家人们好呀!!!
如果你要把全班50个学生的成绩存起来,难道要定义score1、score2、score3......一直到score50吗?那你的代码会像超市小票一样长得让人绝望。
幸运的是,C++早就帮你准备好了解决方案------数组(Array)。你可以把它想象成一排带编号的储物柜,一个名字就能管理一整排柜子,通过编号(下标)直接找到对应的那个。
而字符串(String),本质上也是一种特殊的数组------字符的数组。但由于字符串实在太常用了,C++为它准备了专门的"VIP待遇"。
本文就是你的"数组与字符串完全指南"。我们将从C风格的"老古董"讲起,一直到C++标准库里的现代"利器"。准备好了吗?让我们开始给数据排排坐。
一、数组
1.1 什么是数组?
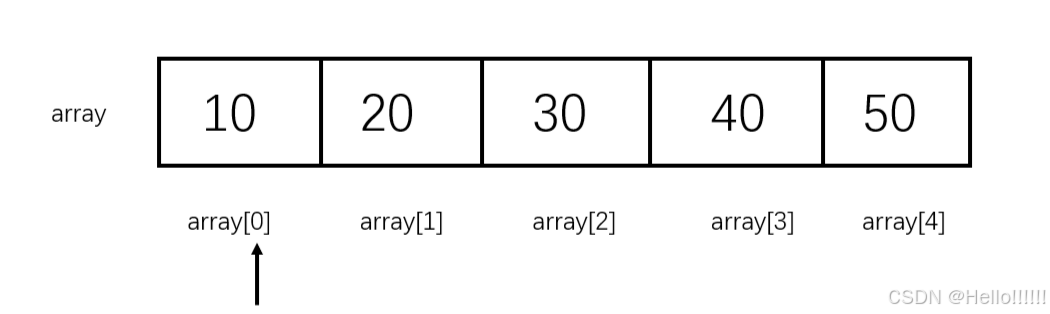
数组是一块连续的内存空间,里面存放着一串相同类型的数据。它的核心特点有三个:
- 类型相同:一个数组里只能放同一种类型的数据(全是int、全是double......)。
- 大小固定(对于内置数组) :一旦创建,数组的长度就不能改变。
- 连续存储:所有元素在内存中是紧密相邻的,这赋予了数组极高的访问效率。
数组就像一列首尾相接的火车车厢。你有一列int号列车,它的每节车厢都只能装整数。你可以通过"第几节车厢"(下标)立刻找到里面的东西(元素),因为这列火车的车厢是连续编号的。
1.2 C风格数组
虽然C++11之后有了更现代的std::array,但C风格的原始数组仍然是很多底层代码的基石,也是理解指针和内存的第一步。
声明与初始化
cpp
// 声明并初始化方式1:指定大小,随后赋值(其他元素自动为0)
int scores[5] = {95, 88, 76, 92, 100};
// 声明并初始化方式2:让编译器自动算大小
double prices[] = {9.99, 19.99, 29.99}; // 自动推导出大小为3
// 声明方式3:先声明,后赋值(所有元素初值为垃圾值!)
int data[10]; // 局部数组,元素值是随机的!重要提醒:局部作用域的C风格数组(在函数内部声明的),如果只声明不初始化,里面的值是垃圾值(内存中残留的随机数)。
访问元素:下标操作符 \[\]
数组用下标(从0开始)来访问元素:
cpp
int scores[5] = {95, 88, 76, 92, 100};
cout << "第一个人的成绩:" << scores[0] << endl; // 输出95
cout << "第三个人的成绩:" << scores[2] << endl; // 输出76
scores[1] = 90; // 把第二个人的成绩改成90数组编序号是从0开始的,这被称为"零基索引"。所以有5个元素的数组,有效下标是0, 1, 2, 3, 4。
为什么程序员数数总是从0开始?因为他们习惯了------数组的第一个元素在偏移量为0的位置,就这么简单。这导致程序员在生活中也经常"从0开始",去餐厅点菜可能会说"我要第0道菜"......
