MiMo-V2.5-Pro
概览
MiMo-V2.5-Pro 是目前小米自研 MiMo 系列中能力最强的一代,在通用智能体(agentic)场景、复杂软件工程任务以及长程推理任务上,相比上一代 MiMo-V2-Pro 有大幅提升。
模型已经在小米 API 平台与 AI Studio 等产品全面开放公测,开发者只需要把模型名称替换为 mimo-v2.5-pro 即可直接接入,无需额外适配成本。
在内部测试中,MiMo-V2.5-Pro 能稳定执行跨越上千次工具调用的长链路任务,同时在指令遵循和超长上下文一致性方面表现突出,适合作为各种"智能体框架"的核心大脑。
设计目标与模型定位
官方将 MiMo-V2.5-Pro 的设计目标概括为"Built to Solve Harder",也就是专门为更难、更长程、更开放的问题而设计。
与只面向对话或单轮问答的传统模型不同,MiMo-V2.5-Pro 被明确定位在"有工具、有代码、有长流程"的复杂环境中,强调与外部工具链、代码仓库、仿真环境等协同工作。
因此,它更适合挂载在 Claude Code、OpenCode、Kilo 等 agent scaffold 或你自研的 RAG / Agent 系统之上,用来驱动多轮规划、代码迭代和自动化工程任务。
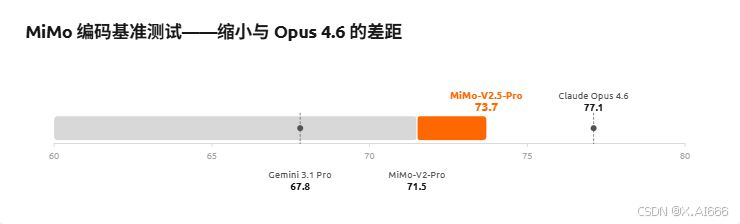
从第三方基准和官方数据来看,MiMo‑V2.5‑Pro 已经稳定站在全球第一梯队:综合智能位列全球前十,实际编码和 Agent 能力逼近 Claude Opus 4.6、GPT‑5.4 等 Frontier 模型,但在 Token 效率和价格上更有优势,是目前最具性价比的'国际顶级模型'之一。"
长程任务能力实例:从零写完一个 SysY Rust 编译器
官方给出的第一个代表性案例,是让 MiMo-V2.5-Pro 完成北京大学《编译原理》课程中的 SysY 编译器大作业,并要求用 Rust 从零实现:包含词法分析、语法分析、AST 构建、Koopa IR 生成、RISC-V 汇编后端以及性能优化等完整流水线。
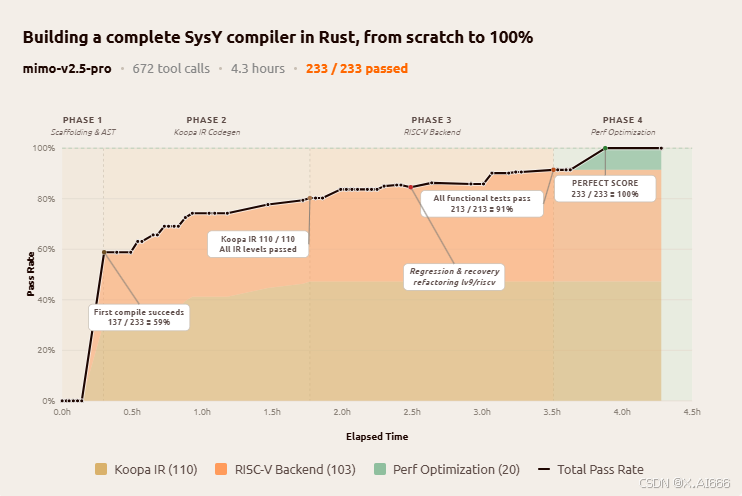
这类项目对于人类学生而言通常需要几周时间才能完成,而 MiMo-V2.5-Pro 在自动化工具链的配合下,用 672 次工具调用、约 4.3 小时就实现了从无到有的完整编译器,并在课程隐藏测试集上取得 233/233 的满分成绩。
从官方给出的曲线可以看到,模型不是"乱试一通"才凑出结果,而是先搭建整体架构,再逐层完善:先确保 Koopa IR 全部通过(110/110),再补齐 RISC-V 后端(103/103),最后才做性能优化(20/20)。
更加有意思的是,曲线中在第 512 轮附近出现过一次性能回退------重构导致 lv9/riscv 的两个测试回归,模型随后完成定位与修复后继续前进,这说明在长程任务中它已经具备一定程度的自我诊断与恢复能力。
模拟电路 EDA:自动设计并优化 FVF-LDO
第二个案例展示了 MiMo-V2.5-Pro 在模拟电路 EDA 领域的潜力:在 TSMC 180nm CMOS 工艺下,从零设计并优化一个 FVF-LDO(Flipped-Voltage-Follower 低压差线性稳压器)。
任务要求同时满足相位裕度、线性调整率(Line Regulation)、负载调整率(Load Regulation)、静态电流(Quiescent Current)、电源抑制比(PSRR)以及瞬态响应等多项指标,难度相当于一名具备经验的模拟电路工程师的毕业级课题。
