文章目录
-
- 前言
- 一、核心定义
- 二、标准体系结构图
- 三、场景推演
- 四、实战案例
-
- [4.1 需求分析](#4.1 需求分析)
- [4.2 架构图](#4.2 架构图)
-
- [4.2.1 面条代码架构图](#4.2.1 面条代码架构图)
- [4.2.2 原型模式架构图](#4.2.2 原型模式架构图)
- [4.3 类图对比](#4.3 类图对比)
-
- [4.3.1 面条代码类图](#4.3.1 面条代码类图)
- [4.3.2 原型模式类图](#4.3.2 原型模式类图)
- [4.4 时序图](#4.4 时序图)
-
- [4.4.1 面条代码时序图](#4.4.1 面条代码时序图)
- [4.4.2 原型模式时序图](#4.4.2 原型模式时序图)
- [4.5 代码分析](#4.5 代码分析)
-
- [4.5.1 面条代码(if-else/硬编码)](#4.5.1 面条代码(if-else/硬编码))
- [4.5.2 原型模式代码](#4.5.2 原型模式代码)
- 总结
前言
在软件开发和系统重构的过程中,我们经常会遇到创建复杂对象导致性能瓶颈的问题。
例如,当一个对象的初始化需要消耗较多计算资源,或者需要频繁发起网络/数据库请求时,每次都使用 new 关键字从头构建是非常低效的。
如果我们需要大量内容相似但细节略有不同的对象,如何优雅地解决性能与代码冗余的问题?
这就是原型模式大显身手的地方。
本文源码:https://github.com/likerhood/CodeDesignWork 其中原型模式在codedesign3.0系列
一、核心定义
原型模式(Prototype Pattern) 是一种创建型设计模式,它允许你通过复制(克隆)现有对象来生成新对象,而无需使代码依赖于它们所属的类。
其核心逻辑在于:将现有对象作为一个"原型",通过调用该原型的克隆方法(如 Java 中的 clone())来快速生成一个包含相同状态的全新实例。
后续可以根据业务需要,对克隆出来的新实例进行局部属性的修改。
二、标准体系结构图
原型模式通常包含以下几个角色:
- 抽象原型 (Prototype): 声明一个克隆自身的接口(通常是一个
clone()方法)。 - 具体原型 (Concrete Prototype): 实现克隆接口,具体定义如何复制自己。
- 客户端 (Client): 提出创建对象的请求,通过调用原型对象的
clone()方法来获得一个新的对象。
uses
implements
implements
<<interface>>
Prototype
+clone() : Prototype
ConcretePrototype1
-field1
+clone() : ConcretePrototype1
ConcretePrototype2
-field2
+clone() : ConcretePrototype2
Client
-prototype: Prototype
+operation()
三、场景推演
