具身智能与视频理解领域一直有个核心难题,即如何让AI像人类一样,直接看无标注的真实视频,就能学会折纸、机器人操作这类复杂长时程技能,并且能够泛化到新环境?字节跳动Seed实验室联合北京交通大学提出了VideoWorld 2模型,首次研究了直接从原始真实世界视频中学习复杂长时程任务可迁移知识的问题。其核心贡献是提出动力学增强的隐式动力学模型(dLDM),将动作动力学与视觉外观解耦。首先,由预训练的视频扩散模型负责视觉外观建模,使dLDM能够学习聚焦于紧凑且有意义的任务相关动力学的隐式编码。随后,对这些隐式编码进行自回归建模,以学习任务策略并支持长时程推理。
论文链接:https://arxiv.org/abs/2602.10102
项目链接:https://VideoWorld2.github.io/
本推文由邓镝撰写,审核为韩煦。
一、研究背景
当前的人工智能模型主要从大规模文本数据中学习知识。然而,仅靠文本无法完整捕捉真实视觉世界的丰富信息,包括世界动力学、空间关系和底层物理规律。相比之下,自然界中的动物可以直接从视觉信号中获取知识,并将其泛化以解决不同场景下的任务。例如,儿童可以使用不同的纸张材料,复现视频中演示的折纸技能,而无需任何语言指导。鉴于互联网上存在海量的视频内容,使人工智能模型能够从原始视频数据中学习可泛化的知识,对于扩大其知识获取规模、提升其在真实世界和数字环境中有效执行任务的能力具有重要意义。
真实世界视频具有显著的视觉多样性、复杂的动作动力学,并且通常涉及长时程、多步骤的交互。这些特性使得已有的训练方法和模型设计无法直接应用于真实场景,这自然引出了以下问题:人工智能模型能否直接从未标注的真实世界视频中,学习复杂长时程任务的可迁移知识?
针对上述问题,该论文提出了VideoWorld 2,旨在通过显式解耦外观建模与动作学习来鲁棒地获取知识,其核心贡献如下:
-
首次研究了直接从原始真实世界视频中学习复杂长时程任务可迁移知识的问题,发现解耦动作动力学与视觉外观建模是有效知识获取的关键。
-
提出了动力学增强的隐式动力学模型(dLDM),将任务相关动力学与视觉外观解耦,显著提升了手工制作和机器人操作任务中所学知识的质量和可迁移性。
-
引入了Video-CraftBench,一个新的基准,旨在解决真实世界手工任务中细粒度、长时程视觉推理这一尚未被充分探索的挑战,为未来直接从原始视频中学习可迁移知识的研究奠定了基础。
二、研究方法
本部分将介绍VideoWorld 2的架构设计。VideoWorld 2整体架构被分为了训练阶段和推理阶段,如图1所示。
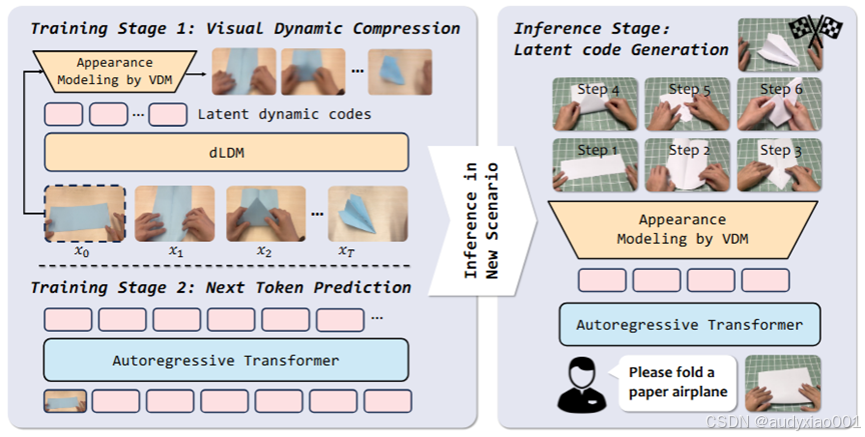
图1 VideoWorld 2模型架构总览。(左)首先,dLDM将未来的视觉变化压缩为紧凑且可泛化的隐式编码。随后,这些编码由自回归Transformer进行建模。(右)在推理阶段,Transformer根据输入图像为全新的、未见过的环境预测隐式编码,这些编码随后被解码为任务执行视频
