ComfyUI 实战:用 ControlNet 实现人物表情编辑,让人物"笑起来"的工作流解析
摘要
在基于 Stable Diffusion 的人物编辑任务中,一个非常常见但并不容易稳定实现的需求是:
在尽量保持人物姿态、发型、服装和整体结构稳定的前提下,对人物表情进行编辑,例如让人物从自然状态变为微笑或大笑。
仅依赖 prompt 往往难以稳定完成这类任务,常见问题包括:
- 表情变化不明显
- 结构容易漂移
- 头发、衣服、背景被连带修改
- 人物一致性下降
针对这一问题,可以引入 ControlNet 对结构进行约束,并结合 SoftEdge 作为结构控制条件,先完成表情编辑链路的验证,再进一步升级到更精细的局部编辑方案。
本文基于一个已经验证通过的 ComfyUI + SoftEdge ControlNet 最小工作流,从问题分析、工作流结构、参数逻辑到优化方向,系统说明如何通过 ControlNet 实现"让人物笑起来"的实战方案 。
效果图:通过修改提示词终于开心得笑了,妲己的效果就有了
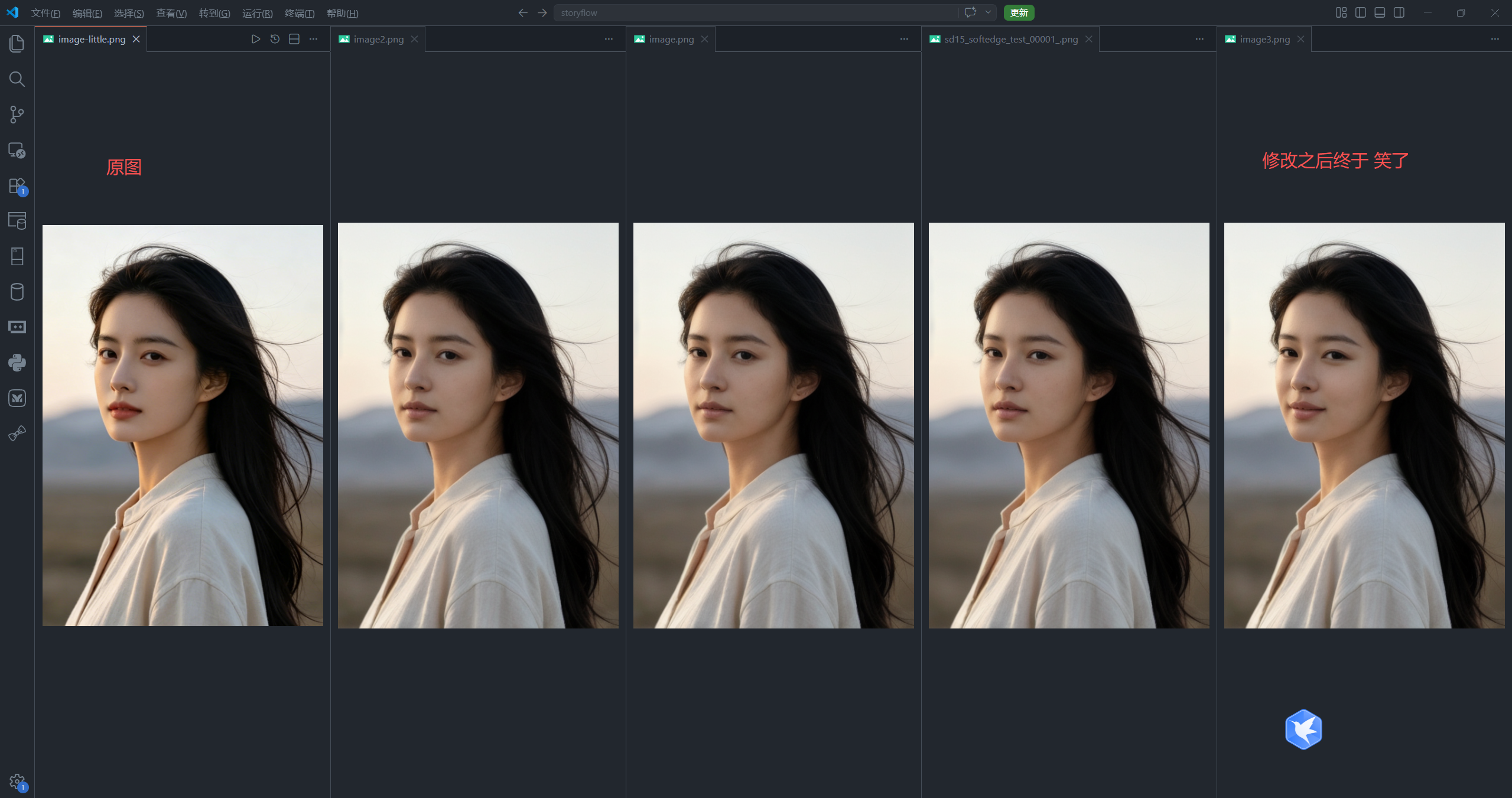
工作流截图
1. 问题背景
人物表情编辑与普通的文生图不同,它通常同时包含两个约束目标:
-
目标变化明确
例如:让人物微笑、让人物大笑、让嘴角上扬。
-
非目标区域尽量稳定
例如:保持姿态不变、服装不变、发型不变、背景结构不变。
这意味着该任务本质上不是简单的"生成一张带笑容的人像",而是:
在原图基础上进行受控编辑。
在这种场景下,单纯依赖文本提示词通常无法提供足够稳定的结构约束,因此需要引入 ControlNet。
2. 为什么只靠 Prompt 往往不够
在人物表情编辑中,即使正向提示词中已经写入:
- smile
- subtle smile
- gentle smile
- happy expression
模型也未必会产生明显变化。
原因主要来自以下三个方面:
2.1 表情语义本身较弱
例如:
subtle smilegentle smileslight upward mouth corners
这些描述本身就是"轻微变化",很容易在重采样过程中被模型弱化。
2.2 img2img / latent 重采样天然倾向于保留原图
在 ComfyUI 中,标准采样节点 KSampler 的输入包括:
modelpositivenegativelatent_image
只要输入了原图对应的 latent,采样过程就会倾向于保留原图已有结构,而不是进行强烈重绘。
2.3 缺少结构级约束
即使 prompt 中写了:
- same pose