数组越界
这是C风格数组最危险的特性:访问数组时,C++不检查下标是否有效!
cpp
int data[5] = {1, 2, 3, 4, 5};
cout << data[10]; // 越界了!但编译能通过,运行时可能崩溃,也可能读到随机值这种错误被称为未定义行为(UB)。结果可能是程序崩溃(运气好),也可能是悄悄读到/写入了不该动的内存,导致程序在另一个完全不相关的地方出错(运气差,调试到你怀疑人生)。
1.3 数组与指针的"纠缠"
这是C/C++中最核心也最令人头疼的关系之一:数组名在大多数情况下会被视为指向数组首元素的指针。
cpp
int arr[5] = {10, 20, 30, 40, 50};
int* ptr = arr; // arr被隐式转换为指向arr[0]的指针
cout << *ptr << endl; // 输出10
cout << *(ptr + 1) << endl; // 输出20(指针偏移到arr[1])有四个例外情况,数组名不会被转换为指针:
- 作为sizeof的操作数:sizeof(arr)返回整个数组的大小(5 × 4 = 20字节)。
- 作为取地址操作符&的操作数:&arr的类型是int(*)5(指向包含5个int的数组的指针),而不是int**。
- 作为字符串字面量用于初始化字符数组。
- 作为decltype的操作数。
指针算术:指针加1,实际上加的是指针所指向类型的大小,而不是1个字节。对于int*,加1就是地址加4字节。
数组作为函数参数:当你把数组名传给函数时,实际上传的是指针(数组首地址),函数并不知道数组有多大。所以通常需要把大小也一并传过去,或者用一个"哨兵值"标记数组结束(C风格字符串用的就是'\0')。
cpp
// 两种写法完全等价
void printArray(int arr[], int size); // arr本质上是指针
void printArray(int* arr, int size); // 和上面一模一样1.4 std::array:来自C++11的现代化"改良版"
std::array(定义在array头文件中)是对C风格数组的C++封装,大小固定但功能更丰富。它支持迭代器、有size()方法、不会退化为指针,是固定大小数组的首选。
cpp
#include <array>
using namespace std;
array<int, 5> scores = {95, 88, 76, 92, 100}; // 大小在签名中指定
// 遍历方式1:标准for循环
for (int i = 0; i < scores.size(); ++i) {
cout << scores[i] << " ";
}
// 遍历方式2:范围for(推荐)
for (int x : scores) {
cout << x << " ";
}
// 实用成员函数
scores.size(); // 获取元素个数
scores.at(0); // 带越界检查的访问(越界会抛出异常)
scores.front(); // 第一个元素
scores.back(); // 最后一个元素
scores.fill(0); // 所有元素填充为0
scores.empty(); // 判断是否为空std::array的优势是它不会退化为指针,当作函数参数传递时类型信息得以保留,使用迭代器遍历也更加安全。在现代C++中,能用std::array的地方就不要用C风格数组。
二、多维数组:套娃的艺术
当一维数组不能满足需求时,比如要存一个矩阵或者一张图像的数据,就需要二维甚至更高维的数组。
2.1 二维数组基础
cpp
// 声明一个3行4列的矩阵
int matrix[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
cout << matrix[0][2] << endl; // 输出3(第0行第2列)二维数组的本质是"数组的数组"。在内存中,它是按行连续存储的(行优先)。
2.2 std::array二维版本
cpp
array<array<int, 4>, 3> matrix2 = {{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
}};
for (const auto& row : matrix2) { // 外层遍历每一行
for (int val : row) { // 内层遍历行中的每个元素
cout << val << " ";
}
cout << endl;
}2.3 多维数组作为函数参数
这是最需要注意的地方------当你把多维数组作为参数传递给函数时,除了第一维,其他维度的大小必须明确指定:
cpp
// 正确:指定了列数
void printMatrix(int matrix[][4], int rows) { /* ... */ }
// 错误!编译器无法确定行的大小
// void printMatrix(int matrix[][]) { ... }(对于更高维数组,也是除了最左边的第一维,其余维度大小都需要在形参声明中指定。)