2.1 从未标注视频中学习知识
一段视频可以被视为一个演示轨迹,它捕捉了世界状态转换和底层动作策略,这些构成了需要学习的知识。因此,论文提出使用生成式模型直接从视频中捕捉这些隐式策略和动作动力学,而无需依赖语言监督。
在训练的第一阶段,论文中采用主流的视频生成模型作为基础框架。它们通常使用VQ-VAE将视频编码为压缩表示,在该空间内执行生成过程以预测未来状态,然后解码回RGB域。然而,这些表示需要数千个离散token或连续嵌入来捕捉全部视觉信息,不可避免地导致时空冗余和知识分布稀疏。为了缓解上述局限性并促进知识学习,研究在之前的工作VideoWorld中引入了隐式动力学模型(LDM),将未来的视觉变化压缩为一组紧凑的隐式编码,有效捕捉多步动作的运动动力学。具体结构如图2所示。
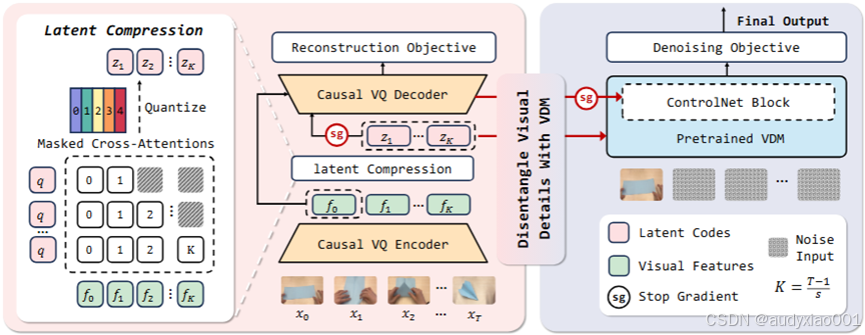
图 2 论文提出的动力学增强型隐式动力学模型( dLDM )。(左) VideoWorld 中的隐式动力学模型:将第一帧与后续帧之间的视觉变化压缩为一组隐式编码。(右) VideoWorld 2 提出的 dLDM :它采用预训练的视频扩散模型( VDM )作为外观先验,从而得到更优质的隐式编码,并支持高保真视频输出
编码器首先将输入片段映射为特征序列。接下来,它定义了多个可学习的查询嵌入,这些查询使用交叉注意力捕捉变化信息,生成其连续表示。然后对该表示进行量化,以防止LDM学习捷径。最后,解码器以因果方式重建后续帧。训练目标是最小化原始帧与重建帧之间的L2距离。这些嵌入被称为隐式动力学编码。虽然VideoWorld通过将时间动力学封装为紧凑的隐式编码,在合成环境中有效处理了长时程推理,但它在真实世界应用中仍然存在困难。论文中提到,这些局限性可能源于动作动力学与视觉外观的解耦不足,隐式编码捕捉了无关的视觉细节,如背景运动、光照变化、纹理和相机位移,使模型对环境变化敏感。
2.2 动力学增强的隐式动力学模型
为了解决这个问题,论文提出了动力学增强的隐式动力学模型(dLDM)。其核心机制是用预训练的视频扩散模型(VDM)替换原始的LDM解码器。通过利用VDM的高保真重建能力来处理外观建模,让LDM编码器和可学习的查询嵌入专门专注于捕捉任务相关的视觉变化。尽管VDM不包含任何目标任务动力学的知识,但一旦获得适当的动力学指导,它就能非常有效地生成真实的视觉内容,非常适合这种分解。具体而言,如图4右图所示,dLDM由将未来视觉变化编码为离散隐式编码的因果VQ-VAE,和重建高保真帧的预训练VDM组成。隐式编码通过投影层和因果交叉注意力提供给VDM。由于VDM处理外观建模,隐式编码无需编码细粒度的视觉细节,而是可以专注于捕捉任务相关的动力学。为了保持时间正确性,在VDM中强制执行因果注意力。
