一点引入
前几天突然有同事聊到日志的事情,正好好几天没有写东西了,正好就来聊聊日志模块的设计。这块我觉得,不论项目大小,都应该要设计好,不能一蹴而就,如同飞机上的黑匣子,虽然不显山不露水,但严谨,可靠,高效的日志设计,可以让我们的系统再出现问题时,得以快速定位,避免严重问题或事故的发生。
一点实践
我这里是使用了ELK来做日志的存储,传输和分析,然后用Redis做的临时中转服务,具体流程如下
搭建ELK服务
实际上,这是个已经被历史证明,甚至可能是最适合做日志存储的架构方案,我们首先需要根据官方文档逐步安装和配置ElasticSearch,Logstash,以及Kibana服务,这些我在之前的博客中都有提到过,这里算是个回顾,再来简单的聊聊。或者,大家嫌麻烦,可以先找个官方的docker镜像先在本地试试,如果有条件的,也可以让你的龙虾助手,帮你在你的私人服务器上先部署一下。
注意,受篇幅限制,本篇不涉及安全相关的配置,上生产的话,安全配置还是不可或缺的。大家可以自行查看官方文档,笔者之前也写过类似的博客:mp.weixin.qq.com/s/5v4Q4fyRw...
搭建ElasticSearch集群
这里先给出官方的配置指导页:www.elastic.co/guide/en/el...我这个是 7.14,如果你用别的版本,就把链接里的版本号改一下就好,目前最新的版本是8.19。
官方指导里,分别给出了源于 elasticsearch.yml,jvm.options,log4j2.propertites 三给关键配置文件的配置说明。我这里只用到了第一个,官方指导了也提到了,对于后两项,分别是调整 Java 虚拟机和日志的选项,一般情况下不需要修改,按默认配置即可。如果是二般情况,就再根据说明按需调整。
yaml
# 节点1,其他节点类似
# ---------------------------------- Cluster -----------------------------------
# 集群名字,每个集群内的节点应该保持一致
cluster.name: magicloud-cluster
# ------------------------------------ Node ------------------------------------
# 节点名称
node.name: es-node1
# 是否可以被选举为主节点
node.master: true
# 是否为数据节点(存储空间足够的情况下,我个人建议把每个节点都设定成可存储数据的节点,这样会最大限度保证数据分片不会丢失)
node.data: true
# ----------------------------------- Paths ------------------------------------
# 数据和日志存放地址,根据官方建议,在生产环境下,这里把数据放到了$ES_HOME之外的位置。
# https://www.elastic.co/guide/en/elasticsearch/reference/7.14/important-settings.html
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
# ---------------------------------- Network -----------------------------------
# 网络配置,默认是127.0.0.1的回环地址,修改成要暴露的ip或者直接0.0.0.0
network.host: 0.0.0.0
# 端口,默认9200,个人不建议修改,不为别的,主要是其他开发或者运维人员一看到9200就知道es在跑着,辨识度较高
http.port: 9200
# --------------------------------- Discovery ----------------------------------
# 集群发现,发现集群内的其他节点,把集群内的节点地址写在这里,官方说也可以写节点名字,但我试了名字不好使,没细研究~~
discovery.seed_hosts: ["ip1:9300", "ip2:9300", "ip3:9301"]
# 初始的主节点,也可以不设置
cluster.initial_master_nodes: ["es-node1"]
# ---------------------------------- Various -----------------------------------
# 为了防止误删除,禁止使用通配符或_all删除索引
action.destructive_requires_name: true
