0.Overview
终于来到了最后一个实验,本次 project 我们要在 project#3 的基础之上实现并发控制协议。
比较奇怪的是和之前的 project 比起来,project#4 文档的质量感觉有所下降,而且读起来和推理小说似的,具体需求还要我自己猜。
众所周知,事务(Transaction)是一个 DBMS 最基本的数据操作单位,任何一个事务都包含了一系列操作组成的序列。
根据事务的定义,事务必须满足四个性质:ACID;即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),具体细节可以在互联网上检索公开资料了解,这不做更多赘述。
所谓的并发控制协议,就是在假设所有事务都是并发运行的情况下,遵循该协议的事务的并发操作结果能够对应到某一个全局串行执行顺序。
非常有意思的是,事务的全局串行执行顺序概念实际上与 C++ 内存序模型中的全局操作顺序有着异曲同工之妙。
也就是说多个事务即使是同时运行的,我们要求它们在运行后产生的持久化结果,必须能够对应上某个按照某种顺序排列这些事务、然后一个接一个运行它们的结果。
为了形式化这一需求,sql 标准定义了事务的四种隔离等级:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)以及串行化(Serializable)。
其中读未提交就是不对事务做任何约束,它们爱读什么读什么,因此这种隔离等级下的事务并发执行顺序一般不可能对应任何有效的全局串行执行顺序。
比较有趣的是,读已提交和可重复读在相当多的 MVCC DBMS 实现中是等价的。
但严格来说,读已提交会让事务看到未来的数据:假设有事务 A 正在访问某张表,且 A 已经读完了表上的所有数据,现在有一个事务 B 对这张表做了若干修改并提交,那么在 B 提交后 A 再次读这张表,就会导致之前看到的数据发生了变化(也就是事务间的隔离性被打破了)。而可重复读不允许这种情况发生。
最后串行化是最严格的隔离等级,它要求所有并发执行的事务必须严格对应一个唯一等价的全局串行执行顺序。
所以到底什么是"全局串行执行顺序"?例如我们有一个医院值班表:
| 医生 | 值班 |
|---|---|
| Alice | false |
| Bob | false |
| Charlie | false |
| Dave | false |
假设有两个人分别检查今晚整个医院是否有人值班,如果没有就随机指派某位医生;因此我们发起了两个事务 T1 和 T2。
假设事务看不到未来的修改,也就是可重复读,我们可以得到其中一个可能的并发执行操作(无序的):
- T1 扫描全表,发现没人值班,因此 T1 随机抽中了 Alice
- T2 扫描全表,发现没人值班,因此 T2 随机抽中了 Dave
因此这两个事务在提交后,值班表会变成下面这样:
| 医生 | 值班 |
|---|---|
| Alice | true |
| Bob | false |
| Charlie | false |
| Dave | true |
尽管 T1 和 T2 是并发甚至可能是并行运行的,但它们完全等价于两个全局串行执行顺序:
- 先执行 T1,然后再执行 T2。
- 或者先执行 T2,然后再执行 T1。
因此这两个事务的并发执行等价于某一个全局执行顺序,也就是所谓的"冲突可串行化"。
不可串行化冲突是指发生了 data race,这类冲突的并发执行顺序不可能对应任何一个全局执行顺序。
但这两个事务绝对不满足串行化,因为这里出现了两个全局串行执行顺序;假设这间医院只需要一个人值班,这两个事务的执行结果就是不正确的(即使没有读写冲突)。
当然,事务的隔离等级支持不是天上掉下来的,我们还是要回到并发控制协议中。
在 DBMS 的发展过程中,业界出现了多种并发控制协议,但随着时间推移,基于多版本快照的并发控制协议逐渐占据了主流,这些控制协议包括:
- 基于时间戳排序的 MVTO
- 乐观并发控制 MVOCC
- 两阶段锁 MV2PL
- 串行化证明 Serialization Certifier
这些协议无一例外都可以被归类为 MVCC,因此实际上 MVCC 并没有一个相对标准的实现;同时这些协议在不同的工作负载下有非常不同的性能表现。
我们要实现的并发控制协议实质上是 MVOCC 的一个变种(其实就是一种简化版本)。
1.Task#1 - Timestamps
在 project#3 的 Insert 算子中我们已经了解过,BusTub 的 TupleMeta 中包含了一个 timestamp_t 类型的 timestamp,这个时间戳代表了对应的 Tuple 被创建、被修改的时间。
1.1 Timestamp Allocation
虽然名字叫时间戳,但它与本地系统时间完全无关。实质上 BusTub 的所有 timestamp 都有一个唯一的来源:TransactionManager::last_commit_ts_,这个 timestamp 会在每个事务提交时向前步进 1;每个事务创建时也会被分派一个创建时所能看到的 last_commit_ts_ 值作为 read_ts_。
因为每个 Tuple 都记录了一个 timestamp,事务在访问某个 Tuple 时就可以根据它的 read_ts 检查这个 Tuple 是否在事务的能见范围之内;换言之,事务可以通过简单的大小关系比较判断是否读取到了一个未来插入、或者正在被其他事务修改的数据,然后决定是否让这个数据参与当前数据查询操作。
总之 Task#1.1 其实很简单,我们只需要在 TransactionManager::Begin 和 TransactionManager::Commit 里面补充 read_ts_ 的赋值和 last_commit_ts_ 的递增逻辑。
而且因为变量是原子量,我们可以分别选择 relaxed 和 release 内存序,而不必总是用 seq_cst。
1.2 Watermark
Watermark 用于追踪全局活跃事务中最小的 read_ts_。
实际上我们可以非常简单的用 std::map 追踪,这种做法的最优和最差时间复杂度都是 O ( l o g N ) O(logN) O(logN);但文档非要说参考实现用了一个均摊 O ( 1 ) O(1) O(1) 的操作,这就不得不挑战一下了。
