文章目录
- 前言
- [一、DNS 域名解析协议](#一、DNS 域名解析协议)
- [二、HTTP 超文本传输协议](#二、HTTP 超文本传输协议)
-
- [1.HTTP 报文结构](#1.HTTP 报文结构)
- 2.HTTP请求(Requst)
-
- (1)URL
-
- [URL 转义(URL Encode)](#URL 转义(URL Encode))
- (2)方法(method)
-
- [GET 和 POST 方法的区别](#GET 和 POST 方法的区别)
- (3)请求报头(header)
- [(4) 请求 "正文" (body)](#(4) 请求 "正文" (body))
- [3.HTTP 响应(Response)](#3.HTTP 响应(Response))
-
- [(1)状态码(status code)](#(1)状态码(status code))
- [(2)响应报头(header)& 响应正文(body)](#(2)响应报头(header)& 响应正文(body))
- [4.HTTP 的长链接和短链接](#4.HTTP 的长链接和短链接)
- 5.HTTP1.1和2.0
- 三、HTTPS协议
-
- [1.HTTP 为何不安全(明文传输风险)](#1.HTTP 为何不安全(明文传输风险))
- [2.SSL/TLS 加密原理(对称+非对称)](#2.SSL/TLS 加密原理(对称+非对称))
-
- (1)对称加密:同一把钥匙
- (2)非对称加密:两把不同的钥匙
-
- 中间人攻击
- [CA 证书与公钥基础设施](#CA 证书与公钥基础设施)
- [3.HTTP和HTTPS 的区别](#3.HTTP和HTTPS 的区别)
- [四、WebSocket 全双工通信协议](#四、WebSocket 全双工通信协议)
- [五、FTP / SFTP文件传输](#五、FTP / SFTP文件传输)
-
- [1.FTP(File Transfer Protocol)](#1.FTP(File Transfer Protocol))
- [2.SFTP(SSH File Transfer Protocol)](#2.SFTP(SSH File Transfer Protocol))
- 六、面试问题
前言
| 协议 | 作用 | 传输协议 | 默认端口 | 典型应用场景 |
|---|---|---|---|---|
| DNS | 将域名转换为 IP 地址 | UDP / TCP | 53 | 浏览器输入网址后第一步解析、邮件路由查询 |
| HTTP | 在客户端与服务器之间传输超文本(网页)数据 | TCP | 80 | 网页浏览、RESTful API 调用、资源下载 |
| HTTPS | 在 HTTP 基础上加入 TLS 加密,实现安全的数据传输 | TCP + TLS | 443 | 电商支付、登录注册、任何涉及敏感信息的 Web 场景 |
| FTP | 在客户端与服务器之间实现文件的上传和下载 | TCP(控制 21 / 数据 20) | 21、20 | 网站源码上传、文件共享(现已被 SFTP 大量替代) |
| SFTP | 基于 SSH 加密通道进行安全的文件传输 | TCP(基于 SSH) | 22 | 服务器远程文件管理、安全文件交换 |
| WebSocket | 在客户端与服务器之间建立全双工持久连接,实现实时双向通信 | TCP | 80 / 443 | 在线聊天、股票行情推送、游戏对战、协同编辑 |
一、DNS 域名解析协议
DNS 域名解析将域名和 IP 地址之间对应起来,例如www.sogo.com 为一个域名。域名解析服务器维护一组服务器,负责维护这里的域名和IP的对应关系。
域名是有层级结构的,DNS 的解析过程也是按照层级从右向左逐级查询的。以 www.example.com. 为例(最后那个点通常省略):
- 根域名服务器(Root):管理顶级域名信息,全球仅 13 组。
- 顶级域名服务器(TLD):管理 .com、.org、.cn 等后缀。
- 权威域名服务器(Authoritative):管理具体的 example.com 下的具体 IP 记录。
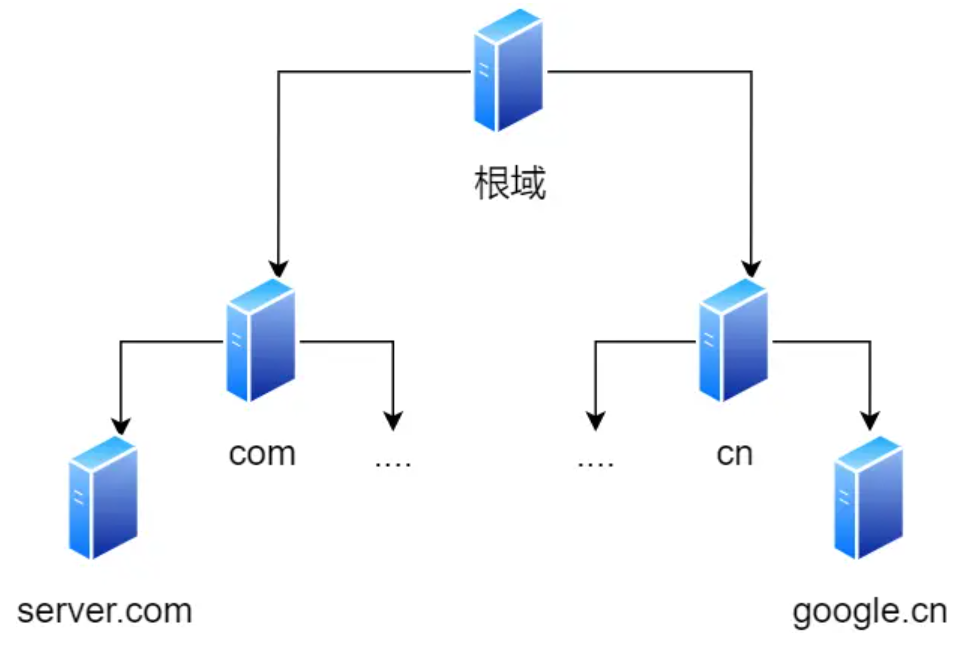
图片来源
bash
www.example.com 完整的格式是 www.example.com.
//越靠右的位置表示其层级越高
根域名服务器(.)