# 节点的通信地址,也就是discovery里配置的节点ip和port,建议host就是本机ip,port就是9300,也是辨识度较高
transport.host: 本机ip
transport.tcp.port: 9300配置文件的关键配置就是这些,关于 es 的配置,还有几个关键的点
- 修改 /etc/security/limits.conf,在配置文件最下面添加
yaml
* soft nofile 65535
* hard nofile 65535否则启动 es 的时候会报错,其实按报错的提示修改即可。
错误大概是这样 max number of threads 2048 for user elasticsearch is too low, increase to at least 4096
- 在 es 7.x 的版本,不可以通过 root 用户启动 es,这个可以强制修改,但还是按官方的建议来比较好,操作也比较简单
yaml
groupadd elsearch #1.添加新的管理组
useradd -m -g elsearch elsearch- #2.添加新管理组下的用户
passwd elsearch #3.回车后输入密码
chown -R elsearch:elsearch /opt/es/elasticsearch7.14.1/ #4.给elsearch用户授予es根目录的管理权限
chown -R elsearch:elsearch /usr/local/elasticsearch/data/ #5.给elsearch用户授予es的存储数据目录的管理权限
chown -R elsearch:elsearch /usr/local/elasticsearch/logs/ #6.给elsearch用户授予es的存储日志目录的管理权限授权完成后,就可以以 elsearch 用户分别启动 es 集群了
yaml
su elsearch #1.切换到elsearch用户
bin/elsticsearch -d #2.后台启动es分别启动各个es节点后,可以在当前终端查看相应进程,也可以通过es的心跳接口查看, 或者通过 kibana或其他es管理客户端来查看运行情况,
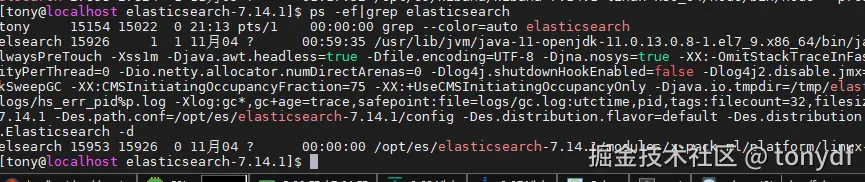
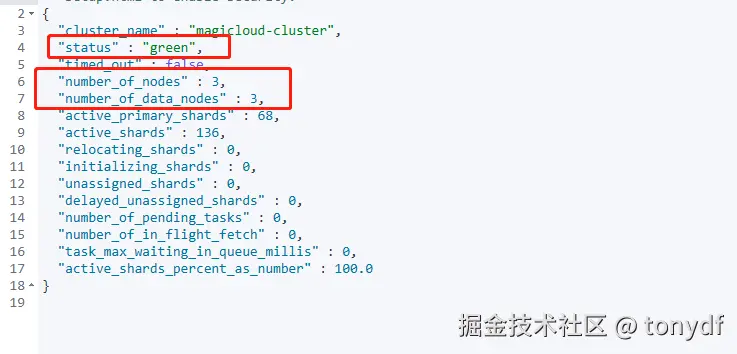
至此,es 的配置就基本完成了.
安装Kibana
配置好 es 集群和,Kibana 的配置就十分简单了,官方配置地址:www.elastic.co/guide/en/ki...
yaml
server.port: 5601 #端口号,建议保持5601的默认配置,依旧是为了高辨识度
server.host: "具体ip" #要暴露的ip地址
server.publicBaseUrl: "http://ip:5601" #默认访问地址,如果挂了域名指向,这里可以写域名地址
elasticsearch.hosts: ["http://ip:9200"] #es集群地址,我这暂时就写了一个
i18n.locale: "zh-CN" #kibana的默认语言配置,默认是英文,我这里改成了中文,英文好的同学可以忽略7.x 以后版本的 es 同样是不建议使用 root 用户启动,所以还是按照给 es 目录授权的步骤,给 Kibana 目录也进行一下普通用户的授权
bash
su root #1.如果当前不是root用户,就先切回到root用户,区分标志就是看命令输入行是$符号还是#符号,#就是root
chown -R elsearch:elsearch /opt/es/kibana/ #2.给elsearch用户授权管理kibana目录
su elsearch #3.切换用户
nohup /opt/es/kibana/bin/kibana & #4.后台启动kibana启动后,就可以在本地浏览器打开 kibana 管理界面了
配置Logstach
logstash 主要是做数据传输管道的,这个没有用户限制,配置也是按需进行,比如我们的业务是用 logstash 来传输日志到 es 进行集中管理。所以我的配置文件就长这样
yaml
input {
redis {
codec => plain
host => "redis地址"
port => 6379
db => 2
key => "eslog"
data_type => list
password => "xxx"
}
redis {
codec => plain
host => "redis地址"
port => 6379
db => 2
key => "eslog"
