
【新智元导读】让全球从春节苦等到四月的 DeepSeek V4,终于来了!
就在刚刚,DeepSeek V4 真的来了!
今天,那个曾经以一己之力打破闭源模型霸权的 DeepSeek,带着 DeepSeek-V4 系列预览版,向全球开发者正式宣告------
百万级上下文(1M Context)的平民化时代,以及开源 Agent 能力、世界知识和推理性能上的新巅峰,已经到来。
DeepSeek V4,再度实现国内与开源领域的领先。
V4 的技术报告,已经同步发布。

论文地址:huggingface.co/deepseek-ai...

DeepSeek-V4-Pro
性能比肩顶级闭源模型
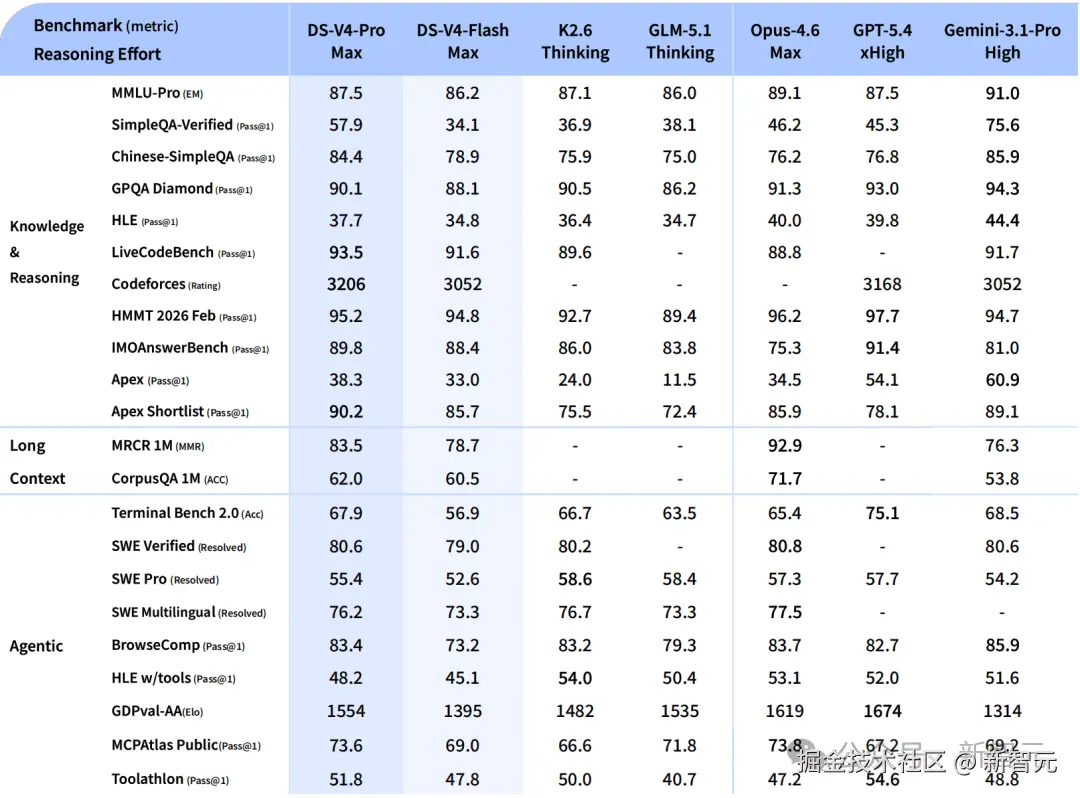
DeepSeek-V4 系列包含两个版本:拥有 1.6T 总参数、49B 激活参数的性能怪兽 DeepSeek-V4-Pro ,以及专为高效率、经济性设计的 284B 总参数、13B 激活参数的 DeepSeek-V4-Flash。


可以说,DeepSeek-V4-Pro 已经达到了开源模型的新巅峰,对标全球顶尖闭源水准。
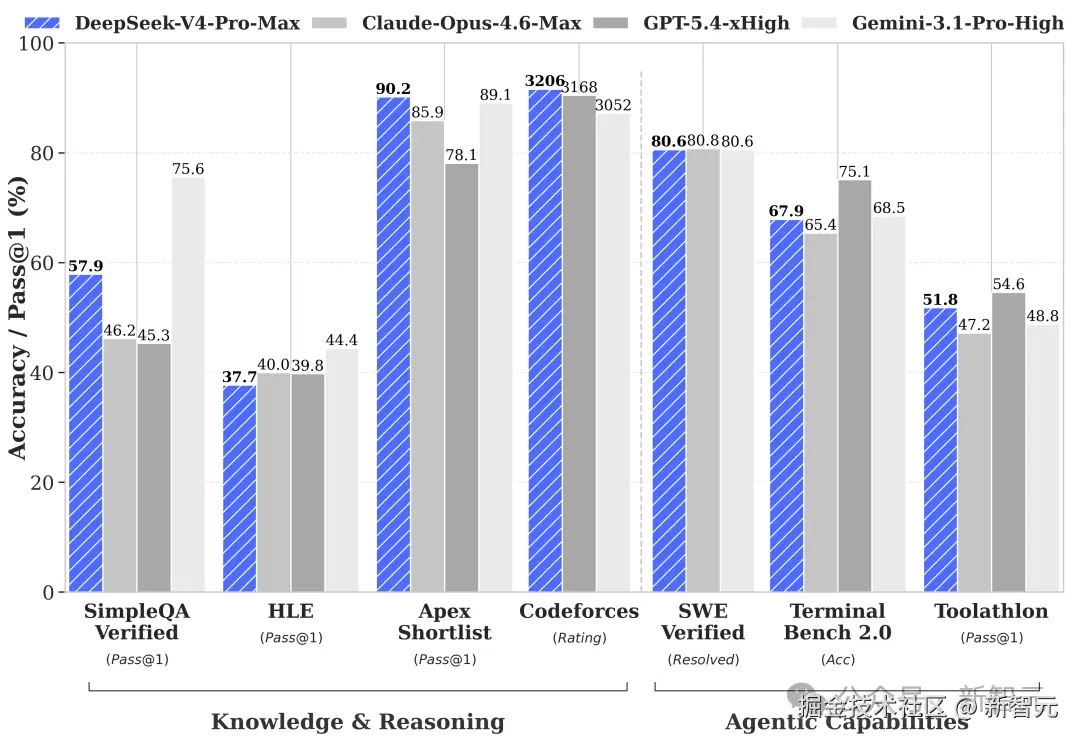
首先,V4-Pro 在 Agent 能力上实现了跨越式突破,其 Agentic Coding 水平稳居开源界首位。
实测反馈显示,其编码体验已超越 Sonnet 4.5,交付质量直追 Opus 4.6(非思考模式),目前已成为公司内部 Agent 编程的首选模型。
