
🎁个人主页:User_芊芊君子
🎉欢迎大家点赞👍评论📝收藏⭐文章
🔍系列专栏:AI


文章目录:
- 【前言】
-
- 一、时序数据库的技术背景与核心挑战
-
- [1.1 什么是时序数据库](#1.1 什么是时序数据库)
- [1.2 核心技术挑战](#1.2 核心技术挑战)
- 二、主流时序数据库的技术架构对比
-
- [2.1 架构范式对比](#2.1 架构范式对比)
- [2.2 存储引擎的设计差异](#2.2 存储引擎的设计差异)
- [2.3 查询能力的对比](#2.3 查询能力的对比)
- [三、Apache IoTDB 的核心技术特性](#三、Apache IoTDB 的核心技术特性)
-
- [3.1 树形数据模型](#3.1 树形数据模型)
- [3.2 高性能写入与压缩](#3.2 高性能写入与压缩)
- [3.3 原生分布式架构](#3.3 原生分布式架构)
- [3.4 边云协同方案](#3.4 边云协同方案)
- 四、选型建议与实践参考
-
- [4.1 场景化选型决策流程](#4.1 场景化选型决策流程)
- [4.2 性能测试参考](#4.2 性能测试参考)
- [4.3 与大数据生态的集成](#4.3 与大数据生态的集成)
- 五、总结
【前言】
在工业物联网和大数据技术深度融合的背景下,时序数据库作为支撑海量设备数据采集、存储与分析的核心基础设施,其选型直接影响系统整体的性能上限与工程复杂度。本文从时序数据库的架构演进出发,结合实际技术指标和落地经验,对主流开源方案进行对比分析,并重点探讨 Apache IoTDB 在不同场景下的技术表现。
一、时序数据库的技术背景与核心挑战

1.1 什么是时序数据库
时序数据库(Time-Series Database, TSDB)是专门针对带有时间戳的数据进行优化的数据库管理系统。与关系型数据库不同,时序数据库在设计上针对以下特征进行了深度优化:
- 写入密集型:数据以极高的频率持续写入,读取通常是批量或聚合查询
- 时间有序性:数据天然按时间排列,时间是最核心的索引维度
- 数据生命周期管理:热数据、温数据、冷数据的自动分层与过期清理
- 多维聚合查询:按时间窗口进行降采样、聚合统计是高频操作
根据 DB-Engines 的数据库流行度排名,时序数据库是近年来增长最快的数据库品类之一,反映出行业需求的快速增长。
1.2 核心技术挑战
在实际的工业物联网和运维监控场景中,时序数据库面临的技术挑战可以归纳为以下几点:
┌─────────────────────────────────────────────────────┐
│ 时序数据库核心技术挑战 │
├──────────────┬──────────────────────────────────────┤
│ 写入吞吐 │ 百万级测点并发写入,要求稳定低延迟 │
│ 存储压缩 │ TB级日增量数据,需要高压缩比降低成本 │
│ 查询性能 │ 跨测点聚合查询,时间窗口扫描效率 │
│ 集群扩展 │ 水平扩展能力,数据分片与负载均衡 │
│ 边云协同 │ 边缘端轻量部署,数据同步到云端 │
└──────────────┴──────────────────────────────────────┘这些挑战不是孤立的。例如,高压缩比可以降低 I/O 压力从而间接提升查询性能,而合理的数据分片策略则同时影响写入吞吐和查询效率。因此,时序数据库的选型需要综合评估多个维度的技术指标。
二、主流时序数据库的技术架构对比
当前开源时序数据库领域中,具有代表性的方案包括 InfluxDB、TimescaleDB、Prometheus 以及 Apache IoTDB。本节从架构设计的角度进行对比分析。
企业版官网链接:https://timecho.com
官方下载链接:https://iotdb.apache.org/zh/Download/
2.1 架构范式对比
不同的时序数据库采用了不同的底层架构范式,这决定了它们在不同场景下的技术边界:
| 维度 | InfluxDB | TimescaleDB | Prometheus | Apache IoTDB |
|---|---|---|---|---|
