Redis
- 一、前言
- 一、常用的通用命令
-
- [1.KEYS------查找匹配的 Key](#1.KEYS——查找匹配的 Key)
- [2.DEL------删除 Key](#2.DEL——删除 Key)
- [3.EXISTS------ 判断 Key 是否存在](#3.EXISTS—— 判断 Key 是否存在)
- [4.EXPIRE------ 设置过期时间](#4.EXPIRE—— 设置过期时间)
- [5.TTL------ 查看剩余过期时间](#5.TTL—— 查看剩余过期时间)
- [6. TYPE------ 查看 Key 的数据类型](#6. TYPE—— 查看 Key 的数据类型)
- 二、Redis常用数据结构
- 三、JAVA客户端
-
- 1.Jedis
- [2.Spring Data Redis](#2.Spring Data Redis)
-
- [(1)RedisTemplate 快速入门](#(1)RedisTemplate 快速入门)
-
- [默认 JDK 序列化的问题](#默认 JDK 序列化的问题)
- (2)自定义RedisTemplate
-
- [@class 冗余问题](#@class 冗余问题)
- (3)StringRedisTemplate
一、前言
1.基本概念
Redis 就是一个运行在内存中的、支持多种数据结构的 NoSQL 数据库
Redis(Remote Dictionary Server)(远程字典服务)是⼀种基于键值对(key-value)的 NoSQL 数据库,其数据主要存储在内存中,而非硬盘,因此读写速度极快。其本质是一个巨大的 Map(字典),通过 Key 来访问 Value,虽然它是键值对,但 Value 支持多种数据结构,如字符串、哈希、列表、集合、有序集合、位图、地理空间等,虽然是内存数据库,但它支持将数据异步或同步地写入硬盘进行持久化,防止重启后数据完全丢失。
2.特性
速度快、基于键值对的数据结果服务器、功能丰富、简单稳定、客户端语⾔多、持久化、主从复制、⽀持⾼可⽤和分布式
- 速度快:Redis 的所有数据都是存放在内存中的,Redis 是用 C 语言实现的,且在在 6.0 版本前,其使用单线程,预防了多线程可能产生的竞争问题,6.0 版本后引入了多线程机制,但主要也是在处理网络和 IO,但命令执行仍然采用单线程模式;
- 键值存储支持多种数据结构:Redis 支持多种数据结构包括:String(字符串)、Hash(哈希表)、List(列表)、Set(无序集合)、Sorted Set(有序集合)、Bitmap(位图)、HyperLogLog(基数统计)、Geospatial(地理空间)、Stream(流式消息);
- 丰富的功能:提供了许多额外的功能包括:键过期功能、发布订阅功能、支持 Lua 脚本功能、简单的事务功能、流⽔线(Pipeline)功能等;
- 简单稳定:Redis 的源码很少,且使用单线程模型,同时其不需要
依赖于操作系统中的类库,Redis 自己实现了事件处理的相关功能; - 客户端语言多:Redis 提供了简单的 TCP 通信协议,很多编程语言可以很方便地接入到 Redis,例如 C、C++、Java、PHP、Python、NodeJS 等;
- 持久化机制(RDB + AOF):Redis 提供了两种持久化方式保证数据安全,两者可以同时使用,实现数据持久化与性能的平衡:
- RDB(快照):在指定时间间隔将内存数据集快照写入磁盘,适合备份与灾难恢复。
- AOF(追加文件):记录所有写操作命令,服务器重启时重放命令,实现更高数据安全性。
- 主从复制:Redis 提供了复制功能,实现了多个相同数据的 Redis 副本(Replica);
- 高可用与分布式扩展:Redis 提供了高可用实现的 Redis 哨兵(Redis Sentinel),能够保证 Redis 结点的故障发现和故障自动转移。也提供了 Redis 集群(Redis Cluster),是真正的分布式实现,提供了高可用、读写和容量的扩展性
3.适用场景
- 缓存(Cache):这是最常见的用法。将数据库(MySQL)中频繁查询但改动较少的数据(如用户信息、商品详情、配置信息)放到 Redis 中
- 排行榜系统:例如按照热度排名的排行榜,按照发布时间的排行榜,按照各种复杂维度计算出的排行榜,Redis 提供了列表和有序集合的结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统
- 计数器应用:例如视频网站播放数、电商网站浏览数,为了保证数据的实时性,每一次播放和浏览都要加 1 操作,如果并发量很大,对于传统关系型数据的性能是一种挑战,Redis 天然支持计数功能而且计数的性能较优。
- 社交网络:赞 / 踩、粉丝、共同好友 / 喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,而且传统的关系型数据不太合适保存这种类型的数据,Redis 提供的数据结构可以相对比较容易地实现这些功能;
- 消息队列系统:消息队列系统具有业务解耦、非实时业务削峰等特性。Redis 提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不够足够强大,但是对于一般的消息队列功能基本可以满足。
一、常用的通用命令
1.KEYS------查找匹配的 Key
KEYS pattern 用于查找所有符合给定模式(pattern)的 Key。支持的通配如下,
| 符号 | 含义 | 示例 |
|---|---|---|
| * | 匹配任意多个字符 | user:* 匹配所有以 user: 开头的 Key |
| ? | 匹配单个字符 | user:? 匹配 user:1、user:a,不匹配 user:10 |
| abc | 匹配括号内的任意一个字符 | user:12 匹配 user:1 或 user:2 |
| \^abc | 匹配不在括号内的任意字符 | user:\^0-9 匹配非数字结尾的 Key |
bash
127.0.0.1:6379> KEYS *
1) "user:1001"
2) "product:200"
3) "order:5001"
4) "cache:homepage"
127.0.0.1:6379> KEYS user:*
1) "user:1001"
2) "user:1002"
3) "user:admin"
127.0.0.1:6379> KEYS user:??
