目录
[7. 理解"一切皆文件"](#7. 理解“一切皆文件”)
[8.1 什么是缓冲区](#8.1 什么是缓冲区)
[8.2 为什么要引入缓冲区机制](#8.2 为什么要引入缓冲区机制)
[8.3 缓冲类型](#8.3 缓冲类型)
[8.4 FILE](#8.4 FILE)
[8.5 进一步的分析](#8.5 进一步的分析)
[8.7 标准错误](#8.7 标准错误)
[8.7.1 现象和操作](#8.7.1 现象和操作)
7. 理解"一切皆文件"
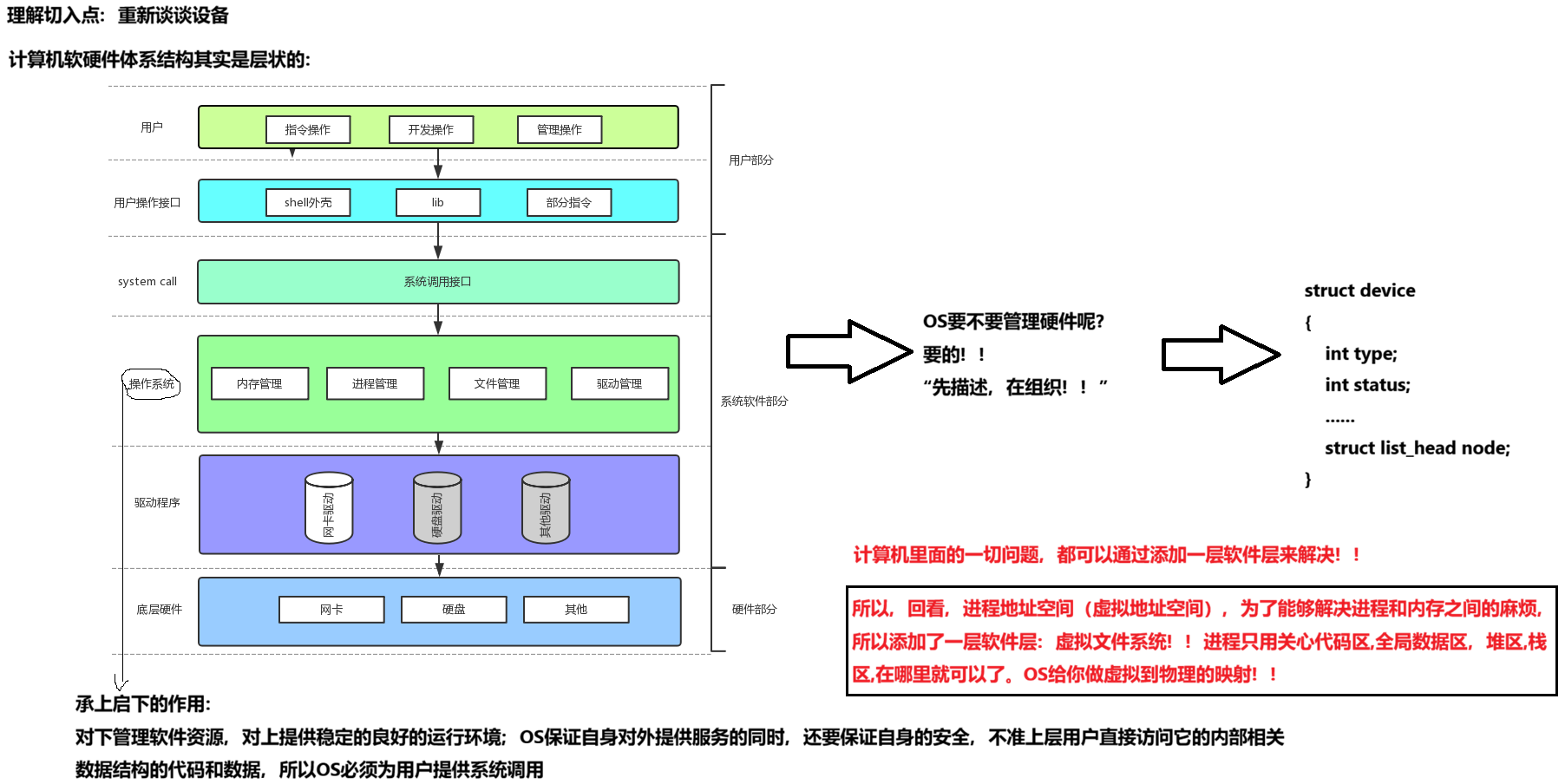
首先,在windows中式文件的东西,在Linux中也是文件;其次在一些windows中不是文件的东西,例如进程,从磁盘,显示器,键盘这样的硬件设备也被抽象成了文件,可以通过访问文件的方法访问他们获得信息;甚至管道,也是文件;后续的socket(套接字)这样的额东西,使用的接口跟文件接口也是一致的。
这样的好处是:**开发者需要一套 API 和开发工具,即可调取 Linux 系统中绝大部分的资源。****(也就是有了一套封装继承多态的体系,访问所有的方法时,使用的都是基类的所有的方法就可以完成所有设备的访问,因为基类指向不同的子类就调用子类不同的方法)**例如:Linux中几乎所有的读(读文件,读系统调用,读PIPE)的操作都可以用 read 函数来进行;几乎所有的更改(更改文件,更改系统参数,写PIPE)的操作都可以用 write 函数来进行。
