摘要
县域配电网具有线路半径大、分支多、负荷分散、运行环境复杂等特点,极端天气、设备老化和负荷波动都可能引发停电风险。本文基于真实项目 county_grid_self_healing,完整拆解一个"风险预测 + 异常检测 + 拓扑建模 + 故障定位隔离 + 遗传算法自愈恢复 + 可靠性评估"的 Python 仿真系统。项目使用 XGBoost/RandomForest 进行停电风险预测,使用 IsolationForest 识别异常运行状态,使用 NetworkX 构建县域配电网图模型,并通过规则推理和图连通分析定位故障区段,最后用遗传算法搜索联络开关重构方案。
从实际运行结果看,该项目在一组固定随机种子下得到的风险预测指标为:Accuracy=0.6991、Precision=0.6920、Recall=0.6582、F1=0.6747、AUC=0.7626。故障最终定位在 F3-Section-03,隔离后通过闭合联络开关 T2 恢复了 70.24% 的失电负荷,自愈后 SAIDI、SAIFI、ENS 分别改善 48.61%、45.28% 和 64.09%。需要说明的是,项目中的潮流与保护逻辑采用了工程化近似实现,适合课程设计、建模展示和技术博客分析,不是严格的工程级保护整定系统。
目录
[1. 项目背景:为什么县域配电网需要风险感知与自愈?](#1. 项目背景:为什么县域配电网需要风险感知与自愈?)
[2. 项目总体架构](#2. 项目总体架构)
[3. 多源数据构建:如何模拟县域配电网运行状态?](#3. 多源数据构建:如何模拟县域配电网运行状态?)
[3.1 主要字段说明](#3.1 主要字段说明)
[3.2 数据生成不是"随机乱造",而是带业务逻辑的](#3.2 数据生成不是“随机乱造”,而是带业务逻辑的)
[4. 停电风险预测模型:XGBoost 如何识别高风险线路?](#4. 停电风险预测模型:XGBoost 如何识别高风险线路?)
[4.1 模型输入与输出](#4.1 模型输入与输出)
[4.2 风险等级划分](#4.2 风险等级划分)
[4.3 自动降级逻辑](#4.3 自动降级逻辑)
[4.4 模型训练核心代码](#4.4 模型训练核心代码)
[4.5 模型评价指标](#4.5 模型评价指标)
[4.6 实际运行结果](#4.6 实际运行结果)
[4.7 风险等级分布与关键特征](#4.7 风险等级分布与关键特征)
[5. 异常检测模型:用孤立森林发现异常运行状态](#5. 异常检测模型:用孤立森林发现异常运行状态)
[5.1 异常检测代码](#5.1 异常检测代码)
[5.2 实际异常结果](#5.2 实际异常结果)
[6. 配电网拓扑建模:用 NetworkX 把线路变成一张图](#6. 配电网拓扑建模:用 NetworkX 把线路变成一张图)
[6.1 本项目的真实拓扑规模](#6.1 本项目的真实拓扑规模)
[6.2 拓扑构建核心代码](#6.2 拓扑构建核心代码)
[6.3 代码中的潮流是近似计算](#6.3 代码中的潮流是近似计算)
[7. 故障定位与故障隔离:规则推理 + 图搜索](#7. 故障定位与故障隔离:规则推理 + 图搜索)
[7.1 真实代码如何定位故障](#7.1 真实代码如何定位故障)
[7.2 故障隔离流程](#7.2 故障隔离流程)
[7.3 实际故障场景结果](#7.3 实际故障场景结果)
[8. 自愈恢复优化:遗传算法如何选择最优开关动作?](#8. 自愈恢复优化:遗传算法如何选择最优开关动作?)
[8.1 染色体编码与目标函数](#8.1 染色体编码与目标函数)
[8.2 约束如何体现在代码里](#8.2 约束如何体现在代码里)
[8.3 初始化、交叉和变异](#8.3 初始化、交叉和变异)
[8.4 适应度函数是整个自愈策略的核心](#8.4 适应度函数是整个自愈策略的核心)
[8.5 遗传算法迭代流程](#8.5 遗传算法迭代流程)
[8.6 实际恢复结果怎么理解?](#8.6 实际恢复结果怎么理解?)
[9. 可靠性指标:自愈前后到底改善了多少?](#9. 可靠性指标:自愈前后到底改善了多少?)
[9.1 可靠性计算代码](#9.1 可靠性计算代码)
[9.2 实际可靠性对比](#9.2 实际可靠性对比)
[10. 结果可视化:从风险分布到恢复路径](#10. 结果可视化:从风险分布到恢复路径)
1. 项目背景:为什么县域配电网需要风险感知与自愈?
相比城市核心区电网,县域配电网往往具备几个典型特征:线路长、分支多、联络关系相对稀疏、设备分布分散,而且对天气变化更敏感。暴雨、大风、雷电会提高线路跳闸和杆塔故障概率;设备老化和检修不足会削弱系统韧性;负荷高峰时的过载和电压偏差,又会进一步放大停电风险。
这类场景下,仅靠"故障后抢修"是不够的,还需要在故障前后分别做两件事:
风险感知,解决"哪里更可能出故障、风险有多高"的问题。
自愈恢复,解决"故障发生后如何尽快隔离故障、恢复非故障区供电"的问题。
这背后对应的是配电自动化中的 FLISR 思想,即:
Fault Location, Isolation and Service Restoration
翻译过来就是:
故障定位、故障隔离与供电恢复
如果把整个过程拆开,可以理解为四个层次:
- 风险感知:提前识别高风险线路或区段。
- 故障定位:故障发生后判断问题在哪一段。
- 故障隔离:快速切除故障,缩小停电影响范围。
- 自愈恢复:通过联络开关转供,优先恢复重要负荷和可恢复区域。
本文要介绍的项目,正是把这四层能力串成了一个完整的 Python 仿真流程。
2. 项目总体架构
这个项目的真实结构如下,主程序、算法模块、数据文件和输出图像都已经组织成标准工程目录。
| 文件 / 模块 | 主要功能 | 对应算法 |
|---|---|---|
| main.py | 主程序入口,串联数据生成、预测、异常检测、故障处理和可视化 | 流程控制 |
| src/data_generator.py | 生成模拟气象、负荷、设备和停电标签数据 | 数据模拟 + 概率建模 |
| src/risk_model.py | 训练停电风险预测模型,输出概率和风险等级 | XGBoost / RandomForest |
| src/anomaly_detection.py | 识别异常运行状态 | Isolation Forest |
| src/topology_model.py | 构建县域配电网拓扑并估算近似运行状态 | NetworkX 图模型 |
| src/fault_location.py | 基于告警关系和连通状态定位故障并执行隔离 | 规则推理 + 图连通分析 |
| src/self_healing_ga.py | 搜索最优联络开关恢复方案 | 遗传算法 |
| src/reliability_index.py | 计算自愈前后可靠性指标 | SAIDI / SAIFI / ENS |
| src/visualization.py | 统一输出图表 | Matplotlib / Seaborn |
| data/synthetic_grid_data.csv | 模拟运行数据 | 模型输入数据 |
| data/grid_topology.csv | 拓扑边属性导出 | 拓扑结构结果 |
| outputs/*.png | 风险、异常、拓扑、恢复、可靠性等图像 | 结果展示 |
从 main.py 的实际实现看,项目主流程是:
- 创建 data 和 outputs 目录
- 生成模拟数据
- 训练停电风险模型
- 做异常检测
- 构建配电网拓扑
- 选取高风险候选故障区段
- 构造上下游告警信号并定位故障
- 执行故障隔离
- 用遗传算法做联络重构
- 计算自愈前后可靠性指标
- 输出控制台报告和全部图片
这种结构的好处是,既能单独研究某个算法模块,也能作为一个完整项目直接运行展示。
3. 多源数据构建:如何模拟县域配电网运行状态?