在 Java 中,原型模式的实现通常依赖于 Cloneable 接口和重写 Object 类的 clone() 方法。
示例:带附件的邮件(展示深拷贝)
假设我们有一个复杂的 Email 对象,里面包含一个 Attachment (附件) 对象。
Java
// 1. 附件类 (需要被深拷贝,所以也要实现 Cloneable)
class Attachment implements Cloneable {
private String fileName;
public Attachment(String fileName) {
this.fileName = fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public String getFileName() {
return fileName;
}
@Override
protected Attachment clone() throws CloneNotSupportedException {
// 附件类本身的克隆
return (Attachment) super.clone();
}
}
// 2. 具体原型:邮件类
class Email implements Cloneable {
private String title;
private String content;
private Attachment attachment; // 引用类型
public Email(String title, String content, Attachment attachment) {
this.title = title;
this.content = content;
this.attachment = attachment;
// 模拟耗时的初始化过程
try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); }
}
public Attachment getAttachment() {
return attachment;
}
// 核心:实现克隆方法
@Override
public Email clone() {
Email clonedEmail = null;
try {
// 首先进行浅拷贝 (复制基本数据类型和引用地址)
clonedEmail = (Email) super.clone();
// 然后进行深拷贝 (把引用类型的对象也克隆一份全新的)
clonedEmail.attachment = this.attachment.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return clonedEmail;
}
public void display() {
System.out.println("邮件标题: " + title + " | 附件名: " + attachment.getFileName());
}
}
// 3. 客户端调用
public class PrototypeTest {
