AstraNav-Memory: Contexts Compression for Long Memory
- 摘要
- 研究背景与痛点
- 背景:终身具身导航需要机器人拥有长时记忆,以便在不同任务和环境中积累经验
- 痛点 :过去主流的做法是 以物体为中心 的记忆(把环境拆解成一个个物体),这种方法严重依赖目标检测和3D重建。这种方法鲁棒性和可扩展性差。
- 本文创新
- 图像为中心的隐式记忆:直接将历史视角的原始图像特征作为记忆。
- E2E大模型架构:引入 Qwen2.5-VL 作为核心导航大脑,将记忆模块与大模型直接结合。
- 技术亮点
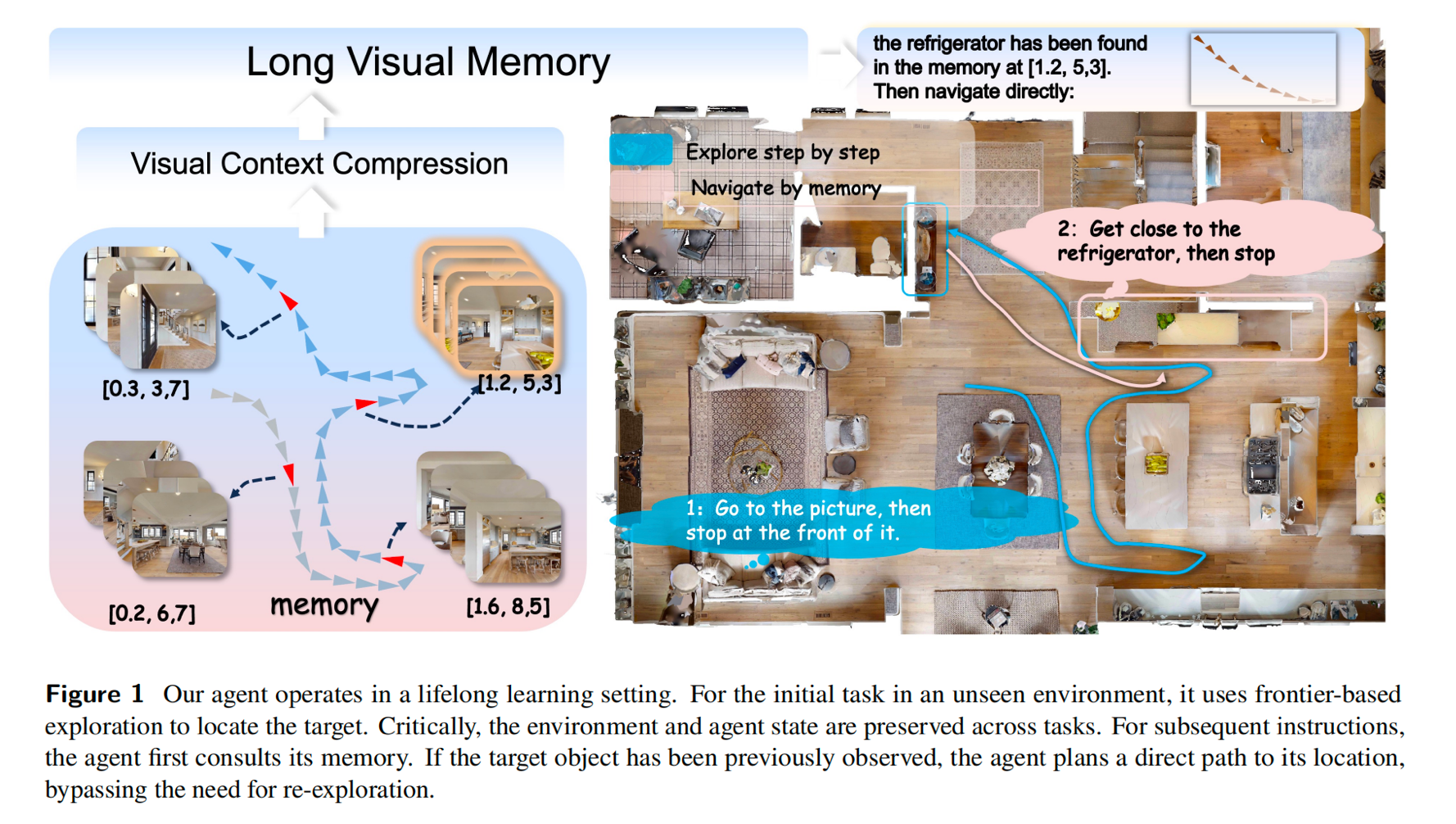
- 高效视觉压缩 :为了防止图像撑爆上下文,作者设计了一个由 ViT、冻结的 DINOv3 特征、PixelUnshuffle 和卷积块组成的 视觉分词器(Visual Tokenizer)。
- 极高的压缩比:支持动态调整压缩率。在16倍压缩下,一张原本复杂的图像被压缩到仅 30 个 token。
- 实验结果与结论
- SOTA:在 GOAT-Bench, HM3D-OVON 中取得了SOTA
- 消融实验:不走极端的适度压缩是兼顾速度和准确率的最好选择。
- 结论:证明了压缩图像记忆是未来具身智能体实现长时序推理和导航的可行方案。
- 研究背景与痛点
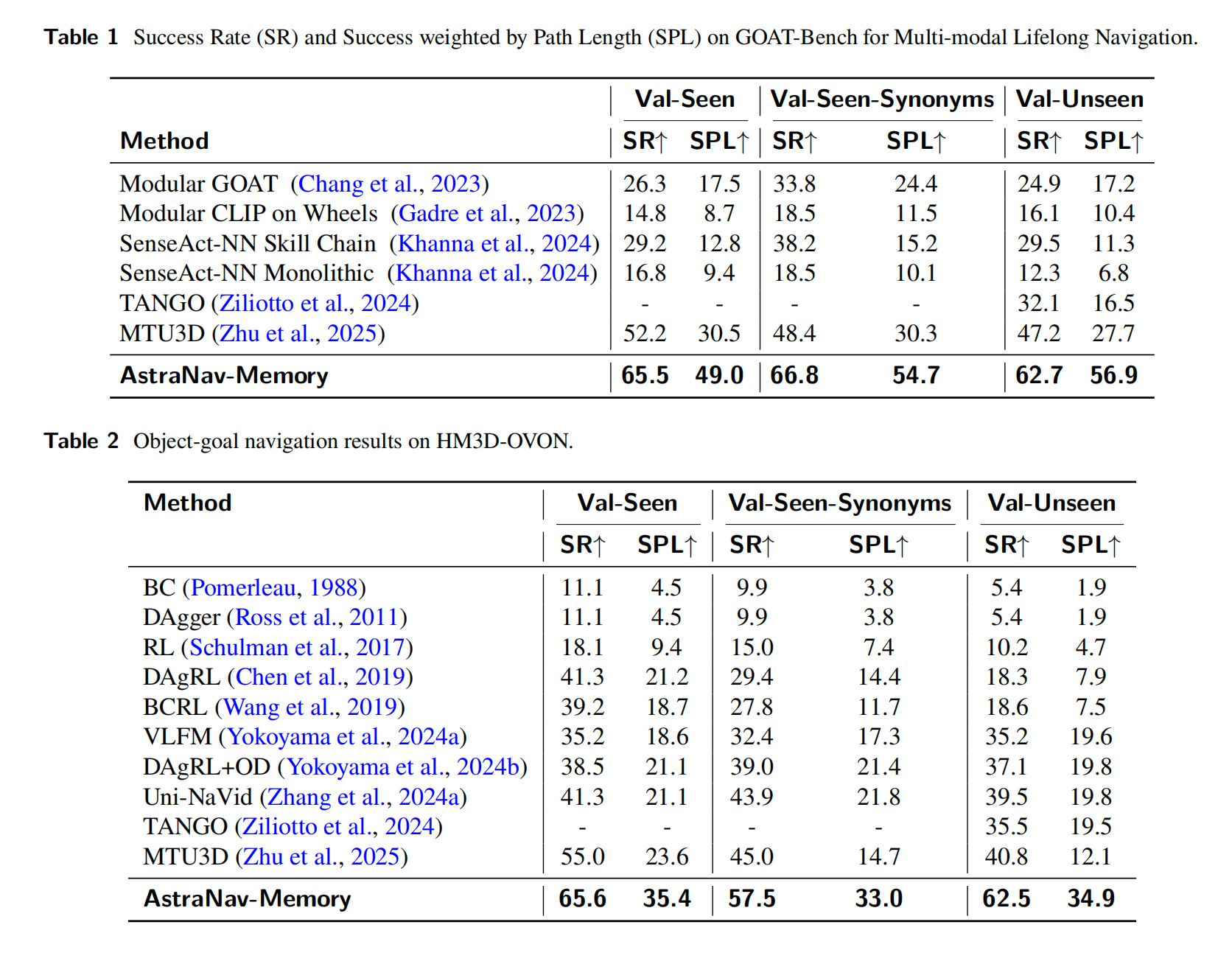
1. Introduction
-
Motivation
-
具身智能正从单次任务执行 向终身多任务学习演进。
-
类人导航的核心特征:
-
在未知环境中具备渐进式推理与探索的能力
-
在已知环境中具备利用记忆走捷径的能力
-
-
实现这一目标的基础方式,就是构建高效的长时空间语义记忆
-
-
现有技术路线:以物体为中心 vs. 以图像为中心
-
物体为中心------显式memory
-
机制:依赖语义地图重建、坐标提取。
-
缺陷:重度依赖上游目标检测,容易产生误差级联;系统管线复杂,跨场景泛化能力差。