真实配电网停电数据通常比较敏感,因此这类项目首先要解决一个问题:如何造出"像真的一样"的数据。
这个项目在 data_generator.py 中构造了 15 个输入特征和 1 个标签字段。按照代码逻辑,数据规模为:

实际生成的 synthetic_grid_data.csv 共有 4320 行、19 列。
3.1 主要字段说明
| 字段名 | 含义 | 对停电风险的影响 |
|---|---|---|
| rainfall | 降雨量 | 降雨越大,绝缘下降、树障和接地风险越高 |
| wind_speed | 风速 | 风速越大,倒杆、断线和异物搭挂风险增加 |
| lightning_count | 雷电次数 | 雷击容易引发线路跳闸 |
| avg_load_rate | 平均负载率 | 长时高负载会增加设备热应力 |
| max_load_rate | 最大负载率 | 峰值负载越高,过载风险越高 |
| load_fluctuation | 负荷波动率 | 波动越剧烈,运行状态越不稳定 |
| equipment_age | 设备年限 | 设备越老,故障概率越高 |
| maintenance_count | 检修次数 | 检修越充分,风险越低 |
| historical_fault_count | 历史故障次数 | 历史故障多的区段,未来风险通常更高 |
| line_length | 线路长度 | 线路越长,暴露面越大 |
| supply_radius | 供电半径 | 半径越大,末端电压和故障影响范围更敏感 |
| important_user_count | 重要用户数量 | 重要用户越多,区段运行压力和恢复优先级越高 |
| voltage_deviation | 电压偏差 | 偏差增大往往是异常运行前兆 |
| current_change_rate | 电流变化率 | 电流突变反映负荷冲击或潜在故障 |
| outage_label | 是否发生停电 | 0 表示未停电,1 表示停电 |
3.2 数据生成不是"随机乱造",而是带业务逻辑的
下面这段代码解决的是"如何把天气、负荷、设备状态映射成停电概率"这个问题:
python
risk_score = (
-6.7
+ 0.035 * rainfall
+ 0.085 * wind_speed
+ 0.22 * lightning_count
+ 0.06 * equipment_age
+ 0.38 * historical_fault_count
+ 2.8 * max_load_rate
+ 1.6 * load_fluctuation
+ 7.5 * abs(voltage_deviation)
+ 0.9 * current_change_rate
+ 0.04 * line_length
+ 0.05 * supply_radius
+ 0.08 * important_user_count
- 0.12 * maintenance_count
)
outage_probability = float(_sigmoid(risk_score))
outage_label = int(rng.random() < outage_probability)这段代码来自项目真实实现,体现的是一种"规则嵌入式数据生成"思路。也就是说,数据虽然是模拟的,但标签不是瞎打的,而是通过一个带业务含义的风险得分函数生成。可以看到:
- rainfall、wind_speed、lightning_count 都是正向提高风险;
- equipment_age 和 historical_fault_count 也会抬高风险;
- max_load_rate、load_fluctuation、voltage_deviation 和 current_change_rate 代表运行压力;
- maintenance_count 则是负向项,检修越多风险越低。
这类生成方式的价值在于,它让后续机器学习模型有机会"学到"符合电网常识的规律,而不是仅仅记忆随机噪声。
另外,代码里还有一个容易被忽略但很重要的步骤:clean_synthetic_data() 会对温度、风速、负载率、电压偏差等变量做边界裁剪,避免模拟值超出合理物理范围。这一点让数据更接近真实运行记录。
4. 停电风险预测模型:XGBoost 如何识别高风险线路?
风险预测模块位于 risk_model.py。从代码实现看,这里不是单一模型,而是"优先 XGBoost,失败后自动降级到随机森林"。
4.1 模型输入与输出
模型输入可写成:
其中,项目中的特征包括降雨量、风速、雷电次数、负载率、设备年限、历史故障次数、线路长度、供电半径、电压偏差、电流变化率等 15 个变量。
风险预测函数可以表示为:
其中:
表示停电概率;
4.2 风险等级划分
项目中对风险等级的划分是直接写在代码里的:
 对应的真实代码逻辑非常直接:
对应的真实代码逻辑非常直接:
python
def classify_risk_level(probability: float) -> str:
if probability < 0.3:
return "低风险"
if probability < 0.7:
return "中风险"
return "高风险"4.3 自动降级逻辑
下面这段代码解决的是"如果本机没有 xgboost 怎么办"这个问题:
python
def _build_primary_model(random_seed: int) -> tuple[Any, str, bool]:
try:
from xgboost import XGBClassifier
model = XGBClassifier(
n_estimators=260,
max_depth=4,
learning_rate=0.05,
subsample=0.9,
colsample_bytree=0.9,
reg_lambda=1.0,
objective="binary:logistic",
eval_metric="logloss",
random_state=random_seed,
)
return model, "XGBoost", False
except Exception:
return _build_fallback_model(random_seed), "RandomForest", True这里的写法很适合工程项目。一方面,优先尝试性能更强的 XGBoost;另一方面,如果环境缺少依赖,也不会让整个项目失败,而是回退到 RandomForestClassifier。这对课程设计和博客项目尤其友好,因为不同电脑环境差异很大。
4.4 模型训练核心代码
下面这段代码解决的是"如何训练模型并输出概率预测":
python
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.25,
random_state=random_seed,
stratify=y,
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1]
cm = confusion_matrix(y_test, y_pred)
full_prob = model.predict_proba(X)[:, 1]
result_df = data.copy()
result_df["risk_probability"] = full_prob
result_df["risk_level"] = result_df["risk_probability"].apply(classify_risk_level)这段代码的含义很清楚:
- X_train 是训练特征;
- y_train 是停电标签;
- y_pred 是二分类预测结果;
- y_prob 是模型给出的停电概率;
- risk_probability 再进一步映射成"低、中、高"三级风险。
4.5 模型评价指标
项目里输出了 Accuracy、Precision、Recall、F1 和 AUC。它们分别对应:
在停电风险预测场景下,这几个指标的意义分别是:
- Accuracy:整体判断对了多少;
- Precision:模型判为"停电"的样本里,有多少真会停电;
- Recall:实际会停电的样本里,有多少被提前识别出来;
- F1:综合平衡精确率和召回率;
- AUC:模型区分"停电"和"未停电"的能力。
4.6 实际运行结果
在当前项目的实际运行中,模型结果如下:
| 指标 | 数值 | 含义 |
|---|---|---|
| Accuracy | 0.6991 | 整体分类正确率 |
| Precision | 0.6920 | 预测为停电样本中真正停电的比例 |
| Recall | 0.6582 | 实际停电样本中被识别出来的比例 |
| F1-score | 0.6747 | 精确率与召回率的综合表现 |
| AUC | 0.7626 | 模型区分停电与非停电样本的能力 |
对应混淆矩阵为:
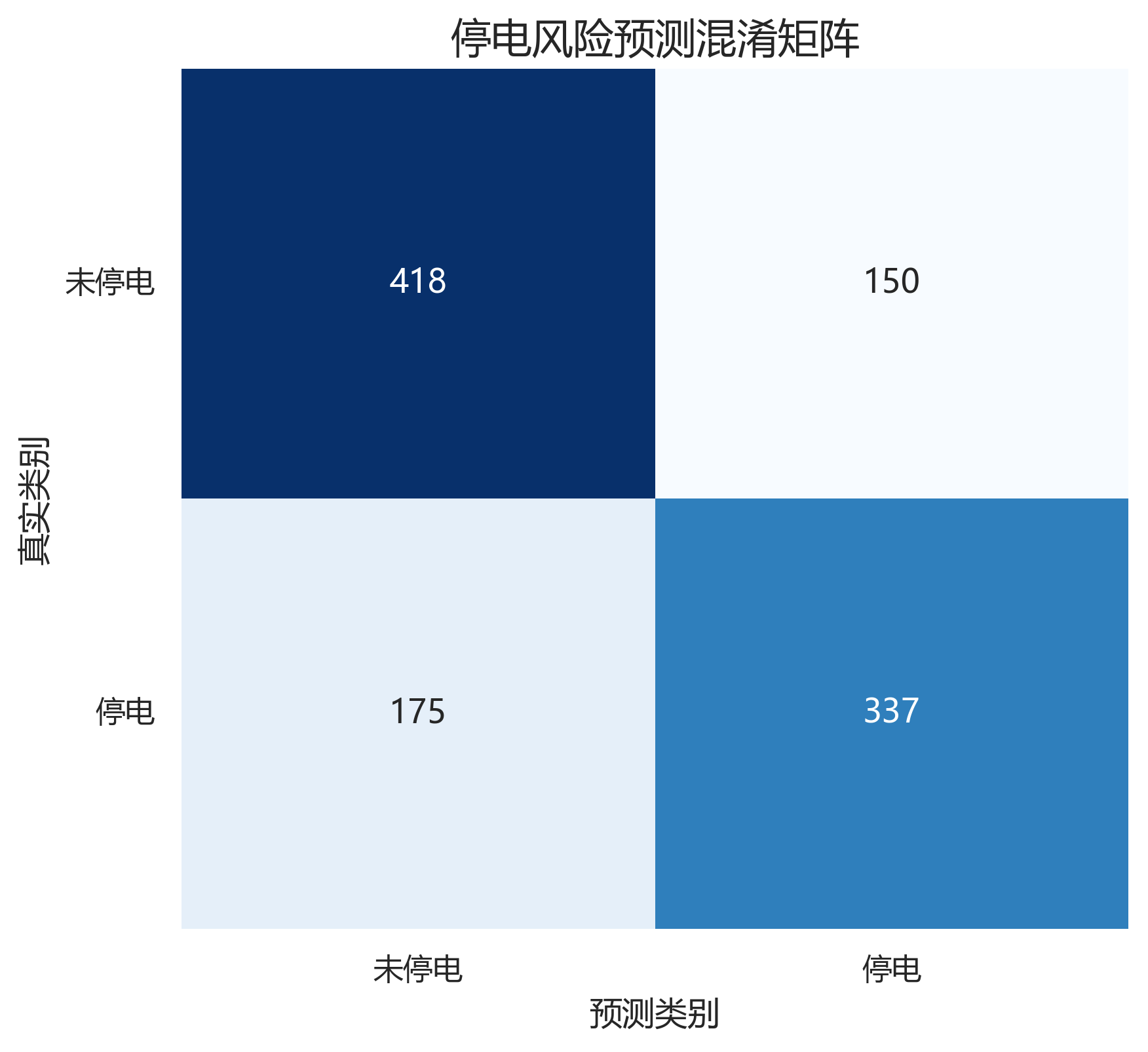
| 真实\预测 | 未停电 | 停电 |
|---|---|---|
| 未停电 | 418 | 150 |
| 停电 | 175 | 337 |
从结果看,这个模型已经具有一定的风险辨识能力,适合做建模展示和算法演示。
4.7 风险等级分布与关键特征
项目运行后,4320 条样本的风险等级分布为:
| 风险等级 | 样本数 |
|---|---|
| 低风险 | 1403 |
| 中风险 | 1784 |
| 高风险 | 1133 |
这里有一个细节值得说明:主程序控制台中打印的是"高风险线路数量",但从代码看,它统计的是高风险样本条数,而不是唯一线路数。这一点在写论文或汇报时最好表述为"高风险样本数"更准确。
模型前五个重要特征为:
| 特征 | 重要性 |
|---|---|
| historical_fault_count | 0.1633 |
| lightning_count | 0.0970 |
| rainfall | 0.0786 |
| max_load_rate | 0.0775 |
| voltage_deviation | 0.0737 |
这和数据生成逻辑基本一致,说明模型学到的规律与模拟设定是统一的。
5. 异常检测模型:用孤立森林发现异常运行状态
风险预测关注的是"未来出故障的概率",而异常检测关注的是"当前运行状态是否异常"。两者是互补关系。
在配电网运行中,以下现象都可能表现为异常:
- 电压偏差突然增大;
- 电流变化率异常;
- 最大负载率持续偏高;
- 雷雨天气下负荷波动显著增加。
项目在 anomaly_detection.py 中使用了 IsolationForest。它的基本思想是:异常点更容易被随机切分出来,因此在树结构中的平均路径长度更短。
