我第一次写 HK-Skills 的时候,问题很明确:Skill 越装越多,全局上下文越来越多。
Agent 的能力本来应该按任务调度,但实际用起来很容易变成另一种混乱:看到一个有用的 Skill 就装,装完就全局启用。短期看很方便,长期看会变成负担。一个项目明明只需要写文章、生成配图和发布公众号,Agent 却同时背着代码审查、部署、论文分析、Web 设计、Git 工作流等一堆无关说明。上下文变重以后,触发变得不稳定,使用者也很难记住自己到底装了什么。
所以第一版 HK-Skills 的目标很简单:把 Skill 集中管起来。
当时我参考了用 symlink 管理 Skill 的方式,把远程 Skill 拉下来,再用软链接暴露给 Agent。这个方案解决了"不要到处复制文件"的问题,但很快又暴露出新的问题:仅仅把文件链接起来还不够。Skill 不是静态文件,它有来源、版本、适配状态、启用范围、触发方式、更新风险,也可能是自己写的本地工作流。如果这些信息只藏在目录名里,系统迟早会失控。
这也是我后来继续升级 HK-Skills 的原因。
我的设想中它不只是 Skill 管理器,也可以通过它管理 Skill 的生命周期。
第一版解决的是"放哪里",第二版解决的是"怎么长期好用"
第一版的核心变化,是从手工目录切到分层目录:
text
registry/