(empty array)
生产环境禁用 KEYS:KEYS 命令会一次性遍历整个数据库的所有 Key,时间复杂度为 O(n)。在 Key 数量庞大的生产环境中执行该命令,会严重阻塞 Redis 主线程,导致其他所有命令无法响应,造成服务雪崩。
2.DEL------删除 Key
DEL key key ... 用于删除一个或多个指定的 Key,不区分数据类型。返回实际被删除的 Key 的数量。如果 Key 不存在,则不计入返回值。
bash
127.0.0.1:6379> SET name "张三"
OK
127.0.0.1:6379> SET age 25
OK
127.0.0.1:6379> DEL name age
(integer) 2 # 成功删除两个 Key
127.0.0.1:6379> DEL not_exist_key
(integer) 0 # Key 不存在,返回 03.EXISTS------ 判断 Key 是否存在
EXISTS key key ... 用于检查一个或多个 Key 是否存在。返回存在的 Key 的数量。
bash
127.0.0.1:6379> SET username "admin"
OK
127.0.0.1:6379> SET age 30
OK
127.0.0.1:6379> EXISTS username
(integer) 1 # 存在
127.0.0.1:6379> EXISTS username age email
(integer) 2 # username 和 age 存在,email 不存在,返回 2
127.0.0.1:6379> EXISTS not_exist
(integer) 04.EXPIRE------ 设置过期时间
EXPIRE key seconds 为指定的 Key 设置生存时间(TTL,Time To Live),单位为秒。时间到达后,Key 会被 Redis 自动删除。返回值为1表示设置成功,为0表示Key 不存在或设置失败。
| 命令 | 说明 |
|---|---|
| EXPIRE key seconds | 以秒为单位设置过期时间 |
| PEXPIRE key milliseconds | 以毫秒为单位设置过期时间 |
| EXPIREAT key timestamp | 设置在指定 Unix 时间戳(秒) 过期 |
| PEXPIREAT key milliseconds-timestamp | 设置在指定 Unix 时间戳(毫秒) 过期 |
| PERSIST key | 移除 Key 的过期时间,使其永久有效 |
bash
127.0.0.1:6379> SET code:123456 "888888"
OK
127.0.0.1:6379> EXPIRE code:123456 60 # 60 秒后过期
(integer) 1
127.0.0.1:6379> SET session:token "abc123"
OK
127.0.0.1:6379> PEXPIRE session:token 30000 # 30 秒(30000 毫秒)后过期
(integer) 1
127.0.0.1:6379> PERSIST code:123456 # 移除过期时间,变为永久有效
(integer) 15.TTL------ 查看剩余过期时间
TTL key 用于查看指定 Key 的剩余生存时间,单位为秒。返回正整数(如 60)表示Key 还存在,剩余 60 秒过期;返回 -1 表示Key 存在但没有设置过期时间(永久有效);返回 -2 表示 Key 不存在(可能已被删除或从未创建)。
| 命令 | 说明 |
|---|---|
| TTL key | 返回剩余秒数 |
| PTTL key | 返回剩余毫秒数 |
bash
# 场景一:Key 存在且有过期时间
127.0.0.1:6379> SET session:user1 "data" EX 120
OK
127.0.0.1:6379> TTL session:user1
(integer) 115 # 剩余 115 秒
127.0.0.1:6379> PTTL session:user1
(integer) 114321 # 剩余 114321 毫秒
# 场景二:Key 存在但永久有效
127.0.0.1:6379> SET config "value"
OK
127.0.0.1:6379> TTL config
(integer) -1
# 场景三:Key 不存在
127.0.0.1:6379> TTL not_exist_key
(integer) -26. TYPE------ 查看 Key 的数据类型
TYPE key 用于返回指定 Key 所存储的值的底层数据类型。Redis 是键值对数据库,每个 Key 对应一个 Value,而 Value 可以是不同的数据结构(String、Hash、List、Set、ZSet 等)。
bash
# 场景一:String 类型
127.0.0.1:6379> SET username "张三"
OK
127.0.0.1:6379> TYPE username
string
# 场景二:Hash 类型
127.0.0.1:6379> HSET user:1001 name "李四" age 25
(integer) 2
127.0.0.1:6379> TYPE user:1001
hash
# 场景三:List 类型
127.0.0.1:6379> LPUSH tasks "task1" "task2"
(integer) 2
127.0.0.1:6379> TYPE tasks
list
# 场景四:Set 类型
127.0.0.1:6379> SADD tags "Java" "Redis" "MySQL"
(integer) 3
127.0.0.1:6379> TYPE tags
set
# 场景五:ZSet 类型
127.0.0.1:6379> ZADD scores 95 "小明" 88 "小红"
(integer) 2
127.0.0.1:6379> TYPE scores
zset
# 场景六:Key 不存在
127.0.0.1:6379> TYPE not_exist_key