异常评分可以简化写成:
其中:
5.1 异常检测代码
下面这段代码解决的是"如何从运行状态中找出异常样本":
python
ANOMALY_FEATURES = [
"voltage_deviation",
"current_change_rate",
"max_load_rate",
"load_fluctuation",
"wind_speed",
"rainfall",
"lightning_count",
]
model = IsolationForest(
n_estimators=240,
contamination=contamination,
random_state=random_seed,
)
subset = data[ANOMALY_FEATURES]
anomaly_label = model.fit_predict(subset)
anomaly_score = model.decision_function(subset)
data["anomaly_score"] = anomaly_score
data["anomaly_label"] = anomaly_label这里的关键点有两个:
- anomaly_label = -1 表示异常;
- anomaly_label = 1 表示正常。
也就是说,项目不是在做监督式故障分类,而是在无标签前提下识别"行为异常"的运行样本。
5.2 实际异常结果
当前项目运行结果中:
- 异常样本数量:346
- 异常比例:8.01%
这个比例和代码里 contamination=0.08 是一致的。输出的散点图以"最大负载率"为横轴、"电压偏差"为纵轴,红色点表示异常。图中可以明显看到,异常点主要分布在高负载率、高电压偏差以及边界离群区域,这和电网实际经验是一致的。
6. 配电网拓扑建模:用 NetworkX 把线路变成一张图
如果说风险模型回答的是"哪里危险",那么拓扑模型回答的就是"故障发生后影响谁、还能怎么转供"。
配电网可以抽象为图:
其中:
6.1 本项目的真实拓扑规模
根据代码运行结果,这个模拟配电网共有:
- 节点数:33
- 边数:35
- 馈线数:3
- 联络开关:3 个,分别为 T1、T2、T3
节点类型分布如下:
| 节点类型 | 含义 | 数量 |
|---|---|---|
| source | 电源点 | 1 |
| switch | 分段开关 | 12 |
| load | 普通负荷 | 12 |
| important_load | 重要负荷 | 5 |
| tie_switch | 联络开关 | 3 |
需要特别说明的是,虽然最初设计中可以设想有 fault 节点,但当前代码并没有单独创建 fault 类型节点,而是通过边属性 faulted 和红色线路高亮来表示故障区段。这是一个真实实现上的简化。
6.2 拓扑构建核心代码
下面这段代码解决的是"如何把配电设备组织成图结构":
python
graph.add_node(
SOURCE_NODE,
node_type="source",
display_name=SOURCE_NODE,
controllable=False,
closed=1,
demand_kw=0.0,
)
feeder_layout = {
"F1": {"y": 4.2, "switches": ["F1_S1", "F1_S2", "F1_S3", "F1_S4"]},
"F2": {"y": 0.0, "switches": ["F2_S1", "F2_S2", "F2_S3", "F2_S4"]},
"F3": {"y": -4.2, "switches": ["F3_S1", "F3_S2", "F3_S3", "F3_S4"]},
}
_add_edge(
graph,
previous_node,
switch_id,
line_id=line_id,
capacity=capacity,
impedance=impedance,
controlled_by=switch_id,
edge_kind="section",
)这段代码的含义是:
- 节点表示电气设备或负荷点;
- 边表示馈线区段或支线;
- capacity 表示线路容量;
- impedance 表示线路阻抗;
- controlled_by 表示这条边由哪个开关控制通断;
- status 在后续会根据开关状态更新。
代码里还定义了多个重要负荷,例如县人民医院、通信基站、自来水厂、政务云机房、冷链物流园,这让后面的"重要负荷优先恢复"更有业务味道。
6.3 代码中的潮流是近似计算
下面这段代码解决的是"在当前开关状态下,如何估算线路负荷、网损和电压偏差":
python
bfs_tree = nx.bfs_tree(energized_active_graph, source)
traversal_order = list(nx.topological_sort(bfs_tree))
downstream_load = {}
edge_flow = {}
for node in reversed(traversal_order):
own_demand = float(graph.nodes[node].get("demand_kw", 0.0)) if node in energized_nodes else 0.0
total_demand = own_demand
for child in bfs_tree.successors(node):
total_demand += downstream_load[child]
downstream_load[node] = total_demand
if node != source:
parent = next(bfs_tree.predecessors(node))
edge_flow[frozenset((parent, node))] = total_demand
line_loss += (flow / max(edge_data["capacity"], 1.0)) ** 2 * edge_data["impedance"] * 180
voltage_drop = min(0.12, 0.008 + path_drop[node])这里用的是"下游负荷累加 + 路径阻抗估计"的近似方法,而不是严格潮流计算。也就是说:
- 用 BFS 树确定供电层级;
- 用下游负荷总和近似支路潮流;
- 用线路负载率和阻抗估算网损;
- 用路径压降近似电压偏差。
这不是 OpenDSS 或 DistFlow 级别的精细仿真,但对于毕业设计、算法博客和建模比赛来说,已经足够清楚地表达"重构方案会影响线路载荷和电压质量"这个核心思想。
7. 故障定位与故障隔离:规则推理 + 图搜索
在 FLISR 中,故障定位并不一定要上来就做复杂机器学习。很多时候,一个清晰可靠的规则推理框架,反而更符合配电自动化逻辑。
项目中的定位逻辑可以概括为:
当上游开关检测到告警,而下游开关未检测到告警时,故障大概率位于两者之间。
可以写成:
7.1 真实代码如何定位故障
下面这段代码解决的是"根据上下游告警开关,确定故障区段并找出受影响负荷":
python
for feeder, switches in feeders.items():
alarm_indices = sorted(switches.index(sw) for sw in alarm_switches if sw in switches)
no_alarm_indices = sorted(switches.index(sw) for sw in no_alarm_switches if sw in switches)
if not alarm_indices:
continue
upstream_index = max(alarm_indices)
downstream_candidates = [index for index in no_alarm_indices if index > upstream_index]
if not downstream_candidates:
continue
downstream_index = min(downstream_candidates)
upstream_switch = switches[upstream_index]
downstream_switch = switches[downstream_index]
line_data = graph[upstream_switch][downstream_switch]
fault_line = line_data["line_id"]
simulated_fault_graph = apply_switch_states(
graph,
get_switch_states(graph),
faulted_lines={fault_line},
)
affected_nodes = get_unenergized_load_nodes(simulated_fault_graph)这段代码不是直接跑 BFS/DFS 来"猜故障点",而是先用告警规则缩小故障区段,再通过图连通状态计算失电负荷。这个思路更贴近保护与配电自动化的实际逻辑。
需要如实说明的是:主程序中的告警信号也是模拟生成的。main.py 会先选择一个高风险候选故障区段,再构造对应的上游告警和下游无告警组合,用于驱动定位模块。这意味着这里的故障定位是"半仿真"的,而不是接真实 SCADA 告警流。
7.2 故障隔离流程
项目中的故障隔离动作可以总结为:
| 步骤 | 操作 | 目的 |
|---|---|---|
| 1 | 识别故障区段 | 判断故障发生位置 |
| 2 | 查找相关开关 | 确定隔离动作对象 |
| 3 | 断开故障相关边 | 防止故障扩大 |
| 4 | 搜索失电区域 | 统计受影响负荷 |
| 5 | 进入恢复优化 | 为自愈算法提供输入 |
对应代码中,isolate_fault() 会断开 fault_result"isolation_switches" 中的开关,并重新计算失电区域。
7.3 实际故障场景结果
在当前运行结果中:
- 故障区段:F3-Section-03
- 受影响负荷:沿街商业负荷 K、冷链物流园、居民台区 L
- 受影响重要用户:冷链物流园
- 隔离动作:
- 断开开关 F3_S3
- 断开开关 F3_S4
这里也要说明一个实现细节:项目中的隔离逻辑是简化版,主要通过"将故障边 status=0 + 打开下游相关开关"来切除失电区域,而不是严格按照工程保护装置双侧边界开关模型来建模。这种简化适合算法展示,但在工程系统中还需要结合保护定值和配网自动化装置实际位置。
8. 自愈恢复优化:遗传算法如何选择最优开关动作?