- same clothes
- same hairstyle
这些也只是语义层面的引导,并不能提供结构层面的硬性限制。
真正能够提供结构控制的,是 ControlNet 这类条件约束模块。
3. 为什么使用 SoftEdge ControlNet
在 ControlNet 的多种控制方式中,SoftEdge 非常适合用于这类任务。
原因在于 SoftEdge 的核心作用是:
- 保持轮廓结构
- 保持边缘走向
- 保持主体与背景的大体关系
- 减少整图编辑时的结构漂移
对于"想改表情,但不希望整张图一起变化"的任务来说,SoftEdge 可以作为第一层结构约束手段。
本文使用的 SoftEdge 最小工作流中,ControlNet 模型为:
control_v11p_sd15_softedge.pth
对应的预处理节点为:
PiDiNetPreprocessor
这套配置已经能够稳定完成 SoftEdge 控制链路的验证。
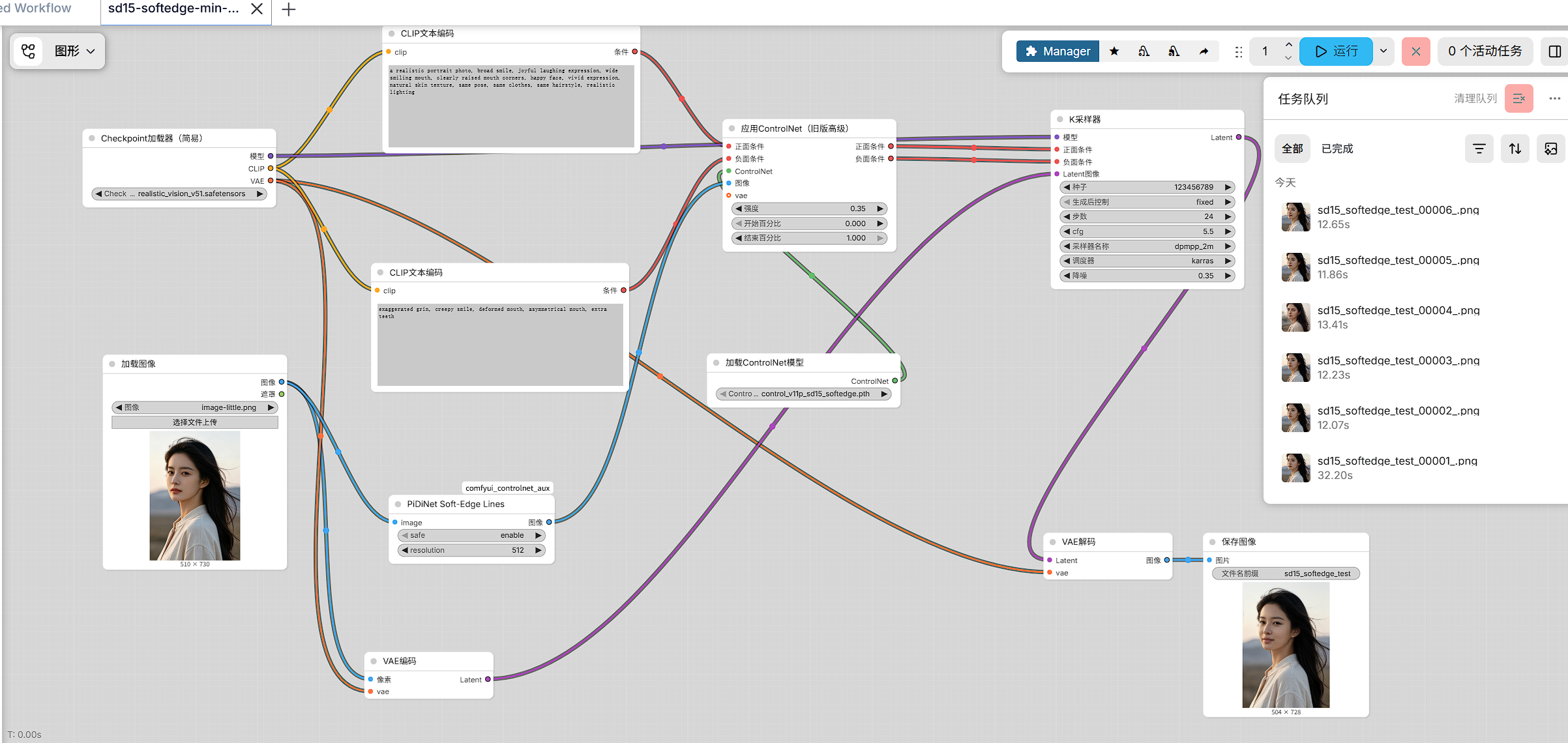
4. 工作流结构解析
本文使用的最小验证工作流,由以下节点组成 :
CheckpointLoaderSimpleCLIPTextEncode(正向)CLIPTextEncode(负向)LoadImagePiDiNetPreprocessorControlNetLoaderVAEEncodeControlNetApplyAdvancedKSamplerVAEDecodeSaveImage
4.1 预处理阶段
输入图像首先进入:
LoadImagePiDiNetPreprocessor
其中 PiDiNetPreprocessor 的参数为:
safe = enableresolution = 512
它的作用是从输入图像中提取 SoftEdge 控制图。
4.2 ControlNet 应用阶段
SoftEdge 预处理结果进入:
ControlNetApplyAdvanced
同时,该节点还接收:
- 正向条件
positive - 负向条件
negative control_net- 预处理后的控制图像
ControlNet 的标准工作方式就是:
将控制条件叠加到正负条件上,再送入采样器
4.3 采样阶段
经过 ControlNetApplyAdvanced 输出的正负条件,再进入:
KSampler
当前工作流中的 KSampler 是标准四输入结构:
modelpositivenegativelatent_image
这说明整个工作流已经不是纯粹的"复制原图",而是在原图 latent 基础上进行一次受控重采样。