顶级域名服务器(.com)
权威域名服务器(.example.com)当在浏览器输入网址并按下回车时,DNS 解析大致经过以下步骤:
- 浏览器/操作系统缓存:先看本地有没有存过这个域名的 IP 记录(Hosts 文件或 DNS 缓存)。
- 递归查询(本地 DNS 服务器):如果本地没有,客户端会向运营商提供的 Local DNS Server 发起请求,由 Local DNS Server 代为完成后续所有查询。
- 迭代查询(本地域名服务器 Local DNS 的工作):
- Local DNS 向根域名服务器询问:.com的服务器在哪?根域名返回.com 服务器地址。
- Local DNS 向 .com 顶级域名服务器询问:example.com 的服务器在哪?顶级服务器返回 example.com 权威服务器地址。
- Local DNS 向权威服务器询问 :www.example.com 的 IP 是多少?权威服务器返回最终 IP:93.184.216.34。
- 返回结果并缓存:Local DNS 把 IP 告诉客户端,并在自己服务器上缓存一段时间(TTL),下次有人查就不用这么麻烦了。
二、HTTP 超文本传输协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最广泛的协议。它规定了客户端(浏览器)如何向服务器请求 Web 页面,以及服务器如何把数据(HTML、图片、JSON)传回给客户端。
1.HTTP 报文结构
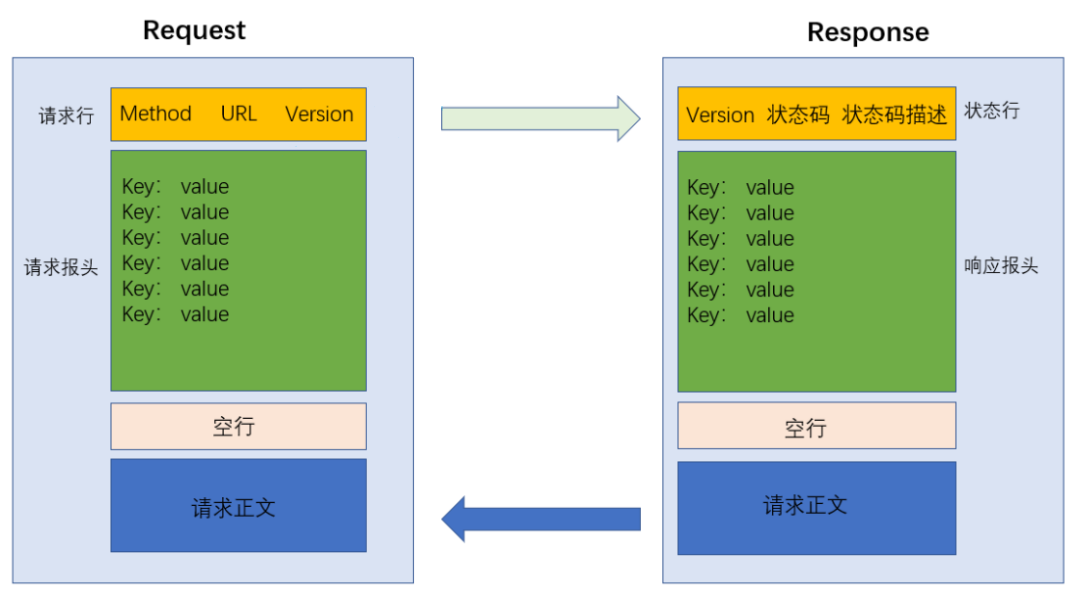
(1)对于请求报文来说,协议分成四个部分
- 请求行(行首),包含三个部分
- HTTP的方法,描述了请求的目的,例如GET就是想从服务器获取某些东西
- URL,描述了想要访问网络上的资源地址,是网络上唯一资源的地址符
- 版本号,描述使用的HTTP版本,例如HTTP/1.1表示当前使用的是HTTP的1.1版本
- 请求头,包含很多行,每一行都是一个键值对,键值对之间用 " : " 来分割,键值对的个数不确定
- 空行,相当于请求头的结束标识
- 请求正文(body)可选,不一定存在
(2)响应报文同样分成四个部分
- 首行,包含三个部分
- 版本号,和请求报文一样
- 状态码,描述了响应是成功还是失败,不同的响应码描述了不用的失败原因。200标识响应成功
- 状态码描述,通过一组简单的单词来描述当前状态码的含义
- 响应头,同样是键值对结构,每个键值对占一行,个数不确定
- 空行,表示响应头的结束标记
- 响应正文(body)服务器返回给客户端的具体数据
2.HTTP请求(Requst)
(1)URL
URL(统一资源定位符)是因特网中的唯一资源的地址,一般来说,每个有效的 URL 都指向一个唯一的资源。

- 协议方案名(Scheme):声明当前 URL 所使用的应用层协议,如 http://、https://、ftp://。浏览器会根据此字段决定采用何种方式发送请求。
- 服务器地址(Host):指示被请求资源所在的主机,可以是 域名(需经过 DNS 解析)或 IP 地址。
- 服务器端口号(Port):指定要访问主机上的具体服务进程。若省略,浏览器会根据协议类型自动补全默认端口(HTTP 默认
80,HTTPS 默认443)。 - 文件路径(Path):定位服务器上的具体资源。该路径可能是服务器磁盘上的真实物理路径,也可能是 Web 框架根据路由规则映射出的虚拟路径*。
- 查询字符串(Query String):路径与查询参数之间用
?分隔。它是客户端传递给服务器的附加参数,格式为key1=value1&key2=value2的键值对结构。 - 片段标识符(Fragment):以 # 开头,用于指示浏览器在加载 HTML 页面后,自动滚动到文档中 id 属性匹配的特定位置。(注意:片段标识符仅在客户端生效,不会被发送至服务器。)
URL 转义(URL Encode)