在故障区段隔离之后,下一步就是恢复供电。这本质上是一个组合优化问题:
- 哪些联络开关应该闭合?
- 是否会形成环网?
- 某条线路会不会过载?
- 哪些重要负荷要优先恢复?
- 开关动作次数能不能再少一点?
这也是为什么项目选择遗传算法来做恢复优化。
8.1 染色体编码与目标函数
项目中的染色体编码为:
其中:
需要注意的是,当前代码并没有把所有开关都纳入染色体,而是将可优化对象简化为联络开关集合,也就是 T1、T2、T3。因此这里的基因长度实际上是 3,而不是整个网络所有开关。这是一个非常重要的实现细节。
目标函数可以写成:
其中:
在工程含义上:
除此之外,代码还额外引入了"重要负荷恢复比例奖励",并对过载、成环、超电压偏差进行额外惩罚。
8.2 约束如何体现在代码里
理论上可以写成:
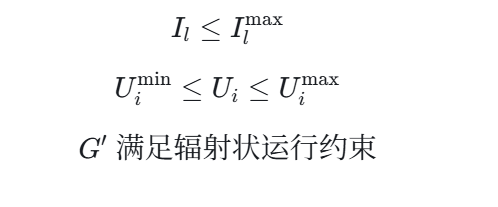
同时满足:
- 故障区段不得重新投入;
- 重要负荷优先恢复。
需要如实说明的是,代码里这些约束主要以适应度惩罚项的形式体现,而不是通过严格的数学规划求解器硬约束实现。这种做法对 GA 来说很常见,也更容易编码。
8.3 初始化、交叉和变异
下面这段代码解决的是"如何构造种群并做基本遗传操作":
python
def _initialize_population(population_size: int, gene_count: int, rng):
if gene_count == 0:
return [np.array([], dtype=int)]
population = [np.zeros(gene_count, dtype=int), np.ones(gene_count, dtype=int)]
for gene_index in range(gene_count):
gene = np.zeros(gene_count, dtype=int)
gene[gene_index] = 1
population.append(gene)
while len(population) < population_size:
population.append(rng.integers(0, 2, size=gene_count, dtype=int))
return population[:population_size]这段初始化不是完全随机,而是有意识地把"全断开""全闭合""单开关动作"这些典型方案预先放进种群。对于只有 3 个联络开关的小规模问题,这种设计很合理,因为能更快覆盖关键候选解。
8.4 适应度函数是整个自愈策略的核心
下面这段代码解决的是"如何评价一个恢复方案到底好不好":
python
p_restore = weighted_restored_load / total_weighted_load
important_restore_ratio = restored_important_kw / total_important_load if total_important_load else 1.0
switch_operation_count = int(
sum(abs(switch_states[switch] - base_switch_states.get(switch, 0)) for switch in candidate_switches)
)
line_loss = performance["line_loss"]
avg_voltage_dev = performance["avg_voltage_deviation"]
max_voltage_dev = performance["max_voltage_deviation"]
cycle_count = len(nx.cycle_basis(active_graph)) if active_graph.number_of_edges() else 0
overload_count = len(performance["overloaded_lines"])
fitness = (
weights["alpha"] * p_restore
- weights["beta"] * switch_penalty
- weights["gamma"] * loss_penalty
- weights["delta"] * voltage_penalty
+ 0.08 * important_restore_ratio
)
if overload_count > 0:
fitness -= 0.65 * overload_count
if cycle_count > 0:
fitness -= 0.85 * cycle_count
if max_voltage_dev > 0.08:
fitness -= 1.2 * (max_voltage_dev - 0.08) / 0.08这里最值得注意的是两点:
- weighted_restored_load 用了 priority_weight,重要负荷权重更高;
- cycle_count 和 overload_count 直接进入惩罚项,保证网络尽量保持辐射状且不过载。
也就是说,这个 GA 不是单纯追求"恢复节点数最多",而是在恢复能力、动作代价、运行质量之间做平衡。
8.5 遗传算法迭代流程
| 阶段 | 作用 | 在自愈恢复中的含义 |
|---|---|---|
| 编码 | 将联络开关状态转化为染色体 | 表示不同重构方案 |
| 初始化 | 生成候选方案 | 构造初始恢复策略 |
| 适应度计算 | 评价方案优劣 | 恢复越多、动作越少、越不超限越好 |
| 选择 | 保留优秀个体 | 保留更优恢复方案 |
| 交叉 | 组合两个方案 | 搜索新的开关组合 |
| 变异 | 随机扰动个体 | 防止陷入局部最优 |
| 迭代更新 | 维护最优个体 | 输出最终自愈动作序列 |
8.6 实际恢复结果怎么理解?
当前项目的实际恢复结果是:
- 闭合联络开关:T2
- 恢复负荷节点:L11、I05
- 未恢复负荷节点:L12
- 恢复负荷比例:70.24%
- 开关动作次数:1
- 估算网损:52.1012
- 平均电压偏差:0.0200
这里有一个很值得写进博客的细节:
- restore_ratio = 70.24% 是按 负荷功率 计算的;
- load_restore_ratio.png 饼图显示的是 节点数量比例,也就是 3 个失电节点中恢复了 2 个,因此是 66.7%。
两者不矛盾,只是统计口径不同。
另外,restoration_process.png 中的收敛曲线几乎是一条水平线。这并不是算法失效,而是因为当前问题规模很小:候选联络开关只有 3 个,理论组合也只有 2^3=8 种,初始化阶段已经覆盖了关键方案,所以最优解很早就被找到,后续迭代没有再提升。这也是一个真实工程实现中很常见的现象。
9. 可靠性指标:自愈前后到底改善了多少?