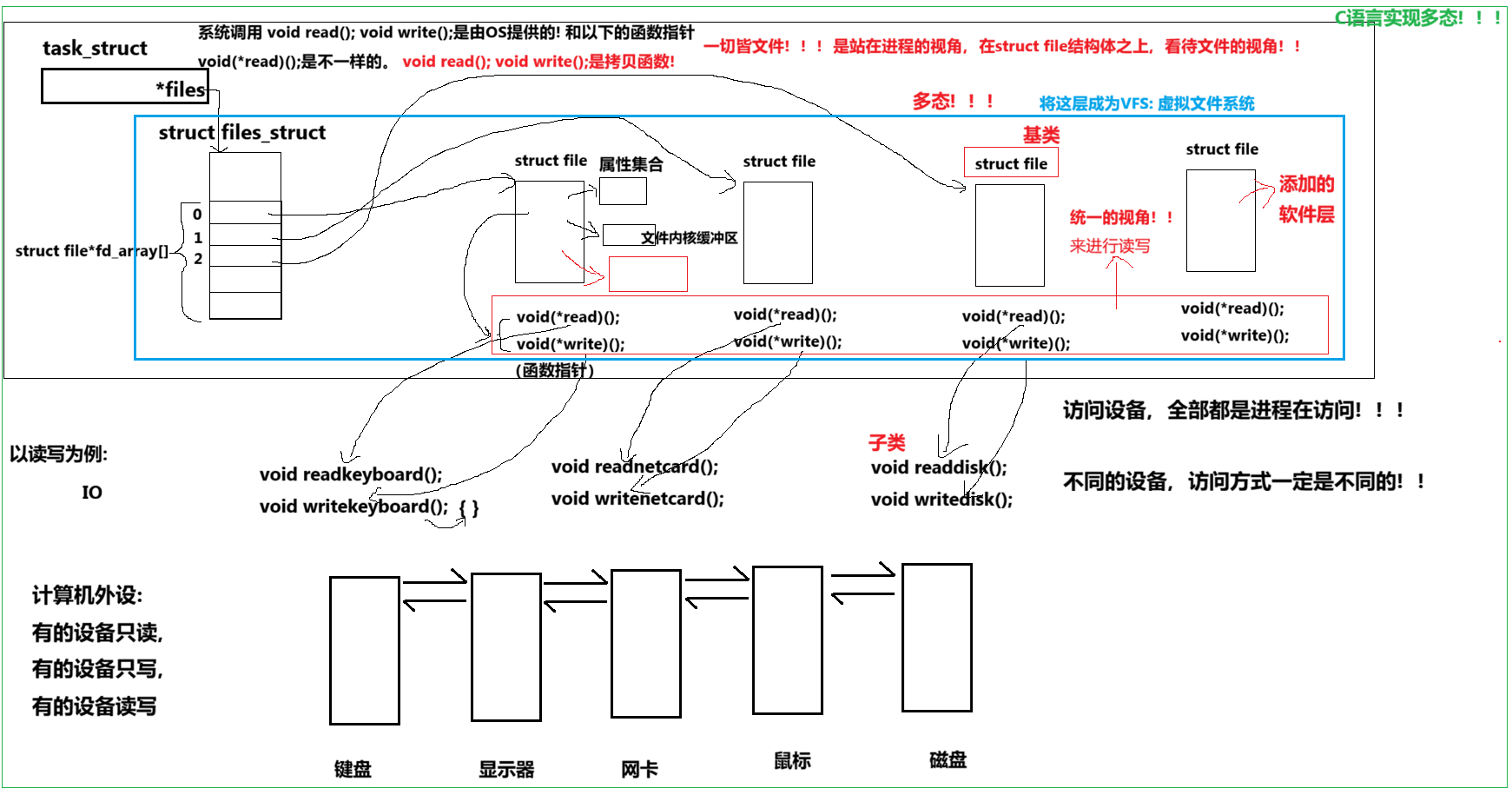

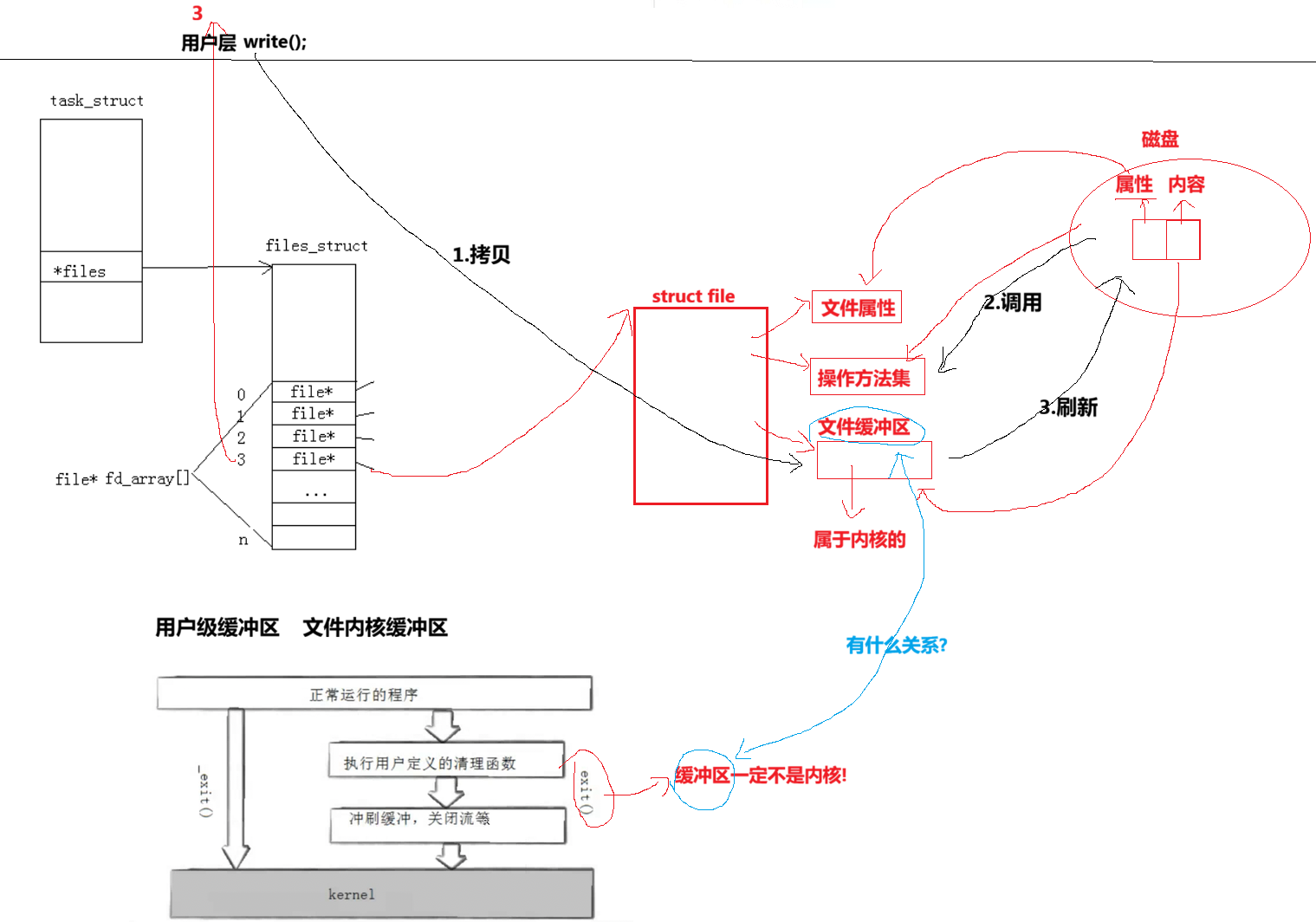
值得关注的是,struct file中 的 f_op 指针指向了一个file_operations 结构体出来,这个结构体中的成员除了 struct* owner 其余的都是**函数指针。**该结构和 stuct file 都在 fs.h下。
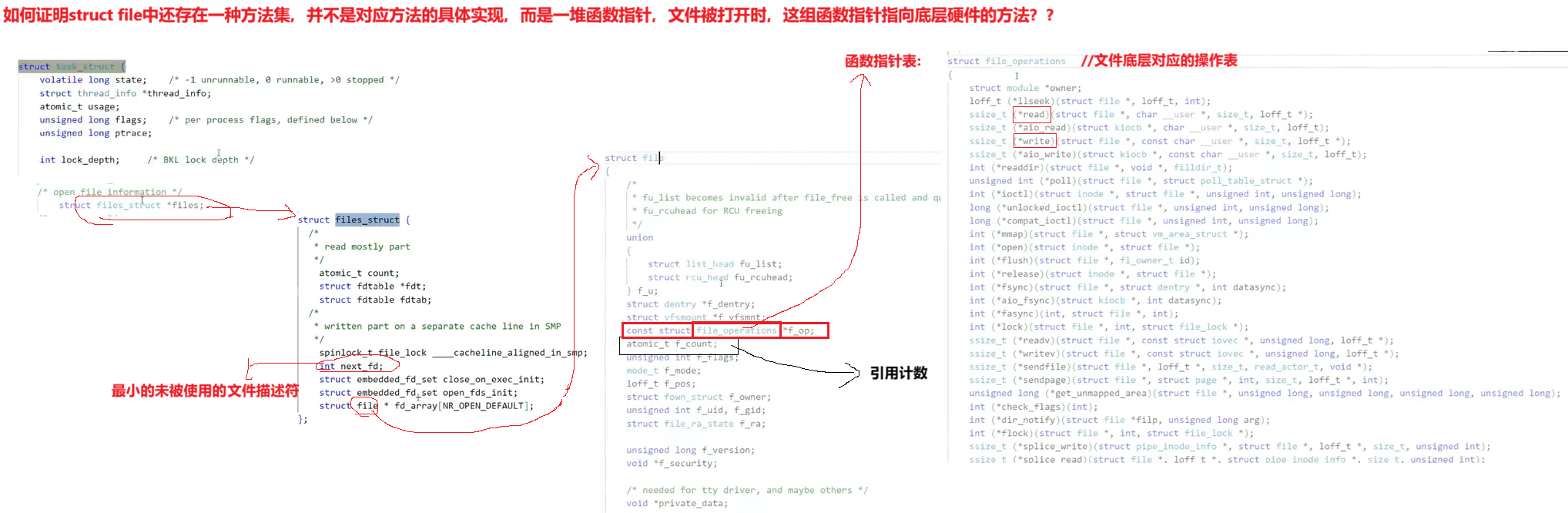
**file_operation 就是把系统调用和驱动程序关联起来的关键数据结构,**这个结构的每一个成员都对应着一个系统调用。读取 file_operation 中相应的函数指针,接着把控制权交给了函数,从而完成了Linux设被驱动程序的工作。
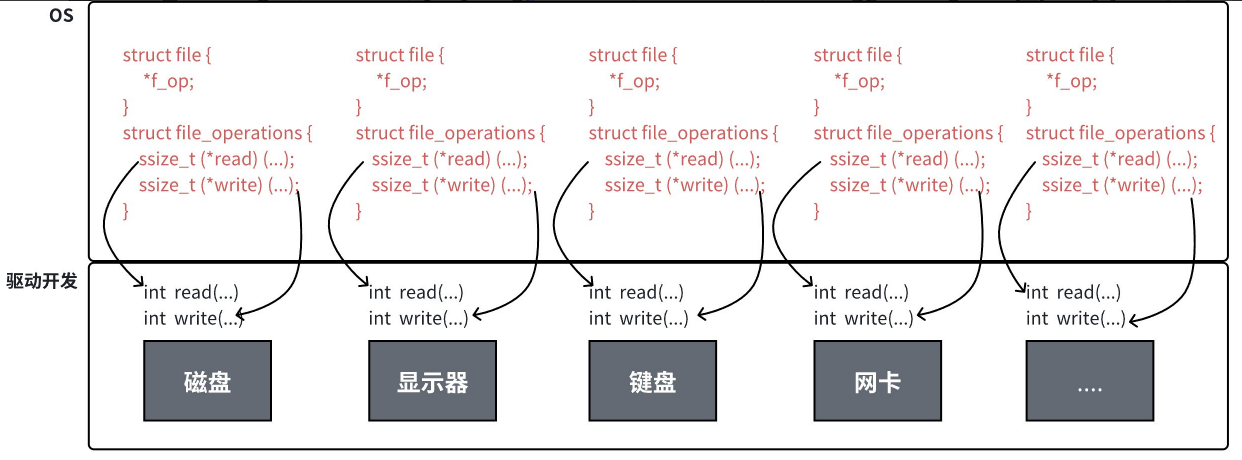
上图中的外设,每个设备都可以有自己的 read、write,但不一定对应着不同的操作方法!!但通过 stuct file 下 file_operation 中的各种函数回调,让我们开发者只用file便可调用 Linux 系统中绝大部分的资源!!这便是 "Linux下一切皆文件" 的核心理解。