| 底层引擎 | 自研 TSM 引擎 | PostgreSQL 扩展 | 自研存储 | 自研 TsFile |
| 数据模型 | Line Protocol | 关系型表 | 指标-标签 | 树形层次结构 |
| 集群方案 | 企业版闭源 | 依赖 PG 集群 | 联邦查询 | 原生分布式 |
| 查询语言 | Flux / InfluxQL | SQL | PromQL | SQL 兼容 |
| 边缘部署 | 较重 | 较重 | Agent 模式 | 轻量级独立部署 |
2.2 存储引擎的设计差异
存储引擎是时序数据库的核心,直接决定写入性能和压缩效率。
InfluxDB 采用自研的 TSM (Time-Structured Merge Tree) 引擎,其设计思想源自 LSM-Tree,通过将写入操作先进入内存,再批量刷盘合并,实现高吞吐写入。但 TSM 引擎在处理**高基数(High Cardinality)**场景时存在性能瓶颈,这与其索引结构的设计有关。
TimescaleDB 基于 PostgreSQL 的存储扩展,将时序数据存储在自动分区的大表中(称为 hypertable)。其优势在于继承了 PostgreSQL 完善的 SQL 支持和丰富的生态,但在极端写入吞吐场景下,关系型引擎的事务开销成为瓶颈。
Apache IoTDB 自研了 TsFile 存储格式,采用列式存储与多级编码压缩。TsFile 的一个设计特点是数据按设备和时间双维度组织,天然适配物联网场景中"每个设备独立采集、时间连续"的数据分布特征。
以下展示了 TsFile 的内部数据组织结构:
TsFile 结构示意
├── TsFileMetaData (文件级元数据)
│ ├── DeviceMetaDataIndex (设备索引)
│ │ ├── DeviceA
│ │ │ ├── Measurement: temperature
│ │ │ └── Measurement: humidity
│ │ └── DeviceB
│ │ ├── Measurement: temperature
│ │ └── Measurement: pressure
│ └── TimeseriesMetaData (时间序列元数据)
├── ChunkGroup (设备级数据块)
│ ├── Chunk (temperature 列)
│ │ ├── Page 1: [time, value] 编码数据
│ │ └── Page 2: [time, value] 编码数据
│ └── Chunk (humidity 列)
│ └── Page 1: [time, value] 编码数据
└── File Footer (校验与统计信息)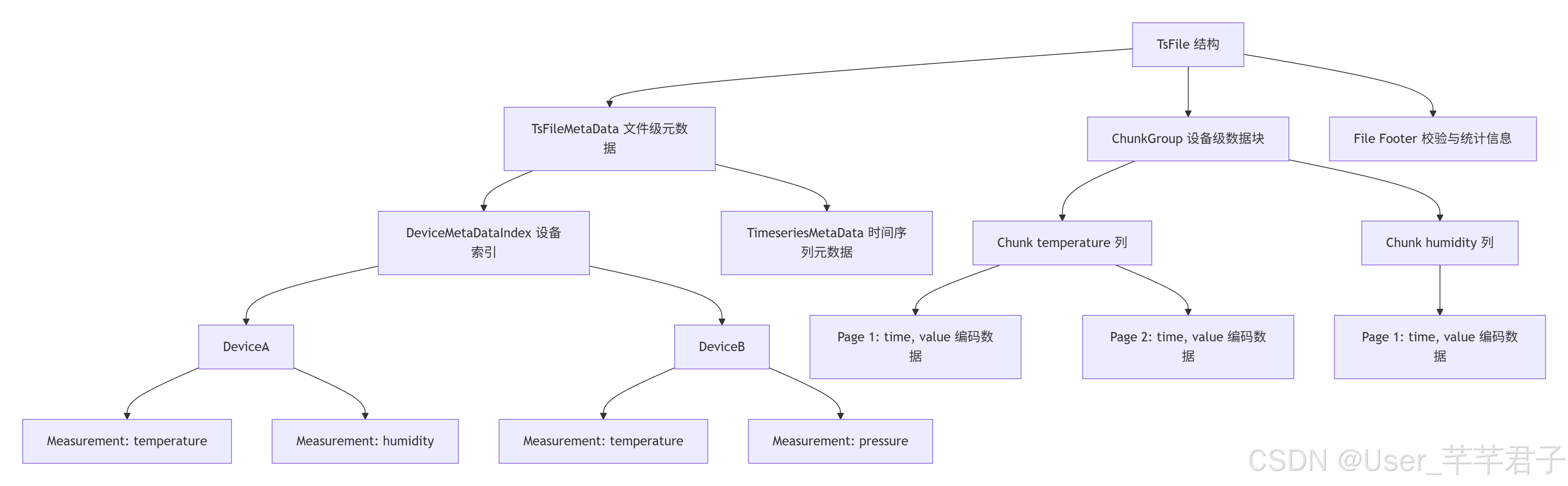
这种按设备维度聚合存储的设计,使得单设备的查询可以减少 I/O 扫描范围,在大规模设备接入场景下具有明显优势。
2.3 查询能力的对比
查询能力是开发者日常使用中感知最明显的维度。以下通过一个典型的聚合查询示例来对比不同数据库的查询方式。
假设场景:查询某工厂所有车间在过去 1 小时内每 5 分钟的平均温度。
InfluxDB(Flux 语法):
flux
from(bucket: "factory")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "temperature")
|> aggregateWindow(every: 5m, fn: mean)TimescaleDB(标准 SQL):
sql
SELECT time_bucket('5 minutes', ts) AS bucket,
workshop,
avg(temperature) AS avg_temp
FROM sensor_data
WHERE ts >= now() - INTERVAL '1 hour'
GROUP BY bucket, workshop
ORDER BY bucket;Apache IoTDB(兼容 SQL 的查询语法):
sql
SELECT avg(temperature) AS avg_temp
