1. auto和范围for
1.1 auto关键字
在这里补充2个C++11的小语法,方便我们后面的学习。
-
在早期C/C++中auto的含义是:使用auto 修饰的变量,是具有自动存储器的局部变量,后来这个不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
-
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
-
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
-
auto不能作为函数的参数,可以做返回值,但是建议谨慎使用
-
auto不能直接用来声明数组
下面我们来演示一下:
cpp
#include<iostream>
#include<string>
#include<map>
using namespace std;
int func1()
{
return 10;
}
// 不能做参数
//void func2(auto a)
//{
// // 可以做返回值,但是建议谨慎使用
// func1();
//}
void func2()
{
// 可以做返回值,但是建议谨慎使用
func1();
}
auto func3()
{
return func2();
}
void Test()
{
std::map<std::string, std::string> dict = { { "apple", "苹果" }, { "orange", "橙子" }, {"pear", "梨" } };
// auto的用法
// std::map<std::string, std::string>::iterator it = dict.begin();
auto it = dict.begin();
while (it != dict.end())
{
cout << it->first << ": " << it->second << endl;
++it;
}
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = func1();
// 编译报错: rror C3531: "e": 类型包含"auto"的符号必须具有初始值设定项
//auto e;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
int x = 10;
auto y = &x;
auto* z = &x;
auto& m = x;
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
cout << typeid(z).name() << endl;
auto aa = 1, bb = 2;
// 编译报错: error C3538: 在声明符列表中,"auto"必须始终推导为同一类型
//auto cc = 3, dd = 4.0;
// 编译报错: error C3318: "auto []": 数组不能具有其中包含"auto"的元素类型
//auto array[] = { 4, 5, 6 };
Test();
return 0;
}其实我认为auto在这里还是蛮坑的,你说auto不能作为函数的参数,但是可以做返回值,并且也不能声明数组,这是不是有点奇怪呢?
再者,auto来接受返回值的话,比如我上面写了三个函数分别为func1,2,3.那么当我一个去嵌套另一个函数时,而返回值时auto,那我们想知道返回值的类型是不是得自己挨个去找啊,这你是不不太行呀,这要是在日常实践也太麻烦了对吧。
那可能会有小伙伴说,那auto有啥用呢?感觉auto如此不堪对吧,实际上我们平常使用auto基本只有一个用途,那就是简化代码,例如我们上方的Test函数,在Test函数中,我们使用了一个map函数对吧,map的底层是树,所以在这里我们创建了一棵树,然后在这里我们使用迭代器去接受begin,我们会发现,啧,这个代码是不是太长了呀,这么老长一趟,写起来是不是也会不太舒服,所以在我们了解这个代码的原理之后,我们就可以直接使用auto,从而简化我们的代码。