三、C风格字符串:以'\0'为终点的时代
在C++早期,字符串就是用字符数组来处理的,并以一个特殊字符'\0'(空字符,ASCII码为0)作为结束标志。这种字符串被称为C风格字符串。
3.1 基础用法
cpp
char name1[] = "Alice"; // 编译器自动在末尾加'\0',数组大小为6
char name2[] = {'B', 'o', 'b', '\0'}; // 手动添加'\0'
char name3[20] = "Charlie"; // 预留足够空间
cout << name1 << endl; // 输出Alice(遇到'\0'才停)关键点:"Alice"这个字符串字面量,实际占用6个字符(5个字母 + 1个'\0')。忘记给'\0'留空间是新手常犯的错误。
3.2 常用操作函数(定义在cstring)
| 函数 | 用途 | 注意 |
|---|---|---|
| strlen(s) | 获取长度(不含'\0') | 遍历到'\0'为止 |
| strcpy(dst, src) | 复制字符串 | 确保dst空间足够 |
| strcat(dst, src) | 拼接字符串 | 同上 |
| strcmp(s1, s2) | 比较大小 | 返回0表示相等 |
cpp
#include <cstring>
using namespace std;
char buffer[50];
strcpy(buffer, "Hello"); // buffer现在是"Hello"
strcat(buffer, " World"); // buffer现在是"Hello World"
cout << strlen(buffer) << endl; // 输出11
cout << strcmp("abc", "abd") << endl; // 输出负数(abc < abd)C风格字符串的优点是简单、与C语言API兼容。但缺点也很明显:操作麻烦、容易越界(忘了留'\0'的空间可能导致缓冲区溢出,这是很多安全漏洞的根源)、不能直接用==比较内容。
四、std::string:现代C++的字符串王者
std::string(定义在string头文件)是C++标准库提供的字符串类型,自动管理内存、支持动态扩容,使用起来像是给字符串操作开了"外挂"。
4.1 基础操作
cpp
#include <string>
using namespace std;
string s1; // 空字符串
string s2 = "Hello"; // 初始化
string s3("World"); // 另一种初始化方式
string s4 = s2 + " " + s3 + "!"; // 直接拼接!输出"Hello World!"长度与访问:
cpp
string str = "Hello";
cout << str.length() << endl; // 输出5
cout << str[0] << endl; // 输出'H'(不检查越界)
cout << str.at(0) << endl; // 输出'H'(检查越界,越界会抛异常)
str[0] = 'h'; // 修改字符,str变成"hello"比较:string可以直接用==、<、>进行比较,按字典序逐个字符比对:
cpp
if (str1 == str2) { /* ... */ }
if (str1 < str2) { /* 按字典序比较 */ }子串与查找:
cpp
string str = "Hello World";
string sub = str.substr(0, 5); // "Hello"(从索引0开始取5个字符)
size_t pos = str.find("World"); // 返回6(首次出现的位置)
size_t pos2 = str.find('o', 5); // 从索引5开始找'o',返回7
size_t pos3 = str.find("xyz"); // 返回string::npos表示没找到
str.replace(6, 5, "C++"); // 从索引6开始,把5个字符替换成"C++"
str.erase(5, 1); // 从索引5开始,删除1个字符
str.insert(0, "Say: "); // 在索引0处插入遍历string:
cpp
string str = "C++";
for (char ch : str) { // 范围for遍历
cout << ch << " ";
}
for (size_t i = 0; i < str.size(); ++i) { // 传统下标遍历
cout << str[i] << " ";
}4.2 string与数值互转(C++11起)
cpp
// 字符串转数值
int a = stoi("42"); // string to int
double b = stod("3.14"); // string to double
long long c = stoll("12345678"); // string to long long
// 数值转字符串
