Actor-Critic 本质上是结合了基于策略 (Policy-Based)和基于价值(Value-Based)两种方法的优点。
想象一个杂技演员(Actor)在表演,旁边有一个评论家(Critic)在观看:
-
Actor(演员) :负责决策。它学习一个策略 π(a∣s),决定在某个状态下应该采取什么动作。它的目标是表演得更好,获得更多的掌声(累计奖励)。
-
Critic(评论家) :负责评价。它不直接做决策,而是学习一个价值函数(通常是状态价值 V(s)或动作价值 Q(s,a)。它的作用是给 Actor 的每一个动作打分,告诉 Actor:"刚才那个动作做得很好,下次多往那个方向走" 或者 "刚才那个动作很糟糕,下次别这么做了"。
目录**:**
- The simplest actor-critic algorithm (QAC)
- Advantage actor-critic (A2C)
- off-policy actor-critic
- Deterministic actor-critic
一 The simplest actor-critic algorithm (QAC)

本节将介绍最简单的actor-critic算法。
策略梯度方法的核心思想是通过最大化一个标量指标 J(𝜃) 来搜索最优策略。用于最大化 J(𝜃) 的梯度上升算法为:
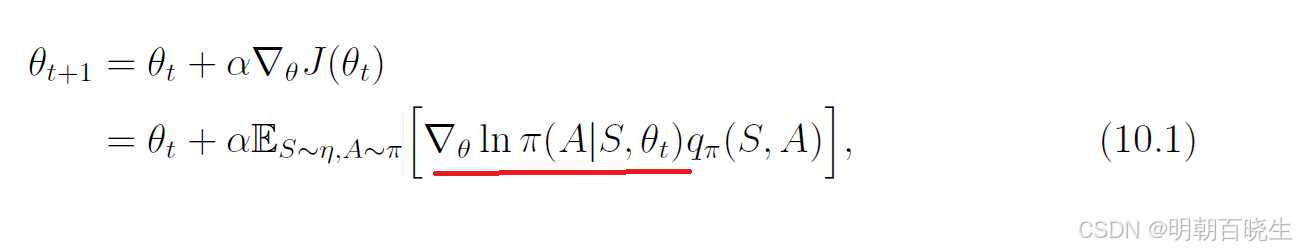
其中 η 是状态S分布。由于真实梯度未知,我们可以使用随机梯度来近似:
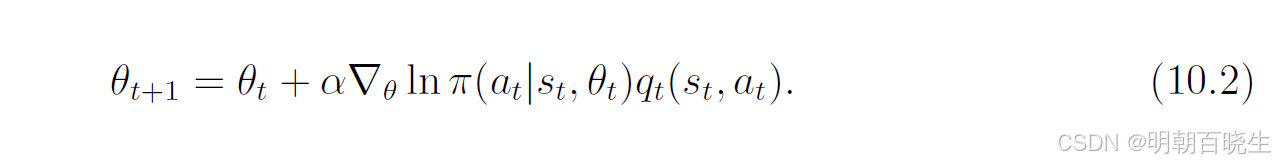
(10.2)非常重要,因为它清晰地展示了如何将基于策略的方法和基于价值的方法结合起来。
一方面,它直接更新策略参数,因此是基于策略的算法。
另一方面,该式需要知道 ,即对动作价值
的估计。因此,需要另一个基于价值的算法来生成
。到目前为止,本书已经研究了两种估计动作价值的方法:
第一种基于蒙特卡洛学习:
相应的算法称为 REINFORCE 或蒙特卡洛策略梯度
第二种基于时序差分学习:
相应的算法通常称为actor-critic 算法。因此,将基于时序差分的价值估计融入策略梯度方法中,就可以得到actor-critic 方法。
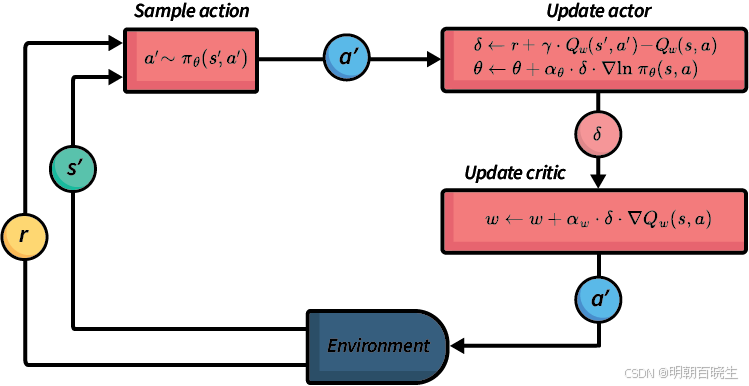
最简单的actor-critic 算法的流程总结在算法10.1中。
critic 对应通过式(8.35)中给出的Sarsa算法进行价值更新步骤,其中动作价值由参数化函数 q(s, a; w) 表示。actor对应式(10.2)中的策略更新步骤。这种actor-critic 算法有时被称为Q actor-critic (QAC)。尽管它很简单,但Q actor-critic (QAC)算法揭示了演员-评论家方法的核心思想。
二 Advantage actor-critic (A2C)

A2C 算法的核心思想是引入基线 来减小 policy gradien 估计方差。
1 关键性质:baseline 不改变期望,基线的数学期望为0

2. 加入baseLine 为什么方差变小
policy gradien 原始问题,利用梯度上升算法求其最大值,
公式A,S 都是随机变量,我们需要通过随机采样来实现,但是随机采样的方差很大。
设原始随机变量为
其中
加上baseline 之后
方差公式
因为前面证明过 所以
公式(1)
可以看做关于b的函数,求最小值,
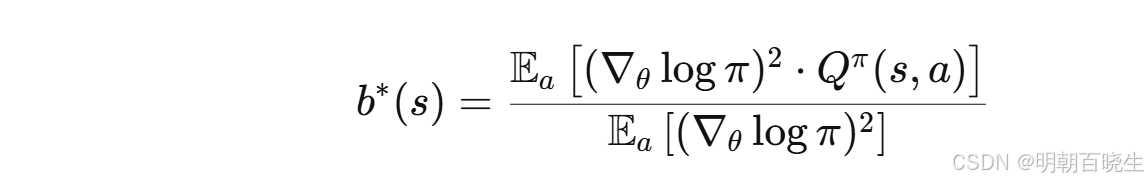
把上面最优解带入上面公式
所以方差是降低的,实际中经常,因为
3 优势函数
原始的形式
所以只要一个网络就可以了