其次,它具备深厚的世界知识储备。
在知识测评维度,V4-Pro 显著领先同类开源产品,与闭源标杆 Gemini-Pro-3.1 的差距已缩减至极小范围。
另外,它还有顶尖的逻辑推理表现。
在数学、STEM 及高难度竞赛代码等硬核领域,V4-Pro 的表现不仅冠绝开源社区,更具备了挑战世界最强闭源模型的实战竞争力。
支撑这两个模型傲视群雄的,是其底层技术的「三大神技」:
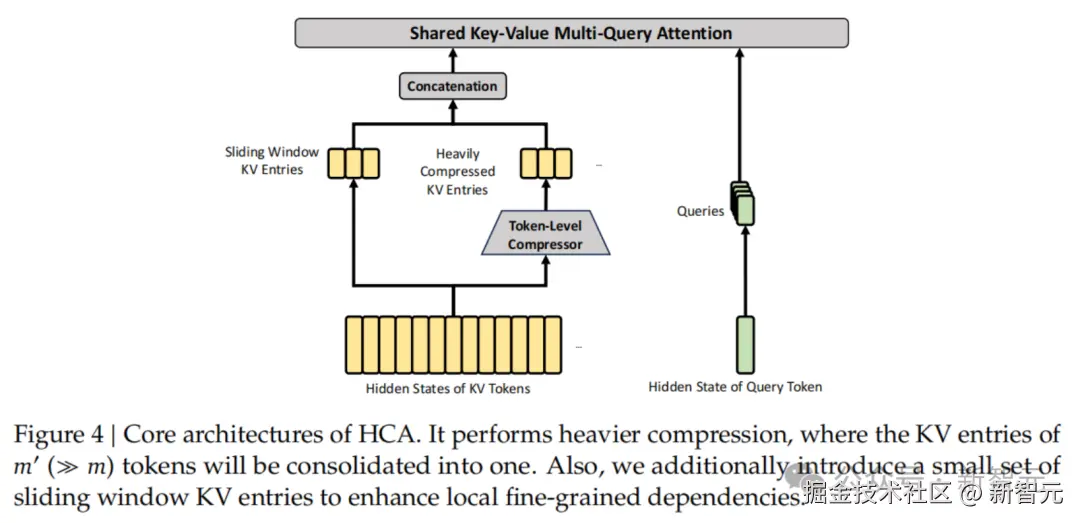
- 混合注意力机制(CSA + HCA)
DeepSeek-V4 并没有盲目增加硬件投入,而是开创性地设计了混合注意力架构。
压缩稀疏注意力(CSA)对 KV 缓存进行 token 维度的压缩并结合 DSA 稀疏注意力;重压缩注意力(HCA)则进行更极致的压缩以维持稠密计算。
这种「长短结合」的策略,让模型在处理百万字上下文时,计算量和显存需求大幅降低。
- 流形约束超连接(mHC)
为了提升信号传播的稳定性并增强模型表达力,V4 引入了 mHC 结构,升级了传统的残差连接。这让模型在深层网络中依然能保持卓越的建模能力。
- Muon 优化器
引入全新的 Muon 优化器,让训练过程不仅收敛更快,且更加稳定。
正是这些结构创新,让 DeepSeek-V4 在推理效率上实现了质的飞跃。
在 100 万 token 上下文的极端场景下,DeepSeek-V4-Pro 的单 token 推理计算量仅为前代的 27%,KV 缓存占用更是缩减到了惊人的 10% 。
DeepSeek-V4-Flash
极致效能与性价比的完美平衡