manifests/
warehouse/
runtime/
bin/hk-skill这个结构解决了一个基础问题:远程原始 Skill、本地原创 Skill、适配后的 Skill、真正启用的 Skill,不能混在一起。
但真正开始高频使用以后,我发现问题又往前走了一步。Skill 管理的难点不是"有没有地方放",而是下面这些问题:
- 我怎么知道当前有哪些 Skill?
- 哪些是远程拉来的,哪些是我自己写的?
- 哪些已经适配,哪些只是草稿?
- 哪些全局启用了,哪些只对某个项目启用?
- 远程 Skill 更新以后,本地适配会不会被覆盖?
- 一个项目到底应该暴露哪些能力给 Agent?
- 我平时反复使用的工作方法,能不能沉淀成 Skill,而不是每次重新提示?
这些问题如果不解决,Skill 越多越难管控。
所以第二轮升级的重点,不是多加几个命令,而是让 HK-Skills 从"安装工具"变成"工作流资产管理系统"。
核心设计一:安装不等于启用
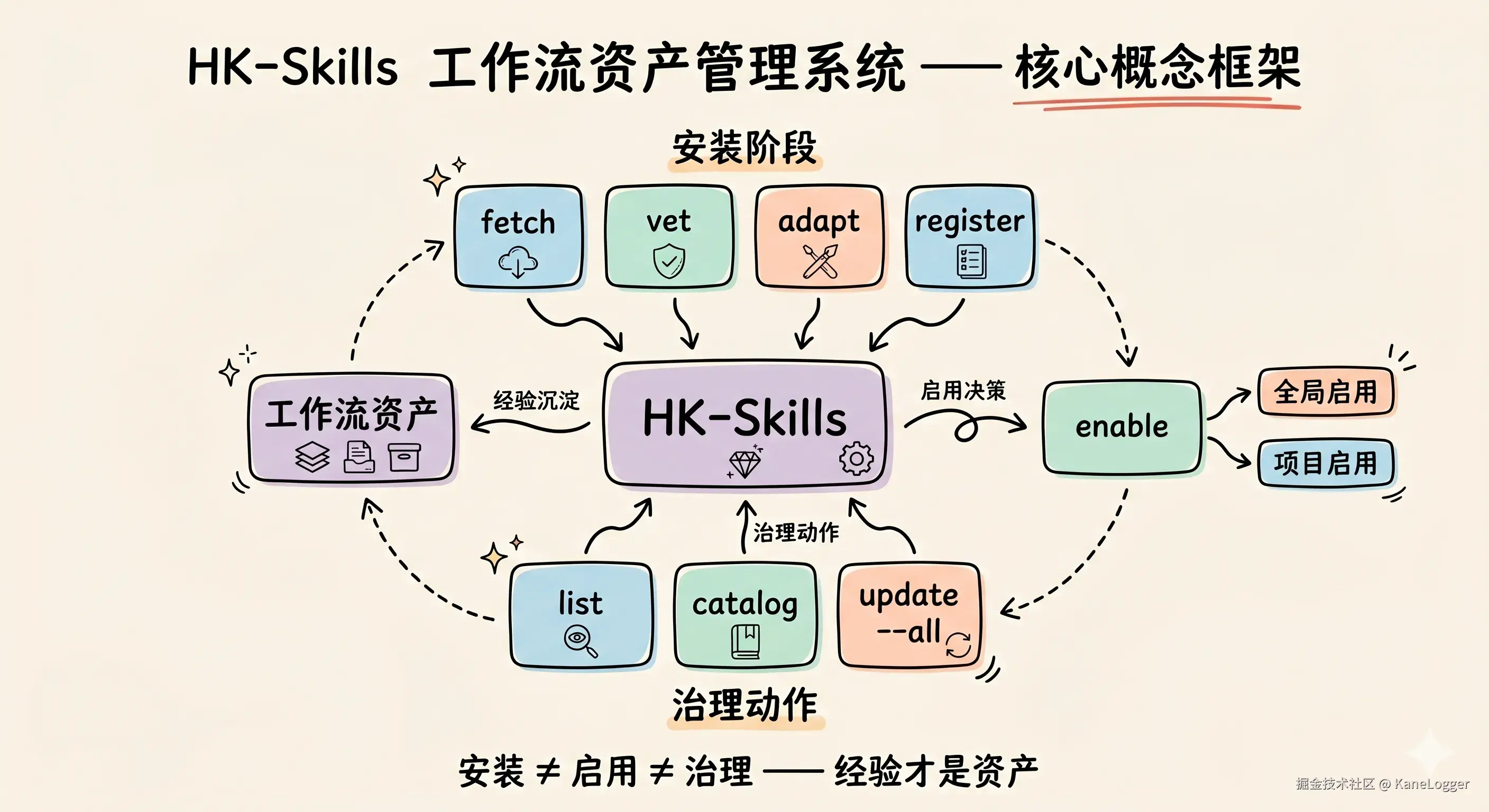
这是 HK-Skills 里最重要的边界。
一个 Skill 被安装,只代表它进入了本地仓库;只有被启用,它才进入 Agent 的可见上下文。
这听起来像一个很小的设计,但对实际使用影响很大。因为 Agent 的上下文不是垃圾桶,不能什么都塞进去。Skill 的价值在于"需要时可用",不是"永远挂在全局"。
