目录
[1. ELF是什么](#1. ELF是什么)
[2. ELF文件类型](#2. ELF文件类型)
[1. ELF组成](#1. ELF组成)
[2. 核心 Section](#2. 核心 Section)
[1. 多个 .o 合并](#1. 多个 .o 合并)
[2. 合并原则](#2. 合并原则)
[1. printf 地址问题](#1. printf 地址问题)
[2. 符号解析与重定位](#2. 符号解析与重定位)
[3. 静态链接总结](#3. 静态链接总结)
一、ELF文件概述
1. ELF是什么
ELF 的全称是 Executable and Linkable Format(可执行与可链接格式)
它是 Linux 以及大多数类 Unix 系统中二进制文件的标准格式。我们可以把它想象成一个极其精密的多层集装箱:
-
它不仅装载着机器指令(代码)和原始数据
-
它还携带了大量的元数据(Metadata),告诉链接器如何合并不同的代码段,或者告诉操作系统如何将这些指令映射到内存中运行

为什么统一格式很重要? 因为有了统一的 ELF 标准,编译器、链接器和操作系统加载器就能使用同一套协议进行协作。如果没有 ELF,每种编程语言或每个编译器生成的二进制文件可能都无法互认,更谈不上构建复杂的软件生态了
2. ELF文件类型
虽然都叫 ELF 文件,但根据所处的开发阶段和用途,内核将其划分为四种主要类型:
| 类型 | 常见后缀 | 核心用途 |
|---|---|---|
| 可重定位文件 | 。这 | 由编译器产生,包含了代码和数据,用于与其他 .o 合并生成最终文件 |
| 可执行文件 | 无 / .out | 经过链接器处理后的完整程序,可以直接由操作系统加载执行 |
| 共享目标文件 | 。所以 | 动态链接库,既可以在链接阶段被链接器使用,也可以在运行时由动态链接器加载到内存中 |
| 核心转储文件 | 核 | 当进程崩溃时,由操作系统生成的进程内存快照,主要用于事后调试 |
所有的 ELF 文件在 Linux 内核看来都是 二进制对象 。内核通过读取文件开头的 Magic Number来识别文件身份
二、ELF结构
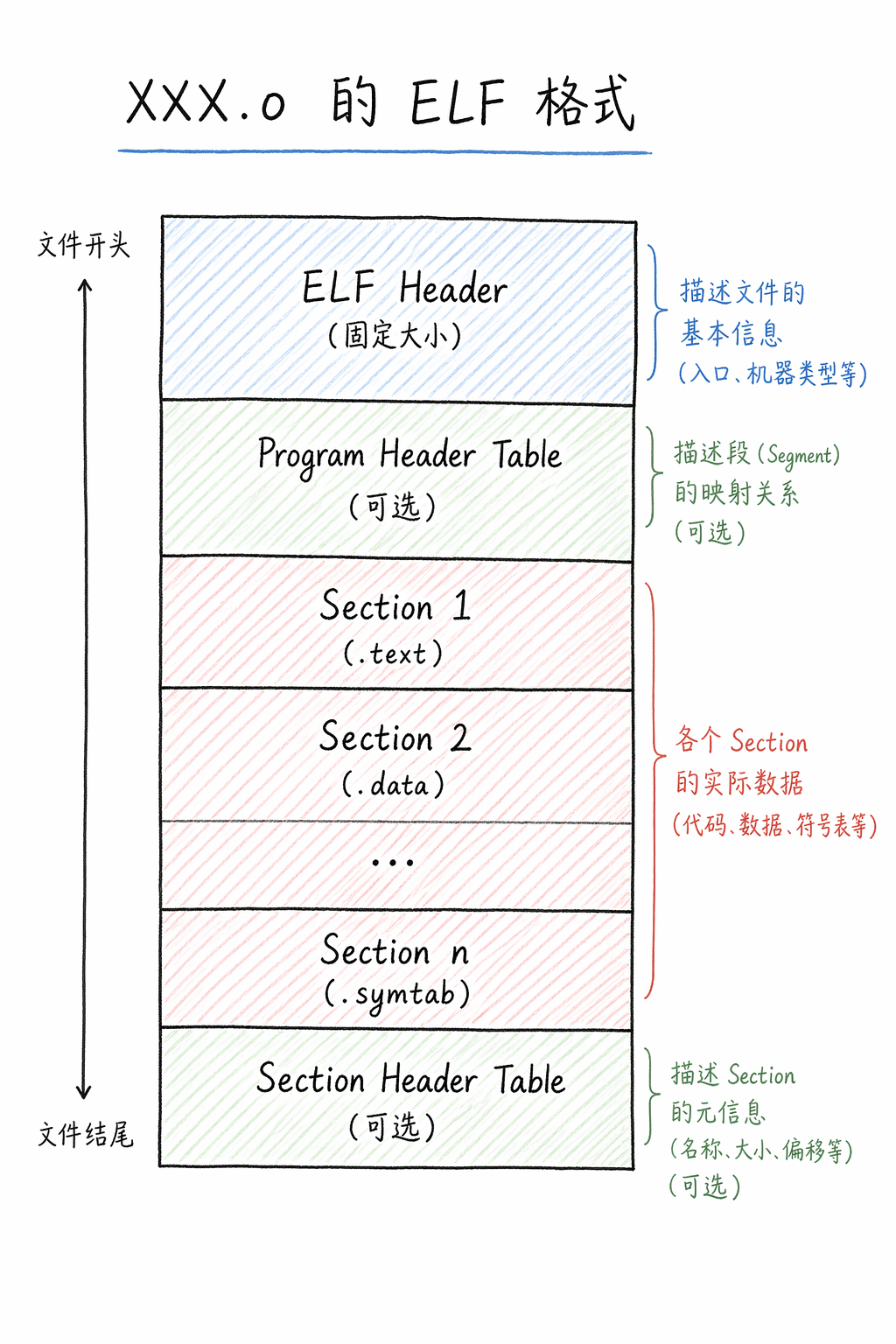
深入剖析 ELF 文件的内部结构可以发现,其整体并非单一固化模块,而是由多个**节(Section)**共同组成
理解节的核心,在于明确其服务对象:节主要面向链接器(Linker)。它构成了 ELF 文件的链接视图,链接器通过这些 Section 将不同的目标文件揉合在一起
1. ELF组成
要把一个 ELF 文件看透,需要掌握这四个关键结构:
-
ELF 头部 :
- 包含 Magic Number、目标架构、它是
.o还是可执行文件、以及程序入口地址 。它还记录了程序 / 节头表在文件中的具体位置
- 包含 Magic Number、目标架构、它是
-