1.2 范围for
- 对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号":"分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代、自动取数据、自动判断结束。
- 范围for可以作用到数组和容器对象上进行遍历
- 范围for的底层很简单,容器遍历实际就是替换为迭代器,这个从汇编层也可以看到。
其实范围for的用法很简单,如下:
cpp
string s2("hello world");
for (auto ch : s2)
{
cout << ch << " ";
}迭代器:
cpp
string::iterator it = s2.begin();
while (it != s2.end())
{
cout << *it << " ";
it++;
}汇编:
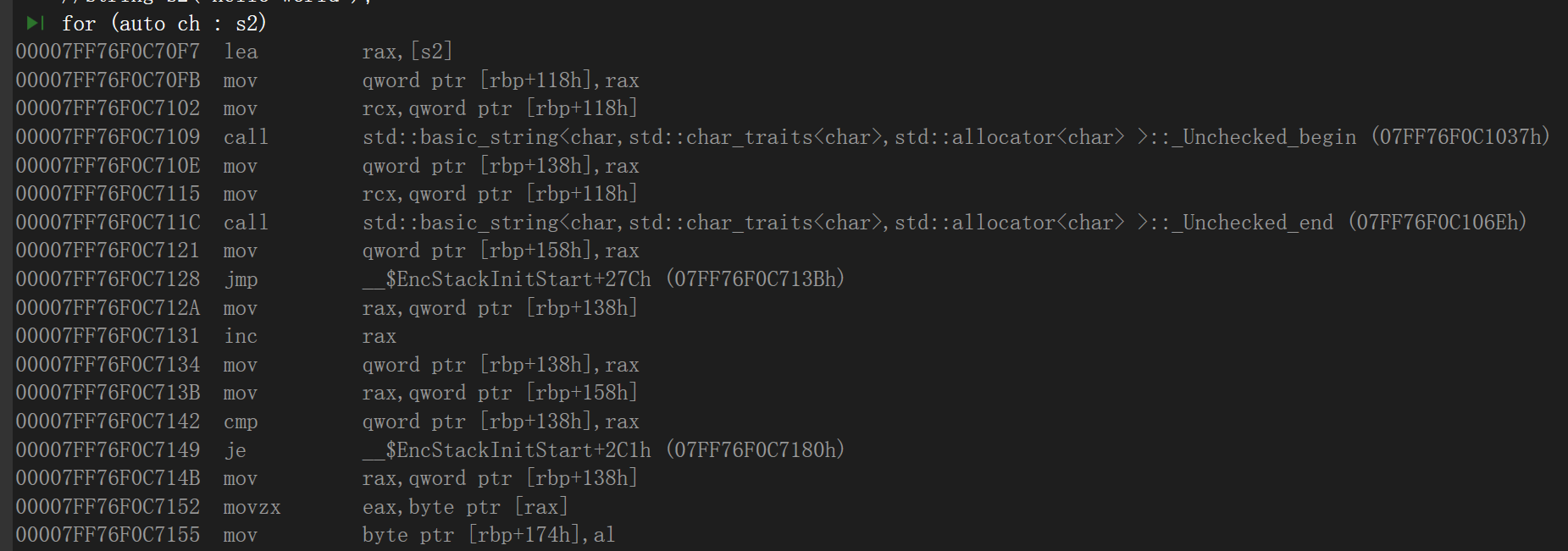
- 获取字符串对象地址
cpp
lea rax, [s2] ; 取 s2 的地址
mov qword ptr [rbp+118h], rax ; 保存到局部变量 (__range 的地址)rbp+118h 处存放了指向 s2 的指针,相当于保存了 __range 对象的地址,以便后面调用迭代器获取函数。
- 调用 Unchecked_begin ------ 获取起始迭代器
cpp
mov rcx, qword ptr [rbp+118h] ; 将 s2 的地址作为 this 指针传入
call Unchecked_begin ; 调用 begin()
mov qword ptr [rbp+138h], rax ; 返回值 (迭代器) 存入 __begin关键铁证:Unchecked_begin 是 MSVC 标准库内部用于获取 basic_string 起始迭代器的函数。对于 std::string,返回的迭代器本质上是一个 char* 指针,指向字符串首字符。
- 调用 Unchecked_end ------ 获取结束迭代器
cpp
mov rcx, qword ptr [rbp+118h] ; this 指针
call Unchecked_end ; 调用 end()
mov qword ptr [rbp+158h], rax ; 返回值存入 __end同样,Unchecked_end 返回尾部迭代器(指向 \0 的位置或 _Ptr + size())。
- 跳转到循环条件判断
cpp
jmp $... ; 直接跳到比较部分,避免第一次就执行循环体内代码C++ 范围 for 也是先进入条件判断的 while 形式。
- 循环体内部:解引用读取字符
cpp
; 循环体开始标记
mov rax, qword ptr [rbp+138h] ; 加载当前迭代器 (即指向字符的指针)
movzx eax, byte ptr [rax] ; 解引用读取一个字节 (即 *__begin)
mov byte ptr [rbp+174h], al ; 存储到 ch 变量这里非常清晰地体现了 迭代器的解引用操作:byte ptr rax 就是读取迭代器所指的内容,也就是 *__begin,然后赋值给 ch。
- 迭代器前进
cpp
mov rax, qword ptr [rbp+138h] ; 取当前迭代器
inc rax ; 迭代器前进 (对于 char* 来说地址加 1)
mov qword ptr [rbp+138h], rax ; 存回 __begin这正是 ++__begin 的体现。因为 std::string 的底层是连续存储的字符数组,迭代器就是原生指针,所以递增就是 inc rax(指针加1)。
- 循环条件判断与跳转
cpp
mov rax, qword ptr [rbp+158h] ; 加载 end 迭代器
cmp qword ptr [rbp+138h], rax ; 比较 __begin 和 __end
je exit_label ; 如果相等则跳出循环这里完美对应 __begin != __end 的条件。如果不相等,就跳回循环体继续执行。
哪里看出了迭代器?