data_type => list
password => "xxx"
}
...其他redis配置
}
filter {
# grok是logstash自带的数据解析插件,我这里用的是正则匹配,注意这里配置好的格式,要和代码里传输日志内容的格式一致
# 这里还能配置一些脱敏配置,比如日志中包含了身份证等敏感信息,又不像改代码的话,可以在这里配置
grok {
match=>{"message"=>"%{DATA:system} %{DATA:level} %{DATA:time} %{DATA:user} %{DATA:method} %{DATA:path} \"%{DATA:param}\" %{DATA:ip} %{DATA:webbrower} \"%{DATA:remark}\"" }
remove_field => ["message"]
}
geoip {
source => "ip" #启用自带的geoip插件,定位ip地址,按需启用,不用就去掉
}
}
output {
elasticsearch {
hosts => ["http://ip:9200"]
index => "cloudlog-%{+YYYY.MM.dd}"
# 注意这里还要有一些安全配置,为了快速跑通,我这里先跳过了,可以参考我上面提到的那个地址进行配置
}
}配置好后,启动 logstash 即可。
至此,elk 的基本配置就完成了
*安装Redis
Redis的安装这里不在介绍,之所以提一嘴,是Redis在我这边的项目里是做中转服务,日志的架构图应该是这样
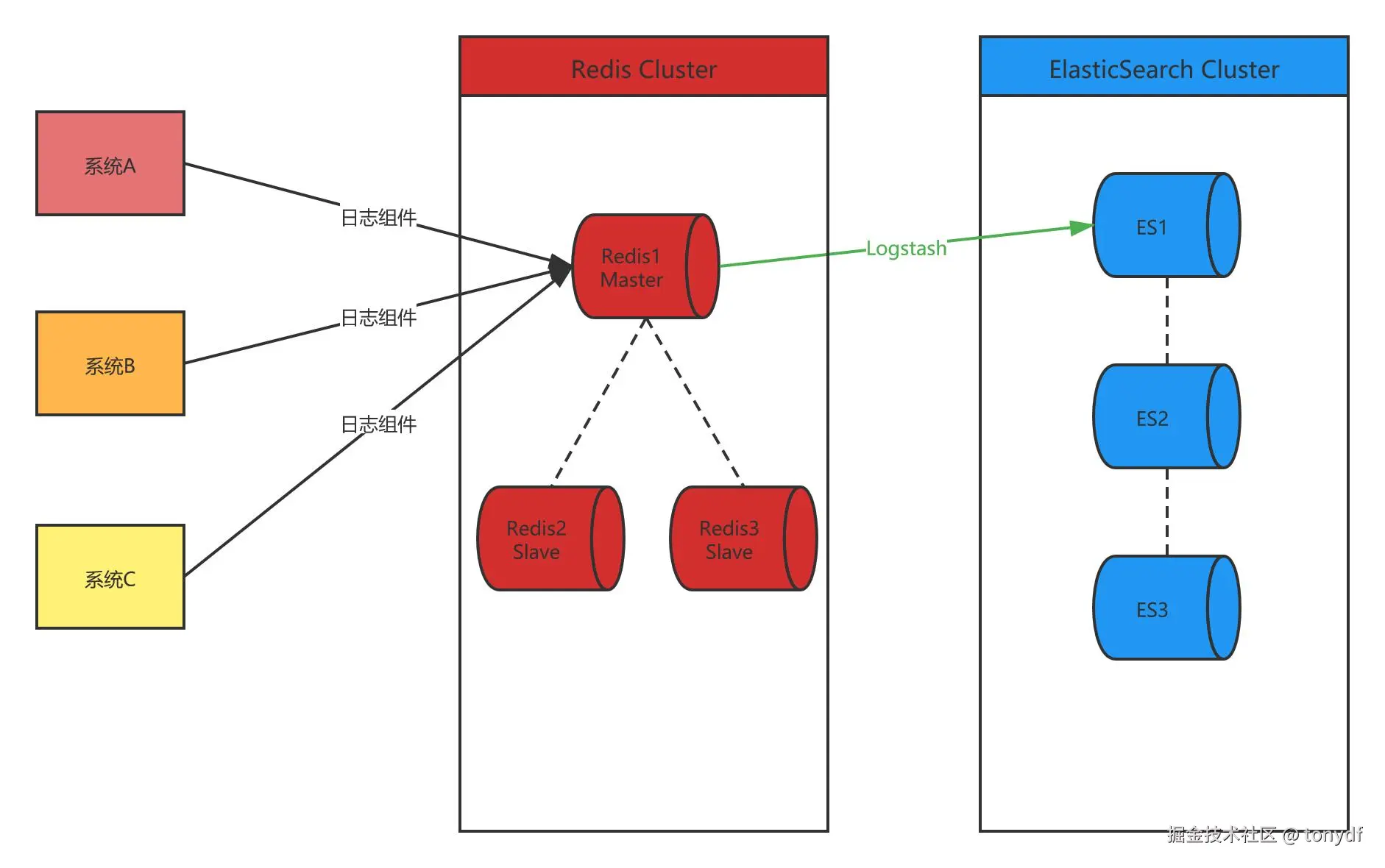
记录日志
前面都是在部署日志传输和存储框架,完成之后,就可以安装我们设计的流程把日志按照一定的规则写到Redis的队列里就好了。也是受篇幅限制,这里简单的介绍一下我这边的方案,我这里使用的日志组件是Serilog。
- 定义日志中间件,把需要写到日志的,统一的信息记录下来,方便日志服务读取,比如ip,请求路径,请求参数,客户端等等,注意敏感数据应在进入管道前(代码层)尽可能脱敏,根据业务场景具体处理即可。
csharp
public class LogContextMiddleware
{
private readonly RequestDelegate _next;
public LogContextMiddleware(RequestDelegate next)
{
_next = next;
}
public async Task InvokeAsync(HttpContext context)
{
// 1. 从Header或Token中解析用户信息
string userToken = "Anonymous";
var tokenItem = context.Request.Headers?.Where(h => h.Key == "Authorization").FirstOrDefault();
if (tokenItem.HasValue)
{
// 为了隐私安全,这里不记录用户明文信息,只记录一个token,后续定位问题的话,可以通过token间接定位到具体用户
userToken = tokenItem.Value.Value.ToString().Replace("Bearer ", "");
}
string ip = GetIp(context);
string path = context.Request.Path;
string method = context.Request.Method;
string param = GetRequestParameters(context);
string userAgent = context.Request.Headers["User-Agent"].FirstOrDefault() ?? "Unknown";
// 2. 使用 Serilog.Context.LogContext 推送属性
// PushProperty 会返回一个 IDisposable 对象,使用 using 确保请求结束后自动清除
using (Serilog.Context.LogContext.PushProperty("UserToken", userToken))
using (Serilog.Context.LogContext.PushProperty("IP", ip))
using (Serilog.Context.LogContext.PushProperty("Path", path))
using (Serilog.Context.LogContext.PushProperty("Method", method))