Query String 的内容完全由开发者自行约定。当参数值中包含 /、?、:、& 等具有特殊含义的保留字符,或者包含中文等非 ASCII 字符时,必须进行 URL 编码(URL Encode),否则服务器可能无法正确解析参数边界。
- 编码规则(URL Encode):将待转义字符对应字节的 ASCII 码十六进制值取出,并在前面加上 % 前缀。例如,空格转义为 %20,中文字符"中"转义为 %E4%B8%AD。
- 解码规则(URL Decode):将 %xx 格式的编码还原为原始字符。
在前后端分离开发中,通过 URL 传递参数(尤其是 GET 请求)时,前端应主动调用 encodeURIComponent()进行编码,后端框架通常会自动解码,但了解底层原理有助于排查乱码问题。
(2)方法(method)
HTTP 定义了多种请求方法,最常用的是:
| 方法 | 语义 | 特点 |
|---|---|---|
| GET | 获取资源 | 参数拼接在 URL 中,有长度限制,不应用于修改数据(幂等)。 |
| POST | 提交数据 | 数据放在 Body 中,无长度限制,常用于表单提交、登录。 |
| PUT | 更新资源(全量替换) | 通常用于 RESTful API 中的更新操作。 |
| DELETE | 删除资源 | 请求删除指定资源。 |
| HEAD | 只获取响应头 | 用于检查资源是否存在或获取文件大小。 |
| OPTIONS | 预检请求 | 用于 CORS 跨域时探测服务器支持的请求方法。 |
GET 和 POST 方法的区别
- 语义不同:
GET ⼀般用于获取数据, POST ⼀般用于提交数据 - 通常情况下,
GET是没有body的,GET通过query string 向服务器传递数据;POST是有body的,POST通过body向服务器传送数据,但是POST没有query string。
(自己构造一个带body的的GET请求,或者构造一个带有query string的POST请求也是完全可以的) GET 是幂等的,意味着多次重复请求对服务器状态的影响与一次请求相同(副作用可控),因此浏览器可以放心缓存 GET 请求的结果。POST 是非幂等的,多次提交可能产生多条重复数据(例如重复下单),因此浏览器通常不会主动缓存 POST 响应。(如果多次请求得到的结果⼀样, 就视为请求是幂等的)GET 可以被缓存, POST 不能被缓存(这⼀点也是承接幂等性,幂等缓存数据,会节省下次访问的开销。如果请求本身不幂等,就不能缓存)- 适用性情况:
登录、支付、上传 等涉及敏感数据或副作用较大的操作,必须使用 POST(且最好配合 HTTPS)(GET请求可能会把数据放到query string中,而POST数据在body,用户不能直接看到,body中的内容对于用户的影响较小)搜索、分页、查看文章等单纯获取数据的操作,优先使用 GET(便于分享链接,且可利用浏览器缓存加速)。
注意:在网络链路层,HTTP 协议下的 GET 和 POST 数据均是明文传输,若未启用 HTTPS 加密,两者都不具备真正的安全性。
(3)请求报头(header)
请求头包含了一系列描述客户端环境、期望响应格式及身份凭证的键值对。以下列举几个开发与排错中高频出现的字段:
- Host :表示服务器主机的地址和端口
- 在 HTTP/1.1协议中,Host 是唯一必填的请求头字段。它解决了单个 IP 地址托管多个虚拟主机时,服务器无法区分请求目标的问题。
- Content-Length :Body 部分数据的字节数
- HTTP协议是基于TCP协议的,但是由于TCP存在粘包问题,因此可以合理设计应用层协议来明确包和包之间的边界。对于不带 Body 的 GET 请求,HTTP 协议依赖空行作为头部结束标志;对于带 Body 的 POST 请求,服务器必须严格依据 Content-Length的值来截取后续的数据流。
- Content-Type :表示请求的 body 中的数据格式,常见的选项有以下几种
