Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第三章 Loops and Iterators(循环和迭代器)
程序通常需要处理固定或动态长度的顺序数据。作为一种主要的命令式编程语言,Python 可以轻松地使用循环实现顺序处理。一般模式是:每次通过循环时,读取存储在变量、列表、字典等中的数据,并执行相应的状态修改或 I/O 操作。 Python 中的循环令人感觉自然,并且能够完成涉及内置数据类型、容器类型和用户定义类的最常见任务。
Python 还支持迭代器,它可以采用更函数式的方法来处理任意数据流。您可以使用迭代器,而不是直接与顺序数据的存储方式进行交互,迭代器提供了隐藏细节的通用抽象。迭代器可以使程序更高效、更容易重构,并且能够处理任意大小的数据。Python 还包含将迭代器组合在一起并使用生成器完全自定义其行为的功能(更多内容请参阅第六章 "推导式和生成器")。
Item 17:更喜欢枚举而不是范围
内置的 range 函数对于循环遍历整数序列非常有用。例如,这里通过为每个 bit 位置掷硬币的方式来生成一个 32 位的随机数:
from random import randint
random_bits = 0
for i in range(32):
if randint(0, 1):
random_bits |=1 << i
print(bin(random_bits))
>>>
0b11101000100100000111000010000001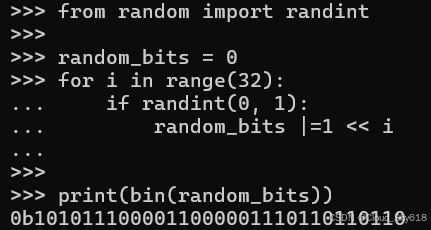
当你拥有一个可进行遍历的数据结构,比如一串字符串列表时,你便可以直接对序列进行循环操作:
flavor_list = ["vanilla", "chocolate", "pecan", "strawberry"]
for flavor in flavor_list:
print(f"{flavor} is delicious")
>>>
vanilla is delicious
chocolate is delicious
pecan is delicious
strawberry is delicious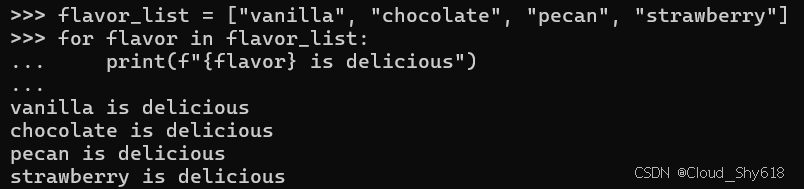
通常情况下,你不仅需要遍历一个列表,还希望能够知晓当前项在列表中的索引位置。例如,假设我想要打印我最喜爱的冰淇淋口味的排名。实现这一目标的一种方法是利用 range() 函数为列表中的每个位置生成一个偏移量:
for i in range(len(flavor_list)):
flavor = flavor_list[i]
print(f"{i + 1}: {flavor}")
>>>
1: vanilla
2: chocolate
3: pecan
4: strawberry与在 flavor_list 范围内的 for 语句的其他示例相比,这看起来很笨拙。我必须得到列表的长度。我必须索引到数组中。多个步骤使得阅读变得更加困难。
Python 提供了 enumerate 内置函数来简化这种情况。 enumerate 用惰性生成器包装任何迭代器(请参阅 Item 43:"考虑生成器而不是返回列表")。该函数会枚举出循环索引与给定迭代器中下一个值的配对。在此处,通过使用内置的 next() 函数来手动推进返回的迭代器,以演示其功能:
it = enumerate(flavor_list)
print(next(it))
print(next(it))
>>>
(0, 'vanilla')
(1, 'chocolate')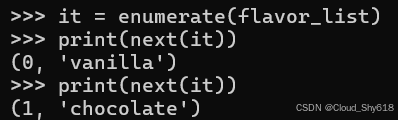
通过枚举方式生成的每一对结果均可通过一个 for 语句简洁地进行解析(请参阅 Item 5:"优先采用多重赋值解析方式而非索引" 以了解具体操作方法)。由此生成的代码更加清晰明了:
for i, flavor in enumerate(flavor_list):