实际上手动维护一个 heap 更合适,因为在缓存命中率上,一个连续数组里的二叉树会比红黑树要好。
所谓均摊 O ( 1 ) O(1) O(1) 一定离不开哈希表,也就是用一个 std::unordered_map<timestamp_t, size_t> 记录每个 timestamp 的引用计数,这样我们总能在 O ( 1 ) O(1) O(1) 时间内更新某个 timestamp。
但只有哈希表我们是找不到全局最小 timestamp 的,所以我们要额外维护一个 std::deque<timestamp_t>,每个新 timestamp 会同时加入到哈希表中和 deque 的队尾,但是调用 RemoveTxn 时我们不会在某个 timestamp 的引用计数归零、从哈希表内弹出时一并移除 deque 的对应项。
相反,只有当调用了 GetWatermark() 的时候,我们才检查 deque 的队首元素是否仍在哈希表中,如果不存在就弹出,循环直到 deque 变空或者 deque 的队首元素仍在哈希表中,此时我们要么返回记录的 commit_ts_,要么成功找到一个全局最小的 timestamp。
这种做法能成立的核心原因在于 timestamp 总是单调递增,因此 deque 存储的 timestamp 一定满足从队首到队尾的严格单调递增。
1.3 测试
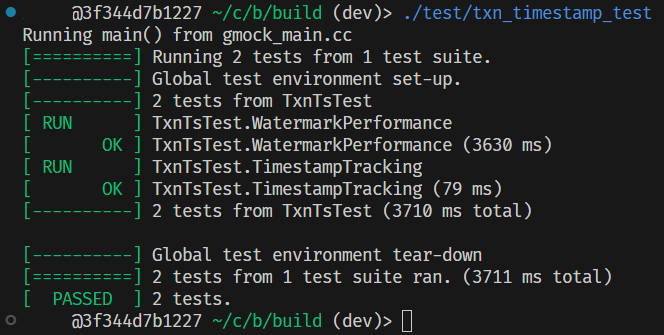
2.Task#2 - Storage Format and Sequential Scan
我们需要改写 project#3 实现的五个数据访问和修改算子:SeqScan、IndexScan、Insert、Delete 和 Update,使得它们能够支持 MVCC 机制。
BusTub 的存储策略是 STEAL + NON-FORCED(详见课程讲义),因此 TableHeap 永远只存储每个 Tuple 的最新版本,而所有过往历史版本都以 UndoLog 的形式分别存储在所有修改了这个 tuple 的事务对象里,即 Transaction::undo_logs_;而且每个事务至多持有同一个 tuple 的一个 UndoLog,这使得任意一个 tuple 的版本链会同时跨越多个 transaction。
同时 TransactionManager 在 PageVersionInfo 类型里用 UndoLink 登记了每个 tuple 的次新版本(也就是最新版本的上一个版本)位置,实质上就是版本链的开头。
特别有趣的是,
PageVersionInfo是按 page 为单位登记UndoLink的,这是因为我们查询某个 tuple 的版本链开头时,总是拿着 tuple 的唯一标识符类型RID发起检索,而这个类型记录的是某个 tuple 所在的 page 页号以及页内偏移量。
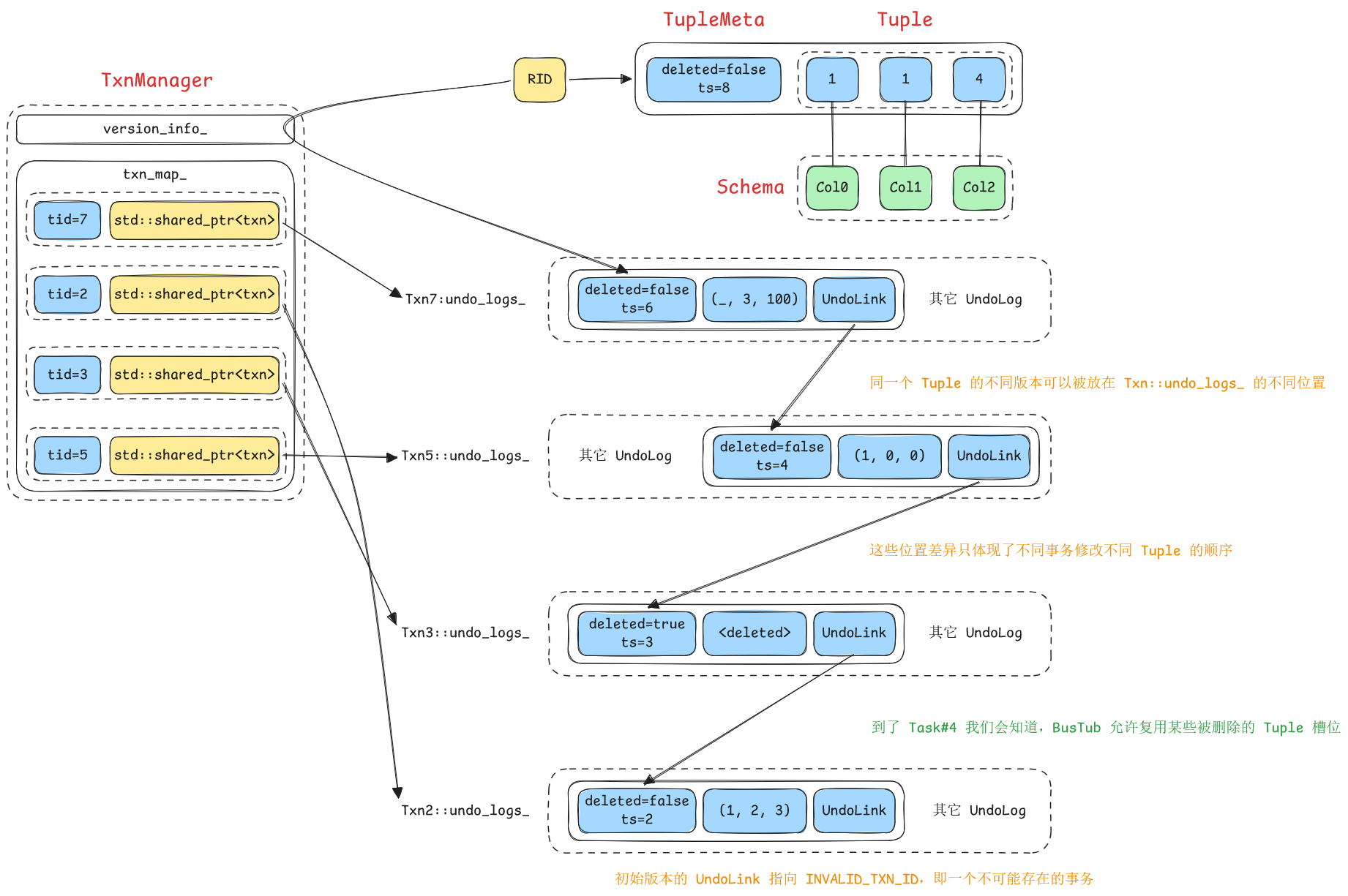
txn_map_是一张哈希表,所以图例有意设计成了乱序存放。
上图演示了 BusTub 组织每个 tuple 不同版本的方式,以及要如何查找到某个 tuple 版本链的开头。
2.1 Tuple Reconstruction
接下来我们就需要实现遍历版本链回溯 tuple 数据的函数 ReconstructTuple。
writeup 已经写得相当清晰了,由于 BusTub 记录的 UndoLog 是差量更新形式,每个 log 内部的 tuple 数据实际上是不完整的,我们要在每次构建一个版本时都重复构造一个能够解析当前 tuple 的 Schema。
而且不难注意到,如果传递进来的 undo_logs 为空,且最新版本已经被删除(base_meta 的 is_deleted_ 为 true)我们可以直接返回一个 std::nullopt 表示版本不可见;而 undo_logs 为空但是没有被删除则可以直接返回 base_tuple 本身。
另外值得注意的是,如果 undo_logs 的末尾元素的 is_deleted_ 字段为 true,很容易想到即使我们沿着参数提供的版本链向上回溯,最终也会因为这个 deleted 标记导致结果不可见,因此这种情况我们也可以返回 std::nullopt。
更有趣的是这种 is_deleted_ 为 true 的 log 还可以出现在版本链中间甚至开头。
这种 log 是不包含任何 tuple 列的,因为它只表示对应的 tuple 在某个版本不可见。
正如之前的图例指出的一样:BusTub 会复用某些被删除的 tuple 的物理槽位,因此这个位置上的 tuple 历史可以存在多次 deleted 标记;根据差量更新机制,每次删除 tuple 后事务都需要全量记录当时 tuple 的全部数据,因此我们回滚的过程中必然会导致 delete 之后的数据被之前的全部覆盖,也就是多做了无用功。
所以我们可以查找 undo_logs 里最后一个 is_deleted_ 为 true 的历史,从这个版本开始回溯,这样可以跳过大量无意义的计算。
2.2 Sequential Scan (Tuple Retrieval)
有了重构 tuple 到指定版本的手段,我们还要再实现收集 UndoLog 的函数 CollectUndoLogs,然后我们就可以实现第一个 MVCC 算子:SeqScan。
BusTub 采用了一个比较取巧的设计,用以标记某个 tuple 是否正在被某个事务修改。
具体来说,BusTub 的每个事务的 id 类型与 timestamp_t 是相同的,即都是 int64_t;而事务的起始 id 会从一个固定常量 TXN_START_ID(即 1L << 62)而不是从 0 开始递增。
并且 BusTub 定义了无效 timestamp 为一个固定常量 INVALID_TS(即 -1),而有效的 timestamp 从 0 开始递增(也是 last_commit_ts_ 的初始值)。
这样做的目的,是让每个 TupleMeta 的 ts_ 字段事实上成为这个 tuple 的一个 ownership flag,或者说叫做行级锁。
而自旋锁正是一种乐观互斥手段,所以我们实现的是一种 MVOCC 协议。