- application/x-www-form-urlencoded:表示最普通的 Form 表单格式,Body 内容等同于 URL 中的 Query String 格式
- multipart/form-data:适用于包含文件上传的表单。数据通过特定的 boundary 分隔符分割成多个部分。通常用于提交图片/文件
- application/json:表示数据为json格式
- User-Agent (简称 UA):表示浏览器/操作系统的属性
- 例如:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54。其中Mozilla是开发firefox浏览器的组织,也是前端一些技术标准的实现者;Windows NT 10.0表示为win10;Win64表示64位的系统; AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54表示浏览器信息
- Referer:告诉服务器"用户是从哪个链接点进来的"。常用于防盗链和流量来源统计。
- Cookie :Cookie 就是浏览器给页面提供的一种能够持久化存储数据的机制,持久化指数据不会因为程序重启或主机重启而丢失。Cookie 中存储了⼀个字符串, 这个数据可能是客⼾端(网页)自行通过 JS 写⼊的, 也可能来⾃于服务器(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据)。往往可以通过这个字段实现 "身份标识" 的功能。
- Cookie的组织形式如下:先按照域名进行组织,对每一个域名分配一块空间,在这个空间内,会按照键值对的方式来组织数据。
- 关键信息存储在服务器的 session 中,服务器中存在很多的 session ,每个 session 里面存储了用户的关键信息,同时包含一个sessionId。当一个请求发送到服务端时,服务器会检索该请求里面有没有包含 sessionId 标识,如果包含了 sessionId,则代表服务端已经和客户端创建过 session,然后就通过这个 sessionId 去查找真正的 session,如果没找到,则为客户端创建一个新的 session,并生成一个新的 sessionId 与 session 对应,然后在响应的时候将 sessionId 给客户端,通常是存储在 cookie 中。
(4) 请求 "正文" (body)
请求正文承载了客户端提交给服务器的核心业务数据。Body 可能为空(如 GET、HEAD 请求),非空时其内容格式严格受上述 Content-Type 请求头约束。调试时,可通过浏览器开发者工具的 Network 面板,在 Payload 或 Request 标签页直观查看解析后的 Body 内容。
3.HTTP 响应(Response)
(1)状态码(status code)
一般来说,状态码2开头的表示成功,3开头属于重定向,4开头表示客户端出现错误,5开头表示服务器出现了错误。
- 200 OK:表示访问成功。
- 404 Not Found:要访问的资源不存在。
- 403 Forbidden:表示访问被拒绝,客户端已经通过了认证,但当前账号没有访问该资源的权限(例如普通用户尝试进入管理员后台)。
- 405 Method Not Allowed:方法不被允许,请求行中使用的 HTTP 方法(如PUT)在该 URL 上不被服务器支持。例如,只提供读取的静态文件服务不允许POST。
- 500 Internal Server Error:内部服务器错误,服务器端代码执行抛出异常或逻辑错误,无法具体指明错误原因时的通用报错。排查此类问题需查看服务端错误日志。
- 504 Gateway Timeout:网关超时,代理服务器在等待上游服务器处理请求时超时了。这通常表明上游服务器的处理逻辑耗时过长或死锁。