print(f"{i + 1}: {flavor}")
>>>
1: vanilla
2: chocolate
3: pecan
4: strawberry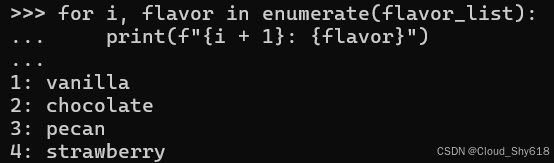
可以通过指定用于开始计数的编号(在此例中为 1)作为第二个参数,来使这段内容变得更加简洁:
for i, flavor in enumerate(flavor_list, 1):
print(f"{i}: {flavor}")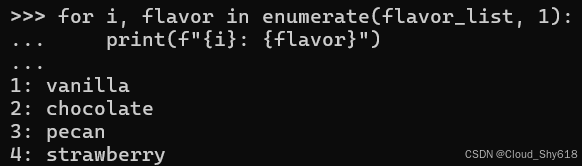
注意:
- enumerate() 提供了简洁的语法,用于遍历一个迭代器,并在遍历过程中获取每个项的索引。
- 建议使用枚举方式,而非通过循环遍历某个范围以及索引序列。
- 您可以为枚举功能提供一个可选的第二参数,该参数用于指定计数的起始编号(默认为零)。
Item 18:使用 zip 进程迭代器进行并行处理
在 Python 中,你常常会遇到大量包含相关对象的列表。使用列表推导式可以轻松地从源列表中生成另一个衍生列表,具体方法是针对每个元素应用一个表达式(参见 Item 40:"使用推导式而非 map 和 filter")。例如,这里我取了一个姓名列表,并创建了一个与之对应的列表,其中记录了每个姓名所包含的字符数量:
names = ["Cecilia", "Lise", "Marie"]
counts = [len(n) for n in names]
print(counts)
>>>
[7, 4, 5]
衍生列表(计数)中的项与源列表(名称)中的项之间是通过它们在序列中的对应位置相关联的。为了在一次循环中访问两个列表中的项,我可以通过遍历源列表(名称)的长度,并使用 range 函数生成的偏移量来对两个列表进行索引。例如,此处我采用并行索引的方式来确定哪个名称最长:
longest_name = None
max_count =0
for i in range(len(names)):
count = counts[i]
if count > max_count:
longest_name = names[i]
max_count = count
print(longest_name)
>>>
Cecilia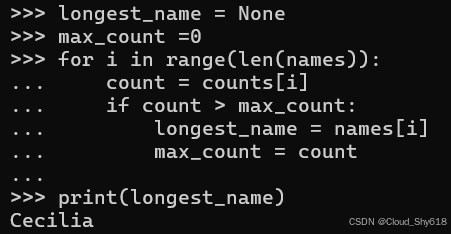
问题在于整个代码表述在视觉上显得杂乱无章。索引操作------namesi 和 countsi ------使得代码难以阅读。通过同一个循环索引对两个数组进行索引操作似乎有些多余。可以通过使用内置的 enumerate() 函数(参见 Item 17:"更喜欢使用枚举而非范围")来对此稍作改进,但这仍不够理想,因为其中包含了 countsi 的索引操作:
longest_name = None
max_count = 0
for i, name in enumerate(names): # Changed
count = counts[i]
if count > max_count:
longest_name = name # Changed
max_count = count为使这段代码更加清晰易懂,Python 提供了内置函数 zip。zip 将两个或多个迭代器包裹在一个惰性生成器中。zip 生成器会依次返回包含来自每个迭代器中下一个值的元组。这些元组可以直接在 for 语句中进行解包(有关背景信息,请参阅 Item 5:"优先采用多重赋值解包而非索引")。通过消除索引操作,生成的代码比上述单独访问两个列表的代码要简洁得多:
longest_name = None
max_count =0
for name, count in zip(names, counts): # Changed
if count > max_count:
longest_name = name
max_count = countzip 会依次遍历它所包裹的迭代器中的每一项,这意味着它可用于处理无限长的输入数据,而不会导致程序因占用过多内存而崩溃(关于如何创建此类输入数据,请参阅 Item 43:"考虑使用生成器而非返回列表"和 Item 44:"考虑使用生成器表达式处理大型列表推导式")。
