python
# -*- coding: utf-8 -*-
"""
@Created on : 2026/4/24 11:44
@creator : er_nao
@File :Day_10.py
@Description :常见报错排查与基础调试
"""
# 导入需要的库
import jieba
import jieba.analyse
# 定义停用词列表
STOP_WORDS = ["的", "是", "在", "和", "有", "也", "就", "都", "而", "及", "与", "着", ",", "。", "!", "?", ";", ":", "、"," "]
# ---------------------- 封装可复用的NLP工具函数 ----------------------
# 函数1:文本分词+过滤停用词
def cut_text_and_filter(input_text):
# 先做基础清洗
clean_text = input_text.strip()
# 用jieba精确模式分词
words = jieba.lcut(clean_text)
# 过滤掉停用词和空字符串
valid_words = [word for word in words if word not in STOP_WORDS and word.strip() != ""]
# 返回有效词语列表
return valid_words
# 函数2:统计词频和占比
def count_word_frequency(valid_words):
# 统计每个词语的出现次数
word_count = {}
for word in valid_words:
if word in word_count:
word_count[word] = word_count[word] + 1
else:
word_count[word] = 1
# 计算总有效词数
total_words = len(valid_words)
# 计算每个词的占比
word_ratio = {}
if total_words > 0:
for word, count in word_count.items():
word_ratio[word] = round(count / total_words, 4)
# 返回词频统计和占比
return word_count, word_ratio, total_words
# 函数3:提取核心关键词
def extract_keywords(input_text, top_k=5):
# 提取TopK核心关键词
keywords = jieba.analyse.extract_tags(input_text, topK=top_k, withWeight=True)
return keywords
# ---------------------- 主程序逻辑 ----------------------
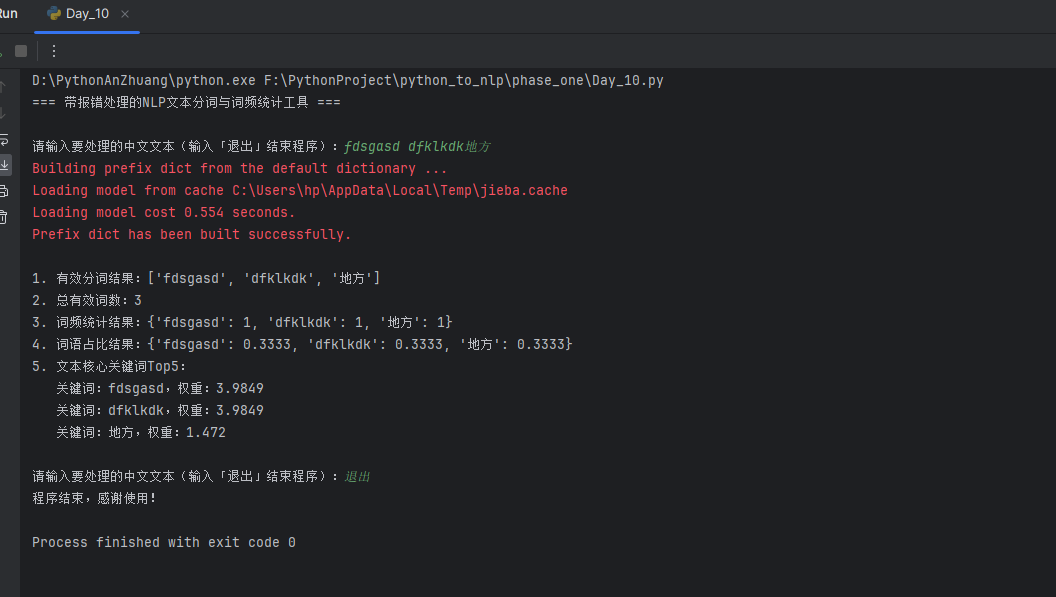
if __name__ == "__main__":
print("=== 带报错处理的NLP文本分词与词频统计工具 ===")
# 持续接收用户输入
is_running = True
while is_running:
# 接收用户输入
input_text = input("\n请输入要处理的中文文本(输入「退出」结束程序):")
# 判断是否退出
if input_text.strip() == "退出":
is_running = False
print("程序结束,感谢使用!")
continue
# 核心处理逻辑,加入报错处理
try:
# 1. 分词+过滤
valid_words = cut_text_and_filter(input_text)
print(f"\n1. 有效分词结果:{valid_words}")
# 2. 词频统计和占比
word_count, word_ratio, total_words = count_word_frequency(valid_words)
print(f"2. 总有效词数:{total_words}")
print(f"3. 词频统计结果:{word_count}")
print(f"4. 词语占比结果:{word_ratio}")
# 3. 核心关键词提取
keywords = extract_keywords(input_text, top_k=5)
print("5. 文本核心关键词Top5:")
for word, weight in keywords:
print(f" 关键词:{word},权重:{round(weight, 4)}")
# 捕获所有可能的报错,做对应的处理
except NameError as e:
print(f"【名称错误】:{e},请检查代码里的变量、函数名是不是拼写正确")
except TypeError as e:
print(f"【类型错误】:{e},请检查输入的文本是不是正确的字符串类型")
except IndexError as e:
print(f"【索引错误】:{e},请检查分词结果是不是空的")
except KeyError as e:
print(f"【键错误】:{e},请检查字典里的key是不是存在")
except AttributeError as e:
print(f"【属性错误】:{e},请检查jieba库是不是安装正确,版本是不是最新的")
except ImportError as e:
print(f"【导入错误】:{e},请检查jieba库是不是已经安装了")
except ZeroDivisionError as e:
print(f"【除零错误】:{e},总有效词数为0,无法计算占比")
except Exception as e:
print(f"【未知错误】:{e},请检查输入的文本是不是正确的")整理了 3 个你写代码的时候,最容易遇到的专属报错:
jieba 分词相关报错
常见报错 1:AttributeError: module 'jieba' has no attribute 'lcut'
原因: jieba 版本太老,老版本的 jieba 里没有lcut方法,只有cut方法
解决: 升级 jieba 到最新版本,用pip install --upgrade jieba命令,或者用jieba.cut()方法,再转成列表list(jieba.cut(text))
常见报错 2:TypeError: cut() got an unexpected keyword argument 'cut_all'
原因: jieba 的cut()方法里,没有cut_all这个参数,你写错了参数名
解决: 正确的参数是cut_all,检查拼写是不是正确,或者用lcut()方法,参数是cut_all=True
文本处理相关报错
常见报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb0 in position 0: invalid start byte
原因: 你读取的文本文件,不是 UTF-8 编码,是 GBK 编码,Python 用 UTF-8 解码的时候出错了
解决: 读取文件的时候,指定编码格式为 GBK,比如open("text.txt", "r", encoding="gbk"),或者先把文件转换成 UTF-8 编码
字典、列表相关报错
常见报错:TypeError: unhashable type: 'list'
原因: 你用了一个列表当字典的 key,字典的 key 必须是不可变类型(字符串、数字、元组),列表是可变类型,不能当 key
解决: 把列表转换成元组,再当 key,比如key = tuple("NLP", "AI"),或者用字符串当 key