什么意思呢?也就是说当一个事务尝试修改一个 tuple、或者尝试插入一个 tuple(我们都把它们叫做"写入")时,如果事务的写入尝试成功了,那么事务必须把 TupleMeta 的 ts_ 字段替换为自己的事务 id,并且在提交的时候将这个字段重新覆写为提交过程中取得的 commit timestamp。
之所以说这种设计很取巧,是因为我们可以利用数值比较快速判定一个 tuple 是否可见。
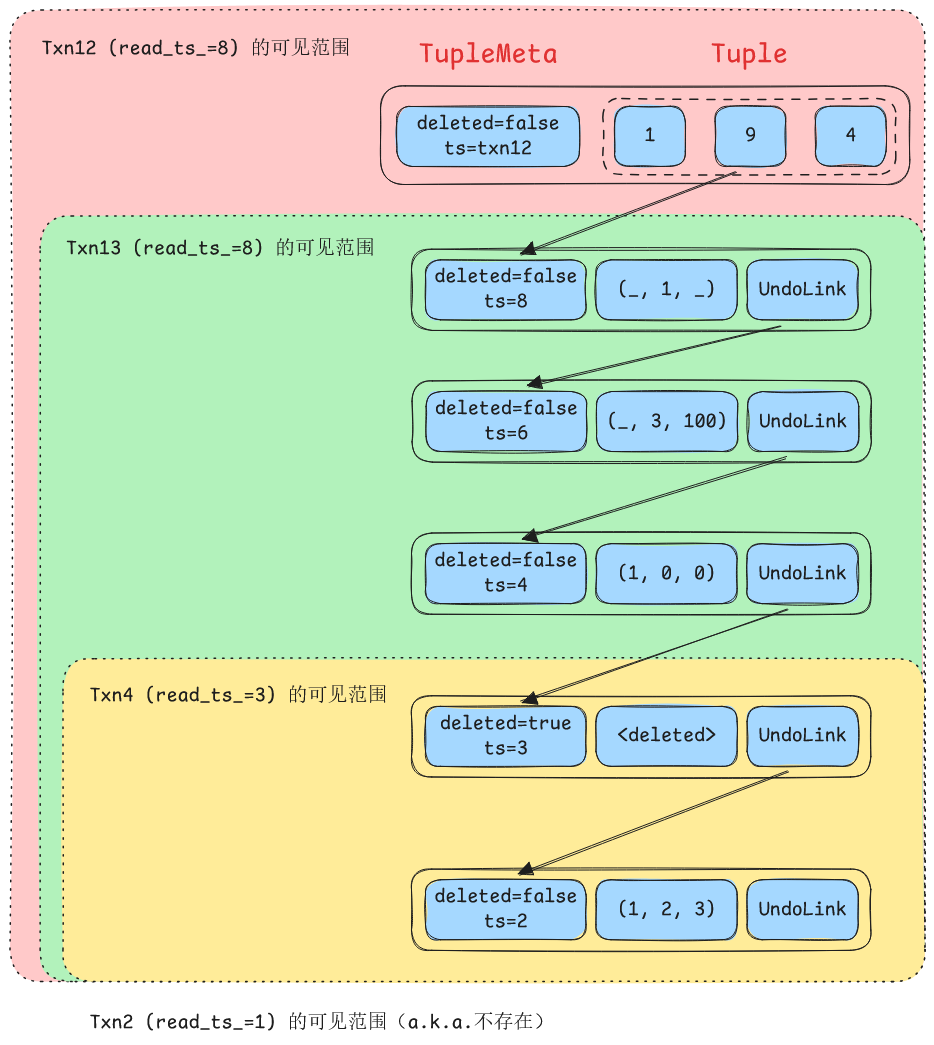
如上图所示,table heap 中最新版本的 ts_ 字段被替换为了事务 Txn12 的 id,因此这个 tuple 正在被修改,除了 Txn12 本身以外,其他任何事务都不应该看到这个版本的数据。
对于其他历史,任何事务只能看到 ts_ 小于自己 read_ts_ 的版本。虽然图示演示的是所有过往版本都对这类事务可见,但实际上我们只关心这些历史里最新的那一个。
因此在可见性上,Txn4 和 Txn2 都看不到这个 tuple 的存在。因为对于 Txn4 来说,在它的历史上这个 tuple 已经被删除;对于 Txn2 来说,这个 tuple 创建发生在未来。
显然,可见性与 txn->read_ts_ >= meta.ts_ 这个表达式的结果有关。而由于事务 id 从一个非负的整数 TXN_START_ID 开始递增,因此任何事务 id 都绝对大于每个事务的 read_ts_,这在判定方式上与刚刚给出的表达式是同构的。
我们不考虑溢出问题,
int64_t的整数空间的大小足够用到天荒地老了。
我们再来谈 CollectUndoLogs 的实现。和 ReconstructTuple 有一个非常相似的地方在于,在收集阶段如果我们遇到了一个 is_deleted_ 为 true 的 log,我们可以丢弃掉过往收集的所有版本并从这个版本开始重新收集。
原因已经说过了,我们在这里重新实现这个优化的好处是可以让 ReconstructTuple 本身更纯粹,而且产生的中间数据量会更少。
注意 CollectUndoLogs 需要检查当前 tuple 是否对某个事务可见,然后再决定要不要遍历版本链;别忘了如果 tuple 被同一个事务修改了,这个 tuple 是始终对该事务可见的。
最后我们要(部分地)重写之前实现的 SeqScan 算子,现在我们要调用 BusTub 提供的原子性接口 GetTupleAndUndoLink 同时获取最新版本的 tuple 以及 UndoLink,然后传给 CollectUndoLogs 并根据返回值决定当前事务能否看到这个 tuple。
顺便一提 writeup 莫名其妙在这里提了一嘴要处理 NULL 数据,但实现过程中完全没发现这有什么要特殊处理的地方。
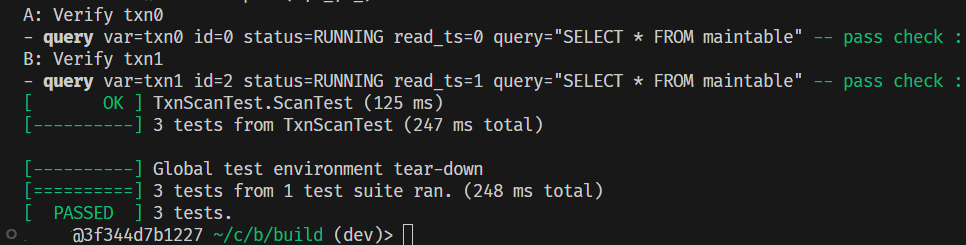
2.3 测试
p4 的测试用例总是会输出一大堆日志,虽然方便 debug 但是对截图不太友好,所以只截取了最后一段测试汇总报告。
3.Task#3 - MVCC Executors
接着我们要彻底重写 project#3 实现的 Insert、Delete 和 Update 算子。
在此之前,必须先抨击一下 BusTub 提供的一个原子性 CAS 函数:UpdateTupleAndUndoLink。
默认提供的 UpdateTupleAndUndoLink 不能用在 MVCC executor 的 tuple 更新中,这是因为 Tuple 的 ts_ 实质上是一个事务间的自旋锁,自然任何适用于自旋锁的更新规则也同样适用于 Tuple,在没有宣称占用之前获取的任何 UndoLink 不保证满足某个全局执行顺序。
但非常不合理的是,UpdateTupleAndUndoLink 要求我们先必须拿到一个 UndoLink 再同时更新 Tuple 和 UndoLink,这导致了我们拿到的 UndoLink 总是有可能过时的,而且在高并发下存在严重的 ABA 问题。
具体来说,在 executor 中调用 UpdateTupleAndUndoLink 会有这样一个 race condition:
有两个需要修改同一个 tuple 的事务 A 和 B,事务 A 成功修改了某个 tuple 并即将修改其他 tuple,但是 A 所在的线程暂时因为系统调度等原因被挂起暂停执行。
现在事务 B 开始修改刚刚被修改的 tuple:B 先获取了 UndoLink,然后马上 A 继续执行,且 A 因为其他修改发生了 write-write conflict 失败并回滚所有修改。再回到事务 B,B 尝试修改刚刚回滚的 tuple 并调用 UpdateTupleAndUndoLink 做 CAS 成功。
问题就来了,事务 B 在 CAS 时拿着的是刚刚被回滚的 UndoLink,B 没能看到 A 的回滚现象导致错误地恢复了本该消失的 UndoLink。因此构造 UndoLink 必须晚于拿到 tuple 的访问权,即更新了 tuple 之后。
那么我们调用 TableHeap::UpdateTupleInPlace 和 TxnMgr::UpdateUndoLink 保证抢占了 tuple 的独占所有权之后再更新行不行?毕竟这两个方法依然是原子性的。
答案是不行,因为这存在着一个 TOCTOU(Time-Of-Check-to-Time-Of-Use)问题:
同样有两个修改同一 tuple 的事务 A 和 B,事务 A 调用 UpdateTupleInPlace 成功,然后 A 所在线程因为调度问题被暂时阻塞,事务 B 开始读取刚刚被修改的 tuple 以准备修改,现在 B 能看到 A 刚修改的 tuple 但看不到 A 的 UndoLink(因为还没写入)。
因为 B 发现拿到的 tuple 正在被其他事务修改,所以尝试根据拿到的 UndoLink(指向版本链开头)准备回溯,然后返回这个历史 tuple。问题出现了,事务 B 在回溯时拿到的 UndoLog 是 A 修改之前的,但是基准 tuple 又是 A 修改过的,这显然会导致错误的回溯。
之所以会错误回溯,是因为版本链内的
UndoLog不记录当前版本所属 timestamp 之外的任何信息。
我们再构想一个场景,如果 executor 硬是要用 UpdateTupleAndUndoLink 会怎么样:
依然有两个修改同一 tuple 的事务 A 和 B,事务 A 在调用 UpdateTupleAndUndoLink 之前,先调用 GetTupleAndUndoLink 获取了 tuple 的最新版本,然后在它之上再做修改并生成 UndoLink,接着用这些参数调用 UpdateTupleAndUndoLink,假设 A 成功。
到事务 B,B 同样 GetTupleAndUndoLink,获取了最新版本做了修改并且准备 CAS,此时事务 A 发生错误并回滚,等到事务 A 执行了 TxnManager::Abort() 之后事务 B 再继续执行;现在事务 B 在 CAS 时看到的最新版本不包含 write-write conflict,但事务 B 的新数据是基于一个本该回滚的 tuple 数据产生的,因此又导致了 B 创建的 UndoLog 指向不该存在的版本。
当然这一点可以要求事务 B 每次 GetTupleAndUndoLink 之后立即回滚数据到它可见的版本从而避免,但这样我们构造了多次冗余计算:
- 首先是
GetTupleAndUndoLink,事务 B 的下层 executor 已经返回了一个当前可见的 tuple,但 B 又重复获取了一次; - CAS 时事务 B 同样要拿到最新的 tuple,不过这一次是不可避免的;
- 下层 executor 已经回滚了数据到唯一可见的版本,但事务 B 调用
GetTupleAndUndoLink后又需要回滚一次。
这里的复杂度显然不是正常算子能够接受的,所以依然需要在锁保护之下构造 UndoLink,而不是手动回滚版本。
综合以上三个场景,不难看出 BusTub 提供的 UpdateTupleAndUndoLink 是一个在 MVCC Executor 层面不可用的接口(但是可以用在 TxnManager::Abort() 当中);为了解决这个问题,我自己写了一个真正满足 CAS 语义的接口:
cpp
template <typename C, typename B>
auto UpdateTupleWithUndoLink(TransactionManager *txn_mgr, RID rid, TableHeap *table_heap, TupleMeta meta,
const Tuple &tuple, C &&checker, B &&builder)
-> std::optional<std::pair<TupleMeta, std::optional<UndoLink>>> {
auto page_write_guard = table_heap->AcquireTablePageWriteLock(rid);
// UpdateTuple
auto page = page_write_guard.AsMut<TablePage>();
auto [base_meta, base_tuple] = page->GetTuple(rid);
// 由于我们不需要默认参数,改传递 lambda 以提高内联可能性
if (!checker(base_meta, base_tuple)) {
return std::nullopt;
}
// Update tuple and tupleMeta if pass in tuple and meta are different
if (meta != base_meta || !IsTupleContentEqual(tuple, base_tuple)) {
table_heap->UpdateTupleInPlaceWithLockAcquired(meta, tuple, rid, page);
}
auto prev_link = txn_mgr->GetUndoLink(rid);
txn_mgr->UpdateUndoLink(rid, builder(base_meta, base_tuple, prev_link));
return {std::make_pair(base_meta, prev_link)};
}基本上就是直接复制自 UpdateTupleAndUndoLink,但不同的地方在于我允许额外传递一个 builder 参数以在锁保护下构造 UndoLink,同时函数在更新成功后会返回先前版本的数据。
3.1 Insert Executor
回到正常实验。本节任务我们要实现一个满足 MVCC 协议的 Insert Executor。
从先前的图例可以看出,一个刚插入的 tuple 不应该有任何历史数据,因此 Insert Executor 不应该给刚插入的 tuple 任何有效、甚至是指向 INVALID_TXN_ID 的 UndoLink。
虽然之前的图例说了 BusTub 允许复用某些被删除的 tuple 槽位,但在 task#4 之前我们不用考虑这个问题。
成功 Insert 一个数据之后,我们还需要将本次变更的 tuple 的标识符 RID 加入到事务的写集合中,这样在提交的时候才能统一将被更改 tuple 的 ts_ 替换为提交时取得的 commit ts。
除此之外,由于 Insert 是一次写入操作,我们还要检查 Write-Write 冲突。也就是说当某个事务 B 在试图抢占当前 tuple 的最新版本时,如果它发现 tuple 已经被另一个事务写入、或者 tuple 的版本比事务 B 预料的要新(也就是发现了未来的数据),就需要中断本次事务(通过抛出一个异常)。
3.2 Commit
接着我们马上就来实现 Commit 函数,这个函数负责处理事务的提交,获取一个 commit timestamp 之后,把事务修改过的所有 tuple 的 ts_ 替换为这个 commit timestamp,最后递增 last_commit_ts_。
因为默认实现里每次进入 Commit 都拿着一把大锁 commit_mutex_,所以整个提交流程是严格串行的;其余没什么好说的,writeup 已经给好了伪代码,照着写就是。
然后在进入下一节之前,课程强烈推荐我们先实现一个 TxnMgrDbg,这非常有助于我们 debug,当然的确如此。
基本上这个函数就是遍历整张表,然后输出每个 tuple 的最新版本及其版本链信息,没什么特别复杂的地方,就是动态拼接字符串挺繁琐的。
但要注意两点,首先遍历 table heap 时应该获取的是 MakeEagerIterator() 返回的迭代器,否则可能无法看到所有 tuple 数据;其次因为 TxnMgrDbg 可能允许并发调度,函数应该被实现成:拼接了整个字符串之后再一次输出,因为这可以利用 IO 互斥性保证输出不被打断。