然而,必须留意 zip 在输入迭代器长度不同时的表现。例如,假设我在 nameslist 中添加了另一个元素,但却忘记更新 countslist。对这两个输入列表执行 zip 操作会产生意想不到的结果:
names.append("Rosalind")
for name, count in zip(names, counts):
print(name)
>>>
Cecilia
Lise
Marie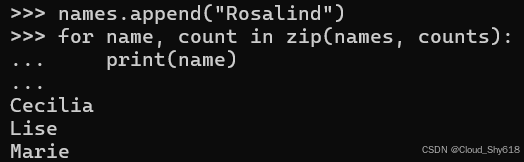
针对 "Rosalind" 的新项并未包含在输出结果中。这是为什么呢?这正是 zip 的运作方式。它会持续生成元组,直至所有被包裹的迭代器均被用尽为止。其输出长度仅为其最短输入的长度。如果过早截断可能给您的程序带来问题,您可以向 zip 传递 strict 关键字参数------这是自 Python 3.10 引入的一项新选项------这将导致返回的生成器在任意一个输入被用尽之前便抛出异常:
for name, count in zip(names, counts, strict=True): # Changed
print(name)
>>>
Cecilia
Lise
Marie
Traceback ...
ValueError: zip() argument 2 is shorter than argument 1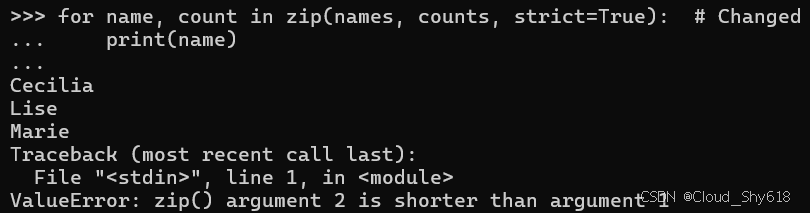
此外,你还可以通过使用内置模块 itertools 中的 zip_longest 函数来解决这种截断问题,该函数可将缺失项用默认值进行填充(请参阅 Item 24:"考虑使用 itertools 来处理迭代器和生成器")。
注意:
- zip 内置函数可用于并行迭代多个迭代器。
- zip 创建一个生成元组的惰性生成器;它可以用于无限长的输入。
- 如果您为其提供不同长度的迭代器,zip 会默默地将其输出截断为最短的迭代器。
- 如果您希望确保不可能进行静默截断,并且不匹配的迭代器长度会导致运行时错误,请将 strict 关键词参数传递给 zip。
Item 19:避免在 for 和 while 循环之后出现 else 块
Python 循环有一个大多数其他编程语言所不具备的额外功能:您可以在循环的重复内部块之后立即放置 else 块:
for i in range(3):
print("Loop", i)
else:
print("Else block!")
>>>
Loop 0
Loop 1
Loop 2
Else block!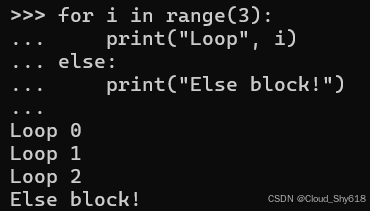
令人惊讶的是,else 块在循环结束后立即运行。 为什么该子句被称为 else ?在 if/else 语句中,else 的意思是 "如果在此之前的块没有发生,则执行此操作"(请参阅 " Item 7:考虑简单内联逻辑的条件表达式"。在 try/except 语句中, except 具有相同的定义:"如果尝试在此之前的块失败,则执行此操作。"
类似地,else from try/ except/else 遵循这种模式(参见 Item 80:"利用 try/except/else/finally 中的每个块"),因为它意味着 "如果没有异常需要处理,则执行此操作"。 try/finally 也很直观,因为它意味着 "总是在尝试之前的块之后执行此操作。"
鉴于 Python 中 else、 except 和 finally 的所有用法,新手程序员可能会认为 for/else 的 else 部分意味着"如果循环未完成,则执行此操作"。事实上,它的作用恰恰相反。在循环中使用 break 语句实际上会跳过 else 块:
for i in range(3):
print("Loop", i)
if i == 1:
break
else:
print("Else block!")
