上一篇文章里基于一个六维评估框架分析了三个主流智能体的对比,发布后获知"爱马仕"Hermes最具代表性的自进化架构,近期被中国AI团队EvoMap实锤抄袭自其开源引擎Evolver。
因此我们后续的相关研究,都以EvoMap今年2月开源的原作------AI Agent自进化引擎Evolver为标杆。本文纵向梳理从Manus、OpenClaw到Evolver的架构演进脉络,同时对标"企业级智能体"标杆Palantir,探索国内企业级AI落地与智能化转型的可行方向。
大模型从聊天到干活需要几步
上一篇文章的"智能体六问",其实就是在回答如何让大模型从对话框进入现实世界、从聊天到执行复杂任务。这个问题的核心,可以形象地理解为:如何将一个"学了许多课本知识、但清澈愚蠢的大学实习生",培养成"能解决现实问题、成熟干练的得力助手"。
去年DeepSeek在国内掀起开源大模型热潮时,网上涌现大量"提示词工程"教程,指导人们如何"调教"大模型、自主"养成"一个或多个个人AI助手。后来还火过一阵"上下文工程"------通过精心构造的上下文示例,让模型学会特定的推理路径和输出格式。
之所以会这样,是因为在大模型平台内,要让模型的输出符合预期,主要就靠对话框内的提示词和上下文。
但受限于大模型平台的功能定位,提示词和上下文只能解决"单次对话"或"单轮任务"中的行为引导问题。它们有几个天然局限:
-
一是无状态------每次对话都是新的,模型不会记住你上次教过它什么;
-
二是不可进化------你这次写了一个精妙的提示词,下次遇到类似场景,模型不会自动复用这个经验;
-
三是用户门槛高------写好一个稳定可靠的提示词,本身就是一门手艺。
智能体要做的,首先就是跨越这三大局限。
Manus:降低提示词的编写门槛
Manus通过PEV架构,将从自然语言到可执行计划的完整推理链路封装到了系统内。用户无需像面对实习生那样,在发出任务指令的同时还要手把手拆解动作、教他每一步怎么做。提示词从:
你是一个数据分析师,请按以下步骤:1.连接数据库 2.查询数据 3.计算指标 4.生成图表 5.撰写结论
简化为:
帮我分析销售数据
但Manus不会告诉你它是如何拆解的,整个推理链路是一个黑盒。用户只输入问题,等待输出结果,中间过程不可见、不可干预。
此外,Manus本质上仍然是无状态 的------每个任务独立,任务结束即销毁。由于每次任务都是从零开始,既没有跨任务的技能沉淀,也没有记忆蒸馏机制,因此不可进化。
OpenClaw:"调教"可配置化,跨会话记忆
OpenClaw以配置文件为核心,为用户提供了按需"调教"智能体的能力。用户可以通过三份 Markdown配置文件精准定义目标智能体:SOUL.md锚定智能体人格特质,USER.md明确用户画像与需求偏好,AGENTS.md规范智能体的行为边界与执行规则。
针对大模型"无状态"的痛点,OpenClaw设计了三层记忆架构:短期日志、近端会话存档、长期MEMORY.md,从而解决了传统对话框"一问一忘"的问题。用户的偏好、事实、历史决策会被跨任务、跨会话持久保留,避免重复设置。相比Manus等早期框架,这是一个显著的工程进步。
然而,OpenClaw看似让用户不需要学习复杂的提示词语法,但手动编辑.md配置文件又带来了新的技术门槛。这也是"龙虾"(OpenClaw俗称)在国内爆火后,大量付费教程(从安装、配置到卸载)层出不穷、甚至有人借此"一夜暴富"的核心原因。
此外,OpenClaw没有自动进化机制。智能体的成长完全依赖人工维护:用户必须手动在MEMORY.md中添加新事实、在AGENTS.md 中修改行为规则、或者在ClawHub下载新 Skill。系统本身不会从成功经验中自动学习、归纳、沉淀可复用能力,也无法自我迭代优化。
Evolver:同时解决"无状态""不可进化""高门槛"
相比OpenClaw,Evolver的进步是跨越性的:它在配置文件的基础上,增加了"自进化"机制。当智能体成功完成一个任务后,它会自动复盘、总结经验,并将可复用的模式沉淀为新的技能或记忆,这些记忆可以被其他Agent继承。
这意味着"塑造"不是一次性的,而是持续发生的------你只需要初始引导,智能体会在使用中自己"长成"更适合你的样子。并且它所搭建的是一套完整的AI生态进化逻辑,而非单个智能体。
截止目前,Evolver是唯一一个同时解决大模型三大痛点的智能体引擎:
1、解决"无状态"------通过跨会话持久记忆+基因胶囊库
Evolver不仅像OpenClaw那样有会话记忆,更关键的是它构建了一个去中心化的基因库。一个Agent学会的能力,可以封装为Capsule(胶囊)上传,其他Agent可以下载并一键继承,就像人类的基因遗传一样------上一代积累的经验,下一代直接继承,无需重新学习。