Program Header Table(程序头表):
- 它告诉操作系统如何将文件映射到内存中。例如:哪些部分应该作为只读代码,哪些部分作为可读写数据。在 .o 文件中,这个表通常是不存在的
-
Section Header Table(节头表):
- 记录文件中所有 Section 的名字、大小和偏移量。它是在开发、调试和链接阶段最重要的参考依据
-
Sections(节):
- 文件的各种数据和指令。这些 Section 会被 Section Header Table 索引
2. 核心 Section
在 .o 目标文件中,源代码被拆分并分类存放在不同的 Section 中
| 节名称 | 含义 | 作用与存放内容 |
|---|---|---|
| 。文本 | 代码节 | 存放编译后的机器指令 |
| 。数据 | 已初始化数据节 | 存放已初始化且不为 0 的全局变量和局部静态变量 |
| .bss | 未初始化数据节 | 存放未初始化 或初始化为 0 的全局/静态变量。它在磁盘上不占空间,只记录所需大小 |
| .rodata | 只读数据节 | 存放只读数据,如常量、字符串字面量 |
| 符号表 | 符号表 | 记录程序中定义的所有符号(函数名、变量名) |
| .strtab | 字符串表 | 存放符号名、节名等字符串原文。符号表里只存索引,实际名字在这里。 |
| .rela.text | 代码重定位表 | 记录 .text 节中哪些位置需要链接器在合并时修正地址 |
两个特殊的 Section
为了在博客中写出深度,建议重点提一下这两个 Section:
(1).bss :由符号开始的块
-
现象:如果你在代码里定义一个 char arr1024\*1024 = {0},生成的 .o 文件体积并不会增加 1MB
-
原理 :未初始化的变量默认值都是 0,内核没必要在磁盘上存一堆 0。ELF 只需要记录我需要 1MB 的零空间,等程序加载到内存时,再由操作系统统一分配并清零
(2) .rela.text
写下 printf("Hello"); 时,编译器在生成 .o 文件时并不知道 printf 的确切地址
-
做法:编译器会在 .text 对应位置先填入一个占位符(通常是 00 00 00 00),然后在 .rela.text 中记录:"在偏移量 X 处,有一个叫 printf 的符号需要重定位
-
使命:链接器的主要工作,就是把占位符替换成真实的地址
三、链接过程
掌握 ELF 文件的底层结构后,我们进一步探究链接器的核心工作流程。链接操作并非单纯的文件拼接,而是一套严谨精密的重构与整合过程
1. 多个 .o 合并
当我们执行 gcc main.o func.o -o app 时,链接器会将离散的可重定位文件作为输入,最终输出一个完整、可运行的可执行文件
这个过程的核心命题是:如何将分散在不同文件中的指令(.text)和数据(.data)排列到最终的内存映射中?