| 汇编证据 | 对应的迭代器操作 |
|---|---|
调用 Unchecked_begin |
__range.begin() |
调用 Unchecked_end |
__range.end() |
cmp [rbp+138h], [rbp+158h] |
__begin != __end |
inc rax (对指针加一) |
++__begin |
movzx eax, byte ptr [rax] |
*__begin (解引用) |
你可以把范围 for 想象成一个自动挡汽车:
- 你只需要挂 D 挡,踩油门(写 for (auto ch : s2)),它就能自动前进。
- 但变速箱里,仍然是齿轮的啮合、分离、变速(begin()、end()、!=、++、*)。
范围 for 只是帮你省去了手动换挡的繁琐,但底层机械原理没变
1.3 遍历
cpp
#include <iostream>
#include <string>
using namespace std;
void Test_string1()
{
string s1;
string s2("hello world");
string s3 = s2;
cout << s1 << s2 << s3 << endl;
s2[0] = 'C';
cout << s1 << s2 << s3 << endl;
for (int i = 0; i < s2.size(); i++)
{
cout << s2[i] << " ";
}
cout << endl;
//auto it = s2.begin();
string::iterator it = s2.begin();
while (it != s2.end())
{
cout << *it << " ";
it++;
}
cout << endl;
//string s2("hello world");
for (auto ch : s2)
{
cout << ch << " ";
}
}
void Test_string2()
{
string s1;
string s2("hello world");
//string::reverse_iterator rit = s2.rbegin();
auto rit = s2.rbegin();
while (rit != s2.rend())
{
*rit += 1;
cout << *rit << " ";
rit++;
}
