对字节的理解
对字节的理解:都知道在计算机世界01能表示任何物体,那01的表示总有数量标准的规定吧,总不能你规定0101表示苹果,我010101表示苹果,01的数量不对等,这样肯定不行,那我到底用几个位来表示一个物品呢,所以我们规定了用字节来表示,一个字节由八个比特位,八个0/1,作为一个基本计量单位,这样一个'A'规定一个字节表示,一个汉字规定三个字节表示,而依据什么规则去用字节来表示字符呢 : 字符需要通过编码规则(如ASCII、UTF-8)转换为字节序列才能在计算机中存储,这样所有物品都由规则的用01来表示了(ps:就像是我们常说的一对一样,一对是几个呢,我们规定一对是两个,用一对当作基本统计单位一样)
我们来把把这个逻辑链条梳理得更具象化一点:
- 物理层(比特):计算机里只有电流的开关(0和1)。
- 计量层(字节) :为了方便管理,我们把8个0/1打包成一个**"字节"**,作为基本搬运单位。
- 逻辑层(编码) :为了解释这些0/1代表什么,我们查阅**"编码表"** (如UTF-8)。
- 查到
01000001-> 翻译为 'A' - 查到
1110xxxx...-> 翻译为 '中'
- 查到
- 应用层(万物):无数的字节组合在一起,通过不同的解释规则,就变成了你看到的文章、图片(图片是字节的颜色坐标)、视频(字节的动态序列)。
这样我们就能更好的理解------01与万物的联系
对CPU、内存、硬盘之间联系的理解
都说CPU与硬盘之间的速度差异过大,内存来缓解,那是怎么缓解的呢,为什么要缓解呢?
CPU: 内存:
内存: 硬盘:
硬盘:
这里提到的"速度"通俗来说,就是**"从发出指令到真正拿到数据所需要等待的时间"**。
- CPU :它的"速度"是指它处理指令的周期。现在的CPU主频很高,处理一个指令可能只需要 0.3纳秒 左右。
- 内存 :它的"速度"是指CPU喊它要数据,它多久能把数据送过来。这个时间大约是 50~100纳秒。
- 硬盘 :它的"速度"是指磁头找到数据位置(寻道)加上把数据读出来的时间。机械硬盘大约需要 5~10毫秒(即5,000,000纳秒),即便是很快的固态硬盘(SSD)也需要几十到上百微秒。
可以这样理解,a从老远的菜园摘菜送到厨房的时间,b把所有菜都洗好,切好,放好调料备用,c只需放菜到锅里,猛火爆炒5s出锅,b就相当于内存起到的作用
还有更完整的知识点点击这里
对CPU是如何不断工作的理解
CPU...(暂定)
虚拟内存空间的理解
ps :虚拟内存空间,那说白了,不就操作系同主要是出于减少内存消耗的目的"骗"一个进程有对应的内存空间,说是你这个进程的内存空间是0x0000到0xFFFF,其实也就在PCB的mm_struct 是这样写的,其实内存里啥也没有,直到CPU要拿或存这个进程的01码或者数据时,才会在内存中找一块空间把.exe文件的内容复制上来,其实也不是找一块,可能是找零零散散的内存空间,但操作系统可以内存映射啊,你这些零零散散的内存空间在内存里是这样的,但在映射前,比如说一群a1,a2,a3,a..,映射一群b1,b2,b3,b...,b1,b2,b3,b...是散的,但我a1,a2,a3,a....是完整有序的啊,它甚至有一个名字叫虚拟内存空间,从高地址到低地址,有栈,堆,.bss段,.data段,.rodata段,.text段。那就是PCB里的mm_struct里是这样写的,真找这个进程的内存数据时,是要通过mm_struct 里的记录的内容来找到进程对应的真正内存地址
-
程序的视角(虚拟内存):连续且有序
操作系统为每个进程(程序)都提供了一个独立的、私有的虚拟地址空间。在这个空间里,内存布局是固定的、连续的。正如你所知,它通常被划分为几个区域:
- 代码段 (Text Segment): 存放程序的机器指令,是只读的。
- 数据段 (Data Segment): 存放已初始化的全局变量和静态变量。
- BSS段: 存放未初始化的全局变量和静态变量。
- 堆 (Heap): 用于动态内存分配(如