FROM root.factory.*.temperature
GROUP BY ([now() - 1h, now()), 5m)
ALIGN BY DEVICE;可以看到,IoTDB 的查询语法在表达多层级设备路径时更加简洁。其 root.factory.*.temperature 的路径通配符天然对应了工厂的层次结构,避免了复杂的 JOIN 操作或标签过滤。
三、Apache IoTDB 的核心技术特性
3.1 树形数据模型
IoTDB 采用树形层次结构 来组织数据模型,这种设计与工业物联网中的设备拓扑高度契合。从根节点 root 开始,逐层定义企业、工厂、产线、设备、测点的层级关系。
数据模型示意:
root
└── factory_a # 企业/集团
├── workshop_01 # 车间
│ ├── device_001 # 设备
│ │ ├── temperature
│ │ ├── humidity
│ │ └── pressure
│ └── device_002
│ ├── temperature
│ └── vibration
└── workshop_02
└── device_003
├── temperature
└── speed这种数据模型的优势在于:
- 路径即语义:数据路径本身携带了业务含义,无需额外的标签系统
- 权限控制细粒度:可以按树节点灵活配置访问权限
- 查询路径灵活 :支持通配符查询,如
root.factory_a.*.temperature即可查询所有车间的温度
3.2 高性能写入与压缩
在写入性能方面,IoTDB 通过以下技术实现了百万级测点并发写入:
批量写入 API:
java
// IoTDB Java SDK 批量写入示例
try (ISessionPool sessionPool = new SessionPool.Builder()
.host("127.0.0.1")
.port(6667)
.user("root")
.password("root")
.maxPoolSize(10)
.build()) {
// 构造 Tablet 批量写入
List<String> measurements = Arrays.asList("temperature", "humidity", "pressure");
List<TSDataType> types = Arrays.asList(
TSDataType.FLOAT, TSDataType.FLOAT, TSDataType.FLOAT);
Tablet tablet = new Tablet("root.factory_a.workshop_01.device_001",
measurements, types, 10000);
for (int i = 0; i < 10000; i++) {
int rowIndex = tablet.rowSize++;
tablet.addTimestamp(rowIndex, System.currentTimeMillis() + i);
tablet.addValue("temperature", rowIndex, 25.5f + random.nextFloat());
tablet.addValue("humidity", rowIndex, 60.0f + random.nextFloat());
tablet.addValue("pressure", rowIndex, 101.3f + random.nextFloat());
}
sessionPool.insertTablet(tablet);
}压缩编码方面,IoTDB 针对不同数据类型提供了多种编码方案:
| 数据类型 | 推荐编码 | 适用场景 |
|---|---|---|
| INT32/INT64 | GORILLA | 时间戳、变化缓慢的整数值 |
| FLOAT/DOUBLE | GORILLA | 浮点传感器数据(温度、压力等) |
| BOOLEAN | RLE | 开关量、状态量 |
| TEXT | DICTIONARY | 设备名称、告警信息 |