如果采用按序堆叠(将 a.o 全部放前面,b.o 全部放后面),会导致最终的文件结构极其混乱,因为每个文件内部都夹杂着代码、数据和只读常量。这不仅不利于操作系统进行权限管理(代码只读,数据读写),还会严重浪费内存对齐的空间
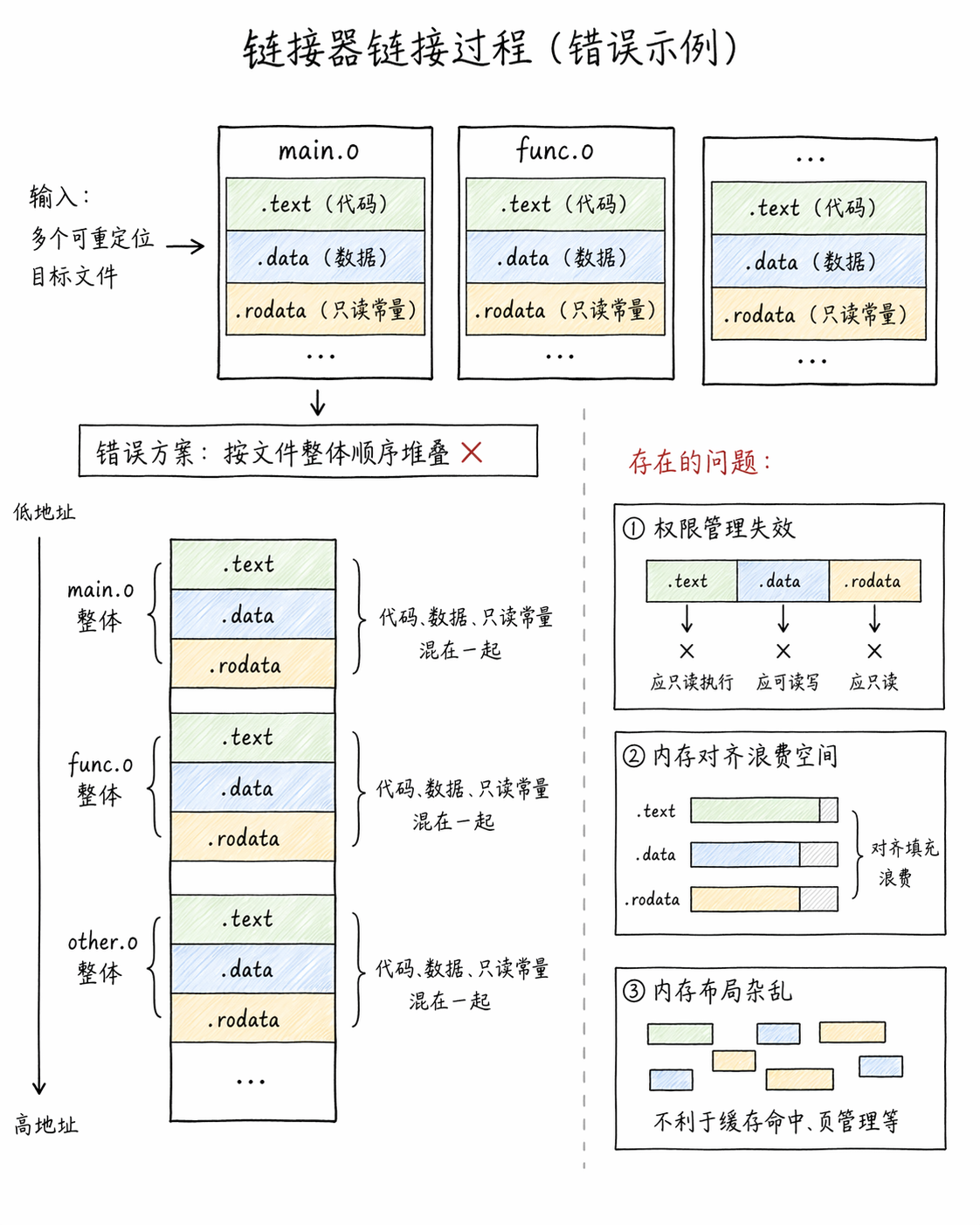
2. 合并原则
现代链接器普遍采用相似段合并原则。即:将所有输入文件中属性相同的 Section 归类,合并成最终文件中的一个大 Section
举例说明:
假设我们有两个目标文件 main.o 和 math.o,它们的结构如下:
-
main.o: 包含 .text (100字节) .data (40字节)
-
math.o: 包含 .text (80字节) .data (20字节)
链接器合并时的动作:
-
扫描所有输入文件,提取出所有的 .text
-
将 main.o 的 .text 和 math.o 的 .text 拼在一起,形成一个 180 字节的新 .text。