string s1 = to_string(42); // int to string → "42"
string s2 = to_string(3.14); // double to string → "3.140000"(注意默认6位小数)4.3 string vs C风格字符串
| 对比维度 | C风格字符串(char\[\]) | std::string |
|---|---|---|
| 内存管理 | 手动,容易溢出 | 自动扩容,安全 |
| 拼接 | strcat,需手动管理空间 | 直接用+号 |
| 比较 | strcmp,不能直接== | 直接用== |
| 获取长度 | strlen(O(n)遍历) | .size()(O(1)) |
| 作为函数参数 | 退化为指针 | 可以传引用,保留类型信息 |
| 学习建议 | 理解原理,知道怎么用就行 | 日常开发首选 |
五、std::vector:C++动态数组
如果数组的大小不确定------比如你需要存一个班的学生成绩,但这个班的人数随时可能变化------那么std::vector就是你的最佳选择。
std::vector定义在vector头文件中,是一个动态数组,可以随时增长或缩小。
cpp
#include <vector>
using namespace std;
vector<int> v; // 空vector
vector<int> v2(5); // 5个元素,初始值为0
vector<int> v3(5, 42); // 5个元素,初始值为42
vector<int> v4 = {1, 2, 3}; // 初始化列表核心操作:
| 操作 | 代码 | 说明 |
|---|---|---|
| 添加元素 | v.push_back(10); | 在末尾添加 |
| 删除末尾 | v.pop_back(); | 删除最后一个元素 |
| 访问 | v0、v.at(0) | \[\]不检查越界,.at()会检查 |
| 大小 | v.size() | 当前元素个数 |
| 容量 | v.capacity() | 已分配的内存能容纳多少个元素 |
| 清空 | v.clear() | 删除所有元素,size变0 |
| 判空 | v.empty() | 是否为空 |
| 首/尾元素 | v.front()、v.back() | 获取第一个/最后一个元素 |
| 在任意位置插入 | v.insert(it, val) | 在迭代器it位置前插入 |
| 删除任意位置 | v.erase(it) | 删除迭代器it指向的元素 |
遍历vector:
cpp
vector<int> v = {10, 20, 30, 40, 50};
for (int x : v) { cout << x << " "; } // 范围for
for (size_t i = 0; i < v.size(); ++i) { cout << v[i]; } // 下标
for (auto it = v.begin(); it != v.end(); ++it) { cout << *it; } // 迭代器vector是动态数组,向其中添加元素可能触发重新分配内存(当size()超过capacity()时)。如果你大致知道会用多少元素,可以用v.reserve(n)预先分配空间来避免多次重新分配。
六、字符串输入再探:getline与cin混用的终极解决方案
在上一篇文章中我们提到过这个"千古谜题",这里再系统梳理一遍。
问题:cin >>读取数字后紧接getline(cin, str),getline会被跳过。
cpp
int age;
string name;
cin >> age; // 输入25,按回车
getline(cin, name); // 读到了回车符,直接返回空字符串!原因:cin >>读取了数字,但把行尾的换行符'\n'留在了输入缓冲区。getline一上来就看到换行符,以为读到了一行空行。
终极解决方案:
cpp
cin >> age;
cin.ignore(numeric_limits<streamsize>::max(), '\n'); // 清掉换行符
getline(cin, name); // 现在正常工作了如果前面有多次cin >>,也可以用循环来清空缓冲区,但最稳妥的做法就是在每次cin >>之后、getline之前加cin.ignore()。
七、现代C++新特性(C++17到C++26)
7.1 C++17:std::string_view
std::string_view(定义在string_view头文件)相当于一个"窗口",它指向一个已存在的字符串的某一段,但不拥有内存,因此创建开销极小。
cpp
#include <string_view>
using namespace std;
string str = "Hello World";
string_view sv = str; // 不复制字符串内容
string_view sub = sv.substr(0, 5); // "Hello",也没有复制!
void print(string_view sv) { // 可以同时接受string和const char*
cout << sv << endl;
}使用场景:函数只需要读取字符串内容而不需要持有它时,用string_view可以避免不必要的拷贝。但要注意string_view不拥有内存,原字符串被销毁后不能继续使用。
7.2 C++20:starts_with 和 ends_with
cpp
string str = "Hello World";
bool b1 = str.starts_with("Hell"); // true
bool b2 = str.ends_with("rld"); // true
bool b3 = str.contains("lo Wo"); // C++23,true7.3 C++20/23:数组相关的其他改进
C++20起部分编译器已支持constexpr vector,C++23全面支持。std::span(C++20)提供了对连续内存区域的安全视图访问。
八、最佳实践
- 能用std::string就别用char\[\]。
- 能用std::array就别用C风格数组(固定大小)。
- 能用std::vector就别用new出来的动态数组(大小可变)。
- 需要只读访问字符串时考虑std::string_view。
- 提交代码前检查所有数组下标是否可能越界。
- cin >>后紧接getline记得清缓冲区。
九、动手实践
打开Visual Studio,把下面的代码跑起来:
cpp
#include <iostream>
#include <string>
#include <array>
#include <vector>
using namespace std;
int main() {
// 1. std::array 演示
cout << "=== std::array ===" << endl;
array<int, 5> scores = {95, 88, 76, 92, 100};
for (int x : scores) cout << x << " ";
cout << endl;
cout << "最高分:" << *max_element(scores.begin(), scores.end()) << endl;
// 2. std::string 演示
cout << "\n=== std::string ===" << endl;
string greeting = "Hello";
greeting += " C++";
cout << greeting << ",长度:" << greeting.length() << endl;
cout << "子串:" << greeting.substr(0, 5) << endl;
// 3. std::vector 演示
cout << "\n=== std::vector ===" << endl;
vector<string> names;
names.push_back("张三");
names.push_back("李四");
names.push_back("王五");
for (const auto& name : names) cout << name << " ";
cout << endl;
system("pause");
return 0;
}十、总结
恭喜你!现在你已经拿下了批量存储数据的基本技能。
快速回顾:
· C风格数组:固定大小、连续内存、下标从0开始、容易越界
· std::array:C风格的安全升级版,固定大小但不退化指针
· 多维数组:数组的数组,参数传递时除第一维外都要指定大小
· C风格字符串:以'\0'结尾的字符数组,提供操作函数
· std::string:现代C++首选,自动管理、支持+拼接、==比较
· std::vector:动态数组,随时增减元素
· std::string_view:C++17,轻量级只读字符串视图
思考题:
- 为什么C风格数组作为函数参数时,往往还需要传一个"大小"参数?
- "Hello"这个字符串字面量实际占用几个字节?为什么?
- std::string可以直接用==比较内容,那char\[\]可以吗?如果可以,它比较的是什么?
- 在什么场景下你会选择std::vector而不是std::array?
- std::string_view和std::string的区别是什么?
下一篇文章,我们将学习C++的函数------如何把代码组织成一个个可以重复使用的"功能模块",让程序结构更清晰。到时候你会发现,main函数只是整个程序的"总导演",精彩的戏都在你自己写的函数里!
------ 一个曾经因为数组越界而让程序"乱码乱飞"的C++学习者
------------------呵呵哒------------------
家人们真的很感谢你们的支持,有幸刷到我的文章也是一种不可磨灭的缘分,我还只是个命苦的学生,如果你的手指还没有残废的话麻烦点一下点赞+收藏+关注(让我不解的是为什么有的人点了赞却不收藏),或者随便评论一下也行(能给双方加积分)。我的专栏里还有很多有趣的内容,呃如果不想买的话可以看里面的试读文章(我真的好良心,一堆试读的),我也会不断更新,当然买下来我会大大滴感谢泥,真的想赚点零花钱呜呜呜T_T