直接训练VDM从噪声生成未来帧会非常缓慢,并且容易产生错误的运动,因为它从未在长时程手工制作等目标任务上进行过训练。因此复用VQ-VAE解码器将隐式编码重建为低保真但富含运动的输出,提供手部运动和物体位移等粗略的时间线索。该信号通过一个梯度停止的、类似ControlNet的分支输入到VDM中。这稳定了训练,并允许VDM专注于细化外观而非从头推断运动。此外,解码器到隐式编码的梯度流被停止,以防止引入无关噪声。
在训练的第二阶段,如图1(左)所示,提取隐式编码后,论文使用自回归Transformer对隐式动力学序列进行建模。这些编码展平为一个序列,并训练Transformer基于初始帧和任务指令来预测它们。这使得模型能够学习复杂任务中的长期模式。
在推理阶段(图1右图),给定来自新的、未见过的环境的单个输入帧,Transformer基于其学习到的任务表示预测未来的隐式动力学,然后dLDM将它们解码为连贯的长时程执行视频。这使得VideoWorld 2能够将其学习到的动力学迁移到新环境,并执行超出训练期间观察到的扩展动作序列。
三、Video-CraftBench数据集
论文中引入了Video-CraftBench,这是一个第一人称视频教程数据集,涵盖五个长时程手工任务:折纸飞机、折纸船,以及用积木搭建塔/马/人。这些手工任务具有难以用语言描述的细粒度、视觉多样化的操作。研究团队通过手动录制和互联网资源收集了约7小时(分为约9.5k个片段)的教程视频,用于长时程知识评估。折纸任务通常持续40-80秒,积木搭建任务持续20-30秒。该基准分为训练集和测试集。测试集(约150个单独收集的视频)包含训练中未见过的新背景、纸张纹理和积木排列,以评估知识的可迁移性。
评估主要关注两个方面:关键动作的准确性和生成视频的视觉质量。评估指标包括:
(1)顺序任务成功率:将折纸分解为7个关键步骤(图3),并训练一个基于DINOv2的分类器来检测它们的完成情况。该分类器仅评估动作正确性,忽略外观一致性(例如与初始帧的外观漂移)。在评估时,为每个测试用例基于第一帧生成3个视频。一个步骤只有在所有前面的步骤都完成时才被视为成功,这能够评估长时程知识的获取。对于较短的积木搭建任务,训练了类似的分类器,但仅用于验证最终生成状态。
(2)视觉质量:使用标准的LPIPS和SSIM指标评估测试环境中的视觉质量,量化视觉保真度和与输入的内容一致性。

图3 Video-CraftBench数据集概览以及折纸任务的核心步骤
四、实验
4.1 实现细节
采用NVIDIA Cosmos AR 4B模型作为自回归Transformer,将其下一个token预测能力重新用于预测隐式编码。对于外观先验,使用Cosmos DiT 2B模型,利用其高保真的图像转视频能力生成93帧(16fps下约5秒)、480px分辨率的视频。dLDM默认也处理93帧的片段,使用大小为1000的词表和嵌入长度N=4。为了提高训练效率,dLDM首先进行短期预热,仅使用原始重建目标优化隐式编码。
4.2 基准和基线
1.基准
在两个基准上评估,具体如下:
(1)Video-CraftBench评估从具有细粒度动作的长时程真实世界任务中学习的能力