相比于 Pro 版本,Flash 版则是更快捷高效的经济之选。
尽管在世界知识的深度上略逊于 Pro 版本,但 DeepSeek-V4-Flash 保留了与之接近的逻辑推理水平。
受益于更精简的参数规模与激活机制,它能为用户提供响应更快、成本更低的 API 接入方案。
在处理基础 Agent 任务时,V4-Flash 的表现与 Pro 版不相上下,但在应对极端复杂任务时仍存在进阶空间。
架构革新
重塑长上下文效率
DeepSeek-V4 引入了革命性的注意力机制,通过在 Token 维度进行高效压缩,并结合 DSA 稀疏注意力(DeepSeek Sparse Attention) 技术,实现了全球顶尖的长文本处理能力。
这种创新大幅削减了对计算资源与显存的依赖。
即日起,1M(100 万 tokens)超长上下文将成为 DeepSeek 官方服务的标准配置。
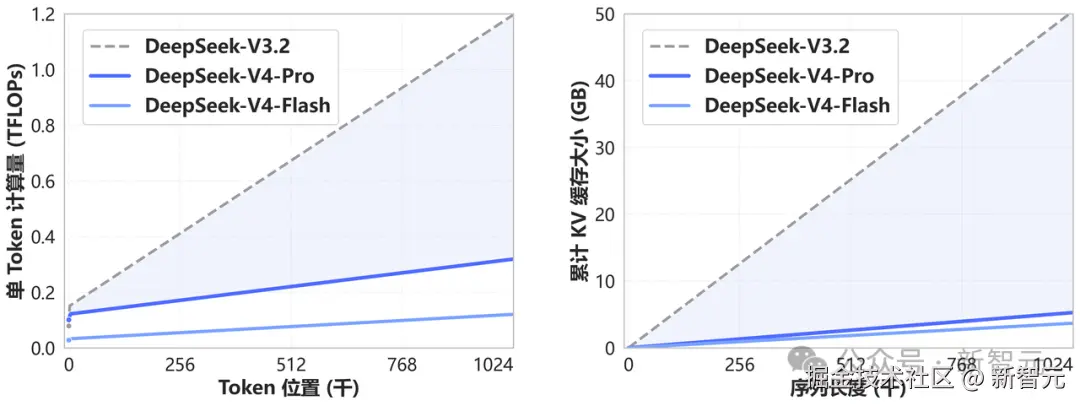
DeepSeek-V4 和 DeepSeek-V3.2 的计算量和显存容量随上下文长度的变化
Agent 能力深度优化
DeepSeek-V4 针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 生态进行了深度适配。
在代码编写与自动化文档生成等场景下,其产出效率显著提升。
V4-Pro 在特定 Agent 框架下自动生成的 PPT 页面实例
(上下滑动查看)
API 全面升级,旧版模型倒计时
对于开发者而言,好消息是:API 已经同步上线!