评价自愈效果,不能只看"恢复了几个节点",更关键的是要看系统可靠性有没有提升。
项目在 reliability_index.py 中计算了三个经典指标:
其中:
9.1 可靠性计算代码
下面这段代码解决的是"如何把恢复前后场景转化为可靠性指标":
python
def compute_reliability_indices(outage_records, total_customers):
total_customers = max(total_customers, 1)
saidi = sum(record["duration_h"] * record["customers"] for record in outage_records) / total_customers
saifi = sum(record["frequency"] * record["customers"] for record in outage_records) / total_customers
ens = sum(record["load_kw"] * record["duration_h"] for record in outage_records) / 1000.0
return {"SAIDI": float(saidi), "SAIFI": float(saifi), "ENS": float(ens)}而在自愈前后场景设定中,项目做了一个清晰的近似:
- 自愈前,失电区域按 repair_time_h=4.0 小时计算;
- 自愈后,已恢复用户按 switching_time_h=0.35 小时计算短时停电;
- 对已恢复用户,停电频率也按 0.15 做折减。
这是一种典型的建模近似,能够把"快速转供"的价值量化到可靠性指标上。
9.2 实际可靠性对比
| 指标 | 自愈前 | 自愈后 | 改善率 |
|---|---|---|---|
| SAIDI | 0.6568 | 0.3375 | 48.61% |
| SAIFI | 0.1642 | 0.0898 | 45.28% |
| ENS | 3.3600 | 1.2065 | 64.09% |
从这张表就能看出,自愈恢复并不只是"让图上多亮几个节点",而是真正降低了平均停电时长、停电频率和未供电电量。
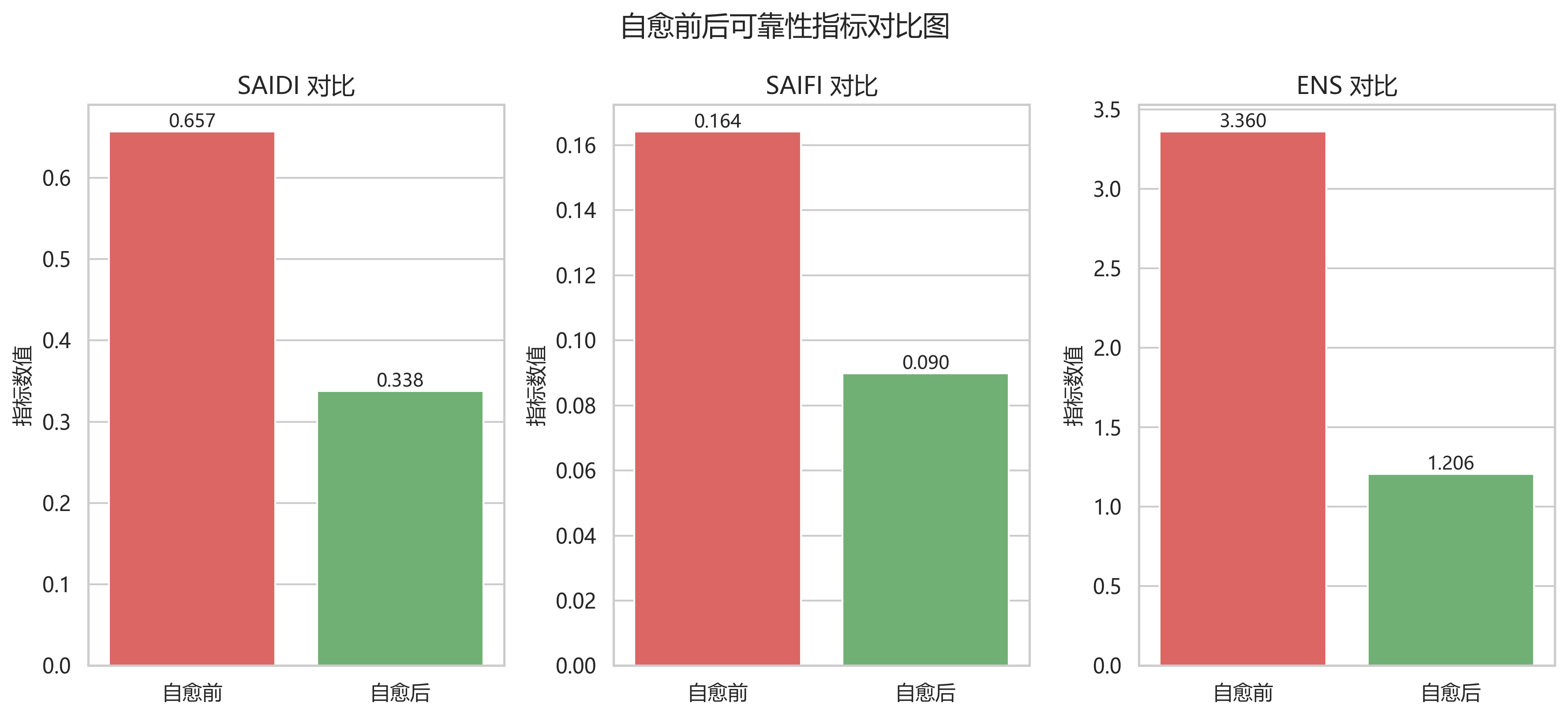
图 reliability_index.png 也很直观:三个指标在自愈后都明显下降,说明故障隔离与联络转供策略确实有效。
10. 结果可视化:从风险分布到恢复路径
这个项目的一个亮点,是把每一步结果都做成了可视化图像。实际 outputs 目录中生成了 11 张图片,文件名与含义如下:
结合图片内容,可以进一步解释几个重点:
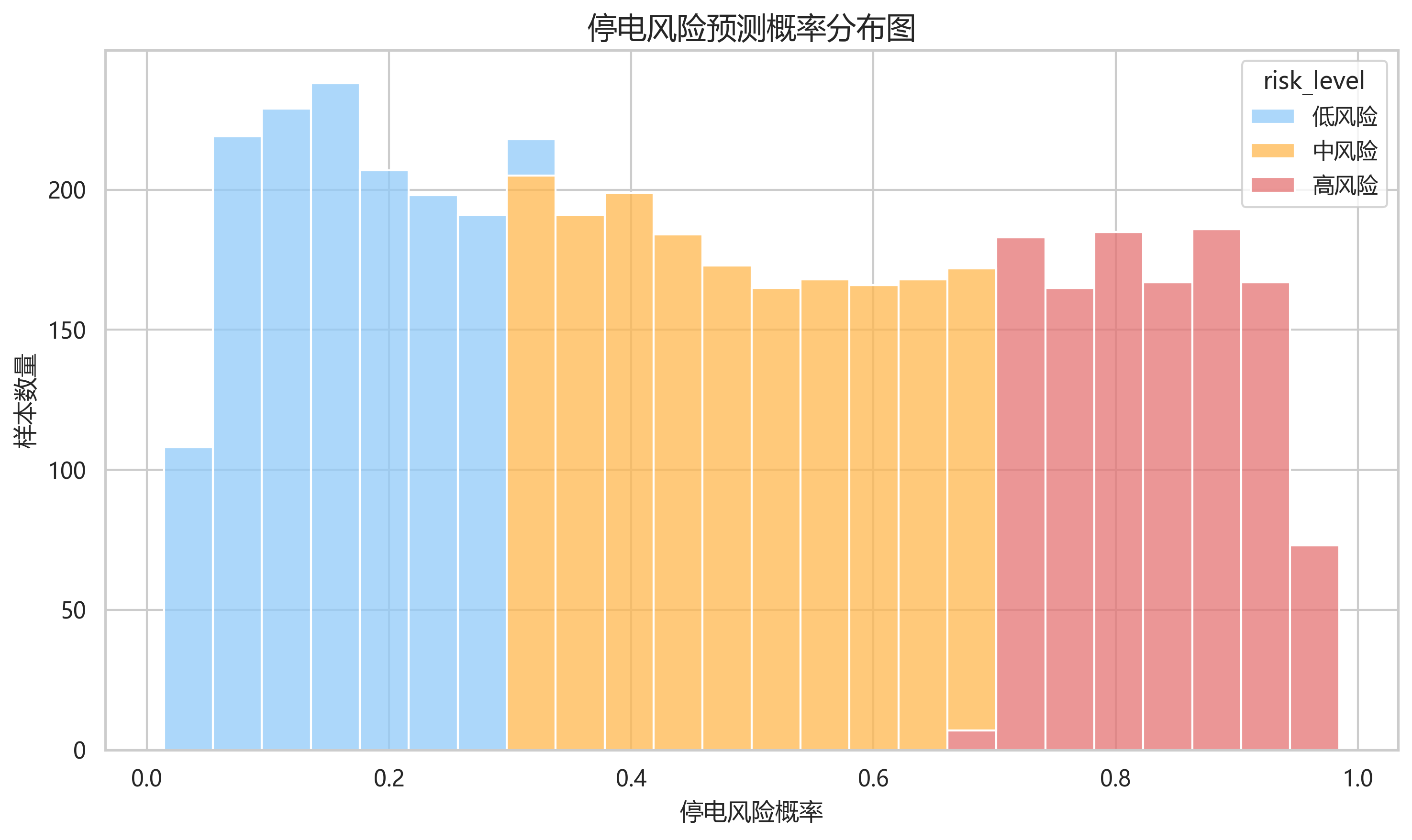
risk_prediction_result.png 不是"12 条线路的风险柱状图",而是所有样本记录的风险概率分布图。图中低风险、中风险、高风险三段区间分界清晰,和项目中的阈值划分一致。
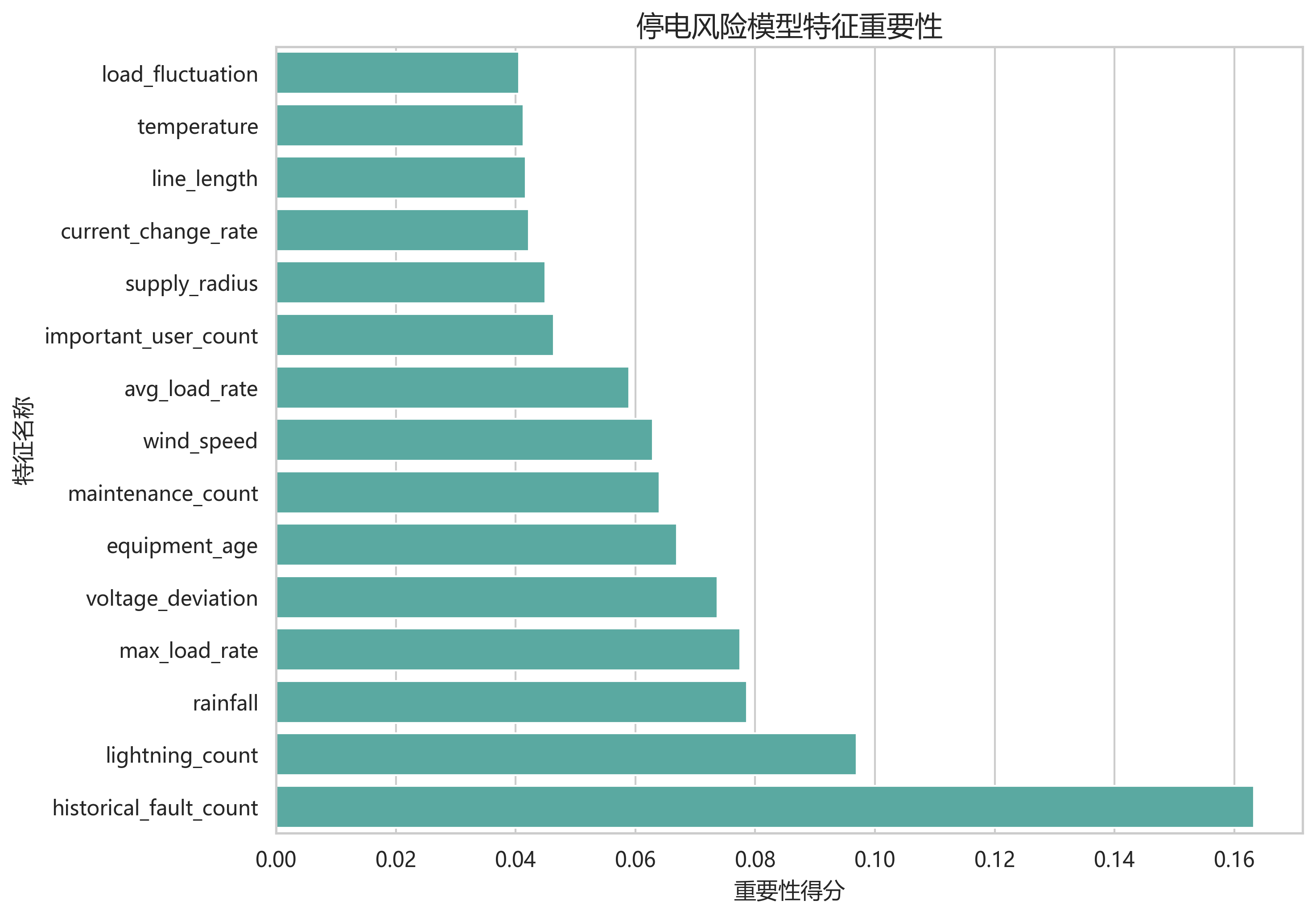
feature_importance.png 显示 historical_fault_count 的重要性最高,其次是 lightning_count、rainfall、max_load_rate 和 voltage_deviation。这说明模型既关注外部扰动,也关注设备劣化与运行状态。
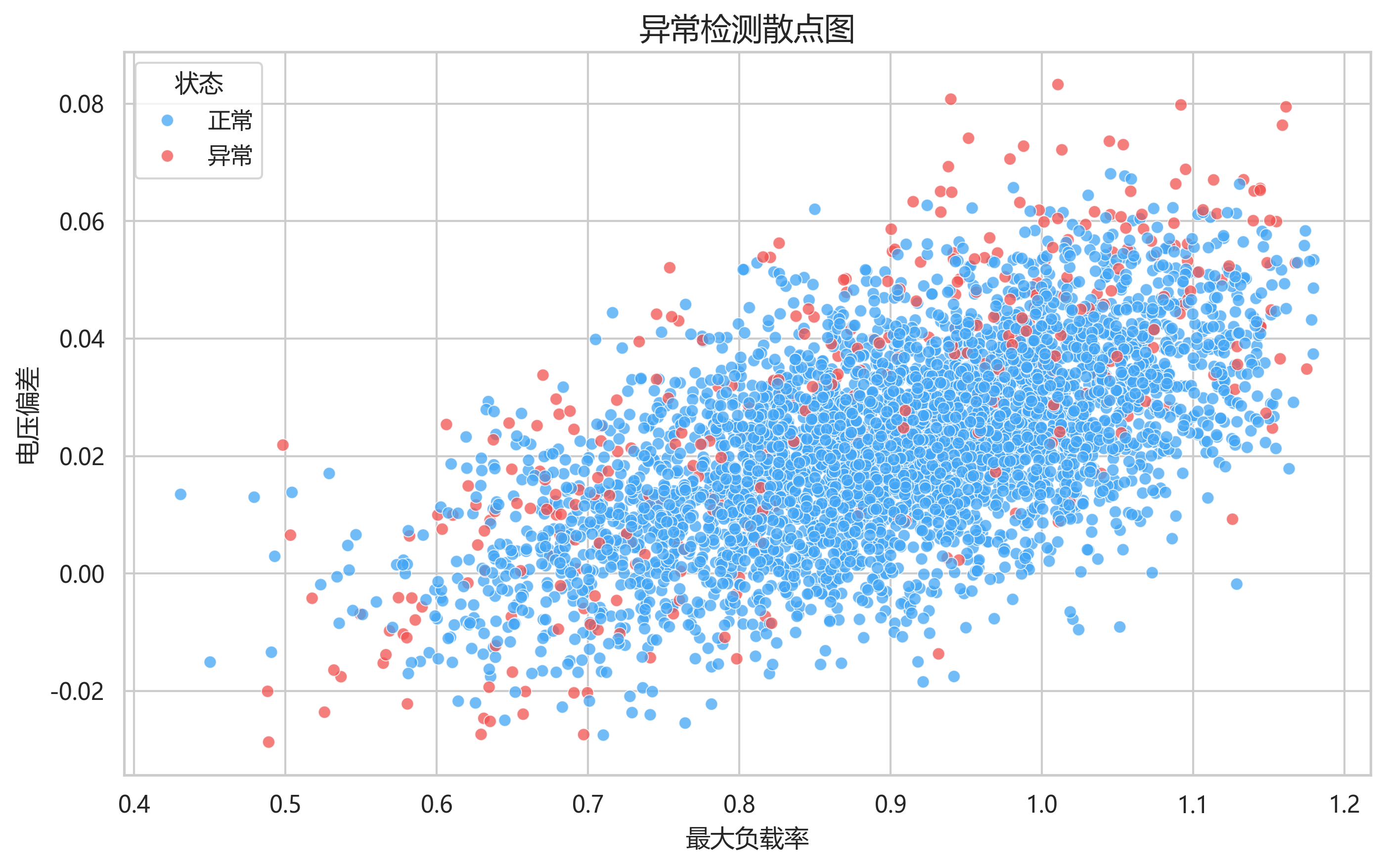
anomaly_detection.png 中红色异常点更多分布在高负载率和较大电压偏差附近,说明异常检测模块能把边缘运行状态挑出来。
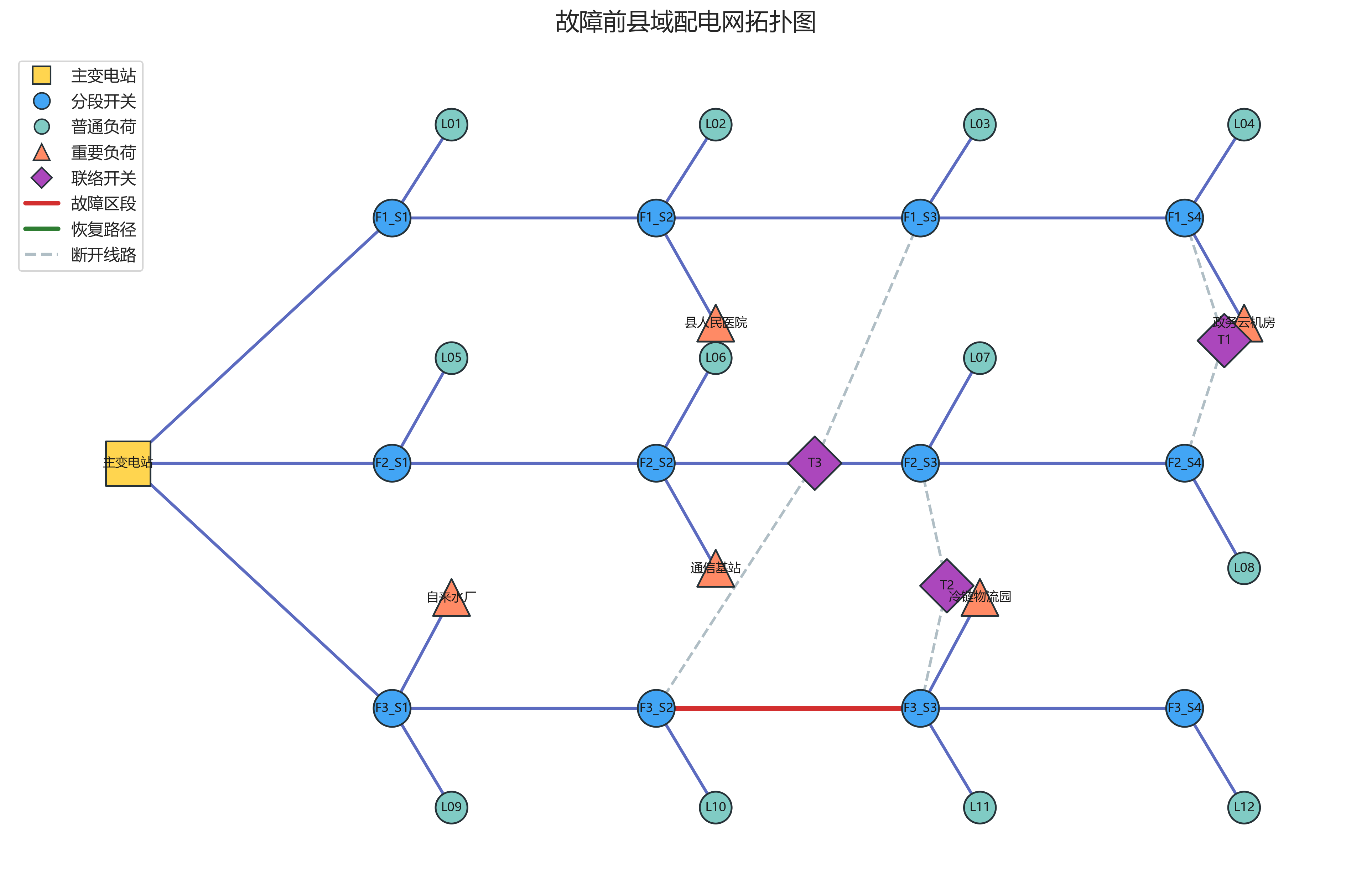
grid_topology_before_fault.png 展示了 3 条馈线、多个普通负荷、5 个重要负荷和 3 个联络开关。虽然标题写的是"故障前",但图中已经用红色标出了本次分析选中的故障区段 F3-Section-03,因此它更像"故障场景标注下的原始拓扑"。