5. 验证阶段为什么优先使用"大笑"而不是"轻微微笑"
在工作流验证阶段,更推荐先使用明显一些的表情目标,例如"大笑",而不是一开始就测试"轻微微笑"。
原因如下:
5.1 轻微微笑难以判断是否生效
如果表情变化本身非常小,就很难区分以下几种情况:
- 工作流没有真正生效
- Prompt 生效了,但变化幅度太小
- 结构约束太强,把变化压掉了
5.2 大笑更适合验证链路是否有效
在当前最小工作流中,正向提示词为:
text
a realistic portrait photo, broad smile, joyful laughing expression, wide smiling mouth, clearly raised mouth corners, happy face, vivid expression, natural skin texture, same pose, same clothes, same hairstyle, realistic lighting对应的负向提示词用于约束常见问题,例如:
- exaggerated grin
- creepy smile
- deformed mouth
- asymmetrical mouth
- extra teeth
这种写法的优点是:
如果链路确实有效,表情变化会更容易被观察到。
6. 当前提示词的作用逻辑
6.1 正向提示词
当前工作流中使用的正向提示词主要分为三部分 :
(1)风格与质量
a realistic portrait photonatural skin texturerealistic lighting
用于定义整体风格为写实摄影。
(2)表情目标
broad smilejoyful laughing expressionwide smiling mouthclearly raised mouth cornershappy facevivid expression
用于明确要求模型朝"大笑、开心、嘴角上扬"的方向生成。
(3)稳定性提示
same posesame clothessame hairstyle
用于从语义层面提示模型保持原始结构特征。
6.2 负向提示词
负向提示词的作用主要是防止出现以下常见问题:
- 表情变得夸张或诡异
- 嘴部变形
- 左右不对称
- 牙齿异常增生
- 低质量或结构错误
因此,负向提示词并不是"可有可无"的,它在表情编辑中非常重要。
7. 为什么即使写了"same pose / same clothes / same hairstyle",结果仍然会有变化
这是很多人在做人物编辑时会遇到的疑问。
本质原因是:
same pose / same clothes / same hairstyle只属于语义提示,并不是硬约束。
真正影响结果稳定性的因素包括:
KSampler的重采样行为ControlNetApplyAdvanced施加的结构条件- 是否使用了 ControlNet 控制图
- 是否引入了更强的人物一致性约束(例如 IP-Adapter)
因此,只要工作流仍然经过了:
VAEEncodeKSamplerVAEDecode
就意味着结果一定会带有一定程度的"重新生成"特征,而不是像素级复制原图。
8. 这套 SoftEdge 工作流验证成功后说明了什么
如果最小工作流能够稳定输出,并表现出以下特征:
- 构图整体稳定
- 姿态没有明显漂移
- 发型和衣服轮廓大体保留
- 背景结构没有明显被破坏
- 表情方向开始发生变化
那么就可以说明以下几个关键点已经验证通过:
PiDiNetPreprocessor节点工作正常control_v11p_sd15_softedge.pth加载正常ControlNetApplyAdvanced的接线结构正确KSampler的条件输入是正确的
这意味着:
SoftEdge ControlNet 已经可以作为后续人物表情编辑正式工作流的结构控制基础。
9. 当前方案的局限性
需要指出的是,当前验证通过的工作流仍然属于:
整图受控重采样验证版
它能够解决的是:
- ControlNet 是否生效
- SoftEdge 是否可以稳定约束结构
- 表情是否能够朝目标方向变化
但它还没有完全解决以下问题:
- 如何只修改嘴部,而不是整图一起参与编辑
- 如何进一步提升人物一致性
- 如何让微笑幅度更自然、可控
- 如何减少非目标区域的细节漂移
因此,这个工作流适合做"第一阶段验证",但不应被视为最终版方案。
10. 更适合正式落地的升级方向
在人物表情编辑任务中,正式落地时更推荐使用以下组合方案:
10.1 加入 IP-Adapter 保持人物一致性
在已有的 ComfyUI 工作流中,IP-Adapter 的标准接法包括:
CLIPVisionLoaderIPAdapterUnifiedLoaderIPAdapterAdvanced12
其中,IPAdapterUnifiedLoader 可以使用:
PLUS FACE (portraits)预设 1
这能够帮助模型更稳定地保持人物身份特征。
10.2 加入局部嘴部 Mask
如果目标是"只让人物笑起来",更有效的做法并不是继续强化整图 prompt,而是:
- 对嘴部做小范围 mask
- 只允许嘴部区域参与编辑
- 其他区域尽量冻结