在实际测试中,针对典型的工业传感器数据(温度、压力、振动等),TsFile 的压缩比通常可以达到 10:1 到 20:1,显著降低了存储成本。
3.3 原生分布式架构
IoTDB 的分布式架构采用计算与存储分离的设计:
IoTDB 分布式架构
┌──────────────────────────────────────────────┐
│ Client Layer │
│ (JDBC / REST API / MQTT / OPC-UA) │
└───────────────┬──────────────────────────────┘
│
┌───────────────▼──────────────────────────────┐
│ ConfigNode (元数据管理) │
│ ┌──────────┐ ┌──────────┐ │
│ │ Leader │◄──►│ Follower │ │
│ └──────────┘ └──────────┘ │
└───────────────┬──────────────────────────────┘
│
┌───────────────▼──────────────────────────────┐
│ DataNode (数据读写节点) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │DataNode1│ │DataNode2│ │DataNode3│ │
│ │ Region-A│ │ Region-B│ │ Region-C│ │
│ └─────────┘ └─────────┘ └─────────┘ │
└──────────────────────────────────────────────┘关键设计特点:
- Region 分片:数据按时间区间和设备维度自动分片到不同的 Region,各 Region 由不同的 DataNode 管理
- 多副本容灾:每个 Region 可配置多个副本,分布在不同 DataNode 上,实现高可用
- 弹性扩缩容:新增 DataNode 后,系统自动进行 Region 迁移以均衡负载
以下是通过命令行进行集群管理的基本操作:
sql
-- 查看集群节点状态
SHOW DATANODES;
-- 查看数据分布
SHOW REGIONS;
-- 手动触发负载均衡
MOVE REGION 1 TO DATANODE 3;3.4 边云协同方案
在工业物联网场景中,边缘端的实时数据处理和云端的全量数据分析通常需要协同工作。IoTDB 提供了原生的边云数据同步能力:
java
// 边缘端配置数据同步到云端
// 边缘 IoTDB 端执行:
CREATE PIPE sync_to_cloud
WITH SINK (
'sink' = 'iotdb-thrift-sink',
'sink.ip' = 'cloud.iotdb.host',
'sink.port' = '10740',
'data.pattern' = 'root.factory_a.*'
);
-- 启动同步管道
START PIPE sync_to_cloud;
-- 查看同步状态
SHOW PIPE sync_to_cloud;边缘端可以独立运行完整的 IoTDB 实例,在本地完成实时聚合计算后,将原始数据或聚合结果同步到云端。这种架构既保证了边缘端的实时性,又实现了数据的集中管理。
四、选型建议与实践参考
4.1 场景化选型决策流程
时序数据库的选型没有银弹,需要根据具体的业务场景和技术约束来决策。以下提供一个参考性的决策流程:
时序数据库选型决策流程
[开始选型评估]
│
▼
[设备规模?]
├─ < 1万测点 ──► [是否需要复杂SQL?] ──Yes──► TimescaleDB
│ └──No──► InfluxDB
│
├─ 1万~100万 ──► [是否需要边缘部署?]
│ ├─ Yes ──► Apache IoTDB
│ └─ No ──► [团队技术栈?]
│ ├─ PG生态 ──► TimescaleDB
│ └─ 独立方案 ──► IoTDB / InfluxDB
│
└─ > 100万测点 ──► [是否需要边云协同?]