fmt::format_to + std::back_inserter 可能会很有用。
3.3 Generate Undo Log
UndoLog 的构造以及更新也是需要我们完成的;实现起来很简单,逐列比较 value 是否严格相等即可。
由于 Tuple 实际上使用了 std::vector 存储二进制数据,而 IsTupleContentEqual(这玩意居然是个友元)的比较逻辑是使用 memcmp 比较两个内存块数据。
众所周知,在现代平台上,两个连续内存块的相互比较可以享受向量化加速,同时它们也非常适合基于 cache 的访问模式,因此在生成和合并 UndoLog 之前我们可以先用 IsTupleContentEqual 实际比较两个版本的数据差异,然后再决定要不要更新 diff。
BusTub 不允许记录两次更新的最小 diff。也就是说如果一个 tuple 的某一列的初始值是 20,那么同一个事务如果产生了这样的更新序列:20 -> 10 -> 30 -> 20,GenerateUpdatedUndoLog 也必须标记这个列被修改,即使它的值并没有发生变化。
而且 GenerateUpdatedUndoLog 参数中的 base_tuple 实际上是已经发生修改的数据 ,也就是说 BusTub 只允许一个事务持有同一个 tuple 的至多一个 UndoLog,一旦这个 log 已经存在,后续对这个 tuple 的所有修改都需要合并到先前创建的 log 当中;因此 base_tuple 是当前事务所作修改的上一个版本。
3.4 Update & Delete Executor
有了以上组件支持,现在我们可以实现 Update 和 Delete Executor 了。
之前在 project#3 中,我们的 Update 是先删除后插入,现在我们可以真正实现原地更新的操作。
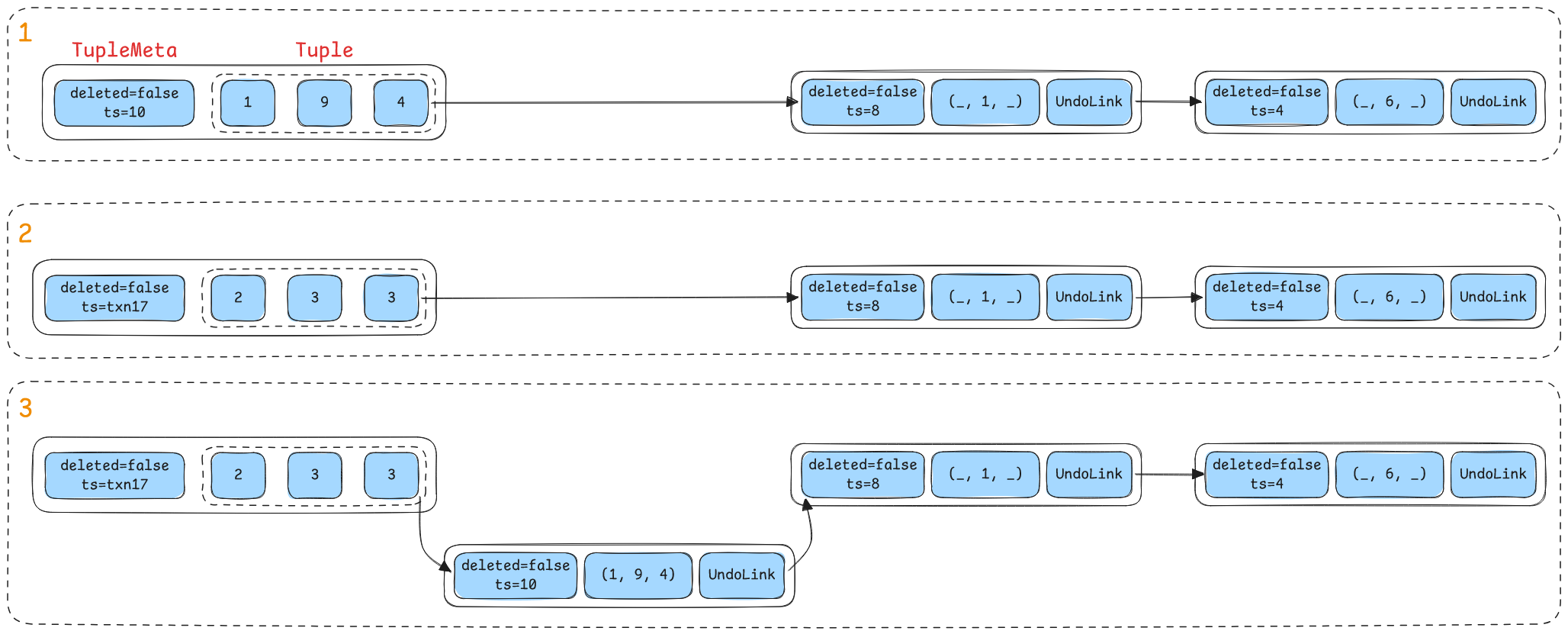
如上图所示,假设执行更新操作的事务是 Txn17;我们一开始已经指出了 UpdateTupleAndUndoLink 的问题,因此我们的 Update 实现采用的是 UpdateTupleWithUndoLink 更新,所以在执行顺序上与 writeup 的示例是不同的:我们先做 write-write conflict 检测,然后更新 tuple,在持有 tuple 的页级锁的情况下利用确定性的 UndoLink 数据构造并生成新的 UndoLink。
Delete 的实现实际上与 Update 基本相同,因为它们都调用的同一类接口,我们不需要关心 UndoLog 里面该写什么,我们只需要按照语义更新 meta 数据并作 write-write conflict 检测即可。
但我们必须处理一个特殊情况:一个 tuple 先被同一个事务插入,然后又被一个事务删除。这种情况下在 Delete 时最好把 TupleMeta 的 ts_ 标记为 0,代表一次 no-op。
当然也可以像正常删除一个 tuple 一样只打一个 deleted 标记,这也没问题。
3.5 Stop-the-world Garbage Collection
显而易见的是,我们不能任由 tuple 的版本链无限增长,我们必须定期删除掉一些不再可能用到的版本。
所谓"不再可能用到"的版本,指的是这些版本不再对任何未来事务造成影响。
从某一时刻开始创建的所有事务,我们对它们的可见集合取并集,然后去掉所有次新版本,如果以上操作结束之后我们依然能够收集到一些版本结点,那么这些版本就是不再对未来事务有任何影响的版本,任何事务向上回溯时都不会回溯到这里;也即所谓的不可达版本。
此时我们就要用上一开始实现的 Watermark,该类型追踪了全局活跃事务中最小的 read_ts(如果不存在活跃事务,则 read_ts 与 last_commit_ts_ 相等)。
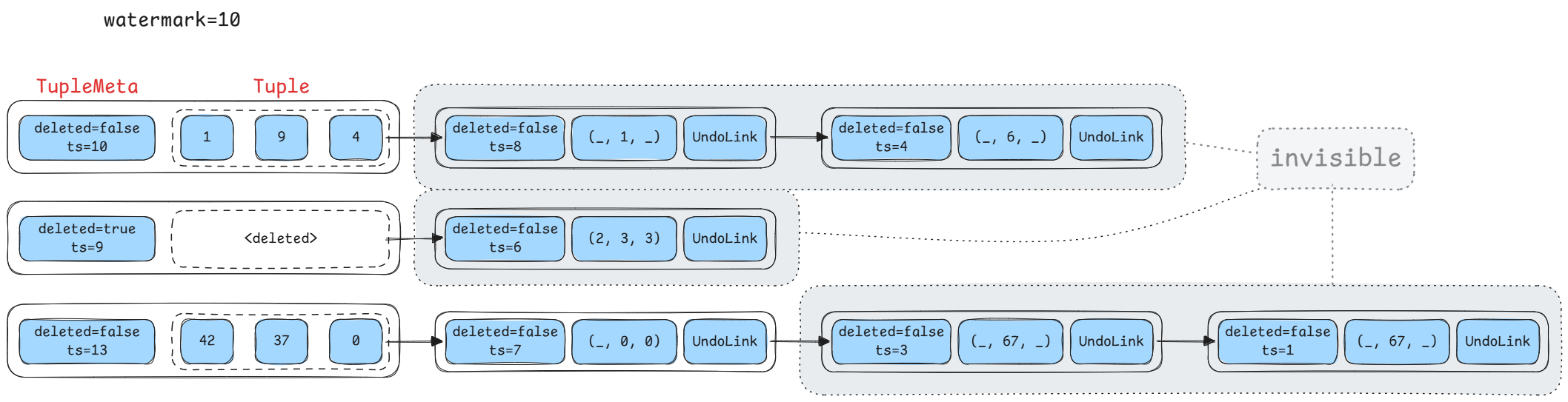
如上图,第一个满足 ts_ <= watermark 之后的版本全都是不可达的,但是第一个满足该条件的版本不是。
这是因为这个 STW 暂停的是所有运行过程中的事务的创建、提交和中止操作,而不是等待所有事务停止运行;在 GC 期间依然允许某些事务正在执行。
假设我们有一个 read_ts_ 为 11 的事务,从上图可以看出,这个事务能够看到 ts_ 分别为 10、9 和 7 的 tuple。
关键就在于这个 ts_ 为 7 的事务,很显然它的 ts_ 小于 watermark,但是仍然有事务能够且需要看到它,所以我们不能移除第一个满足该条件的版本。
另一方面,因为 UndoLog 被存储在每个事务自己私有 workspace 的一个 std::vector 对象中,而 UndoLink 由事务 id 和指向的 log 在事务中的偏移量构成,这导致我们绝对不能破坏 Txn::undo_logs_ 的结构,我们必须采用某种标记-删除实现。
其实就是一个
std::unordered_map<txn_id_t, std::unordered_set<size_t>>。
并且当标记数量等于事务的 log 数量时,将该事务从 txn_map_ 里移除。
由于可达性分析必须从最新版本开始沿着版本链检查,我们得在 GarbageCollection 里遍历 txn_map_ 记录的所有事务的 write_set_,这样做会比较慢。
一个优化思路是事务每次 Commit 时、在 txn_map_mutex_ 的保护下,总是主动登记自己本次执行修改了哪些 tuple,这样 GC 的时候就可以直接遍历已经缓存的列表,减少重复遍历。
3.6 Abort
最后我们要实现 Abort 函数。
奇怪的是往年的 Abort 和 GC 居然是 bonus task。
和 Commit 不同,进入 Abort 的事务已经被判了死刑,我们只需要回撤它所作的所有修改。
即遍历 write_set_、调用 UpdateTupleAndUndoLink(是的这里可以调用它),最后更新 TxnManager 的数据。
3.7 测试
4.Task#4 - Primary Key Index