所以之前我们写的进度条,将进度条写到显示器的时候,其实数据将来字符串是要写到内核当中的,写到操作系统中,OS帮忙做刷新,调用显示器所具体的方法,刷新出去。
8.缓冲区
8.1 什么是缓冲区
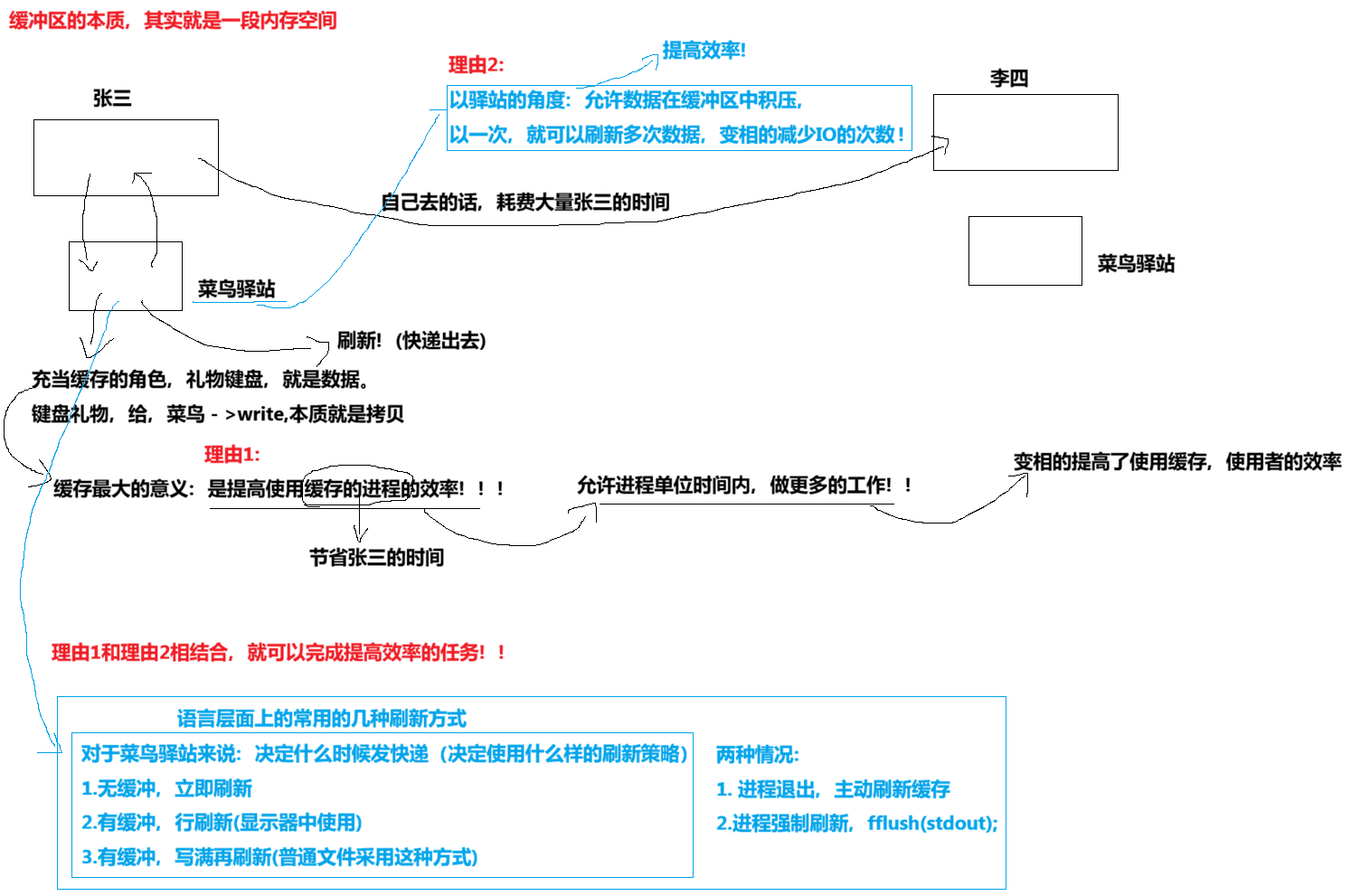
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备的还是输出设备,分为输入缓冲区和输出缓冲区。
8.2 为什么要引入缓冲区机制
- 读写文件时,如果不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),那么每次对文件进行⼀次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行⼀次系统调用,执行⼀次系统调用将涉及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
- 为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂文件进行操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运⾏速度。