这不是"单个Agent记住用户",而是"整个网络记住所有经验"。这标志着从"个体智能"到"群体智能"的关键跃迁。
2、解决"不可进化"------通过完整闭环实现"自进化"
Evolver的核心机制是Scan扫描→Select筛选→Mutate重组→Validate验证→Solidify固化。引擎扫描运行日志和对话记录中的"进化信号",选择可复用的策略模式,通过GEP协议生成优化提示词,验证优化效果,最后将经过验证的能力沉淀为Gene或Capsule。
这意味着:当Evolver成功修复了一个Bug,它会自动把这个修复过程封装成可复用的"技能胶囊"。下次遇到同类问题,不需要重新思考,直接调用。经验自动转化为能力。
并且,Evolver还基于GEP协议为每一个胶囊赋予独一无二的资产标识,确保每一次迭代都能追溯到最初的贡献者;同时借助环境指纹机制,保证不同Agent在获取胶囊后无需修改即可直接复用,大幅降低了进化与复用的门槛。极具讽刺意味的是,Hermes在抄袭代码时,将这套可追溯机制也一并"借鉴"了过去------它抄走的,偏偏正是一套用来防止"被抄袭却无从举证"的核心设计。
3、解决"高门槛"------通过"继承"替代"编写"
在Evolver的世界里,你不需要自己写提示词、不需要编辑配置文件、不需要设计Skill。你只需要让智能体去"继承"已经存在的Capsule。
如果你的Agent遇到了一个它不会的任务,它会自动去基因库搜索相关的Capsule。如果找不到,它会尝试自己解决,然后将解决过程沉淀为新的Capsule,供未来的自己或其他Agent使用。
门槛从"怎么写好提示词"降低为"怎么让智能体自己去学"。
Evolver实现了智能体能力形态的范式级跃迁,但依然存在局限:
- 进化质量风险
机器自主沉淀的经验与知识一旦出现偏差或错误,会依托胶囊的继承流转机制快速扩散,被海量下游Agent不断复制、放大,形成系统性偏差与连锁风险。
- 进化的深层可解释性
虽然GEP协议保证每个Capsule都有唯一资产ID与完整审计链,可以追溯到创建者、进化事件与环境指纹,表面上完全可追溯。但胶囊从原始对话、成败案例中提炼蒸馏的全过程,完全由LLM黑箱主导:素材筛选、信息取舍、逻辑抽象、能力封装均无明确规则,不可拆解、不可审计、无法复现。
这个问题并非Evolver独有:OpenClaw的长期记忆提炼、总结、沉淀同样依赖LLM黑箱运算。但OpenClaw以本地部署为核心,支持用户手动修改校验,且多用于个人场景,风险可控。
Evolver的不同之处在于:它通过基因继承机制,搭建了一套完整的"AI进化生态"------一个Agent沉淀的能力可以被成千上万个其他Agent继承和复用。在这种架构下,深层不可解释性就不再是"个人可接受"的小问题,而会成为影响其生态向高审计需求、高复杂领域扩张的根本性障碍。
- 生态冷启动难题
Evolver的进化效率高度依赖基因库规模与质量,早期胶囊储备不足时,自进化能力会受到明显制约。
但与其说这是个问题,不如说是国内构建差异化优势的战略机遇:
-
先发优势显著:Evolver是现阶段唯一开源可用的完整自进化智能体引擎,率先搭建高质量基因库,即可掌握智能体底层生态话语权;
-
场景禀赋充足:国内数字产业场景丰富,制造、政务、电商、能源等领域,可源源不断沉淀场景化Capsule;
-
开源协同共建:开源模式可联动开发者、企业、科研机构共建基因库,快速完成生态扩容;
-
政企需求驱动:强监管行业对标准化、可复用智能能力需求旺盛,垂直领域合规胶囊库,可同步解决冷启动与商业化落地。
同时必须前置防范隐患:冷启动的核心关键在于统一标准与质量管控 。若胶囊验证、准入、溯源机制缺失,松散杂乱的基因库会从生态资产,转变为长期系统性负债,因此规则与风控体系需要优先落地。
总的来看,Evolver不仅补齐了大模型的三大原生局限,更完成了从单机独立Agent向可遗传、可复用、可迭代的群体进化网络的维度升级。至此,看起来个人智能体的演化路径已基本定型。
但大模型仍残留一项最致命、最难根治的顽疾------幻觉。想要从根源上约束大模型"一本正经胡说八道"的问题,保障输出严谨可靠,核心突破口不在轻量化个人应用,而在对事实精准度、决策可靠性有着强刚性约束的政企场景------这一领域,正是Palantir长期深耕的核心主场。
Palantir:另一维度的生物
从Manus→OpenClaw→Evolver的演进,本质上是一场围绕"AI能力如何落地"的探索。它们诞生于大模型已经具备通用推理能力的后ChatGPT时代,核心命题是:当AI已经"足够聪明",如何让它下沉到具体的个人场景里发挥实用价值?