-
对 .data 执行同样的操作,形成一个 60 字节的新 .data。
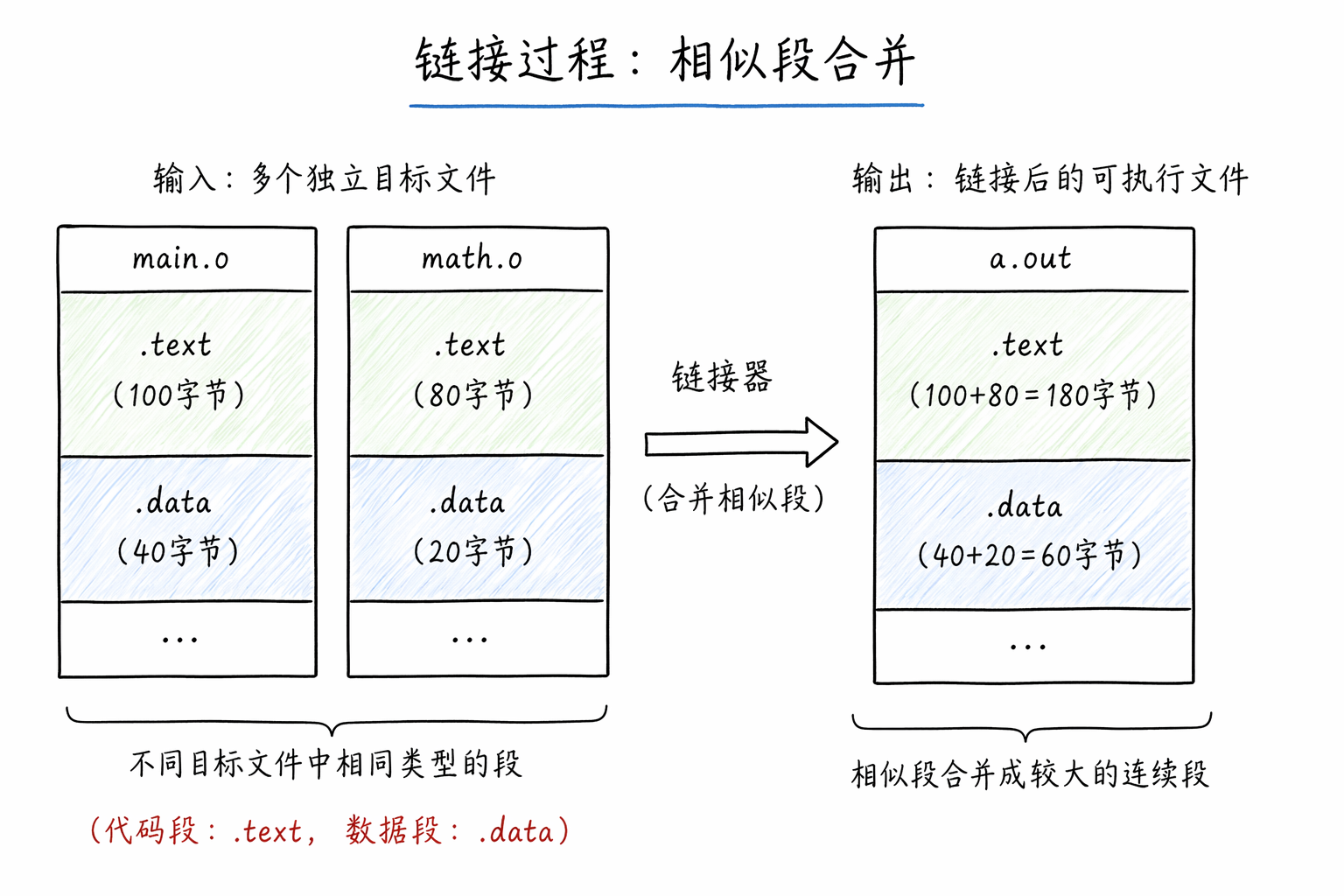
这种合并不仅仅是物理上的挪动,它直接导致了地址的变化
-
在 math.o 中,某个函数的起始偏移可能是 0x00。
-
合并后,由于它被排在了 main.o 的代码之后,它的虚拟地址会加上 main.o 的代码长度
为什么要这样合并?
从底层视角看,这种合并方式有两个核心收益:
-
内存效率: 操作系统对内存的管理是以页为单位的。代码段合并在一起,可以统一设置为可读可执行;数据段合并在一起,统一设置为可读可写。这大大减少了内存碎片的产生
-
符号地址: 只有当所有 Section 的位置固定后,链接器才能为程序中的每一个函数、每一个全局变量分配一个全局唯一的虚拟内存地址
四、静态链接的本质
为了理解静态链接的本质,我们直接从一行最简单的代码入手