malloc),从低地址向高地址增长。 - 栈 (Stack): 用于函数调用,存放局部变量、函数参数等,从高地址向低地址增长。
从程序的角度看,这些区域就像一本页码连续的书,访问起来非常方便。
-
操作系统的视角(物理内存):分散且高效
在真实的物理内存条上,情况完全不同。操作系统通过一个叫**分页(Paging)**的机制来管理内存。
- 分页映射: 虚拟内存和物理内存都被划分成固定大小的块(例如4KB),分别叫"页"和"页框"。
- 页表: 操作系统为每个进程维护一张"页表 ",这张表就像一个目录,记录了程序的哪个虚拟"页"对应物理内存中的哪个"页框"。
- 非连续分配: 一个程序在虚拟空间中连续的几页,在物理内存中可以被分配到任何空闲的页框里,它们之间不需要是连续的。
这种设计的好处非常多:
- 突破物理限制: 可以让程序使用比实际物理内存更大的空间(部分数据可以暂时存放在硬盘上)。
- 简化内存分配: 操作系统只需找零散的空闲页框即可,无需寻找一大块连续的空闲物理内存。
- 内存保护: 每个进程都有自己独立的虚拟空间和页表,无法访问其他进程的内存,保证了系统的安全和稳定。
mm_struct的内容理解
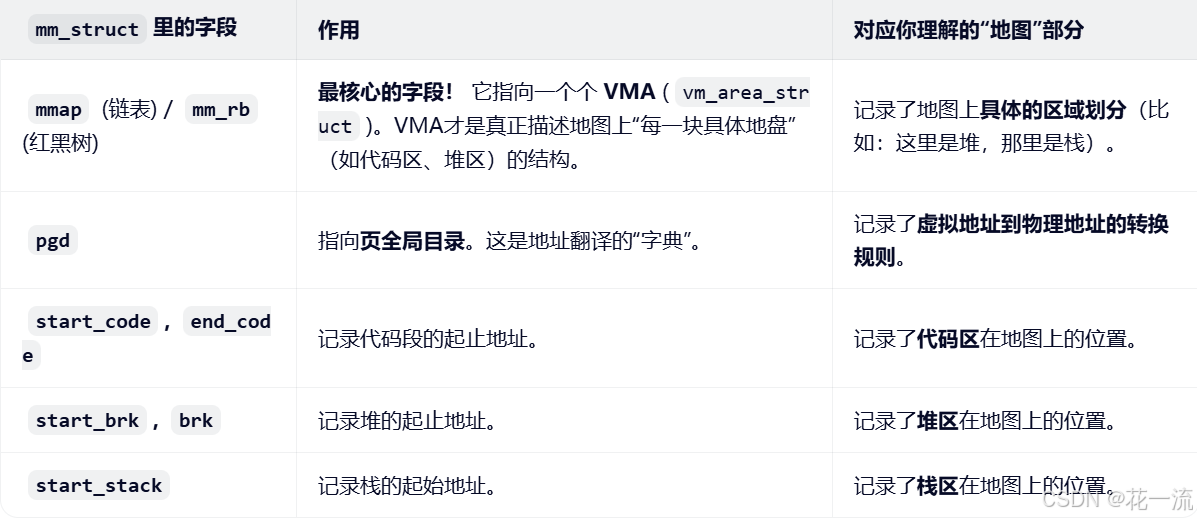
mm_struct 在PCB结构体中,记录了在虚拟内存空间中的代码段,堆,栈的位置,还有虚拟地址与真实地址对应关系
-
mm_struct 是这张地图的总管家,它手里拿着两份核心文件:
- VMA 链表 :记录了地图的区域规划 (哪里是代码,哪里是堆),以及这些区域对应硬盘上的哪个文件。
- PGD(页表) :记录了地图上的坐标(虚拟地址)和**真实世界坐标(物理地址)**的对应关系。
-
VMA(虚拟内存区域):
- 作用 :它是**"合法性检查员"** 和**"规则制定者"**。
- 场景:当你访问一个地址时,内核(操作系统)会先看 VMA 链表。VMA 会告诉你:"这个地址属于堆区,你是可读可写的"或者"这个地址属于代码段,你只能读不能写"。如果地址不在任何 VMA 范围内,那就是非法访问(Segmentation Fault)。
- 记录内容:它记录了"地图上的这块区域(比如 0x400000-0x500000)对应磁盘上的哪个文件(比如 exe 文件),是数据段,还是代码段,还是栈,还是堆"。
-
PGD(页全局目录,页表的一部分):
- 作用 :它是**"极速导航员"**。
- 场景 :当 VMA 确认地址合法后,CPU 的 MMU(内存管理单元)硬件会直接去查 PGD(以及后面的多级页表)。PGD 不负责讲规则,它只负责翻译:直接把虚拟地址转换成物理地址。按照映射规则,通过虚拟地址在硬盘中找到物理地址。
- 记录内容:它记录了"虚拟页号 10 对应物理页框号 888"。
对函数栈帧的理解
栈帧的创建与销毁流程
我们以一个经典的C语言函数调用为例,看看底层发生了什么:
-
准备阶段(在调用者函数中)
- 参数压栈: 编译器会生成指令,将函数的参数按照从右到左的顺序依次"压入"栈中。
- 调用函数: 执行
call指令。这个指令会做两件关键事:- 将下一条指令的地址(返回地址)压入栈,这样函数执行完后才知道该回到哪里。
- 跳转到被调用函数的入口地址。
-
建立新栈帧(在被调用函数的开头)
这是最关键的一步,通常由三条汇编指令完成,称为"函数序言(Function Prologue)":
push ebp:保存上一层函数的栈底指针(EBP),形成一个调用链。mov ebp, esp:将当前的栈顶指针(ESP)的值赋给EBP。现在,EBP就成为了当前函数栈帧的固定基准点。sub esp, N:将栈顶指针ESP向下移动N个字节,为当前函数的所有局部变量分配空间。
至此,一个全新的、独立的栈帧就创建好了。
-
存储局部变量
现在,栈帧已经建立,EBP是基准点。那么局部变量存在哪里呢?答案是:它们就存放在我们刚刚用
sub esp, N开辟出来的空间里,通过相对于EBP的偏移量来访问。- 比如,第一个局部变量可能存放在
[ebp - 4]这个地址。 - 第二个局部变量可能存放在