现在 HK-Skills 的安装流程是:
text
fetch -> vet -> adapt -> register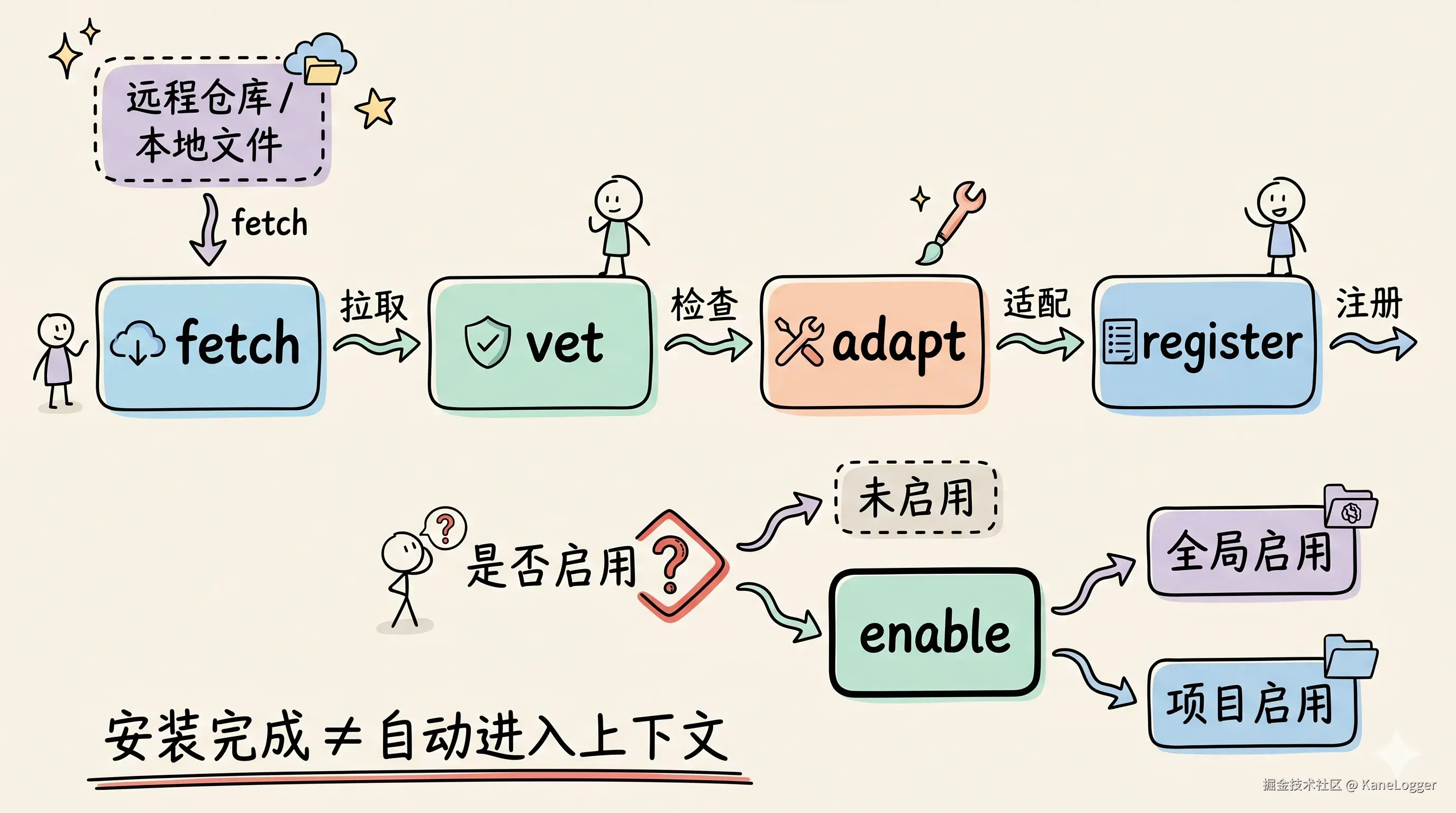
对应到实现上:
fetch负责拉取远程仓库,或者复制本地 Skill。vet负责做基础安全检查,确认SKILL.md和 frontmatter 合法。adapt负责生成适配后的副本和 manifest。register负责写入 registry,让系统知道这个 Skill 的状态。
安装完成以后,它仍然可以保持未启用状态。等某个项目需要它,再执行:
bash
./bin/hk-skill enable <skill-name> --project /path/to/project这样 Skill 会出现在目标项目的:
text
<project>/.agents/skills/<skill-name>/SKILL.md这才是面向 Agent 的真实入口。
这个设计让我从"机器上装了什么 Skill",切换到"这个项目需要什么能力"。前者是囤积,后者是配置。
核心设计二:目录只是存储,状态必须由元数据管理
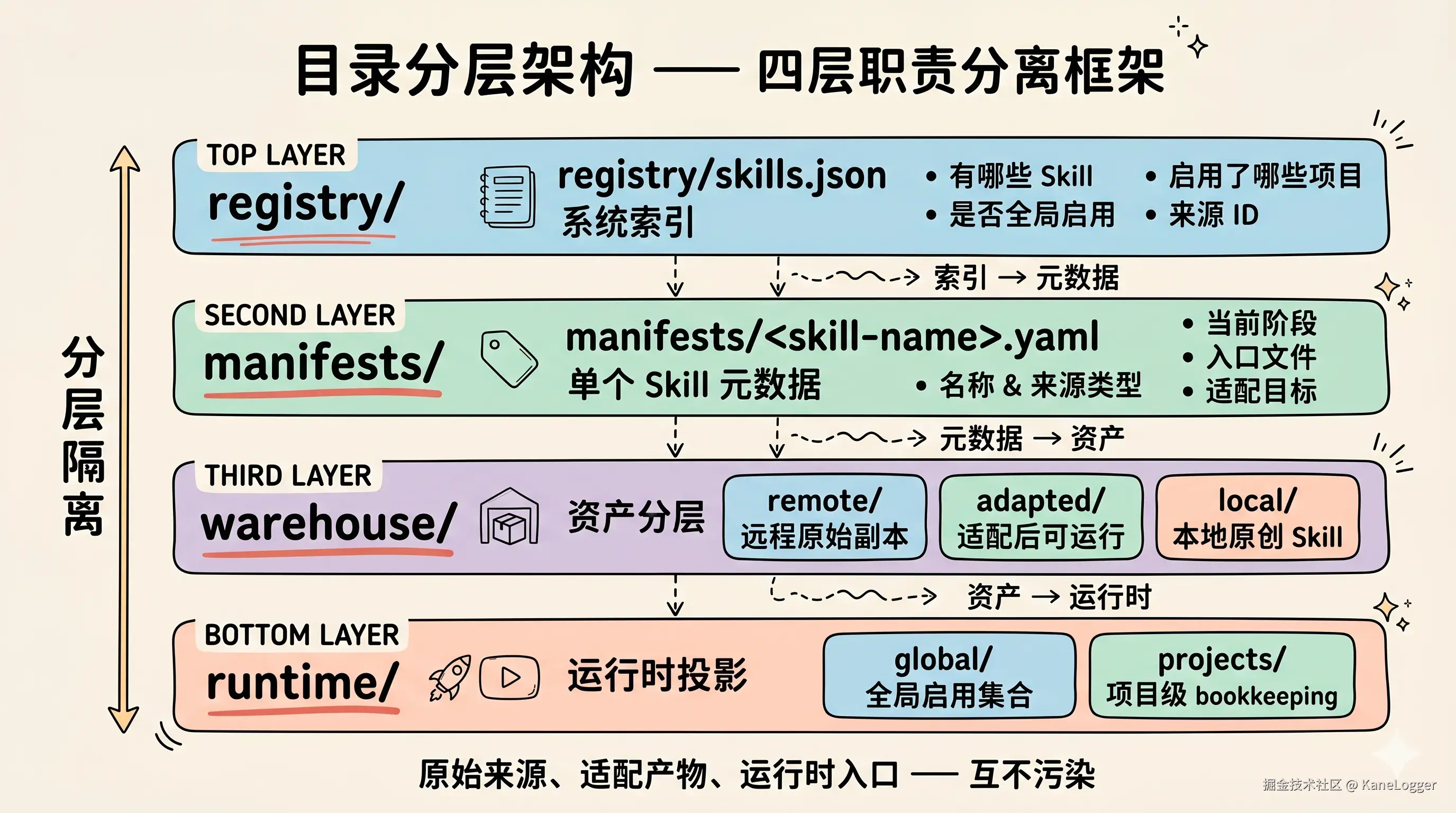
早期我用目录区分状态:
text
custom/
remote/
skills/这个设计直观,但不够稳。因为目录只能表达"文件在哪里",不能表达"系统怎么看待它"。
现在 HK-Skills 用 registry 和 manifest 做状态管理。
registry/skills.json 解决的是系统索引问题:有哪些 Skill、是否安装、是否全局启用、启用了哪些项目、来源 ID 是什么。
manifests/<skill-name>.yaml 解决的是单个 Skill 的元数据问题:它叫什么、来源类型是什么、当前阶段是什么、入口文件是什么、适配目标是什么。
warehouse/ 解决的是资产分层问题:
text
warehouse/remote/ # 远程原始副本,尽量保留上游原貌
warehouse/adapted/ # 适配后的可运行版本
warehouse/local/ # 自己写的本地 Skillruntime/ 解决的是运行时投影问题:
text
runtime/global/ # 全局启用集合
runtime/projects/ # 项目级 bookkeeping这套分层的好处是:原始来源、适配产物、运行时入口互不污染。
远程仓库更新了,不会直接覆盖当前运行版本;本地原创 Skill 不会和远程缓存混在一起;项目启用的 Skill 也不会被误认为"全局可用"。
核心设计三:项目优先,全局极简
我现在更倾向于把 Skill 当成项目配置,而不是机器配置。
全局只放少数高度通用的基础能力,比如:
prompt-optimizer:把模糊需求编译成可执行 Prompt。session-achieve:复盘多轮对话,把纠偏经验沉淀成黄金提示词。blog-checker:审阅中文技术文章质量。
其他大部分 Skill 更适合跟项目走。
比如内容生产集中在 kane_inbox,它需要翻译、URL 转 Markdown、文章配图、封面图、信息图、公众号发布、小红书图片、PPT 生成等能力。这些 Skill 对内容项目非常有用,但对代码项目未必应该默认出现。
再比如知识库项目可能更需要文章分析、资料整理、Obsidian 管理。Web 项目才需要 Web 设计、浏览器测试、部署和前端工程能力。
项目级启用让 Agent 的上下文变得更干净。它不是"能力越多越好",而是"当前项目只暴露必要能力"。
核心设计四:更新必须可回滚,目录必须可生成
Skill 一旦变多,另一个问题就会出现:你不可能记住每个 Skill 的来源、状态和用法。
所以 HK-Skills 增加了几个治理动作。
list 用来查看当前安装和启用状态:
bash
./bin/hk-skill list它回答的是"现在系统里有什么,以及启用在哪里"。
catalog 用来生成可读目录:
bash
./bin/hk-skill catalog这个目录不是给机器看的 registry,而是给人看的 Skill 总览。它应该按使用场景分类,保留触发关键词,并区分启用和未启用状态。对我来说,这一点很重要。因为 Skill 的问题不只是安装,还包括"我记不记得它存在"。
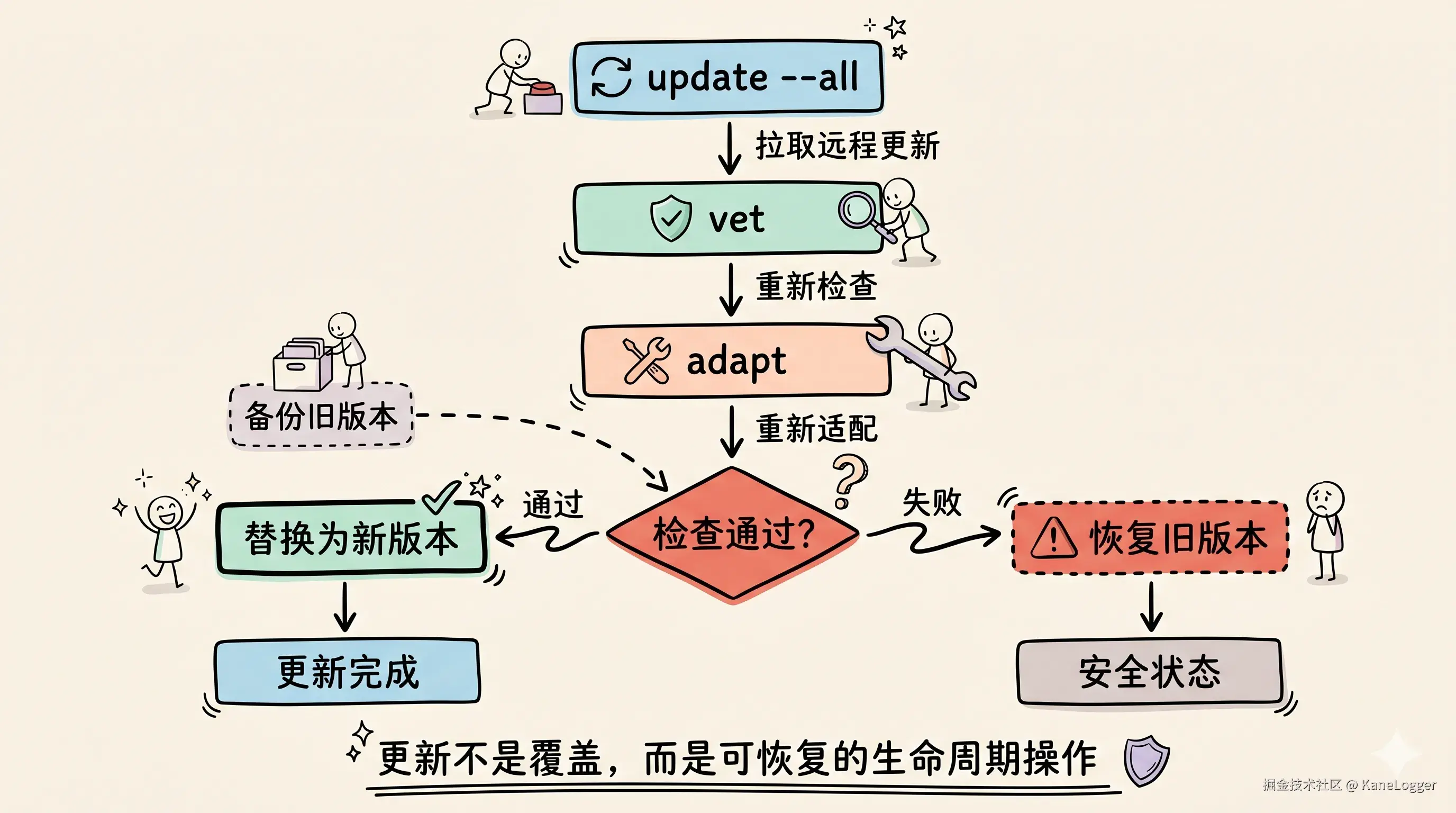
update --all 用来更新远程 Skill:
bash
./bin/hk-skill update --all更新流程里有备份和回滚。远程拉取以后,仍然要重新走 vet 和 adapt。如果检查或适配失败,就恢复旧版本。这样 Skill 更新不再是一次危险的覆盖动作,而是可验证、可失败、可恢复的生命周期操作。
这也是 HK-Skills 和简单 symlink 管理最大的区别之一。symlink 解决的是路径问题,生命周期管理解决的是长期维护问题。
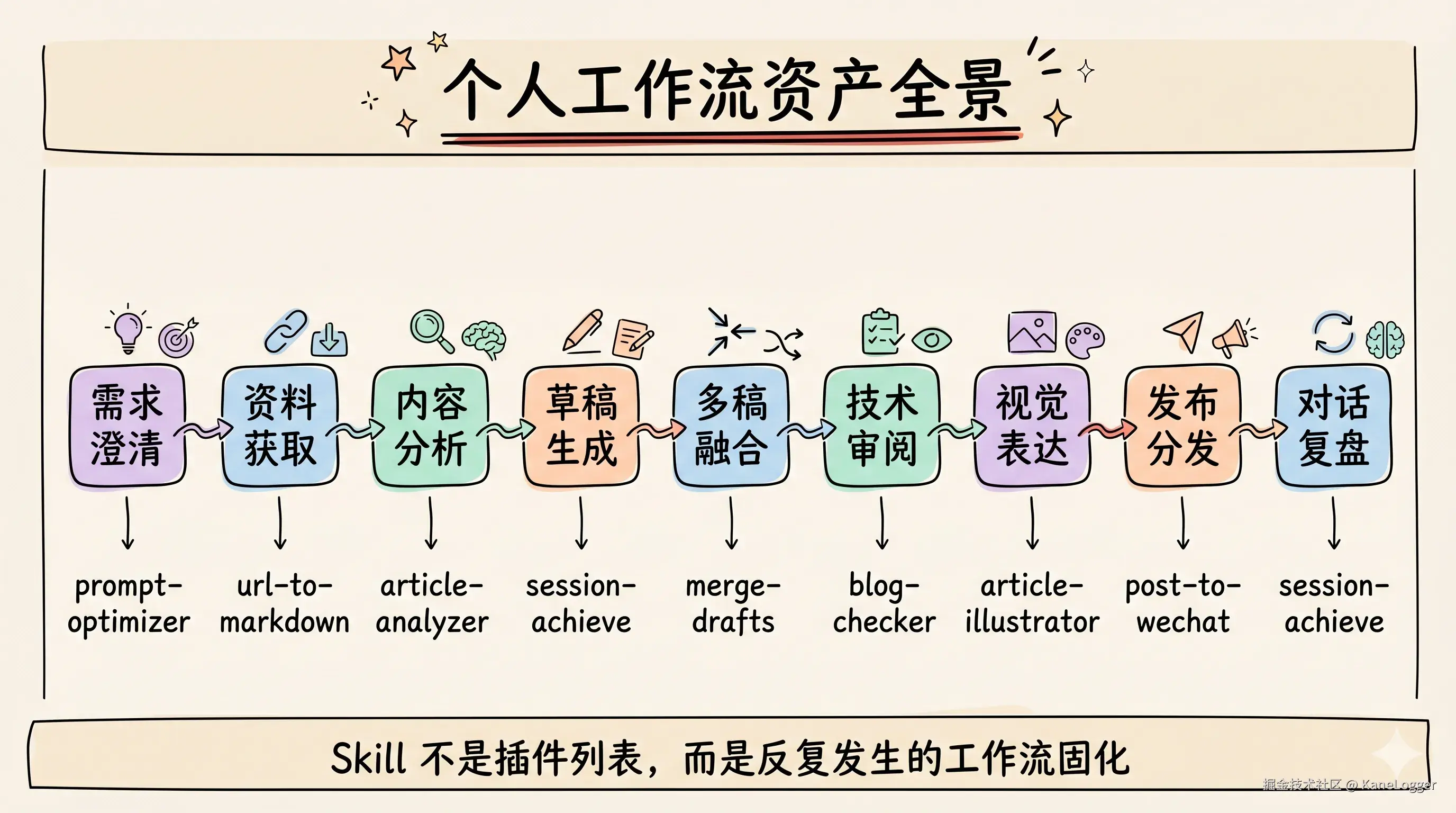
我常用的 Skills,其实是我的工作流资产
这一轮升级以后,我对 Skill 的理解也变了。
Skill 不是"给 Agent 增加一个功能"这么简单。更准确地说,Skill 是把一段反复发生的工作流固化下来。
我现在最常用的几类 Skill,基本都对应我自己的高频工作。
prompt-optimizer
解决的是需求编译问题。很多时候,我并不是缺一个答案,而是缺一段能稳定驱动模型完成任务的指令。这个 Skill 会把模糊需求整理成结构化 Prompt,补齐目标、边界、成功标准和输出格式。

session-achieve
把一段多轮对话中的初始目标、实际产出、偏差、纠偏节点和隐性偏好,整理成一份可复用的复盘资产,并沉淀出下一次可以直接使用的「黄金提示词」。

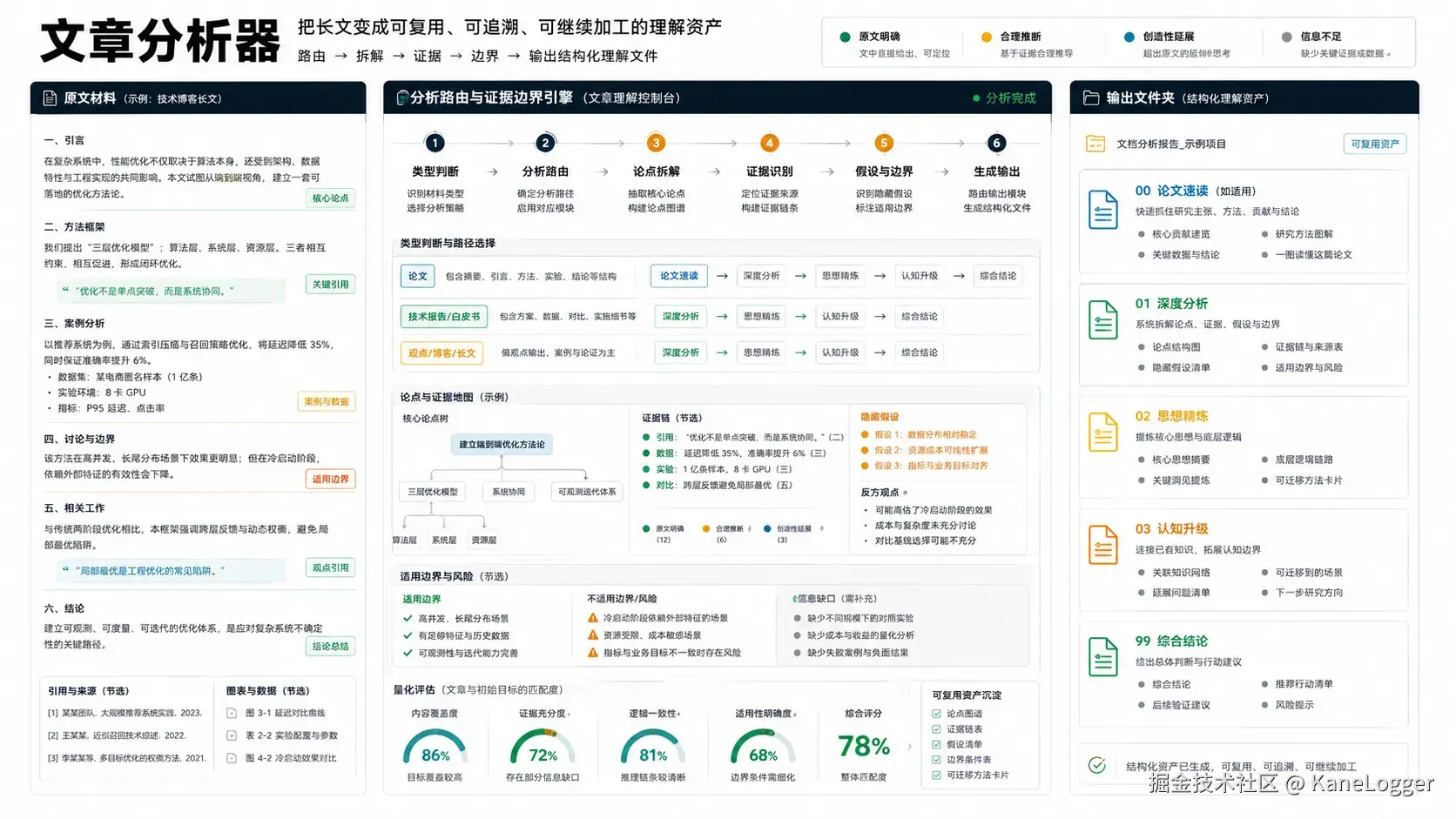
article-analyzer
解决的是深度阅读问题。它不是简单总结文章,而是把文章、论文、报告拆成结构化理解包:主线、证据、隐含假设、可迁移模型、认知升级。适合用来处理长文、论文和复杂观点。
merge-drafts
解决的是多稿融合问题。多篇草稿放在一起,最差的做法是拼接。这个 Skill 会先评估各稿结构、覆盖、表达和独特价值,再选底稿,把其他稿子的亮点融合进去。

blog-checker
解决的是技术文章审阅问题。它按问题驱动、技术脉络、方案对比、推导过程、原理方法论和资料来源六个维度检查文章。这个标准能避免技术文章写成"概念罗列"。

这些 Skill 放在一起,本质上不是一个插件列表,而是一套个人工作系统:
text
需求澄清 -> 资料获取 -> 内容分析 -> 草稿生成 -> 多稿融合 -> 技术审阅 -> 视觉表达 -> 发布分发 -> 对话复盘HK-Skills 的价值,就是让我能把这套系统装进本地项目,而不是每次从零开始教 Agent。
这轮升级给我的启发
第一版 HK-Skills 解决的是"Skill 怎么管理"。
第二版 HK-Skills 让我更明确地意识到:真正值得管理的不是 Skill 文件,而是工作流经验。
一个好用的 Agent 系统,不能只靠更强的模型,也不能只靠更长的上下文。模型会变,工具会变,但你自己的工作方法、判断标准和交付流程会不断积累。Skill 是这些经验的载体。
所以 HK-Skills 的方向不是做一个花哨的插件市场,而是做一个本地的、可控的、项目优先的工作流资产管理工具。
它要解决的是三个长期问题:
第一,能力不能污染上下文。安装和启用必须分开,项目应该只暴露自己需要的 Skill。
第二,经验不能散落在对话里。高频工作流应该沉淀成可复用的 Skill,而不是每次重新提示。
第三,资产不能失去治理。来源、状态、适配、更新、启用范围,都应该进入 registry 和 manifest,而不是靠人脑记忆。
这也是我觉得 HK-Skills 变得更好用的地方。它不再只是帮我管理一堆 SKILL.md,而是在帮我管理自己和 Agent 协作的方式。