假设我们的源文件 main.c 只有一行核心代码
cpp
#include <stdio.h>
int main() {
printf("hello world\n");
return 0;
}1. printf 地址问题
当我们使用 gcc -c main.c 生成目标文件 main.o 时,如果我们用反汇编工具(如 objdump -d)去观察它的机器码,会发现一个惊人的现象:
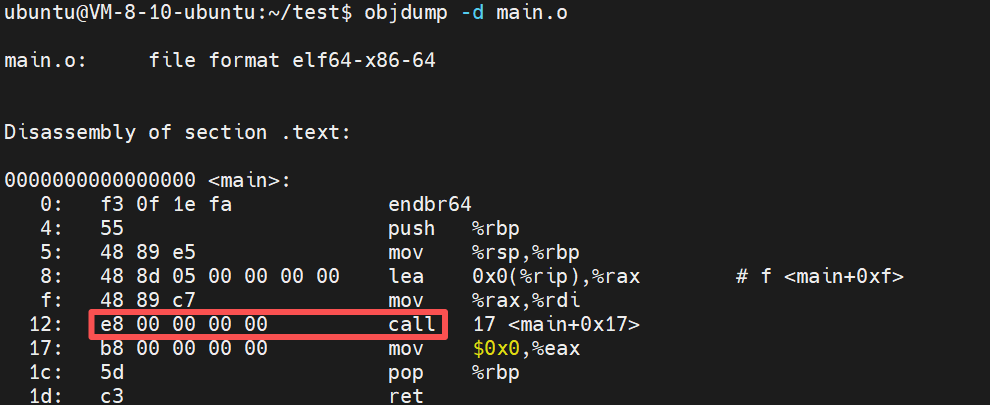
编译器在处理 main.c 文件时采取了合理的处理方式:暂时保留空缺位置,并标记为待处理状态。在生成的代码段中,对于 printf 的调用地址,它先填入一个临时的、无意义的地址
编译器同时在 ELF 文件的 .rela.text 节中标记:在代码偏移处,我引用了符号 printf,目前地址是错的,请链接器在合并时帮我修好