-
-
以图像为中心------隐式memory
- 机制:端到端保留相机位姿与多视角图像,由模型内化空间结构。
- 优势:消除外部模块瓶颈,训练目标与导航策略统一。
- 瓶颈:面对长程历史时,海量时空冗余会引爆显存,并使得注意力机制失效。
-
-
本文方法
- 模块设计 :提出了一个 ViT原生、即插即用的Visual Tokenizer。
- 网络架构 :
- 冻结的 DINOv3 特征提取
- PixelUnshuffle 空间下采样
- 轻量级卷积特征融合
- 对接 Qwen2.5-VL。
- 压缩量化:将 720×640 分辨率下的 598 个 Token 极限压缩至约 30 个(20倍压缩率),使单次上下文能够容纳数百张历史帧。
2. Related Work
2.1 Long-term memory
- 路线一:外显外部记忆与检索
- 核心机制:
- 将记忆存储在模型外部的数据库中,需要时通过检索增强来调用结构化索引。
- 检索增强方式:如 RAG、MemGPT、GraphRAG 等
- 优势: 具有极强的可解释性,记忆调用的过程是透明可控的。
- 缺陷:
- 严重依赖文本分块和索引策略的启发式设计
- 极易受检索召回率和延迟的影响
- 这种割裂的检索方式会破坏长时序决策中的时间连贯性,导致其与具身导航的闭环规划耦合度极低。
- 核心机制:
- 路线二:隐式的基于 Token 或参数化记忆
- 核心机制:
- 将记忆直接融合到模型的隐状态、Token 序列或网络参数中。
- 代表工作:上下文窗口扩展(YaRN)、流式注意力(StreamingLLM)、多模态长文本(Flamingo, LongVLA)以及测试时训练(TTT)。
- 优势: 能够实现真正的"端到端"训练,摆脱了对外部索引库的依赖。
- 瓶颈:
- 缺乏对实体、位置等结构化信息的定向检索能力。
- 随着memory变大,注意力机制的计算成本呈指数级增长,且极易引入Attention Noise。
- 核心机制:
2.2 Visual context compression and token efficiency