noneTYPE 的时间复杂度为 O(1),是一个非常轻量的命令,可以安全地在生产环境中使用。
二、Redis常用数据结构
Redis 是一个 Key-Value 类型的数据库,但它的 Value 支持多种丰富的数据结构,这是 Redis 区别于普通缓存系统(如 Memcached)的核心优势。
Key的层级格式
在实际项目中,Redis 的 Key 通常采用冒号分隔的层级命名规范,这样可以避免 Key 冲突(不同业务模块的 Key 通过前缀区分)、便于管理(可通过前缀批量查询或删除)、结构清晰(一目了然地看出 Key 的含义)。
- 推荐格式:项目名:业务名:类型:id
如下例所示,
bash
set test:name:1 '{"id":1,"name":"Jack","age":21}'
set test:name:2 '{"id":2,"name":"make","age":18}'
1.String
| 命令 | 功能 | 示例 | 解释 |
|---|---|---|---|
| SET key value EX seconds | 设置 Key 的值(可同时设过期时间) | SET name "张三" EX 60 | 将 Key 为 name 的值设置为 "张三",并在 60 秒后自动删除。若 Key 已存在则覆盖旧值 |
| GET key | 获取 Key 的值 | GET name | 返回 Key name 对应的值。若 Key 不存在则返回 nil(空) |
| MSET key1 v1 key2 v2 | 批量设置多个 Key | MSET a 1 b 2 c 3 | 一次性设置三个 Key:a=1、b=2、c=3。原子操作,要么全部成功,要么全部失败 |
| MGET key1 key2 | 批量获取多个 Key | MGET a b c | 一次性获取 a、b、c 三个 Key 的值,返回一个数组(如 "1","2","3")。不存在的 Key 返回 nil |
| INCR key | 将值原子递增 1 | INCR views | 将 Key views 中存储的整数值加 1。若 Key 不存在则先设为 0 再加 1。常用于计数场景 |
| INCRBY key num | 将值原子递增指定数值 | INCRBY score 10 | 将 Key score 的值增加 10。若 Key 不存在则先设为 0 再加 10。支持负数 |
| DECR key | 将值原子递减 1 | DECR stock | 将 Key stock 的值减 1。若 Key 不存在则先设为 0 再减 1(结果 -1)。常用于库存扣减 |
| SETNX key value | 仅当 Key 不存在时才设置 | SETNX lock:order "1" | 仅当 lock:order 不存在时才设置成功,返回 1;若已存在则设置失败,返回 0 |
| SETEX key seconds value | 设置值并同时指定过期时间 | SETEX code 60 "8888" | 将验证码 8888 存入 Key code,并同时设置 60 秒后自动过期。等价于 SET code "8888" EX 60 |
bash
# 基础读写
127.0.0.1:6379> SET username "admin" EX 3600
OK
127.0.0.1:6379> GET username
"admin"
# 批量操作
127.0.0.1:6379> MSET a 10 b 20 c 30
OK
127.0.0.1:6379> MGET a b c
1) "10"
2) "20"
3) "30"
# 计数器
127.0.0.1:6379> SET article:100:views 0
OK
127.0.0.1:6379> INCR article:100:views
(integer) 1
127.0.0.1:6379> INCRBY article:100:views 5
(integer) 6
127.0.0.1:6379> DECR article:100:views
(integer) 5
# 分布式锁(SETNX)
127.0.0.1:6379> SETNX lock:order:123 "uuid-123"
(integer) 1
127.0.0.1:6379> SETNX lock:order:123 "uuid-456"
(integer) 0 # 已存在,加锁失败
# 带过期时间的验证码
127.0.0.1:6379> SETEX sms:13800138000 300 "123456"
OK
127.0.0.1:6379> GET sms:13800138000
"123456"2.Hash
Hash 是一个键值对集合,特别适合存储对象。一个 Hash 类型的 Key 下可以包含多个 field-value 对。
未使用Hash存储的方式

使用Hash存储的方式
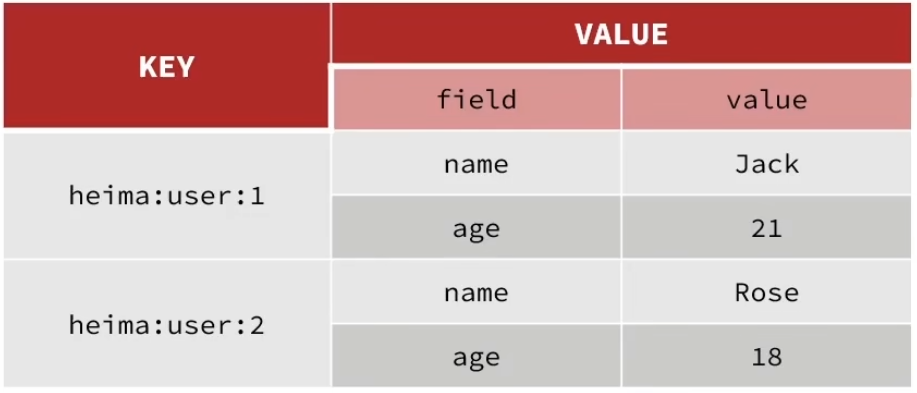
| 命令 | 功能 | 示例 | 解释 |
|---|---|---|---|
| HSET key field value field value ... | 设置一个或多个字段 | HSET user:1001 name "张三" | 将用户 1001 的姓名设为 "张三" |
| HGET key field | 获取指定字段的值 | HGET user:1001 name | 获取用户 1001 的姓名,若字段不存在则返回 nil |
| HMSET key field value field value ... | 批量设置多个字段 | HSET user:1001 name "张三" age 25 | 将用户 1001 的姓名设为 "张三",年龄设为 25 |
| HMGET key field field ... | 批量获取多个字段 | HMGET user:1001 name age email | 一次性获取姓名、年龄、邮箱,返回数组 |
| HGETALL key | 获取所有字段和值 | HGETALL user:1001 | 返回所有 field 和 value,交替排列 |