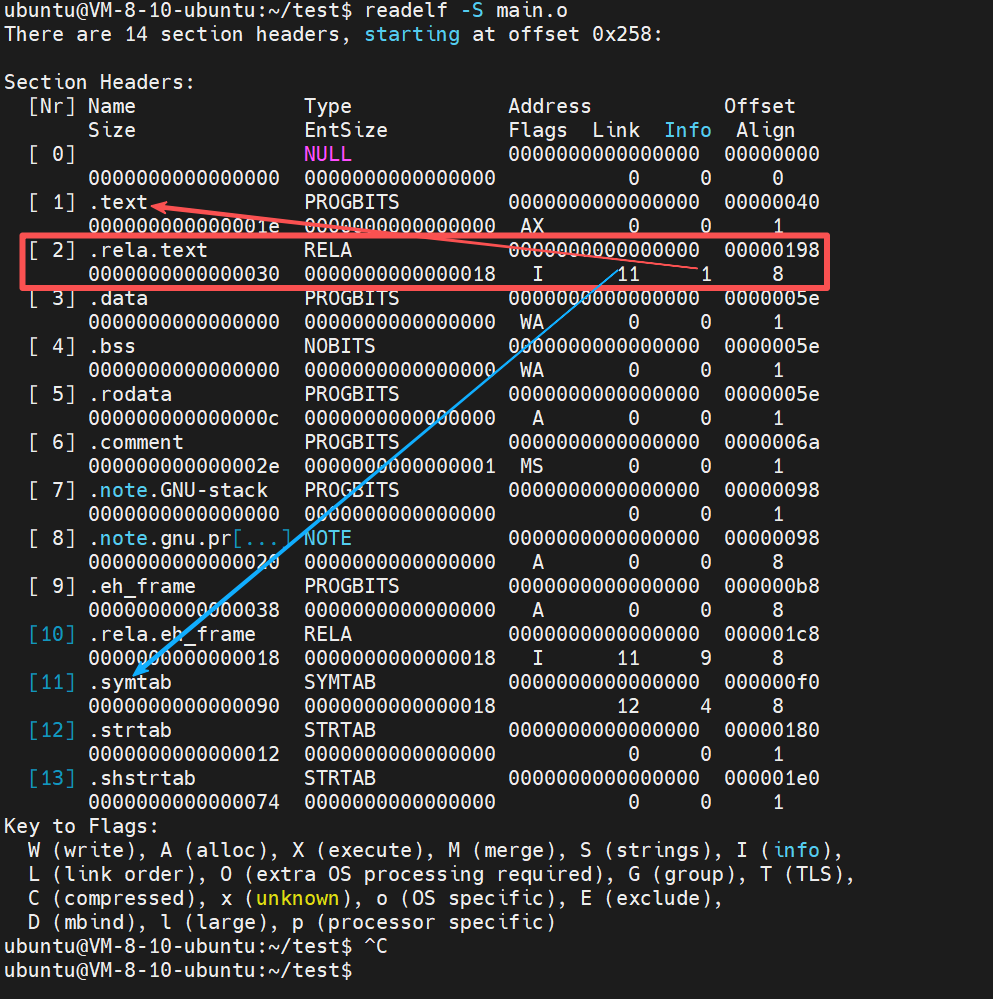
重点观察第 1 项和第 2 项:
-
1 .text:类型为 PROGBITS。这就是存放机器指令的地方(即我们之前反汇编看到的 call 指令所在位置)
-
2 .rela.text:类型为 RELA(重定位表)
-
Info 字段:注意第 2 行的 Info 这一列的值是 1。
-
Info 字段的值为 1,意味着该重定位表专门服务于索引为 1 的节(即 .text)。由此可见,.rela.text 是用于维护 .text 段重定位修正的专用数据表
-
再看第 2 项和第 11 项:
-
11 .symtab:符号表。该段存储了 puts 等符号的定义信息
-
Link 字段:注意第 2 行的 Link 这一列的值是 11
-
这表示该重定位表在执行补丁动作时,需要参考索引为 11 的节(即 .symtab)来获取符号的真实地址
2. 符号解析与重定位