- 路线一:Pre-encoding and merging
- 机制:在视觉特征提取阶段内部,通过层级聚合 或全局-局部融合来减少 Token 数量。
- 缺陷:这些方法主要是感知驱动的,即为了看清图像而压缩,而不是为了下游控制而压缩,无法保证长时序决策的一致性。
- 路线二:Pruning and sparsification
- **机制:**直接丢弃或降低那些低信息量 Token 的权重(如 TokenCarve, FocusLLaVA)。
- 缺陷:虽然即插即用且极其简单,但极度不稳定。它们经常会不小心把导航中至关重要的关键帧或关键视角给剪裁掉,面对未知的场景分布时表现得很糟糕。
- 路线三:Model-internal and language-side compression
- **机制:**将压缩过程与大语言模型结合,追求极致的压缩率。
- **缺陷:**目标域不匹配。以 DeepSeek-OCR 为例,它的极限压缩是为了文本识别,并不保证能保留具身导航所必须的空间几何与语义方位信息。
3. Method
3.1 Preliminary
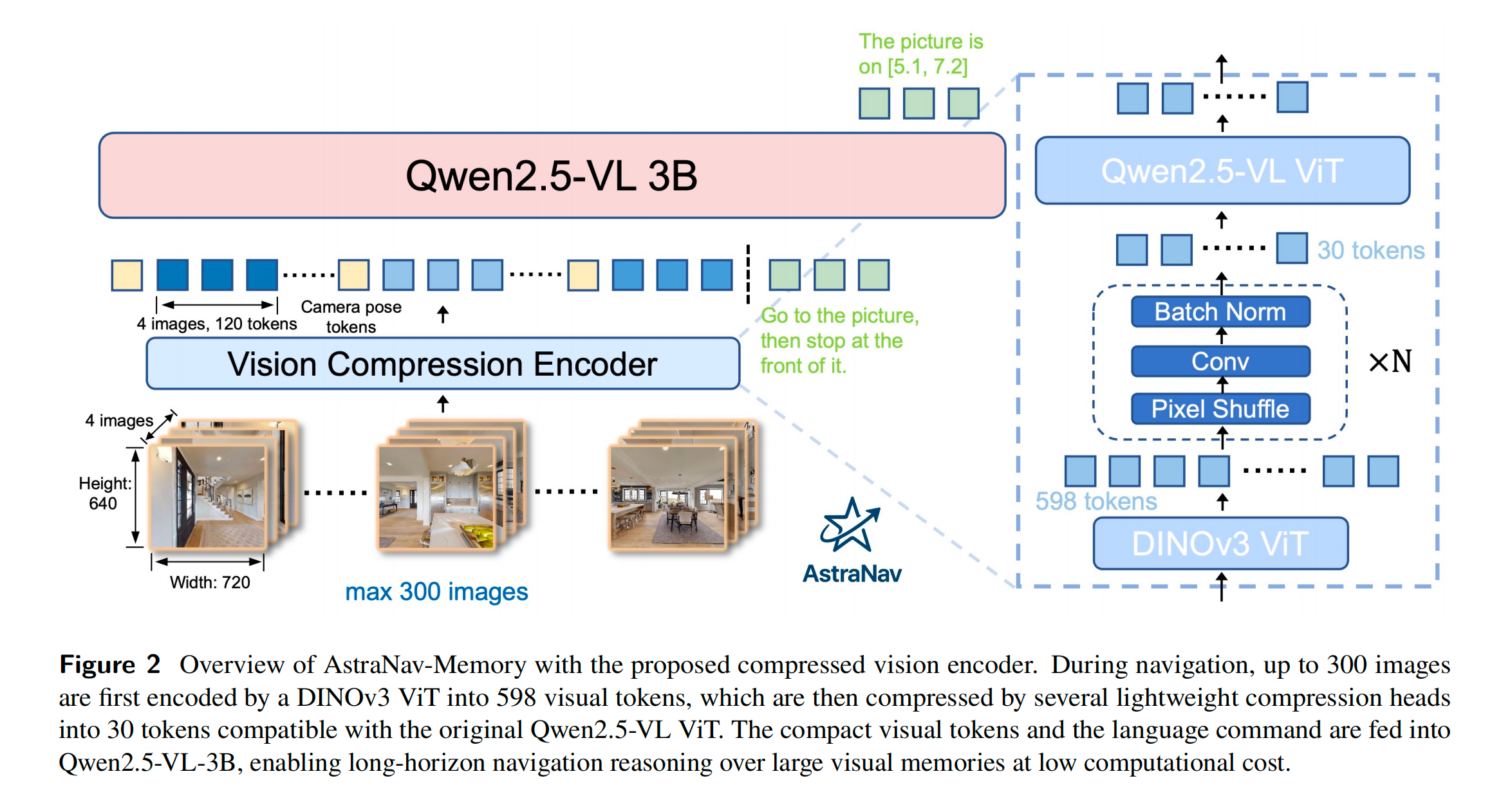
将具身导航定义为多模态 LLM 的 Seq2Seq 文本生成任务。
- 输入格式 :x=SYS;(P1,I1);(P2,I2);...;(PT,IT);INSTRx = \\text{SYS}; (P_1, I_1); (P_2, I_2); ... ; (P_T,I_T); \\text{INSTR}x=SYS;(P1,I1);(P2,I2);...;(PT,IT);INSTR
- SYS\text{SYS}SYS 是系统提示词,INSTR\text{INSTR}INSTR 是当前指令, (PT,IT)(P_T,I_T)(PT,IT)表示第 TTT 个相机位姿和图像对。
- 输出格式 :输出带有特殊坐标标签(如