此前我们实现的所有 MVCC 都只适用于 tuple 数据,而索引结构并没有受到保护。
4.1 Index Insert
我们需要进一步修改 Insert Executor 的实现,使得它可以在 MVCC 机制下不会导致索引的破坏性修改。
仅在这一环节,当我们插入一个已经存在的 tuple(通过索引检索)时,就需要抛出一个异常中断事务执行;否则再实际插入 tuple 到 table heap 里,然后再更新索引;如果更新索引时又发现 key 已存在,我们又需要抛出异常中断执行。
实际上我们可以总是先向 table heap 里创建 tuple,然后再尝试直接创建一个索引。根据我们在 project#2 实现的 B+ 树索引来看,任何重复 key 的插入都会返回一个 false,所以我们可以节省一次索引遍历。
做事乐观点。
4.2 Index Scan, Delete, & Update
IndexScan 的逻辑实际上与 SeqScan 是相同的,也就是加上了版本感知和 tuple 回溯的代码。但 Delete 不一样了。
因为索引结构本身没有版本链设计,而且我们记录的 UndoLog 是 tuple 的数值变更,而不是具体的数据操作日志,我们不可能在事务回滚后回撤它做过的所有对索引的变更操作。
所以现在在 Delete 时,我们不再把 key 从索引中删除,而是保持 key 指向一个被标记为 deleted 的 tuple;这也有利于未来重复插入某个键的时候复用这个 tuple 所在的槽位。
4.3 Primary Key Updates
writeup 说现在 Update 必须变成一个 pipeline breaker,也就是从下层算子加载所有数据,然后再更新。
这是因为如果 Update 修改了索引列,我们不能再破坏索引结构,必须将 Update 改写成标记原来的 tuple 为 deleted,然后再插入新的 tuple;也就是变成 Delete + Insert 的混合逻辑。
但仅仅把 Update Executor 改写为 pipeline breaker(也就是缓存所有需要更新的 tuple)还不够,我们不能一边标记原 tuple 已删除,一边向 table heap 中插入 update 后的数据。
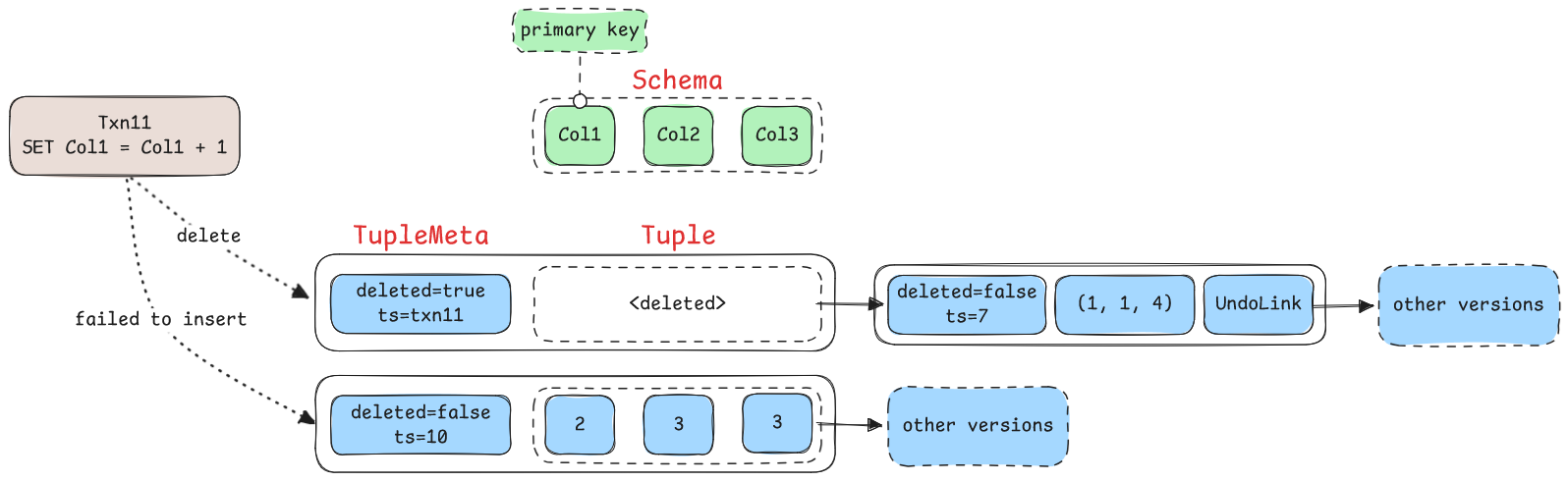
如上,有这样一个 sql 更新逻辑:SET Col1 = Col1 + 1,且 Col1 为主键;显然如果我们仅仅将 Update 改写为了 pipeline breaker,但我们依然一边扫描已经缓存的 tuple 一边向 table heap 中插入数据,假设存在上图所示两个数值相当巧合的 tuple,就会导致删除第一个 tuple 之后准备插入更新后的值时,发现更新后所对应的 key 已经存在,使得事务错误地认为自己发生了 write-write conflict 并中断。
因此我们必须在读取 tuple 的同时,计算这个 tuple 在更新后的新 tuple,而且仅保留这个新 tuple,并立即标记原来的 tuple 为 deleted。
因为每个事务自己改写过的 tuple 依然对事务本身可见,如果真的出现了更新范围覆盖,重复插入了一个已经存在的 tuple 也没有任何问题。
当然如果本次 Update 不涉及索引列更新的话我们就可以优化为原地更新,这样做的开销会小很多。
我们可以在 Update Executor 的 Init 函数中提前遍历更新表达式,检查索引列是否不是一个恒等变换,从而判断本次更新是否会修改索引列。
4.4 Serializable Verification
最后是 Serializable 验证;因为 BusTub 的并发控制协议基于 MVOCC,它的大量约束都是基于后验验证的,也就是先让事务并发执行,等提交的时候再检查它们的执行顺序是否满足一个唯一全序。
如果是 MVTO 协议则不需要这一步骤,MVTO 严格保证事务提交时的读写操作顺序一定对应一个唯一全序。
要知道一个事务的执行顺序是否对应一个唯一全序,最简单的办法是检查事务运行期间,它的可见集合是否发生了任何"偏移";也就是不允许有先于该事务 B 提交的事务 A,在 B 运行期间 A 修改了 B 访问过的某些 tuple 的数据。
回到我们一开始举过的例子,我们有这样一张值班表:
| 医生 | 值班 |
|---|---|
| Alice | false |
| Bob | false |
| Charlie | false |
| Dave | false |
事务 T1 和 T2 并发执行以在没有人值班的情况下指派一个人值班,然后我们在 SnapshotIsolation 等级(也就是每个事务只能看到它们所属版本的数据)下得到一个这样的执行顺序:
- T1 检查表,发现没人值班,随机选中 Alice
- T2 检查表,发现没人值班,随机选中 Dave
我们发现无论 T1 还是 T2 先后执行,只要其中一个事务不在另一个事务提交之前发起,就可能得到这样一个结果:
| 医生 | 值班 |
|---|---|
| Alice | true |
| Bob | false |
| Charlie | false |
| Dave | true |
显然 T1 的结果建立在没人值班的基础上,T2 同理;又因为两个事务分别修改了两个不同的 tuple,我们可以得到一个循环依赖的读写顺序:
- T1 先发现 Dave 为 false,再写 Alice,因此 T1 happen-before T2
- T2 先发现 Alice 为 false,再写 Dave,因此 T2 happen-before T1
我们发现两个事务分别推断出了一对顺序恰好相反的 HB 关系;而且 T1 和 T2 至少有一个事务是领先提交的(因为提交是互斥的),后提交的事务它的可见集合被先提交的事务改动过。
原理和解决方案都说清楚了,接下来我们分析如何实现 VerifyTxn。
BusTub 在每个事务对象里维护了一张哈希表 scan_predicates_,这张哈希表代表了当前事务在读表过程中使用过的所有谓词,实际上就是可见集合约束(而且这个东西依赖于谓词下推优化)。
在 SeqScan 和 IndexScan 中补充了收集谓词的代码后,我们没必要看 writeup 那个又臭又长的叙述。