public static void main(String[] args) {
// 创建原型对象 (耗时)
Attachment attachment = new Attachment("初始设计稿.pdf");
Email originalEmail = new Email("项目启动会议", "请查看附件", attachment);
System.out.println("--- 原型对象 ---");
originalEmail.display();
// 通过克隆创建新对象 (极快,不需要再等1秒)
Email clonedEmail = originalEmail.clone();
System.out.println("\n--- 克隆对象 ---");
clonedEmail.display();
// 验证深拷贝:修改克隆对象的附件名称
clonedEmail.getAttachment().setFileName("最终设计稿.pdf");
System.out.println("\n--- 修改克隆对象的附件后 ---");
System.out.print("原邮件: ");
originalEmail.display(); // 原邮件附件不应被改变
System.out.print("克隆邮件: ");
clonedEmail.display(); // 克隆邮件附件已改变
}
}注:除了重写 clone() 方法,在实际开发中,深拷贝也经常通过 序列化与反序列化 (Serialization) 或使用 JSON 转换工具 (如 Gson, Jackson) 来实现,这样可以避免繁琐地手动调用每一个子对象的 clone()。
四、实战案例
4.1 需求分析
假设我们需要开发一个在线考试系统。为了防止考生作弊,我们需要为每一位考生生成一份"专属试卷":
- 试卷包含的题目内容是相同的(保证公平性)。
- 每份试卷的题目顺序必须随机打乱。
- 每道选择题的选项顺序(A/B/C/D)必须随机打乱,且对应的正确答案标识也要随之动态映射。
如果使用传统方式,面对一万名考生,系统需要从数据库读取一万次题库,并执行一万次极其繁琐的组卷和洗牌逻辑,这无疑会压垮数据库和应用服务器。
我们需要实现一个试卷生成器:
- 基础物料: 选择题(
ChoiceQuestion)、问答题(AnswerQuestion)。 - 核心动作: 输入考生姓名和学号,输出一份题目打乱、选项打乱的专属试卷。
4.2 架构图
4.2.1 面条代码架构图
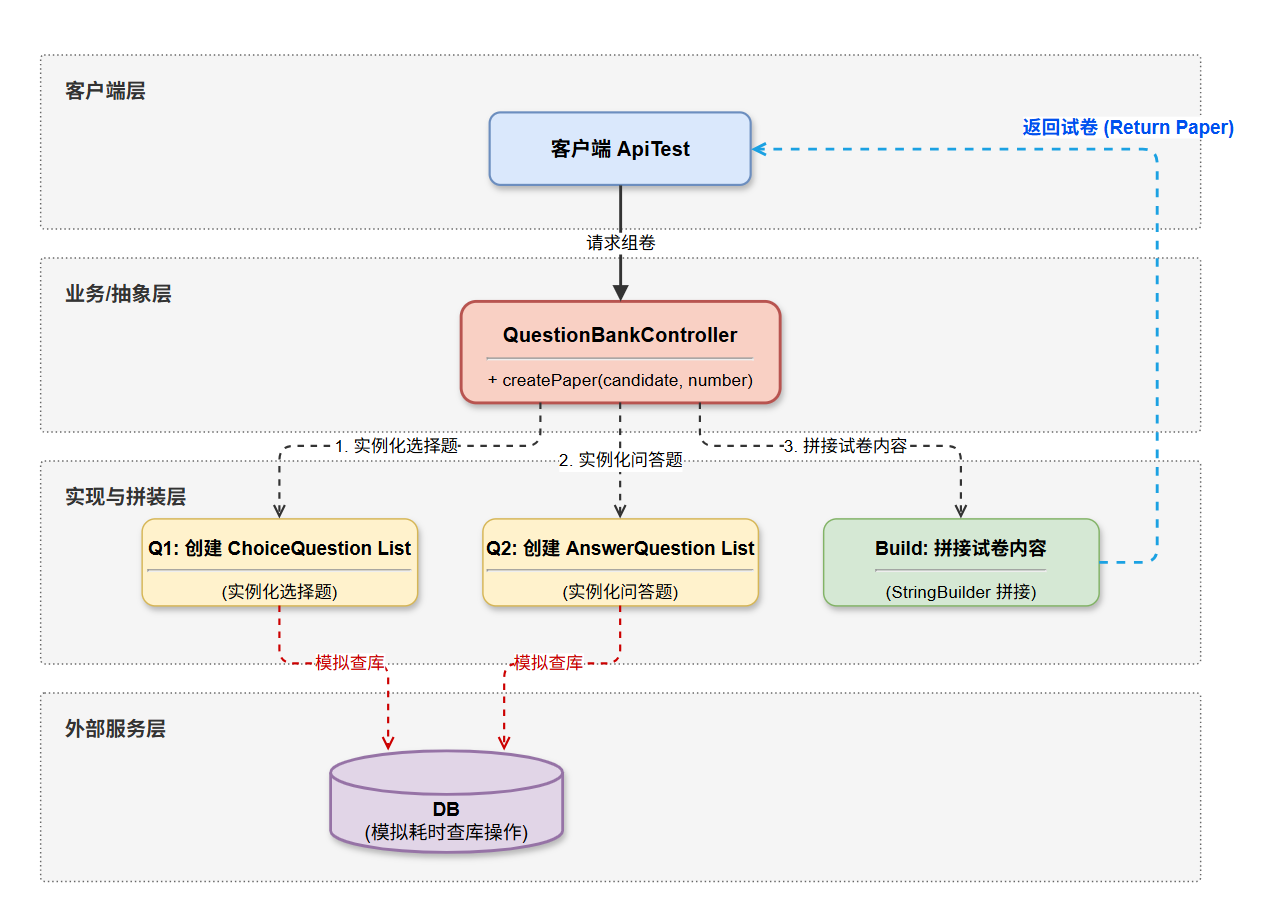
痛点:客户端每次调用,Controller 都要从头创建所有题目列表,相当于每次都走一次全量构建(模拟查库),耗时极高。
4.2.2 原型模式架构图
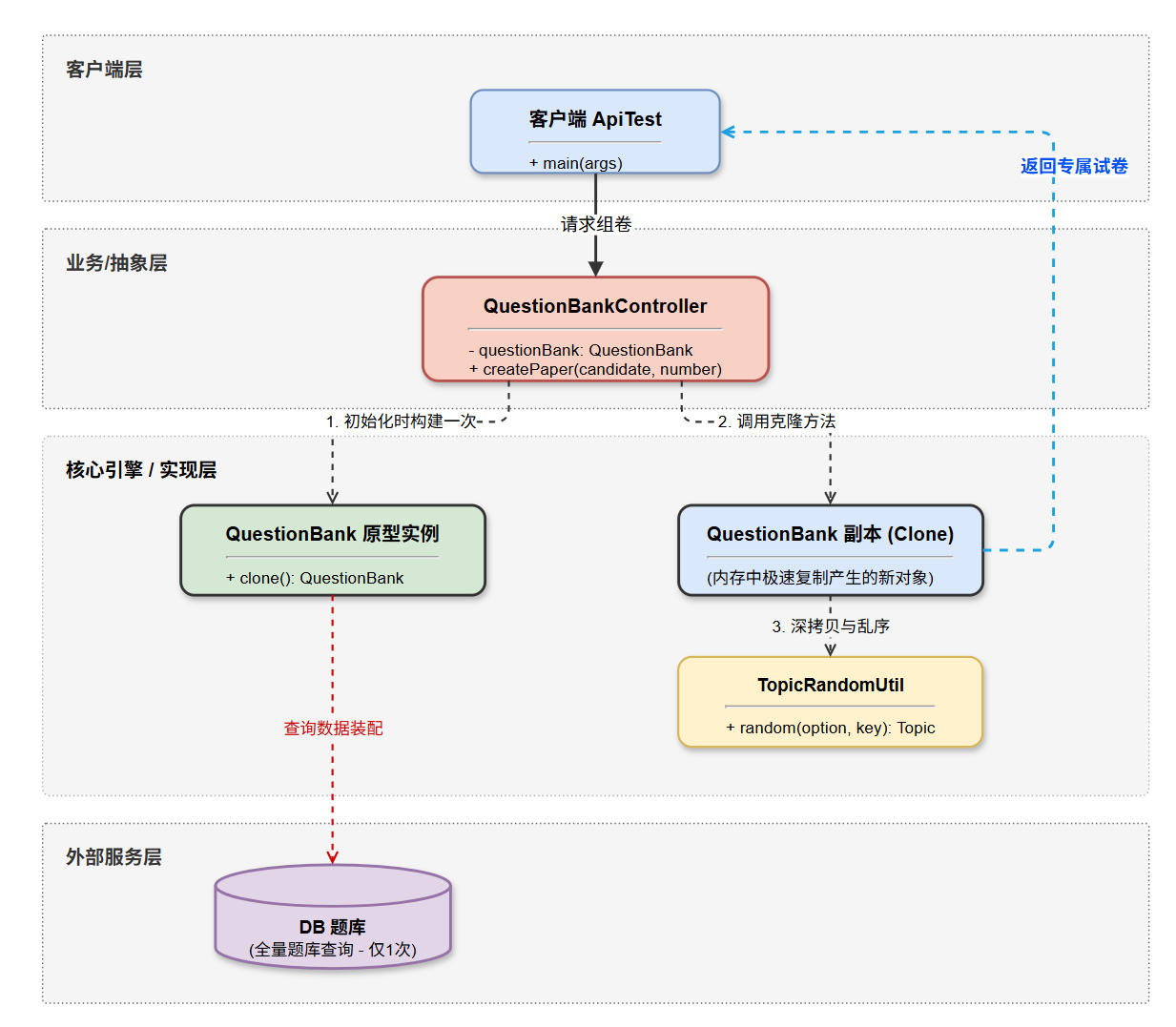
4.3 类图对比
4.3.1 面条代码类图
creates
creates
QuestionBankController