<coordinate>x, y</coordinate>)的自然语言指令。 - 核心痛点 :随着时间 增长,原生视觉大模型面临二次方级算力爆炸,必须在不改变后续语言模型的前提下,对视觉输入序列进行极度压缩。
3.2 Model Architecture
-
Base feature extractor------DINOv3
- 采用冻结的 DINOv3 提取具有强几何/物理意义的初始特征,保证跨域泛化性。
-
Compression ------PixelUnshuffle
PU2:RH×W×C→RH2×W2×(4C) PU_2: \mathcal{R}^{H×W×C} → \mathcal{R} ^{\frac{H}2 × \frac{W}2 ×(4C)} PU2:RH×W×C→R2H×2W×(4C)- 传统的池化会粗暴地丢弃信息,而 PixelUnshuffle 是一种无损的空间降维方式:它把画面变小(长宽各减半),但把压缩的信息的信息存进 Channel 里,从而完美保留了空间几何关系。
-
Compression Block ------Conv & BN
X(i)=SiLU(BN(Conv(X(i−1))) X^{(i)} = \text{SiLU}(\text{BN}(\text{Conv}(\textbf{X}^{(i−1)})) X(i)=SiLU(BN(Conv(X(i−1)))-
其中 (Hi,Wi)=(Hi−1/2,Wi−1/2).(H_i, W_i) = (H_{i−1}/2, W_{i−1}/2).(Hi,Wi)=(Hi−1/2,Wi−1/2).
-
在每次 PixelUnshuffle(步长为 2)之后,张量通过一个步长为 1 的 3×3 卷积,接着是 BatchNorm 和 SiLU 激活函数,堆叠N个压缩块产生的总空间压缩率如下所示。
r=22N=4N,(HN,WN)=(H02N,W02N) r = 2^{2N} = 4^N, (H_N,W_N)=(\frac{H_0}{2^N},\frac{W_0}{2^N}) r=22N=4N,(HN,WN)=(2NH0,2NW0)