- 又比如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀块内存区,它用在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和高速的CPU能够协调⼯作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率⼯作。
8.3 缓冲类型
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲方式要求填满整个缓冲区后才进⾏I/O系统调用操作。对于磁盘⽂件的操作通常使用全缓冲的方式访问。
- 行缓冲区:在行缓冲情况下,当在输⼊和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使用行缓冲方式。因为标准I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行I/O系统调用操作,默认行缓冲区的大小为1024。
- 无缓冲区:无缓冲区是指标准I/O库不对字符进⾏缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
除了上述列举的默认刷新⽅式,下列特殊情况也会引发缓冲区的刷新:
- 缓冲区满时;
- 执行flush语句;
- 进程结束
8.4 FILE
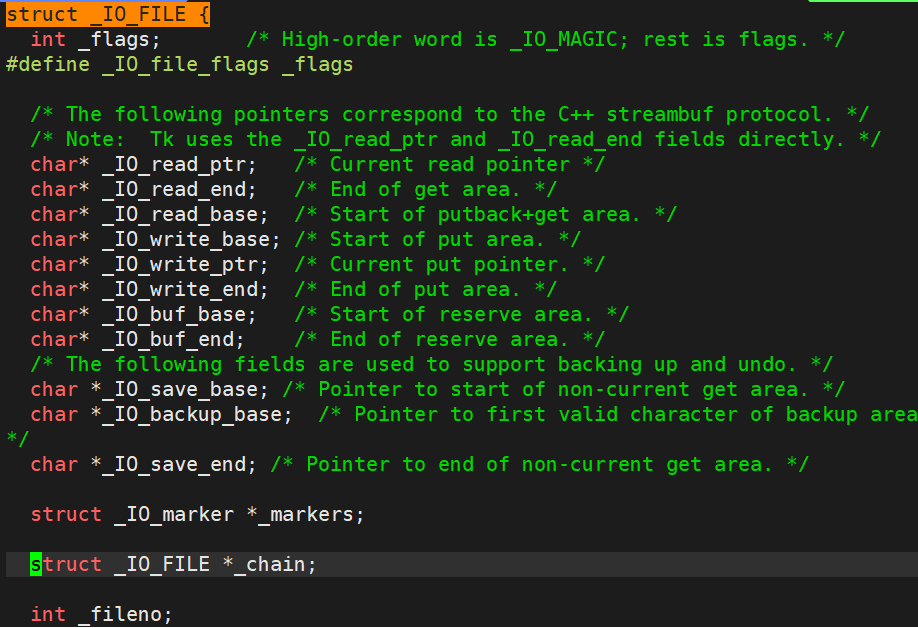
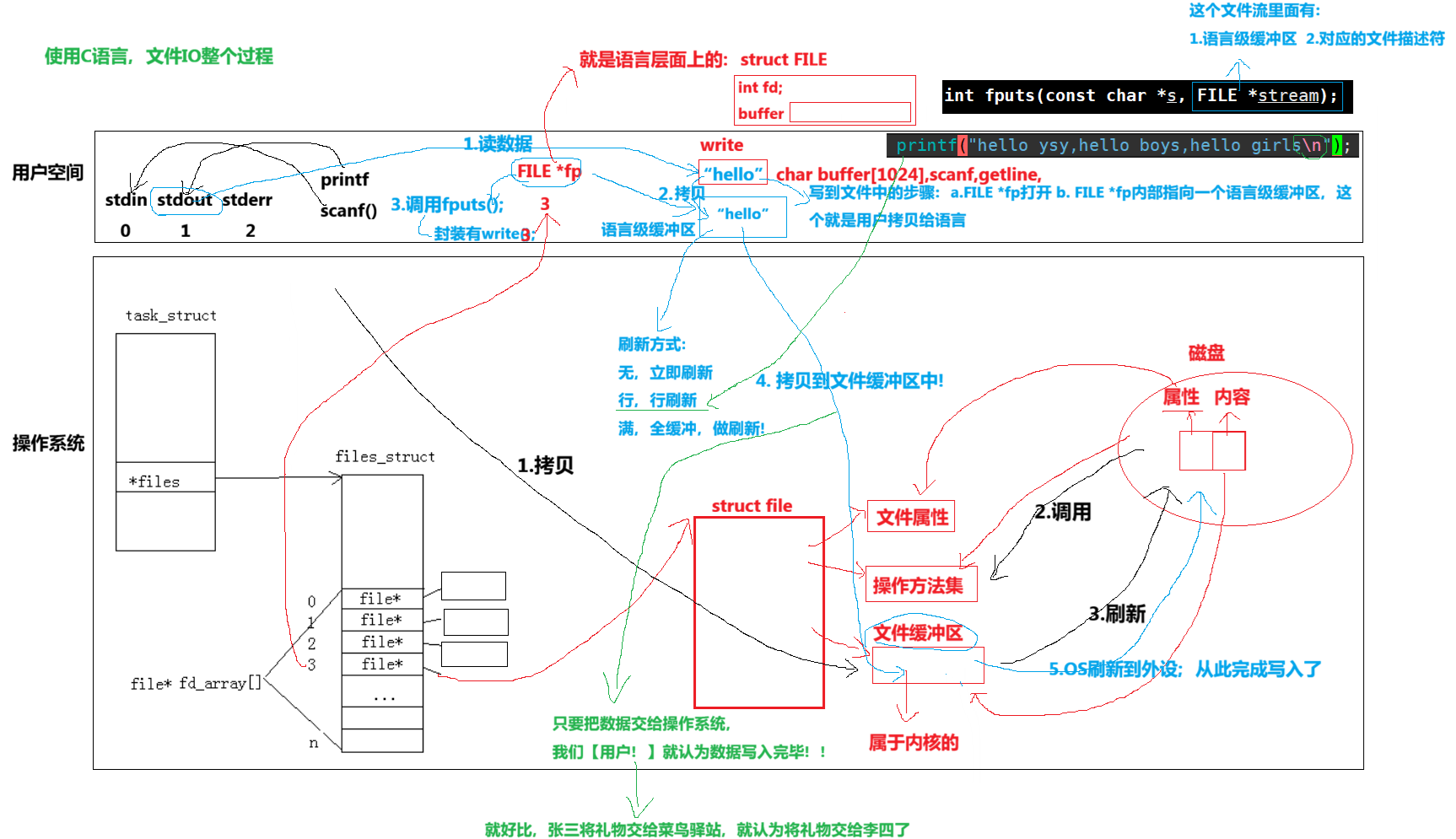
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问⽂件都是通过fd访问的。
所以C库当中的FILE结构体内部,必定封装了fd。
8.5 进一步的分析
下面的板书是对上面有关缓冲区文字描述的代码和进一步分析:
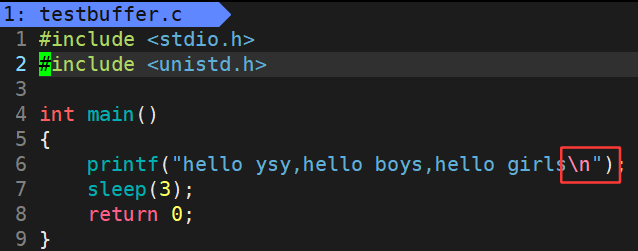
运行结果:

打印出该字符串,3秒之后该进程结束。
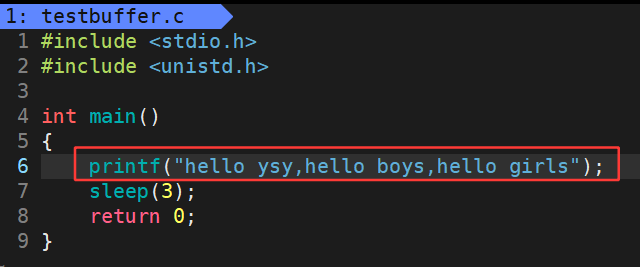
没有 '\n' 的运行结果:

字符串并没有立即显示出来,3秒之后才显示出来:

实际上是先运行的是printf,再是运行的是sleep(3)。
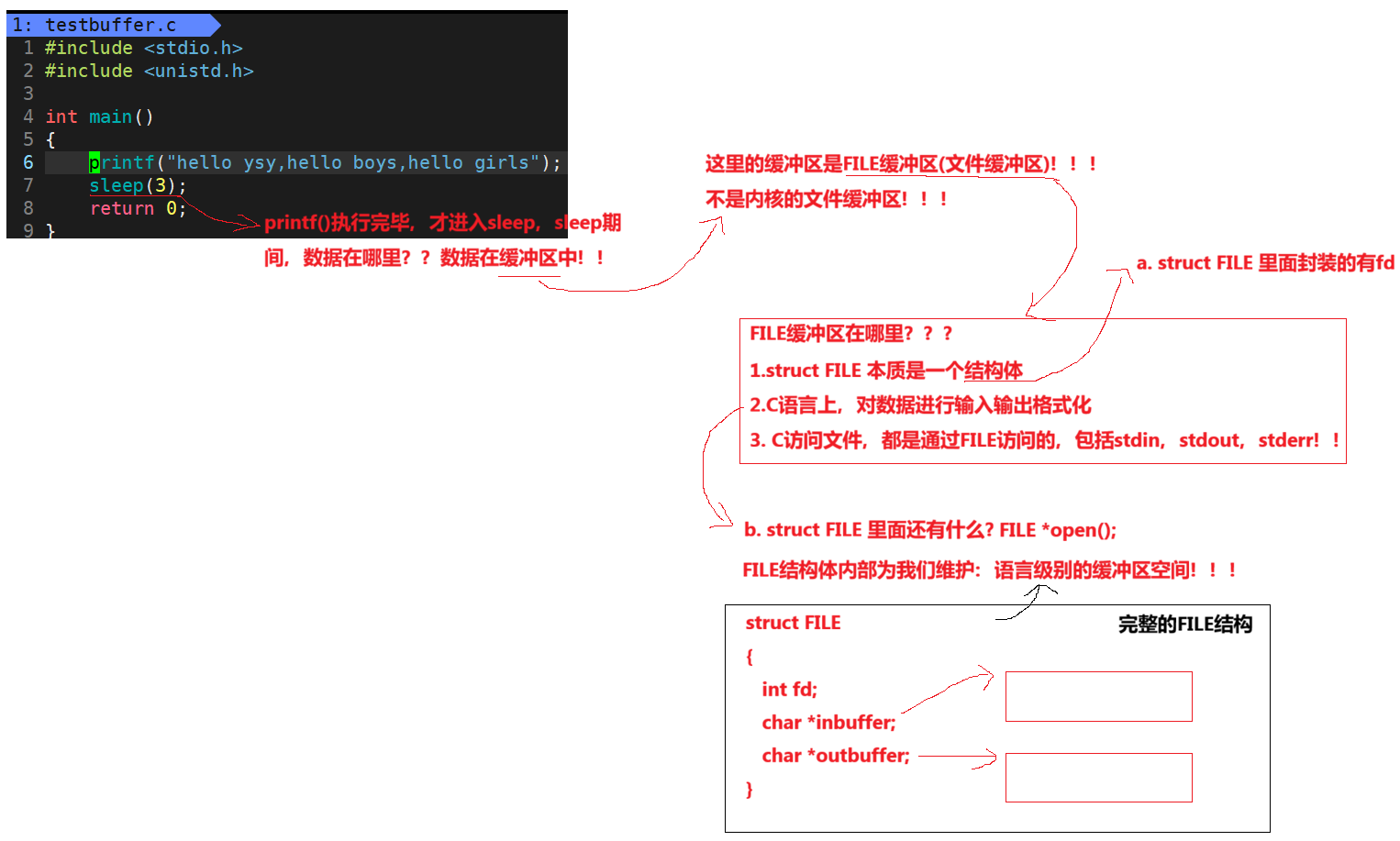
代码验证语言级别的缓冲区空间确实存在?