只需简单修改 model_name 即可接入这两款新旗舰:
- 追求性能:deepseek-v4-pro
- 追求效率:deepseek-v4-flash
**特别提醒:**原有的 deepseek-chat 和 deepseek-reasoner 模型名将作为 V4 的过渡别名(分别指向 V4-Flash 的非思考与思考模式),但这两个旧名称将于 2026 年 7 月 24 日正式停用。
论文解读
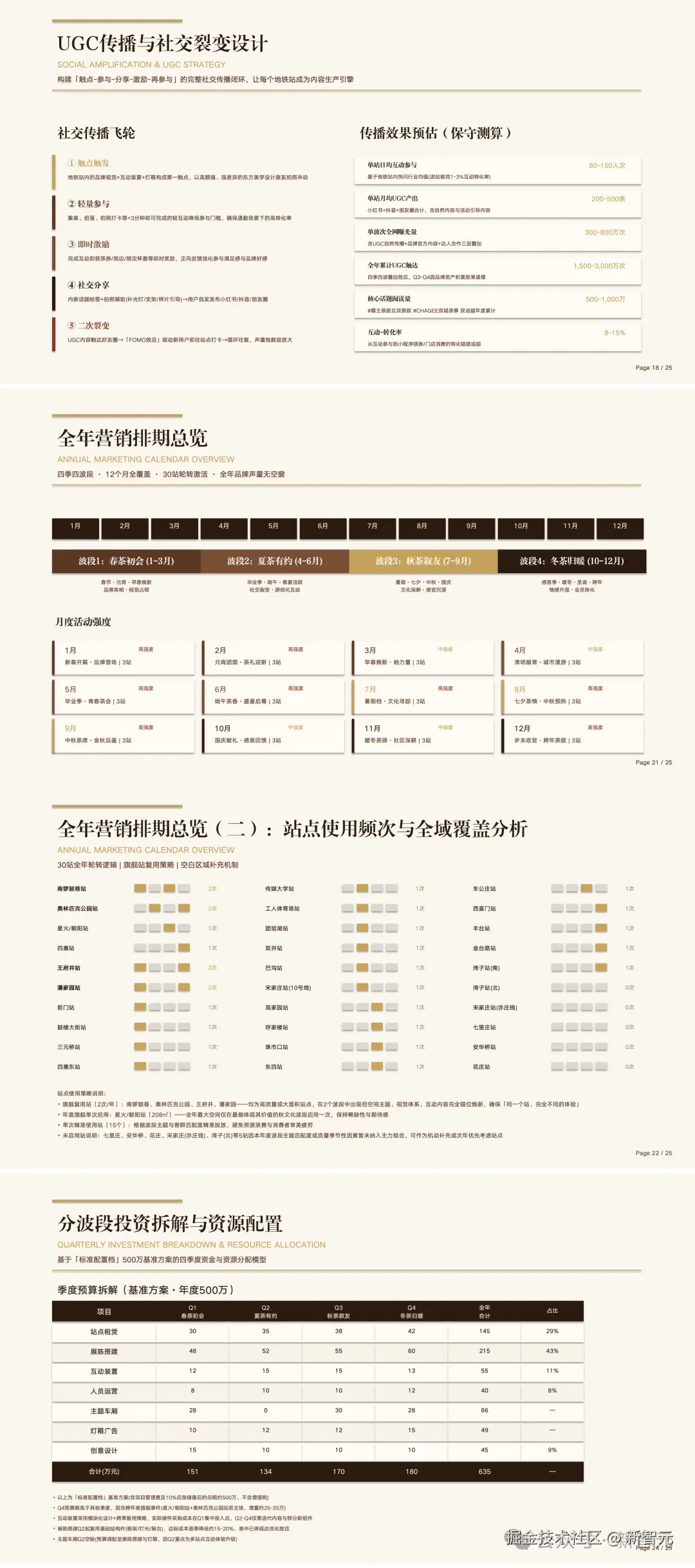
两种压缩,一套组合拳
V4-Pro 中,CSA 的压缩率为 4,每 4 个 token 的 KV 缓存合并成一个条目。
压缩之后再通过 Lightning Indexer 对压缩后的 KV 条目打分,每个 query token 只选 top-1024 个条目做注意力计算。索引计算用 FP4 精度,超长上下文下开销极低。
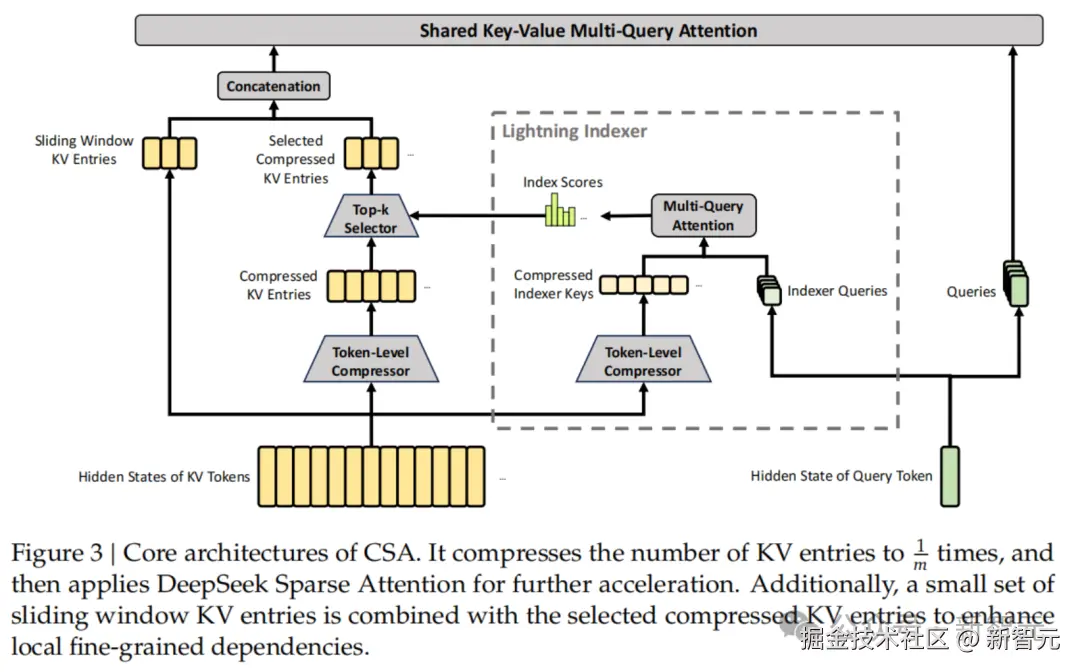
HCA 走另一条路。压缩率拉到 128,比 CSA 激进得多,但不做稀疏选择,所有压缩后的 KV 条目都参与计算。极致压缩换全局视野。
 |
 |
|---|
两种机制交替堆叠,CSA 精细检索,HCA 全局感知,再加上每层 128 token 的滑动窗口捕捉局部依赖,三条路径协同。
算一笔账。
以常规 BF16 GQA8(头维度 128)作为基线,V4 在 100 万 token 下的 KV 缓存只有基线的约 2%。KV 条目还采用混合精度存储,RoPE 维度 BF16,其余 FP8,体积比纯 BF16 再砍一半。