using (Serilog.Context.LogContext.PushProperty("Params", param))
using (Serilog.Context.LogContext.PushProperty("UserAgent", userAgent))
{
await _next(context);
}
}
}
// 在入口文件中使用该中间件,注意注册位置,根据你的业务情况
app.UseMiddleware<LogContextMiddleware>();- 定义统一的日志服务,注意我是使用redis做的中间层,临时存储日志消息,这里因为我的业务场景里这是足够支撑的,实际大家设计日志时候,并不一定要这么设计,也可以 使用诸如Channels(System.Threading.Channels) 做内存缓冲,实现更优雅的"生产者-消费者"模型
csharp
// 日志服务接口,打印各类日志
public interface ILoggingService
{
void LogInformation(string message, params object[] args);
// Blazor项目专用
void LogInfoArgs(string message, object? args = null);
void LogWarning(string message, params object[] args);
void LogError(string message, params object[] args);
void LogDebug(string message, params object[] args);
}
// 打印日志的条件,开发环境和生产环境略有不同
public class ConditionalLogSink : ILogEventSink
{
private readonly ILogEventSink _sink;
public ConditionalLogSink(bool isDevelopment, string rootPath, string systemLabel = "MagicDeclaration")
{
if (isDevelopment)
{
// 开发环境有一些特殊的配置,受篇幅限制,本篇不介绍LevelBasedFileSink方法类
_sink = new LevelBasedFileSink(rootPath, isDevelopment: true, systemLabel);
}
else
{
_sink = new RedisLogSink(systemLabel);
}
}
public void Emit(LogEvent logEvent)
{
_sink.Emit(logEvent);
}
}
public class LoggingService : ILoggingService
{
private readonly ILogger _logger;
public LoggingService(ILogger<LoggingService> logger)
{
_logger = logger;
}
public void LogInformation(string message, params object[] args)
{
_logger.LogInformation(message + "\r\n", args);
}
/// <summary>
/// 记录信息日志,可以附加业务参数数据对象,仅blazor端调用时有效
/// blazor端调用时,参数对象会被序列化为 JSON 字符串存入日志中,方便后续分析和查询
/// var postModel = new { Id = 1, Name = "张三", Remark = "测试修改" };
/// _loggingService.LogInfoArgs("修改用户信息", postModel);
/// </summary>
/// <param name="message"></param>
/// <param name="args"></param>
public void LogInfoArgs(string message, object? args = null)
{
if (args != null)
// 使用 {@args} 会让 Serilog 将对象解构为 key-value 存入 Properties
_logger.LogInformation(message + " 内容: {@BusinessData}", args);
else
_logger.LogInformation(message);
}
public void LogWarning(string message, params object[] args)
{
_logger.LogWarning(message+"\r\n", args);
}
public void LogError(string message, params object[] args)
{
_logger.LogError(message + "\r\n", args);
}
public void LogDebug(string message, params object[] args)
{
_logger.LogDebug(message + "\r\n", args);
}
}
public class RedisLogSink : ILogEventSink, IDisposable
{
private readonly string _systemLabel;
private readonly IRedisServiceProvider _redisService;
public RedisLogSink(string systemLabel,IRedisServciceProvider redisService)
{
_systemLabel = systemLabel;
_redisService = redisService;
}
public void Emit(LogEvent logEvent)
{
if (logEvent == null) return;
// 注意,这里ConsoleHelper是我封装的一个只在开发环境下生效的输出方法,生产环境不会生效,提高效率
ConsoleHelper.WriteLine(logEvent.RenderMessage());
if(logEvent.Level == LogEventLevel.Verbose || logEvent.Level == LogEventLevel.Debug)
{
// 生产环境不记录这两类日志
return;
}
// 这里GetPropValue就是读取我们前面在中间件里注入的参数
var userToken = GetPropValue(logEvent, "UserToken");
var ip = GetPropValue(logEvent, "IP");
var path = GetPropValue(logEvent, "Path");
var method = GetPropValue(logEvent, "Method");
var param = GetPropValue(logEvent, "Param");
var UserAgent = GetPropValue(logEvent, "UserAgent");
//var remark = logEvent.RenderMessage();
// 渲染消息主体(原本的日志信息)
var message = logEvent.RenderMessage();
var msg = $"{_systemLabel} {logEvent.Level} {DateTime.Now.ToString("HH:mm:ss")} {userToken} {method} {path} \"{param}\" {ip} {UserAgent} \"{message}\"";
await _redisService.LPushAsync("Redislogkey", msg);
}
public void Dispose()
{
// 可以在这里释放连接等资源
// 目前没有使用连接池或其他资源,所以这里不需要做任何事情
}
}- 注册日志服务
csharp
Log.Logger = new LoggerConfiguration()
.MinimumLevel.Debug()
.Enrich.FromLogContext()
.Enrich.WithEnvironmentName()
.WriteTo.Conditional(
c => isDev,
wt => wt.Console(
outputTemplate: "[{Timestamp:HH:mm:ss} {Level:u3}] {Message:lj}{NewLine}{Exception}",
theme: Serilog.Sinks.SystemConsole.Themes.AnsiConsoleTheme.Literate,
restrictedToMinimumLevel: Serilog.Events.LogEventLevel.Information)
).