| HDEL key field field ... | 删除一个或多个字段 | HDEL user:1001 age | 删除年龄字段 |
| HEXISTS key field | 判断字段是否存在 | HEXISTS user:1001 name | 检查姓名是否存在,存在返回 1,否则返回 0 |
| HKEYS key | 获取所有字段名 | HKEYS user:1001 | 返回所有 field 名称的列表 |
| HVALS key | 获取所有字段值 | HVALS user:1001 | 返回所有 value 的列表 |
| HINCRBY key field num | 将字段值原子递增 | HINCRBY user:1001 age 1 | 将年龄字段的值加 1 |
bash
# 存储用户完整信息
127.0.0.1:6379> HSET user:1001 name "张三"
(integer) 1
# 获取单个字段
127.0.0.1:6379> HGET user:1001 name
"张三"
# 批量设置多个字段
127.0.0.1:6379> HSET user:1001 age 25 email "zhangsan@example.com" city "北京"
(integer) 3
# 批量获取多个字段
127.0.0.1:6379> HMGET user:1001 name age email city
1) "张三"
2) "25"
3) "zhangsan@example.com"
4) "北京"
# 获取所有字段和值
127.0.0.1:6379> HGETALL user:1001
1) "name"
2) "张三"
3) "age"
4) "25"
5) "email"
6) "zhangsan@example.com"
7) "city"
8) "北京"
# 判断字段是否存在
127.0.0.1:6379> HEXISTS user:1001 phone
(integer) 0
# 获取所有字段名
127.0.0.1:6379> HKEYS user:1001
1) "name"
2) "age"
3) "email"
4) "city"
# 获取所有值
127.0.0.1:6379> HVALS user:1001
1) "张三"
2) "25"
3) "zhangsan@example.com"
4) "北京"
# 递增年龄
127.0.0.1:6379> HINCRBY user:1001 age 1
(integer) 26
# 删除字段
127.0.0.1:6379> HDEL user:1001 city
(integer) 13.List
List 是一个双向链表,支持从两端推入或弹出元素,元素有序且可重复。
List 的特征与 LinkList 类似:有序、元素可以重复、插入和删除快、查询速度一般。
| 命令 | 功能 | 示例 | 解释 |
|---|---|---|---|
| LPUSH key value value ... | 从左侧头部插入 | LPUSH tasks "task1" | 将 "task1" 插入到列表 tasks 的头部 |
| RPUSH key value value ... | 从右侧尾部插入 | RPUSH tasks "task2" | 将 "task2" 追加到列表 tasks 的尾部 |
| LPOP key | 从左侧弹出并移除 | LPOP tasks | 移除并返回列表头部的元素 |
| RPOP key | 从右侧弹出并移除 | RPOP tasks | 移除并返回列表尾部的元素 |
| LRANGE key start stop | 获取指定范围的元素 | LRANGE tasks 0 -1 | 获取列表 tasks 的全部元素(-1 表示最后一个) |
| LINDEX key index | 获取指定索引的元素 | LINDEX tasks 0 | 获取列表第一个元素 |
| LLEN key | 获取列表长度 | LLEN tasks | 返回列表中元素的数量 |
| LREM key count value | 删除指定值的元素 | LREM tasks 1 "task1" | 删除列表中 1 个值为 "task1" 的元素 |
| LTRIM key start stop | 截取保留指定范围 | LTRIM tasks 0 99 | 只保留前 100 个元素,其余全部删除 |
| LSET key index value | 设置指定索引的值 | LSET tasks 0 "new_task" | 将列表第一个元素修改为 "new_task" |
| BLPOP key key ... timeout | 阻塞式左侧弹出 | BLPOP tasks 10 | 若列表为空则阻塞等待最多 10 秒,直到有新元素 |
| BRPOP key key ... timeout | 阻塞式右侧弹出 | BRPOP tasks 10 | 同上,但从右侧弹出 |
bash
# 构建队列(右侧进,左侧出)
127.0.0.1:6379> RPUSH queue "job1" "job2" "job3"
(integer) 3
127.0.0.1:6379> LPOP queue
"job1"
127.0.0.1:6379> LPOP queue
"job2"
# 构建栈(同侧进出)
127.0.0.1:6379> LPUSH stack "a" "b" "c"
(integer) 3
127.0.0.1:6379> LPOP stack
"c"
127.0.0.1:6379> LPOP stack
"b"
# 查看所有元素
127.0.0.1:6379> LPUSH tasks "task1" "task2" "task3"
(integer) 3
127.0.0.1:6379> LRANGE tasks 0 -1
1) "task3"
2) "task2"
3) "task1"
# 获取指定索引和长度
127.0.0.1:6379> LINDEX tasks 1
"task2"
