Java 后端分层架构详解
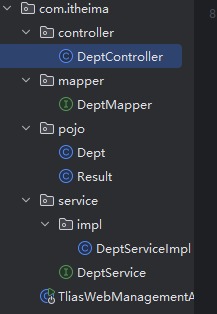
我完全懂你的疑惑!刚接触 Java 后端的人,都会觉得:"不就是写个接口吗?为啥要建这么多文件?"
其实这不是"多此一举",而是 Java 后端最标准的「分层架构」,每个文件/包都有明确的分工,就像外卖平台的不同岗位,各司其职,代码才不会乱成一团。
我结合你项目里的结构,用通俗比喻+逐文件拆解,给你讲得明明白白!
一、先看整体:你的项目是怎么分工的?
你的接口流程,就像一个「部门列表接口」的完整外卖流程,数据是这样走的:
前端请求 → Controller(接单) → Service(处理业务) → Mapper(取餐) → 数据库
而 POJO 就是传递数据的「餐盒」。
二、逐个拆解:每个文件到底干啥?
- controller 包:DeptController(接单员/前台)
-
图标:蓝色 C,表示是一个类
-
作用:接口的入口,只和前端打交道,不处理任何业务逻辑
-
具体干的事:
-
接收前端的请求(比如 GET /dept/list)
-
调用 Service 层的方法
-
把 Service 返回的结果,包装成统一格式返回给前端
-
-
举个例子:
@RestController
@RequestMapping("/dept")
public class DeptController {
@Autowired
private DeptService deptService;
@GetMapping("/list")
public Result list() {
// 只负责调用service,不写任何业务逻辑
List<Dept> list = deptService.list();
return Result.success(list);
}}
- 为什么单独建?
如果把业务逻辑写在 Controller 里,以后接口多了,代码会乱成一锅粥,而且 Controller 只需要负责"接请求、返回结果",不需要知道"怎么查数据库、怎么处理数据"。
- service 包:DeptService + DeptServiceImpl(后厨/业务处理)
这是两个文件,是 Java 里典型的接口+实现类模式,你可以把它们当成"后厨的菜单+厨师":
① DeptService(绿色 I,接口)
-
作用:定义「业务规则」,也就是"后厨要做什么菜"
-
只写方法名,不写具体逻辑,比如:
public interface DeptService {
List list(); // 查询部门列表
void add(Dept dept); // 新增部门
void delete(Integer id); // 删除部门
}
② DeptServiceImpl(蓝色 C,实现类)
-
作用:真正干活的「厨师」,实现接口里定义的所有方法,写核心业务逻辑
-
具体干的事:
-
处理业务逻辑(比如新增部门时,校验部门名称是否重复;查询列表时过滤禁用状态)
-
调用 Mapper 层的方法,获取/修改数据库数据
-
-
举个例子:
@Service
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
@Override
public List<Dept> list() {
// 业务逻辑:只查询启用的部门
return deptMapper.list().stream()
.filter(dept -> dept.getStatus() == 1)
.toList();
}}
- 为什么要分成两个文件?
这是 Java 的「面向接口编程」,好处是:
-
以后要修改业务逻辑,只需要改 DeptServiceImpl,不用动 DeptService 和 Controller
-
Spring 框架会自动帮你把实现类注入进去,代码更灵活
- mapper 包:DeptMapper(取餐员/数据库操作)
-
图标:绿色 I,接口
-
作用:只负责和数据库打交道,写SQL、做增删改查,不处理任何业务逻辑
-
具体干的事:
-
写 SQL 语句(比如 SELECT * FROM dept)
-
从数据库查出数据,返回给 Service 层;或者把 Service 传来的数据,写入数据库
-
-
举个例子(用MyBatis的话):
@Mapper
public interface DeptMapper {
// 查询所有部门
@Select("SELECT * FROM dept")
List list();
// 新增部门
@Insert("INSERT INTO dept(name, status) VALUES(#{name}, #{status})")
void add(Dept dept);}
- 为什么单独建?
把"数据库操作"和"业务逻辑"彻底分开:
-
以后换数据库(比如从MySQL换成Oracle),只需要改 Mapper 层的SQL,不用动 Service 和 Controller
-
找bug的时候,数据不对就看Mapper,逻辑不对就看Service,问题定位超清晰
- pojo 包:Dept + Result(餐盒/数据模型)
这两个都是数据模板,用来装数据,在各个层之间传递:
① Dept(蓝色 C,实体类)
-
作用:对应数据库的 dept 表,是部门数据的模板
-
里面的字段和数据库表的列一一对应,比如:
public class Dept {
private Integer id; // 部门ID
private String name; // 部门名称
private Integer status; // 状态:1启用 0禁用
private LocalDateTime createTime; // 创建时间
// ...getter、setter、构造方法
}
- 从数据库查出来的数据,会自动封装成 Dept 对象,在 Service、Controller 之间传递。
② Result(蓝色 C,统一返回类)
-
作用:统一接口返回格式,就是你之前写的 {code, msg, data}
-
所有接口都返回这个格式,前端不用处理五花八门的返回结果,直接按 code 判断成功/失败:
public class Result {
private Integer code; // 响应码:200成功 500失败
private String msg; // 提示信息
private Object data; // 返回数据
// ...success、fail静态方法
}
- 启动类 TliasWebManagementA(餐厅大门)
- 这个是 Spring Boot 项目的入口,不用管太多,只要知道:运行这个类,整个项目就启动了,接口就能被访问了。
三、写一个接口,数据到底怎么走?
用你的「部门列表接口」举个完整流程,你就懂了:
-
前端请求 GET /dept/list → 到 DeptController
-
DeptController 调用 deptService.list() → 把请求交给 Service 层
-
DeptServiceImpl 处理业务逻辑(比如过滤禁用部门),再调用 deptMapper.list() → 交给 Mapper 层
-
DeptMapper 执行SQL,从数据库查出部门数据 → 返回给 Service
-
Service 把处理好的数据返回给 Controller
-
Controller 把数据包装成 Result 格式,返回给前端
四、为什么一定要这么分?(小白也能懂的好处)
-
职责清晰,好维护:每个文件只干一件事,找bug的时候,数据错了看Mapper,逻辑错了看Service,接口报错看Controller,一眼就能定位问题。
-
代码可复用:比如 DeptService 里的 list() 方法,可以被多个 Controller 调用,不用写两遍。
-
方便修改:以后要改业务逻辑,只改 DeptServiceImpl;要改SQL,只改 DeptMapper,不用动其他层,不会"牵一发而动全身"。
-
和前端联调更稳定:统一用 Result 返回,前端不用处理各种奇葩格式,联调效率高。
五、和你之前写的代码对比一下
你之前写的读取 user.txt 的代码,是把"读文件、解析数据、返回结果"全写在 Controller 里,这是没有分层的写法,只能写简单接口,项目大了就会乱。
现在你学的分层写法,是企业级项目的标准规范,学会这个,你写的接口就和大厂的后端代码结构一模一样了!
要不要我帮你写一个「部门列表接口」的完整代码,把每个文件的内容都补全,你直接复制就能跑?