随着 Qwen3.6、Gemma 4 等新一代开源模型的爆发,本地 LLM 的性能边界不断被刷新。本文基于最新硬件实测,为你整理了一份针对 16GB、32GB、64GB 三种主流内存配置的本地大模型选型速查表。无论你是 MacBook 用户、游戏本玩家还是工作站开发者,都能找到最适合你的"黄金组合"。
💡 前言:为什么需要这份速查表?
在本地运行大模型(Local LLM),显存/内存(RAM) 是决定你能跑什么模型、跑多快、上下文有多长的核心瓶颈。
很多开发者常问:
- "我的 Mac Mini M2 16GB 能跑 Qwen 吗?"
- "32GB 内存是不是只能跑小模型?"
- "64GB 内存到底能解锁哪些旗舰体验?"
为了回答这些问题,我整理了这份涵盖 日常聊天、代码编程、逻辑推理、视觉多模态 的全场景模型推荐清单。所有推荐均基于 GGUF 量化格式,确保在 CPU/GPU 混合推理下的最佳兼容性。
📊 一、16GB RAM:轻薄本与 Mac Mini 的极限优化
适用场景 :日常辅助、轻量级代码补全、文档摘要、快速问答。
核心策略 :"小而美"。优先选择参数量在 2B-9B 之间的高效率模型,保留至少 4-6GB 内存给操作系统和上下文窗口(KV Cache)。

✅ 推荐模型清单
| 分类 | 模型名称 | 量化建议 | 特点与用途 |
|---|---|---|---|
| 🏆 日常主力 | Qwen3.5 9B | Q4_K_M | 全能王者。聊天、起草、翻译、研究。如果只装一个,选它。 |
| 🧠 推理引擎 | DeepSeek-R1 Distill Qwen 7B | Q4_K_M | 慢但深。擅长数学、逻辑、逐步推导。适合需要"深思熟虑"的场景。 |
| 💻 代码专家 | Qwen2.5 Coder 7B | Q4_K_M | 编程专用。补全、重构、Debug。比通用模型更懂代码结构。 |
| 📚 长上下文 | Llama 3.1 8B | Q4_K_M | RAG利器。虽然输出不是顶级,但在有限内存下拥有极强的长文本处理能力。 |
| ⚡ 效率助手 | Phi-4 Mini / Gemma 4 E4B | Q4/Q5_K_M | 口袋助手。极速响应,适合摘要、提取信息、作为主模型的副手。 |
| 🔍 微型路由 | Qwen3.5 0.8B | Q5_K_M | 分类器。用于关键词路由、二元决策、任务分发,几乎不占资源。 |
💡 16GB 最佳实践组合
- 单模型方案 :
Qwen3.5 9B (Q4_K_M)------ 平衡了智能与速度。 - 双模型方案 :
Qwen3.5 9B(主聊) +Qwen2.5 Coder 7B(写代码) 或Phi-3.5 Mini(快速摘要)。
🚀 二、32GB RAM:进阶玩家与旗舰入门
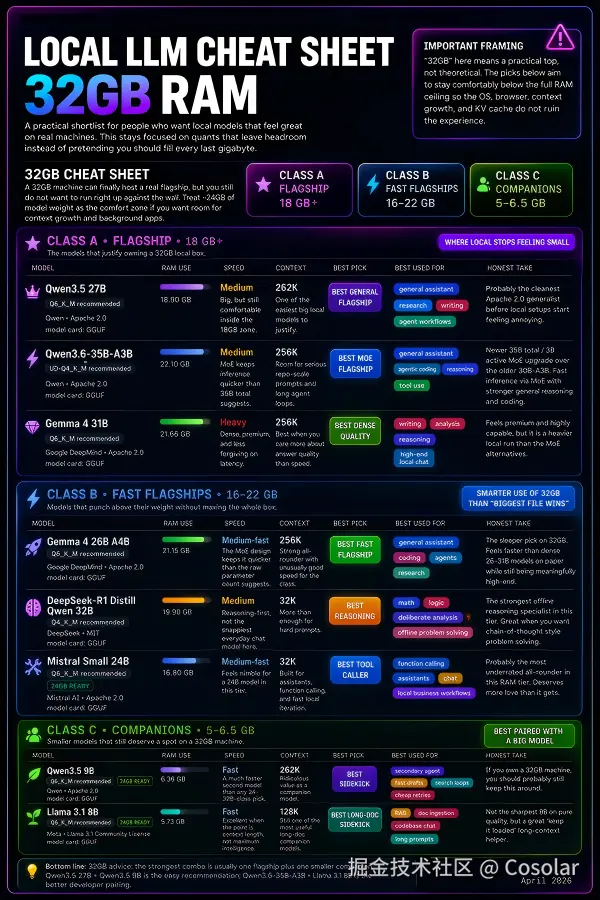
适用场景 :复杂代理工作流、中长篇写作、本地 RAG 系统、中等规模代码库分析。
核心策略 :"旗舰下沉"。可以舒适运行 27B-35B 级别的稠密或 MoE 模型,获得接近云端 API 的体验。
✅ 推荐模型清单
| 分类 | 模型名称 | 量化建议 | 特点与用途 |
|---|---|---|---|
| 👑 整体旗舰 | Qwen3.5 27B | Q6_K_M | 32GB 首选。通用聊天、写作、研究。几乎能处理一切且表现优秀。 |
| ⚡ 快速旗舰 | Qwen3.6-35B-A3B (MoE) | UD-Q4_K_M | 速度与智能兼得。在编码、工具使用上超越许多小模型,响应更快。 |
| 📝 高质量密集 | Gemma 4 31B | Q6_K_M | 写作与分析。当质量优于速度时选择它,高阶本地聊天体验极佳。 |
| 🛠️ 工具调用 | Mistral Small 24B | Q6_K_M | Agent 专用。擅长函数调用和本地业务任务,24GB 内存也可尝试。 |
| 🧮 离线推理 | DeepSeek-R1 Distill 32B | Q4_K_M | 逻辑怪兽。专为数学、复杂逻辑分析设计,适合硬核推理任务。 |
| 🤝 最佳副手 | Qwen3.5 9B / Llama 3.1 8B | Q6_K_M | 辅助任务。即使有旗舰模型,仍需要小模型处理快速草稿、RAG 检索等低成本任务。 |