根据冲突发生的原理,在验证 Serializable 的时候我们需要收集所有 commit_ts_ 大于当前事务的事务,这些事务属于潜在冲突事务。
因为提交是互斥的,而且 BusTub 采用的是 STEAL + NON-FORCED 存储策略,因此在验证的时候 table heap 内的 tuple 就是最新版本,我们完全可以收集所有潜在冲突事务的 write_set_,而不是以事务为单位遍历。
以事务为单位遍历有很大可能会重复检查某些 tuple。
然后我们遍历当前事务用到的谓词集合;由于当且仅当事务的可见集合发生了偏移才会导致读写循环依赖,我们主要关心的就是谓词列的变化,因为只有谓词列的改变才可能导致可见集合的缩放。
为此我们可以在遍历某个谓词表达式时,先检查这个表达式引用了哪些列,然后在后续遍历版本链时跳过所有谓词列没有变动的 UndoLog,只重点审查变动前后的 tuple 版本。
但这种剪枝是不够的,它会漏判非谓词列变动的情况;也就是说如果某个 tuple 在所有版本中始终对当前事务可见(即满足谓词表达式),如果有另一个事务修改了 tuple 上的任何一列,我们一样认定它产生了读写循环依赖。
实际上是因为 BusTub 不支持收集当前事务真正使用到了哪些数据列,我们不可能回答这种修改究竟会不会导致读写依赖。
解决这个问题很简单,如果某个 tuple 的最新版本就对当前事务可见,而且它包含版本链,那么当前事务就不满足 Serializable。
虽然我们此前说过 BusTub 不会记录两次修改的最小 diff,但测试用例集里似乎在有意规避这种情况,所以我们认为不会出现这种虚假修改导致的假阳性。
如果要考虑这种虚假 diff 的影响,我们必须完整重建 tuple 到对应版本并作 content 比较。
不包含版本链的是刚刚被插入的数据,显然这种数据也会导致当前事务违反 Serializable。
但如果 tuple 的最新版本不满足谓词表达式,我们就要利用上面说过的谓词列索引追踪导致谓词列变动的版本,重放 tuple 到该版本检查是否满足谓词;如果满足谓词则意味着原本可见的 tuple 突然消失,即违反 Serializable。
有趣的是,这种情况下我们只关心谓词列的变更;因此在重放 tuple 的过程中我们可以跳过中间访问过的所有无关 log,仅部分重建 tuple 为变更前的版本。
注意,即使是在验证过程中,刚拿到一个 tuple 的时候这个 tuple 可能正在被某个事务修改,这类 tuple 我们必须先做一次版本回滚才能检查最新版本的谓词满足性。
最后补充一点有意思的,如果有个事务发起了全表扫描,并且修改了某些 tuple;这个事务不包含任何可供验证的谓词,但它的确是产生了一些读写依赖关系。这种事务的 Serializable 验证会比基线实现更复杂,因为需要同时考虑虚假 diff 的问题。
当然 BusTub 也在有意规避这种情况。
4.5 测试
这个任务比较离谱,有一大堆测试。
5.最优化性能
5.1 减少互斥区内操作
不难注意到 TxnManager 的很多函数把大量本该可以依赖原子变量实现无锁并发的代码放到了锁保护内,例如 Begin 函数居然在 txn_map_mutex_ 的保护下尝试分配内存。
本身这些操作就不需要同步,而且操作执行失败了又不会破坏 MVCC(更何况一般不会失败),所以我们可以把它们移出锁保护区。
5.2 并发 Commit
默认的 Commit 函数被一个大锁 commit_mutex_ 保护,但对于 Serializable 以外的隔离等级的事务来说这把锁是没有必要的。
这把锁实质上是在保证 last_commit_ts_ 的分派是互斥的,因为 writeup 的建议是先申请一个 commit_ts,然后更新事务的 write_set_,最后再实际递增 last_commit_ts_。
由于 last_commit_ts_ 是一个原子变量,以上操作纯属脱裤子放屁,我们完全可以要求这个锁只在 Serializable 等级下有效。
为什么 Serializable 等级下的
VerifyTxn不能并行呢?是因为 Verify 的目标是所有在当前事务发起之后提交的事务,因此 Serializabe 等级下的与当前事务无关的事务的
Commit必须严格 happen-before 当前事务开始执行VerifyTxn;也就是说,我们不能在仍有事务处在提交阶段的时候开始收集事务,这会导致漏判。因为每一个通过了
VerifyTxn验证的事务的 commit_ts,都必然大于下一个即将开始验证的事务的 read_ts,我们势必需要把这个刚通过了验证的事务也加入到下一个即将开始验证的事务的检索集合里,而且 Verify 操作在事务实际获取 commit_ts 并且更新
write_set_之前,我们要等到先发事务做完以上操作才能真正开始检查版本链这是一种典型的数据依赖导致的顺序执行。
但这样我们会遇到一个问题:每个事务必须拥有一个唯一的 commit_ts,因此我们需要同时更新 last_commit_ts_ 并且获取被指派的 commit_ts(一般通过 fetch_add),不过这个时候我们只获得了一个 timestamp,我们还没有更新当前事务写过的所有 tuple。
这时候就导致了未发布的版本出现了可见性泄露,也就是如果提交过程中有另一个事务通过 Begin 发起,它能看到 last_commit_ts_ 已经递进了,但是因为我们此时还没有更新写入过的 tuple,因此这个新事务居然意料之外的看不到本该能看到的数据。
问题的原因是我们耦合了"下一个版本的分配"与"当前已分配的最新版本的分配",Begin 需要的是目前为止已发布的最新版本号,而 Commit 需要的是下一个可供使用的版本。
我们可以简单地引入一个新的原子量 next_commit_ts_ 解决这个问题:Commit 时每个事务都通过 fetch_add 从这个新的原子量处原子性申请一个版本。
不过问题还没完,现在下一版本号的分派是没问题了,但是已发布的最新版本号递增还没解决。last_commit_ts_ 的递增必须严格连续递增,我们不能中间跳过多个版本,更不能让某个还没写入完成的事务的版本被提前发布。
其实就是说不能让每个事务在写入完成后简单调用
last_commit_ts_.fetch_add()然后拍拍屁股走人。