- 301 Moved Permanently:永久重定向旧地址的资源已被永久移除,搜索引擎会更新索引。浏览器通常会记住此映射,下次直接访问新地址。
- 302 Move temporarily:临时重定向,资源临时被移动到新地址,客户端本次应访问 Location 头指定的 URL,但下次请求仍应使用原地址。常用于未登录用户跳转登录页,或短链接跳转。
(2)响应报头(header)& 响应正文(body)
响应报头的键值对结构与请求报头基本一致。像 Content-Type、Content-Length 的含义与请求中完全相同。
常用的响应报头字段如下:
-
Content-Type:告诉浏览器 Body 里的数据属于哪种格式,常用的有以下格式:
- text/html:body 数据格式是 HTML
- text/css:body 数据格式是 CSS
- application/javascript:body 数据格式是 JavaScript
- application/json:body 数据格式是 JSON
-
Set-Cookie:服务器通过此字段向浏览器要求保存 Cookie 信息,例如 Set-Cookie: sessionid=abc123; HttpOnly; Secure; Path=/
-
Location:配合 3xx 重定向状态码使用,指明客户端接下来应当跳转到哪个 URL 地址。
响应正文格式完全由 Content-Type 头部定义。在浏览器开发者工具(F12)的 Network 面板中,点击具体请求,可以在 Response 或 Preview 标签页看到格式化后的内容(JSON 树状展示、图片预览或 HTML 源码视图),这是排查 BUG 的最直观手段。
4.HTTP 的长链接和短链接
短连接指的是:客户端与服务器每进行一次 HTTP 通信,就建立一个 TCP 连接,任务结束后立刻中断连接,下一次通信再重新握手建立。短连接是管理简单,服务器无需维护连接状态,资源占用可控。但频繁的 TCP 握手带来巨大的时间和资源开销,尤其在 HTTPS 环境下,还需要额外的 TLS 协商,延迟问题更加突出。
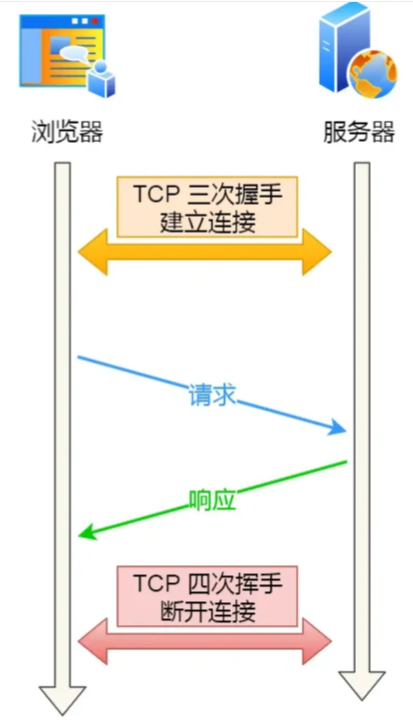
长连接/持久连接 指的是:客户端与服务器建立 TCP 连接后,在一段时间内保持该连接不关闭,后续的多个 HTTP 请求可以复用这同一个连接,连续发送和接收数据。
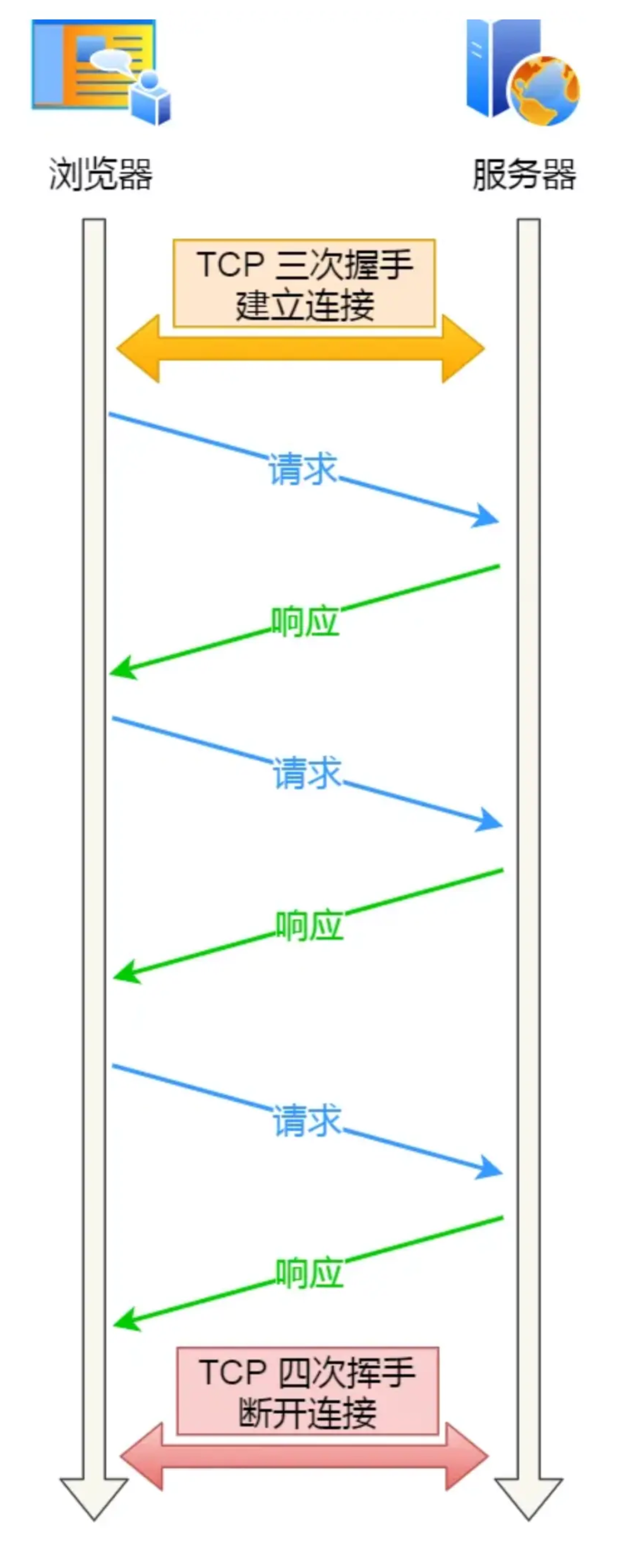
图片来源
长连接的局限:队头阻塞
非管道化长连接:虽然 TCP 连接被复用,但 HTTP 请求依然必须串行排队。下一个请求必须严格等待上一个请求的响应完整返回后才能发出。如果某个响应很慢(比如一个大文件下载),就会堵住后面所有的请求。
管道化长连接:HTTP/1.1 引入了"管道化"概念,允许客户端不等响应就连续发送多个请求。然而,服务器必须按照接收顺序依次返回响应,这意味着即使第 2 个请求处理得很快,也得等第 1 个慢请求的响应发完后才能轮到它输出
由于实现复杂且问题重重,管道化在主流浏览器中已被默认禁用
5.HTTP1.1和2.0
HTTP/2 相对于 HTTP1.1 的核心优化
-
二进制分帧层:HTTP/1.1 是纯文本协议,解析复杂且容易出错。HTTP/2 在应用层和传输层之间加入了一个二进制分帧层,将所有传输内容(Header + Body)拆分成更小的二进制帧(Frame)
HTTP/1.1: 纯文本 → 按换行符分割
HTTP/2: 二进制帧 → HEADERS帧 / DATA帧 -
多路复用:这是 HTTP/2 最核心的改进。它允许在一个 TCP 连接上,同时交错传输多个请求和响应的帧,彻底解决了队头阻塞问题。每个请求/响应都被分配一个唯一的 Stream ID。接收方根据 Stream ID 将乱序到达的帧重新组装成完整的消息。多个流之间独立并发,互不阻塞。
-