推理端则把压缩 KV 和滑动窗口 KV 分开管理,支持磁盘级缓存存储,避免共享前缀的重复 prefill。
mHC,6.7% 的代价换来的稳定性
标准 HC 扩展残差流宽度来增强信息传递,但多层堆叠时数值会炸。
mHC 的做法是把残差映射矩阵约束在双随机矩阵流形(Birkhoff 多面体)上,确保谱范数不超过 1,信号深层传播不发散。投影通过 Sinkhorn-Knopp 算法迭代 20 次实现。
工程代价可控,扩展因子只有 4,经过融合 kernel 和选择性重计算优化后,额外墙钟时间仅 6.7%。
训练万亿参数的「土办法」
Muon 的核心是对梯度动量做 Newton-Schulz 正交化,V4 用 10 次混合迭代,前 8 次快速收敛,后 2 次精确稳定。
但优化器只是一半的故事。V4 报告披露了两个训练稳定性技巧。
Anticipatory Routing,把路由索引的计算和主干网络的更新解耦,用历史参数提前算好路由并缓存。系统在检测到 loss spike 时自动触发,日常开销可忽略。
SwiGLU Clamping,把 SwiGLU 线性分量钳制在 -10, 10,门控上界钳制在 10。简单粗暴但有效。
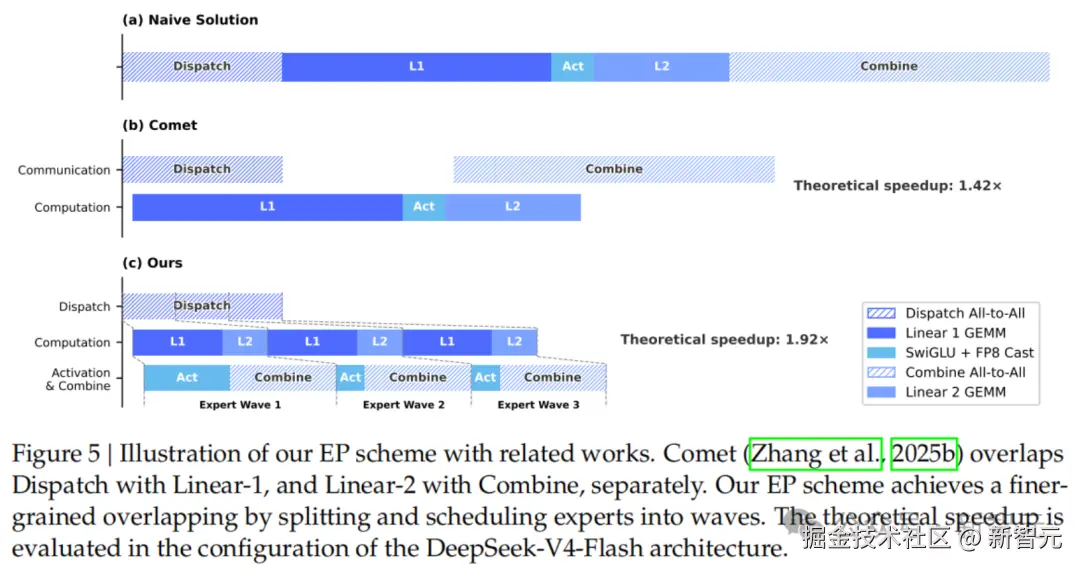
MoE 工程上,V4 开源了 MegaMoE,把通信和计算融合进单个 pipeline kernel,通用场景加速 1.5 到 1.73 倍,延迟敏感场景最高 1.96 倍。