cout << endl;
string::const_reverse_iterator crit = s2.rbegin();
while (crit != s2.rend())
{
//*crit += 1;
cout << *crit << " ";
crit++;
}
}
int main()
{
Test_string1();
Test_string2();
//TestPushBack();
return 0;
}以上为三种遍历方式,在这里不再赘述了。
2. reserve
那么在看reserve之前,我们先需要清楚 string 底层到底长什么样
cpp
void TestPushBack()
{
// reverse 反转 逆置
// reserve 保留、预留
string s;
// 提前开空间,避免扩容,提高效率
//s.reserve(100);
size_t sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
cout << "making s grow:\n";
for (int i = 0; i < 100; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
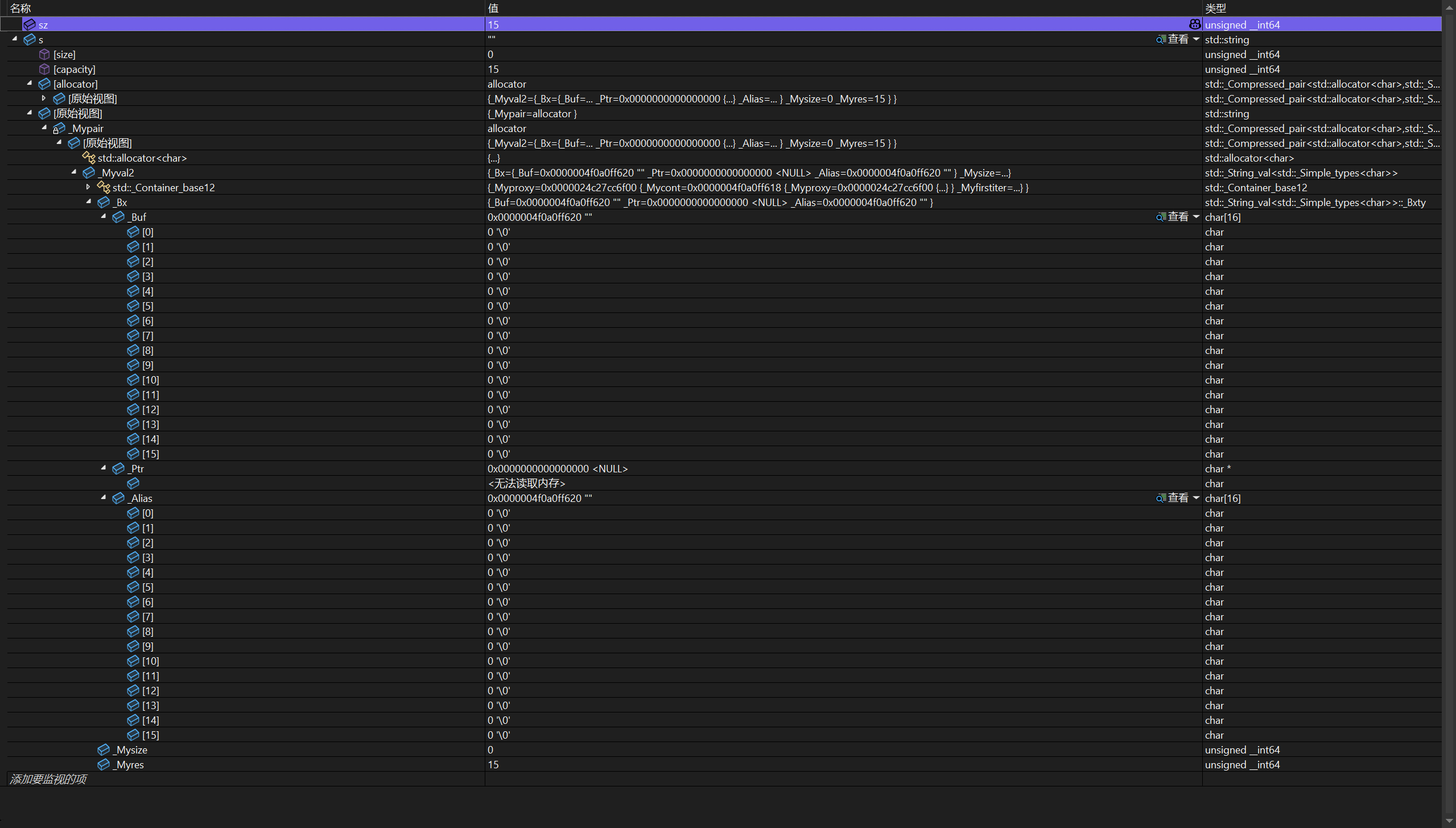
}我们来调试看一下监视窗口:
2.1 std::string 的基本原理
std::string 本质上是一个动态字符数组的管理类,它需要存储三样核心信息:
- 字符串内容(字符数组)
- 当前字符串长度(size)
- 当前分配的容量(capacity)
经典内存布局(没有优化的情况):
cpp
std::string 对象(通常在栈上):
┌──────────────────────┐
│ _Ptr (指向堆内存) │ ──────┐
│ _Size (长度) │ │
│ _Cap (容量) │ │
└──────────────────────┘ │
V
堆内存:
┌────────────────┐
│ h e l l o \0 │
└────────────────┘这种设计下,每个 string 对象固定占用 3 个指针/整型的大小(通常是 24 字节或 32 字节,取决于平台和实现)。就像在vs平台下是28
2.2 第二部分:SSO(小字符串优化)------ 为什么监视窗口里有 _Bx 和 _Buf?