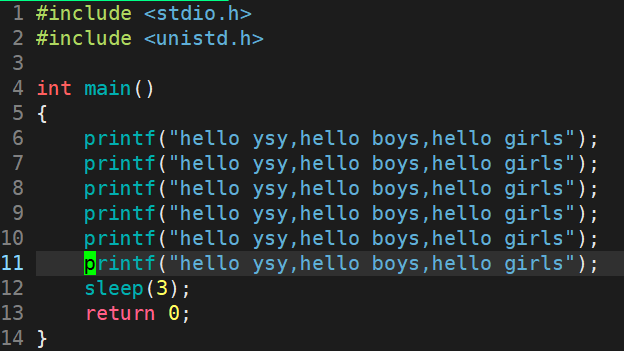
上面代码输出的结果是:
进程退出时才会打印出我们写的所有内容(struct FILE中存储的数据)

确实是sleep(3)后,进程结束时,才将数据刷新到显示器中。
这个代码好比就是菜鸟驿站,缓存缓存,缓存到一定程度时数据量够了才做刷新(但上面的代码是进程结束时才进行刷新,菜鸟驿站是达到某一定的值才进行刷新,有点小区别)。

回到之前写的代码中:
运行结果:

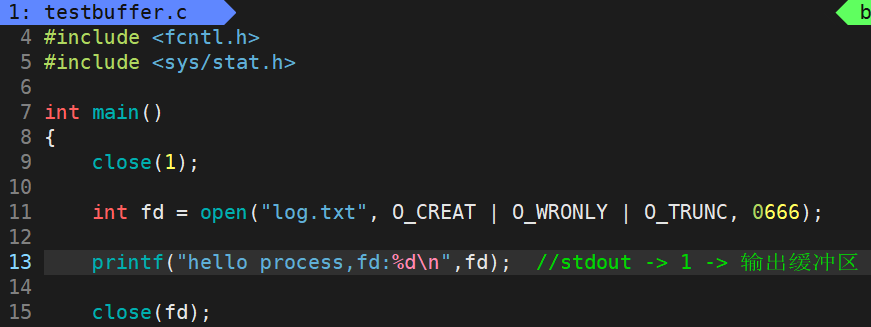
将数据存在缓冲区中,本来应该是在进程退出时进行刷新,但是close(fd);将文件关掉了,关掉了,还往哪里写呢?所以可以看到文件有,但是内容却没有。
将close(fd)注释掉:
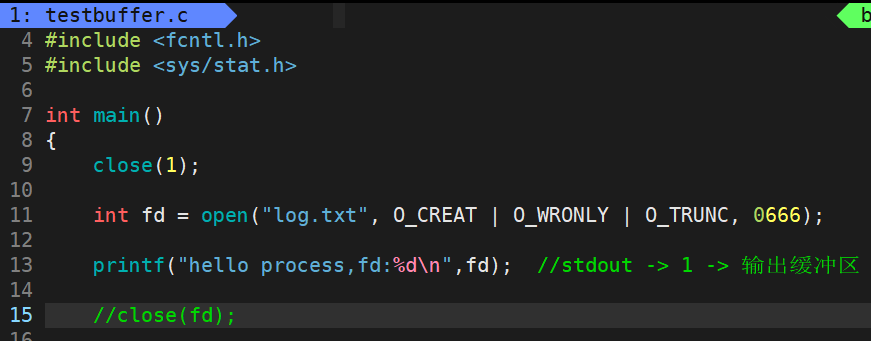
不光有,文件的内容也刷新出来了:
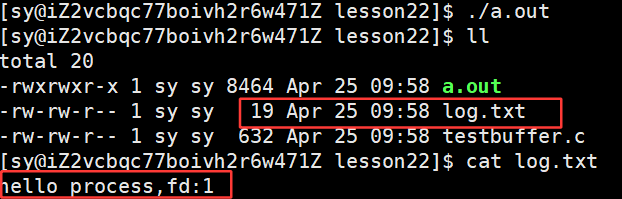
因为没有关闭文件描述符,进程结束,自动刷新。
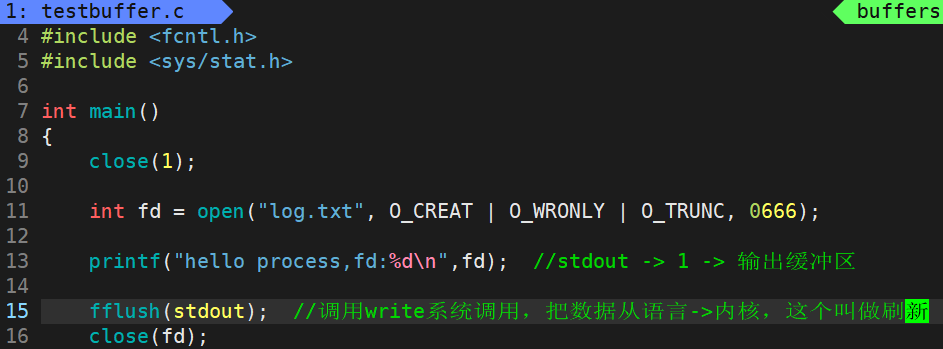

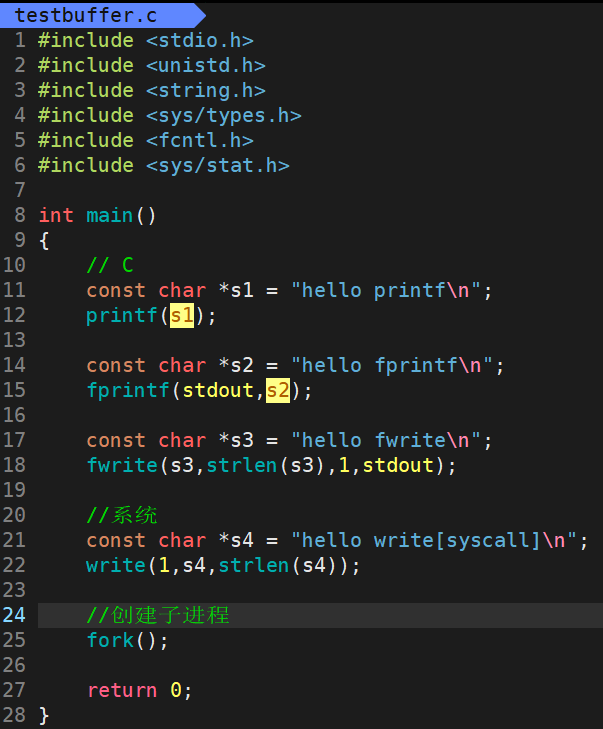
运行结果:
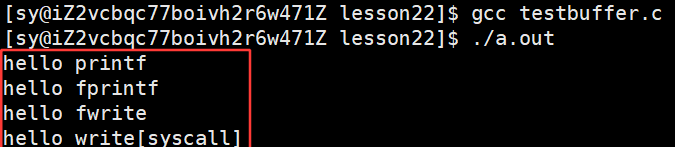
但是当我们将 log.txt 文件中的内容清空时,再次编译,将./a.out里面的内容重定向到 log.txt 时,查看 log.txt 文件内容,此时运行出的结果不一样:
这又是什么原因呢??