头部压缩:HTTP/1.1 里每次请求都要把整套 Header(如 Cookie、User-Agent)原样发送一遍,哪怕连续 100 次请求中这些内容完全相同。HTTP/2 引入 HPACK 算法,如果同时发出多个请求的头是一样的或是相似的,那么,协议会消除重复的部分。
-
服务器推送:在 HTTP/1.x 中,浏览器必须先拿到 HTML、解析它,发现 和
三、HTTPS协议
HTTP 报文以明文形式在网络上传输,内容完全透明。HTTPS的出现,就是为了解决 HTTP 的信任与安全问题。它在 HTTP 和 TCP 之间插入了一层 SSL/TLS加密层,确保数据传输的机密性、完整性与身份可信。
1.HTTP 为何不安全(明文传输风险)
在没有加密的 HTTP 通信中,数据以明文形式穿梭于网络。任何能够截获网络流量的人(如同一个 Wi-Fi 下的黑客、运营商、恶意代理),都可以轻易实施以下攻击:
- 窃听(Eavesdropping):浏览器输入的密码、银行卡号、聊天内容完全暴露。
- 篡改(Tampering):在网页中植入恶意脚本或修改跳转链接(运营商劫持广告)。
- 冒充(Impersonation):伪造一个假的银行网站,浏览器却无法判断其真伪。
2.SSL/TLS 加密原理(对称+非对称)
HTTPS 的核心在于 TLS(传输层安全协议,其前身为 SSL) 握手阶段建立的加密信道。其混合使用了对称加密和非对称加密两套机制。
(1)对称加密:同一把钥匙
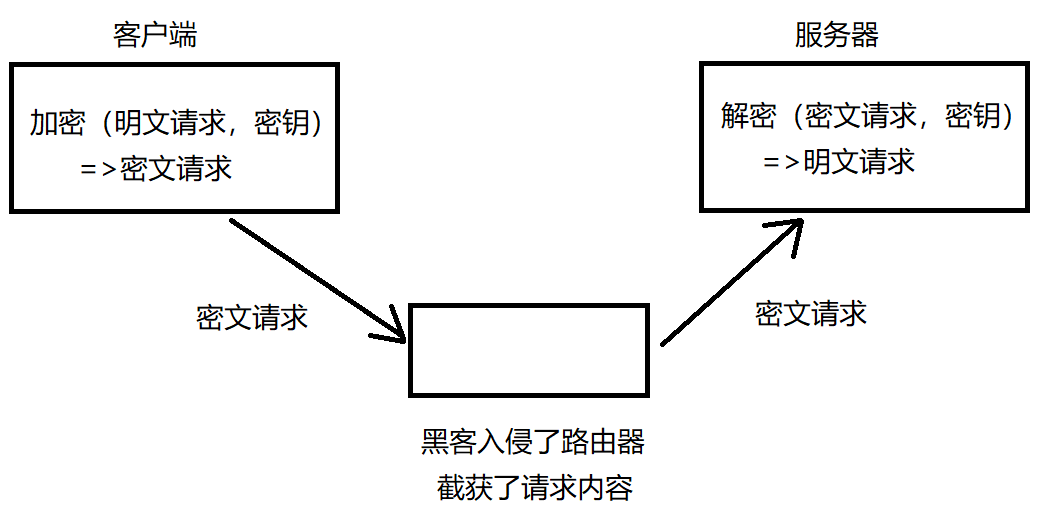
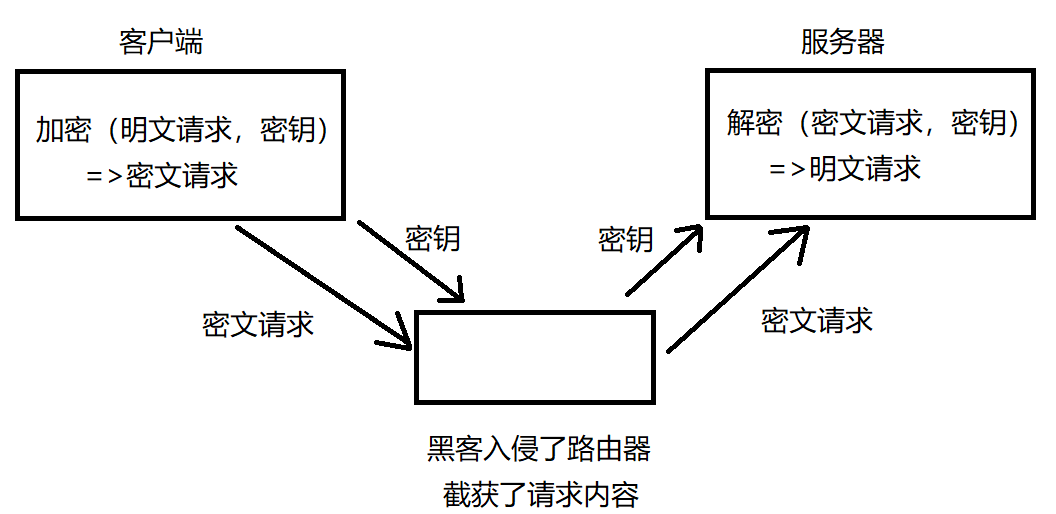
对称加密的情况如下,客户端和服务器持有同一个密钥,客户端传输的数据(HTTP请求的 header 和 body 都通过这个密钥来进行对称加密)网络上传输的是密文,服务器拿到密文后,会根据密钥来进行解密,从而拿到明文。
服务器可能面对成千上万个客户端,如果每个客户端都用不同对称密钥,服务器得记住海量密钥,而且需要让客户端和服务器之间能够传递这个密钥(第一次传输密钥,密钥在网络上进行明文传递,来通知客户端/服务器,可能被黑客入侵)。
(2)非对称加密:两把不同的钥匙
非对称加密有两个密钥,公钥和私钥,可以使用公钥加密私钥解密,也可以使用私钥加密公钥解密。用公钥加密的数据,只有对应的私钥才能解密;反之,用私钥加密的数据,也只有对应的公钥才能解密。
- 公钥(Public Key):可以公开给任何人。
- 私钥(Private Key):必须严格保密,仅自己持有。
具体的流程如下:
- 服务器已经提前生成好了一对密钥(公钥和私钥),公钥随时可以发出去,私钥死死锁在自己手里。
- 客户端请求公钥,服务器返回公钥,公钥以明文的形式在网络中传输。
- 客户端生成临时对称密钥:客户端在自己本地,随机生成一串字符串,这把字符串就是本次通话用的临时对称密钥(通常叫会话密钥,就是例子中的8888)。
- 客户端用公钥加密对称密钥:客户端用服务器的公钥,对生成的临时对称密钥进行加密。加密后得到一段密文。这段密文就是被保护的对称密钥。
- 密文发送给服务器:客户端把加密后的对称密钥密文发给服务器。
- 服务器用私钥解密:服务器收到密文,使用自己持有的私钥,对密文进行解密。解密成功后,服务器得到了那把临时对称密钥。
- 双方都用对称密钥:此后,客户端和服务器都知道了这把临时对称密钥。客户端用它加密 HTTP 请求正文,服务器用它解密。服务器用它加密 HTTP 响应正文,客户端用它解密。
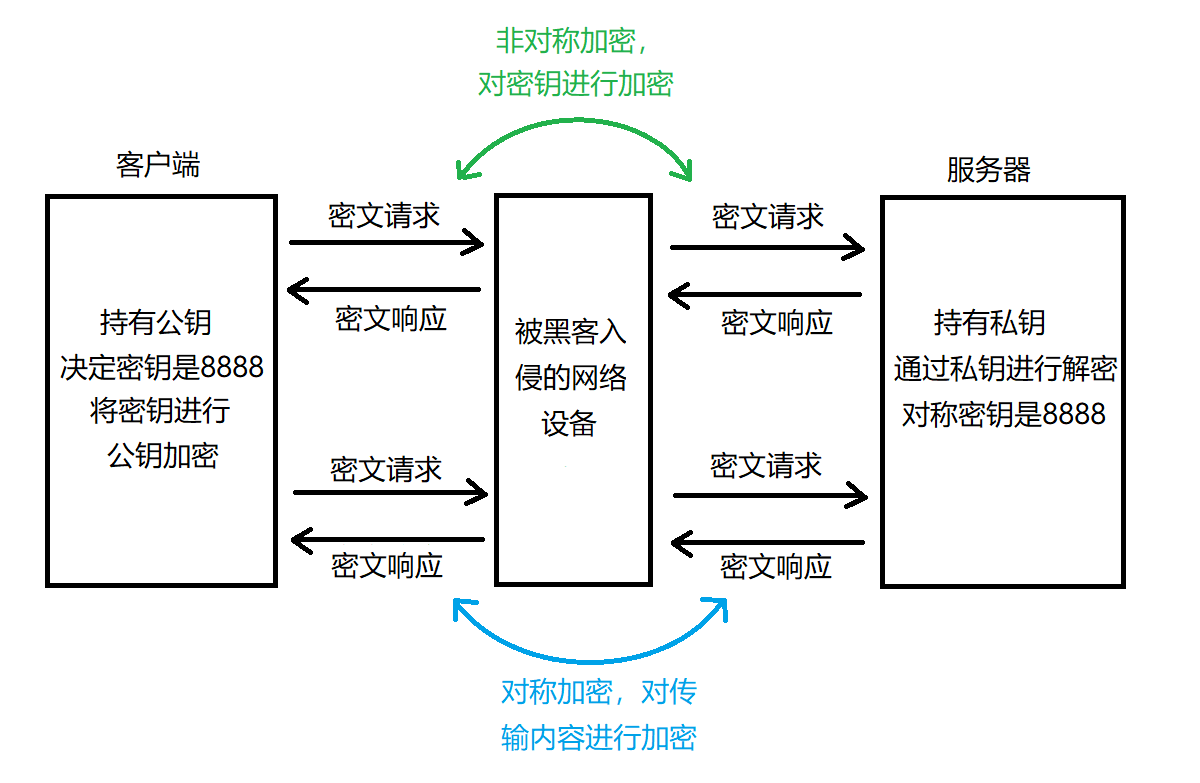
但是对于传输内容来说,最好使用对称加密,因为对称加密的开销远小于非对称加密的开销 ,因此在具体实现中所以 TLS 采用了这种非对称握手 + 对称通信的混合架构,兼顾了安全与性能,,只是少量的使用对称加密,如果对大量数据进行对称加密,成本较大。
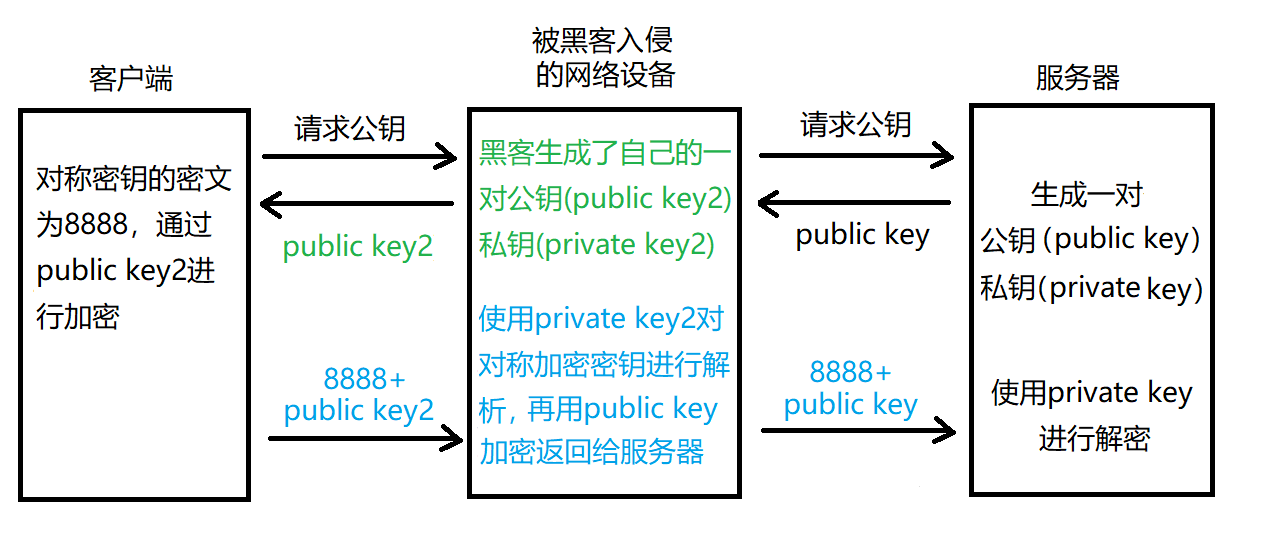
中间人攻击
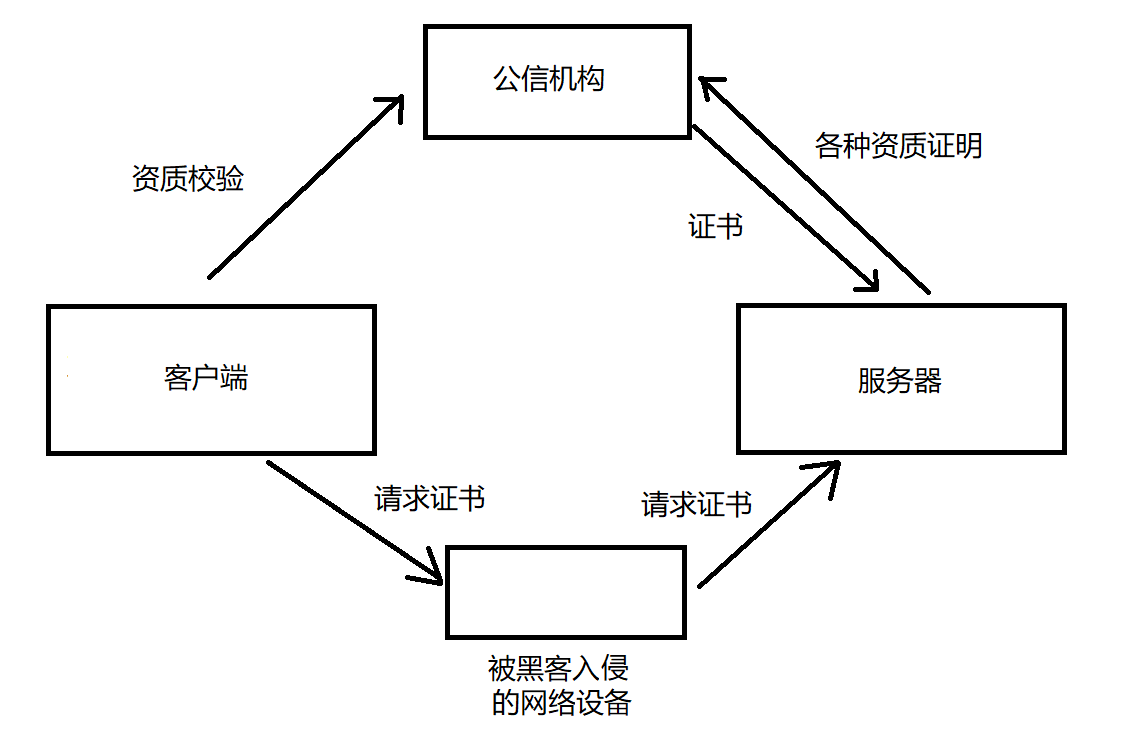