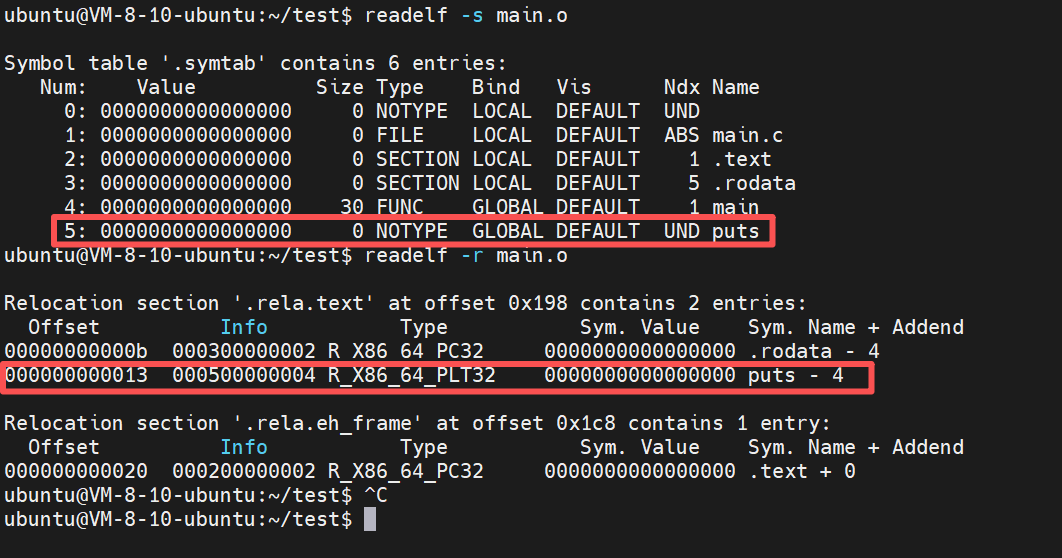
符号表(readelf -s)
在符号表(.symtab)中,重点看第 5 号条目:
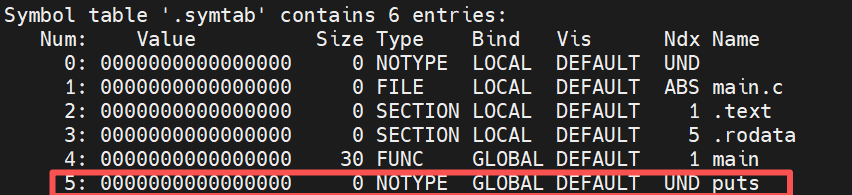
-
puts:这是 printf 被编译器优化后的符号名
-
UND :这是核心。它表示:我知道程序要用 puts ,但我的代码里没有它的实现。
-
Value 0:因为不知道在哪,所以地址暂时只能填 0
重定位表(readelf -r)
仅仅知道缺一个 puts 是不够的,链接器还需要知道代码里哪一行需要补救。这就是 .rela.text 的作用。看这一行:

-
Offset 0x13:这就是重定位的精确坐标
-
对照之前的反汇编图,call 指令在 0x12 处,指令占 5 个字节(e8 00 00 00 00)
-
0x13 恰好就是 e8 之后那 4 个全 0 占位符的起始位置!
