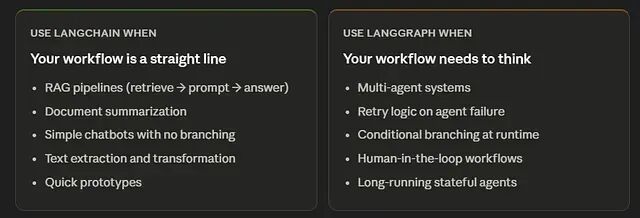
现在介绍LangGraph 和 LangChain 的文章。每一篇的结论都差不多:简单流程用 LangChain,复杂的用 LangGraph。
但是简单和复杂都是相对的,如果是具体问题呢,比如说一个做代码分析、三个 Agent 串起来的流水线,到底该拿哪一个上线?
所以本文用同一个需求分别用两个框架实现,Agent、逻辑、Gemini 2.5 Flash 调用全部一致,一遍 LangChain,一遍 LangGraph。
两个框架到底在做什么
LangChain 是一个模块化工具包,提供 prompt 模板、文档加载器、retriever、输出解析器、memory 抽象这些零件,再把它们按线性顺序 A → B → C 串起来。像一条传送带:定义步骤,数据往前流,结束。
LangGraph 是一层编排。它把工作流建模成状态机 ------ 节点是函数,边是转换 ------ 而边可以是条件的。流水线可以循环、分支、重试,也能暂停等待人工输入。就是一张流程图。
不过从 LangChain v1.0(2025)开始,LangChain 自己的 Agent 抽象就是建在 LangGraph 之上的。所以这两个不是两个互相竞争的框架,而是同一个系统不同的抽象层级。
实验:同一条流水线,两个框架
测试用例是一条三阶段的代码审查流水线:
- Context agent ------ 抓 PR diff 和仓库历史
- Analysis agent ------ 在改动代码中定位问题
- Review agent ------ 输出带严重程度评分的结构化反馈
BugLens 线上的 analysis agent 有时需要回头再去拉一轮 context 才能给出有把握的判断。正是这个条件回跳把我逼到了决策点。
LangChain 版本
from langchain_core.prompts import ChatPromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.output_parsers import StrOutputParser
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash")
context_chain = (
ChatPromptTemplate.from_template("Analyze this PR diff: {diff}")
| llm
| StrOutputParser()
)
analysis_chain = (
ChatPromptTemplate.from_template("Find issues in: {context}")
| llm
| StrOutputParser()
)
review_chain = (
ChatPromptTemplate.from_template("Write review for: {analysis}")
| llm
| StrOutputParser()
)
# 线性执行
def run_pipeline(diff: str):
context = context_chain.invoke({"diff": diff})
analysis = analysis_chain.invoke({"context": context})
review = review_chain.invoke({"analysis": analysis})
return review干净、可读,五分钟能写完。问题在于:analysis 返回的置信度一旦偏低,整条链就会有问题 ------ 得在链外面加 if/else,手动 re-invoke,再自己把状态拼回去。
LangGraph 版本
from langgraph.graph import StateGraph, END
from typing import TypedDict
class ReviewState(TypedDict):
diff: str
context: str
analysis: str
review: str
confidence: float
iterations: int
def context_node(state: ReviewState) -> ReviewState:
# 根据 diff 和仓库历史获取 context
context = fetch_context(state["diff"])
return {**state, "context": context}
def analysis_node(state: ReviewState) -> ReviewState:
result = run_analysis(state["context"])
return {
**state,
"analysis": result["content"],
"confidence": result["confidence"],
"iterations": state.get("iterations", 0) + 1
}
def review_node(state: ReviewState) -> ReviewState:
review = write_review(state["analysis"])
return {**state, "review": review}
def should_loop(state: ReviewState) -> str:
# 置信度低则回头再取一轮 context
if state["confidence"] < 0.75 and state["iterations"] < 3:
return "fetch_more_context"
return "write_review"
graph = StateGraph(ReviewState)
graph.add_node("get_context", context_node)
graph.add_node("analyze", analysis_node)
graph.add_node("review", review_node)
graph.set_entry_point("get_context")
graph.add_edge("get_context", "analyze")
graph.add_conditional_edges("analyze", should_loop, {
"fetch_more_context": "get_context",
"write_review": "review"
})
graph.add_edge("review", END)
pipeline = graph.compile()前置代码多了不少,但是置信度阈值触发自动回跳;状态在节点之间自动流转,不用人工维护;后续要加 human-in-the-loop 审核时,一行
interrupt()就够了 ------ LangGraph 原生支持。
LangChain 依然占优的场景
LangChain 的 pipe 语法
chain1 | chain2 | chain3用在线性流程上是真的漂亮。BugLens 里不需要分支的那些环节我还是用它:总结单个文件、从 diff 里抽结构化数据、给最终输出做格式化。不该分支的地方没必要背上 LangGraph 的开销。
更现实的一点是生态:LangChain 有 600+ 开箱即用的集成。要快速接一个向量库、PDF 加载器、外部 API,这套生态目前没有对手。LangGraph 并不是要替代它们,而是叠在上面。
反转:LangChain 1.0 内部跑的就是 LangGraph
大多数对比文章漏掉了这一条:从 LangChain v1.0 起,
AgentExecutor事实上已经废弃,LangChain 新的 Agent 抽象在底层直接构建在 LangGraph 上。
现在调用
create_react_agent(),跑的就是 LangGraph 状态机。真正的问题不是 LangChain 还是 LangGraph,而是想要 LangChain 那层更高的封装,还是想直接控制这张图。
先用 LangChain 的高层 API;撞到墙(循环、重试、条件分支、持久化)再往下落到 LangGraph。二者可以共存,不少生产系统同时用两套。
决策框架
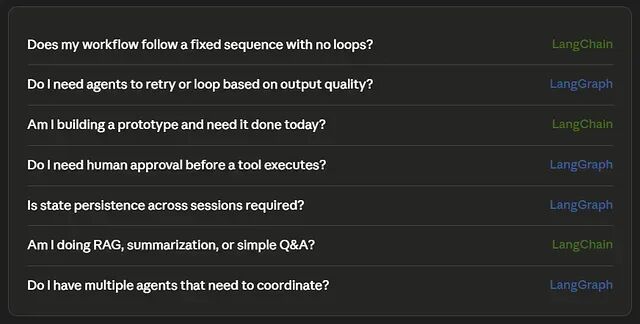
其实可以两个都用。外层编排 ------ GitHub webhook 事件路由、决定调用哪条 Agent 流水线、API 失败后的重试管理 ------ 全部走 LangGraph;内层链 ------ 格式化 diff、总结文件、解析结构化输出 ------ 交给 LangChain LCEL。
总结
构建一条简单的 RAG 流水线或单步 LLM 工作流,LangChain 更快也更干净,没必要让 LangGraph 把复杂度压上去。
一旦涉及到多 Agent、条件逻辑、重试行为或需要持久化的状态,LangGraph 就不只是"更好"而已,它是唯一的选项;想在纯 LangChain 里复刻这套控制流,最后拼出来的正是 LangGraph 被造出来要替掉的那种缝合式状态管理。
https://avoid.overfit.cn/post/ecb8b4a277b0443ea312fe4c100aead6
by Satyabrata Mohanty