对于很短的字符串(比如 "hello"),如果每次都要去堆上分配内存,开销太大。所以主流实现都采用了 SSO (Small String Optimization):
当字符串长度小于某个阈值(MSVC 中是 15 字符)时,字符串内容直接存储在 string 对象内部,不分配堆内存。
MSVC 的 std::string 内部结构简化版:
cpp
class string {
union _Bxty {
char _Buf[16]; // 用于 SSO 的内部缓冲区
char* _Ptr; // 指向堆内存的指针
char _Alias[16]; // 用于对齐的别名
} _Bx;
size_t _Mysize; // 当前长度
size_t _Myres; // 当前容量
};关键设计:_Bx 是一个 union,它要么充当内部缓冲区 _Buf,要么充当堆指针 _Ptr。通过容量 _Myres 的值来区分当前处于哪种模式。
2.3 监视窗口字段逐一拆解
| 字段名 | 值(示例) | 含义 |
|---|---|---|
[size] |
0 |
当前字符串长度,即 s.size() |
[capacity] |
15 |
当前容量,对于 SSO 模式,这个值固定为 15(即 _Buf 能容纳的最大字符数,不含空字符) |
[allocator] |
allocator |
内存分配器,默认是 std::allocator<char> |
[原始视图] |
--- | 调试器将原始内存数据以不同形式展示的视图 |
_Mypair |
{...} |
内部用于存储分配器和压缩对的基础类(EBO 空基类优化) |
_Mysize |
0 |
同 size,当前长度 |
_Myres |
15 |
同 capacity,当前容量 |
_Bx |
--- | 联合体,SSO 下显示 _Buf 数组内容 |
_Buf |
char[16] |
SSO 内部缓冲区,即使字符串为空,也能看到 16 个字节的原始数据 |
_Alias |
char[16] |
与 _Buf 共享内存的别名,用于对齐或类型转换 |
_Ptr |
--- | 当容量大于 15 时,_Bx 变为堆指针,此时此字段有效 |
- _Myres <= 15 → SSO 模式,数据在 _Buf 里。
- _Myres > 15 → 堆模式,数据在 _Ptr 指向的堆内存中。
2.4 扩容输出示例
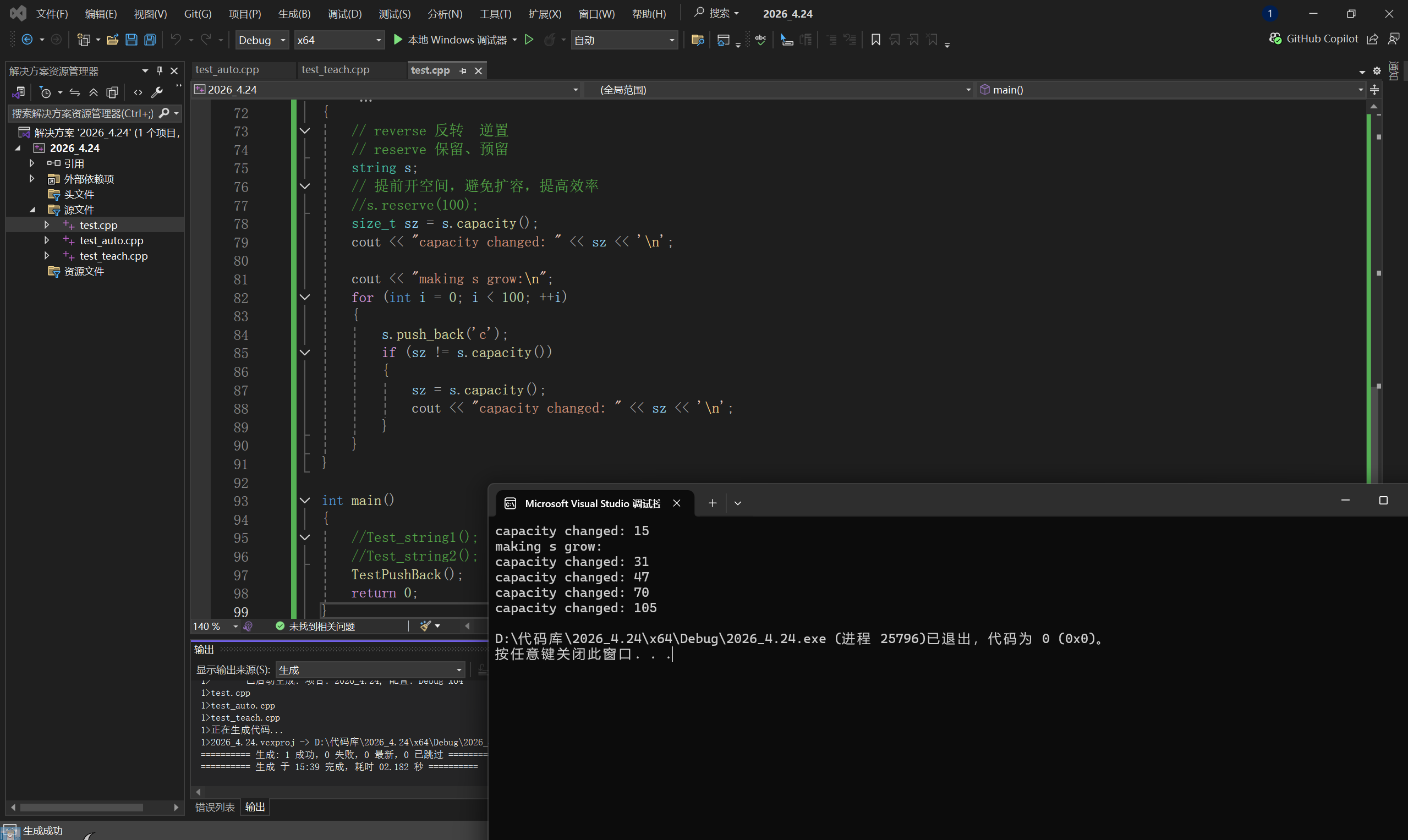
扩容规律:
- 初始时,空字符串处于 SSO 模式,capacity = 15。
