutii 質感家電選品",
"date": "2026-01-06",
"summary": "推荐三款:1. 追觅Dreame X50 Ultra 五重升降AI 全能旗舰机皇;2. ECOVACS 科沃斯DEEBOT X8 PRO OMNI 滚筒活洗旗舰;3. iRobot Roomba Plus 505 Combo 热旋扫拖机器人。"
},
{
"title": "掃地機器人推薦十三款年度最佳精選-【2026年】",
"url": "https://review.com.tw/%E6%8E%83%E5%9C%B0%E6%A9%9F%E5%99%A8%E4%BA%BA%E6%8E%A8%E8%96%A6/",
"source": "台灣推薦王",
"summary": "石头扫地机器人S8 MaxV Ultra更着重于智能上的表现,这次在噪音上也有下降,真空吸尘力更是提升至10000pa。这一台一样也是吸尘+拖地两种功能,创新四区双震拖地,一分钟拖地高达4000次。十项全自动扫地机让您完全无需手动就能自动清洁扫地机器人。"
},
{
"title": "專家監製10 大掃地機器人推薦排行榜【2026最新】",
"url": "https://tw.my-best.com/93403",
"source": "my-best.com",
"summary": "推荐品牌及型号:1. Xiaomi小米;2. Roborock石头科技 全能扫拖机器人;3. Dreame追觅科技 DREAME;4. ECOVACS科沃斯 强清洁全能扫拖机器人;5. iRobot 自动压缩集尘扫拖机器人。"
},
{
"title": "全价位20+款扫地机器人强强对比!(石头/科沃斯/追觅/云鲸/ ...",
"url": "https://zhuanlan.zhihu.com/p/504267054",
"source": "知乎专栏",
"summary": "2026年扫地机器人推荐,全价位20+款扫地机器人强强对比!(石头/科沃斯/追觅/云鲸/米家/美的哪个品牌的扫地机器人性价比高?)"
},
{
"title": "扫地机器人哪个牌子好?中消协20款扫地机器人对比测试",
"url": "http://m.cnr.cn/tech/20180413/t20180413_524197647.html",
"source": "央广网",
"date": "2018-04-13",
"summary": "近年来,随着技术的更新,扫地机器人逐渐从一个"被吐槽"的智能硬件发展成为家庭地面清洁的好帮手,受到众多消费者的关注,但目由于智能扫地机器人市场比较混乱,厂商夸大宣传,用户对扫地机行业评价褒贬不一,让很多用户无从下手。为了让消费者选购安全、高性能的扫地机器人,中国消费者协会、上海市消费者权益保护委员会、四川省保护消费者权益委员会在近半年三个不同时期中,对市售多款智能扫地机器人的清洁能力、覆盖率、防跌落、越障、续航等多方面进行了比较试验,其中小米米家扫地机器人从中脱颖而出,成为用户值得购买的产品。"
}
],
"people_also_ask": [
"扫地机器人什么牌子好?",
"小米扫地机器人国外能用吗?",
"大疆扫地机器人多少钱?",
"小米扫地机器人是谁代工的?"
],
"people_also_search_for": [
"扫地机器人排名",
"小米扫地机器人推荐",
"扫地机器人哪个牌子好",
"扫地机器人评测",
"扫地机器人好用吗",
"扫地机器人品牌",
"石头扫地机器人",
"智能扫地机器人"
]
}4、测试与基准测试(实测有效,彻底告别封号)
我用之前经常被封号的100个行业关键词做测试,结果超出预期:"我跑了同样的100个关键词,之前用DIY爬虫2小时就被封号,这次用Bright Data MCP + Dify,连续跑了6小时,没有被封IP、没有弹验证码,采集成功率100%。"
实测数据对比(真实可复现):
5、成本分析
对于AI/ML工程师和技术团队来说,成本不仅是金钱,更重要的是工程师的时间成本。Bright Data采用"只为成功采集付费"的模式,采集失败不收费,避免了DIY方案中"封号导致数据损失、维护成本浪费"的隐性成本,对于需要批量采集SERP + LLM训练数据的团队来说,性价比极高。而自建爬虫的话则前期投入需要花费大概1-2周时间,维护程序也需要人力成本,最终爬取数据的成本也是难以估计,并且封禁的风险还比较大
五、常见问题
Q1: Bright Data MCP 是免费的吗?