Z~t=M2(Flatten(X~(N)))+P(2D),Z~t∈RLt×CN \tilde{Z}_t = \mathcal{M}_2(\text{Flatten}(\tilde{X}^{(N)}))+\text{P}^{(2D)},\tilde{Z}_t \in \mathcal{R}^{L_t \times C_N} Z~t=M2(Flatten(X~(N)))+P(2D),Z~t∈RLt×CN
- 完整计算流程
- 输入图像 DINOv3 提取后变为 45×40 的网格 →\rightarrow→ 补齐边缘变为 48×40 →\rightarrow→ 经过两次压缩块降维 16 倍变为 12×10 →\rightarrow→ 最后通过原生 2×2 合并器再降 4 倍,即 30 。
- 最后用卷积把通道数调成 1280,完美伪装成原生 Token 喂给Qwen
-
3.3 Data Construction
- 探索能力构建 (OVON):
- 方式:构建单次任务数据集。通过维护 3D 占据地图并使用前线最短路径算法,生成专家轨迹,教会模型在未知环境中的探索方式。
- 数据量:在145个场景中构建了OVON-500K
- 长记忆构建 (GOAT):
- 方式:构建多目标不重置数据集。环境和状态持续连贯,强迫模型利用长期积累的历史记忆去优化后续路径。划分了 50~500 步不同跨度的高难度数据用于极限施压。
- 数据量:因为GOAT中机器人状态不重置,所以设计了GOAT-1M-50L, GOAT-1M-100L, GOAT-1M-200L和GOAT-1M-500L多种难度的数据集。
4. Experiment
4.1 Setup
- 基座模型:Qwen2.5-VL-3B
- 训练集规模:总计 150万 (1.5M) 个样本。
- 算力配置:32 张 H20 GPU 进行分布式训练
- 学习率: 设定为 1×10−51 × 10^{-5}1×10−5。
- 其他参数:
- Warmup ratio: 0.05
- Epochs: 2
4.2 Results