├─ Yes ──► Apache IoTDB
└─ No ──► InfluxDB (需企业版集群)4.2 性能测试参考
以下提供一个基于 IoTDB 的简单基准测试脚本,供选型阶段进行验证:
java
public class IoTDBBenchmark {
private static final int DEVICE_COUNT = 1000;
private static final int MEASUREMENT_COUNT = 10;
private static final int BATCH_SIZE = 5000;
public static void main(String[] args) throws Exception {
try (ISessionPool pool = new SessionPool.Builder()
.host("127.0.0.1").port(6667)
.user("root").password("root")
.build()) {
long totalPoints = 0;
long startTime = System.currentTimeMillis();
for (int d = 0; d < DEVICE_COUNT; d++) {
String deviceId = "root.bench.device_" + String.format("%04d", d);
Tablet tablet = buildTablet(deviceId);
pool.insertTablet(tablet);
totalPoints += tablet.rowSize;
}
long elapsed = System.currentTimeMillis() - startTime;
double throughput = totalPoints / (elapsed / 1000.0);
System.out.printf("写入总量: %,d 条%n", totalPoints);
System.out.printf("耗时: %.2f 秒%n", elapsed / 1000.0);
System.out.printf("吞吐量: %,.0f 条/秒%n", throughput);
}
}
private static Tablet buildTablet(String deviceId) {
// 构建测量点列表
List<String> measurements = new ArrayList<>();
List<TSDataType> types = new ArrayList<>();
for (int i = 0; i < MEASUREMENT_COUNT; i++) {
measurements.add("s_" + i);
types.add(TSDataType.DOUBLE);
}
Tablet tablet = new Tablet(deviceId, measurements, types, BATCH_SIZE);
long baseTime = System.currentTimeMillis();
Random rand = new Random();
for (int row = 0; row < BATCH_SIZE; row++) {
tablet.addTimestamp(row, baseTime + row);
for (int m = 0; m < MEASUREMENT_COUNT; m++) {
tablet.addValue(measurements.get(m), row, rand.nextGaussian() * 10 + 50);
}
tablet.rowSize++;
}
return tablet;
}
}在 3 节点集群(每节点 16C/64G)环境下,上述基准测试的吞吐量通常可达数百万数据点/秒,具体数值取决于硬件配置、网络条件和数据特征。
4.3 与大数据生态的集成
IoTDB 作为 Apache 顶级项目,天然具备与大数据生态的良好集成能力。以下展示通过 Spark 读取 IoTDB 数据进行离线分析的方式:
scala
// Spark 读取 IoTDB 数据示例
val df = spark.read
.format("org.apache.iotdb.spark")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.option("sql", "SELECT * FROM root.factory_a.*.temperature WHERE time >= 1714000000000")
.load()
df.createOrReplaceTempView("temperature_data")
// 使用 Spark SQL 进行复杂分析
val result = spark.sql("""
SELECT
date_trunc('hour', FROM_UNIXTIME(time / 1000)) AS hour_bucket,
avg(value) AS avg_temp,
max(value) - min(value) AS temp_range,
stddev(value) AS temp_stddev
FROM temperature_data
GROUP BY date_trunc('hour', FROM_UNIXTIME(time / 1000))
ORDER BY hour_bucket
""")
result.show()此外,IoTDB 还支持通过以下方式与大数据工具链集成:
- Flink Connector:实时流处理,支持 IoTDB 作为 Source 和 Sink
- Kafka 集成:通过 Kafka Connect 实现 IoTDB 与消息队列的数据桥接
- Grafana 插件:直接在 Grafana 中配置 IoTDB 数据源,实现可视化监控
- HDFS/Hive:TsFile 可直接存储在 HDFS 上,支持 Hive 外部表查询
五、总结
时序数据库的选型是一个需要综合权衡的技术决策。从架构层面看,不同产品在设计哲学上存在显著差异:
- InfluxDB 在 DevOps 监控和轻量级 IoT 场景中有成熟生态,但其集群版本的商业化策略和 Flux 查询语言的学习成本是需要关注的因素
- TimescaleDB 凭借 PostgreSQL 生态在需要复杂 SQL 分析的场景中占优,但面对极高写入吞吐时存在架构性瓶颈
- Apache IoTDB 在大规模工业物联网场景下展现出独特的技术优势------树形数据模型天然适配设备拓扑、TsFile 存储引擎提供高压缩比和查询性能、原生分布式架构支持弹性扩展、边云协同方案满足工业部署需求
对于正在进行时序数据库技术选型的团队,建议先明确自身的核心场景(设备规模、查询模式、部署架构),再结合各方案的特点进行 PoC 验证,通过实际测试数据驱动最终决策。