专家分训,蒸馏合一
V4 用 On-Policy Distillation(OPD)替代了 V3.2 的混合 RL。先独立训练数学、代码、Agent 等领域专家,再用一个学生模型对十几个专家做全词表 logit 蒸馏。
工程上的关键突破是,不缓存教师 logits(显存放不下),只缓存最后一层隐藏状态,训练时按需重建 logits,用 TileLang 专用 kernel 加速 KL 散度计算。
V4 还引入了 Generative Reward Model(GRM),让 actor 网络同时充当奖励模型,评判和生成能力联合优化,不再依赖传统标量奖励模型。
后训练阶段同步做了 FP4 量化感知训练,对 MoE 专家权重和 CSA 索引器做 FP4 量化,且 FP4 到 FP8 反量化无损,整个流程复用现有 FP8 框架。
DeepSeek
再度证实开源的力量
从 V3 的横空出世到 V4 的效率革命,DeepSeek 始终坚持将最顶级的技术通过开源分享给社区。
DeepSeek-V4 的上线,不仅是技术参数的跳跃,更是对「百万长上下文」和「高性能 Agent」这两大未来趋势的有力回应。
它证明了通过架构创新,我们可以在不牺牲性能的前提下,极大降低大模型的门槛。
现在,你可以在官方 App 或 chat.deepseek.com 立即开启 1M 上下文的全新体验。
这不仅仅是一个对话框,这是一个能装下整部百科全书、能理解万行代码逻辑的「第二大脑」。
参考资料: