前言:
卡尔曼滤波,古老而神秘。在数据处理的世界里,我们早已拥有诸多优秀的算法:低通滤波、高通滤波、半径滤波、K近邻滤波、均值滤波......它们各司其职,稳健可靠。然而,唯有卡尔曼滤波,仿佛是在时间的舞台上挥毫作画------它不仅能够预测未来的形态,更让整个系统的可靠性跃升至新的维度。所以,我将写下这篇博客,让我们走近卡尔曼,同时也走进卡尔曼。
主要参考以下文章:
正文:
一、卡尔曼滤波
其实,在实际控制系统中,我们常常面临一个棘手的问题:如何融合多个传感器的数据?因为我们通常不会轻易地完全相信某一个传感器的输出。例如,激光雷达在遇到反光或透光物体时,采集到的数据会变得不可靠------这时我们多么希望能借助相机数据来补偿雷达的不足。再比如,开车导航时,在开阔的室外我们信赖GPS,但一旦进入隧道,GPS信号减弱甚至丢失,此时就只能更多依赖手机的陀螺仪(IMU)。而本文重点讨论的视觉跟踪也面临类似困境:当跟踪的目标被遮挡时,我们无法直接知道下一秒目标会去哪里。这时,就需要利用之前的数据对下一时刻做出预测,直到遮挡结束再更新测量值。正是这些场景,让卡尔曼滤波有了用武之地。
1、简介
卡尔曼滤波是一种递归的最优估计算法,核心是"预测---更新":先根据系统运动规律猜一下下一时刻的状态,再拿实际传感器数据去修正这个猜测,权重由两者各自的不确定度决定。它诞生于1960年,由卡尔曼提出,克服了传统滤波需要存储全部历史数据且无法处理非平稳系统的缺点,很快就在阿波罗导航等任务中落地。后来为了应对现实中的非线性问题,又发展出扩展卡尔曼滤波、无迹卡尔曼滤波以及自适应、鲁棒等变体,甚至与深度学习结合。如今,它的身影无处不在:自动驾驶中融合GPS、激光雷达和相机,手机导航里用IMU补偿隧道中的信号丢失,机器人定位、视觉跟踪的目标遮挡预测,乃至金融时序分析,都离不开这个"在时间舞台上作画"的算法。
2、核心公式
其实,说到这个算法,其实也还是很简单,具体就是下面这五个核心的公式。

关于这五个公式的数学推导,我也会在本文章中体现出来。
3、公式数学推导
实际例子:
直接套用上面那些矩阵公式,理解起来还是有些困难------矩阵毕竟太抽象。所以我们先从一个一维的例子入手。假设有一辆车以1 m/s的速度做直线运动,车上装有GPS,可以测量它行驶的距离。理论上,经过时间 Ts秒,车子应该走 Ts米。但在实际情况中,由于轮子可能打滑,实际位移未必等于 Ts米;同时,GPS信号也会上下波动。我们就用这个例子,来推导卡尔曼滤波五个核心公式在一维情况下的具体形式。
前提知识:
在开始推导之前,我们需要对小学知识做一个回忆。
一组数据的和除以数据的个数就是平均数,它能反映一组数据的平均水平。
每个数据与平均数之差的平方和的平均值就是方差。方差反映的是一组数据的离散程度或波动大小------方差越大,数据越分散;方差越小,数据越集中。特殊地,方差为0时,所有数据都等于平均数。
在实际生活中,绝大多数数据都服从(或近似服从)正态分布。正态分布曲线关于 x=μ(平均值)对称,曲线的"胖瘦"由标准差 σ(即方差的平方根)决定。数据落在 μ−σ,μ+σ 这个区间内的概率约为68%,落在区间外的概率约32%;而落在更宽的区间(如 μ−2σ,μ+2σ])内的概率则更高(约95%)。总之,数据落在平均值附近区间内的概率,明显大于落在远离平均值的区间外的概率。
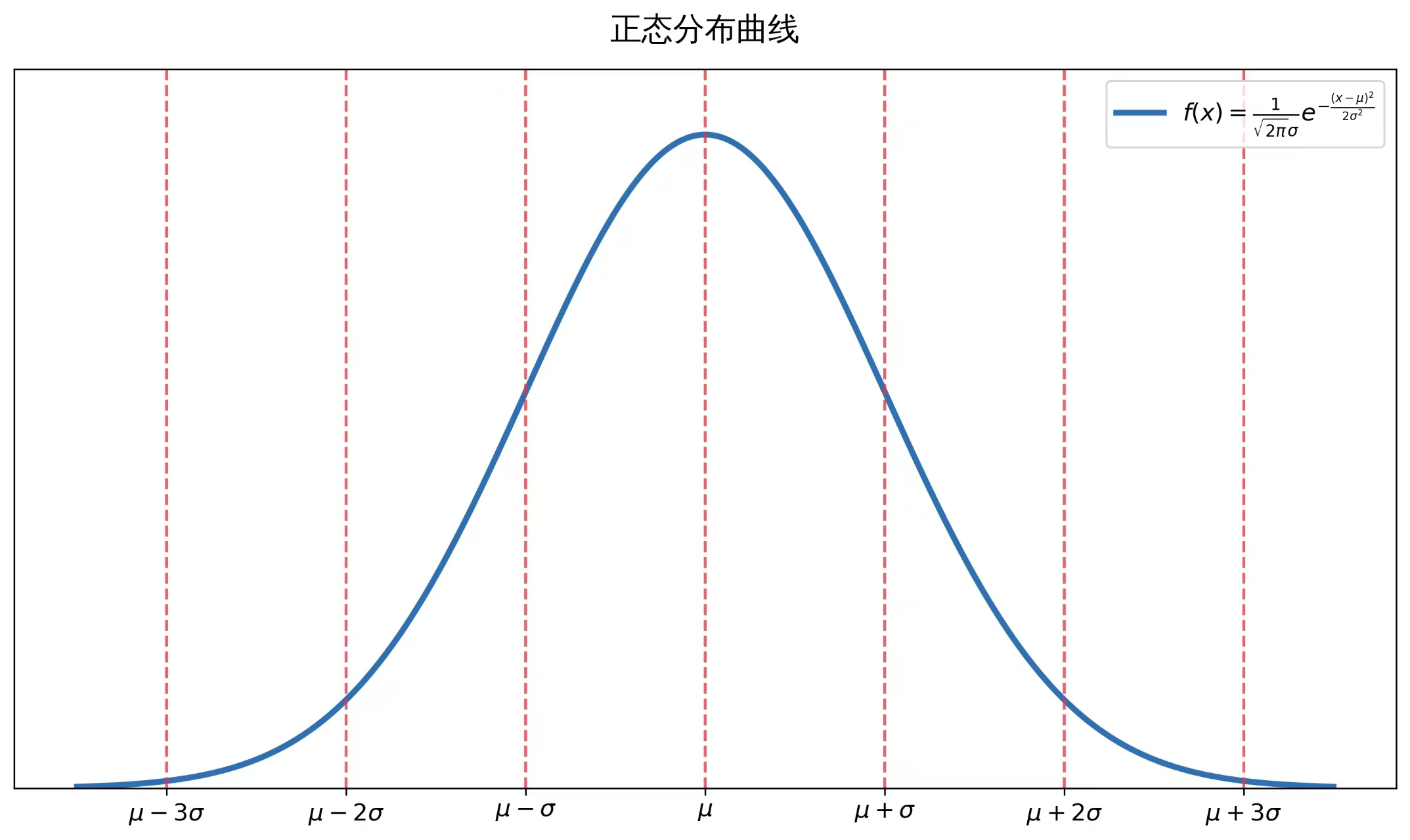
开始计算:
假如我们通过 1 m/s 的速度乘以时间 dt 来预测小车的位置,记预测值为 x1,并假设它的方差为 σ1²=1 m(即标准差 σ1=1 m,这个数值可以随便取,随着卡尔曼滤波的进行会逐渐收敛到合理值)。
那么,在 dt 时间后,预测位置 x1 的均值 是 1×dt,而它的可能取值大约在 1×dt±1 的范围内(因为 ±1倍标准差包含了约 68% 的概率)。换句话说,x1大致会在 1×dt+1 和1×dt−1 之间波动。
同时,我们假设GPS测量的移动距离也有4m的波动,既σ2²=4 m(即标准差 σ2=2 m,这个数值一般传感器厂家会给的)。
那么,我们就可以得到下表:

然而,上述推导隐含了一个假设:小车的运动完全精确地遵循"1 m/s 的匀速模型"。实际上,路面摩擦、微小加减速、风阻等随机扰动会使真实速度发生波动,导致模型预测值与真实轨迹之间出现额外的偏差。这种未建模的随机加速度 称为过程噪声 。为了反映这种不确定性,我们需要在每一步预测中增加一个过程噪声方差 Q。于是,预测方差不再保持固定值,而是更新为:
σ²= σ1²+Q
其中 σ1² 是上一时刻的最优估计方差, σ²就是新时刻的 σ1²。Q 越大,表明模型越不可靠,滤波器会更加信任测量值。引入 Q 后,估计方差不会无限减小,而是稳定在一个合理的平衡值,从而更真实地描述动态系统。
下面是引入Q后的计算表格:

好了,通过上面的实际例子,我们现在对卡尔曼滤波在一维的应用应该是有了一个初步的概念,实际上:
-
状态:小车位置 x(标量)
-
控制输入:速度 u=1m/s,作用时间 dt
-
状态转移矩阵:F=1(位置直接传递)
-
控制矩阵:B=dt
-
观测矩阵:H=1(直接测量位置)
-
过程噪声方差:Q=2
-
测量噪声方差:R=4m²
在k时刻,对应上面那5个公式就是:


其实这就很好的解释了卡尔曼滤波的过程,下面就让我们来扩展为多维矩阵形式。
推导扩展:
a、前提已知条件
那么,经过上面的案例,实际上我们对卡尔曼滤波的运算也就清楚了。现在就让我再在上面例子的基础上新增一些东西,比如小车的位置为p,小车的速度为v,小车外部加速度为a,GPS测量位置和上面一样方差为4。
好的,现在开始计算的话就是:
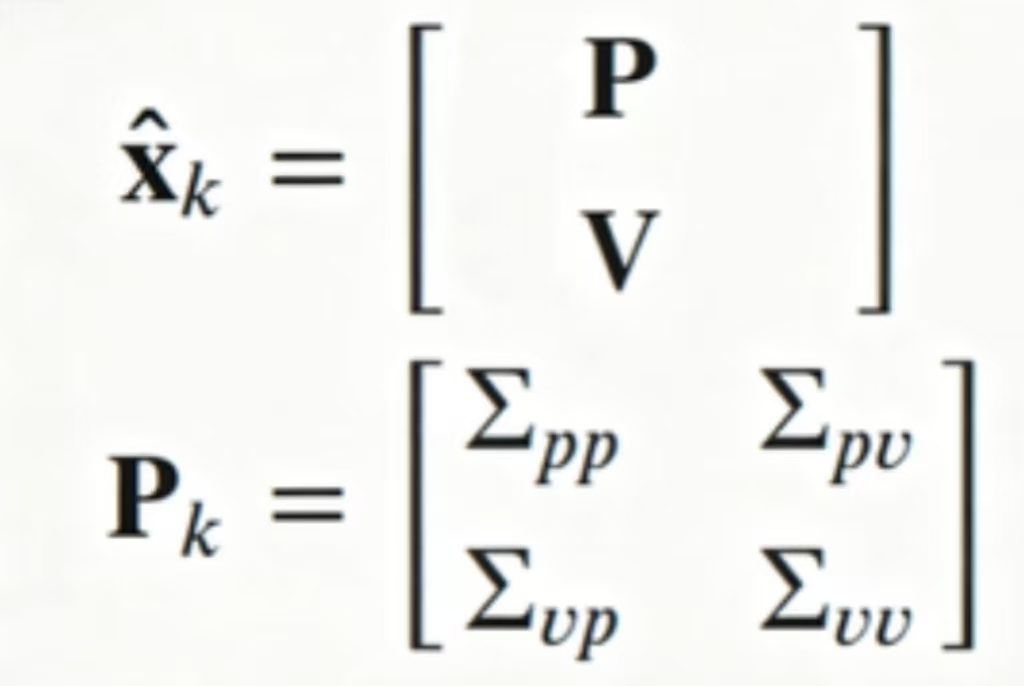
这里 Pk其实和上面一维的方差道理一样的,不同的是我们这里这个叫做协方差矩阵,关于协方差我在下面补充处说明,如果不需要可以跳过。
补充:
协方差矩阵用于描述多个随机变量之间的方差与相关性。
-
对角线元素:每个变量自身的方差(如位置方差、速度方差)。
-
非对角线元素:两个变量之间的协方差(表示它们的变化是否同步,正负表示相关方向)。
在卡尔曼滤波中,状态向量(如位置和速度)的协方差矩阵记为 P,它表示状态估计的不确定性及变量间耦合关系。

end补充
b、预测步公式骤推导
那么,我们可以有:
0时刻 位置为P0 速度为V0
dt时刻 位置为P0+V0dt 速度继续为V0 (这里我们认为dt很小 忽略了a的影响)
如果加入a的控制的话,那么:
dt时刻 位置为P0+V0dt+1/2adt² 速度为 V0+adt

这就是第一个公式的来源。

所以就有了
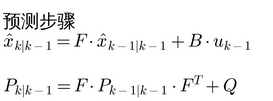
c、更新步骤推导
更新步骤的核心是将卡尔曼滤波的预测结果与传感器实测数据进行最优融合,同时迭代更新协方差矩阵,以降低状态估计的不确定性。

以上便是一维卡尔曼滤波在多维情形下的自然扩展。借助一维例子中的直观理解(预测与测量的加权融合),可以更好地把握多维滤波的核心思想。整个卡尔曼滤波过程,本质上就是不断重复"预测"与"更新"两个步骤的递推循环。
二、实际应用
1、应用场景