>>>
Loop 0
Loop 1另一个令人意外的是,如果循环空序列,则 else 块会立即运行:
for x in []:
print("Never runs")
else:
print("For else block!")
>>>
For else block!当 while 循环最初为 False 时,else 块也会运行:
while False:
print("Never runs")
else:
print("While else block!")
>>>
While else block!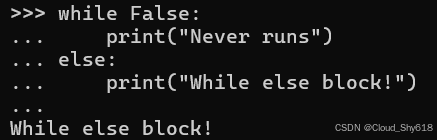
这些行为的基本原理是,当您搜索某些内容时,循环后的 else 块非常有用。例如,假设我想确定两个数字是否互质(即它们的唯一公约数是 1)。在这里,我迭代每个可能的公约数并测试数字。尝试完每个选项后,循环结束。 else 块在数字互质时运行,因为循环不会遇到中断:
a = 4
b = 9
for i in range(2, min(a, b) + 1):
print("Testing", i)
if a % i == 0 and b % i == 0:
print("Not coprime")
break
else:
print("Coprime")
>>>
Testing 2
Testing 3
Testing 4
Coprime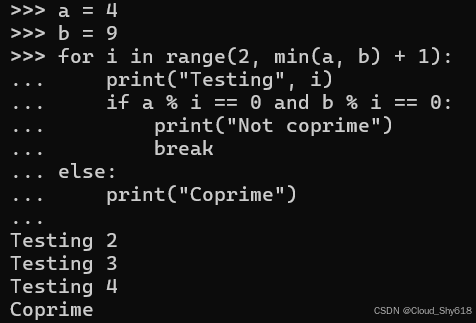
实际上,并不会这样编写代码。相反,会编写一个辅助函数来进行计算。可以使用两种常见样式中的任何一种来编写此类函数。
第一种方法是当符合正在寻找的条件时尽早返回。如果陷入循环,只会返回默认结果:
def coprime(a, b):
for i in range(2, min(a, b) + 1):
if a % i == 0 and b % i == 0:
return False
return True
assert coprime(4, 9)
assert not coprime(3, 6)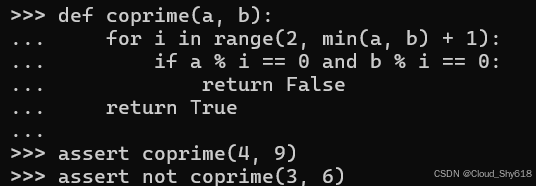
第二种方法是使用一个结果变量来指示是否在循环中找到了要查找的内容。在这里,只要找到东西就跳出循环,然后返回该指示变量:
def coprime_alternate(a, b):
is_coprime = True
for i in range(2, min(a, b) + 1):
if a % i == 0 and b % i == 0:
is_coprime = False
break
return is_coprime
assert coprime_alternate(4, 9)
assert not coprime_alternate(3, 6)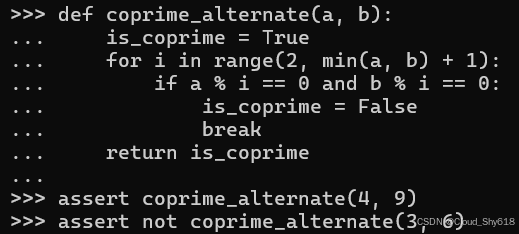
对于不熟悉代码的读者来说,这两种方法都更加清晰。根据具体情况,两者都可能是不错的选择。然而,您从 else 块中获得的表达能力并不会超过您给将来想要理解您的代码的人(包括您自己)带来的负担。像循环这样的简单结构在 Python 中应该是不言而喻的。您应该完全避免在循环之后使用 else 块。
注意:
- Python 有特殊的语法,允许 else 块立即跟在 for 和 while 循环内部块之后。
- 仅当循环体未遇到 break 语句时,循环后的 else 块才会运行。
- 避免在循环后使用 else 块,因为它们的行为不直观并且可能令人困惑。
Item 20:循环结束后切勿使用 for 循环变量
当您在 Python 中编写 for 循环时,您可能会注意到为迭代创建的变量在循环完成后继续保留:
for i in range(3):
print(f"Inside {i=}")
print(f"After {i=}")
>>>
Inside i=0
Inside i=1
Inside i=2
After i=2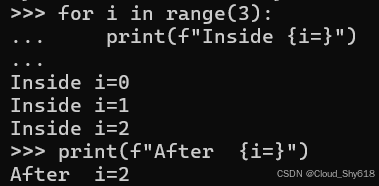
可以利用这种循环变量赋值行为来发挥自己的优势。例如,在这里我实现了一种算法,通过在列表中搜索周期性元素的索引来将它们分组在一起:
categories = ["Hydrogen", "Uranium", "Iron", "Other"]
for i, name in enumerate(categories):
if name == "Iron":
break
print(i)
>>>
2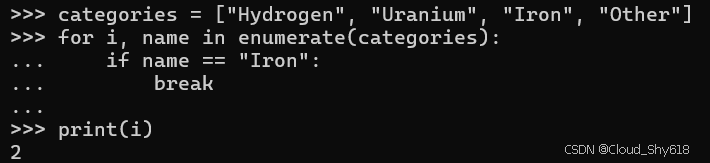
如果在列表中找不到 给定元素,则在迭代结束后将使用最后一个索引,将该项目分组到 "其他" ctach-all 的类别中(在本例中为索引 3):
for i, name in enumerate(categories):
if name == "Lithium":
break
print(i)
>>>
3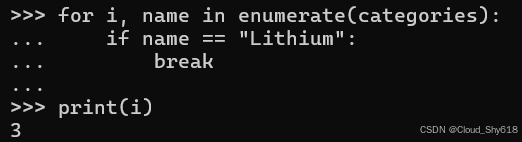
该算法的假设是,要么循环将找到匹配项并由于 break 语句而提前结束,要么循环将迭代所有选项并失败。不幸的是,还有第三种可能性,即循环永远不会开始,因为迭代器最初为空,这可能会导致运行时异常:
categories = []
for i, name in enumerate(categories):
if name == "Lithium":
break
print(i)
>>>
Traceback ...
NameError: name 'i' is not defined有一些替代方法可以处理从不处理任何内容的循环(请参阅 Item 19:"避免在 for 和 while 循环之后出现 else 块")。但要点是相同的:当您尝试在循环后访问循环变量时,您不能总是确定循环变量是否存在,因此最好在实际中永远不要这样做。
幸运的是(或许不幸的是)其他 Python 功能不存在这个问题。列表推导式或生成器表达式不会表现出循环变量泄漏行为(请参阅 Item 40:"使用推导式代替映射和过滤器"和 Item 44:"考虑大型列表推导式的生成器表达式")。 如果您在执行后尝试访问推导式的内部变量,您会发现它们永远不存在,因此您不会无意中遇到此陷阱:
my_numbers = [37, 13, 128, 21]
found =[i for i in my_numbers if i % 2 == 0]
print(i) # Always raises
>>>
Traceback ...
NameError: name 'i' is not defined但是,推导式中的赋值表达式可能会改变这种行为(请参阅 Item 42:"使用赋值表达式减少推导式中的重复")。 异常变量也不存在这种泄漏问题,尽管它们以自己的方式很奇怪(参见 Item 84:"谨防异常变量消失")。
注意:
- 即使循环终止后,也可以在当前作用域中访问 for 循环中的循环变量。
- 如果循环从未进行过一次迭代,则不会在当前范围内分配 for 循环变量。
- 默认情况下,生成器表达式和列表推导式不会泄漏循环变量。
- 异常处理程序不会泄漏异常实例变量。