这一步会比整图 prompt 控制更有效,也更容易做到"其他地方不动"。
10.3 继续保留 SoftEdge
即使进入局部编辑阶段,SoftEdge 依然有保留价值,因为它可以继续帮助保持:
- 发丝边缘
- 衣服轮廓
- 肩颈结构
- 背景边界
因此,更推荐的正式方案应当是:
局部 inpaint + IP-Adapter + SoftEdge ControlNet
11. 一个更合理的调试顺序
为了提高工作流调试效率,推荐按以下顺序推进:
第一步:验证 SoftEdge 最小工作流
目标是确认:
- 节点能否正常运行
- ControlNet 模型能否加载
- 结构约束是否生效
第二步:使用更明显的表情目标验证变化能力
例如先测试:
- broad smile
- joyful laughing expression
- wide smiling mouth
避免在"变化太弱"的情况下误判工作流无效。
第三步:逐步降低表情变化幅度
在大笑已经可控之后,再逐步回退到:
- smile
- subtle smile
- gentle smile
这样更容易看出参数与结构约束之间的平衡关系。
第四步:升级为局部嘴部编辑
进入局部 mask 阶段之后,工作流才真正接近高质量的"人物自然微笑编辑"。
12. 总结
从解决问题的角度来看,本文这套工作流主要完成了以下任务:
(1)验证了 SoftEdge ControlNet 在人物表情编辑中的可行性
通过:
PiDiNetPreprocessorcontrol_v11p_sd15_softedge.pthControlNetApplyAdvancedKSampler
可以建立一条稳定的结构受控编辑链路。
(2)解释了为什么"轻微微笑"往往不明显
原因不在于 prompt 完全无效,而在于:
- 变化语义太弱
- 结构约束太强
- 重采样本身倾向于保留原图
(3)给出了更合理的验证策略
在验证阶段,先使用更明显的表情目标(例如大笑)更容易判断工作流是否真正生效 。
(4)明确了正式版的升级方向
如果要进一步实现:
- 只改嘴部
- 保持人物身份一致
- 自然微笑
- 后续可衔接视频动画
则推荐继续升级为:
IP-Adapter + 局部嘴部 mask + SoftEdge ControlNet
13. 后续优化方向
如果继续往下做,这条路线可以自然延伸到两个方向:
方向一:高质量静态表情编辑
适合做:
- 自然微笑
- 不露齿微笑
- 明显大笑
- 局部嘴角精修
方向二:单图到视频的表情动画
在静态关键帧已经稳定之后,再衔接到 AnimateDiff 或其他人像驱动方案,会比直接从原图做视频更稳定。