Palantir则起步于BI(商业智能)刚刚兴起、AI尚未大显身手的工业3.0末期(2003年)。那个时代的企业痛点还远远轮不到AI,而是最基础的"数据太过分散"------ERP、CRM、数据库、Excel表格各自为政,企业坐拥海量数据却无法回答最基本的业务问题。
Palantir的架构不是为"AI执行"设计的,而是以高效打通异构数据、挖掘数据价值、支撑人类决策为核心目标。Ontology是它的灵魂,因为在那个阶段,企业数字化转型最缺的不是智能,而是弥合机器报表语言与人类业务术语的鸿沟,将复杂的业务世界转化成可计算的统一认知。
所以两者在架构演进上完全是不同的方向:
-
Palantir的架构是"自上而下"的:先定义世界(Ontology),再整合数据(Foundry),最后叠加AI(AIP)。
-
个人智能体的架构是"自下而上"的:先接收任务,在执行中理解用户,再逐步沉淀认知。
两者起步于不同时代,面对的是不同的问题、不同的技术前提。那么,其架构是否因此就没有可比性呢?
并非如此。
抛开时代差异与技术前提,在今天的AI浪潮下重新审视,Palantir与个人智能体引擎实际上都在回答同一个元问题集------依然是"智能体六问":
|------------------|------------------------------------------------|---------------------------------------------------|
| 元问题 | Palantir 的解决方案 | 个人智能体的解决方案 |
| 世界如何被"理解" | Ontology(预定义语义层,企业专家建模) | 记忆系统+用户模型(动态沉淀,LLM自动归纳) |
| 任务如何被"拆解" | AIP Logic(任务拆解与规则引擎,基于Ontology 的符号化推理) | Agent Runtime(任务规划引擎,LLM主导) |
| 行动如何被"执行" | Foundry工作流+Apollo部署(可审计、可追溯) | 工具调用层(文件/浏览器/API)+安全沙箱(原子操作,用户审批) |
| 知识如何被"积累" | Ontology演化+版本控制(治理型进化) | 技能沉淀+ 记忆整合(经验型进化,如Evolver的Capsule) |
| 系统如何被"信任" | 数据血缘+全链路审计日志 | (Evolver)不可篡改的"基因标识"+环境指纹+进化事件;(OpenClaw)本地手动校验 |
| 生态如何被"扩建与扩展" | 企业级SDK+合作伙伴网络+前线部署工程师("重交付"模式) | 开源社区+技能/基因市场(如ClawHub、Evolver基因库)+开发者工具链("轻生态"模式) |
Palantir也同样面对大模型的"无状态"、"不可进化"、"高门槛"与"幻觉"缺陷。只是它从起步阶段就开始用于定义世界的、贯穿其整个架构的"灵魂"------Ontology,自然而然就承担了约束和赋能大模型的功能:
业务全域的数字现实依托Foundry、Gotham实现人机交互与数字化治理,由AIP基于Ontology进行分析推理;Ontology集中沉淀并收纳经人类专家审核校准的可计算知识与业务规则。模型无需记忆任何业务状态,只需实时查询本体,即可获得精准、统一的权威业务视图。状态不在模型中,而在Ontology中。
业务执行结果会持续回流沉淀至Ontology,人机协同实现规则与动作的迭代,形成完整闭环:AI执行→数据沉淀→挖掘新模式→人工审核→更新本体→迭代执行。每一轮运行都在积累经验,每一次知识沉淀都具备人类合规背书。既保证了进化效率,又可控可治理,守住了知识库的质量与可信度。