- 当第 16 个字符被添加时,SSO 缓冲区溢出,string 被迫切换到堆模式。
- 切换到堆模式后,容量通常会按 1.5 倍或 2 倍 增长(MSVC 大约是 1.5 倍)。
内存切换过程图解:
cpp
初始状态 (SSO 模式):
┌──────────────────────────────────┐
│ _Bx._Buf: [c][c][c]...[c][\0] │ 最多 15 个有效字符
│ _Mysize: 15 │
│ _Myres: 15 │
└──────────────────────────────────┘
push_back 第 16 个字符时:
1. 在堆上分配一块新内存(比如 31 字节)
2. 将 _Buf 中的 15 个字符拷贝到堆内存
3. 添加第 16 个字符
4. _Bx._Ptr 指向堆内存
5. _Myres 更新为 31
切换后 (堆模式):
┌──────────────────────────────────┐
│ _Bx._Ptr ──────────────────────┐ │
│ _Mysize: 16 │ │
│ _Myres: 31 │ │
└─────────────────────────────────┼─┘
V
堆内存:
[c][c][c]...[c][\0] (共 31 字节容量)2.5 reserve 的作用
那么reserve 的作用是什么呢?
代码中的 s.reserve(100); 就是提前切换到堆模式并分配足够容量,避免后续 push_back 时频繁扩容。如果你取消注释,第一次 capacity 就会是至少 100,后续 100 次 push_back 都不会触发扩容。
cpp
string s;
s.reserve(100); // 直接分配至少 100 字节的堆内存
cout << s.capacity() << endl; // 输出 111 或 100(取决于实现)我们可以去查一下reserve:

这里注意一下,他是被视为非约束性的,所以这里情况不一定是什么样子,我们来看看在vs下,当遇到不同的情况,vs是如何进行处理的:
cpp
void Test_string3()
{
string s2("hello worldxxxxxxxxxxxxx");
cout << s2.size() << endl;
cout << s2.capacity() << endl << endl;
s2.reserve(20);
cout << s2.size() << endl;