非对称加密也存在一定的问题,如中间人攻击的情况如下图所示,黑客拦截到公钥密文后,生成自己的一组公钥和私钥,将自己的公钥返回给客户端,等客户端发送对加密后的称加密密钥后,进行解密,又为了隐藏黑客身份,将密钥使用服务器端的公钥进行加密,返还给服务器。
CA 证书与公钥基础设施
需要客户端确认当前的公钥是来自于服务器的,而不是由黑客仿造的。需要引入一个第三方公信机构,来证明公钥是一个合法的公钥。
服务器在上线的时候就需要先去公信机构申请证书,服务器自己生成的公钥就放在证书中,客户端会请求一个证书,客户端会校验证书是否合理(证书上自身有的校验机制,或去公信机构进行求证),如果是黑客伪造的证书,就会校验失败。实际中,客户端会自身包含一些公信机构的信息(内置在操作系统中)可以直接本地进行认证。
3.HTTP和HTTPS 的区别
- 安全性:
HTTP是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS则解决HTTP不安全的缺陷,在TCP和HTTP网络层之间加入了SSL/TLS安全协议,使得报文能够加密传输。 - 连接与资源消耗:
HTTP 连接建立相对简单,TCP 三次握手之后便可进行HTTP的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行SSL/TLS的握手过程,才可进入加密报文传输。 - 默认端口:
HTTP默认端口号是8O,HTTPS默认端口号是443。 - 证书:
HTTPS协议需要向CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。 - HTTP/2 兼容性:对浏览器应用:如果想用 HTTP/2 享受多路复用等新特性,就必须部署 HTTPS。这就造成了"HTTP/2 离不开 HTTPS"的普遍认知。
四、WebSocket 全双工通信协议
HTTP 协议是典型的"一问一答"模式:客户端发请求,服务器回响应。服务器无法主动向客户端推送数据。
但在实时应用中(在线聊天、股票行情、游戏对战、协同编辑),服务器有新消息时,必须立刻通知客户端。早期用 HTTP 实现此需求,只能靠"轮询":客户端每隔几秒问一次"有新消息吗?",大量请求都是空转,浪费带宽和服务器资源。
WebSocket 在客户端和服务器之间建立了一条全双工的持久连接。
- 全双工:客户端和服务器可以随时、独立地向对方发送数据,不再需要"你问我答"。服务器有新消息时,直接推给客户端即可。
- 一次握手,持续使用:连接建立后,这条通道一直保持,直到主动关闭。
WebSocket 通信流程流程如下:
- 握手:客户端通过 HTTP 发起一个特殊的"升级请求"(携带 Upgrade: websocket 头)。服务器同意后,协议从 HTTP 切换为 WebSocket。
- 通信 :之后双方可以自由发送消息,消息格式不再是 HTTP 报文的文本,而是更轻量的二进制帧,开销小,延迟低。
- 关闭:任一方都可以主动关闭连接。
五、FTP / SFTP文件传输
1.FTP(File Transfer Protocol)
FTP 是互联网早期专门用来传文件的协议。上传网页源码、下载资料包等场景会用到。与 HTTP 不同,FTP 使用两条 TCP 连接:
- 控制连接(端口 21):一直保持,负责传输操作命令(登录、切换目录、请求下载)。
- 数据连接(端口 20):每传输一个文件,临时建立一条连接,传完即断。
缺点:所有信息(包括用户名、密码、文件内容)都是明文传输,极不安全,现代公网环境基本不推荐使用。
2.SFTP(SSH File Transfer Protocol)
SFTP 和 FTP 名字很像,但底层完全无关。 SFTP 建立在 SSH 加密协议之上,是 SSH 的一个子系统。
- 核心优势:所有数据全程加密传输,包括登录密码和文件内容。
- 连接方式:只需要一条 SSH 连接(默认端口 22),控制命令和文件数据都在这条加密通道里走。