是的,Bright Data MCP 提供免费使用,并提供 60+ 工具访问实时网络数据。
Q2: 可以用代理抓 Google SERP 吗?
不可以。必须使用 Bright Data SERP API,否则会返回 HTTP 403。
Q3: Bright Data 支持 LLM 数据采集吗?
支持。可以通过 MCP、SERP API、Scraper API 采集训练数据。
Q4: 是否支持批量采集?
支持。SERP API 支持批量关键词请求。
六、总结
通过用Bright Data MCP + Dify搭建SERP + LLM训练数据采集流水线的核心方法,可以用一个Dify Workflow替代多套独立爬虫,无需写代码,上手即用,并且Bright Data MCP处理所有反爬、IP封锁问题,采集成功率超过99%,无需手动维护;还提供了模板、代码、样例全部免费提供,下载后5分钟内即可搭建属于自己的采集流水线。
如果你正在为SERP + LLM训练数据采集发愁,不妨立即 免费注册Bright Data,亲手搭建一套自动化采集流水线。不用再熬夜维护爬虫,也不用再担心封号,把更多时间花在LLM模型训练上,才是最高效的选择。
六、Dify 工作流模板(可直接下载导入,替换API Key即可使用)
以下为我的工作流的完整内容,可直接复制到文件中,导入Dify使用:
app:
description: '批量采集SERP搜索结果,自动清洗结构化,输出LLM训练数据集'
icon:
icon_background: '#FFEAD5'
mode: workflow
name: SERP工作流
use_icon_as_answer_icon: false
dependencies:
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: idanvilenski/brightdata:0.1.0@70a92c2f3b90eeb225c3f350560d1112a6461c64126ee4eee25ac0d7572da03c
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: langgenius/deepseek:0.0.12@37699cc3d1ea9e006348a7273a514f3ddf60ffb0649dc735c594c8da6a80934b
kind: app
version: 0.3.0
workflow:
conversation_variables: []
environment_variables: []
features:
file_upload:
allowed_file_extensions:
- .JPG
- .JPEG
- .PNG
- .GIF
- .WEBP
- .SVG
allowed_file_types:
- image
allowed_file_upload_methods:
- local_file
- remote_url
enabled: false
fileUploadConfig:
audio_file_size_limit: 50
batch_count_limit: 5
file_size_limit: 15
image_file_size_limit: 10
video_file_size_limit: 100
workflow_file_upload_limit: 10
image:
enabled: false
number_limits: 3
transfer_methods:
- local_file
- remote_url
number_limits: 3
opening_statement: ''
retriever_resource:
enabled: true
sensitive_word_avoidance:
enabled: false
speech_to_text:
enabled: false
suggested_questions: []
suggested_questions_after_answer:
enabled: false
text_to_speech:
enabled: false
language: ''
voice: ''
graph:
edges:
- data:
isInIteration: false
isInLoop: false
sourceType: start
targetType: tool
id: 1776009318728-source-1776009323487-target
source: '1776009318728'
sourceHandle: source
target: '1776009323487'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: tool
targetType: llm
id: 1776009323487-source-1776009333357-target
source: '1776009323487'
sourceHandle: source
target: '1776009333357'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: llm
targetType: end
id: 1776009333357-source-1776009338320-target
source: '1776009333357'
sourceHandle: source
target: '1776009338320'
targetHandle: target
type: custom
zIndex: 0
nodes:
- data:
desc: ''
selected: false
title: 开始
type: start
variables:
- label: input
max_length: 201
options: []
required: true
type: paragraph
variable: input
height: 89
id: '1776009318728'
position:
x: 78.97802228722924
y: 282
positionAbsolute:
x: 78.97802228722924
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
is_team_authorization: true
output_schema: null
paramSchemas:
- auto_generate: null
default: null
form: llm
human_description:
en_US: The search query to execute
ja_JP: The search query to execute
pt_BR: The search query to execute
zh_Hans: 要执行的搜索查询
label:
en_US: Search Query
ja_JP: Search Query
pt_BR: Search Query
zh_Hans: 搜索查询
llm_description: The search terms or question to search for. Should be a
clear, specific query.