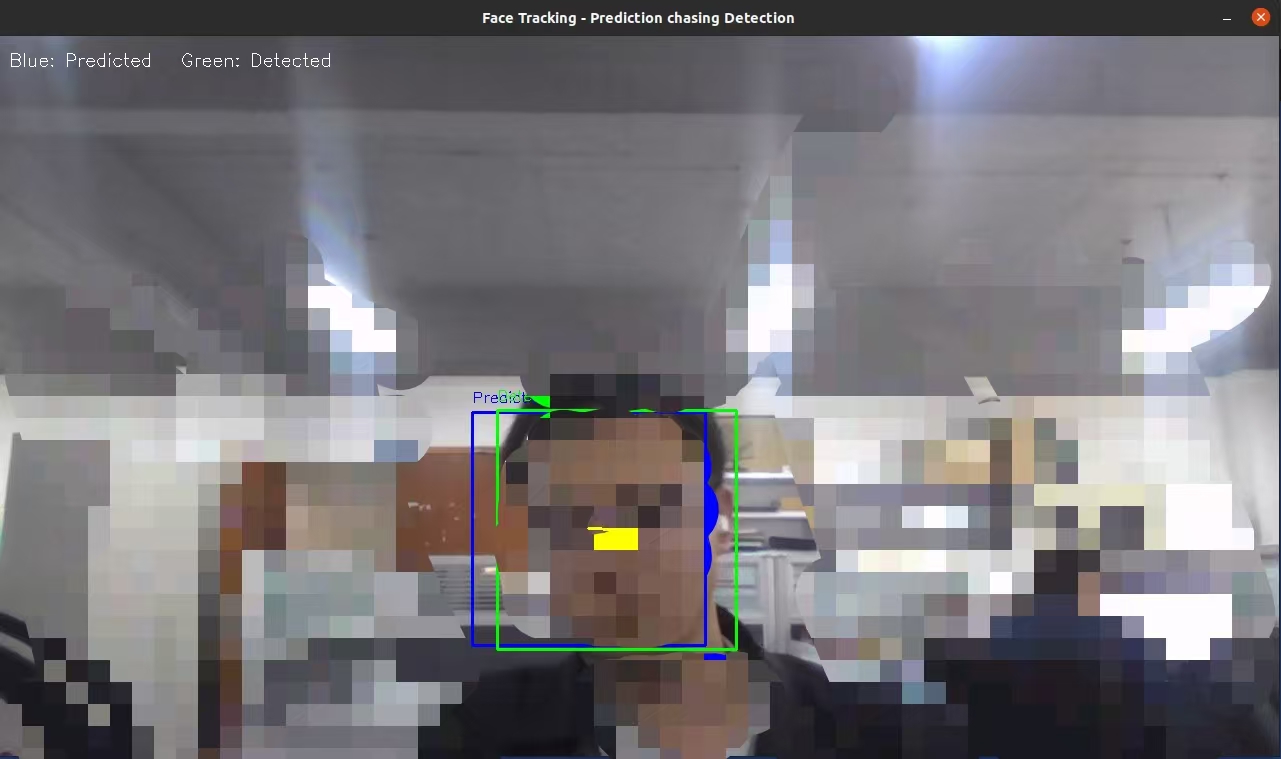
开发一个实时人脸跟踪系统,利用摄像头采集视频流,结合卡尔曼滤波算法对人脸位置进行预测和跟踪。系统能够持续输出预测框(蓝色)和检测框(绿色),并通过预测框"追击"检测框的方式直观展示滤波效果。
2、关键技术
a. Haar 级联分类器(人脸检测)
-
原理:基于 Viola-Jones 框架,使用 Haar-like 特征和 AdaBoost 训练得到的级联分类器。
-
作用 :在灰度图像中快速检测人脸区域,返回边界框
(x, y, w, h)。 -
**说明:**这里人脸识别的方式不是关键,关键是卡尔曼滤波,所以也可以用yolo等方法。
b. 卡尔曼滤波(Kalman Filter)------ 核心
- 目标 :对人脸中心点
(x, y)及其速度(vx, vy)进行最优估计,即使检测偶尔失败也能平滑预测位置。

3、代码实现
python
import cv2
import numpy as np
import os
import urllib.request
# ================== 1. 自定义卡尔曼滤波器 ==================
class KalmanFilter:
"""
二维匀速运动模型的卡尔曼滤波器
状态向量 x = [x, y, vx, vy]^T
- x, y : 目标中心坐标
- vx, vy: 速度分量
"""
def __init__(self, dt=1.0):
self.dt = dt
# ---------- 状态转移矩阵 F ----------
# 根据匀速运动模型:位置 = 上一位置 + 速度 * dt,速度保持不变
# [ x_new ] [1, 0, dt, 0] [ x ]
# [ y_new ] = [0, 1, 0, dt] [ y ]
# [vx_new] [0, 0, 1, 0] [vx]
# [vy_new] [0, 0, 0, 1] [vy]
self.F = np.array([
[1, 0, dt, 0],
[0, 1, 0, dt],
[0, 0, 1, 0],
[0, 0, 0, 1]
], dtype=np.float32)
# ---------- 观测矩阵 H ----------
# 我们只能直接观测到位置 (x, y),不能直接观测速度
# 所以观测值 z = H * x,H 将状态空间映射到观测空间
self.H = np.array([
[1, 0, 0, 0],
[0, 1, 0, 0]
], dtype=np.float32)
# ---------- 过程噪声协方差矩阵 Q ----------
# 描述系统模型的不确定性(如速度突变、未建模的加速度)
# 这里简化为对角矩阵,数值越小表示模型越可信
self.Q = np.eye(4, dtype=np.float32) * 0.01
# ---------- 观测噪声协方差矩阵 R ----------
# 描述检测器(人脸检测)的噪声,数值越大表示检测结果越不可信
self.R = np.eye(2, dtype=np.float32) * 0.1
# ---------- 误差协方差矩阵 P ----------
# 初始值较大,表示初始状态非常不确定,随着滤波进行会收敛
self.P = np.eye(4, dtype=np.float32) * 100.0
# ---------- 状态向量 x ----------
# 初始化为 0,第一次检测后会通过 set_state 或 correct 赋值
self.x = np.zeros((4, 1), dtype=np.float32)
def predict(self):
"""
预测步骤(卡尔曼滤波公式 1 和 2)
--------------------------------------------------
1. 状态预测: x_pred = F * x
2. 协方差预测: P_pred = F * P * F^T + Q
返回预测的位置 (x, y)
"""
# 公式 (1) 状态预测
self.x = self.F @ self.x
# 公式 (2) 协方差预测
self.P = self.F @ self.P @ self.F.T + self.Q
# 返回预测的位置(二维)
return self.x[:2].flatten()
def correct(self, measurement):
"""
更新步骤(卡尔曼滤波公式 3、4、5)
--------------------------------------------------
3. 卡尔曼增益: K = P_pred * H^T * (H * P_pred * H^T + R)^{-1}
4. 状态更新: x_opt = x_pred + K * (z - H * x_pred)
5. 协方差更新: P_opt = (I - K * H) * P_pred
参数 measurement: 检测到的目标中心 (x, y)
返回更新后的位置 (x, y)
"""
# 将测量值转为列向量
z = np.array(measurement, dtype=np.float32).reshape(2, 1)
# 新息(残差): 测量值 - 预测的观测值
y = z - self.H @ self.x
# 新息协方差: S = H * P_pred * H^T + R
S = self.H @ self.P @ self.H.T + self.R
# 公式 (3) 卡尔曼增益
K = self.P @ self.H.T @ np.linalg.inv(S)
# 公式 (4) 状态更新(融合测量值)
self.x = self.x + K @ y
# 公式 (5) 协方差更新(标准形式,要求数值稳定可改用 Joseph 形式)
self.P = (np.eye(4) - K @ self.H) @ self.P
return self.x[:2].flatten()
def set_state(self, x, y, vx=0, vy=0):
"""手动设置状态向量(通常用于初始化)"""
self.x = np.array([[x], [y], [vx], [vy]], dtype=np.float32)
# ================== 辅助函数:下载 Haar 级联文件 ==================
def download_haarcascade(filename="haarcascade_frontalface_default.xml"):
"""如果当前目录下不存在指定的级联文件,则从 OpenCV GitHub 下载并提示用户"""
if os.path.exists(filename):
return filename
url = f"https://raw.githubusercontent.com/opencv/opencv/master/data/haarcascades/{filename}"
print(f"未找到人脸检测模型文件 '{filename}',正在从网络下载...")
try:
urllib.request.urlretrieve(url, filename)
print(f"下载完成,已保存为 '{filename}'")
except Exception as e:
raise IOError(f"下载失败:{e}\n请手动下载 {filename} 并放在当前目录下。")
return filename
# ================== 2. 人脸跟踪器(同时返回预测框和检测框) ==================
class KalmanFaceTracker:
def __init__(self, cascade_filename="haarcascade_frontalface_default.xml",
detection_interval=1):
"""
:param cascade_filename: 级联分类器文件名(默认在当前目录查找)
:param detection_interval: 检测间隔(1 = 每帧检测)
"""
# 确保模型文件存在(自动下载)
cascade_path = download_haarcascade(cascade_filename)
self.face_cascade = cv2.CascadeClassifier(cascade_path)
if self.face_cascade.empty():
raise IOError(f"无法加载分类器: {cascade_path}")
self.kf = KalmanFilter(dt=1.0)
self.detection_interval = detection_interval
self.frame_count = 0
self.last_known_size = (100, 100) # 默认人脸尺寸(用于绘制预测框)
self.is_initialized = False # 是否已获得第一次检测
def detect_face(self, gray_frame):
"""在灰度图中检测最大人脸,返回中心点和边界框"""
faces = self.face_cascade.detectMultiScale(
gray_frame, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)
)
if len(faces) == 0:
return None, None
# 取面积最大的人脸(通常是最靠近摄像头的人)
x, y, w, h = max(faces, key=lambda f: f[2] * f[3])
center = (x + w // 2, y + h // 2)
return center, (x, y, w, h)
def update(self, frame):
"""
处理一帧图像
返回:
- pred_bbox: 预测框 (x, y, w, h) (蓝色)
- det_bbox: 检测框 (x, y, w, h) (绿色,如果没有检测则为 None)
"""
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
self.frame_count += 1
# ---------- 1. 卡尔曼预测(每帧执行) ----------
pred_center = self.kf.predict()
pred_x, pred_y = int(pred_center[0]), int(pred_center[1])
# 用上一次已知的人脸尺寸生成预测框(保证预测框大小稳定)
w_pred, h_pred = self.last_known_size
pred_bbox = (pred_x - w_pred // 2, pred_y - h_pred // 2, w_pred, h_pred)
# ---------- 2. 按间隔进行人脸检测 ----------
det_bbox = None
if self.frame_count % self.detection_interval == 0:
center, bbox = self.detect_face(gray)
if center is not None:
det_bbox = bbox
# 更新已知人脸尺寸(为下一帧的预测框提供参考)
self.last_known_size = (bbox[2], bbox[3])
# 卡尔曼更新(用检测值修正滤波器)
self.kf.correct(center)
if not self.is_initialized:
self.is_initialized = True
return pred_bbox, det_bbox
def reset(self):
"""重置跟踪器状态(用于重新开始跟踪)"""
self.kf.x = np.zeros((4, 1), dtype=np.float32)
self.kf.P = np.eye(4, dtype=np.float32) * 100.0
self.frame_count = 0
self.is_initialized = False
self.last_known_size = (100, 100)
# ================== 3. 主程序 ==================
def main():
cap = cv2.VideoCapture(0)
# 检测间隔设为 1,每帧都检测,响应最快(也可改为 2~5 以提高帧率)
tracker = KalmanFaceTracker(detection_interval=1)
print("按 'q' 退出,按 'r' 重置跟踪器")
print("蓝色框: 卡尔曼预测框(会追击绿色检测框)")
print("绿色框: 实际人脸检测框(观测值)")
while True:
ret, frame = cap.read()
if not ret:
break
pred_bbox, det_bbox = tracker.update(frame)
# 绘制预测框(蓝色)
px, py, pw, ph = pred_bbox
cv2.rectangle(frame, (px, py), (px + pw, py + ph), (255, 0, 0), 2)
cv2.putText(frame, "Prediction", (px, py - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 1)
# 绘制检测框(绿色)
if det_bbox is not None:
dx, dy, dw, dh = det_bbox
cv2.rectangle(frame, (dx, dy), (dx + dw, dy + dh), (0, 255, 0), 2)
cv2.putText(frame, "Detection", (dx, dy - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# 绘制预测中心到检测中心的连线(黄色),直观显示"追击"效果
pred_center = (px + pw // 2, py + ph // 2)
det_center = (dx + dw // 2, dy + dh // 2)
cv2.line(frame, pred_center, det_center, (0, 255, 255), 2)
# 图例说明
cv2.putText(frame, "Blue: Predicted Green: Detected", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 1)
cv2.imshow('Face Tracking - Prediction chasing Detection', frame)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('r'):
tracker.reset()
print("跟踪器已重置")
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()上面是python代码,需要python和opencv的开发环境,并且需要有usb或者电脑摄像头才能运行。
4、运行效果
结语:
数学,是一门精妙而优雅的语言。生在这个时代,我们是幸运的------数学知识空前丰沛,AI工具俯拾皆是,获取真知的渠道从未如此宽广。只要我们沉心静气,步步为营,每一道曾经高不可攀的技术门槛,终将成为我们拾级而上、攀向下一座高峰的坚实阶梯。