[ebp - 8]这个地址。 - 而函数的参数,则可以通过
[ebp + 8]、[ebp + 12]等正偏移量来访问。
所以,栈并不是"知道"要存局部变量,而是编译器在编译时就已经计算好了需要多少空间,并生成了精确的指令来分配空间和通过偏移量访问它们。
- 比如,第一个局部变量可能存放在
-
销毁栈帧(在函数返回时)
函数执行完毕,需要返回时,会执行"函数结语(Function Epilogue)"来清理现场:
mov esp, ebp:将栈顶指针ESP恢复到EBP的位置,相当于释放了所有局部变量占用的空间。pop ebp:将栈中保存的上一层函数的EBP值弹出,恢复到EBP寄存器,回到了上一层函数的栈帧。ret:从栈中弹出之前保存的返回地址,并跳转回去,程序继续执行。
整个过程就像搭积木,调用函数时搭上一块(创建栈帧),函数返回时拆掉这块(销毁栈帧),一切都有条不紊,完全由编译器和CPU的指令自动完成。
对数据段的理解
数据段里存放的绝对不是 01 这种指令码,而是数据的"真身"(二进制数值)。
为了让你彻底明白,我们需要区分**"动作"** 和**"对象"**。
- 核心区别:指令 vs 数据
- 代码段(.text) :存放的是动作 。
- 比如
01(假设的指令码)代表"加法"。这是告诉 CPU "去做什么"。
- 比如
- 数据段(.data) :存放的是对象 。
- 比如
10(二进制1010)。这是告诉 CPU "操作的具体数值是多少"。
- 比如
打个比方:
- 代码段 就像剧本,上面写着:"主角拿起苹果"。(这是指令)
- 数据段 就像道具库 ,里面真的放着一个苹果。(这是数据)
- 深入底层:
int count = 10;到底长啥样?
当你写下 int count = 10; 这行代码,经过编译器编译后,它在磁盘上的可执行文件(比如 .data 段)里是这样的:
在数据段(.data)里:
这里只存数值,不存变量名(变量名在编译后通常就丢了,变成了地址)。
- 内容 :就是数字
10的二进制形式。 - 样子 :在 32 位系统里,它通常长这样(十六进制表示):
0A 00 00 00。- 这就是
10的真身。CPU 读到这个内存地址时,它看到的不是"指令",而是"数值 10"。
- 这就是
在代码段(.text)里:
这里存的是搬运指令。
- 为了让
count变成 10,CPU 需要执行指令。 - 指令 :类似于
MOV [地址], 10。 - 样子 :这才会出现类似
C7 05 ...这样的操作码(Opcode)。这条指令的意思是:"把数值 10 搬运到内存的某个地址去"。
ps : 不就是代码段里的指令写好了,要去哪里拿数据,数据段在那个地址放着数据
对程序运行阶段的总结
- 进程创建与账本建立 :双击 exe 后,操作系统首先创建 PCB(进程控制块),并初始化
mm_struct(内存描述符),这是管理内存的"总账本"。 - 虚拟地址空间规划(画地图) :加载器读取 exe 文件头,在虚拟地址空间中划定代码段、数据段、堆和栈的范围,但此时不分配任何物理内存。
- VMA 与文件映射 :
mm_struct通过 VMA(虚拟内存区域)记录虚拟地址与磁盘文件的对应关系(例如:虚拟地址 0x400000 对应 exe 文件的第 0 字节)。 - 首次执行与缺页异常:CPU 尝试执行第一条指令时,因页表为空触发"缺页异常",内核介入,分配物理页框并将代码从硬盘读入内存。
- 栈的自动分配:栈空间在虚拟内存中高地址向下增长。当栈指针移动触发缺页异常时,内核自动分配物理页,实现"按需增长"。
- 堆的延迟分配 :
malloc仅通过brk/mmap扩展虚拟地址范围,只有当程序真正读写堆内存时,才会触发缺页异常并分配物理页。 - 物理内存的碎片化与映射:虚拟内存是连续的,但对应的物理内存是离散的。通过页表(PGD)的映射,操作系统将零散的物理页框(Page Frame)拼接成连续的虚拟空间。
- 核心机制总结 :虚拟内存的本质是**"按需调页"**。操作系统通过"画饼"(虚拟地址)和"按需兑现"(缺页异常处理),实现了内存的高效利用和进程隔离。