cout << s2.capacity() << endl << endl;
s2.reserve(28);
cout << s2.size() << endl;
cout << s2.capacity() << endl << endl;
s2.reserve(40);
cout << s2.size() << endl;
cout << s2.capacity() << endl << endl;
s2.clear();
cout << s2.size() << endl;
cout << s2.capacity() << endl << endl;
cout << typeid(string::iterator).name() << endl;
cout << typeid(string::reverse_iterator).name() << endl;
}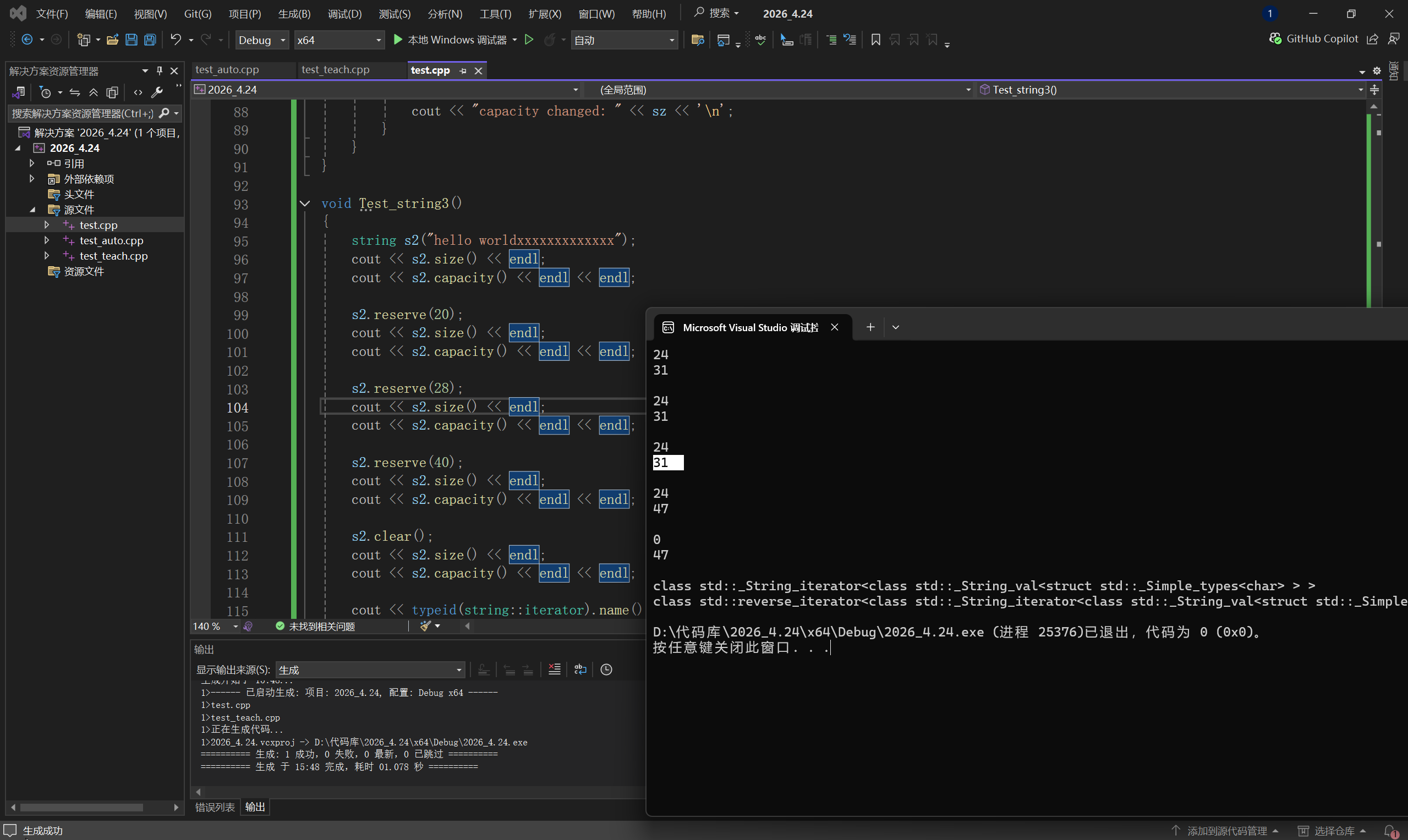
我们可以发现,此时s2开辟完是24个字节,容量为31,这里就是我们之前说的了,然后我们来试试当reserve的空间在比大小小,和在大小和容量之间,和在比容量大的时候,分别是什么情况:
- reserve的值 < size
如图所示,在vs下编译器什么都没有做,也就是说我们并不能通过reserve的值<size,从而使s2发生改变或者缩小,也就是说我们对于s2是不能发生变动的,这点在reserve的介绍中也有所提及
- size < reserve的值 < capacity
如图所示,编译器依然什么都没有改变,虽然此时28大于24,我们感觉改变了容量其实对s2不会造成影响,但编译器表示不行,你这个思想有大大的错误,我不允许,所以在这里我们仍然是什么也没有改变
3.capacity < reserve的值
那么这种是不是就是正常情况了呀,我们就正常扩容就行了
在最后我们需要明确一点,迭代器的用法虽然像指针,但我们绝不能简单的当作指针去使用
2.6 linux下string空间
那么我们之前说过,在vs下,string大小为28,那我们来对比一下linux下的不同:
g++下string的结构
g++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:
- 空间总大小
- 字符串有效长度
- 引用计数
cpp
struct _Rep_base
{
size_type _M_length;
size_type _M_capacity;
_Atomic_word _M_refcount;
};- 指向堆空间的指针,用来存储字符串。