(2)对于机器人任务,在大规模OpenX数据集上训练我们的隐式表示,并测试其向CALVIN的知识迁移。CALVIN包含34个任务,并使用与折纸设置类似的长时程顺序评估协议:模型必须完成一个5任务序列,其中成功取决于所有前面的任务。
2.基线
为了证明VideoWorld 2的有效性,建立了三个基线,在上述基准上进行对比分析。
(1)预训练视频生成模型:选择四个最先进的视频生成模型:NVIDIA Cosmos AR 4B、NVIDIA Cosmos DiT 2B、Wan2.2 14B和混元视频 13B。在Video-CraftBench上进行微调。还使用了Qwen2.5-VL 72B为每个关键步骤提供详细的语言注释以辅助生成。在推理时,这些模型基于初始图像和文本指令生成任务执行视频,然后基于它们自己的先前输出自回归生成后续视频片段。
(2)隐式动作模型:论文的方法与五个同时期工作进行比较。这些方法将帧间视觉变化压缩为隐式编码,作为操作任务的预训练目标,同时支持视频重建。
(3)VideoWorld:使用原始的隐式动力学模型进行视频知识学习。
4.3 在Video-CraftBench数据集上的实验结果
在表1中,首先评估了在Video-CraftBench上微调的预训练视频生成模型(第1-4行)。虽然这些模型在折纸任务的第一步取得了较高的成功率,在积木堆叠任务中达到了38%,但对于完整的、时长数分钟的序列,它们的性能迅速恶化。到折纸的第4步(第7列),成功率降至≤10.6%,并且完全无法生成后续步骤。至关重要的是,即使在训练和推理期间为每个步骤提供了详细的文本描述以利用它们的文本条件能力,这种失败仍然存在。这表明当前模型难以从真实世界视频中学习复杂的长时程知识,凸显了对更有效范式的需求。
表1 在Video-Craftbench数据集上的对比
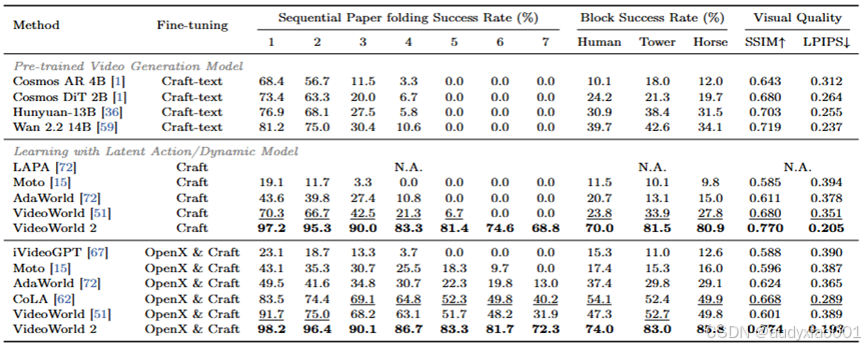
表中还评估了利用隐式动作或动力学模型的现有方法。在Video-CraftBench上训练这些基线,并训练AR Transformer来预测它们的隐式编码。注意,由于LAPA的结构限制,解码其编码为长时程序列会导致严重的性能下降,因此其结果标记为"N.A."。对于其他三个基线,Moto使用预训练的视觉编码器提取动力学,AdaWorld利用辅助扩散头进行视频合成,VideoWorld具有长时程动力学压缩和生成能力。尽管它们生成了连贯的视频,但无法泛化到新环境。具体而言,没有一个模型能够在新设置(如不同的桌面或纸张样式)下完成完整的折纸序列。
相比之下,VideoWorld 2(第9行)在测试环境中生成了完整且连贯的任务序列。值得注意的是,无需对这些隐式编码进行大规模预训练,仅在Video-CraftBench上训练就实现了68.8%的折纸任务成功率和高达81.5%的积木堆叠任务成功率。此外,得益于VDM的外观先验,VideoWorld 2不仅生成了准确的动作,还生成了具有更高SSIM和PSNR指标的视频。