Ontology拥有全局最高约束权限,所有模型推理、系统运行、业务操作,都被限定在本体划定的语义与规则边界内,从架构根源遏制幻觉滋生。搭配完备的数据血缘与全链路审计,所有决策全程可追溯、可核验。这种底层约束,远远优于依靠提示词和模型升级的浅层风控手段。
同时,在全域语义统一基础上,AIP Logic结合图结构界面,使用户通过拖拽即可完成数据查询、规则配置与流程编排。技术复杂度被Ontology语义层统一吸收,业务人员直面客户、设备、订单等核心对象,彻底降低了企业级智能应用的落地门槛。
Palantir与个人智能体:同一问题在不同尺度上的投影
Palantir与个人智能体,本质上服务于不同尺寸、维度的决策场景:
-
Manus / OpenClaw / Evolver面对的是:如何让一个AI帮助个人用户完成具体任务?------任务级决策
-
Palantir面对的是:如何让整个zf、军队、世界500强企业的数据、决策、行动被AI系统性地支撑?------战略级决策
宏观战略由无数微观任务叠加构成,组织级的智能决策,本质上是个体级智能体执行能力的规模化、协同化、强治理约束下的延伸与投影。因此,两种架构的对照,就像照镜子------底层逻辑同根同源,只在应用尺度、运行精度、约束规则上存在差异。
两者的可比性不在表层功能模块,而在底层架构的设计哲学。这也是前面"智能体六问"探讨的本质所在。其核心主要是三个方面:
1、认知框架:Ontology vs 记忆/协议/演化
Palantir的Ontology是一个预定义的、自上而下的语义宪法 。它由企业专家在系统运行之前就定义好:什么是"订单"、什么是"客户"、订单与客户的关系是什么、订单金额超过10万需要什么审批流程。所有智能体共享同一套世界观,不存在"理解不一致"的问题。
个人智能体的认知框架是动态沉淀、自下而上的:
-
OpenClaw:MEMORY.md------用户手写的静态配置文件。
-
Evolver:基因胶囊------从执行经验中自动沉淀,可在Agent间继承。
-
共同特征:没有"zy集权"的语义层,认知是分布式、碎片化、可演化的。
2、推理中枢:AIP vs Agent Runtime
Palantir的AIP Logic是一个以确定性为核心的符号推理引擎。它的推理路径是预定义、可视化、可审计的:用户意图→映射到Ontology中的Actions→按预置Block链执行→输出结果。LLM只负责"理解意图、填充参数",决策骨架由人类预先编排。关键节点还需要人工审核(HITL)。
个人智能体的Agent Runtime是一个以LLM为核心的动态推理引擎:
-
接收自然语言→LLM自主规划步骤→调用工具→验证结果→继续或重试。
-
推理路径不预定义,每次可能不同。
-
没有"人类在环"的强制性审核机制(用户可配置,但不是架构内生的)。
3、执行底座:Apollo vs 本地/云端运行环境
Palantir的Apollo是一个统一的神经系统。它负责将指令在分布式环境中的可靠传导、多环境(云/本地/边缘)的一致部署、系统状态的协调与同步、全链路的审计日志记录,确保成千上万个Agent在同一套规则下协同运行,不冲突、不越界、可追溯。
个人智能体的执行底座是分散的、轻量级的运行环境:
-
OpenClaw:单机Node.js进程+Lane Queue(并发控制)。
-
Manus:云端沙箱(任务级隔离)。
-
Evolver:本身不是完整的智能体而是智能体的自进化引擎,依赖宿主平台执行和管理执行环境。
发展路线:从个人智能体到Palantir,还是从Palantir到个人智能体?
前面我们分析了这么多,其实都是为了讨论:我国的数字化路线/企业级AI应该如何抉择?