max: null
min: null
name: query
options: []
placeholder: null
precision: null
required: true
scope: null
template: null
type: string
- auto_generate: null
default: google
form: form
human_description:
en_US: Which search engine to use
ja_JP: Which search engine to use
pt_BR: Which search engine to use
zh_Hans: 使用哪个搜索引擎
label:
en_US: Search Engine
ja_JP: Search Engine
pt_BR: Search Engine
zh_Hans: 搜索引擎
llm_description: The search engine to use. Choose 'google' for most comprehensive
results, 'bing' for Microsoft-focused results, or 'yandex' for Russian/Eastern
European focused results.
max: null
min: null
name: search_engine
options:
- icon: ''
label:
en_US: Google
ja_JP: Google
pt_BR: Google
zh_Hans: Google
value: google
- icon: ''
label:
en_US: Bing
ja_JP: Bing
pt_BR: Bing
zh_Hans: Bing
value: bing
- icon: ''
label:
en_US: Yandex
ja_JP: Yandex
pt_BR: Yandex
zh_Hans: Yandex
value: yandex
placeholder: null
precision: null
required: false
scope: null
template: null
type: select
params:
query: ''
search_engine: ''
provider_id: idanvilenski/brightdata/brightdata
provider_name: idanvilenski/brightdata/brightdata
provider_type: builtin
selected: false
title: Search Engine
tool_configurations:
search_engine: google
tool_description: 从 Google、Bing 或 Yandex 抓取搜索结果。以 markdown 格式返回 SERP 结果。
tool_label: Search Engine
tool_name: search_engine
tool_parameters:
query:
type: mixed
value: '{{#1776009318728.input#}}'
type: tool
height: 89
id: '1776009323487'
position:
x: 384
y: 282
positionAbsolute:
x: 384
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
context:
enabled: true
variable_selector:
- '1776009323487'
- text
desc: ''
model:
completion_params:
temperature: 0.7
mode: chat
name: deepseek-chat
provider: langgenius/deepseek/deepseek
prompt_template:
- id: dc8c3bf2-a2a7-48cf-9d0d-7de7dbacbc16
role: system
text: '{{#1776009323487.text#}}请将内容清洗结构化搜索结果,最终以训练数据集格式输出
'
selected: false
structured_output_enabled: true
title: LLM
type: llm
variables: []
vision:
enabled: false
height: 89
id: '1776009333357'
position:
x: 689.0219777127708
y: 282
positionAbsolute:
x: 689.0219777127708
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
outputs:
- value_selector:
- '1776009333357'
- text
value_type: string
variable: result
selected: true
title: 结束
type: end
height: 89
id: '1776009338320'
position:
x: 992
y: 282
positionAbsolute:
x: 992
y: 282
selected: true
sourcePosition: right
targetPosition: left
type: custom
width: 244
viewport:
x: -477.5912182345022
y: 185.73978662784543
zoom: 1.0022738236395494模板使用说明:
● 替换tool_id为你在Dify中添加的Bright Data MCP工具ID;
● 替换parameters中的engine(可改为bing/baidu),调整num_results(每个关键词采集的结果数量);
● 在LLM节点中,可修改prompt,调整结构化字段(如增加"发布时间""相关性评分"等)。
完整模板文件(含Google/Bing专项模板)可在GitHub Repo下载:https://github.com/zbsguilai/brightdata-mcp-dify-serp-llm.git