last_commit_ts_ 的递增仅发生在当前事务获得的 commit_ts 恰好与 last_commit_ts_ 的值相差 1 时,这条约束可以保证所有版本的发布顺序严格等同于事务获取 commit_ts 的顺序,既不会提前发布也不会遗漏发布。
为了检测这种变化并且阻塞所有不满足该条件的并发线程,我们得在 Commit 里写一个简易自旋等待,当然因为我们写的是 OCC 协议,自旋这种乐观同步操作本就无可厚非。
cpp
auto expected = commit_ts - 1;
// 注意我们使用了 release 内存序,这是为了确保任何看到 last_commit_ts_ 递增的线程都一定能看到事务已经更新了修改过的 tuple 数据
while (!last_commit_ts_.compare_exchange_weak(expected, commit_ts, std::memory_order_release)) {
expected = commit_ts - 1;
}另外在 VerifyTxn 中我们还可以利用 last_commit_ts_ 和 next_commit_ts_ 的差值关系缩小锁临界区的范围;甚至利用 next_commit_ts_ 和事务 read_ts_ 的大小关系跳过某些比较。
5.3 异步 GC 线程
writeup 说在 bench 测试阶段不会调用我们之前实现的 GarbageCollection,但是运行过程中累计的 UndoLog 数量又会影响 leaderboard 排名,因此我们要在适当的时候以适当的形式发起 GC。
显然 GC 需要触发一次完整的可达性分析,这太耗时了; BusTub 并不限制我们搞一个后台异步 GC 出来,所以我们可以放手去做。
在设计之前,我们必须关注一个问题:GC 是否会导致 UAF(use-after-free);也就是说 GC 不应该回收一些可能仍在被访问或需要被访问的数据。
前面已经说了可以被 GC 回收的版本链的特点,为什么这里重复提及这个问题?是因为我们之前只针对了 COMMITTED 事务的回收,现在我们必须处理 ABORT 事务。
ABORT 事务虽然是一个失败的历史,它持有的所有版本都从数据库历史线中脱离,但是我们不能保证在运行过程中是否有别的线程刚好读到了 ABORT 写过的数据,然后即将利用 ABORT 事务的 UndoLog 回滚到正确的版本。
假设有两个事务 A 和 B,A 先修改 tuple,B 接着读到了刚改过的 tuple,然后 A 因错误中断,此时 B 还需要依赖 A 的
UndoLog回滚到主线版本。
简单来说,一个能被 GC 回收的 ABORT 事务,它的影响一定对当前所有事务不可见,这样事务才不会读到 ABORT 写过的数据然后又打算回滚。
因此 writeup 里说"ABORT 事务的
UndoLog可以被直接移除"是完全不准确的。
现在关键在于界定这个"影响力范围"。很容易想到,如果某个事务 ABORT 之后,所有在执行 Abort 的时候之前创建的事务全部结束了,那么现在活跃的所有事务一定都看不到这个 ABORT 事务曾经所作的任何修改,也就不需要依赖该事务的 UndoLog 记录,这也意味着我们可以直接完整删掉这个 ABORT 事务。
我们在实现 Commit 函数时做过这样一件事:每次创建事务时都令事务的 read_ts_ 等于当前 last_commit_ts_,而每次一个事务提交时都会递增 last_commit_ts_。
设递增前的 last_commit_ts_ 为 X,如果所有 read_ts_ 等于 X 的事务都消失了,我们就可以断言从现在起创建的新事务所能够回溯到的最远版本,其 ts_ 的值一定大于等于 X。
类似的,我们同样可以在 Abort 里,每次事务回撤了所有操作之后,递增一个全局的 epoch_ 原子量;同时在 Begin 里为每个事务分派一个当前的最新 epoch_。
然后我们像维护 Watermark 一样维护一个 Epochmark,不同点在于我们不需要更新而且也不存在 commit ts,而且我们可以用 uint64_t 承载 epoch,如果当前不存在活跃事务我们直接返回一个极大值。
这样一来,如果所有 epoch 等于 X 的事务都消失了,根据 MVCC 的特性,我们就能知道这一代的事务当中,ABORT 的事务的修改一定对现在运行的所有事务不可见,于是我们就可以全部删掉它们。
至关重要的前提是我们必须在
Abort回撤了所有修改之后,以 release 内存序递增epoch_。
虽然这个代际 GC 想法很好,但它不适用于 COMMITTED 事务,这类事务必须使用基于可达性分析 + 标记删除的 GC 算法。
这是因为一个 tuple 的 UndoLog 会分散在不同的事务对象中,因此一组 tuple 的版本链会胡乱指向不同的事务对象,一团乱麻。而 TableHeap 里记录的最新版本的 ts_ 会直接影响后续版本链的可达性,显然我们必须从源点开始遍历版本链。
同时也间接导致了如果我们只看 epoch 删除所有 COMMITTED 事务的话必然会导致 UAF(因为 tuple 的次新版本会分散存放在不同事务里,即使这些事务的其他 UndoLog 已经不可达)。
根据以上分析,虽然我们可以实现一个异步 GC 机制,但因为 TxnManager 的部分元数据必须置于 txn_map_mutex_ 的保护下,我们的这个 GC 依然是一种 STW GC。
所以我们应该降低 GC 的频率,我们可以让这个 GC 线程周期性唤醒,同时也可以被前台线程在每次 Commit/Abort 时因事件通知的形式提前唤醒。
5.4 提交
最后拿下了单项第三、其余第一的成绩,可能一段时间之后就会被人打爆吧(笑)。
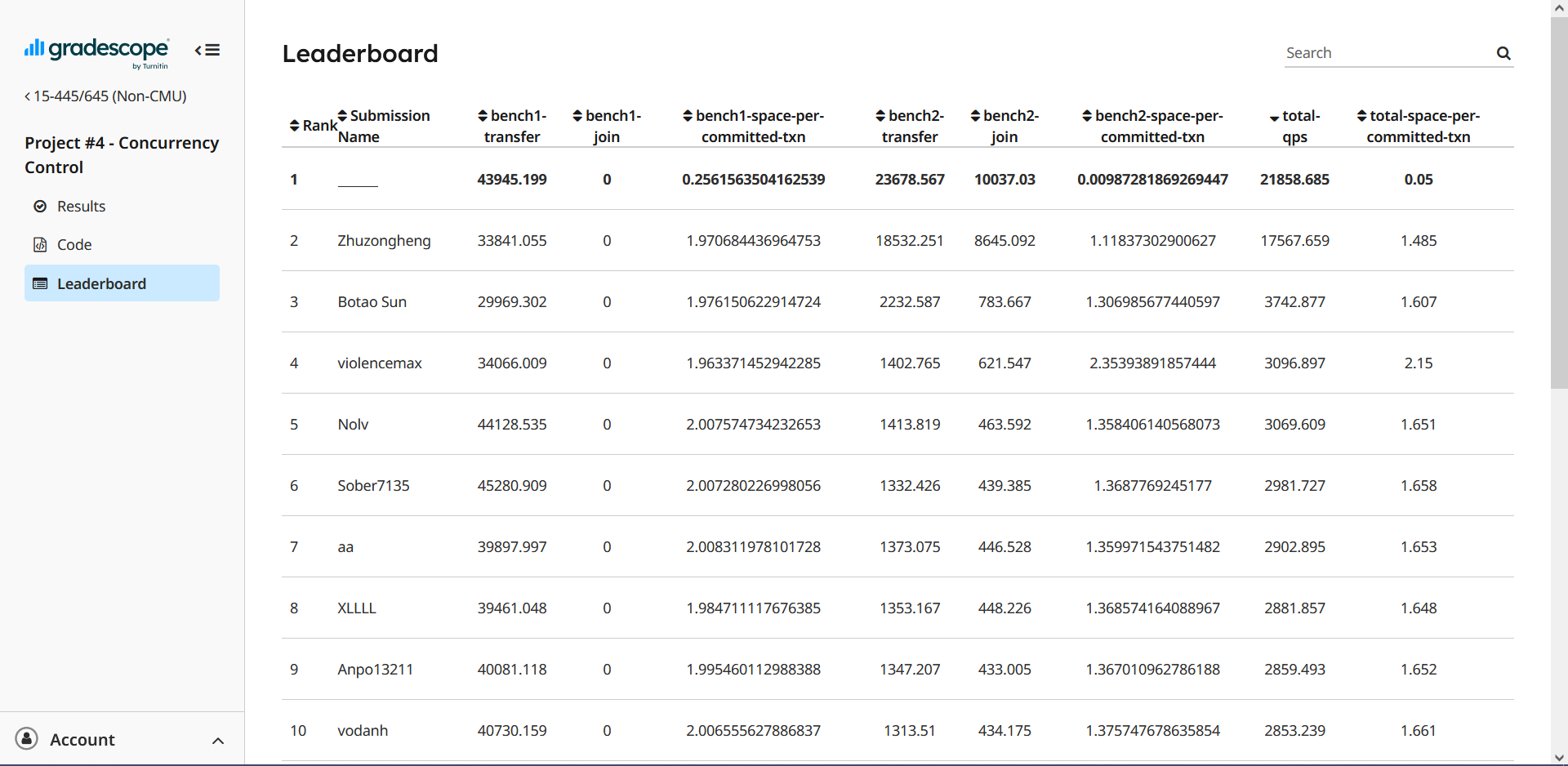
不知道为什么榜单上的所有人都对 GC 不感冒,搞得我的 GC 成绩鹤立鸡群。
6.总结
写 task#4 的时候被 UpdateTupleAndUndoLink 狠狠坑害了...
Reference
1 CMU Fall 2024 15-445 MVCC & SI & P4
2 An Empirical Evaluation of In-Memory Multi-Version Concurrency Control(译文)
4 课程的公开讲义