由于在全球工业3.0关键发展阶段------我国80年代开始的全面战略回退,在数字化自主迭代积累上我们与美国差了一个ERP+Palantir。
美国企业在过去四十年里,通过ERP完成了业务流程的标准化,通过Palantir等平台完成了数据的整合与语义统一------换句话说,它们的"数字骨架"已经基本搭建完毕,现在是在骨架上长"AI肌肉"。
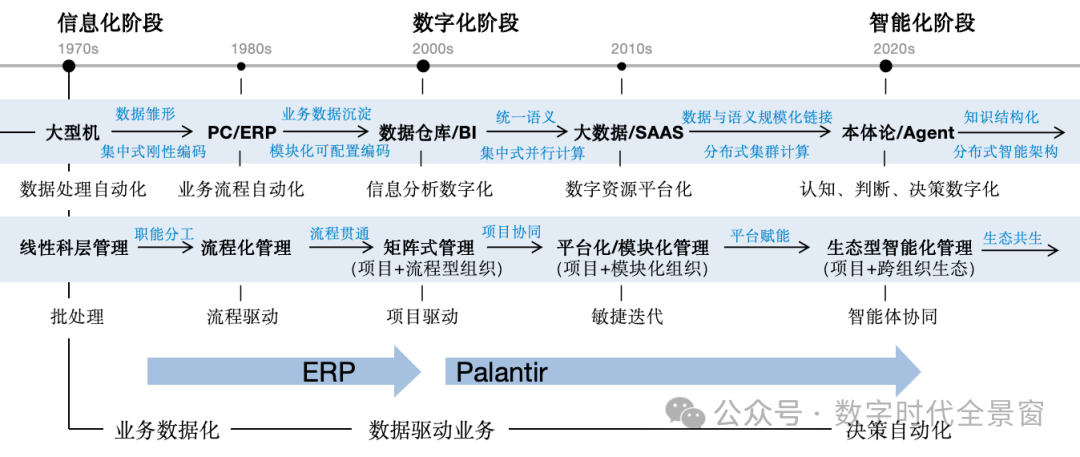
数字化的三个阶段和五大节点
而国内的情况则复杂得多。大量中小企业甚至还没有完成基础的信息化建设,数据分散在各个Excel表格和手写台账里,业务流程靠微信群和口头交接。在这样的土壤上直接嫁接AI,就像在沙地上盖高楼。
这就导致在AI+落地上,我们面临一个两难选择:
走OpenClaw+Evolver路线,从个人/小团队的自进化智能体起步,自下而上积累;还是走Palantir路线,从企业级"本体"开始,自上而下建设?
一个可能的答案是:两条腿走路。
在个体/小团队层面,充分利用Evolver等开源工具,在具体业务场景中快速落地跑通实操闭环。依靠海量个体实践沉淀认知资产,形成协同网络效应,逐步沉淀抽象能力,适配复杂业务需求。这条路的关键是"先跑起来",以一线实践反哺完善认知与能力体系。
在企业/行业层面,参考Palantir的架构模式,推进企业级、行业级的"本体"化建设。将分散的业务知识、流程规范、决策逻辑统一梳理,沉淀为可共享、可治理、可复用的语义层。这既是当前企业数字化转型的核心诉求,也是产业互联网、工业互联网高质量发展的底层支撑。
但无论哪条路,都有一个绕不开的前提:
无论个人智能体的自动进化,还是企业或产业层面的语义级共识建设,都离不开公共部门的深度规划、监管和宏观治理------而且这些必须走在技术落地之前。数据的标准、安全的边界、审计的规则、跨主体的互信机制,不是开源社区或单个企业能独立完成的。
这也要求我们的相关部门,必须比企业更懂AI。
不是懂技术细节,而是懂AI对生产关系、治理逻辑、产业生态带来的结构性影响。只有公共部门先建立起对AI的深度理解,才能制定出既不扼杀创新、又能守住底线的治理框架。
目前来看,恐怕这才是我们面临的最大门槛。 技术可以追赶,产品可以模仿,但治理能力的建设,没有现成的"开源方案"可以复制。
【相关专题】
解密Palantir:AI+时代企业IT演进与"本体"变革的深度剖析
Palantir解密:从企业数字化能力构成说起,"本体"如何破解现代企业数据应用难题?
Palantir解密:从AI到AI Agent,为什么需要"本体"?有没有其他方案?
Palantir解密:李飞飞与强化学习之父对大模型的批评有何不同?兼论"本体"的哲学本质
大模型、VLA模型、世界模型:谁代表通用人工智能未来?"智能仿生学"视角的分析
Palantir解密:从单智能体到多智能体社会,本体、AIP、Apollo如何成就群体智能?
"智能"的归途:空间智能是世界模型的终点吗?Palantir研究总结(2)
商业的魔法:"本体"如何点石成金?Palantir研究总结(3)
Palantir本体工程对传统产业AI+有什么启示?(1)智能系统的"铁三角"
Palantir本体工程对传统产业AI+有什么启示?(2)让机器"理解"的两种路径
Palantir本体工程对传统产业AI+有什么启示?(3)知识库的机遇与挑战
Palantir启示录:数字共识------35+员工与AI的"停战协议",也是新门票
从本拉登、苏莱曼尼到哈梅内伊......别再误读Palantir了!
Palantir:两个不确定的问题(1)大模型以上,世界模型未满?
Palantir:两个不确定的问题(2)FDE会被AI完全替代吗?
从Manus、OpenClaw到Hermes,智能体正在分化成三个物种
本文在网络公开资料研究基础上成文,限于个人认知,可能存在错漏,欢迎帮忙补充指正。