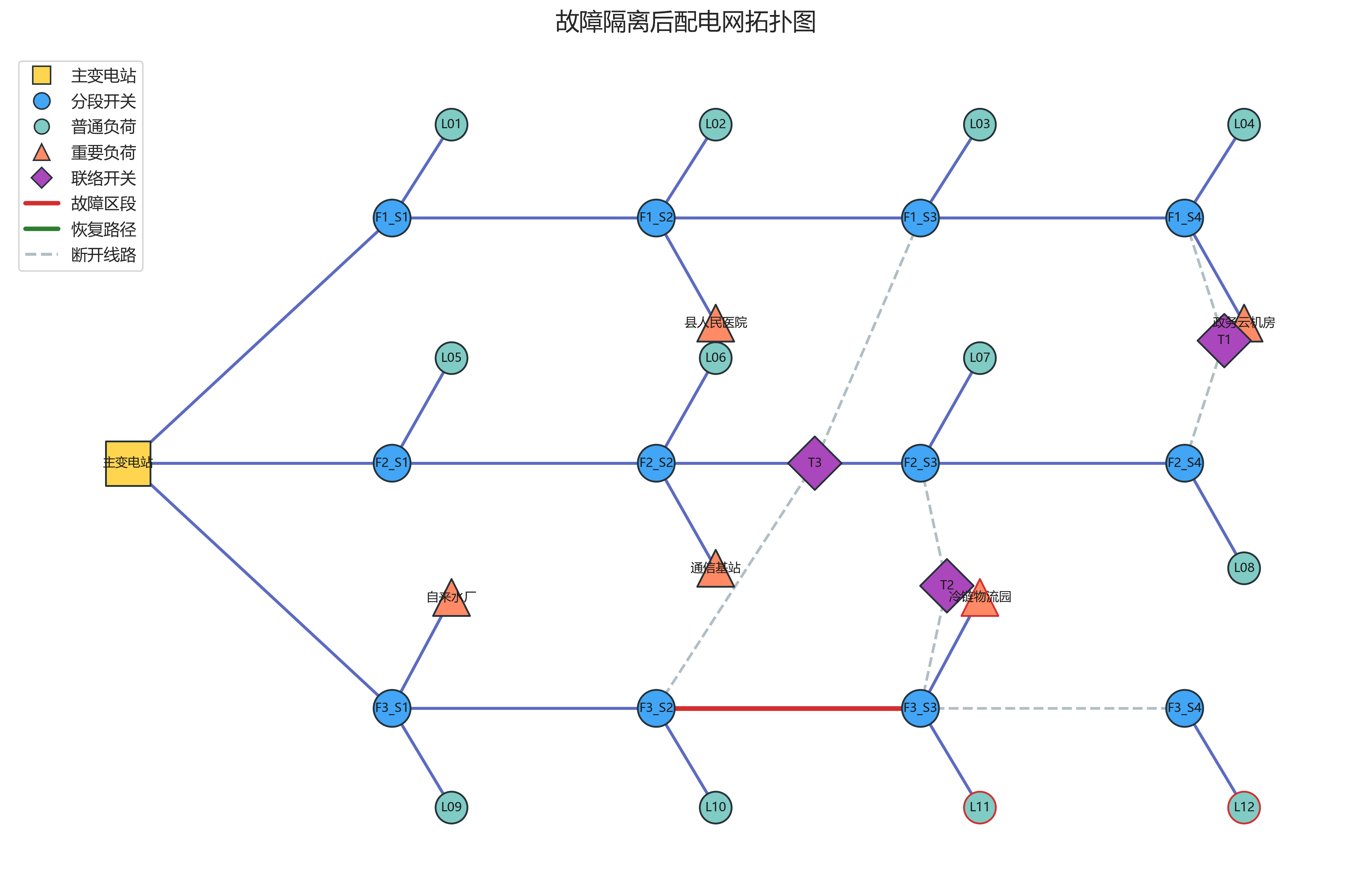
grid_topology_after_isolation.png 中,故障段仍为红色,断开的线路变为灰色虚线,受影响节点被红色边框突出。可以清楚看到,隔离之后 L11、I05 和 L12 处于失电区域。
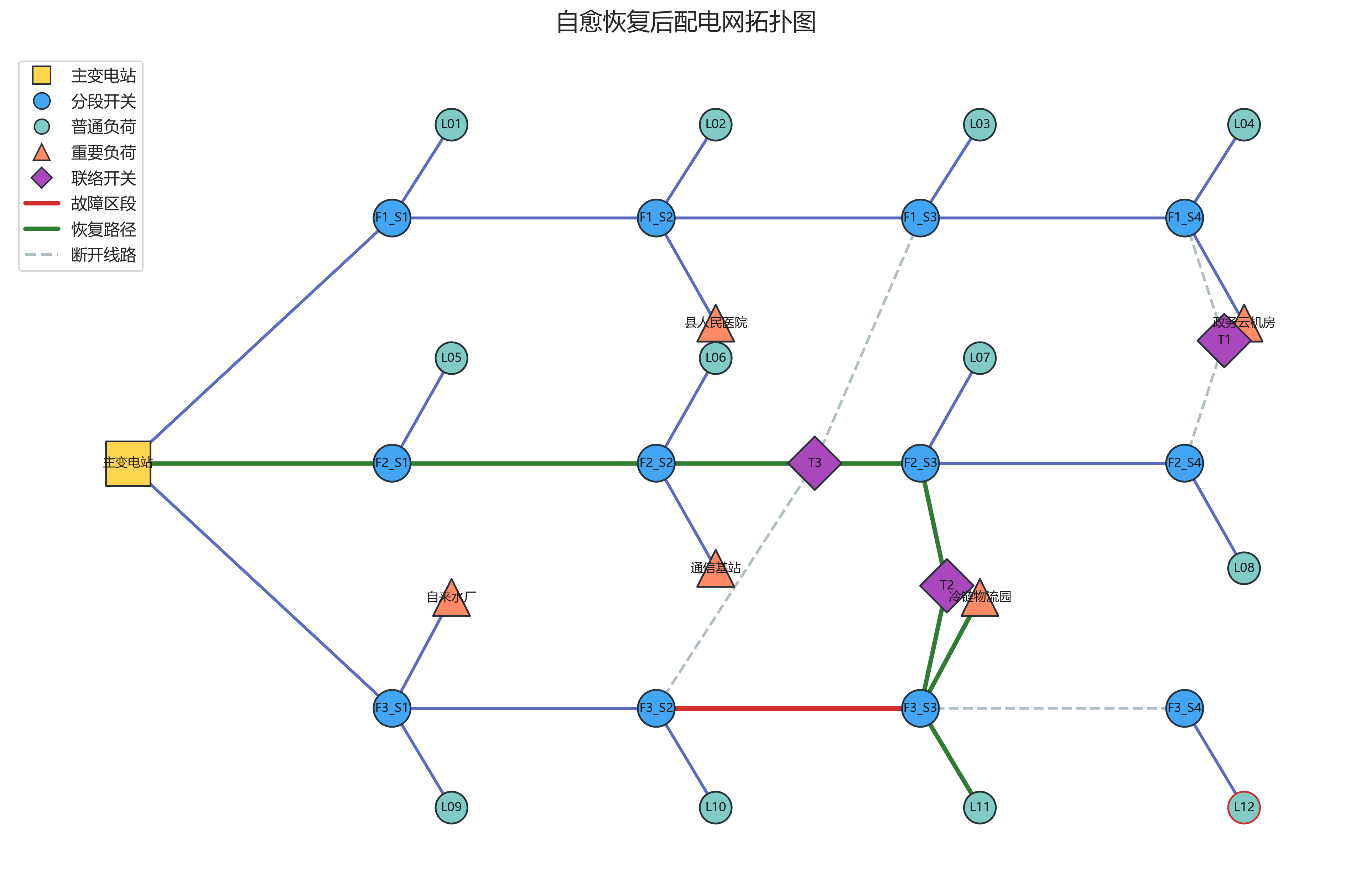
grid_topology_after_healing.png 是最有代表性的一张图。绿色路径显示了通过联络开关 T2 完成转供的路线,L11 和重要负荷 I05 被重新送电,而 L12 仍未恢复。这非常符合"优先恢复重要用户和可恢复负荷"的自愈目标。
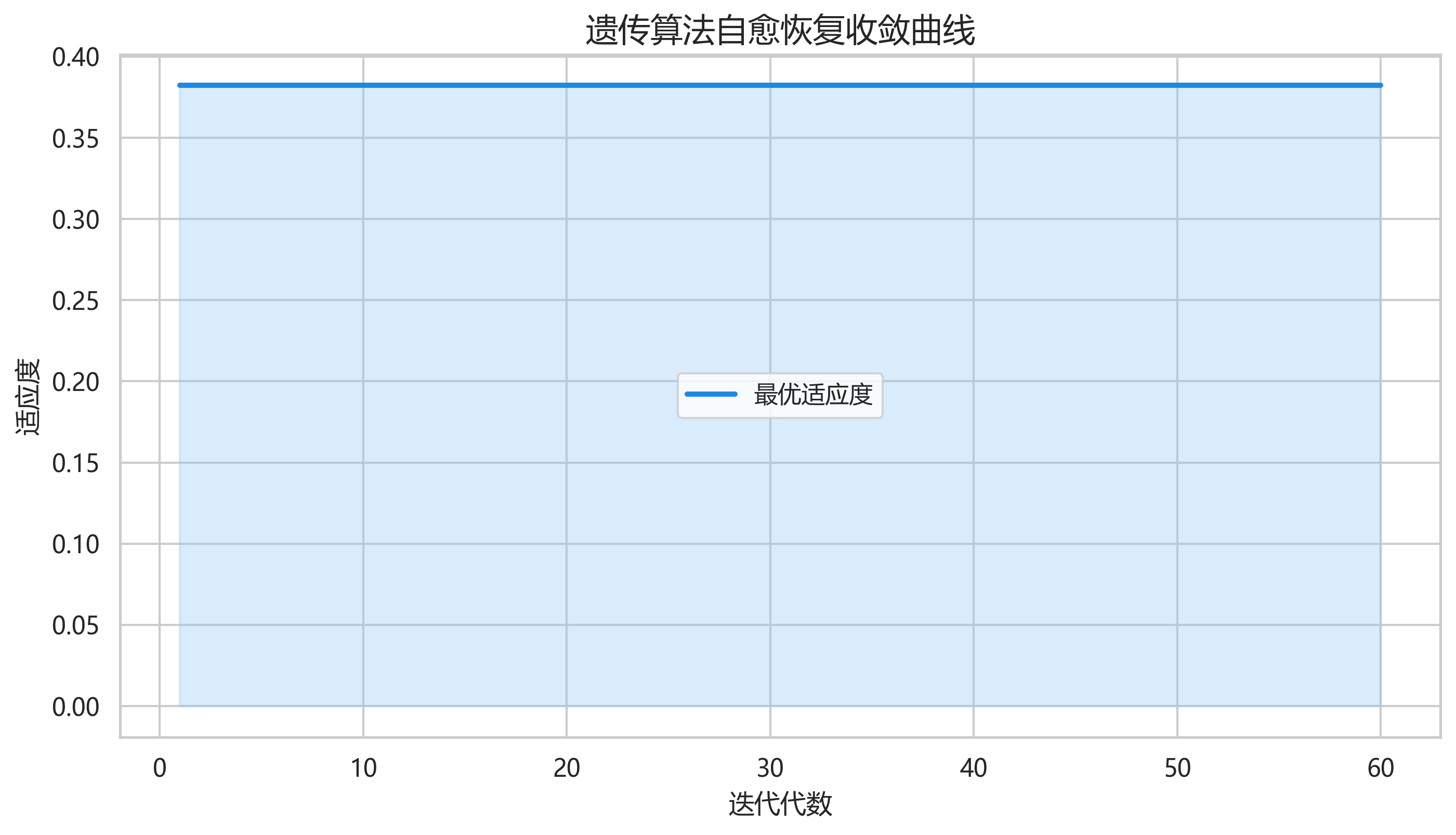
restoration_process.png 中曲线几乎不变,这反映的是"小规模离散搜索空间下,初始化即命中最优解"的情况,而不是算法没有工作。
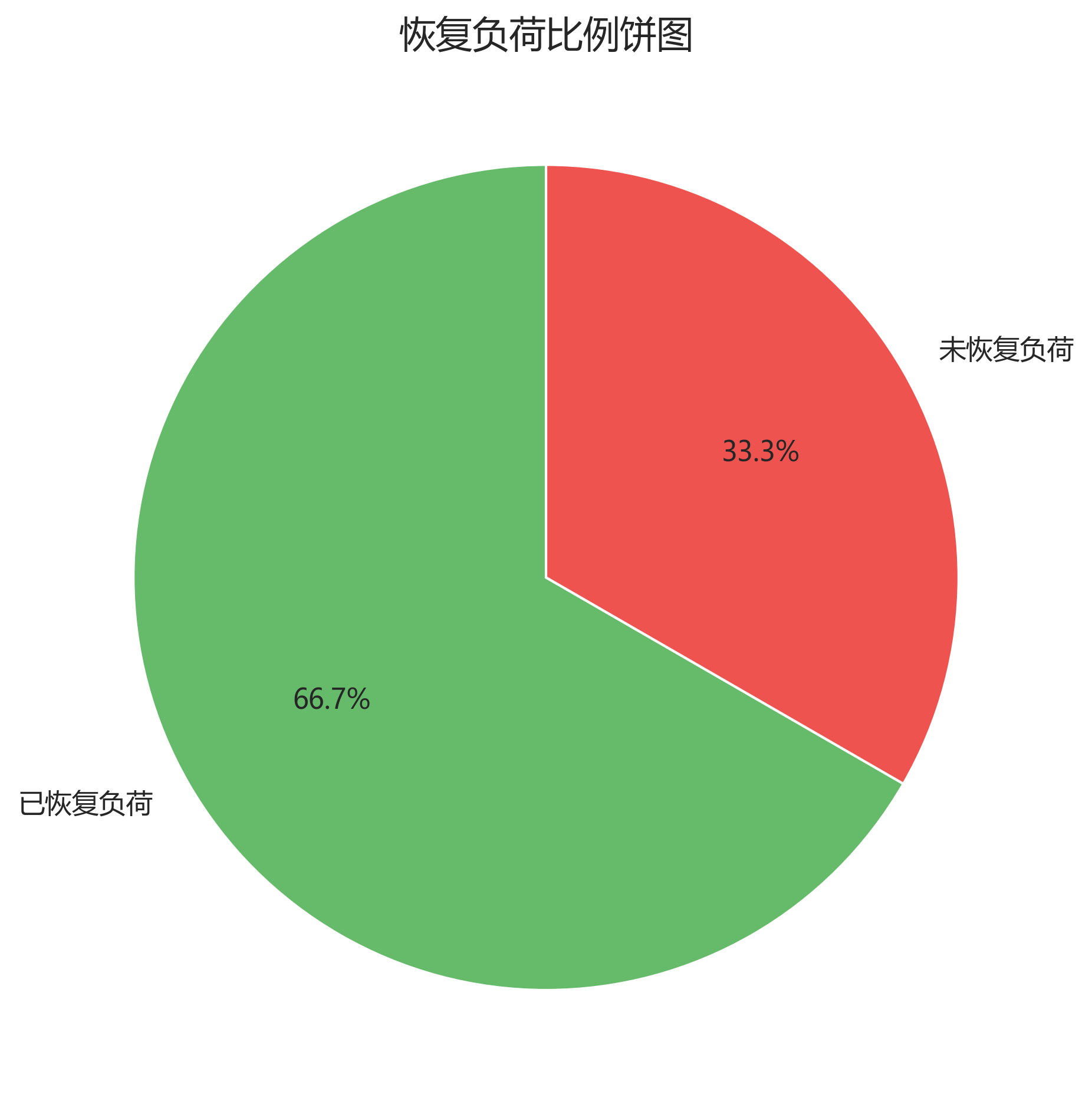
load_restore_ratio.png 则从节点数量角度说明:3 个失电节点里恢复了 2 个,因此饼图是 66.7% 对 33.3%。
需要代码的请在评论区下留言,作者会逐个回复,制作不易,请各位看官老爷点个赞
