时序数据库选型指南:从大数据架构看,为什么越来越多企业关注 Apache IoTDB
当企业开始建设实时数据平台时,最容易低估的一类数据,就是时序数据。设备测点、传感器指标、工业控制信号、能源负荷、车联网遥测、运行日志指标,看上去都只是"带时间戳的数据",但当数据规模进入亿级、十亿级甚至更高量级之后,问题就不再是"能不能存",而是"能否持续高效地写、低成本地存、按时间语义高效地查,并且在生产环境里稳定跑下去"。
这也是为什么时序数据库在近几年逐渐从细分工具,变成大数据平台中的关键基础设施。尤其在工业物联网、能源电力、交通运输、智慧园区等场景中,企业越来越倾向于将时序数据从通用数据库或临时拼装方案中剥离出来,交给专门的时序数据库处理。在这个背景下,Apache IoTDB 之所以持续受到关注,并不是因为它只是一个"国产替代"选项,而是因为它在大规模时序数据管理所关注的几个核心维度上,给出了一套相对均衡、且更贴近企业场景的答案。
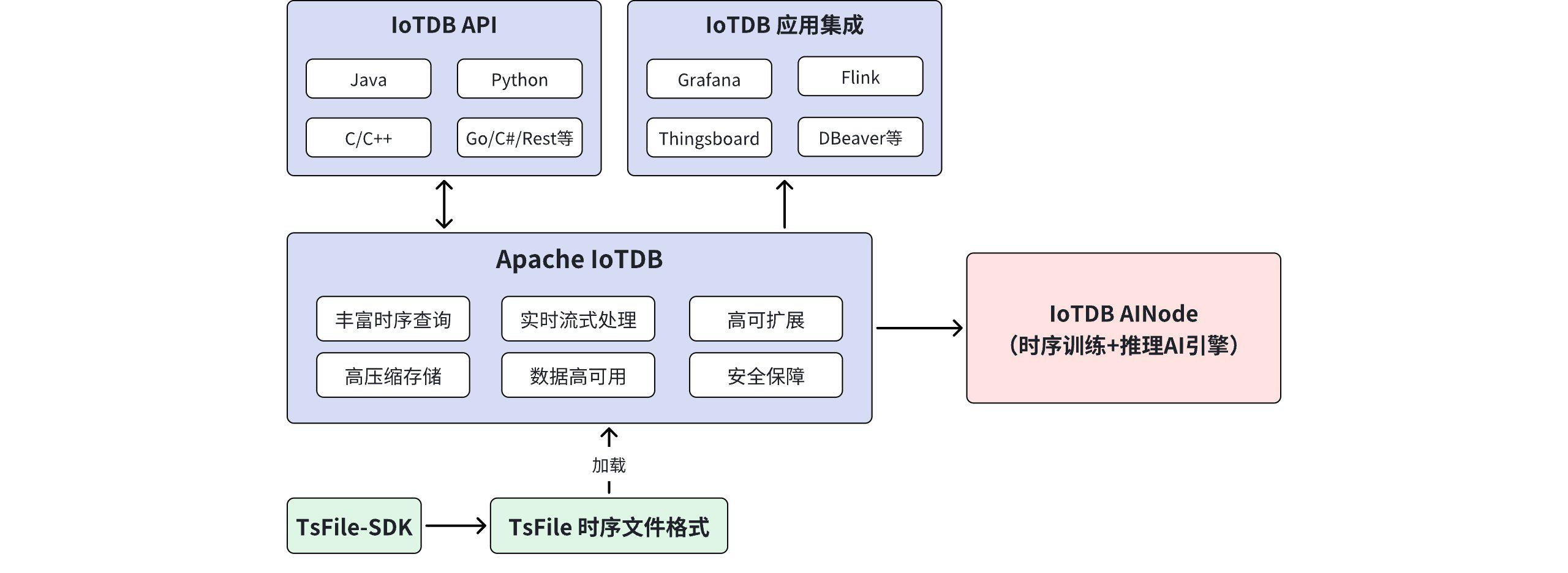
一、为什么大数据场景下要单独做时序数据库选型
很多企业在项目早期,习惯先用通用关系型数据库、NoSQL 数据库,或者对象存储加离线计算的组合来承接时序数据。这种方式在规模不大时没有明显问题,但一旦进入真实生产环境,就会逐步暴露出几个典型矛盾。
第一,写入压力与数据密度会迅速上升。时序数据天然具有持续追加、高频写入、多源并发的特征,设备数量一多、采样周期一缩短,写入压力就会呈指数级放大。第二,数据并不是写进去就结束了,企业往往还要求长期留存、冷热分层、按周期聚合、按设备回放、按窗口分析,这意味着存储成本与查询语义要同时被考虑。第三,时序场景并不只是"按主键查一条记录",而是需要对齐查询、降采样、时间窗口聚合、最近点查询、异常点定位等原生时序能力。第四,在工业、能源、交通等场景里,系统还要面对边缘端资源有限、网络条件复杂、跨区域部署、高可用要求高等现实约束。
从国际市场的发展路径看,时序数据库已经是一个独立赛道。无论是面向监控指标、工业采集还是车联网遥测,企业最终都要回到同一个问题:这个数据库是否真正为"时间序列"设计,而不是把时序数据勉强塞进别的数据库模型里。也正因为如此,时序数据库选型不能只看单点性能指标,而要放回整个大数据架构与业务生命周期中去评估。
二、企业做时序数据库选型,建议重点看这 6 个维度
1. 写入吞吐与海量设备接入能力
时序数据库首先要解决的是"写得进"。如果数据库无法稳定承接高频写入、乱序写入、多设备并发写入,那么后面的查询、分析和应用都会失去基础。对于工业场景和物联网场景而言,选型时应重点关注系统是否能够支撑大规模设备接入,是否适合持续追加型写入模式,以及在弱网、边缘侧、批量导入等复杂条件下是否还能保持稳定。
2. 存储压缩与长期留存成本
时序数据最大的现实压力之一,不是写入,而是长期保存。很多项目上线半年之后,存储成本才真正成为瓶颈。一个真正适合大数据场景的时序数据库,必须在文件格式、压缩策略、冷热数据管理、历史数据归档方面具备成熟能力,否则系统越运行越贵,越积累越难管。
3. 查询分析能力是否贴合时序语义
企业在选型时容易高估"通用 SQL 能力",低估"时序语义能力"。对时序数据来说,时间对齐、窗口聚合、降采样、最近点分析、跨设备时间维比对,往往比简单的条件过滤更重要。数据库如果没有对这些需求做原生支持,业务层就需要自己拼逻辑,不仅复杂,而且性能不稳定。
4. 集群扩展性与高可用能力
当系统从 PoC 走向生产,单机是否能平滑演进为集群,集群是否具备容错能力,扩容是否会影响业务连续性,就会成为决定性因素。时序数据库不能只在实验环境里跑得快,还要能够在生产环境里长期稳定运行。
5. 与大数据生态的协同能力
时序数据库不是孤立存在的。企业通常还需要对接 Spark、Flink、Hadoop、Grafana,或者对接采集工具、可视化平台、算法平台和上层业务系统。一个好用的时序数据库,不能只把数据"锁"在库里,而要能顺畅进入企业现有的大数据链路。
6. 运维复杂度与企业落地成本
最后一个容易被忽略但非常关键的维度,是运维和交付成本。很多产品在实验室里表现不错,但一到现场部署、参数调优、故障定位、跨环境迁移、权限治理和团队培训阶段,实际使用门槛就会急剧上升。真正适合企业落地的产品,不仅要技术上成立,还要让交付团队、运维团队、业务团队能用得起来。
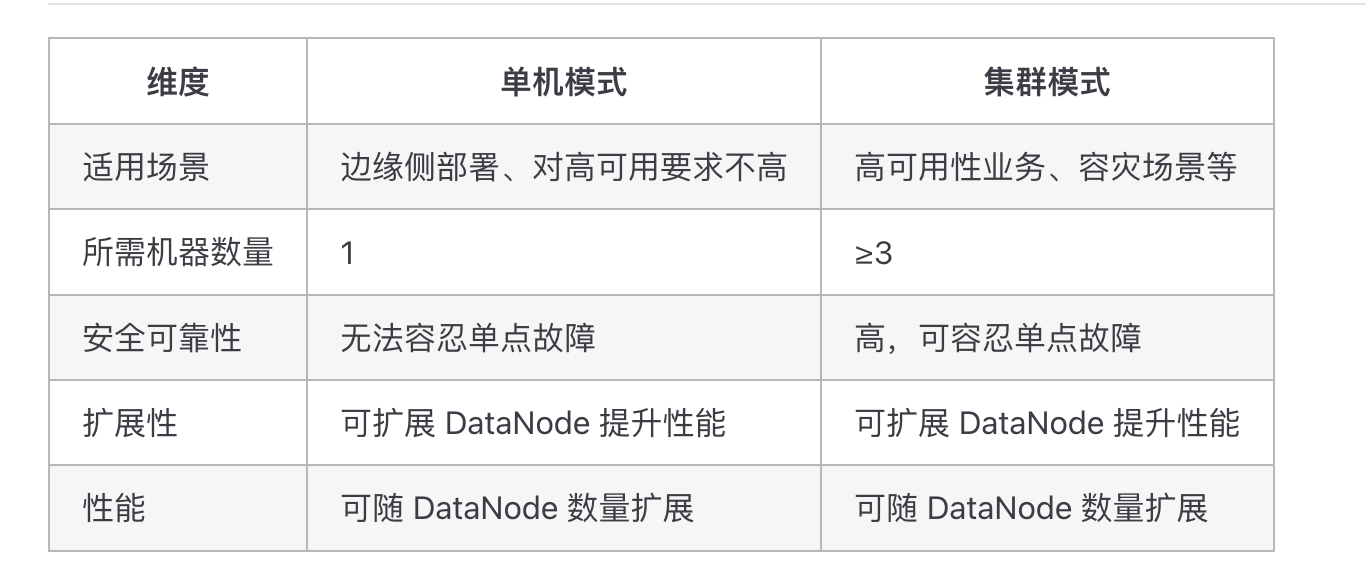
三、为什么说 Apache IoTDB 是一个值得重点关注的选项
如果把上面的 6 个维度放在一起看,Apache IoTDB 的优势不在于某一个点特别"激进",而在于它对大规模时序数据管理的关键问题覆盖得比较完整。
首先,从架构层看,IoTDB 并不是一个只适合单机场景的小型数据库。根据官方文档,IoTDB 支持单机模式和集群模式,单机实例可以采用 1 个 ConfigNode 加 1 个 DataNode 的 1C1D 形态,而企业级场景可以采用 3 个 ConfigNode 加不少于 3 个 DataNode 的 3C3D 集群模式。官方文档同时给出的集群概念说明表明,IoTDB 围绕 ConfigNode、DataNode、多副本与分区机制来构建高可用和可扩展能力。这意味着 IoTDB 在设计上就是朝着海量设备、分布式扩容和生产级稳定运行去建设的,而不是后期补丁式扩展。
其次,从存储和模型层看,IoTDB 对时序数据的"原生性"比较强。官方产品介绍中提到,IoTDB 体系不仅包含数据库本身,还包含 Apache TsFile 这一面向时序数据设计的标准文件格式。对企业来说,这意味着其底层并不是把时序数据简单映射到通用存储结构里,而是围绕时间序列的读写、压缩、管理和分析进行系统设计。对于需要长期保存海量历史数据的场景,这一点非常关键。
再次,从查询和场景能力看,IoTDB 支持时间对齐查询、时间维度聚合、降采样等典型时序语义。官网和文档也多次强调其面向复杂组织结构设备的层级化管理能力,这对于工业测点、生产装置、站点设备树这类典型结构非常重要。很多企业真正的难点不是"数据有没有",而是"海量测点能不能被清晰建模和快速检索",这一点恰恰是 IoTDB 的强项之一。
再往上看大数据生态能力,IoTDB 官网明确提到支持 Hadoop、Spark、Flink、Grafana 等生态集成。这意味着它并不只是一个独立的数据终点,而是可以作为企业实时分析、可视化、批流一体处理链路中的一环。对于已经有数据平台体系的企业,这种兼容性会直接影响后续建设成本。
最后,IoTDB 的应用场景覆盖也比较说明问题。官网中展示了能源电力、航空航天等行业案例,这些场景的共同点是数据量大、实时性强、稳定性要求高、业务链条长。一个产品能否在这些场景中站得住,往往比实验室里的单次 benchmark 更能说明其工程价值。

四、从开源试用到企业级生产落地,IoTDB 与 Timecho 如何衔接
从选型路径上看,Apache IoTDB 的一个现实优势,是它非常适合作为企业时序数据库建设的起点。技术团队可以先从开源版本切入,验证数据模型、写入链路、查询语义和与现有平台的集成方式,再逐步评估是否进入更高要求的生产建设阶段。开源安装包下载地址可直接使用官方页面:https://iotdb.apache.org/zh/Download/。
但当项目进入正式生产,企业关心的问题会发生变化。此时除了数据库本身,还会关注更强的性能和稳定性保障、更完善的可视化运维工具、更系统的原厂支持、企业级交付与服务能力。这也是为什么很多企业在开源验证之后,会进一步关注基于 Apache IoTDB 的企业版能力。
从官方资料看,Timecho 提供的是基于 Apache IoTDB 的企业级产品与服务体系。IoTDB 官方产品介绍页面也直接给出了 Timecho 官网入口,并说明其提供商业化产品 TimechoDB。Timecho 官网则进一步展示了企业级能力的承接方式,例如可视化控制台 Workbench、系统监控面板、原厂技术支持服务,以及面向能源、电力、交通、航空航天、智慧物联等行业的解决方案。对企业来说,这种衔接关系意味着可以先从开源版本快速验证,再按项目阶段决定是否引入企业版能力,而不需要在一开始就把技术路线与商业路线割裂开。
这类路径对企业尤其重要。因为真正成熟的数据库选型,往往不是一次性"拍板",而是要兼顾试点验证、正式上线、规模扩张和长期运维四个阶段。如果一个产品能够同时提供开源入口、清晰架构、生态兼容能力,以及企业级升级路径,那么它在选型中的实际可用性就会更高。
五、结语:时序数据库选型,核心不是"谁更火",而是谁更适合生产体系
时序数据库选型,本质上不是选一个"能存时间戳数据"的数据库,而是在为企业未来几年的数据基础设施做决策。尤其在大数据场景中,真正决定成败的,从来都不是单一指标,而是写入能力、压缩成本、查询语义、扩展性、生态协同和运维复杂度之间的整体平衡。
如果企业当前还处在验证期,那么 Apache IoTDB 是一个值得优先试用的方向:架构清晰、场景适配度高、生态连接能力强,并且有明确的开源入口。如果企业已经进入生产建设和规模化运营阶段,那么在 Apache IoTDB 的基础上继续评估 Timecho 这样的企业版路线,也是一条更符合真实落地逻辑的选择路径。
归根到底,时序数据库的价值,不只是把数据存下来,而是帮助企业以更低成本、更高效率、更强稳定性,把持续增长的时间序列数据真正变成可管理、可分析、可应用的数据资产。
参考入口
- Apache IoTDB 开源下载:https://iotdb.apache.org/zh/Download/
- Apache IoTDB 官网:https://iotdb.apache.org/zh/
- IoTDB 产品介绍:https://iotdb.apache.org/zh/UserGuide/latest-Table/IoTDB-Introduction/IoTDB-Introduction_apache.html