为了评估VideoWorld 2的隐式编码是否能从更大规模的数据中受益,纳入了OpenX数据集,它包含大量的操作演示。与Video-CraftBench相比,OpenX具有多样化的机器人智能体和环境外观,是评估VideoWorld 2过滤智能体特定和环境因素同时扩展其动作提取能力的理想测试平台。首先在OpenX和Video-CraftBench的组合上训练dLDM和基线模型,然后使用得到的隐式编码仅在Video-CraftBench上训练AR Transformer。如表1第10-12行所示,基线模型的质量有所提高,所有任务的成功率都有所上升。然而,Moto和iVideoGPT仍然无法完成完整的折纸序列。虽然VideoWorld可以生成完整的序列,但其最后一步的成功率仍然很低。CoLA是一项同时期的工作,也使用VDM来优化隐式动作编码,但它仅限于短的2帧转换,并且忽略了来自粗糙VAE输出的结构化时间线索。采用CoLA的训练方案仅获得了40.2%的最后一步成功率。相比之下,VideoWorld 2在其基线性能的基础上进一步提升,实现了72.3%的折纸最后一步成功率和85.8%的积木堆叠成功率。
4.4 在CALVIN数据集上的实验结果
论文按照LAPA的协议进行了隐式预训练实验。首先在22k个CALVIN轨迹的隐式编码上预训练AR Transformer,然后仅在2k个真实动作标签上对其进行微调。如表2所示,与基线(第2行)相比,这种预训练策略显著提升了VideoWorld 2在长时程任务上的性能(第4行)。值得注意的是,其性能接近在22k个完整动作标签数据集上训练的模型(第1行),证明了高数据效率。虽然LAPA(第3行)也从该协议中受益,但它仍然落后于VideoWorld 2。
表2 在CALVIN数据集上的对比
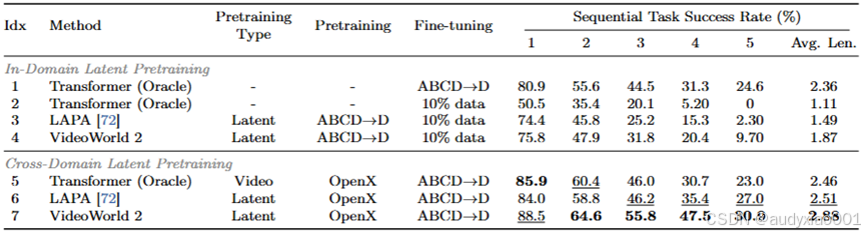
通过在1.3M OpenX数据集上预训练并在22k个CALVIN轨迹上微调,进一步评估了可迁移性。如表2所示,与仅在标注的CALVIN数据上训练(第1行)相比,这种预训练显著提升了LAPA(第6行)和VideoWorld 2(第7行)的成功率。与之前的发现一致,VideoWorld 2从这种预训练中在长时程任务上获益更多。研究团队还纳入了一个在OpenX上预训练的token预测基线(第5行)。结果表明,论文中的隐式预训练更有效,验证了它作为一种比直接在视频上预训练更高效的知识迁移范式。
五、结论
该论文通过在Video-CraftBench和机器人操作环境上的实验,探索了从原始视频中学习复杂长时程任务知识的问题。研究发现,将视觉外观与核心动作解耦是真实世界知识学习的关键。基于这一发现,提出了VideoWorld 2,该模型具有动力学增强的隐式动力学模型(dLDM),利用预训练的VDM直接从视频中学习通用的、可迁移的策略。虽然该方法显示出巨大的潜力,但其持续扩展将留给未来的工作,朝着使人工智能能够学习封装在真实世界中的海量知识的目标迈进。