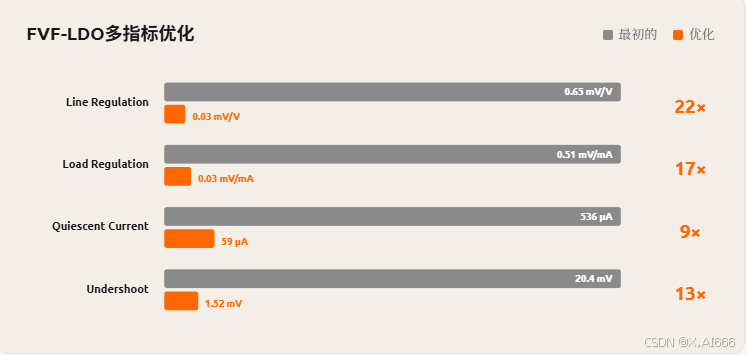
小米团队将 MiMo-V2.5-Pro 接入 ngspice 仿真闭环,并通过类似 Claude Code 的 harness 驱动模型"看波形---调参数---再仿真",在约 1 小时内得到一套所有指标达标、且关键指标相较初始设计提升一个数量级的最终方案。
官方给出的柱状图中,Line Regulation、Load Regulation、静态电流以及 Undershoot 等指标在"Initial"与"Optimized"之间有 9--22 倍不等的改善,这对于完全自动化的模拟设计流程来说具有相当的示范意义。
更重要的是,这个实验说明 MiMo-V2.5-Pro 在有"仿真器 + 脚本环境"的工程闭环里,可以表现出对工具环境的高度适配性:合理安排参数扫描、记录中间结果,并沿着梯度最明显的方向持续收敛。
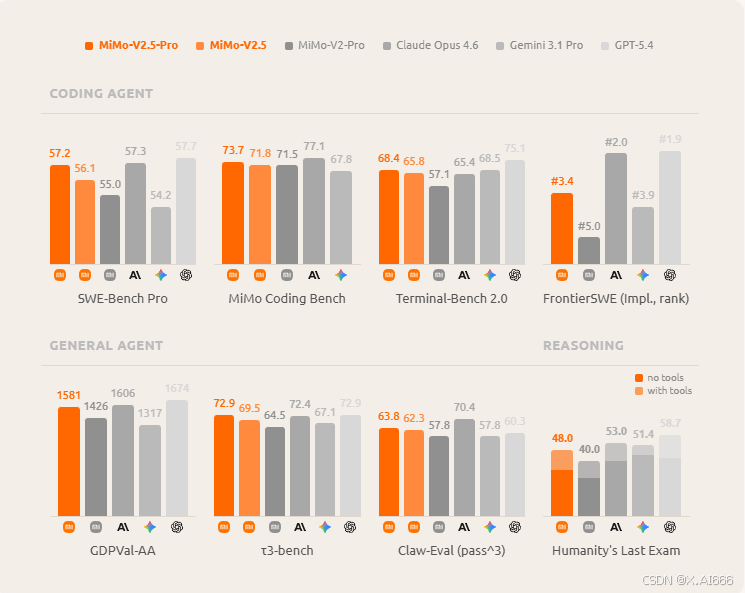
Frontier 级编码智能:MiMo Coding Bench & 多项榜单
小米自研的 MiMo Coding Bench 用于评估模型在 agent 框架下的编码能力,包括仓库理解、项目搭建、代码审查、规划与分解、软件工程任务等多个维度。
在这套基准上,MiMo-V2.5-Pro 与 MiMo-V2.5-Pro(带额外调优)在多个项目上已经逼近甚至追平 Claude Opus 4.6 等 Frontier 模型,同时在成本上更具优势。
从官方给出的柱状图可以看到:在 SWE-Bench Pro、MiMo Coding Bench、Terminal-Bench 2.0 等编码 agent 任务上,MiMo-V2.5-Pro 系列基本位于第一梯队;在 GDPVal-AA、t3-bench、Claw-Eval(pass^3)、Humanity's Last Exam 等通用/推理基准上也保持了接近 Frontier 模型的表现。
更关键的是,这些基准大多在"带工具"的场景下评测,反映的并不是纯语言能力,而是"看文档、调脚本、查日志、调用 API"这一整套开发工作流中的综合表现。
Token 效率:更省钱的 Frontier 能力
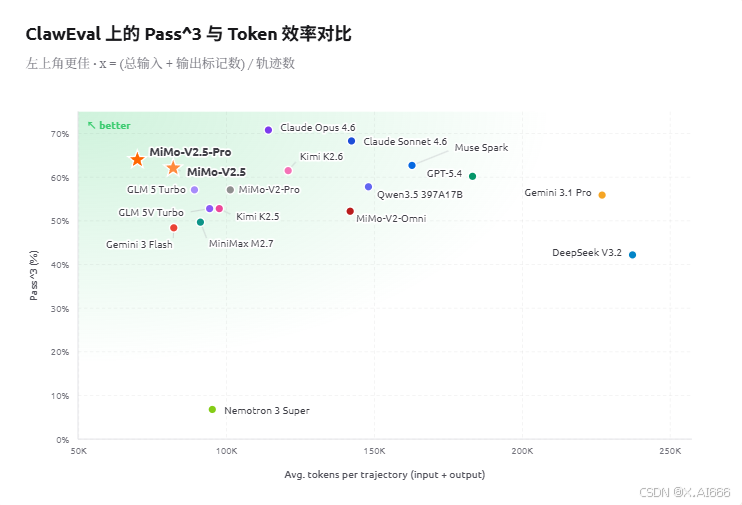
在 ClawEval pass^3 这一长程推理评测中,MiMo-V2.5-Pro 在约 70K tokens/trajectory 的平均开销下达到了 64% 的 pass^3 通过率,落点明显位于散点图的"左上角"。
这意味着在相近的任务完成度下,它比 Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4 等模型平均少用大约 40--60% 的 tokens,直接降低了长程 Agent 工作流的整体推理成本。
对于需要在生产环境中大规模运行的自动化脚本、智能客服、长链路数据清洗/标注流水线而言,token 效率往往比"最高分数"更关键,因为成本可控性决定了业务能否规模化落地。
如果你已经在自建多轮工具调用框架或复杂 RAG 系统,MiMo-V2.5-Pro 这种"高分 + 高性价比"的组合非常值得重点评估。
与前代 MiMo-V2-Pro 的差异
虽然官方页面没有给出逐项对比表,但从描述中可以推断出 MiMo-V2.5-Pro 相比 MiMo-V2-Pro 主要有三个方向的提升:
- 更强的 agentic 任务能力:在需要多轮规划、调用大量工具、维护长期记忆的场景下更稳定,出错后具备一定的自我诊断恢复能力。
- 更高的编码智能:通过增加后训练算力(post-training compute),在自家 MiMo Coding Bench 以及多项开源基准上都取得明显提升。
- 更优的 token 效率:在 ClawEval 等长程任务上,以更少的 token 达到与 Frontier 模型相近的成绩,从而降低大规模部署成本。
对于已经使用 MiMo-V2-Pro 的团队,升级到 V2.5-Pro 基本没有"迁移成本":只需要将模型名称改为 mimo-v2.5-pro 即可直接享受能力与效率的双重提升。
计费与 Token Plan 升级
MiMo-V2.5-Pro 在正式上线时,保持了与原有计划一致的定价策略,开发者无需额外支付溢价即可使用更强的新模型。
同时,小米对 Token Plan 做了一轮升级:在 4 月 21 日 14:00 UTC 之前已购买 Token Plan 的用户,其已用 Credit 会被重置,相当于白送了一轮"试用新模型"的机会,有利于大家在真实业务里大胆压测。
即将开源:对生态的潜在影响
官方已明确表示,MiMo-V2.5 系列将"即将正式发布并开源"。
如果最终开源的模型维持接近当前展示的能力,那么对于中文社区尤其是国内自建 Agent 框架、RAG 系统和企业级自动化流程,将是一个非常重要的基础设施级补全。
开源意味着:可以在本地或私有云环境中部署高能力模型,降低数据出境与隐私合规风险;同时,社区可以围绕模型进行二次微调、评测与工具生态建设,形成正向循环。
适用场景与实战建议
结合官方页面的多个案例,可以初步给出 MiMo-V2.5-Pro 的适用方向建议:
- 复杂软件工程与代码智能体:如自动搭建项目脚手架、对接 CI/CD 流水线、自动修复测试用例、构建内部工具等。
- 工程闭环中的优化任务:例如 EDA 仿真优化、参数搜索、自动调参与实验设计等,前提是你能提供一个稳定可调用的"仿真/评测器"。
- 长链路业务流程自动化:调用数据库、第三方 API、消息队列等,在几十到上千个 step 中保持目标一致性与上下文连贯性。
- 高性价比长程推理:在需要大量 Agent episode 的场景中,以较低 token 消耗获得接近 Frontier 的推理能力。
如果你正在构建自己的 RAG + Agent 系统,可以考虑优先在以下几个维度对 MiMo-V2.5-Pro 做压力测试:
- 长对话/长文档上下文稳定性:测试在 100K 级 token 上下文里的指令遵循与引用精准度。
- 多工具协同:设计 3--5 个工具组合的任务,看模型是否能主动选择合适的调用顺序。
- 错误恢复能力:故意制造失败的 API 返回或编译错误,观察模型是否能复盘并修正。
- 成本曲线:统计在相同任务完成率下,各模型的平均 token 消耗,重点对比 MiMo-V2.5-Pro 与现有方案。
总结
综合官方提供的编译器、EDA、视频编辑器等案例,可以看出 MiMo-V2.5-Pro 的核心优势集中在"长程 Agent 能力 + 高编码智能 + 优秀 token 效率"这三个维度。
对于希望在生产环境中大规模部署智能体、自动化脚本或复杂 RAG 工作流的团队,这一代 MiMo 模型提供了一个兼顾能力与成本的新选项,值得在下一轮架构升级中重点评估与引入。