💡 32GB 最佳实践组合
- 社区首选单模型 :
Qwen3.5 27B或Gemma 4 31B。 - 最强通用双模 :
Qwen3.5 27B(主脑) +Qwen3.5 9B(副手/快速响应)。 - 代码密集型 :
Qwen3.6-35B-A3B(编程/推理) +Llama 3.1 8B(长上下文/RAG)。
🔥 三、64GB RAM:本地 AI 工作站与专业生产力
适用场景 :全量代码库分析、超长文档处理、多模态视觉理解、复杂 Agent 规划、私有化部署。
核心策略 :"全能释放"。你可以运行未过度量化的大型稠密模型,甚至触及 70B 级别,同时保留巨大的上下文窗口。
✅ 推荐模型清单
| 分类 | 模型名称 | 量化建议 | 特点与用途 |
|---|---|---|---|
| 🏆 终极旗舰 | Qwen3.6-27B | Q8_0 | 64GB 最佳。近乎无损的量化,通用能力极强,聊天/编码/推理全覆盖。 |
| ⚡ 极速旗舰 | Qwen3.6-35B-A3B | Q6_K | 代理首选。在保持高质量的同时,提供更快的迭代速度,适合 Tool Use。 |
| 🐘 巨无霸 | Llama 3.3 70B | Q4_K_M | 知识百科。虽然性价比略低,但 70B 的世界知识和稳定性无可替代。 |
| 🧮 推理专家 | Nemotron Super 49B v1.5 | Q6_K | 结构化推理。比通用模型更擅长数学、分析和代理规划。 |
| 📚 长文专家 | Kimi-Linear-48B-A3B | Q5_K_M | 海量上下文。全代码库问答、长篇研究报告的首选。 |
| 👁️ 视觉多模态 | Qwen3-VL-32B | Q6_K | 看图说话。图像理解、OCR、UI 分析。64GB 下运行多模态模型的甜蜜点。 |
| 💻 代码专精 | Qwen3-Coder 30B-A3B | Q6_K | 编程代理。仓库级编辑、PR 生成,构建 Code Agent 的最佳选择。 |
💡 64GB 最佳实践建议
- 追求极致质量 :运行
Qwen3.6-27B (Q8_0),体验接近浮点精度的本地推理。 - 追求长上下文 :
Kimi-Linear-48B是你的不二之选,轻松吞下百万字文档。 - 多模态需求 :
Qwen3-VL-32B能在本地流畅处理图像和视频帧分析,无需上传云端。
🛠️ 技术小贴士:如何选择合适的量化版本?
在 GGUF 格式中,量化等级决定了文件大小 、内存占用 和智能损失程度:
- Q8_0 (8-bit) :
- 精度:极高,几乎无损。
- 适用:64GB+ 内存,追求极致效果的旗舰模型(如 27B)。
- Q6_K / Q5_K_M (5-6 bit) :
- 精度:高,智能损失极小,肉眼难以察觉。
- 适用:32GB-64GB 内存,平衡速度与质量的黄金选择。
- Q4_K_M (4-bit) :
- 精度:良好,目前的主流标准。
- 适用:16GB-32GB 内存,绝大多数用户的默认选择。
- Q2/Q3 (2-3 bit) :
- 精度:较低,可能出现逻辑混乱。
- 适用:仅用于极低内存设备或超大模型(如 70B+ 在受限环境下)。
公式参考 :
所需内存 ≈ 模型参数量(B) × 量化位数(bit) / 8 + 上下文缓存(KV Cache)例如:7B 模型 Q4 量化 ≈ 7 × 4 / 8 = 3.5GB + 2~4GB KV Cache ≈ 6-8GB 总占用
📝 总结与建议
| 内存配置 | 核心定位 | 推荐主力模型 | 关键优势 |
|---|---|---|---|
| 16 GB | 轻量便携 | Qwen3.5 9B | 速度快,发热低,适合日常辅助 |
| 32 GB | 进阶全能 | Qwen3.5 27B | 旗舰体验,兼顾推理与创作 |
| 64 GB | 专业工作站 | Qwen3.6-27B (Q8) | 无损精度,支持多模态与超长上下文 |
💬 互动话题 : 你现在的设备是多少内存?正在运行哪个模型?欢迎在评论区分享你的配置和体验!如果有 128GB 或更高配置的需求,也请留言,下期我们继续深挖!👇
喜欢这篇文章?欢迎 点赞、收藏、转发 支持!关注我不迷路,获取更多 AI 前沿技术与实战干货。 🚀