-
-
Type R_X86_64_PLT32:这是补丁的类型。它告诉链接器:请计算一个 32 位的相对偏移地址填进去
-
Sym. Name puts :它将这个坐标与符号表里的 puts关联了起来
链接器的提取逻辑
链接器在扫描静态库时,遵循按需索取原则:
-
匹配符号 :链接器在 libc.a 的符号表中查找,发现 puts 这个符号由库中的 puts.o 提供
-
链接器并不是把整个 libc.a 塞进你的程序,而是仅将 puts.o 提取出来。
-
Section 合并 :链接器将提取出的 puts.o 里的 .text(代码)和 .data(数据),按照我们之前讲的相似段合并原则,分别并入最终可执行文件的对应位置
最终定址
一旦 puts.o 的内容被合并,puts 函数将被分配一个确定的虚拟内存地址,不再处于未定义状态
此时,链接器再回头查看 main.o 的 .rela.text:
-
将 puts 的真实地址代入计算
-
修改 0x13 偏移处的 4 个字节。至此,puts 符号在 main.o 符号表里的状态从 UND 变为了指向最终可执行文件内部某个具体坐标
3. 静态链接总结
静态链接的本质,是链接器将多个彼此孤立的二进制目标文件以及库文件,通过空间合并 与逻辑缝补,最终生成一个完整独立、可直接运行的可执行文件
我们可以通过以下三个核心阶段来复盘这一过程:
(1) 相似段合并
链接器不再以文件为单位堆砌数据,而是以 Section 为操作单位,遵循相似段合并原则:
-
所有的 .text(代码)合并成最终程序的代码段
-
所有的 .data(数据)合并成最终程序的数据段
结果:这种合并方式优化了内存对齐,并使操作系统能够统一为不同的 Segment 设置只读或读写权限
(2) 符号解析
-
它扫描每一个 .o 文件的符号表(.symtab),发现处于UND状态的符号(如 puts)
-
随后,系统会检索静态库,定位包含该符号定义的 .o 文件,并将其内容整合到整体架构中
结果 :每一个符号都获得了一个在虚拟地址空间中唯一的绝对坐标
(3) 重定位
-
链接器根据重定位表(.rela.text)记录的偏移量,回到已经合并好的代码段中
-
它将编译器预留的全零占位符抹去,填入经过严密计算的真实跳转地址或偏移地址
静态链接是完全闭环的整合过程:该过程会消解所有未定义符号与空白占位地址,将零散的机器指令统一整合为完整、地址确定的程序。链接操作完成后,程序不再依赖外部开发库,可作为独立完整的二进制文件直接运行
五、链接与执行视图
两种视图的宏观定义
在 ELF 文件的说明书中,存在两种并行的组织方式:
-
链接视图(Linking View) :以 Section 为单位。这是给链接器看的,目的是方便代码的合并、符号的解析与重定位
-
执行视图(Execution View) :以 Segment 为单位。这是给操作系统看的,目的是方便将程序映射到内存并设置权限
1. 链接视图
对应结构:节头表
在链接阶段,文件结构的粒度非常细。编译器将代码和数据按功能差异拆分成众多的 Section
-
链接器的核心任务:为了提升空间利用率,链接器在合并多个目标文件时,会将这些零散的节进行分类规整
-
为什么要合并? 物理内存的分配是以页为单位的(通常为 4KB)。如果每个细小的 Section 都独立占用一个内存页,会导致巨大的碎片浪费
-
链接器在链接阶段,将属性相似的小块合并,规整成更大的、具备统一读写执行属性的段(Segment)
2. 执行视图
对应结构:程序头表
当程序要运行时,操作系统内核接手了 ELF。此时,内核并不关心你的代码里有多少个微小的 Section,它关心的是内存管理效率
(1) 权限归并
操作系统是以页为单位管理内存的(通常是 4KB)。如果 ELF 里有 50 个小 Section,每个都占用独立的内存页,会造成巨大的空间浪费。 因此,内核会将权限相同 的 Section 打包成一个 Segment:
-
.text 和 .rodata 都是只读的,它们被打包成一个 Code Segment(只读代码段),权限设为R-X
-
.data 和 .bss 都是可读写的,它们被打包成一个 Data Segment(数据段),权限设为 RW-
(2) 管理工具:Program Header Table
这就是我们在 ELF 结构中提到的程序头表。它记录了每一个 Segment 在文件中的偏移、映射到内存的虚拟地址、以及该段的读写执行权限
总结
综上所述,通过对 ELF 文件结构的分析以及链接过程的梳理,我们可以看到,一个可执行程序并不是简单编译生成的结果,而是由多个目标文件在链接阶段完成统一拼装的产物。在这一过程中,链接器通过符号解析与重定位,将编译阶段留下的未确定地址逐一修正,使程序从半成品转变为可以独立运行的完整实体
从 Section 到 Segment,从链接视图到执行视图,ELF 文件为程序在不同阶段提供了统一而清晰的组织方式,也让我们第一次真正从数据结构的角度理解了程序本身
但仍有一个关键问题尚未解决:在使用动态库时,像 printf 这样的函数并不会在链接阶段被写死地址,那么程序在运行时又是如何找到这些函数的?地址又是在什么时候被确定的?
在下一篇中,我们将进入动态链接机制,深入分析 GOT、PLT 等关键结构,揭示程序在运行时完成符号解析的全过程