+createPaper(candidate: String, number: String) : String
ChoiceQuestion
-name: String
-option: Map<String, String>
-key: String
AnswerQuestion
-name: String
-key: String
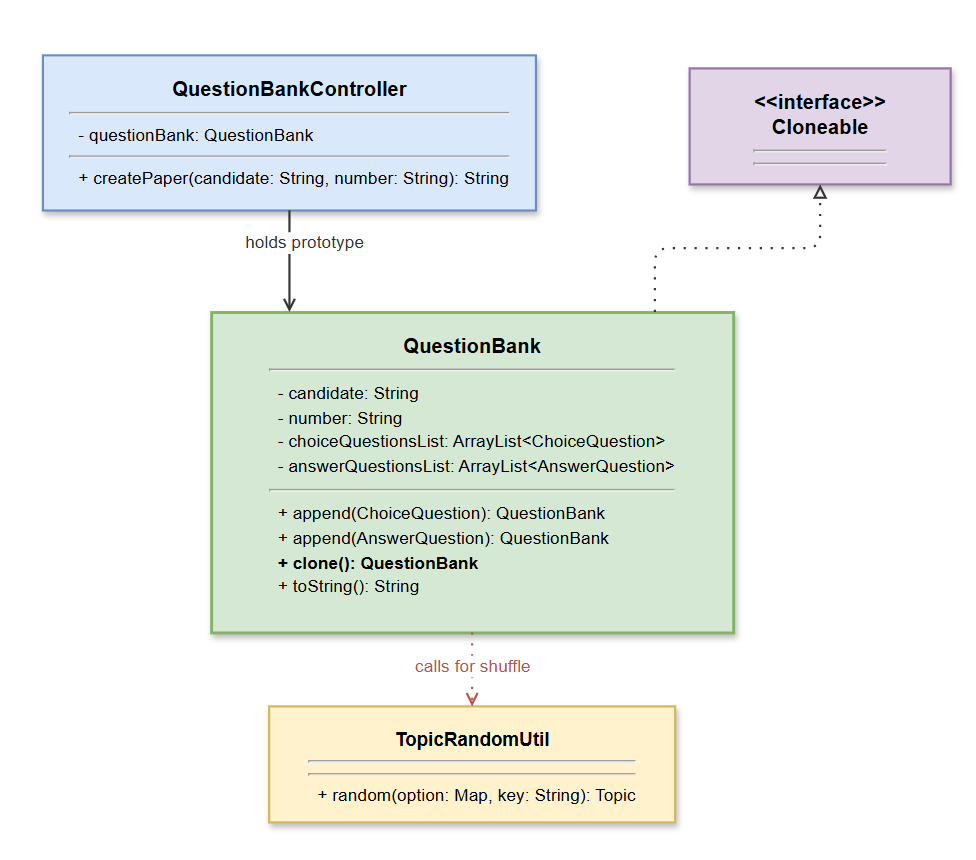
4.3.2 原型模式类图
4.4 时序图
4.4.1 面条代码时序图
QuestionBankController ApiTest QuestionBankController ApiTest createPaper("花花", "1001") new ArrayList<ChoiceQuestion>() new ArrayList<AnswerQuestion>() StringBuilder 拼接 返回花花试卷 createPaper("豆豆", "1002") new ArrayList<ChoiceQuestion>() new ArrayList<AnswerQuestion>() StringBuilder 拼接 返回豆豆试卷
4.4.2 原型模式时序图
TopicRandomUtil QuestionBank (Prototype) QuestionBankController ApiTest TopicRandomUtil QuestionBank (Prototype) QuestionBankController ApiTest 构造函数中完成原型对象的初始化(只查一次库) loop 每道选择题 append(ChoiceQuestion) append(AnswerQuestion) createPaper("花花", "1001") clone() Collections.shuffle(题库) random(options, key) 乱序后的 Topic 返回克隆且乱序的新 QuestionBank 设置考生姓名/学号 返回花花试卷
4.5 代码分析
4.5.1 面条代码(if-else/硬编码)
在 codedesign3.0-1 中,QuestionBankController 的 createPaper 方法包揽了所有的脏活累活。
Java
public class QuestionBankController {
public String createPaper(String candidate, String number){
// 每次调用都会重新 new 集合,模拟了极大的资源开销
List<ChoiceQuestion> choiceQuestionList = new ArrayList<>();
choiceQuestionList.add(new ChoiceQuestion("JAVA所定义的版本中不包括", new HashMap<String, String>() {{ ... }}, "D"));
// ... 极其冗长的题目硬编码录入 ...