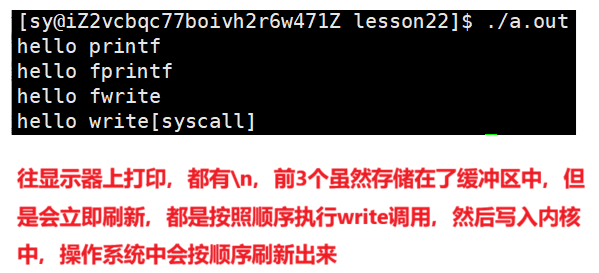
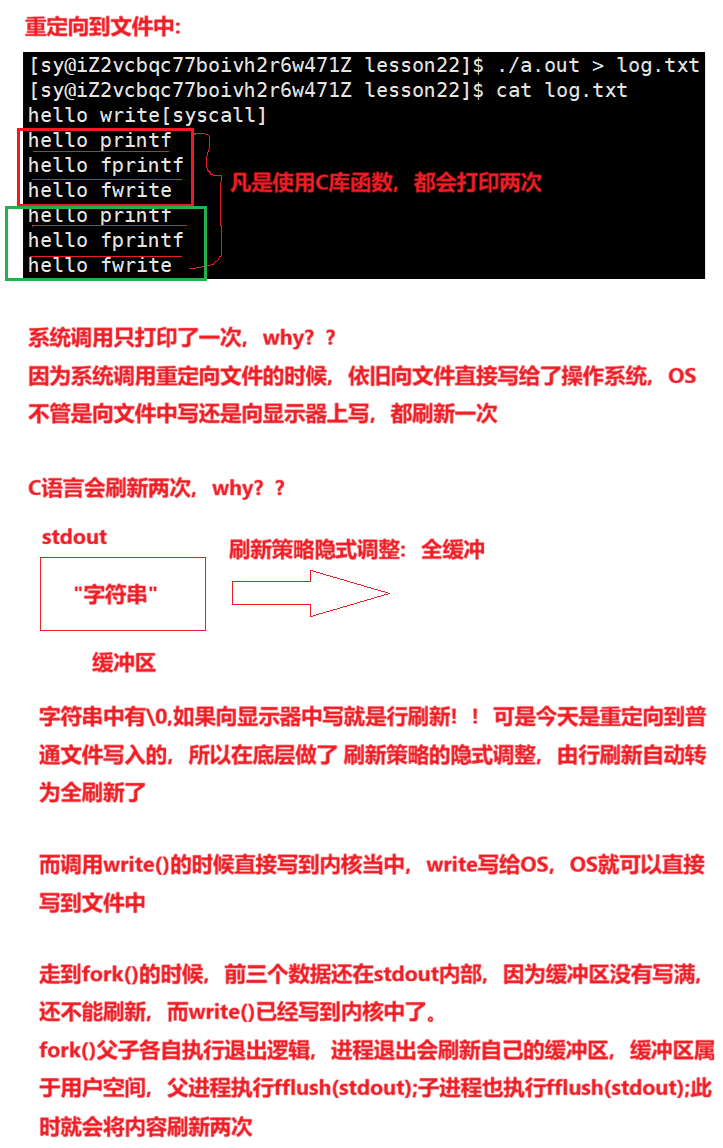

所以之前我们写进度条的时候做刷新的时候,为什么看不到?其实是进度条信息是写到了文件缓存区中,后来又是进程退出,exit()和_exit()之间的区别:_exit()直接终止进程,exit()会fflush刷新stdout()内容就显示出来了。
是因为操作系统需要一个从用户空间拷贝到内核空间的一个代码,将数据拷贝到缓冲区中,所以设计了write()函数。
至此,用户将数据交给OS的文件缓冲区中,至此用户层就完成了对应的工作,那OS对文件缓冲区又是什么时候刷新呢?

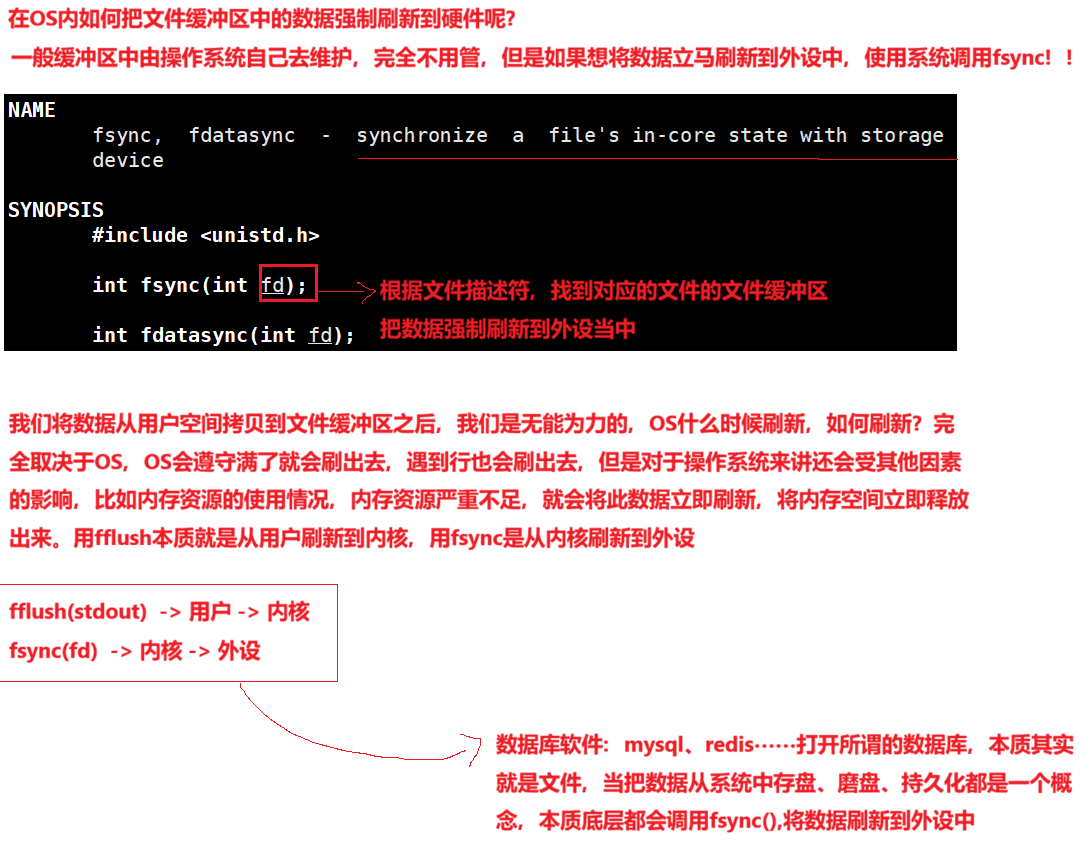
解决下一个问题:
代码如下:
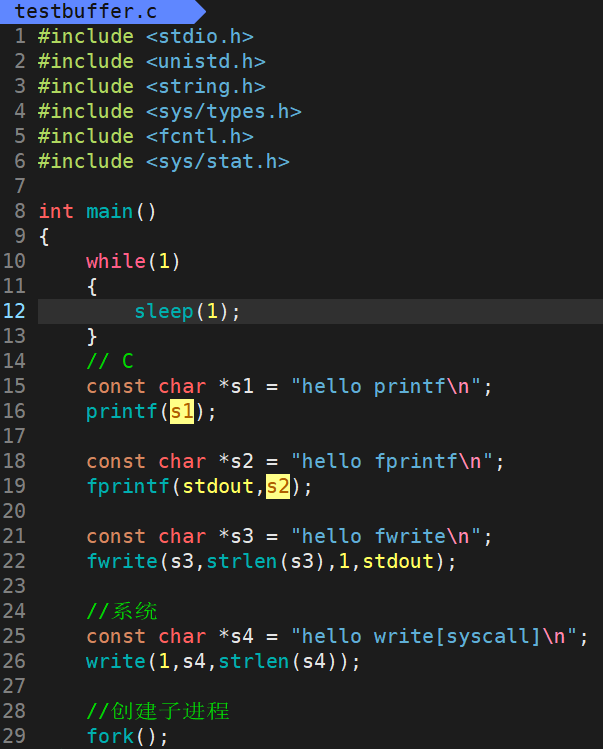
运行起来,查看此进程的id:

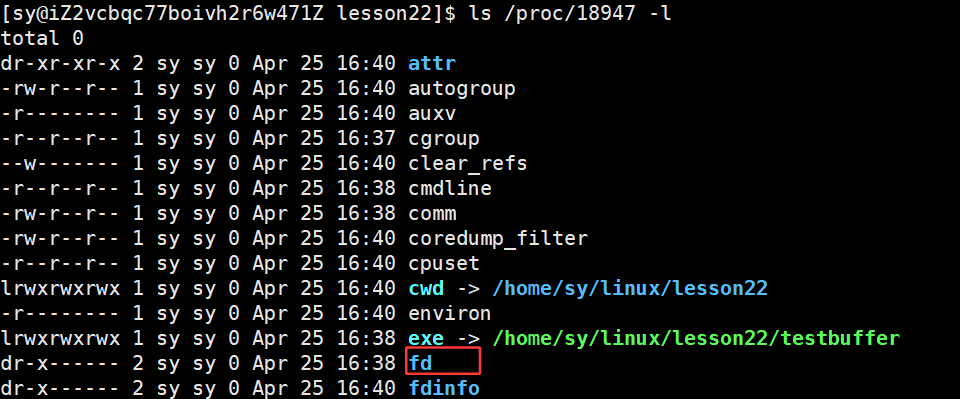

指向的就是标准输入、标准输出、标准错误。
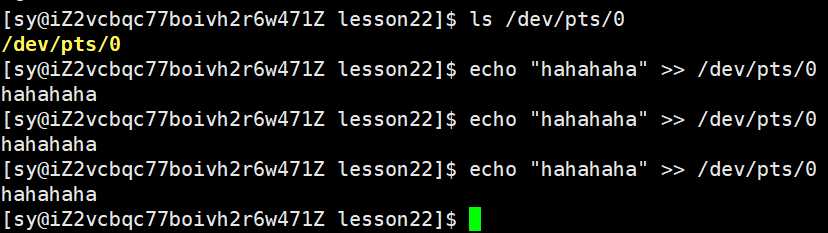
/dev/pts/0 指向的就是进程启动的当前的终端。
怎么这里的都是显示器?不应该是键盘、显示器、显示器吗?