127.0.0.1:6379> LLEN tasks
(integer) 3
# 修改和删除
127.0.0.1:6379> LSET tasks 0 "important_task"
OK
127.0.0.1:6379> LREM tasks 1 "task1"
(integer) 1
# 截取保留(模拟最新列表)
127.0.0.1:6379> LPUSH news "news1" "news2" "news3" "news4"
(integer) 4
127.0.0.1:6379> LTRIM news 0 2 # 只保留最新的 3 条
OK
127.0.0.1:6379> LRANGE news 0 -1
1) "news4"
2) "news3"
3) "news2"
# 阻塞等待(在另一个终端测试)
127.0.0.1:6379> BLPOP queue 304.Set
Set 是一个无序、元素不重复的集合,支持集合间的交、并、差运算,类似于 Java 中的 HashSet 。
| 命令 | 功能 | 示例 | 解释 |
|---|---|---|---|
| SADD key member member ... | 添加元素 | SADD tags "Java" "Redis" | 将 "Java" 和 "Redis" 添加到集合 tags 中 |
| SREM key member member ... | 删除元素 | SREM tags "Java" | 从集合 tags 中移除 "Java" |
| SMEMBERS key | 获取所有元素 | SMEMBERS tags | 返回集合 tags 中的所有元素 |
| SISMEMBER key member | 判断元素是否存在 | SISMEMBER tags "Java" | 检查 "Java" 是否在集合中,存在返回 1,否则返回 0 |
| SCARD key | 获取元素个数 | SCARD tags | 返回集合中元素的数量 |
| SPOP key count | 随机弹出元素 SPOP tags 2 | 随机移除并返回 2 个元素 | |
| SRANDMEMBER key count | 随机获取元素(不删除) S | RANDMEMBER tags 3 | 随机返回 3 个元素,但不删除 |
| SINTER key key ... | 求交集 SINTER set1 set2 | 返回同时在 set1 和 set2 中的元素 | |
| SUNION key key ... | 求并集 SUNION set1 set2 | 返回 set1 和 set2 中的所有元素(去重) | |
| SDIFF key key ... | 求差集 SDIFF set1 set2 | 返回在 set1 但不在 set2 中的元素 | |
| SINTERSTORE dest key ... | 交集结果存入新集合 | SINTERSTORE result set1 set2 | 将交集结果存入 result 集合 |
bash
# 添加元素
127.0.0.1:6379> SADD user:1:tags "Java" "Redis" "MySQL" "Spring"
(integer) 4
# 判断是否存在
127.0.0.1:6379> SISMEMBER user:1:tags "Java"
(integer) 1
127.0.0.1:6379> SISMEMBER user:1:tags "Python"
(integer) 0
# 获取所有元素
127.0.0.1:6379> SMEMBERS user:1:tags
1) "Java"
2) "Redis"
3) "MySQL"
4) "Spring"
# 获取元素个数
127.0.0.1:6379> SCARD user:1:tags
(integer) 4
# 随机获取(不删除)
127.0.0.1:6379> SRANDMEMBER user:1:tags 2
1) "Spring"
2) "MySQL"
# 随机弹出(会删除)
127.0.0.1:6379> SPOP user:1:tags 1
1) "Spring"
# 删除元素
127.0.0.1:6379> SREM user:1:tags "MySQL"
(integer) 1
# 集合运算
127.0.0.1:6379> SADD user:1:friends "user2" "user3" "user4"
(integer) 3
127.0.0.1:6379> SADD user:5:friends "user2" "user3" "user6"
(integer) 3
# 共同好友(交集)
127.0.0.1:6379> SINTER user:1:friends user:5:friends
1) "user2"
2) "user3"
# 并集
127.0.0.1:6379> SUNION user:1:friends user:5:friends
1) "user2"
2) "user3"
3) "user4"
4) "user6"
# 差集(user1 有而 user5 没有)
127.0.0.1:6379> SDIFF user:1:friends user:5:friends
1) "user4"
# 存储交集结果
127.0.0.1:6379> SINTERSTORE common:friends user:1:friends user:5:friends
(integer) 2
127.0.0.1:6379> SMEMBERS common:friends
1) "user2"
2) "user3"5.SortedSet
SortedSet是一个可排序的 set 集合,与 Java 中的 TreeSet 有些类似,但底层数据结构却差别很大。SortedSet 中的每一个元素都带有一个 score 属性,可以基于 score 属性对元素排序,底层的实现是一个跳表(SkipList)加hash表。
SortedSet具备可排序、元素不重复、查询速度快的特性
| 命令 | 功能 | 示例 | 解释 |
|---|---|---|---|