// 这里ConditionalLogSink,就是前面我们定义的根据不同条件记录日志的方法
WriteTo.Sink(new ConditionalLogSink(isDev, Environment.CurrentDirectory))
.CreateLogger();
// 使用Serilog作为默认的日志提供者
builder.Logging.ClearProviders();
builder.Logging.AddSerilog();
// 注册日志服务
builder.Services.AddSingleton<ILoggingService, LoggingService>();
看一下在kibana里的效果
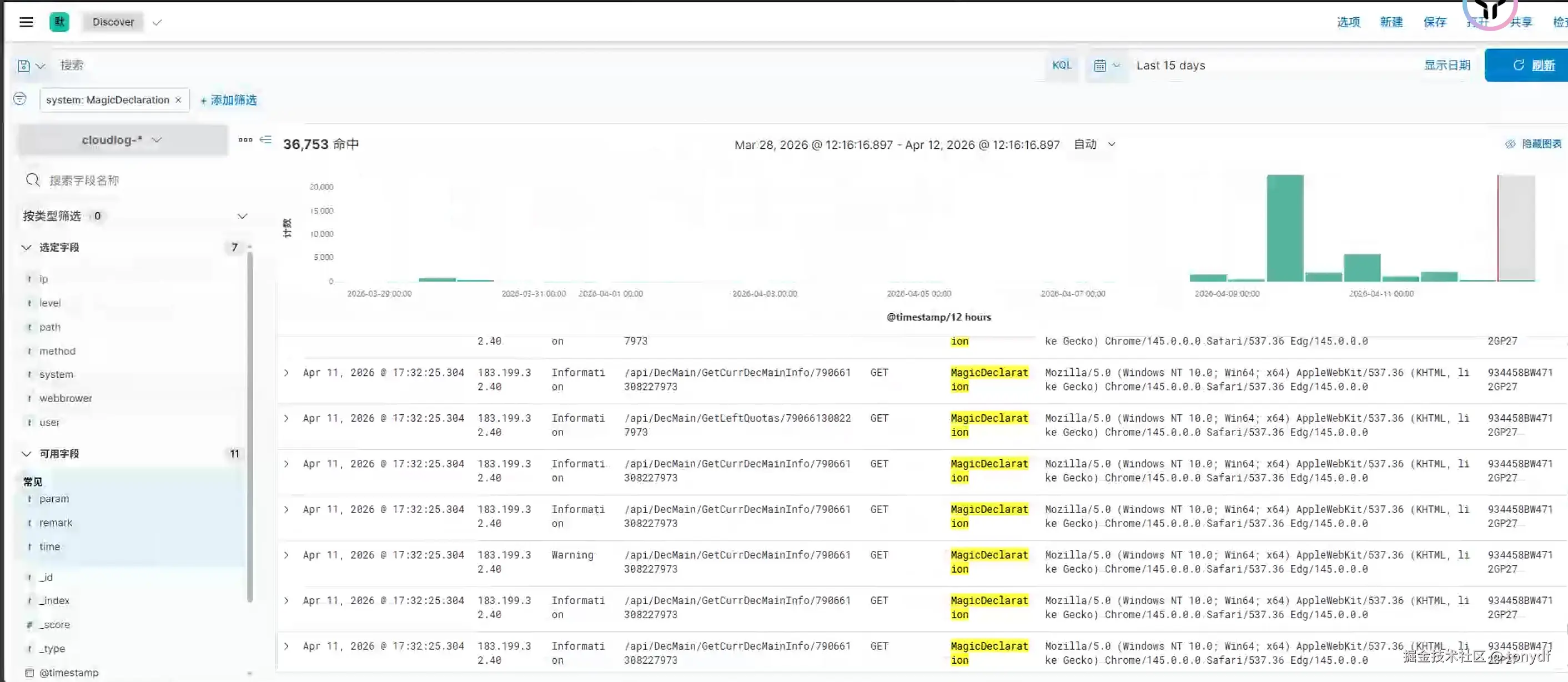
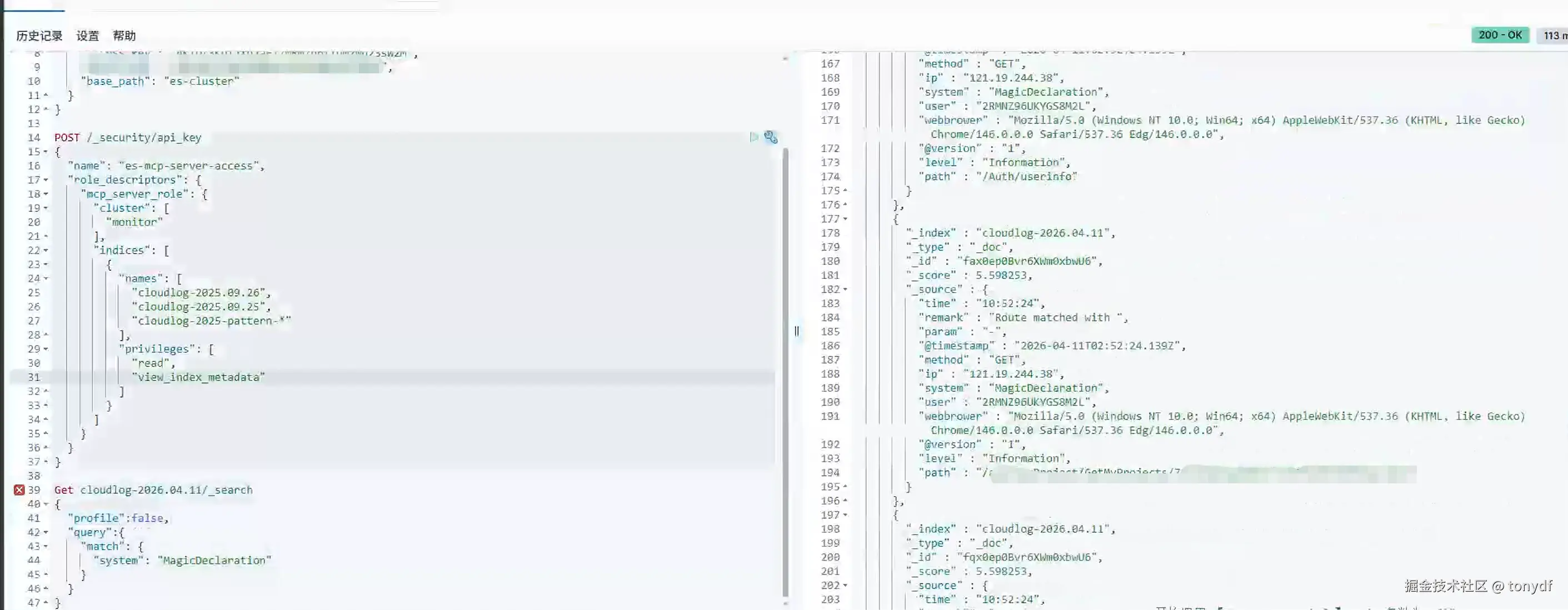
后续操作
还有一些日志的善后工作,比如短期内的日志,可以保存在ES里,比较长期的日志,可以归档到一些对象存储设备等等,这个就看具体的业务要求了,不再赘述。说起来关于对象存储的内容,我之前也聊过MinIO和RustFS相关的话题,可以参考。
一点总结
我这边的日志模块设计,分别用到了ELK,Redis,对象存储等等,会不会过度设计了?直接存关系数据库不香吗?