装的是虚拟机的话,获取的数据就是通过见键盘和显示器输入和输出,但是我们用的是云服务器,只有终端文件做输入输出
8.7 标准错误
8.7.1 现象和操作
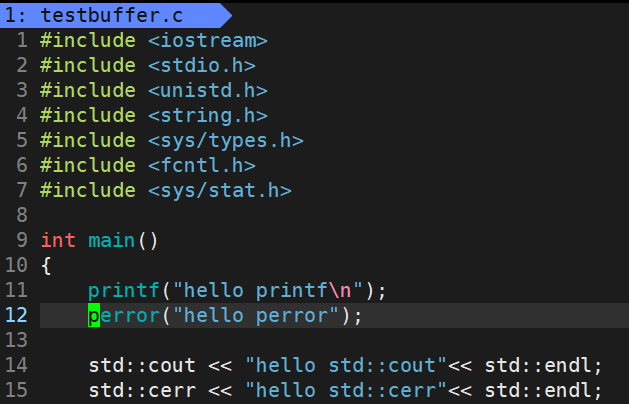
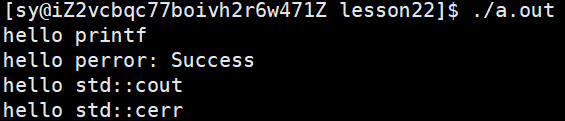
运行结果:
再次操作:
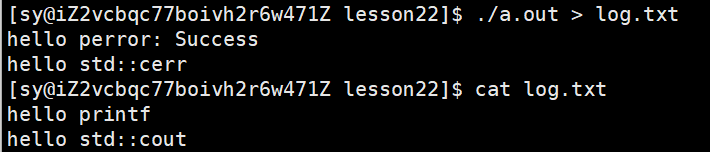
为什么会出现这样的情况呢?
原因:
因为输出重定向修改的是向标准输出1号文件进行重写,因为1和2指向的是标准输出、标准错误,都是显示器文件,都往显示器上打印,printf 和 cout 都是向1号里面打的,perror 和 cerr 都是向2号里面打的。所以输出重定向是对1号进行重定向,2号没有影响,所以1号里面写进去了,2号里面没有写进去。【只做了标准输出的重定向,标准错误并没有重定向】
所以回答问题:为什么C++里面要提供 perror 、cerr 这样的接口呢?
因为这样的接口是往2里面打的,如果可以话,就可以将正常输出和错误输出进行分离!!!
分离操作:
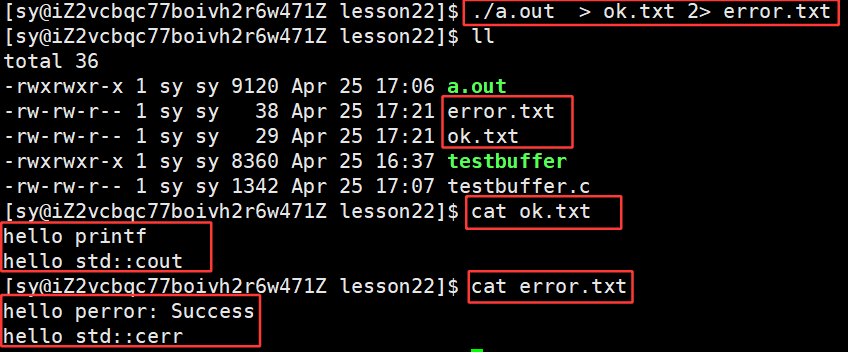
此操作的意义:
将来在编程时,输出信息有正确的消息,有错误的消息,Debug代码时关注错误的消息,这就是语言要提供2号的原因!!!
所以,以前的 ./a.out > log.txt 是一种简写,完整的写法为:
./a.out 1> log.txt 2>error.txt 或是追加:./a.out 1>> log.txt 2>>error.txt
所以:
为什么所有的语言都提供C,也提供cerr,未来出错时,喜欢用perror来打印,就是未来支持重定向,就可以写在不同文件中,写在文件中自己分析文件就只看错误消息。
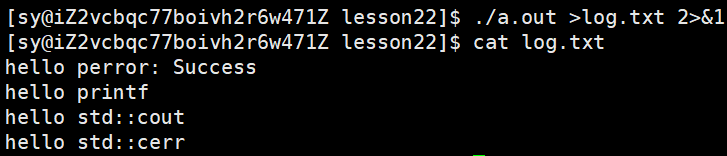
想把所有的信息重定向到一个文件,该如何操作??
./a.out >log.txt 2 &1:
&1 把1号文件描述符表里面的内容取出来拷贝到2里面,此时2也指向了log.txt文件
再来理解下面的代码:
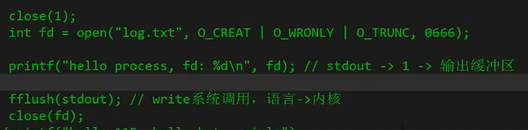
将1号文件关闭,打开log.txt,已经是全缓冲了,printf中的字符串是在用户缓冲区里,强制fflush是将用户缓冲区的数据刷新到内核,最后进程结束了,OS就把进程打开的所有文件都关掉,将文件内核的缓冲区刷新到外设,所以就可以看见了。