| ZADD key score member score member ... | 添加元素(可批量) | ZADD rank 95 "张三" 88 "李四" | 将 "张三" 分数 95、"李四" 分数 88 加入排行榜 |
| ZREM key member member ... | 删除元素 | ZREM rank "张三" | 从排行榜中移除 "张三" |
| ZSCORE key member | 获取元素的分数 | ZSCORE rank "张三" | 返回 "张三" 的分数 |
| ZRANK key member | 获取正序排名(从低到高) | ZRANK rank "张三" | 返回 "张三" 的排名(从 0 开始,分数越低排名越靠前) |
| ZINCRBY key increment member | 增加元素的分数 | ZINCRBY rank 5 "张三" 将 "张三" 的分数增加 5 | |
| ZRANGE key start stop WITHSCORES | 正序获取指定范围 | ZRANGE rank 0 -1 WITHSCORES 按分数从低到高返回全部元素及分数 | |
| ZRANGEBYSCORE key min max WITHSCORES | 按分数范围正序获取 ZRANGEBYSCORE rank 80 90 | 返回分数在 80~90 之间的所有元素 | |
| ZCARD key | 获取元素个数 | ZCARD rank | 返回排行榜中的元素数量 |
| ZCOUNT key min max | 统计分数范围内的元素数 ZCOUNT rank 80 90 | 返回分数在 80~90 之间的元素个数 | |
| ZREMRANGEBYRANK key start stop | 按排名删除 | ZREMRANGEBYRANK rank 0 10 删除排名 0~10 的元素 | |
| ZREMRANGEBYSCORE key min max | 按分数范围删除 | ZREMRANGEBYSCORE rank 0 60 | 删除分数低于 60 的元素 |
| ZDIFF numkeys key key ... | 求差集 | ZDIFF 2 zset1 zset2 | 返回在 zset1 中但不在 zset2 中的元素,numkeys 指定参与运算的集合数量 |
| ZINTER numkeys key key ... | 求交集 | ZINTER 2 zset1 zset2 | 返回同时在 zset1 和 zset2 中的元素 |
| ZUNION numkeys key key ... | 求并集 | ZUNION 2 zset1 zset2 | 返回 zset1 和 zset2 中所有元素的并集 |
bash
# 添加排行榜数据
127.0.0.1:6379> ZADD leaderboard 9500 "player1" 8800 "player2" 9200 "player3" 8900 "player4" 9100 "player5"
(integer) 5
# 获取元素分数
127.0.0.1:6379> ZSCORE leaderboard "player1"
"9500"
# 获取排名(倒序,分数高排前)
127.0.0.1:6379> ZREVRANK leaderboard "player3"
(integer) 2 # 第 3 名
# 获取正序排名(分数低排前)
127.0.0.1:6379> ZRANK leaderboard "player1"
(integer) 4 # 第 5 名(分数最高)
# 获取 Top 3(倒序)
127.0.0.1:6379> ZREVRANGE leaderboard 0 2 WITHSCORES
1) "player1"
2) "9500"
3) "player3"
4) "9200"
5) "player5"
6) "9100"
# 获取全部正序(分数从低到高)
127.0.0.1:6379> ZRANGE leaderboard 0 -1 WITHSCORES
1) "player2"
2) "8800"
3) "player4"
4) "8900"
5) "player5"
6) "9100"
7) "player3"
8) "9200"
9) "player1"
10) "9500"
# 增加分数
127.0.0.1:6379> ZINCRBY leaderboard 300 "player2"
"9100"
# 按分数范围查询
127.0.0.1:6379> ZRANGEBYSCORE leaderboard 9000 9500 WITHSCORES
1) "player2"
2) "9100"
3) "player5"
4) "9100"
5) "player3"
6) "9200"
7) "player1"
8) "9500"
# 统计分数范围
127.0.0.1:6379> ZCOUNT leaderboard 9000 9500
(integer) 4
# 获取元素个数
127.0.0.1:6379> ZCARD leaderboard
(integer) 5
# 删除排名最低的 2 个
127.0.0.1:6379> ZREMRANGEBYRANK leaderboard 0 1
(integer) 2
127.0.0.1:6379> ZRANGE leaderboard 0 -1
1) "player5"
2) "player3"
3) "player1"
# 删除元素
127.0.0.1:6379> ZREM leaderboard "player5"
(integer) 1所有的排序默认是升序的,要想降序,需要在Z后添加REV,例如ZREVRANK 获取倒序排名(从高到低)
三、JAVA客户端
Redis 官方和社区提供了多种 Java 客户端,常见的有 Jedis、Lettuce 和 Redisson。Spring Boot 默认集成的是 Spring Data Redis,它底层封装了 Jedis 和 Lettuce,提供统一的 RedisTemplate API。
1.Jedis