- 使用场景:如今服务器运维、文件远程管理,主流都用 SFTP(或 SCP),各大开发工具(如 VSCode、Xftp)都直接支持。
注:还有一个容易混淆的叫 FTPS,它是 FTP + SSL/TLS 加密,相当于给传统 FTP 加了个安全层,不要和 SFTP 弄混。
六、面试问题
1.HTTP到底是不是无状态的?携带Cookie的HTTP请求是有状态还是无状态的?
无状态是指,从协议层面看,两次相邻的 HTTP 请求之间没有任何关联。服务器处理完一个请求就把它忘了,再接到下一个请求时,协议本身不会告诉服务器"这个请求和上一个请求来自同一个用户"。
Cookie 不是 HTTP 协议原生具备的能力,而是浏览器和服务器共同遵守的一种扩展机制。流程是:
- 服务器在响应头里放一个
Set-Cookie。 - 浏览器把它存下来。
- 下次请求时,浏览器自动在请求头里带上
Cookie。 - 服务器读到 Cookie 里的
SessionId,去自己的存储(内存/数据库)里查出对应用户的状态数据。
所以,准确的说法是:HTTP 协议本身是严格无状态的,但我们通过 Cookie + Session 机制在协议之上构建了"有状态"的应用层体验。
2.Cookie和Session的区别
| 维度 | Cookie | Session |
|---|---|---|
| 存储位置 | 浏览器(客户端) | 服务器端(内存、数据库、Redis) |
| 安全性 | 较低,存储在客户端,可通过 JS 读取(除非设了 HttpOnly),存在被窃取和篡改风险 | 较高,核心数据只在服务器端,客户端只持有 SessionId |
| 存储容量 | 单个 Cookie 约 4KB,每个域名 Cookie 数量有限制 | 理论上取决于服务器资源,没有明确上限 |
| 数据类型 | 只能存字符串 | 可以存任意类型(对象、列表等) |
| 生命周期 | 可设置过期时间,也可设为"浏览器关闭则删除" | 默认有一定过期时间,服务器重启可能丢失(取决于存储方式) |
| 核心关系 | Cookie 常用来承载 SessionId | Session 通过 SessionId 来标识和索引 |
3.客户端禁用了cookie,session还能用吗?
Session 机制需要客户端携带一个标识(SessionId)给服务器。Cookie 被禁用后,主流替代方案是:
- URL 重写:把 SessionId 拼接到每个 URL 后面,如 http://example.com/page?jsessionid=abc123。但实现极其繁琐,每个链接、表单、重定向都要手动拼接,且暴露在浏览器地址栏和日志里,安全风险明显增大。
- 表单隐藏域:在每个表单里加一个 。只能覆盖表单提交的场景,点击普通链接时无法携带。
实际结论:现代 Web 开发中,如果客户端彻底禁用 Cookie,Session 机制基本瘫痪。这也是为什么现在很多网站一旦检测到 Cookie 被禁用就会提示"请开启 Cookie"。
4.HTTP长连接与WebSocket有什么区别?
| 维度 | HTTP 长连接 | WebSocket |
|---|---|---|
| 通信模式 | 半双工,仍然是"一问一答"(请求-响应)。客户端不发请求,服务器无法主动推送 | 全双工,连接建立后双方随时可以独立发送数据 |
| 协议关系 | 仍是 HTTP 协议,只是复用了 TCP 连接来承载多次请求 | 最初通过 HTTP 握手升级,但升级后就运行独立的 WebSocket 协议 |
| 消息格式 | 完整的 HTTP 报文头+正文,每次请求都带大量 Header | 二进制帧,头部仅 2-14 字节,传输高效 |
| 服务端推送 | 不能主动推,必须等客户端请求 | 可以随时推给客户端 |
| 适用场景 | 传统 Web 网页浏览、API 调用 | 实时通信(聊天、股票推送、游戏、协同编辑) |