我认为,日志模块的设计,每个人有不同的想法,首先我不太认同将日志记录到关系数据库,或者说,关系数据库不应该承担记录操作日志主要作用。一些核心的,关键操作的审计类日志,可以记录到关系数据库,但全局范围的操作日志,我觉得还是应该保存到专门的文档数据库,比如ElasticSearch,Mongodb等。
我反对将日志记录到关系数据库主要有2点,一是对于业务系统来说,尤其是web系统,日志的产生应该来说是非常密集的,频繁的读写关系数据库会严重影响性能,当然你也可以和业务库分开,但仍然避免不了它的快速的增长,后续也很难做一些日志分析类相关的操作,这是关系数据库的弱项,却是ES之类文档数据库的强项;另一个原因是,关系数据库里记录日志,从内部安全审计角度来看,被篡改的门槛很低,相关开发者一个sql语句就可以抹掉或者改到很多真实的记录,这个懂得都懂。
但话又说回来,如果是一些小项目,也要做ES之类的介入吗,复杂性会不会太高了。
关于这点,我的观点是,开发团队自己要对项目做好定位,即便是简单的项目,也应该对日志模块花一些功夫,毕竟这是系统自己说的话,可以定位很多问题。如果觉得ES,Mongodb这类中间件的引入投入产出比太低,或者缺乏相关的运维能力,那至少,日志也要同步一份记录到文件系统里,或者你要做好防篡改的机制,比如利用一些密码学知识,增加一些哈希值的记录等等,总之要确保日志是真实可靠的。
好了,基本就是这些了,周末愉快。