// 拼接试卷
StringBuilder detail = new StringBuilder(...);
// ...
return detail.toString();
}
}问题暴露: 代码极度臃肿。如果在高并发场景下,一千个考生并发请求,由于没有对象复用机制,堆内存中会瞬间产生海量的冗余对象,垃圾回收(GC)压力剧增。
4.5.2 原型模式代码
这是优雅的重构版本。首先,我们将"试卷"抽象为一个 QuestionBank 类,并实现 Cloneable 接口。
最核心的逻辑在于 clone() 方法的重写:
Java
public class QuestionBank implements Cloneable{
// ... 属性省略 ...
@Override
public QuestionBank clone() throws CloneNotSupportedException{
// 1. 浅克隆基础对象
QuestionBank questionBank = (QuestionBank) super.clone();
// 2. 深克隆引用类型(关键点:将题目列表也复制一份,避免各试卷互相影响)
questionBank.choiceQuestionsList = (ArrayList<ChoiceQuestion>) choiceQuestionsList.clone();
questionBank.answerQuestionsList = (ArrayList<AnswerQuestion>) answerQuestionsList.clone();
// 3. 原型模式的高级应用:在克隆过程中顺便修改状态(题目乱序)
Collections.shuffle(choiceQuestionsList);
Collections.shuffle(answerQuestionsList);
// 4. 选项乱序处理
ArrayList<ChoiceQuestion> choiceQuestionsList = questionBank.choiceQuestionsList;
for (ChoiceQuestion choiceQuestion : choiceQuestionsList) {
Topic newTopic = TopicRandomUtil.random(choiceQuestion.getOption(), choiceQuestion.getKey());
choiceQuestion.setOption(newTopic.getOption());
choiceQuestion.setKey(newTopic.getKey());
}
return questionBank;
}
}而在 QuestionBankController 中,工作量骤减:
Java
public class QuestionBankController {
// 作为原型对象,只在容器/系统启动时初始化一次
private QuestionBank questionBank = new QuestionBank();
public QuestionBankController(){
// ... 一次性加载巨量题库 ...
}
public String createPaper(String candidate, String number) throws CloneNotSupportedException{
// 极速生成试卷,直接在内存中基于二进制流进行拷贝,性能极高
QuestionBank questionBankClone = questionBank.clone();
questionBankClone.setCandidate(candidate);
questionBankClone.setNumber(number);
return questionBankClone.toString();
}
}总结
通过引入原型模式,我们实现了从"每次重新构建"到"一次构建,无限克隆"的架构跃迁。这带来的直接好处是:
- 性能的大幅提升: 绕过了复杂的构造函数初始化过程,内存级别的对象复制在 JVM 中执行速度极快。
- 代码职责的解耦: Controller 不再负责繁琐的数据装配,它只需持有一个"母版"(Prototype),在需要时调用
clone即可。
工程实践注意点:
在使用原型模式时,务必警惕深拷贝与浅拷贝 的陷阱。在实战代码的 QuestionBank 中,如果只执行 super.clone(),那么所有的试卷将共享同一个题目列表的内存引用。一旦某一试卷打乱了题目,其他所有试卷也会同步被打乱。因此,针对对象内部包含的 ArrayList 或 Map 等引用类型,必须手动调用它们自身的 clone() 方法来实现彻底的深拷贝。
适用场景
- 资源优化场景: 类的初始化需要消耗非常多的资源(数据、硬件资源等)。
- 性能和安全要求的场景: 通过
new产生一个对象需要非常繁琐的数据准备或访问权限,可以使用原型模式提高性能。 - 一个对象多个修改者的场景: 一个对象需要提供给其他对象访问,并且各个调用者可能都需要修改其值。可以考虑使用原型模式拷贝多个对象供调用者使用(比如在某些状态机或规则引擎中保存历史状态)。