Jedis 是 Redis 官方推荐的 Java 客户端,API 命名与 Redis 命令完全一致,学习成本极低。但其连接是线程不安全的,多线程环境必须配合连接池使用。
(1)Jedis的使用
①引入依赖
html
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>7.1.0</version>
</dependency>② 建立连接、执行命令、释放连接
java
package com.test;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
public class JedisText {
private Jedis jedis;
@BeforeEach
void setUp() {
//建立连接
jedis = new Jedis("127.0.0.1",6379);
//设置密码
jedis.auth("123456");
//选择库
jedis.select(0);
}
@Test
void textString(){
//插入数据,方法名称就是redis命令名称,非常简单
String result = jedis.set("name","张三");
System.out.println("result=" + result);
//获取数据
String name = jedis.get("name");
System.out.println("name =" + name);
}
@AfterEach
void tearDown() {
//释放资源
if (jedis!=null);
jedis.close();
}
}(2)Jedis连接池
Jedis 连接对象是线程不安全的,每次 new Jedis() 都会建立新的 TCP 连接,高并发下会耗尽系统资源。因此生产环境必须使用 JedisPool 连接池。
① 连接池工具类
java
package com.Jedis.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//最大连接
jedisPoolConfig.setMaxTotal(8);
//最大空闲连接
jedisPoolConfig.setMaxIdle(8);
//最小空闲连接
jedisPoolConfig.setMinIdle(0);
//设置最长等待时间, ms
jedisPoolConfig.setMaxWaitMillis(200);
//创建连接池对象
jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379, 1000, "123456");
}
//获取Jedis对象
public static Jedis getJedis() {
return jedisPool.getResource();
}
}② 使用连接池改造测试类
java
public class JedisText {
private Jedis jedis;
@BeforeEach
void setUp() {
jedis = JedisConnectionFactory.getJedis();
}
@Test
void textString(){...}
@AfterEach
void tearDown() {jedis.close();}
}从 JedisPool 获取的连接,其 close() 方法已被重写为归还连接池,而非真正关闭 Socket。这是连接池能够复用的核心
2.Spring Data Redis
Spring Data Redis 是 Spring 生态中对 Redis 的整合方案,它抽象了底层客户端(Jedis / Lettuce),提供统一的 RedisTemplate API,并解决了序列化、连接管理、集群支持、发布订阅等一系列生产级问题。
Spring Data Redis 的核心特性:
- 对 Jedis 和 Lettuce 的无缝切换(默认 Lettuce)
- 提供 RedisTemplate 统一操作 API
- 支持 Redis 哨兵、集群模式
- 支持发布订阅、Stream、Geo 等高级功能
- 支持多种序列化方式(JDK、JSON、String、二进制)
- 支持基于 Lettuce 的响应式编程(ReactiveRedisTemplate)
(1)RedisTemplate 快速入门
① 引入依赖
html
<!-- Spring Data Redis(默认使用 Lettuce 客户端) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池依赖(Lettuce 默认使用 commons-pool2) -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>② 配置文件(application.yml)
yml
spring:
data:
redis:
host: 127.0.0.1
port: 6379
password: 123456
database: 0
lettuce:
pool:
max-active: 8 # 最大连接数
max-idle: 8 # 最大空闲连接
min-idle: 0 # 最小空闲连接
max-wait: 200ms # 获取连接最大等待时间③注入 RedisTemplate 并操作数据
| API | 返回值类型 | 说明 |
|---|---|---|
| redisTemplate.opsForValue() | ValueOperations | 操作 String类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作Hash类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作List类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作 Set 类型数据 |
| redisTemplate.opsForZSet() | ZSetOperations | 操作 SortedSet 类型数据 |
| redisTemplate | 通用的命令 |
java
@SpringBootTest
class SpringRedisStudysApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}默认 JDK 序列化的问题
运行上面的测试代码后,去 Redis 客户端查看 Key:

会发现 Key 不是 "name",而是一串乱码。这是因为 RedisTemplate 默认使用 JDK 序列化器,会将 Java 对象序列化为字节数组存储。
这样的Redis客户端可读性差、兼容性差(非 Java 程序无法反序列化)、体积大、安全性低。
(2)自定义RedisTemplate
Key 用 String,Value 用 JSON
针对默认JDK序列化带来的问题,生产环境可以自定义序列化类,将序列化器改为 StringRedisSerializer(用于 Key)和 Jackson2JsonRedisSerializer(用于 Value)。
如下代码所示,Spring Boot 默认会创建一个 RedisTemplate<Object, Object> Bean
java
package com.example.demo.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}
java
@Autowired
private RedisTemplate<String,Object> redisTemplate; 此时在 RDM 中使用JSON风格可以查看中文

@class 冗余问题
当使用自定义 RedisTemplate 存入一个自定义对象时
java
package com.example.demo.redis.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.AllArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private Integer age;
}
java
@Test
void testSaveUser() {
// 写入数据
redisTemplate.opsForValue().set("user:100", new User("虎哥",12));
// 获取数据
User o = (User) redisTemplate.opsForValue().get("user:100");
System.out.println("o = " + o);
}在 RDM 中会发现,存入的 JSON 里多了一个 @class 字段

这个 @class 是 GenericJackson2JsonRedisSerializer 自动附加的全限定类名 ,用于反序列化时知道该把 JSON 还原成哪个 Java 类型。但这也带来了问题:
- 浪费存储空间:类名往往比数据本身还长。
- 耦合项目结构:类名包含具体包路径,一旦重构类名或包名,历史数据全部作废。
为了节省内存空间,我们并不会使用JsoN序列化器来处理value,而是统一使用String序列化器,要求只能存储String
类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
(3)StringRedisTemplate
Key 是纯字符串,Value 也只能是字符串
为了解决上述 @class 冗余问题,Spring 官方早已内置了一个更纯净的模板类StringRedisTemplate,省去了我们自定义 RedisTemplate 的过程。StringRedisTemplate 继承自 RedisTemplate<String, String>,它的 Key 和 Value 都默认使用 StringRedisSerializer,即:
- Key 是纯字符串
- Value 也只能是字符串
但是对于对象来说,则需要先把 Java 对象手动转成 JSON 字符串,把 JSON 字符串写入 Redis,读取时再手动把 JSON 字符串转回 Java 对象(整个过程可以用 Jackson 的 ObjectMapper 完成)
java
@SpringBootTest
public class SpringRedisTemplateTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testString() {
// 写入一条String数据
stringRedisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
@Test
void testSaveUser() throws JsonProcessingException {
// 创建对象
User user = new User("虎哥", 21);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入数据
stringRedisTemplate.opsForValue().set("user:300", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:300");
// 手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println("user1 = " + user1);
}
}这样存入 Redis 的数据就是这样干净的 JSON

StringRedisTemplate操作Hash值
java
@Test
void testHash() {
stringRedisTemplate.opsForHash().put("user:400", "name", "虎哥");
stringRedisTemplate.opsForHash().put("user:400", "age", "21");
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");
System.out.println("entries = " + entries);
}